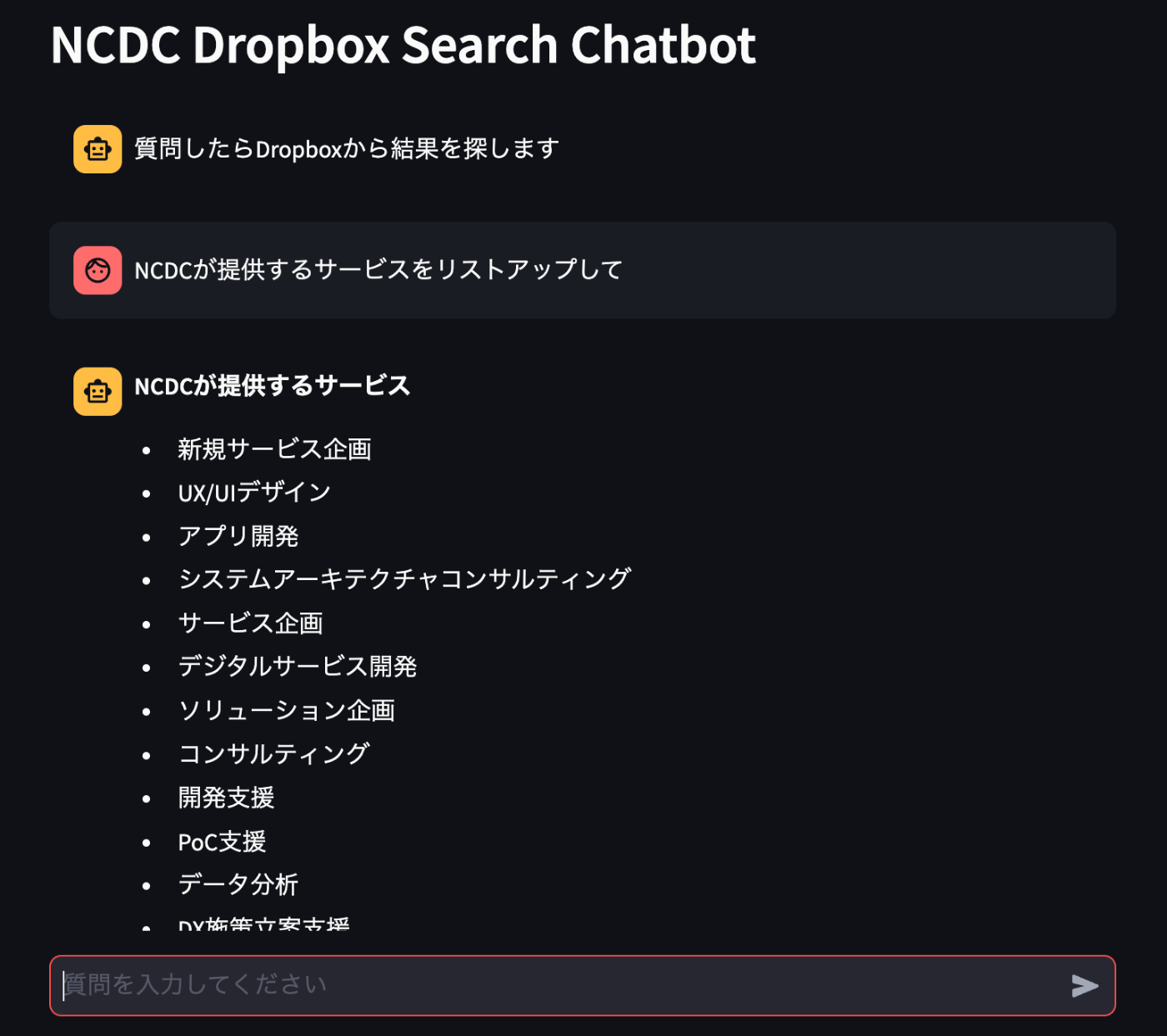
費用、特に運用コストをなるべく抑えて、社内ドキュメントをソースにしたAIチャットアプリを作れないかと思い、業務の合間に作ってみました。安さ優先で性能や速度は後回しにしています。
この記事は、Qiita Advent Calendar 2023 「GCP(Google Cloud Platform) Advent Calendar 2023」 17日目です。
はじめに
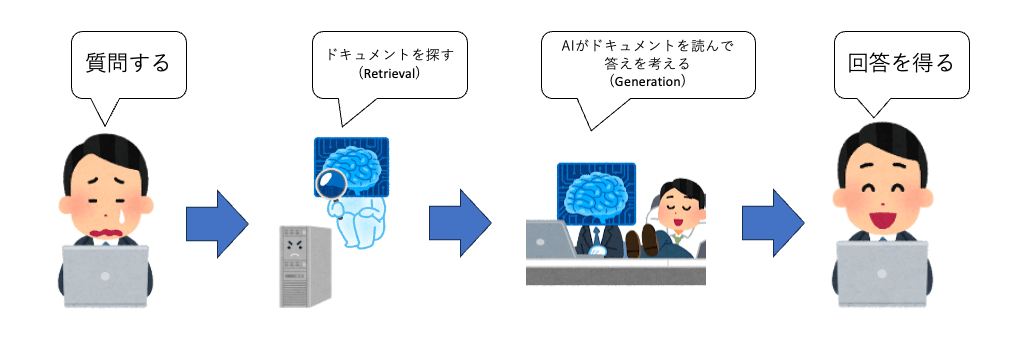
RAGとは、Retrieval-Augmented Generationの略で、情報検索(Retrieval)とAIによるテキスト生成(Generation)を組み合わせることです。つまり、自分が持っている最新情報を検索してその結果をAIに渡すことで、AIがローカルな情報を元に適切な回答を返してくれます。
RAGによりネットの最新情報を使ったチャットAIも作れますし、自分(or自社)専用のチャットAIを作る事もできます。
しかしですよ。RAGのRつまりRetrievalなのですが、お値段が高くないですか?
例えば、クラウド前提ならAWSかAzureかGoogle Cloudを利用することが候補に上がると思います。これらのクラウドでRetrievalに適したサービスとして下記のようなものがあります。
- AWSのAmazon Kendra
- AzureのAzure AI Search(旧Azure Cognitive Search)
- Google CloudのVertex AI Search and Conversation(旧Enterprise Search)
いま挙げたサービスは、まともに使おうとすると最低でも月10万円以上はかかります。
扱うデータ量が数GB程度のPoCであれば月1万円程度でできたりもしますが、正直そのくらいのデータ量であればAIに頼らなくても人が情報を探せると思います。普通はファイルサーバーなんてものは最低でも数百GBでTB超も当たり前。それだけ膨大な情報の整理が人間にはツラいからAIに頼りたいわけです。ですが、そうなると月額で数十万〜数百万円の利用料になってしまいます。
大企業であれば使えない人類をAIに置き換える判断になるかもしれません。しかし個人や多くの会社では、たとえその金額の価値があることが分かったとしても気軽に払えない金額ではないでしょうか?
一方で、最近のAIやベクトル検索関連の記事、各社が発表する新サービスを見ると、正確性や応答速度などの性能アップが主流で、コスト削減を重視していることは少ない気がします[1][2]。基礎研究としてはよいと思いますが、ビジネス的には性能がよくても得られる成果よりも値段が高かったら使わなくない?と思っています。
ということで、性能や速度などはあるていど割り切ってしまって、Retrievalを安くしてかつアプリ全体を単純な作りにすることで運用費を抑えられないかなと思いました。
実際に作ったもの
では、どんな感じに作ったかを説明していきます。
全体構成
アプリの構成は下図のようにしました。Google Cloudを使っていますが、アプリ本体はコンテナ化したので他の場所で動かす事も可能です。
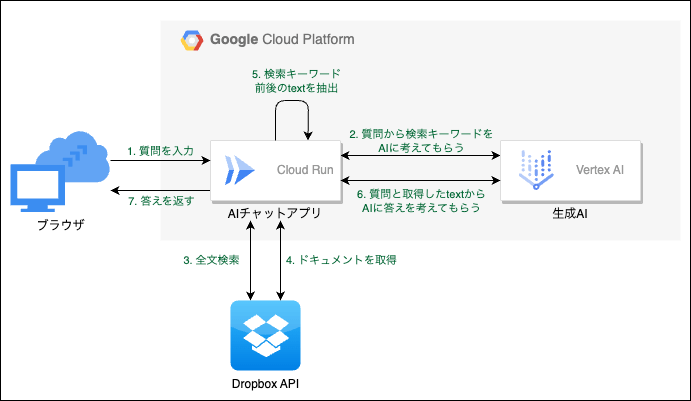
処理内容
-
質問を入力
