はじめに
DynamoDBのフィルタリング戦略について、DynamoDBBookの著者として知られるAlex Debrieさんの登壇をYoutubeで見て学習したので、ここにアウトプットします。
出典:YouTube「Data modeling with Amazon DynamoDB – Part 2(re:Invent 2020)」
登壇者:Alex Debrie
対象読者
- DynamoDBの設計に興味がある
- DynamoDBの基本概念はある程度知っている
フィルタリング戦略
フィルタリングはどんなデータベースを選ぶにしても大事な要素です。
リレーショナルデータベースではWhere句を使うことで、列の値でフィルタリングしたり、テーブルを結合してその列の値でフィルタリングしたりできました。
また、現在時刻を用いた組み込み関数を使ったりもできました。
しかし、DynamoDBにはそのような柔軟性はありません。
Where句もなければ、組み込み関数もありません。
なので、データモデリングに関してより意識的に考える必要があります。
Alex Debrieさんは以下4つのフィルタリング戦略を紹介されています。
- パーティションキーでのフィルタリング
- ソートキーでのフィルタリング
- Sparse index
- クライアントサイドでのフィルタリング
1.パーティションキーでのフィルタリング
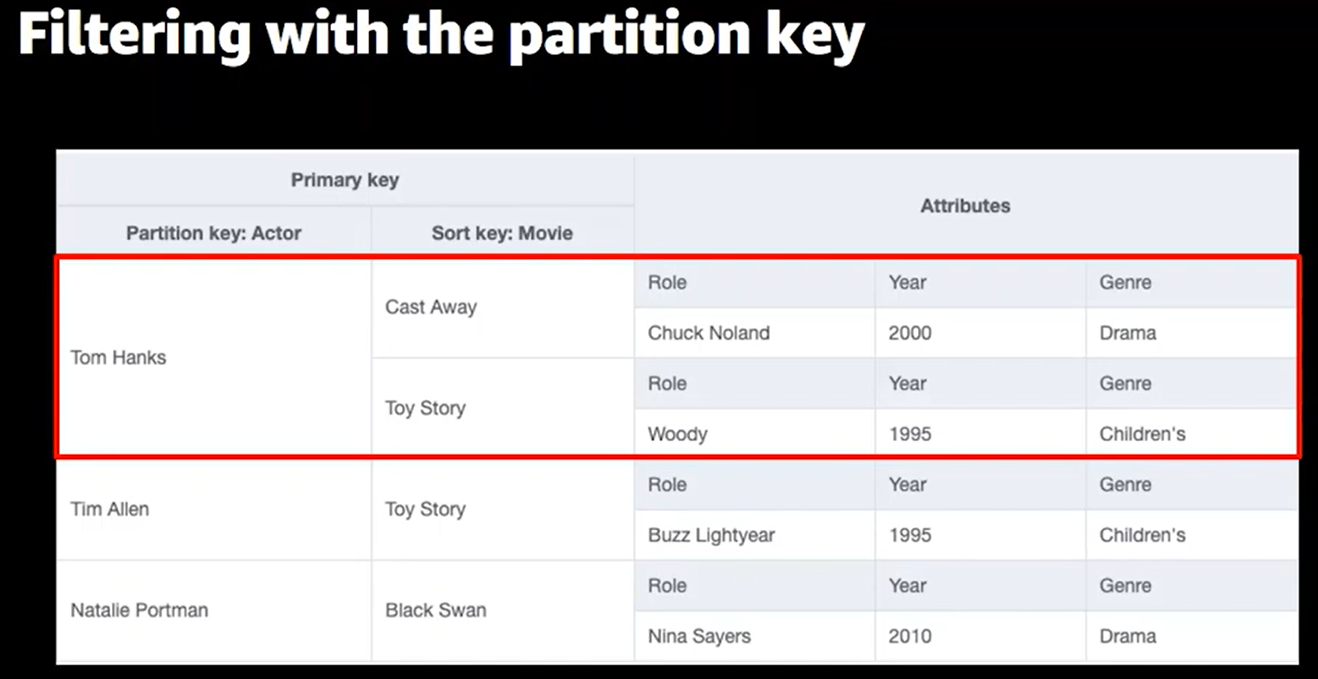
オーソドックスに、パーティションキーが完全一致するものをQueryで取得する方法です。
「Tom Hanksの映画をすべてください」という取得の仕方ですね。
ちなみにパーティションキーは完全一致でのQueryしかできず、範囲検索とかはできません。
2.ソートキーでのフィルタリング
パーティションキーだけじゃ足りなくて追加のフィルタリングパターンが必要になることがあります。
そのような場合にソートキーが役立ちます。
パーティションキー + ソートキーでフィルタリングします。
ソートキーでのフィルタリングには2つのパターンがあります。
- ソートキー自体に意味があるパターン
- モデリングによってソートキーが意味を持つパターン
ソートキー自体に意味があるパターン
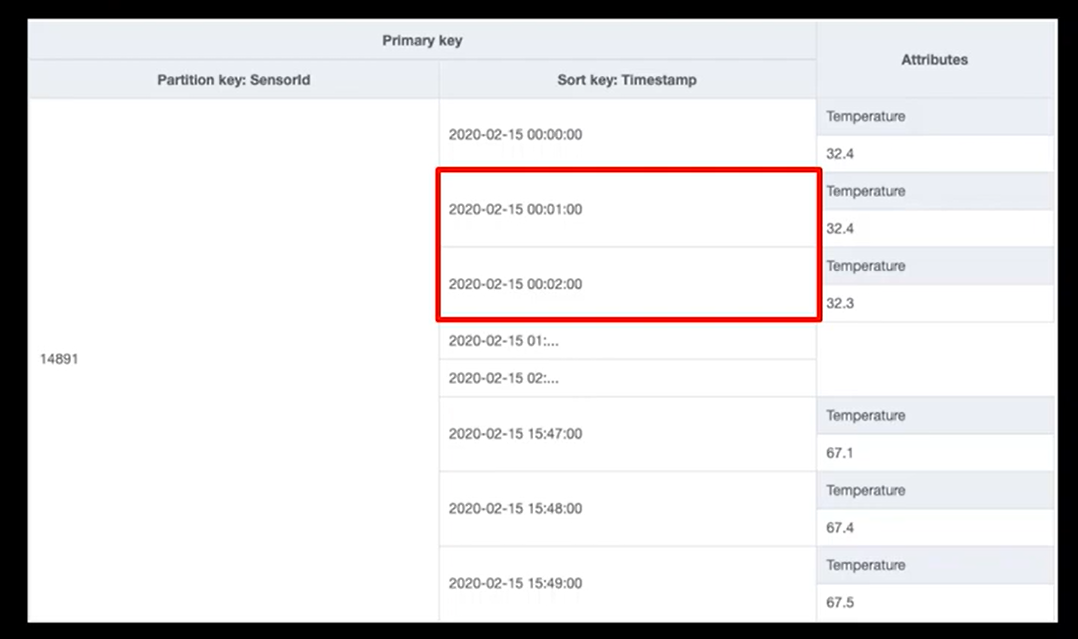
IOTアプリケーションのデータの例です。
パーティションキーにセンサーID、ソートキーにタイムスタンプを持っています。
ソートキー自体に意味があり、タイムスタンプに基づいて順序付けされています。
ソートキーは完全一致も範囲検索もできます。
なので、特定のタイムスタンプのデータを取得することもできますし、
特定の期間のデータを取得することもできます。
モデリングによってソートキーが意味を持つパターン

これはGithubの情報をモデリングした例です。
6つの異なるItemが同じパーティションキーにあり、3つの種類のアイテムがあります。
Repo item
テーブル内のGithubリポジトリを参照するものです。
Issue items
Githubのリポジトリにアクセスすると、issueを作成できます。
リポジトリとissueは1対多の関係です。
Star items
ユーザーがリポジトリにアクセスし、気に入ったことをスターをつけることで示せます。
リポジトリとスターは1対多の関係です。
ソートキーの種類によってフィルタリングすることで、異なるアイテムのコレクションを取得することができます。
特定のリポジトリのすべてのIssueを取得するというアクセスパターンを考えてみましょう。
同じリクエストでIssueとそのリポジトリを取得したいというものです。
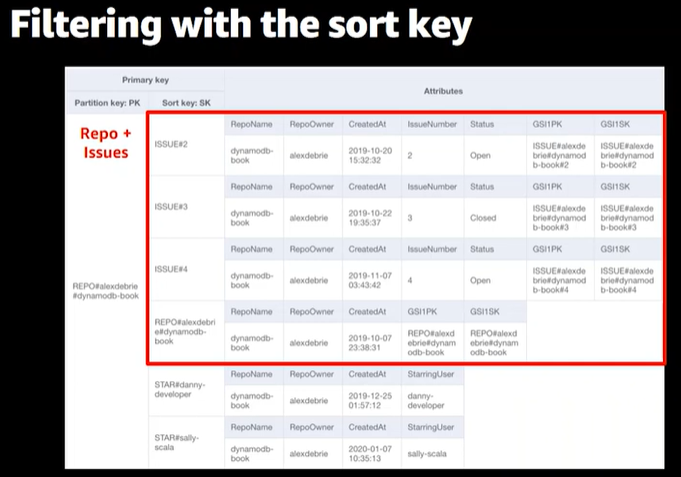
「このパーティションキーとソートキーの条件を指定してクエリを実行し、Issueからリポジトリへと移動することで実現できます」
とAlex Debrieさんはおっしゃてました。
自分的にはソートキーを具体的にはどう指定するのか気になったので調べました。
前提知識として、ソートキーが文字列順でソートされているということを抑えておく必要があります。
文字列順ではISSUE#、REPO#、STAR#の順になるため、同じパーティションキー内ではこの順序でアイテムが並ぶと理解しておく必要がありそうです
その前提のもと以下のようなクエリになると思います。
Key("PK").eq("REPO#alexdebrie#dynamodb-book") &
Key("SK").between("ISSUE#", "REPO~")
ISSUE# からREPO~までを範囲指定するクエリになっています。
~ は「チルダ」というのですが、これは ASCIIコード的にアルファベットより後に来るので、
"REPO#..." をすべて含む範囲を確実にカバーできます。
別のアクセスパターンとして、特定のリポジトリのすべてのStarを取得するということを考えてみましょう。
この場合も考え方は同様で、以下のようなクエリになるでしょう。
Key("PK").eq("REPO#alexdebrie#dynamodb-book") &
Key("SK").between("REPO#", "STAR~")
なるほど~と思いつつ、文字列順に頼って範囲指定するというやり方はなかなか危うさもあるなと個人的には感じました。
たとえば、「Organization#」というアイテムを追加したくなったら、ISSUE# からREPO~の間に存在することになるので、その時には改修が必要になるなぁなどと思いました。
3. Sparse index
まずはセカンダリインデックスについておさらいします。
セカンダリインデックスを作ると新しいprimary keyを作成できます。
セカンダリインデックスにprimary keyを定義すると、元テーブル内のその属性を持つアイテムがすべてコピーされます。
言い換えると、セカンダリインデックスにパーティションキー(とソートキー)を定義すると、元テーブル内でそのキー属性を持つアイテムのみがセカンダリインデックスにコピーされます。この特性を利用して、特定の条件を満たすアイテムだけをインデックスに含めることができます。
このセカンダリインデックスを使う際の特徴を戦略的に活用することで、特定の条件に基づいて望まないItemをインデックスから除外できます。
2つの戦略を見ていきます。
条件に基づき、エンティティタイプ内でフィルタリングする

組織とユーザーをモデリングした例です。
以下のアクセスパターンを想像します。
「特定の組織の管理者ユーザーをすべて取得したい」
このようなアクセスパターンに対応するためにグローバルセカンダリインデックス(GSI)を使用します。

GSI1PK,GSI1SKという汎用primary keyを追加しています。
3個目と5個目のItemを見ると、Adminロールを持つItemのみGSI1PKに「ORG#ほにゃらら」となっています。
2個目Itemを見ると、MemberロールのItemなのでGSI1PKを持っていません。
1個目と4個目のItemは組織Itemでこれらはまた違うアクセスパターンで使用します。
(今回の説明には関係ないので無視してください)
セカンダリインデックス作成によって作られた新しいテーブルがどうなってるか見てみましょう。

「BERKSHIREHATHAWAY社のAdminロールを持つユーザーをすべて取得したい」という場合には、
GSI1PKが「ORG#BERKSHIRE」に一致するものを検索するという風になり、Warren Buffetが取得できます。
まとめると、管理者ユーザーにのみGSI1PKとGSISKの値を与えることで、管理者とメンバーをフィルタリングしました。
単一のエンティティタイプをセカンダリインデックスに投影する

Eコマースストアの例を見ていきましょう。
PKを見ると3つの種類のItemがあることがわかります。
- CUSTOMER#:顧客
- ORDER#注文
- INVENTORY:在庫
マーケティング部から「毎朝、すべての顧客にマーケティングメールを送信したい」と言われたとします。
アクセスパターンでいうと、「顧客Itemだけ取得したい」という場合ですね。
そのような場合は、以下のようにCustomerIndexIdという属性を追加し、顧客Itemにのみ付与します。

このCustomerIndexIdをセカンダリインデックスとして定義すると、以下のように新しいテーブルが作られます。

複数種類のItemを含むシングルテーブル設計を使用している場合、単一の種類のItemだけ取得したい場合があります。そのような場合にこのフィルタリング戦略は有効です。
4. クライアントサイドでのフィルタリング
クライアントサイドでのフィルタリングは、バックエンドサーバーやフロントエンドでフィルタリングするというものです。
以下のような状況の時に効果的な方法です。
- DynamoDBのモデリングでフィルタリングするのが難しい場合
- データセットがそれほど大きくない場合

俳優と映画をモデリングした例で見ていきましょう。
たとえば、「ユーザーはTom Hanksのページに行き、2000年以前のすべてのデータを表示してほしい」という場合を考えてみます。
DynamoDBのモデリングでフィルタリングすることは可能かもしれませんが、Tom Hanksのデータはそんなに多くありません。
なので、ユーザーがTom Hanksのページにアクセスしたら、Tom Hanksのデータをすべて取得して、ブラウザに返し、ブラウザ上でフィルタリングしてもらうことが可能です。
データ量が多くない場合はDynamoDBでフィルタリングをやりきる必要はないという考え方を持っておきたいです。
セカンダリインデックスを使うと追加のコストもかかりますしね。
DynamoDBでなんでも解決しようとするのではなく、アプリケーション全体で解決しようという考えを持つことが大事です。
感想・気づき
Alex Debrieさんが動画の中で「パーティションキーのみ、またはパーティションキーとソートキーでのフィルタリングで年間の8~9割はカバーできる」と言っていました。
逆に言うと、8~9割カバーできないならば、DynamoDBではないデータベースを選定すべきなのでは?という疑いを持っても良いのかなと思いました。

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion