はじめに
2023年11月に社内で行われたイベントにて、AWS Bedrockを連携させたSlackチャットbotアプリの作成をしました。当時はBedrockが公開されて間もなかったため、何かBedrockを活用した動くものを作ってみようというのが動機になります。
その過程で大変だったBedrockが関係している点を中心にハンズオンレポートを作成しました。
アプリ概要

構成は上記の通りです。全体としては学習フェーズとアプリ利用フェーズに分かれています。
学習用ソースをアップロードしたブランチをGithub上でMainブランチにマージすることでコンテナのリスタートおよび、Bedrockが学習を再度実行します。
利用時にはSlackアプリをメンションしてメッセージを送ることで、そのメッセージのスレッド内に回答をもらえるようにしています。
また学習時と回答生成時でBedrockの別モデルを使用しています。
学習時: Titan
回答生成時: Claude
ソースコードはTypeScriptをメインとして使い、AWSリソースの管理にはTerraformを使用しています。
Bedrockの使用についてはLangchainを使用しています。
Langchainについては以下の記事がとても参考になりました。
Bedrockの利用開始方法
使いたいBedrockのモデルを有効化する必要があります。今回は学習用にTitan、回答生成用にClaudeの二つのモデルを有効化する必要があります。また、東京・大阪リージョンでは使えないのでBedrockが使用できるリージョンに変更して作業を進めてください。
詳しい有効化の方法について良い記事がありましたので以下を参考にしてみてください
Bedrockが有効化できたらBedrockに対してアクセス権限のあるIAMユーザーを作成して、アクセスキーとシークレットキーを作成し、メモしておいてください
AWSリソースの設定
Terraformを使って環境構築をしています。全てを記載してしまうととても長くなってしまいますので、バックエンドサーバーとQdrant DBサーバーの設定のみを抜粋して記載させていただきます。
resource "aws_ecs_task_definition" "api_app" {
family = "api-app"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "512"
memory = "4096"
execution_role_arn = aws_iam_role.ecs_task_exec.arn
task_role_arn = aws_iam_role.service_task.arn
container_definitions = jsonencode([{
name = "qdrant"
image = "qdrant/qdrant:latest"
memory = 2048
portMappings = [{
containerPort = 6333
}]
},{
name = "api-app"
image = "${aws_ecr_repository.api_app.repository_url}:latest"
memory = 2048
portMappings = [{
containerPort = 80
}]
}])
}
Bedrockを使用した学習
今回はテキストファイルを学習させます。学習では具体的にEmbeddingという処理を行います。Embeddingとは単語や文といった自然言語の情報を、その意味を表現する三次元空間(ベクトル空間)に配置することを指します。
難しい話は省略しますが、Embedding専用のモデルを使い三次元空間に各文や単語を配置することで、各要素の関係性を数値にして扱えるようになります。このおかげで、与えられた要素に近しい意味を持つ要素まで検索できるようになります。
学習用のソースは事前に取得してテキストファイルとしてディレクトリ内に保存しています。Textファイルであれば今回紹介するコードで学習できます。
また、Embeddingされたデータの保存先としてベクトルデータベースが必要となります。今回はその中でもQdrandというデータベースインスタンスを使用します。
Embeddingの実行
- Titanインスタンスの作成
- Vector Storeインスタンスの作成
- テキストファイルの分割
- 学習
Bedrock モデルTitanのインスタンスの作成
import { BedrockEmbeddings } from "langchain/embeddings/bedrock";
const embeddings = new BedrockEmbeddings({
region: "us-east-1",
credentials: {
accessKeyId: process.env.BEDROCK_ACCESSKEY,
secretAccessKey: process.env.BEDROCK_SECRET,
},
model: "amazon.titan-embed-text-v1",
});
Vector Storeインスタンスの作成
クラスター内の別タスクにてQdrant DBサーバーが動いていることが前提になります。Dockerイメージで配布されており、ポートは6333です。
const collectionName = "vector_db";
const vectorStore = new QdrantVectorStore(embeddings, {
url: "http://localhost:6333",
collectionName,
});
テキストファイルの分割
学習に使用するテキストファイルのサイズが大きいと一度にEmbeddingができないので、テキストを分割する前処理が必要になります。分割にはLangchainを使用します。また今回準備した学習用データがマークダウン形式で記述されていたため、テキストの分割もマークダウンに対応できるものを使用します。
分割されたテキストのことはchunkと呼び、chunkSizeは最大文字数、chunkOverlapはチャンク同士をどの程度オーバーラップさせるかどうかを決めるものです。この2つを制御することでテキストが単語の途中で分割され、意味がわからないチャンクが作成されないようにしています。
import { MarkdownTextSplitter } from "langchain/text_splitter";
const chunkSizeBase = 1024;
const textSplitter = new MarkdownTextSplitter({
chunkSize: chunkSizeBase * 0.8,
chunkOverlap: chunkSizeBase * 0.2,
});
const source = fs.readFileSync("./learning-source.txt", "utf8");
const documents = await textSplitter.createDocuments([source]);
学習
準備が整いましたので、実際にテキスト(chunk)をTitanモデルを使用してEmbeddingして、結果をQdrant DBに保存していきます。すでにvectorStoreにEmbeddingモデルを紐づけていますので学習は以下のとおりとてもシンプルになります。
for (const [index, doc] of documents.entries()) {
await vectorStore.addDocuments([doc]);
}
この後この学習データを保存しているvectorStoreをもとにBedrockインスタンスを作成することで学習したデータを含む回答をするようになります。
Bedrockを使用したQ&Aアプリの作成
学習したデータを蓄積したSlackチャットbotを作成していきたいと思います。アプリ利用時に実行される部分になります。Langchainを使用しているのでBedrockのインスタンスを作成した後はとても簡単に対話型の答えを作成することができます。
Bedrockインスタンスの作成
AWSコンソールから取得したアクセスキーとシークレットキーを使用してBedrockのモデルを作成します。こちらは学習時にEmbeddingインスタンスに設定したものと同じものです。
maxTokensとはBedrockが回答に使用する最大文字数です。
const model = new Bedrock({
model: "anthropic.claude-instant-v1",
region: "us-east-1",
credentials: {
accessKeyId: process.env.BEDROCK_ACCESSKEY,
secretAccessKey: process.env.BEDROCK_SECRET,
},
maxTokens: 1000,
});
Langchainの設定
実際に質問の回答をBedrockで生成するには、LangChainが提供している回答作成ツールであるRetrievalQAChainを使用します。RetrievalQAはベクトル化されたテキストデータから質問に合致する情報を検索し、LLM(今回はBedrock)を使用してその情報に基づく回答を生成します。
import { RetrievalQAChain } from "langchain/chains";
const qaChain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());
質問から回答を生成する
LangchainのMethodを使用して質問の回答を生成していきます。Bedrockに質問をするときには以下のようなフォーマットで質問をしないとエラーになってしまいますので注意してください(関連Issue)
const question = body.event.text
const answer = await qaChain.run(
`\n\nHuman:${question}\n\nAssistant:`
);
実際にはユーザーがSlackで入力した質問内容がbody.event.textの中に入っています。
今回はテスト稼働のためユーザーが入力した値をそのままモデルに対するプロンプトとして使用していますが、精度の高い回答を得るためにはプロンプトの改良が必須となります。
Slackに回答を返却する
Bedrockの要素は含みませんがSlackへの回答の返却方法も参考までに記載しておきます。
import { WebClient } from "@slack/web-api";
const slackClient = new WebClient(process.env.SLACK_TOKEN);
await slackClient.chat.postMessage({
channel: body.event.channel,
text: answer,
thread_ts: body.event.ts,
});
実演
Slackのアプリ設定、Terraformを通したAWSリソースの設定が完了するとBedrockを搭載したSlackチャットbotの完成です。社内の情報になりますのでマスキングさせてもらっています。
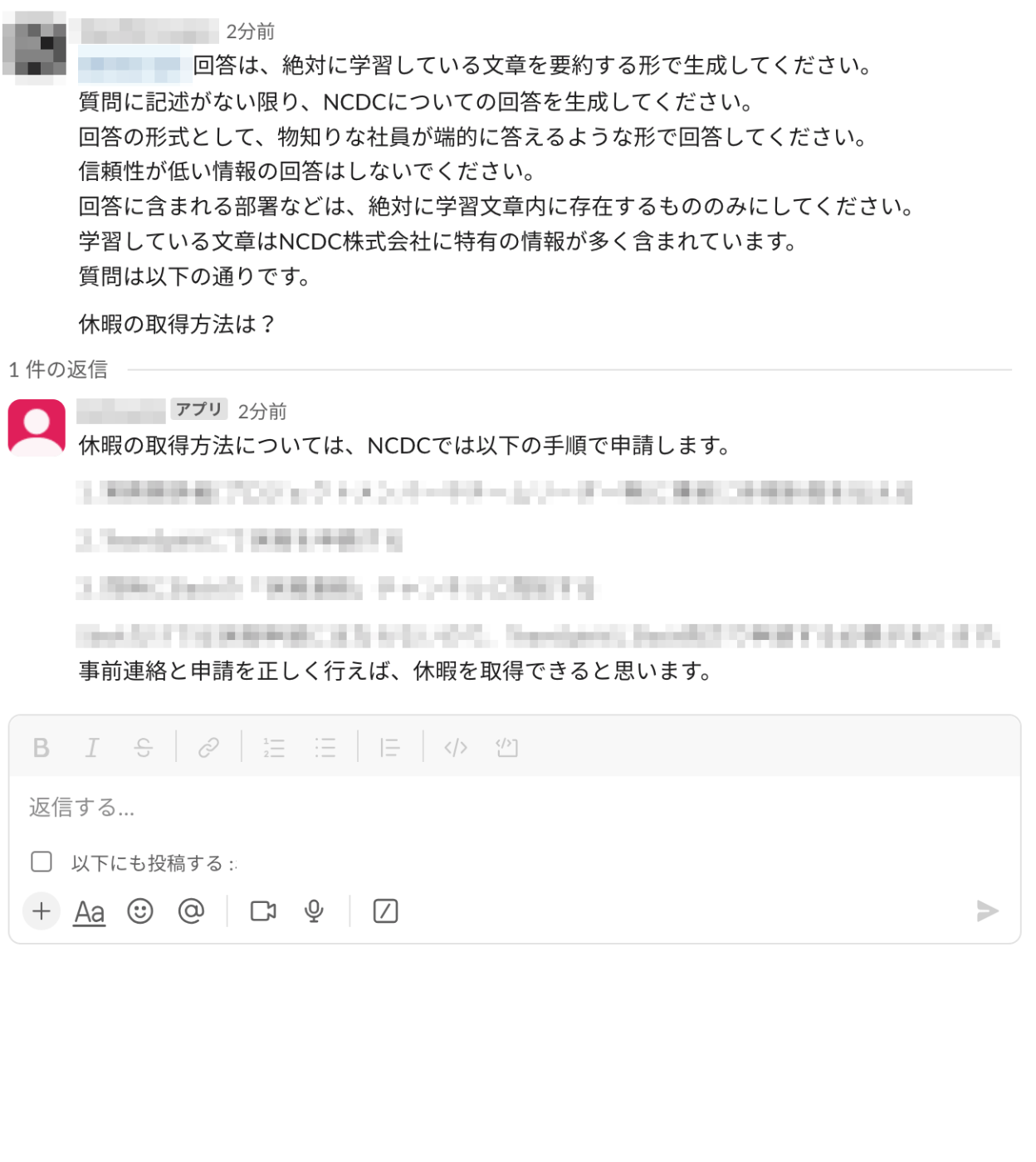
ちなみに今回はSlackでの質問がそのままプロンプトとして使われているので、社内の情報リソースだけでなく一般的な内容も答えることができます。
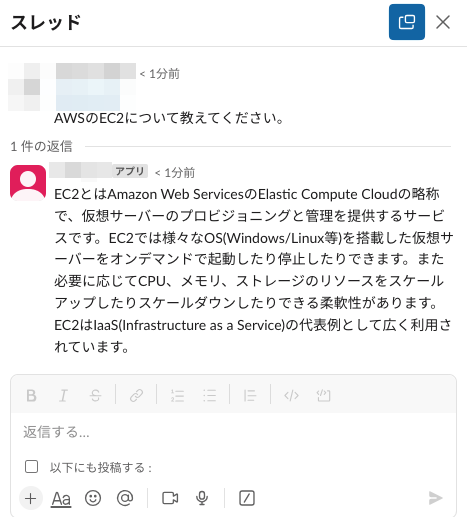
なんとか動くものは作ることができましたが、やはりプロンプトを工夫していなかったり、学習時に詳細の設定をしていないので精度には問題ありな状態です😭
終わりに
ドキュメントやリソースの少なさがとても厄介でした。開発をしていた当初はBedrockが公開されてまもないばかりだったので中々良いドキュメントや記事が見つからず公式ドキュメントと睨めっこしていた時間が長かったように感じます。
また、LLMやLangchainについて無知な状態で「Bedrockを触ってみよう」と開発を始めたので、Bedrock以外のLangchainについてやベクトルデータベース等の学習にも苦労しました。
今後やりたいこととしては、学習データ取得の自動化と回答の精度の改善になります。精度の改善は具体的に、プロンプトの改善やスレッド内の会話を参考にした回答の生成、回答に対する精度をユーザーにレビューしてもらい、今後の回答の生成に役立てられるようにしていきたいです。
参考資料

NCDC株式会社( ncdc.co.jp/ )のエンジニアチームです。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください! ※エンジニア以外も記事を投稿することがあります
Discussion