はじめに
2025年のAWS re:Inventに会社から参加させてもらえることになり、英語学習を行っている今日この頃です。
私の現在の英語力は一般的な日本人レベルなので、re:Inventに向けて作戦を立てました。
それは、自分の聞くセッション担当の方の英語に慣れること。
全英語力をアップグレードするほどの時間はないので、ドメイン・人を絞りに絞って学習しようという作戦です。
ということで今回は私が聞きたいDynamoDBのセッションを担当するAlex Debrieさんの過去の登壇を見て、こちらの記事にアウトプットすることにします。
AWS re:Invent 2020: Data modeling with Amazon DynamoDB – Part 1
出典:YouTube「Data modeling with Amazon DynamoDB – Part 1(re:Invent 2020)」
登壇者:Alex Debrie
URL:https://www.youtube.com/watch?v=fiP2e-g-r4g
このYoutubeでは以下3つが語られています。
- DynamoDB basics:DynamoDBの基礎(本記事)
- SQL vs NoSQL:SQLとNoSQL(本記事)
- one-to-many relationships:1対多の関係(その2の記事で書きました)
DynamoDB basics

アプリケーションにユーザーがサインアップするサービスがあるとすると、DynamoDBのテーブルは上記のようになります。
Item
リレーショナルデータベースでいうレコードに似ている。
Primary Key
アイテムがテーブル内に一意になるように指定するもの。
Attribute
Primary Key以外でItemに含めることができる追加のデータ。リレーショナルデータベースのカラムに似ている。事前にAttributeの定義しなくていいのが違い。リレーショナルデータベースだと、DDLでまずはテーブル定義を作成するが、その作業が必要ない。DynamoDBがスキーマレスと言われる所以。
ただこのスキーマレスの部分についてAlex Debrieさんは以下のように言っています。
So, people call DynamoDB schema list, that's true in the sense that DynamoDB itself is not going to force your schema.
訳)人々は DynamoDB をスキーマレスと呼びますが、これはDynamoDB自体がスキーマを強制しないという意味では真実です。
なんか若干歯切れのよくない言い方をされていますね。
私の解釈では、おそらく「DynamoDBはスキーマレス!」という覚え方をしてほしくないのだと思います。
スキーマレス故の注意点を知ってほしかったり、スキーマレスだから設計をしなくていいというミスリーディングにならないようにという気持ちが込められている気がします。
The database wasn't going to do it like it would in a relational world.
So, what you need to do is make sure you're enforcing that scheme and having a schema in your application code.
訳)データベースは、 リレーショナルの世界のようには機能しません。したがって、必要なのは、 そのスキーマを強制適用し、アプリケーションコードにスキーマを含めることです。
リレーショナルデータベースだと以下のようなエラーを出して、不正なデータが入ることを防いでくれたりしますよね。
ERROR: null value in column "age" violates not-null constraint
DynamoDBの場合、データベース側でスキーマの保証はしないので、アプリケーションコード側で担保してねということですね。
type
それぞれのAttributeはtype(型)を持つことができる。
文字列や数値、配列などの複雑な型を持つことができる。
Primary Key詳しく
DynamoDBを使用する場合、Primary Keyには2種類あります。
- Simple primary key(partition key)
- Composite primary key(partition key + sort key)
先ほど見たこちらの例は、Simple primary key。
Usernameという一つの要素のみがprimary keyを構成し、各アイテムを一意に識別していました。

こちらはComposite primary keyの例。
俳優や女優が出演した映画の役柄を含むテーブル。
partition keyがActorでsort keyがMovie。
ActorとMovieの組み合わせで各アイテムを一意に識別しています。
SQL vs NoSQL
SQLのどんな問題をNoSQLが解決するのか。

x軸にデータ量、y軸にパフォーマンスを示したグラフ。
データ量が少ない時はサクサク動くが、データ量が増えると遅くなっていく様子が示されています。
こういったデータ量の増加によるパフォーマンス悪化はリレーショナルデータベースの典型的な問題です。
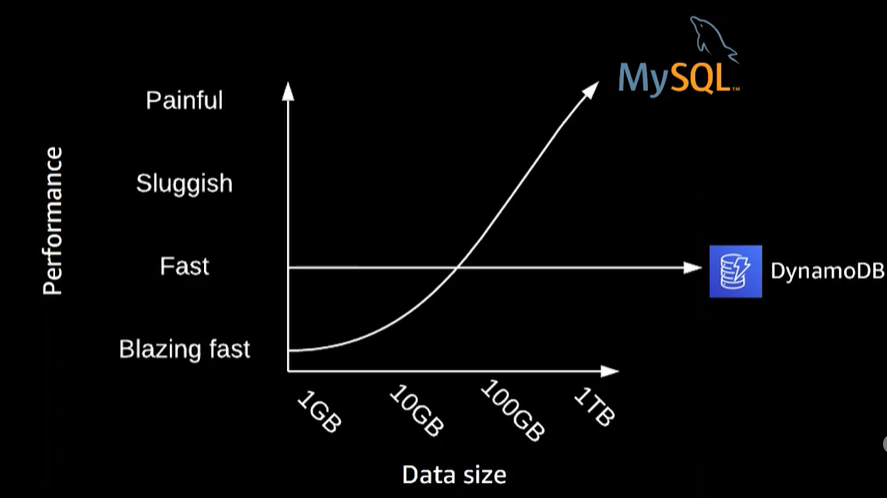
DynamoDBの場合のパフォーマンス曲線は上記のようになり、データ量が増えてもパフォーマンスは一定であることが示されています。
これこそがDynamoDBが目指していることです。
DynamoDBのドキュメントには載っていないが、Alex Debrieさんが大切だと考える原則があります。
それは「スケールしない操作を許可しない」というものです。
From SQL to NoSQL
スケールしない操作を許可しないためにどのようなことをやっているか見ていきます。
ここでは2つ挙げています。
- Primary keyは大事
- joinがない
Primary keyは大事
Primary keyはほぼすべてのクエリパターンを実行する方法です。

このテーブルから「Natallie PortmanのBlack Swanを見つけてください」や、
「Tom Hanksの映画を全部見つけてください」とすることはとても簡単です。
しかし、属性でクエリ(検索)することは難しいです。
「2000年代の映画を全部見つけてください」や「ドイツ映画をすべてください」とすることはできません。
セカンダリインデックスを使えばクエリ可能になるが、DynamoDBはPrimary keyで検索をするという認識を持つのがまずは大事ってことを伝えたいのだと思います。
joinがない

DynamoDB ではさまざまなパーティションにデータを分割していて、異なるストレージパーティションが存在します。

DynamoDB でアイテムを挿入する際にどのようなことが内部で行われているか見てみましょう。
DynamoDBフロントエンドといわれる場所でパーティションキーをハッシュし、どのパーティションに所属するかを決めています。
この仕組みにより、どのパーティションにデータがあるかは常にHashMapで検索を行うことができ、高速です。
Alex Debrieさんは上記の説明後、以下のように言います。
So, now we know about those partitions,we know that's why we can't do join.
訳)パーティションについて理解できたので、joinがなぜできないかを理解できました。
joinを許すと、複数パーティションをまたいだデータ集約が必要になり、スケールしにくくなるということだと思います。
「スケールしない操作を許可しない」というAlex debrieさんの言う原則ですね。
また、データモデリングへの影響も3点説明されいます。
- アクセスパターンを事前に知っておく
- セカンダリインデックスを使う
- シングルテーブル設計
アクセスパターンを事前に知っておく
リレーショナルデータベースの設計とは異なります。
リレーショナルデータベースの場合、テーブル設計をしてから、そのテーブルへのアクセスパターンを考えます。
DynamoDB の場合、アクセスパターンに合わせてテーブル設計を行い、効率的な検索を行うことができます。
なぜそのような順番で設計するかはこの記事がわかりやすいです。
セカンダリインデックスを使う
先ほどPrimary keyは大事という話がありました。
Primary key以外の属性で検索したくなったらどうでしょうか?
たとえば、「2000年以降のTom Hanksの映画をすべてください」という異なるアクセスパターンが必要な場合はどうしたらいいでしょうか?
そんな時に使うのがセカンダリインデックスです。
セカンダリインデックスを使うと、DynamoDBは新しいPrimary keyの形にデータを複製し、追加のアクセスパターンに対応できるようにします。

Partition KeyにActor、Sort keyにYearというPrimary keyのテーブルをDynamoDB側が作っている。
これにより、Tom Hanksの特定年の映画を取得ということができるようになります。
シングルテーブル設計
すべてのエンティティを1つのテーブルに入れ、汎用的なprimary keyを使うという設計のことをシングルテーブル設計と言います。
例を用いて説明されています。
Saasのアプリケーションでorganizationsとusersというエンティティを持つ場合を考えてみます。
organizationsからまずはモデル化してみます。

primary keyの名前が汎用的なのがポイントです。
partition keyはPK、sort keyはSK。
テーブル内に複数の種類のアイテムがある場合、同じ名前で扱うわけにはいかないからです。

他のポイントとしては、primary keyの値です。
「ORG#」という文字列が頭についています。
これはテーブル内にあるアイテムの種類を区別するのに役立ちます。
(次の図を見るとイメージがわくと思います。)

userアイテムを追加すると上図のようになります。
「USER#」という文字列が頭についてるのがuserアイテムです。
organizationアイテムの方は、OrgNameやSubscriptionLevelという属性を持ちますが、
userアイテムの方は、UserNameやRoleという属性を持っています。
DynamoDBはスキーマレスなのでこのように各アイテムが持つ属性を区別することができます。
これがシングルテーブル設計の基本です。
one-to-many relationshipsの部分については、また別記事で書くことにします。
→書きました(2025/10/20)
感想・気づき
Alex Debrieさんは「sort of」をよく言う。
順番という意味ではなく、「ちょっと」「~っぽい」という意味。
本記事の内容は動画だと15分程度ですが、記事書くのは5時間かかりました。
何回も聞き直すと内容は頭に入ったので、音を認識できるように練習していこうと思います。

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion
人まで絞って対策するのは凄いですね👀