- 人間がブラウザから質問を入力します
-
質問から検索キーワードをAIに考えてもらう
- Dropboxには自然な日本語から検索するなんてことはできないので、キーワードを抽出する必要があります。
- 素人にはそんなロジックなど組むことはできないのでAIに丸投げします。
-
全文検索
- DropboxAPIを使って全文検索します。
-
ドキュメントを取得
- DropboxAPIの全文検索はファイルのパスしか得られません。
- 回答を得るには中身も必要なのでダウンロードします。
-
検索キーワード前後のtextを抽出
- ドキュメントを全てAIに投げると文字数が多すぎて課金が増えるので、事前に減らします。
- キーワードは分かっているので、キーワード前後数百文字のtextだけ抽出します。
-
質問と取得したtextからAIに答えを考えてもらう
- 生成AIに、最初の質問とソースになるtextを渡して回答を考えてもらいます。
-
答えを返す
- 画面に回答を表示します。
使用した技術要素とその理由
- 検索 : DropboxAPI
- 会社の主なファイル置き場がDropboxなのとりあえず使う。
- Dropbox Businessの契約があれば、無料で全文検索が使える。
- 生成AI : Vertex AI(
PaLM 2Gemini Pro)- CloudRunから楽に使える。
- 課金が文字数ベースなので計算しやすい。
- (※先程値段が高いと書いたVertex AI Search and Conversationとは別機能)
- アプリのホスティング : Cloud Run
- コンテナをサーバレスで簡単にホスティングできる。
- WebSocketをサポートしているのでStreamlitが動く。
- アプリの主要ロジックの構築 : LangChain
- 生成AI系のアプリならとりあえず使っとくのが主流なので。
- アプリのUIの作成 : Streamlit
- 簡単にチャット画面を作れる。
- ユーザー認証 : Google OAuth2
- 社員全員がアカウントを持っているのでユーザー管理が不要。
- 他の要素とあわせてGoogle Cloudで完結する。
詳細
社内の共有ドキュメントは基本Dropboxに置かれているのですが、DropboxAPIはなんと月100万回まで無料でこの中には全文検索(日本語可)も含まれています。ということでDropboxAPIを使えばとりあえず無料でRetrievalが用意できます。
アプリは汎用性を考えコンテナを前提に考えました。生成AI系なのでとりあえずLangChainを使おうと思い、LCELでChainを繋げたかったのでTypeScriptではなくPythonで書くことにしました。UIも全部含んだ1個で完結したアプリにしたかったのでStreamlitでWebアプリ化しようと思いました。ですが、Streamlitを含め昨今のPythonのwebフレームワークはリアルタイムで画面を描画する為にWebSocket前提で作られています。コンテナ+WebSocketという技術要素であれば、Cloud Runにホスティングするのが一番楽でコスパがいい[3]と考えました。
AIは正直何でもよかったのですがGoogle Cloud統一でVertexAIにしました。作り始めた後に最新かつ低価格なGeminiを使えるようになってラッキーでした。あとはユーザー認証もGoogleでやるのが一番楽だよねと言う感じです。
アプリの概要はだいたいこんな感じになります。
メインの内容はココまで、以下は補足事項などを垂れ流します。
工夫した点、イマイチ点、改善すべき点、ぽえむなど
Geminiを採用してみた
12月13日(米国時間)にGoogle最新のモデルであるgemini-proが公開されました。さっそく取り入れました。新しいのを使いたいと言うのもありますが、料金が従来のモデルの半額以下だったからです(試用期間中は無料。正式リリース後でも半額以下)。
ですが、Geminiに変更したことで回答の癖が微妙に変わってしまいAIに質問するテンプレートの微調整が必要になりました。モデル変更はパラメータだけで対応できる想定でいたのですが、意外と面倒くさいと感じました。また、ハラスメント判定やヘイトスピーチ判定が厳しくなっており、回答が得られないケースが増えたのも対処に悩むところです。やはりAIの性能が高ければ使いやすいとはならないと思いました。従来と値段が同等なら戻すところですが、安いので頑張って調整[4]します。
AIとは関係ない部分で性能が悪い
Dropboxの全文検索はおそらくAIが利用することなんて考えていないと思います。
まず、自然な日本語で検索できないので検索前にキーワードを抽出するフェーズが入ります。ここで情報が落ちるので精度が下がります。
次に、Dropboxの全文検索はファイルの一覧しか取れないので、実際にファイルをダウンロードして中身を確かめる必要があります。時間がかかりますので今回のアプリでは上位3ファイルを対象にしました。つまり4ファイル目に有力な情報があっても切り捨てられますので、ここでも精度が下がります。
それから、VertexAIに入力する時に大量のデータを同時に渡すと何故か精度が大幅に下がります。InputとOutputは別課金扱いの認識だったのですが、Inputが多いとOutputの量があからさまに減ります。謎です。コレに関しては許容できないレベルで精度が落ちるので、ファイル毎にAIに問い合わせをして最後に全体を要約する処理にしました。しかし、個別回答の粒度が異なる場合があり、要約する時に重要ではない部分が強調されることがあります。これにより精度が下がります。
という感じで精度は落ちます。安いから仕方がないよね。
時間がかかる
時間もかかります。具体的にはDropboxからファイルをダウンロードする為の時間です。
意味がある回答が得られる場合だいたい20〜30秒くらいユーザーを待たせることになります。
安いから待ってもらうしかないですね。
CallBack関数を組み込んで、進捗を表示した
遅いのはどうしようも無いのですが、ユーザーからすると何も表示されずに待たされるのはツラいです。ですので、進捗表示をするためにCallback関数で処理中に今実行している処理を表示するようにしました。

アプリの処理はLangChainというライブラリを中心に使用しており、LangChainにはCallback機能があったので、、、あったのですが、よく分からなかったので自力で組み込みました。
進捗が表示されることで、待ち時間の精神的な苦痛は減ったかなと思います。たぶん。
DropboxAPIのPythonライブラリが使いにくい
DropboxAPIを使うためにPythonのDropboxのライブラリを使ったのですが、使いにくいです。世の中のこのライブラリの情報が少ないことも理由としてあります。しかしそれ以上にツラいのが、ライブラリに型アノテーションが皆無なことでした。アノテーションみるとNoneなのに実際は中身がある関数が当たり前に存在します。というか、全ての関数がNoneを返すアノテーションになっているというか、そんな感じでかなり辛かったです。私には理解できないので、ChatGPT先生に頑張ってもらいました。Pythonってこういうライブラリが多くてツラいですよね。そんな中で、型がしっかり定義されているLangChainはとても使いやすいです。
LangChainを使うべきか問題
LangChainは使うべきではないという意見は結構あるみたいです。
私はそういう意見は知らずに今月に入ってから使い始めた素人なのですが、最初の感想は「めっちゃ楽に書けてスゴい。Pythonなのに型定義もしっかりしてて分かりやすい!!」でした。とても良いライブラリだと思います。
ですが実際アプリを作った後に振り返ると、LangChainを活用している部分は次の2点だけでした。
- プロンプトとLLMを繋ぐ
- 各処理を|で繋いでかっこよく書く
というのも、いざ開発となるとアプリ特有の考慮点とかカスタマイズが必要になってきまして、LangChainの機能に固執すると寧ろ冗長で分かりにくいコードになってしまいます。それに伴いAIに処理させる文字数も増えがちになるので課金的にもちょっと微妙でした。そこで、独自に処理を書いて関数化しRunnableLambdaでラップしてChainさせるみたいな作りに落ち着きました。つまりLangChainいらないじゃんという状態です。
LLM周りの処理も最初に使ったのがそのまま残っているだけで、やりたいことは素で書いても数行で書けるんですよね。
その他にも微妙な点があります。コレはちょっと、、、と思ったのが、LangChainのDropboxのプラグインのコードがなんというかアレで、、、そんな感じでした。最初に使おうと思って試したのですが欲しい機能が足りませんでした。具体的にはPDFは開けるのにパワポは開けませんでした。プラグインを改造して機能追加しようかなと思ってコードみたら、なんというか、まぁ、、、結果的にプラグインは使わずに自力で実装することにしました。実装する上での参考にはなりました。各種プラグインの品質にはもう少し力を入れるべきなんじゃないかと思います。
一方で、LangChainを使うことで次のようなメリットを感じました。
- Runnableプロトコルで各処理を統一することになるので、コードの構成がきれいにできる
- Chainする為に前後の処理の入出力を合わせることになり、その為に型定義がきれいになる
要約すると、使う必然性はないけど、型定義やアプリの構成をきれいにする為と|で繋ぐとかっこいいからLangChainを使う。それでいいかなと思いました。
なお、LangChainにはTypeScript版もありますが、TSなら最初から型はきれいでしょうし、一方で|で繋ぐことはどう頑張っても無理です。なので、私が今からTSで処理を書くならLangChainは使わない可能性も高いです。(便利な部分もあると思うので使うかもしれません。その時考えます。)
認証はどうするか問題
作ったアプリを自分だけで使ってもあまり有効ではないので、利用者つまり社内に公開する必要があります。一方で社員以外には使えないようにする必要があります。つまり認証機能が必要です。
普段は、アプリ内に認証機能をつけるよりも、アプリをネットワーク的に隔離してしまってロードバランサーとかCDNとかリバプロを設置して認証はそっちでやる構成にすることが多いです。ですが、今回はネットワーク含めてコンパクトな構成にしたかったので、アプリ内にOAuth2でGoogle認証が出来る機能を追加しました。
ただ、やっぱり、認証をかけたとしても直にインターネット上から触れるのは怖いので、ある程度使ってみたらIAP(Identity-Aware Proxy)を設置しようかとも思っています。StreamlitのWebSocketが不要ならもっといろいろ選択肢があるんですけど。。。そう考えるとNext.jsとかで書いたほうが汎用性高かったのだろうとも考えてしまいます。
実装したアプリは完全にステートレスです
コンテナなのでステートレスなのは当たり前ですが、最初の構成から分かるようにDBもストレージも持っていません[5]。
つまり、どういうことかというと、このAIチャットアプリは安い上にとても簡単に導入できます。
と言いつつ現状ソースコードは公開していないですし販売計画とかも無いのでどう育てていくかは悩み中です。
本当に安いの?
開発中に1日平均200回くらい使って1日平均200円くらいGoogle Cloudの費用を使っていました。1回あたり1円前後って感じですね。安いと見るか高いと見るかは得られる情報次第だとは思います。ですが、使わなければ課金もほぼ0円になる構成ですので、使い物にならなければ自然と課金されないし、使われれば高くなるけどそれだけ有用ってことでいいのかなと思います。
もし仮に月20万円とかになるほど使われることがあれば、最初に書いた高いけど高性能なサービスに乗り換えれば良いわけです。そのくらい使うとDropboxAPIに上限である月100万回も限界になるので乗り捨てるのにちょうどよいタイミングです。
おわり
他にも、いろいろ書けることはある気がしますが、それは気が向いたら別途記事にしようかなと思います。長くなってきたのでこの記事は以上です。
参考にした資料や記事
おまけ
Geminiくんさぁ😅
-
少ないと言ってもゼロではなく、例えば先日のAWS re:Invent 2023で発表された「Vector Engine for Amazon OpenSearch Serverless」などは、コスト削減と性能が両立できる可能性があると思っています。 ↩︎
-
クラウドサービスに依存せずにOSSの検索エンジンを活用すれば直接的な費用は抑えて運用することは出来るように思えます。しかし、ある程度自力で保守運用をする必要があり、人件費含めたコストがどこまで抑えられるかは疑問です。 ↩︎
-
AWS App RunnerはWebSocketに対応してない。Azure WebAppsはコスパが悪い。それよりもリッチなコンテナサービスでは構築が面倒くさい。なので、Cloud Runが最適だと思います。 ↩︎
-
ここでいう「調整」とはAIに何か手を加えるということではなく、ハラスメント回避の為にふわふわ言葉でAIに語りかけるという意味です。 ↩︎
-
そのうちキャッシュ系のDBとの連携を考えるかもしれませんが、やつらは結構高いので悩みます。 ↩︎

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion