はじめに
DynamoDBのソート戦略について、DynamoDBBookの著者として知られるAlex Debrieさんの登壇をYoutubeで見て学習したので、ここにアウトプットします。
出典:YouTube「Data modeling with Amazon DynamoDB – Part 2(re:Invent 2020)」
登壇者:Alex Debrie
対象読者
- DynamoDBの設計に興味がある
- DynamoDBの基本概念はある程度知っている
ソート戦略
DynamoDBのソート戦略について、以下のような構成で見ていきます。
- 基本的なソート
- ソートキーでのみソートされる
- UTF-8の順序でソートされる
- タイムスタンプでのソート
- ユニークなソートID
- 変化する属性でのソート
- 昇順か降順か
基本的なソート
ソートキーでのみソートされる
DynamoDBのソートについて知っておくべきことは、ソートキーのみがソートされ、特定のパーティションキー内でソートされるということです。

組織とユーザーを表す例で見てみましょう。
赤いボックス内では、ORG#BERKSHIREのパーティションキーの内で、ソートキーに従ってソートされています。青いボックス内も同様です。
パーテションキーを跨いではソートされず、パーテションキーの内でソートされます。
UTF-8 の順序でソートされる
また、このソートはUTF-8の順序で行われます。
UTF-8は基本的にはアルファベット順ですが、注意すべき点もあります。
以下の例を見てみましょう。

DeBrieがDeanより前に来るのはなぜでしょうか?
それはUTF-8では大文字はすべて小文字の前に来るからです。
もしDeanをDeBrieより前に並ばせたい場合は、すべての文字を大文字にするなどして、標準化してください。
記号や数字がどの順番かも気にする必要があるので、UTF-8 bytes chartを見て確認するようにしましょう。
タイムスタンプでのソート
ソートキーにタイムスタンプを使う場合がよくあります。
具体的にはエポックタイムを使うべきかISO-8601を使うべきかというような選択をするシーンも多いでしょう。
結論、どちらでもソートできますが、Alex DebrieさんのおすすめはISO-8601です。
ISO-8601は人間が読める形式であるからです。
ISO-8601の例は以下です。

※エポックタイムは、「1970年1月1日午前0時0分0秒(UTC)」からの経過秒数で表現する方法です。
エポック時間を見てパッと時間がわかる人間は珍しいでしょう。
絶対やってはいけないのは、「May 26 2025」のように保存することです。
時系列順にソートができないからですね。
ユニークなソートID
新しいアイテムを作成する際にはユニークな識別子が必要で、UUIDがよく使われます。
しかし、UUIDの問題はソートができないことです。
そんな時にはULIDを使用します。
ULIDは128bitの文字列で、最初の48bitがミリ秒のタイムスタンプ、残りの80bitがランダム文字列となっています。
ユニークになるので、URLセーフでもあります。
(URLで一意にリソースを表すことから、ULIDをURLの一部分として使うことが可能という意味)
変化する属性でのソート
ソートしたいけど、その属性が変化するという場合がありえます。
ゲームのリーダーボードを考えてみましょう。
特定のゲームをパーテションキーとして、そのゲーム内でユーザーのスコアを記録するような場合、
スコアは変化していくので、誰がリードしているのかなどを示すためにソートしたいとします。
ここで問題になるのが、変化する属性をソートキーに組み込むとその属性の更新が難しくなるということです。
ソートキーはプライマリキーの一部です。プライマリキーの変更にはdeleteとputという2つのアクションが必要です。なので主キーの属性を変更するのは少し面倒です。
そういう時のおすすめ策がセカンダリインデックスを使用して、DynamoDBが処理してくれるようにすることです。

セカンダリインデックスを使用しない場合、ソートキーに更新日時を持たせようと考えるかもしれません。
しかしこの更新日時は、注文済み、配達済みなどの度に更新されます。
その度にアイテムをdeleteしてputしなければなりません。
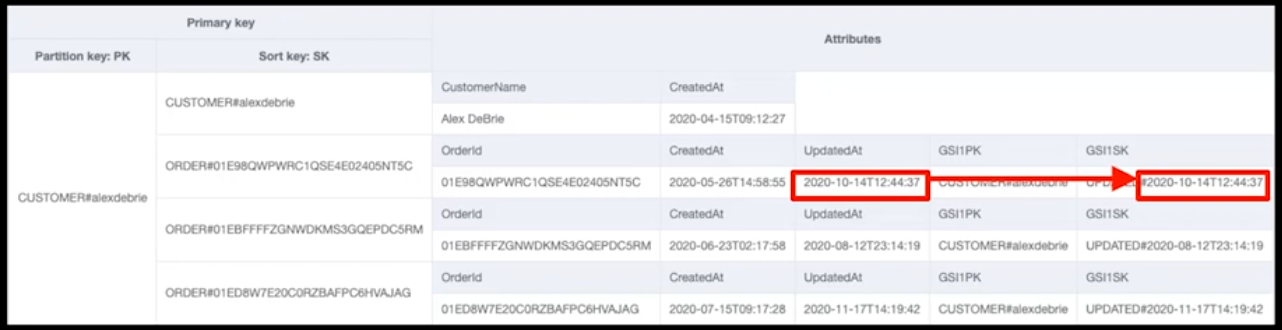
セカンダリインデックスを使用する場合、GSI1PK,GSI1SKを追加して、GSI1SKを「UPDATED#タイムスタンプ」としています。
アプリケーション側では、UpdatedAt属性を更新すると同時に、GSI1SK属性も"UPDATED#" + "(更新日時)"という形式で更新します。
DynamoDB側では、その新しく更新されたGSI1SKの値を読み取り、GSI(セカンダリインデックス)の正しいソート順の位置に格納してくれます。
ベーステーブルのプライマリキーを変更するdelete/putの2ステップの手間が、GSIのキーではない属性(GSI1SK)を1ステップでupdateするだけで済む点がメリットです。

昇順か降順か
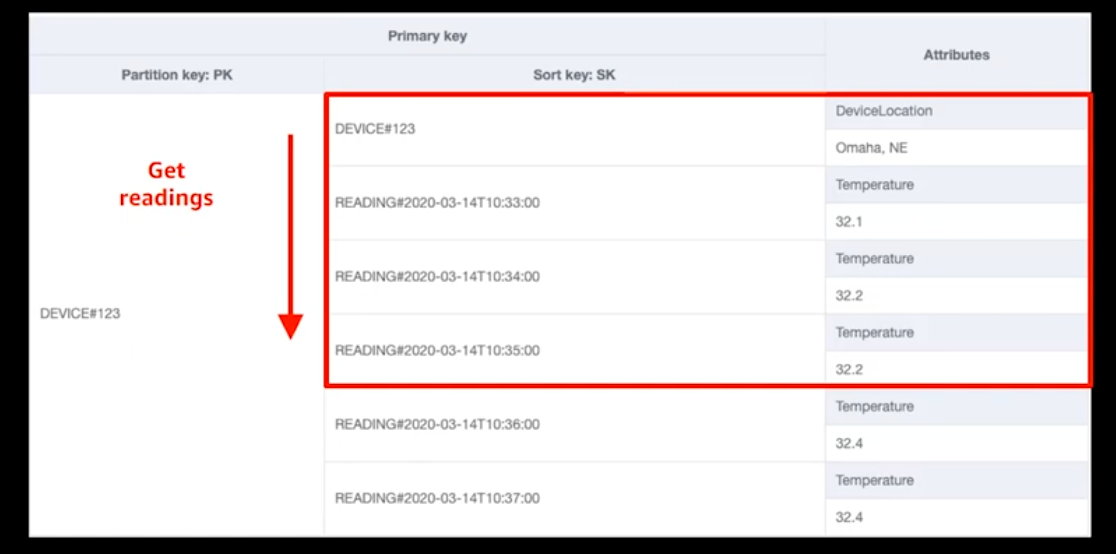
IOTアプリケーションの例です。
2種類のアイテムがあり、デバイス情報を表すアイテム(1個目)と時系列でのIOTデータ(2個目以降)があります。
もっとも一般的なアクセスパターンは「このデバイスの最新の読み取り値を取得する」というものでしょう。
しかし、上記のモデリングだと1個目のデバイス情報を表すアイテムを取得した後、古い順にアイテムが並んでいて、欲しい順番でデータが取得できません。
そういう時は以下のように解決します。

ScanIndexForward=False(降順)でクエリを投げると、アイテムはUTF-8の逆順でソートされます。
UTF-8の昇順では記号(#)が英字(D)より先に来るため、降順では英字(D)が記号(#)より先に(リストの先頭に)来ます。
その結果、DEVICE#123(デバイス情報)が必ず1件目に返され、その後ろに#READING#...(測定値)が新しい順に並ぶことになります。
これにより、1回のクエリでデバイス情報と最新の測定値をまとめて取得できます。
コードを見た方がわかりやすいかもしれないのでサンプルコード貼っておきます。
import boto3
from boto3.dynamodb.conditions import Key
# DynamoDBリソースに接続
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('DeviceData') # (テーブル名は仮)
pk_value = "DEVICE#123"
# 降順で11件取得
response = table.query(
KeyConditionExpression=Key('PK').eq(pk_value),
ScanIndexForward=False, # 降順 (DEVICE# が先頭に来る)
Limit=11 # デバイス情報(1) + 測定値(10)
)
# データを取得できた場合
if 'Items' in response and response['Items']:
# 1件目をデバイス情報として扱う (決め打ち)
device_info = response['Items'][0]
# 2件目以降を測定値として扱う
readings = response['Items'][1:]
# --- 結果の表示 ---
print("--- デバイス情報 ---")
print(f"SK: {device_info['SK']}, Location: {device_info.get('DeviceLocation')}")
print("\n--- 最新10件の測定値 ---")
for item in readings:
print(f" {item['SK']} -> Temp: {item.get('Temperature')}")
else:
print("データが見つかりません。")
感想・気づき
ソート戦略を具体例を通して学ぶことで、改めてアクセスパターンがわかってないとモデリングできないなと思いました。

NCDC株式会社( ncdc.co.jp/ )のエンジニアチームです。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください! ※エンジニア以外も記事を投稿することがあります
Discussion