はじめに
LangChainのOpen Deep ResearchをAmazon Bedrock経由で使ってみるときにエラーがいくつか出て引っかかったので備忘録として書いておきます。
2025年6月20日時点(最新コミットID:e5a5160a398a3699857d00d8569cb7fd0ac48a4f)のコードでは以下の変更で動かせることを確認しています。
ちなみに本ライブラリをテーマにこちらのLT会でお話ししました(資料)。
前提
- マルチエージェント型のみ記載
- Web検索ツール:Tavily
- 使用するLLM:Bedrock経由のClaude 3.5 Haiku
- 上記リポジトリをクローンしておく
- ローカルでLangGraph Studioを起動してレポート生成を試せるため。
- 動作環境:Mac PC
コードの変更
configuration.py
open_deep_research/src/open_deep_research/configuration.pyの84行目と85行目に以下を追加します。
Web検索ツール内のsummarization_modelとエージェント(supervisor_modelとresearcher_model)に設定するリージョンやAWSプロファイル名などを格納します。
@@ +78,78 +84,84 +85,85 @@
+ summarization_model_kwargs: Optional[Dict[str, Any]] = None
+ supervisor_model_kwargs: Optional[Dict[str, Any]] = None
+ researcher_model_kwargs: Optional[Dict[str, Any]] = None
utils.py
open_deep_research/src/open_deep_research/utils.pyを変更します。
以下の変更で上記の設定をinit_chat_model()に設定できるようにします。
@@ +1404,1404 @@
+ summarization_model_kwargs = get_config_value(configurable.planner_model_kwargs or {})
@@ -1416,1416 +1416,1417 @@
- **extra_kwargs
+ **extra_kwargs,
+ **summarization_model_kwargs
multi_agent.py
open_deep_research/src/open_deep_research/multi_agent.pyを変更します。
以下の変更で上記の設定をinit_chat_model()に設定できるようにします。
@@ +197,197 @@
+ supervisor_model_kwargs = get_config_value(configurable.supervisor_model_kwargs or {})
@@ -199,199 +199,199 @@
- llm = init_chat_model(model=supervisor_model)
+ llm = init_chat_model(model=supervisor_model, **supervisor_model_kwargs)
@@ +356,356 @@
+ researcher_model_kwargs = get_config_value(configurable.researcher_model_kwargs or {})
@@ -358,358 +358,358 @@
- llm = init_chat_model(model=researcher_model)
+ llm = init_chat_model(model=researcher_model, **researcher_model_kwargs)
以下のオプションはBedrock Converse APIには存在せず扱えないので削除(またはコメントアウト)します。
@@ -214,214 -379,379 @@
- parallel_tool_calls=False,
- parallel_tool_calls=False,
LLMからWeb検索ツール(Tavily)への値の受け渡しがうまくいくように修正します。
@@ +263,263 -265,265 +265,265 -267,267 +267,267 @@
+ fixed_args = fix_search_tool_args(tool_call["name"], tool_call["args"], search_tool_names)
# Perform the tool call - use ainvoke for async tools
try:
- observation = await tool.ainvoke(tool_call["args"], config)
+ observation = await tool.ainvoke(fixed_args, config)
except NotImplementedError:
- observation = await tool.ainvoke(tool_call["args"], config)
+ observation = tool.invoke(fixed_args, config)
@@ +414,414 -416,416 +416,416 -418,418 +418,418 @@
+ fixed_args = fix_search_tool_args(tool_call["name"], tool_call["args"], search_tool_names)
# Perform the tool call - use ainvoke for async tools
try:
- observation = await tool.ainvoke(tool_call["args"], config)
+ observation = await tool.ainvoke(fixed_args, config)
except NotImplementedError:
- observation = await tool.ainvoke(tool_call["args"], config)
+ observation = tool.invoke(fixed_args, config)
@@ +186,205 @@
+ def fix_search_tool_args(tool_name: str, tool_args: dict, search_tool_names: set[str]) -> dict:
+ """Fix tool arguments for search tools, particularly handling string queries that should be lists"""
+ if tool_name not in search_tool_names:
+ return tool_args
+
+ # Fix queries parameter if it's a string that looks like a list
+ if "queries" in tool_args:
+ queries = tool_args["queries"]
+ if isinstance(queries, str):
+ # Try to parse as JSON first
+ try:
+ parsed_queries = json.loads(queries)
+ if isinstance(parsed_queries, list):
+ tool_args = {**tool_args, "queries": parsed_queries}
+ else:
+ # If it's not a list after parsing, wrap it in a list
+ tool_args = {**tool_args, "queries": [str(parsed_queries)]}
+ except (json.JSONDecodeError, TypeError):
+ # If JSON parsing fails, treat as a single query
+ tool_args = {**tool_args, "queries": [queries]}
+ return tool_args
LangGraph Studioを起動してレポートを生成してみる
ターミナルで以下を操作します。
# リポジトリをクローンしてリポジトリ直下に移動する
$ git clone https://github.com/langchain-ai/open_deep_research.git
$ cd open_deep_research
# 環境変数を設定する。TavilyのAPIキーを記載しておく。
$ cp .env.example .env
# uvをイントールする
curl -LsSf https://astral.sh/uv/install.sh | sh
# LangGraph serverとして起動する
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev --allow-blocking
ここからは画面から操作します。


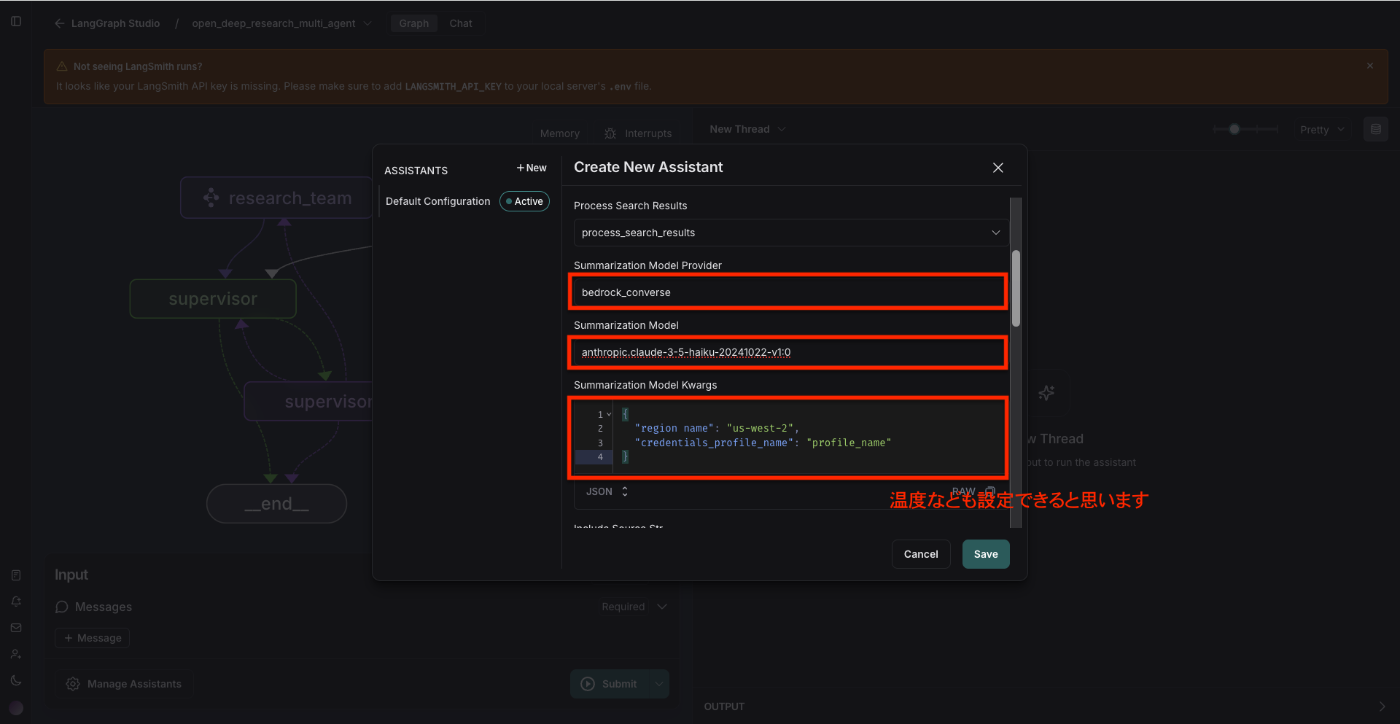

上記まで設定した後、Saveボタンを押下して、質問してみます。

これでレポート生成を始める or トピックを明確にする質問をした後、レポートを生成を開始してくれると思います。
おわりに
ここまでご覧いただきありがとうございました。
サッとBedrock経由で試したいだけなのにエラーが出て試せないという方の参考になると幸いです。

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion