はじめに
7月に理研によりスパコン「富岳」をAWS上で仮想化した「バーチャル富岳」が公開されました。
会社でハッカソンのイベントがあったので、社内のエンジニアと共にこれを構築して何か独自計算してみようと思いました。しかし、私はスパコン初心者。理研のシンプルなドキュメントではスムーズな導入が出来ず、2日間のハッカソンが終わった時点で、サンプルアプリを動かすまでしか出来ませんでした。
この記事は、サンプルを動かすまでを振り返って「バーチャル富岳」の構築方法を整理したものになります。
使用する主要なサービスやソフトウェア
構築には、主に以下のようなサービスやソフトウェアを使います。
- AWS ParallelCluster
- https://aws.amazon.com/jp/hpc/parallelcluster/
- AWSで高性能計算(HPC)クラスターを簡単に構築・運用できるツール。自動スケーリングやジョブスケジューラとの連携機能を提供し、科学計算やシミュレーション向け。
- AWS PCS (AWS Parallel Computing Service) とは別物なので注意しましょう。
- Slurm
- https://slurm.schedmd.com/documentation.html
- Linux向けのオープンソースジョブスケジューラ。HPCクラスター上でジョブの投入、実行管理、リソース割り当てを行い、複数ユーザーの利用を効率的に制御する。
- Singularity
- https://sylabs.io/singularity/
- コンテナ技術の一つで、特にHPC環境での利用に適している。Docker同様アプリケーションの実行環境をパッケージ化できるが、セキュリティと互換性を重視した設計。
全体の構成とか
そもそもスパコンやHPCはこういう構成で動くよという説明になります。書くのが面倒なので生成AIに書かせた文章を貼っておきます。
記事全体が長いので閉じておきます。
スパコンの各ノードとAWS ParallelCluster、Slurm、Singularityの関係性を説明します。
システム全体の構成要素
- 作業用PC(ローカルPC)
- ユーザーが直接操作するマシン
- AWS ParallelCluster CLIを使用してクラスターに接続(内部的にはSSH)
- プログラムの編集やデータの準備を行う
- ヘッドノード(ログインノード)
- AWS ParallelClusterで構築されたクラスターの入り口
- Slurmのコントローラーとして動作し、ジョブの投入・管理を行う
- 重い処理は行わない
- 計算ノードへのジョブ分配を制御
- 計算ノード
- 実際の計算処理を実行
- Singularityコンテナ内でアプリケーションを実行
- 複数のノードで並列処理が可能
- ユーザーは直接アクセスせず、Slurmを介して利用
各技術の役割
- AWS ParallelCluster
- HPCクラスター全体の構築・管理を自動化
- クラスターの作成、削除、スケーリングを制御
- 作業用PCからの接続を管理
- Slurm
- ジョブスケジューラとして動作
- 計算リソースの割り当てを最適化
- ジョブのキューイングと実行管理を担当
- Singularity
- 計算ノード上でアプリケーションの実行環境を提供
- コンテナ化により環境の再現性を確保
- HPCに最適化されたコンテナランタイム
この構成により、クラウド上でHPC環境を効率的に構築・運用し、ユーザーは必要な計算リソースを柔軟に利用できます。
注意:AWSの権限が結構高いレベルで必要
詰まった点は多々あります。それは都度記載しようと思うのですが、人によっては自力ではどうにも解決出来ないので完全に詰む可能性があることを最初に書いておきます。途中まで試して詰むと萎えますからね。
これは「バーチャル富岳」というよりAWS ParallelClusterの注意事項ですが、必要な権限がヤバいです。具体的には以下のURLに記載されている権限が必要です。
今回はハッカソンだったのでSandbox環境のAdmin権限でやってしまいました。
本格活用するには権限設計が大変そうですし、お試しするにもほぼAdminに近い権限を持っていなければ出来ないので注意が必要です。
構築の流れ
構築に入る前に公式ドキュメントを確認しましょう。以下の流れで構築するように書いてあります。

なので、まずはEC2インスタンスを、、、別に作らなくてもいいです。
いや、まぁ、作ってもいいですよ。ですが最初のEC2は作業用ですし、かつvenv上での作業なります。つまりローカルPCにPythonの仮想環境があれば問題ないと思います。
(もっともハッカソンで作業するには、他の人との共有が楽だったのでEC2を作って正解でしたが、、、)
ということで、構築の流れは以下になります。
- 作業用PC内に仮想環境をセットアップして、ParallelClusterをインストールする
- AWS上にSingularityが入ったParallelCluster用のAMIを作る
- 作業用PCでParallelCluster用の定義ファイルの作成する
- 作業用PCからクラスタを作成
- ヘッドノードに「バーチャル富岳」用のコンテナイメージを取得する
- ヘッドノードからサンプルアプリを実行
はい。作業用EC2とかのレベルでなく公式と手順を変えています。
というのも、ParallelCluster用の標準のAMIにはSingularityが入っていないので、計算ノード用にSingularity入のAMIを自分で作る必要があります。(1敗)
そうなると、ヘッドノードもSingularityを後からインストールするより、最初から入っているAMIを使ったほうが効率が良いです。ヘッドノードで作業すると、スペックが低すぎてインストールに時間がかかるという問題もあります。
ですので、ドキュメントに書いてあるようにクラスタ構築→Singularityインストールの順ではなく、Singularity入のAMIを作成→クラスタ構築の方が楽だと思います。
実際に構築する
作業用PCに環境をセットアップする
まずは、以下のAWSのドキュメントを参考にしつつ、ParallelClusterの作業環境を構築します。
仮想環境のセットアップ
面倒くさいのでPythonの環境管理にuvを使います。(使うほどでもないが楽なので)
仮想環境を作って、ParallelClusterをインストール
$ uv init
$ uv python pin 3.12
$ uv add aws-parallelcluster
$ uv sync
確認
$ uv run pcluster version
{
"version": "3.11.1"
}
AWS上に、Singularityが入ったParallelCluster用のAMIを作る
ここで一旦、仮想環境から離れてAWS上にAMIを作っていきます。
以下のAWSのドキュメントが参考になります。
AMIのベースになるEC2インスタンスを立てる
AMI作成用の新規のEC2インスタンスを作ります。
ここでベースにするAMIに条件があります。
- arm64であること(1敗)
- parallelcluster用であること(1敗)
- parallelclusterのバージョンが正しいこと
- OSがAmzon Linux2(2023ではない)であること
ということで、以下の条件で検索して、コミュニティAMIからベースイメージを探します。
parallelcluster 3.11.1 amzn2 -2023 arm64
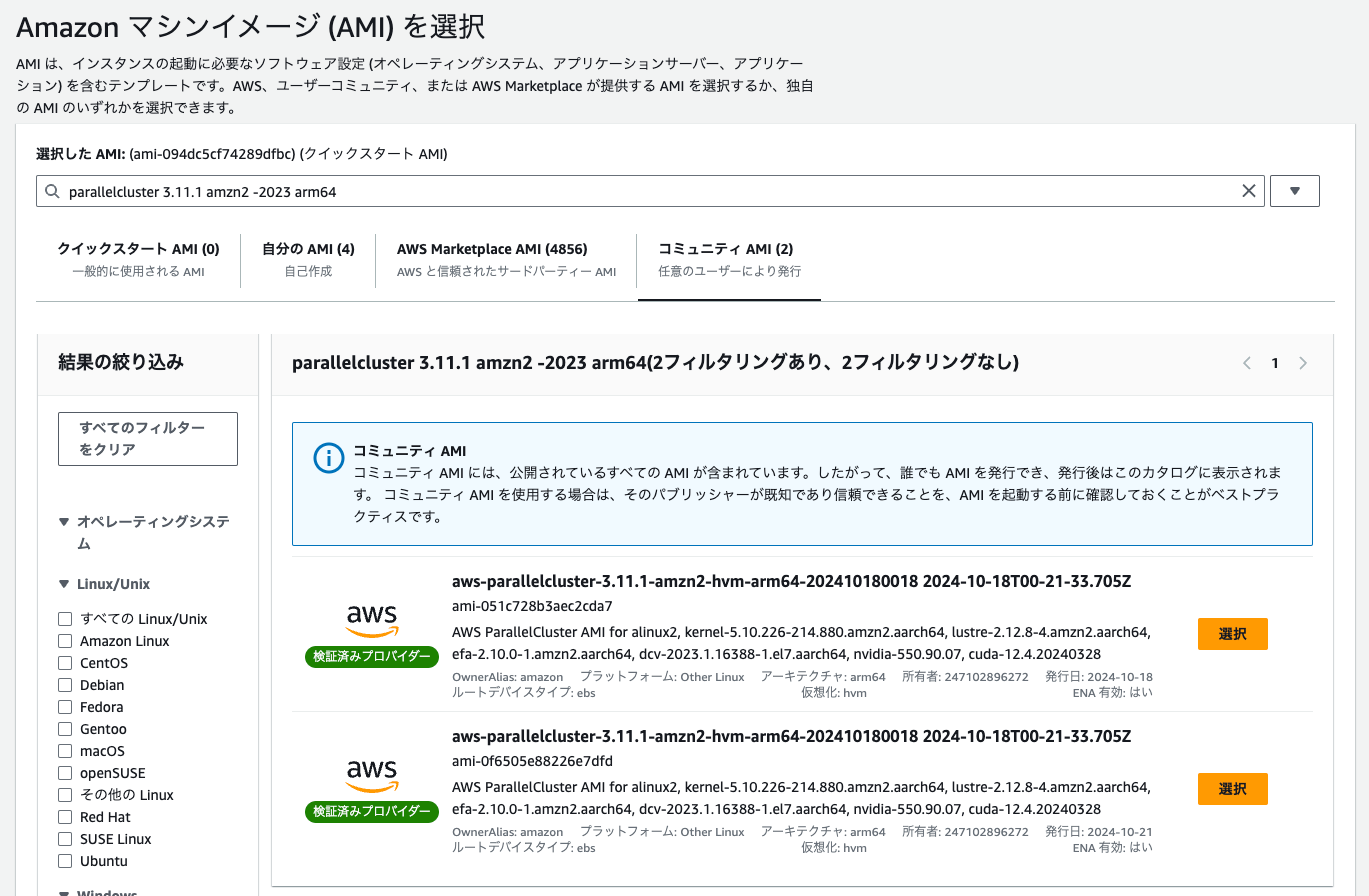
2つ見つかりましたが、両方同じものだと思われます。
AMI作成用なのでインスタンスタイプは何でも良いですが、スペックが低すぎるとSingularityのビルドに時間がかかると思うのでc7gn.xlargeにしておきます。

作成したEC2上にSingularityをインストールする
作成したEC2インスタンス内に入り、以下のSingularityのドキュメントを参考に、Singularityをインストールします。
必要なライブラリ類のインストール
$ sudo yum update
Development Toolsをインストール(ベースに最初から入ってたから不要かも)
$ sudo yum groupinstall -y 'Development Tools'
Goをインストール
$ sudo yum install golang
各種ライブラリをインストール
sudo yum install -y \
autoconf \
automake \
crun \
cryptsetup \
fuse \
fuse3 \
fuse3-devel \
git \
glib2-devel \
libseccomp-devel \
libtool \
squashfs-tools \
wget \
zlib-devel
GitからSingularityCEのコードを取得
$ git clone --recurse-submodules https://github.com/sylabs/singularity.git
$ cd singularity
$ git checkout --recurse-submodules v4.1.0
Singularityをビルド
ビルドします。
$ ./mconfig
$ make -C ./builddir
$ sudo make -C ./builddir install
終わったら確認します。
$ singularity version
4.1.0
SINGULARITYのBINDの設定を追加する
この行為に関しては、これが正しいのか分からないのですが、、、
/usr/local/etc/singularity/singularity.confに以下の設定を追加します。
+ bind path = /usr/lib64/libhwloc.so.5
+ bind path = /usr/lib64/libevent_core-2.0.so.5
+ bind path = /usr/lib64/libevent_pthreads-2.0.so.5
+ bind path = /usr/lib64/libgfortran.so.4
+ bind path = /usr/lib64/libnuma.so.1
+ bind path = /usr/lib64/libltdl.so.7
なんかですね。これらのライブラリをマウントしないと最終的に動作しないのですよね。(10敗くらい)
/usr/lib64ごと全てマウントするとそれはそれで動かなかったです。(1敗)
上記のファイルだけに絞ってマウントしたら動いたのですが、アプリの実行の度に指定するのが面倒だったので、ここで設定入れちゃいます。
設定の影響を考えるとあまりよい方法とも思えないので、正しいやり方を知っている人がいたら教えて欲しいです。
(素人考えにはイメージを作り直してコンテナ内に入れておくべきでは。。。?と思ってしまう)
AMI作成の準備
最後に、以下のコマンドを実行してAMI作成の準備を整えます。
$ sudo /usr/local/sbin/ami_cleanup.sh
ログを消しているようにしか見えませんが、これを実行しないと正常に動いてくれませんでした。(1敗)
AMIを作る
AWSコンソールから、EC2インスタンスを停止してAMIを作ります。

HeadNode用のSSHのキーペアを作る
この後、ParallelClusterを構築する時にHeadNode用にSSHのキーペアが必要になります。
EC2用の適切なキーペアがない場合は、このタイミングで作っておくと良いと思います。
ParallelCluster用の定義ファイルの作成する
ここで頭を切り替えて、最初の作業用PCの仮想環境に戻り、ParallelClusterを構築に必要な定義ファイルを作ります。
AWSのドキュメント
AWSのサンプル
作った定義ファイル
Region: ap-northeast-1
Image:
Os: alinux2
HeadNode:
InstanceType: t4g.micro
Networking:
SubnetId: (subnet-xxxxxxxx)
LocalStorage:
RootVolume:
Size: 64
Encrypted: true
VolumeType: gp2
DeleteOnTermination: true
Ssh:
KeyName: parallelCluster
Image:
CustomAmi: (ami-xxxxxxxx)
Scheduling:
Scheduler: slurm
SlurmSettings:
QueueUpdateStrategy: TERMINATE
ScaledownIdletime: 5
SlurmQueues:
- Name: queue2
ComputeResources:
- Name: c7gn2xlarge
Instances:
- InstanceType: c7gn.2xlarge
MinCount: 0
MaxCount: 10
Networking:
SubnetIds:
- (subnet-xxxxxxxx)
Image:
CustomAmi: (ami-xxxxxxxx)
簡単な説明
- HeadNode
- HeadNodeのスペックは不要なので
t4g.microにしています。 - サブネットは自分が動かしたいサブネットを指定してください。
- ボリュームはデフォルトが40GBなのですが、「バーチャル富岳」のコンテナが重くて40GBだとギリギリすぎるので64GBに増やしました。(1敗)
- SSHのキーペアは先ほど作ったものを指定します。
- AMIは先ほど作ったもの指定します。
- HeadNodeのスペックは不要なので
- Scheduling
-
QueueUpdateStrategy: TERMINATEを入れておかないと後でクラスタの更新が面倒くさくなります。(1敗) -
ScaledownIdletime: 5を入れることで、処理終了後5分でインスタンスを終了させます。デフォルト10分なので、設定してもそんなに差はないです。 - キューの名前はジョブの実行時に使うので、こだわりのある場合はいい感じに命名しましょう。
- 計算ノードのインスタンスは
c7gn.2xlargeにしました。必要に応じて変更しましょう。 - MinCountとMaxCountは適当です。ただしMinCountは0以外にすると課金がヤバいと思います。
- サブネットは自分が動かしたいサブネットを指定してください。私はヘッドノードと同じにしました。
- AMIや先ほど作ったもの指定します。前述の通りデフォルトのものはSingularityが入ってないのでアプリ実行時にエラーになります。
-
クラスタの作成
設定ファイルが出来たら、クラスタを作成します。
注意点
VPCのパブリックサブネットの「パブリック IPv4 アドレスを自動割り当て」が有効化されていないと、クラスタの作成に失敗します。(1敗)
必ず自動割り当てを有効化してください。以下の記事が参考になりました。
クラスタを作る
仮想環境に入ります。
. .venv/bin/activate
クラスタを作成します。
export AWS_PROFILE=sandbox
pcluster create-cluster --cluster-configuration ./slurm.yaml --cluster-name (クラスタ名) --region ap-northeast-1
クラスタ名は、いい感じに変更してください。
--profileオプションがなかったので、環境変数でプロファイル指定しています。
カスタムAMIを使ったことによるWARNINGがでますが、エラーが出てなければたぶん大丈夫だと思います。
AWSコンソール上でいい感じに確認できる画面はないので、CloudFormationのスタックのステータスやEC2にヘッドノードが出来ているかで確認しましょう。


cliからは以下のコマンドでステータスを確認できます。
$ pcluster describe-cluster -n (クラスタ名) -r ap-northeast-1
構築が完了したら、以下のコマンドでHeadNodeにsshで入ることが出来ます。
$ pcluster ssh -n hackathon-parallelcluster-2 -i (sshのkey)
実は普通のsshコマンドでも接続できますが、基本的にはpcluster sshを使うのが良いかと思います。
補足です。多分使うことがあるので。
クラスタの更新が必要な場合はpcluster update-cluster
$ pcluster update-cluster --cluster-config ./slurm.yaml -n (クラスタ名) -r ap-northeast-1
消したくなったらpcluster delete-cluster
$ pcluster delete-cluster -n (クラスタ名) -r ap-northeast-1
「バーチャル富岳」用のコンテナイメージを取得する
ここからは、HeadNodeに入って作業します。
以下のコマンドを実行し「バーチャル富岳」用のイメージをダウンロードしてください。
$ singularity pull library://riken-rccs/virtual-fugaku/vf-ver1
6.7GBあるのでのんびり待ちましょう。
サンプルアプリを動かす
「バーチャル富岳」のドキュメントのアプリ実行例1を動かす
HeadNodeで必要なファイルをダウンロードして解凍します。
$ wget https://www.r-ccs.riken.jp/labs/cbrt/wp-content/uploads/2020/12/benchmark_mkl_ver4_nocrowding.tar.gz
$ tar -xzvf benchmark_mkl_ver4_nocrowding.tar.gz
$ cd benchmark_mkl_ver4_nocrowding
解凍したbenchmark_mkl_ver4_nocrowdingフォルダ配下に以下のようなshellファイルを作ります。
#!/bin/bash
#SBATCH -p queue2
#SBATCH --ntasks=8
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=4
#SBATCH -J test_genesis
set -ex
SIFFILE=~/vf-ver1_latest.sif
export SINGULARITY_BIND=${PWD},/opt/amazon
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}
cd npt/genesis1.6_2.5fs/jac_amber
mpiexec --use-hwthread-cpus -n ${SLURM_NTASKS} singularity -v run ${SIFFILE} spdyn p${SLURM_NTASKS}.inp
ここで指定しているqueue2は、ParallelCluster用の定義ファイルで指定したSlurmQueuesの名前です。
また、ntasks、nodes、nodes、ntasks-per-node、cpus-per-taskの関係性は以下のとおりです。
関連性を理解せずに条件を満たさない数字を雑にいれると動きません(3敗くらい)。
記事全体が長いので閉じておきます。
AIに聞いてみました。
※ この説明部分は、上記の実行例と値が異なる例なので注意してください。
- パラメータとその役割
#SBATCH --nodes=3 # 使用するノード数
#SBATCH --ntasks=9 # 全体のタスク数
#SBATCH --ntasks-per-node=3 # 1ノードあたりのタスク数
#SBATCH --cpus-per-task=2 # 1タスクあたりのCPUコア数
- パラメータ間の関係式:
ntasks = nodes × ntasks-per-node
1ノードの使用コア数 = ntasks-per-node × cpus-per-task
全体の使用コア数 = ntasks × cpus-per-task
- 満たすべき要件:
a. ノードの制約
- ntasks-per-node × cpus-per-task ≤ ノードあたりの総CPU数
例:3 × 2 = 6 ≤ 8(c7gn.2xlargeの場合)
b. タスク数の整合性
- ntasks ≤ nodes × ntasks-per-node
例:9 ≤ 3 × 3
c. リソースの効率的利用
- 使用コア数はノードの総コア数以下
- タスク数は均等に分散されることが望ましい
- 設定時の注意点:
a. インスタンスタイプに応じた制限
- CPU数の上限を考慮
- メモリ制限も考慮
b. 効率性
- ノードのコア数に近い使用率が望ましい
- 過度な分散は通信オーバーヘッドの原因に
c. タスク配置
- 均等な配置が望ましい
- ノード間でのバランスを考慮
雑ですが、理解のためにハッカソン中に図を書いてみました。


実行します。
$ sbatch example1.sh
Submitted batch job 2
暫く待つと、nodesに指定した数のEC2が動きだします。

更に暫く待つとslurm-2.outというファイルが作られます。この2は実行時に表示されたジョブIDです。
$ cat slurm-2.out
(前略)
[STEP6] Deallocate Arrays
Output_Time> Averaged timer profile (Min, Max)
total time = 46.271
setup = 1.544
dynamics = 44.727
energy = 26.565
integrator = 10.926
pairlist = 2.381 ( 2.294, 2.452)
energy
bond = 0.061 ( 0.050, 0.068)
angle = 0.179 ( 0.134, 0.208)
dihedral = 0.315 ( 0.246, 0.382)
base stacking = 0.000 ( 0.000, 0.000)
nonbond = 24.115 ( 23.974, 24.284)
(後略)
なにかそれっぽい結果が出力されました。
サンプルアプリではありますが無事にAWS上で「富岳」を動かすことが出来ました!!
注意点まとめ
- 「バーチャル富岳」の公式ドキュメントの記載が圧倒的に足りていない。少なくとも私には
- パラレルクラスターに必要なAWS権限には要注意
- パラレルクラスターで使用するEC2インスタンスはGravitonプロセッサを使うこと(gがついているインスタンスタイプ、gnならよりよい)
- SingularityをインストールしたAMIを作ること(HeadNodeとComputeResources両方)
- AMIは作成時のベースは、ARMであることに加えて、
- OSはAmzon Linux2を選ぶ(2023ではない)
- パラレルクラスター用のものをベースにする
- singularityインストール後、最後に以下のコマンド実行を忘れない。
sudo /usr/local/sbin/ami_cleanup.sh
- AMIは作成時のベースは、ARMであることに加えて、
- パラレルクラスターのHeadNodeのストレージをデフォルトから増やしておくこと
- パラレルクラスターが動くVPCはIPアドレスを自動割り当てする必要がある
- 全タスク数(ntasks)、ノード数(nodes)、ノードあたりのタスク数(ntasks-per-node)、タスクあたりのCPUコア数(cpus-per-task)、ノードのCPUコア数の関係はしっかり把握する必要がある
- Singularityでホスト側のライブラリを複数バインドしてあげないと動かなかった
- AWSにはパラレルクラスターの他にパラレルコンピューティングサービス(AWS PCS)があるが、全くの別サービスなので間違わないこと
最後に感想とか
- 「バーチャル富岳」に関しては、少なくとも公式ドキュメントをもっと充実させるべきだと思う。
- ドキュメントを更新するつもりがないなら、せめて技術的な問い合わせ窓口は欲しいです。
- 現状は広報用の窓口しかなく、広く技術者に情報提供するつもりがあるとは思えない。
- いいものを作って公開したからヨシ!ではなくて、使われてこそ意味があると思うのです。
- ドキュメントを更新するつもりがないなら、せめて技術的な問い合わせ窓口は欲しいです。
- AWS ParallelClusterに関してはHPCなのに結構安いので驚いた。ヘッドノードは最低限のスペックで良いし、計算ノードは動かす時だけ立ち上げて使い捨てる。なので最小限の費用しかかからない。まさにクラウドの利点を感じた。
- ドキュメントが充実して無いため自力でいろいろ調べる事になり、結果としてHPCの基礎知識を学ぶことが出来た。勉強になった。
- 普段はサーバレスの世界で生きているので、こんなにEC2触ったの久しぶりです。そういう意味でも勉強になった。
- やってることの高度さの割にアプトプットが計算結果のテキストしか出ないので、いい感じに見せるところまでやらないと見栄えがしないなぁと思った。
以上です。

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion