【AWS re:Invent 2025】 AWS DevOps Agentのワークショップに参加してみた
先週、AWS re:Invent 2025に参加させてもらいました。
今回のre:Inventでは「AI Agent」が大きなキーワードになっていましたが、その中でも開発・運用にフォーカスした 「AWS DevOps Agent」 のワークショップに参加してきました。
また、ワークショップで隣だった方と話ながらできたのが良い経験だったので、そこで得た気づき等も書きたいと思います。
AWS DevOps Agentとは?
DevOps Agentは、re:Invent 2025で発表された「Frontier Agents」の一つです(他にはKiro Autonomous Agent、AWS Security Agentなどが発表されました)。
「開発・運用」 に焦点を当てたAIエージェントで、主な役割は以下の3点です。
- 調査 (Investigation): 何が起きているかログ等から原因を特定する
- 修正プランの提案 (Mitigation): 障害を復旧させるための手順を提案する
- 予防策の提案 (Prevention): 再発防止策を提案する
なお、現時点(2025年12月)ではプレビュー版となっており、バージニア北部リージョンでのみ利用が可能です。
ワークショップのシナリオ
今回参加したワークショップでは、以下のようなトラブルシューティングを体験しました。
- システム構成: LambdaからDynamoDBへ書き込みを行なっているシステム
- 発生している問題: Lambda関数でエラーが発生している
- 原因: 誰かが手動でDynamoDBのWCU(書き込みキャパシティユニット)を 250から2 に書き換えてしまったため、書き込みスロットリングが発生している
これに対して、DevOps Agentを使って原因発見して、修正できるのか?という内容でした。
1. 調査(Investigation)
まず、DevOps Agentの管理画面(チャット形式)で調査を依頼します。
Investigate the DynamoDBWriteThrottleAlarm alarm といった自然言語で指示を出すと、エージェントが自律的に動き出します。

CloudWatchのログや
CloudTrailのログを見て、DevOpsエージェントが調査を開始。
調査の進捗がタイムライン形式で画面にどんどん出力されていきます。


的確な根本原因の特定
最終的にエージェントが出した「根本原因(Root Cause)」のレポートです。
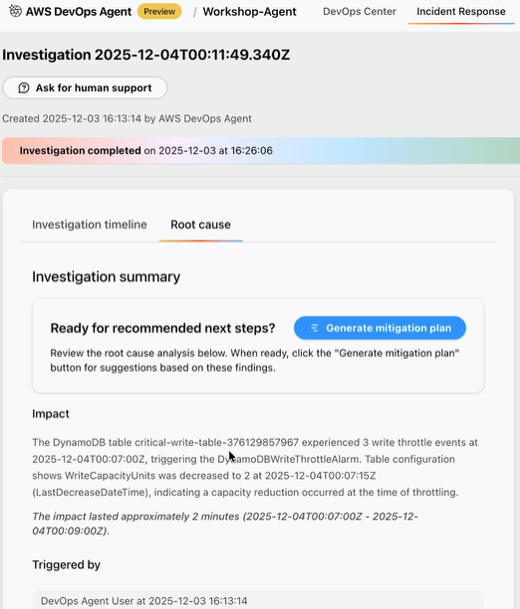

Manual reduction of DynamoDB write capacity from 250 WCU to 2 WCU
2025-12-04T00:07:11Zに、ユーザーが手動でUpdateTable APIを実行し、書き込みキャパシティを250 WCUから2 WCU(99.2%減)に変更しました。これがスロットリングの直接的な原因です。
CloudTrailのログから「誰が」「いつ」「何をしたか」まで特定し、それが現状のエラー(スロットリング)とどう関係しているかまで調査してくれました。
AIならではの「揺らぎ」
面白かったのが、隣に座っていた方と画面を見比べた時のことです。
調査内容は似ており、結論も同じでしたが、書きっぷりや表現は私の画面と異なっていました。
AIなので全く一緒にはならないよなと感じる瞬間でした。
2. 修正プランの提案(Mitigation Plan)
原因がわかったところで、「Generate mitigation plan」ボタンを押すと、AIが復旧手順を生成してくれます。
この生成された手順が、「慎重かつ丁寧」 だったのが印象的です。
単に「WCUの設定を戻す」だけでなく、以下の4ステップ構成で提案されました。
※コマンドを実行するのは人間でした。
Step 1: Prepare(現状確認)

変更を加える前に、現在のシステムの状態(現在のWCU設定値など)を記録し、万が一のロールバックに備えたベースラインを作ります。
Step 2: Pre-validate(事前検証)
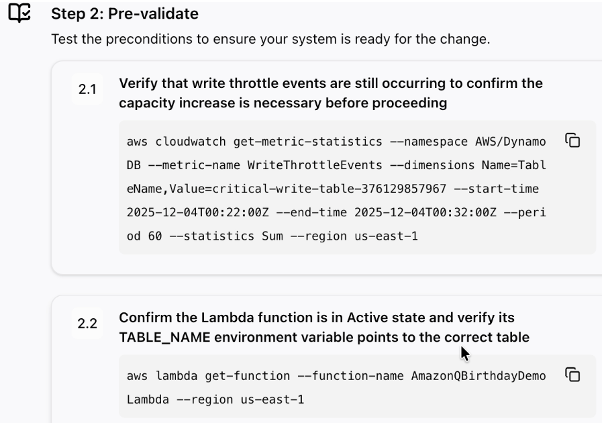
本当に今キャパシティ不足が起きているか(WriteThrottleEventsが発生しているか)、Lambda関数がActive状態かなどを確認します。
Step 3: Apply(適用)

実際に設定を変更します。ここで提示されたコマンドには、コストに関する注意書きまで添えられていました。
意訳
このキャパシティ増加は、テーブルを元のプロビジョニングされたスループットレベルである250 WCUに復旧させますが、これはDynamoDBのコストを増加させる可能性があります。しかし、これは手動削減前の00:07:11Zにワークロードを正常に処理していたキャパシティレベルです。
Step 4: Post-validate(事後検証)

変更後、設定値が正しく250になっているか、また変更後10分間スロットリングが停止したかを監視する手順が含まれていました。
ロールバック確認

「とりあえず直すコマンド」を出すだけでなく、オペレーションの安全性を考慮した手順書を作ってくれる点が非常に丁寧だと思いました。
Cursorとか使うのとは違って、DevOpsに特化してるのはこういう部分かと感じました。
3. 予防策の提案(Prevention)
対応完了後、「Prevention」タブで「Run Now」を押すと、再発防止策を提案してくれます。
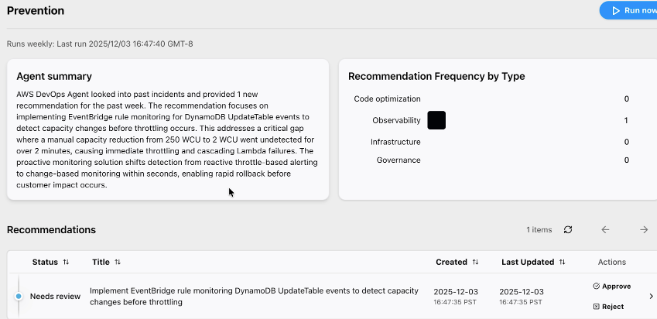
私への提案:EventBridgeによる監視
私の画面で提案されたのは以下の内容でした。
提案内容: EventBridgeルールを実装して DynamoDB UpdateTable イベントを監視する。
理由: スロットリングが発生してからアラートを出すのではなく、設定変更が行われた時点で検知することで、迅速な対応を可能にするため。
隣の方への提案:Auto Scaling
興味深かったのは、隣の方は 「WCUをオートスケール設定にする」 という全く別のアプローチの提案を受けていたことです。
AIによって導き出されるアプローチが変わる可能性があるため、提案内容を鵜呑みにせず、人間が「今のプロジェクトに合うのはどっちか」を判断する必要はありそうです。
外部ツールとの連携
今回のワークショップでは AWSコンソール上だけでなく、外部ツールとの連携も試しました。 Dynatrace, Datadog, New Relic, Splunk, ServiceNow, PagerDuty, Slack, GitHub, GitLabなど、多くの主要ツールと連携可能です。
デモでは、Dynatraceでエラーを検知し、Webhook経由でDevOps Agentに通知、そのままAgentが即座に調査を開始するというフローを試しました。
まとめ
DevOps Agentのワークショップを通じて感じたポイントは以下の通りです。
-
手順が丁寧: 「現状確認」「事後確認」「ロールバック」を含めた手順書を作ってくれるのが丁寧でいいなぁと思いました。
-
AIのランダム性: 提案内容に揺らぎがあるため、最終決定権は人間が持つ必要がありそう(隣の方と予防策が違ったように)。
-
調査の機能だけ使うでも有用かも: 夜間利用ないのにスケジューリング停止してないDBのリソース洗い出すとかできたら嬉しそう。

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion