はじめに
Amazon Comprehendのキーフレーズ抽出と感情分析を使ってみたときがあり、組み合わせて何かできないかと考え、より出現頻度が高く、よりポジティブ/ネガティブな文脈で使われているキーフレーズのランキングを作れないかと思ってやってみました。
仮のストーリー
飲食店を経営していてカスタマーレビューからよく出現する、かつ、よりポジティブ(またはネガティブ)な文脈で使われているキーフレーズのランキングを作成して経営に活かしたいとします。
架空のオムライス屋さんの良い点、悪い点を数名に書いてもらったと仮定して、それらを1つの文章にした以下のテキストファイルをGoogle Geminiを使って作り、本記事で使用することにしました。
何度食べても飽きない、絶品のオムライスです。
ふわふわの卵が口の中でとろけるような食感で、幸せな気分になります。
チキンライスも上品な味付けで、卵との相性も抜群です。
デミグラスソースは濃厚で、ご飯によく合います。
大盛りにしてもペロリと食べられてしまうほど、美味しいです。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
何度でも通いたくなる、そんなお店です。
「カクウノオムライスヤ」のオムライスは、ソースが決め手です。
デミグラスソースは、コクがありながらも上品な味わいで、ご飯との相性も抜群です。
チキンライスも、しっとりとした食感で、味付けもちょうど良いです。
卵はふわふわで、口の中でとろけるような食感がたまりません。
ボリュームも満点なので、お腹いっぱいになります。
何度食べても飽きない、そんな一品です。
子供の頃から慣れ親しんだ「カクウノオムライスヤ」の味。
変わらない美味しさが嬉しいです。
ふわふわの卵と、チキンライスとのハーモニーがたまりません。
デミグラスソースも、昔ながらの味で、懐かしさを感じます。
店内は昔ながらの喫茶店の雰囲気で、落ち着いて食事を楽しめます。
何度食べても飽きない、そんな大好きな一品です。
街の中にある隠れ家のようなお店です。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
オムライスは、ふわふわの卵と、チキンライスとのハーモニーが絶妙です。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
ボリュームも満点なので、お腹いっぱいになります。
何度食べても飽きない、そんな一品です。
「カクウノオムライスヤ」は、コスパの良さも魅力の一つです。
ボリューム満点のオムライスが、リーズナブルな価格で楽しめます。
ふわふわの卵と、チキンライスとのハーモニーがたまりません。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
「カクウノオムライスヤ」は、何度食べても飽きない、そんな魅力的なお店です。
ふわふわの卵と、チキンライスとのハーモニーがたまりません。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
ボリュームも満点なので、お腹いっぱいになります。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
老舗の洋食屋さんならではの、本格的なオムライスが楽しめます。
ふわふわの卵と、チキンライスとのハーモニーが絶妙です。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
店内は昔ながらの喫茶店の雰囲気で、落ち着いて食事を楽しめます。
何度食べても飽きない、そんな大好きな一品です。
ランチタイムはいつも賑わっている人気店です。
ふわふわの卵と、チキンライスとのハーモニーが絶妙です。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
ボリュームも満点なので、お腹いっぱいになります。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
「カクウノオムライスヤ」は、デートにもおすすめです。
店内は落ち着いた雰囲気で、ゆっくりと二人の時間を過ごすことができます。
ふわふわの卵と、チキンライスとのハーモニーが絶妙です。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
一度食べたら忘れられない、そんな絶品のオムライスです。
ふわふわの卵と、チキンライスとのハーモニーがたまりません。
デミグラスソースも、コクがありながらも上品な味わいで、ご飯によく合います。
ボリュームも満点なので、お腹いっぱいになります。
店内は落ち着いた雰囲気で、ゆっくり食事を楽しめます。
リピーターが多いのも納得の味です。
期待して行ったのですが、正直がっかりでした。
オムライスの卵はパサついていて、全然とろけるような食感ではありませんでした。
チキンライスも味が薄く、物足りなさを感じました。
デミグラスソースもコクがなく、全体的に味がぼやけていました。
値段も少し高めなので、コスパも良くありません。
以前はもっと美味しく感じていたのですが、最近は味が落ちたように感じます。
オムライスの卵が硬く、パサついているのが気になりました。
チキンライスも味が薄く、物足りないです。
デミグラスソースもコクがなく、昔の方が濃厚で美味しかったと思います。
SNSで話題になっていたので行ってみたのですが、期待していた味とは違いました。
オムライスの卵はパサついていて、もう少しふわふわしている方が好みです。
チキンライスも味が薄く、物足りなさを感じました。
デミグラスソースも、もっとコクがある方が良かったです。
オムライスのボリュームが少なかったです。男性には物足りないかもしれません。
もう少しご飯の量が多いと嬉しいのですが。
味は普通でしたが、特に感動するような美味しさではありませんでした。
お店の雰囲気は良かったのですが、店員さんの対応が少し残念でした。
注文を聞き間違えられたり、料理が出てくるのが遅かったりしました。
料理の味も普通だったので、もう二度と行くことはないと思います。
オムライス以外のメニューが少なく、選択肢が少ないのが残念です。
デザートの種類も少なかったです。
オムライス自体は普通でしたが、もう少しメニューが豊富だと嬉しいです。
値段が高い割に、味は普通でした。オムライスの卵はパサついていて、もう少しふわふわしている方が好みです。
チキンライスも味が薄く、物足りなさを感じました。
デミグラスソースも、もっとコクがある方が良かったです。
店内は狭く、テーブルとテーブルの間隔が狭いので、落ち着いて食事を楽しむことができませんでした。
また、換気があまり良くなく、油のにおいが気になりました。
休日に行ったので、とても混んでいて待ち時間が長かったです。
30分以上待ったのに、出てきたオムライスはパサついていて、期待はずれでした。
一度行けば十分です。オムライスの卵がパサついていて、美味しくありませんでした。
チキンライスも味が薄く、物足りないです。
デミグラスソースもコクがなく、全体的に味がぼやけていました。
ポジ/ネガフレーズTOP5の作成手順
作成手順として以下を考えてみました。
- 全てのレビューを1つの文章にしてキーフレーズを抽出する。
- 1から、キーフレーズである確率が高いものから順に50個抽出する。
- 2のそれぞれのキーフレーズについて出現する文とその数を求める。
- キーを3の出現する文、値をその文の感情の種類とした辞書を作成する。
- 1つの行が以下で構成される表を作成する。
- キーフレーズ
- 出現する文
- 出現する文の感情の種類
- 出現する文の数
- 5を以下に変換する。
- キーフレーズ
- 出現する文の数
- 出現する文群におけるポジティブな文の割合...(a)
- 出現する文群におけるネガティブな文の割合...(b)
- 6の「出現する文の数」と(a)を組み合わせて1つにした指標を元にランキングを作成し、それをポジティブフレーズのランキングとする。ネガティブフレーズのランキングも(b)を使用して同様に行う。
ソースコード
import boto3
from comprehend_sample.key_phrase import KeyPhrase
from typing import TypedDict
class SentimentType(TypedDict):
sentiment_name: str
positive_score: float
negative_score: float
neutral_score: float
mixed_score: float
class ComprehendClient:
def __init__(self: "ComprehendClient") -> None:
self.session = boto3.Session(profile_name="profile_name")
self.client = self.session.client(
service_name="comprehend",
region_name="ap-northeast-1",
)
def fetch_key_phrases(self: "ComprehendClient", text: str) -> list[KeyPhrase]:
"""
Amazon Comprehendを使ってテキストからキーフレーズを抽出してKeyPhraseTypeのリストにして返す
"""
try:
# Amazon Comprehendを使ってテキストからキーフレーズを抽出
response = self.client.detect_key_phrases(
Text=text,
LanguageCode="ja",
)
# レスポンスをKeyPhraseTypeのリストに変換する
return [
KeyPhrase(
text=key_phrase["Text"],
score=key_phrase["Score"] * 100, # Scoreをパーセントにする
original_texts=[],
)
for key_phrase in response["KeyPhrases"]
]
except Exception as e:
raise e
def fetch_batch_sentiment(
self: "ComprehendClient",
texts: list[str],
) -> list[SentimentType]:
"""
Amazon Comprehendを使って各テキストの感情スコアを取得してSentimentTypeのリストにして返す
1回のリクエストで25件までの制限がある
"""
try:
response = self.client.batch_detect_sentiment(
TextList=texts,
LanguageCode="ja",
)
return [
SentimentType(
sentiment_name=sentiment["Sentiment"],
# 感情スコアをパーセントにする
positive_score=sentiment["SentimentScore"]["Positive"] * 100,
negative_score=sentiment["SentimentScore"]["Negative"] * 100,
neutral_score=sentiment["SentimentScore"]["Neutral"] * 100,
mixed_score=sentiment["SentimentScore"]["Mixed"] * 100,
)
for sentiment in response["ResultList"]
]
except Exception as e:
raise e
from itertools import groupby
class KeyPhrase:
def __init__(
self: "KeyPhrase", score: float, text: str, original_texts: list[str] = []
) -> None:
self.score = score
self.text = text
self.original_texts = original_texts
@staticmethod
def remove_duplicate_key_phrases(
key_phrases: list["KeyPhrase"],
) -> list["KeyPhrase"]:
"""
KeyPhraseのリストから重複するキーフレーズを削除して返す
"""
# textをキーとしてグループ化する
grouped_key_phrases = groupby(
sorted(key_phrases, key=lambda p: p.text),
key=lambda p: p.text,
)
# 各グループからscoreが最も大きい要素を取り出す
filtered_key_phrases: list["KeyPhrase"] = []
for _, phrases in grouped_key_phrases:
filtered_key_phrases.append(max(phrases, key=lambda p: p.score))
return filtered_key_phrases
@staticmethod
def match_key_phrase_to_sentences(
key_phrase_text: str,
sentences: list[str],
) -> str:
"""
キーフレーズを含んでいる文を取得する
"""
matched_sentences: list[str] = []
for sentence in sentences:
if key_phrase_text in sentence:
matched_sentences.append(sentence)
matched_sentences_deduplicated = list(set(matched_sentences))
return matched_sentences_deduplicated
@staticmethod
def get_sorted_key_phrases(
key_phrases: list["KeyPhrase"],
) -> list["KeyPhrase"]:
"""
KeyPhraseのリストをキーフレーズの信頼度の降順にソートする
"""
return sorted(
key_phrases,
key=lambda p: p.score,
reverse=True,
)
手順5の内容をCSV形式で保存するノートブックの実行
from pathlib import Path
import pandas as pd
from comprehend_sample.comprehend_client import ComprehendClient
from comprehend_sample.key_phrase import KeyPhrase
from comprehend_sample.comprehend_client import SentimentType
# srcディレクトリまでのパスを取得する
script_dir: Path = Path(Path().resolve())
src_dir: Path = script_dir.parents[0]
# テキストファイルを読み込む
with open(Path(src_dir / "repo_name" / "sample_text.txt"), ) as f:
texts: list[str] = f.read().splitlines()
# テキストを結合する
text_joined = "".join(texts)
# テキストからAmazon Comprehendを使ってキーフレーズを取得する
comprehend_client = ComprehendClient()
key_phrases = comprehend_client.fetch_key_phrases(text=text_joined)
# KeyPhraseのリストから重複するキーフレーズを削除して返す(手順1)
key_phrases_deduplicated: list[KeyPhrase] = KeyPhrase.remove_duplicate_key_phrases(key_phrases=key_phrases)
# key_phrasesをキーフレーズの信頼度の降順にソートして50個まで取得する(手順2)
key_phrases_sorted = KeyPhrase.get_sorted_key_phrases(key_phrases=key_phrases_deduplicated)[:50]
# キーフレーズにマッチする文を取得する
key_phrases_add_original_texts: list[KeyPhrase] = []
for key_phrase in key_phrases_sorted:
key_phrase.original_texts = (
KeyPhrase.match_key_phrase_to_sentences(
key_phrase_text=key_phrase.text,
sentences=texts,
)
)
key_phrases_add_original_texts.append(key_phrase)
for key_phrase in key_phrases_add_original_texts:
print(f"キーフレーズ: {key_phrase.text}")
print(f"信頼度: {key_phrase.score}")
キーフレーズ: 値段
信頼度: 99.99830722808838
キーフレーズ: 店内
信頼度: 99.9945878982544
キーフレーズ: 注文
信頼度: 99.99446868896484
...
# キーフレーズの抽出元のテキストを取得する
original_texts: list[str] = [original_text for key_phrase in key_phrases_add_original_texts for original_text in key_phrase.original_texts]
# 重複するテキストを削除する(手順3)
original_texts_deduplicated: list[str] = list(set(original_texts))
print(original_texts_deduplicated)
['店内は昔ながらの喫茶店の雰囲気で、落ち着いて食事を楽しめます。',
'ボリューム満点のオムライスが、リーズナブルな価格で楽しめます。',...,
'オムライスの卵はパサついていて、全然とろけるような食感ではありませんでした。']
# 各テキストに対する感情辞書(手順4)
sentiment_dict: dict[str, SentimentType] = {}
req_texts: list[str] = []
for cnt, text in enumerate(original_texts_deduplicated, 1):
req_texts.append(text)
# 25個ずつテキストを感情分析する
if cnt == len(original_texts_deduplicated) or cnt % 25 == 0:
sentiments: list[SentimentType] = comprehend_client.fetch_batch_sentiment(texts=req_texts)
for i, req_texts in enumerate(req_texts):
sentiment_dict[req_texts] = sentiments[i]
req_texts = []
# DataFrameに変換するリスト用
input_df_data: list = []
for key_phrase in key_phrases_add_original_texts:
for original_text in key_phrase.original_texts:
sentiment = sentiment_dict[original_text]
input_df_data.append(
[
key_phrase.text,
len(key_phrase.original_texts),
original_text,
sentiment["sentiment_name"]
]
)
df = pd.DataFrame(
input_df_data,
columns=[
"key_phrase", # キーフレーズ
"comment_num", # キーフレーズの出現テキスト数
"origin_text", # キーフレーズの出現テキスト
"sentiment_type" # テキストの感情
]
)
df.head()
- 実行結果
| key_phrase | comment_num | origin_text | sentiment_type |
|---|---|---|---|
| 値段 | 2 | 値段も少し高めなので、... | NEGATIVE |
| 値段 | 2 | 値段が高い割に、味は普... | NEGATIVE |
| 店内 | 4 | 店内は昔ながらの喫茶... | POSITIVE |
| ... | ... | ... | ... |
# DataFrameをCSV形式で保存する(手順5)
df.to_csv(Path(src_dir / "repo_name" / "output.csv"), index=False, encoding='utf-8-sig')
手順6、7をExcel上で行う
上記のCSVファイルをExcelで開き、キーフレーズごとに、そのキーフレーズが出現する文群におけるポジティブ(またはネガティブ)な文の割合を求めたものが以下になります。
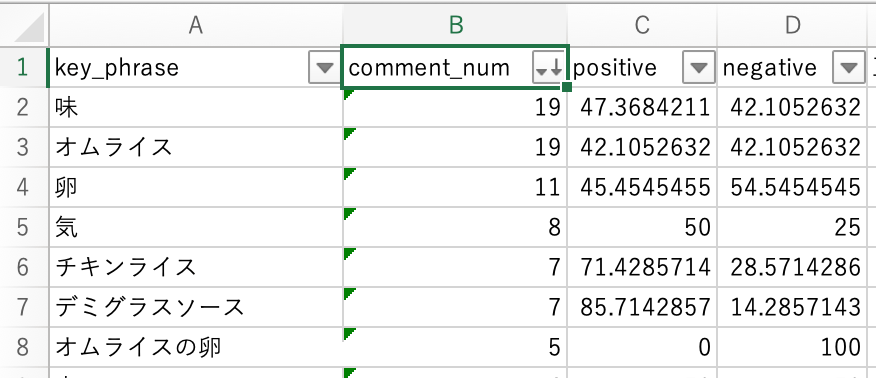
例えば、「味」が出現する文を集めてきたとき、その文群のおよそ47%(全19文中9文)はポジティブと判定されているということになります。
次に、キーフレーズの出現テキスト数、ポジティブの割合、ネガティブの割合を0〜1に正規化しました。
キーフレーズの出現テキスト数は、飛び抜けて大きい数がいくつかあり、そのまま正規化すると過小に求められてしまう印象でした。また、1や2が多く、そのような出現数が少ないキーフレーズはトップに出てきてほしくありませんでした。
そのため、キーフレーズの出現テキスト数は、65%タイル以上で95%タイル以下のものを抽出した後、その範囲の中で正規化し、その範囲に入っていないものは0としました。
なお、ポジティブの割合、ネガティブの割合は100で割ることで正規化しています。
そのようにして、正規化後のキーフレーズの出現テキスト数と正規化後のポジティブの割合を求め、それらを足した値(以下のnew_posi)で降順にソートすることでポジティブフレーズTOP5を求めました。

1位の「デミグラスソース」について原文にあたってみると、比較的出現数が多いフレーズであることがわかります。さらに、ポジティブな文脈で使われていることが多く、満足しているお客さんの方が多そうです。デミグラスソースの良さをもっと宣伝してみる等して、利益に活かせるとよさそうです。

また、ネガティブフレーズTOP5は以下の通りになりました。

最後に
本記事では、Amazon Comprehendのキーフレーズ抽出と感情分析を使用して、架空の飲食店のレビューのポジ/ネガフレーズTOP5を出してみました。
使い方によっては、感情スコアの方をもう少し重視したいとかが出てきてその分、重みをかけてみる等、調整が必要なのかなと思いました。
また、「気」や「方」など、パッとみてわからないものもキーフレーズとして抽出されてしまうようです。ストップワードリストを作ってこのようなフレーズは除くようにすると良いんですかね。
以上です。ここまでご覧いただき、ありがとうございました。

NCDC株式会社( ncdc.co.jp/ )のエンジニアチームです。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください! ※エンジニア以外も記事を投稿することがあります
Discussion