最新モデル Cohere Command R+ と AWS Step Functions でノーコード RAG をやってみる
最近、Amazon Bedrock で Cohere Command R と Cohere Command R+ という新しいモデルが利用可能になりました。
(2 つのモデルは性能に差があるようですが、コンセプトは同一のため、以後、記事内で利用する Cohere Command R+ に統一します。)
Cohere Command R+ の特徴として、RAG を見据えて構築されたモデルおよびインターフェイスになっていることが挙げられます。
例えば、
search_queries_only パラメータを有効化すると、通常のチャット応答ではなく、検索クエリを返します。
例):
ユーザーの入力: Amazon Bedrock で利用可能なモデルを教えてください。
モデルからの出力: Amazon Bedrock available models
プロンプトエンジニアリングに当てはめると、
「以下のユーザーからの入力を元に、検索用のクエリを生成してください。${prompt}」
のようなプロンプトをモデル (API) 側で勝手に補完してくれるイメージに近いです。
その他にも、documents パラメータに参考文献を入れてリクエストを行うと、それに基づいた回答を行ってくれる機能もあります。(後ほど利用します)
今回は、これらの機能と AWS が提供するマネージドなワークフローサービスである AWS Step Functions を用いて、コードを書かずに、プロンプトエンジニアリングもせずに RAG を実現してみます。
ノーコード RAG を構築する
実際に構築する前に、AWS Step Functions について簡単に紹介しておきます。AWS Step Functions は、AWS が提供するマネージドなワークフローサービスです。
ワークフローの定義は Amazon State Language(ASL) と呼ばれる JSON 形式で定義されますが、これを書いてしまってはノーコードとは言えません。
そこで、今回はマネジメントコンソール上で利用可能な GUI のエディタである、Workflow Studio の機能を用いてワークフローを定義していきます。
完成物
今回はこんなワークフローを作成します。

簡単に試したい人は以下の ASL をコピペしてデプロイしてみてください。
ASL
{
"Comment": "No code RAG",
"StartAt": "Generate search query",
"States": {
"Generate search query": {
"Type": "Task",
"Resource": "arn:aws:states:::bedrock:invokeModel",
"Parameters": {
"ModelId": "arn:aws:bedrock:us-west-2::foundation-model/cohere.command-r-plus-v1:0",
"Body": {
"message.$": "$.user_prompt",
"search_queries_only": true
},
"ContentType": "application/json",
"Accept": "*/*"
},
"Next": "Map",
"ResultPath": "$.result_one",
"ResultSelector": {
"search_queries.$": "$.Body.search_queries"
}
},
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "Retrieve",
"States": {
"Retrieve": {
"Type": "Task",
"Parameters": {
"KnowledgeBaseId.$": "$.KnowledgeBaseId",
"RetrievalQuery": {
"Text.$": "$.search_query.text"
}
},
"Resource": "arn:aws:states:::aws-sdk:bedrockagentruntime:retrieve",
"End": true,
"ResultPath": "$.result_two",
"ResultSelector": {
"documents.$": "$.RetrievalResults[*].Content"
}
}
}
},
"Next": "Invoke model with documents",
"ItemsPath": "$.result_one.search_queries",
"ItemSelector": {
"search_query.$": "$$.Map.Item.Value",
"KnowledgeBaseId.$": "$.KnowledgeBaseId"
},
"ResultPath": "$.result_map"
},
"Invoke model with documents": {
"Type": "Task",
"Resource": "arn:aws:states:::bedrock:invokeModel",
"Parameters": {
"ModelId": "arn:aws:bedrock:us-west-2::foundation-model/cohere.command-r-plus-v1:0",
"Body": {
"message.$": "$.user_prompt",
"documents.$": "$.result_map[*].result_two.documents[*]"
},
"ContentType": "application/json",
"Accept": "*/*"
},
"End": true
}
}
}
0. 準備
Amazon Bedrock では、モデルごとにアクセスを有効化する必要があります。Bedrock のマネジメントコンソールから Cohere Command R+ のアクセス権をリクエストしてください。(即時承認されるはずです)
また、Cohere Command R+ は現在 us-east-1, us-west-2 の 2 つのリージョンでのみ利用可能です。
1. 検索クエリの生成
検索クエリの生成は、冒頭で説明した Cohere Command R+ の組み込みの機能である search_queries_only オプションを利用するだけです。
ユーザーからの Workflow Studio の左のペインで、Bedrock: InvokeModel を選択し、cohere.command-r-plus-v1:0 のモデルを選択します。
Bedrock Model Parameters には
{
"message.$": "$.user_prompt",
"search_queries_only": true
}
このように設定します。$ は JSONPath という記法で JSON のルートを示します。Step Functions では各タスクの入出力を JSONPath で表現します。今回の場合は、ルート直下の user_prompt を受け取ることになります。つまり、この時点では、このワークフローは実行時に、
{
"user_prompt": "Amazon Bedrock とは何ですか?"
...
}
のような JSON を期待します。

ステートマシンはこんな感じ
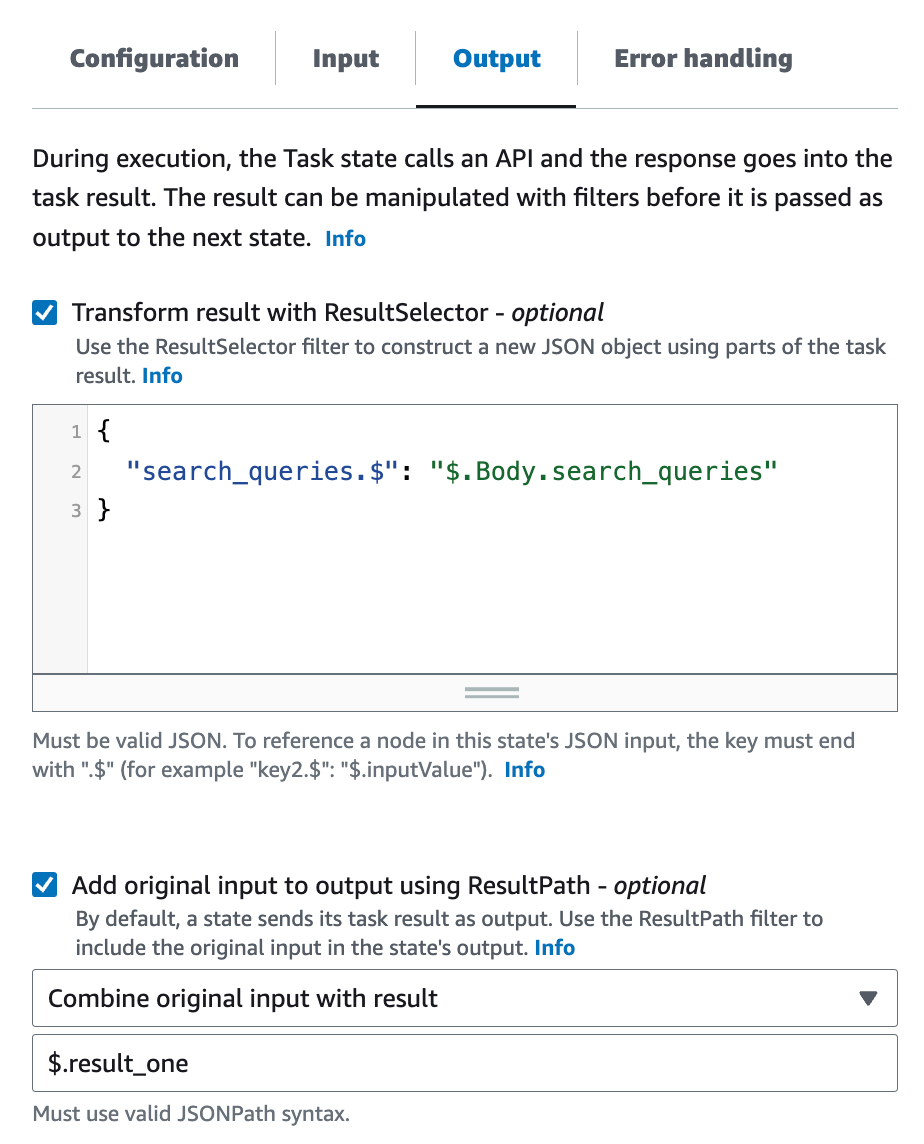
出力を整形するために、Output タブの Transform result with ResultSelector を
{
"search_queries.$": "$.Body.search_queries"
}
に、
そして、このステートの結果を追加しながら、最初の input も次以降のステートに渡していきたいため、
Add original input to output using ResultPath を Combine original input with result として、$.result_one を入力します。
最初のステートの Output の設定
テスト実行 (Option)
ここでは、2023 年の Re:invent でリリースされた新機能であるテストステート機能を使って、単一ステートのテストをしてみます。
コンソールの右上の Save をクリックすると、ワークフローの定義から自動的に IAM ロールが作られます。IAM ロール作成のために一旦保存しましょう。
その後、Workflow Studio の画面に戻るとって、Generate search query を選択して、Test state をクリックします。
Execution Role は先ほど作成された IAM ロールが設定されているはずです。
State input に
{
"user_prompt": "{お好きな質問}"
}
を入れて実行すると、早速 Cohere Command R+ が検索クエリに変換してくれます。すごい!

余談ですが、この Step Functions + state のテストの組み合わせは、Bedrock などの AWS API を手軽に試したいときに使いやすい手法だと感じています。
2. 検索部分の実装
実装といってもブロックを配置するだけです。
ここでは、Map ステートと、Bedrock Runtime Agents: Retrieve のタスクを組み合わせて使用していきます。
Map ステートを用いるのは、Cohere Command R+ が複数のクエリを生成する場合があるためです。
2-1 Map ステート
まずは Map ステートの設定です。
Provide a path to items array に $.result_one.search_queries を設定します。これは、result_one に格納した前のステートの実行結果 (つまり、生成された検索クエリ) に対して Map を行うという意味です。
(Step Functions でいう Map ステートはプログラミング言語でよく実装されている map のイメージです。Array の要素それぞれに対して処理を行います。)
Modify items with ItemSelector には
{
"search_query.$": "$$.Map.Item.Value",
"KnowledgeBaseId.$": "$.KnowledgeBaseId"
}
を設定します。ここは少し複雑なのですが、search_query には Map で入ってくる要素(=生成されたクエリ)を、KnowledgeBaseId には実行時のユーザー入力の KnowledgeBaseId を参照します。
つまり、このワークフローは、1. 検索クエリの生成で説明した内容に加えて、
{
"user_prompt": "Amazon Bedrock とは何ですか?"
"KnowledgeBaseId": "ABCDEFGH"
}
のような JSON を期待します。

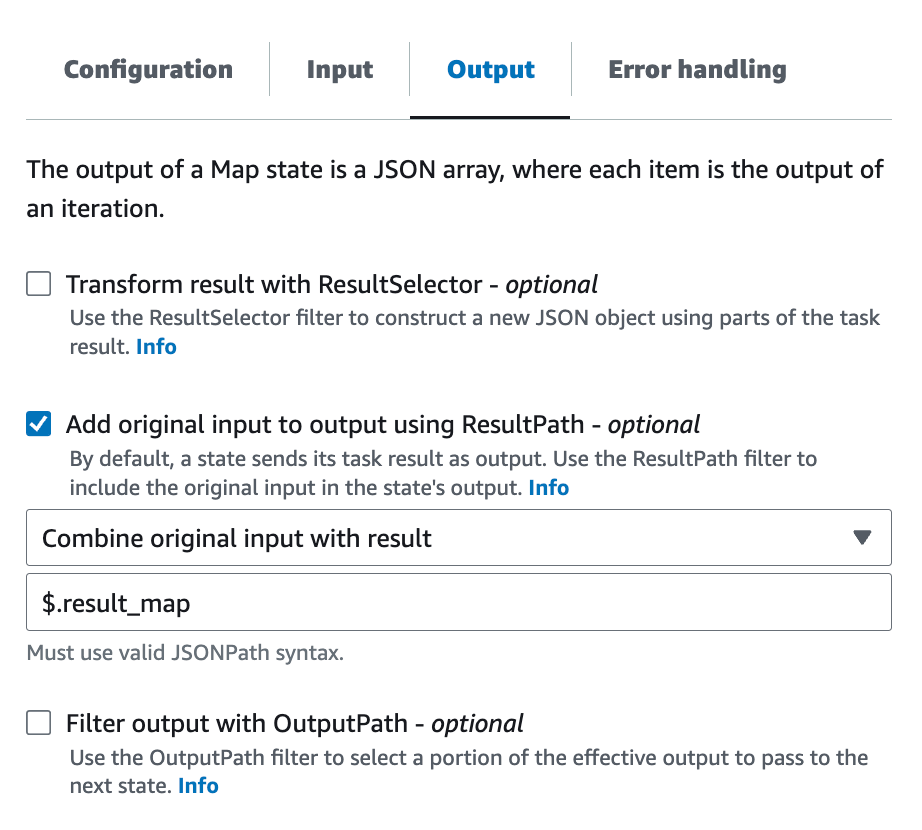
次に、Map としての Output を設定します。
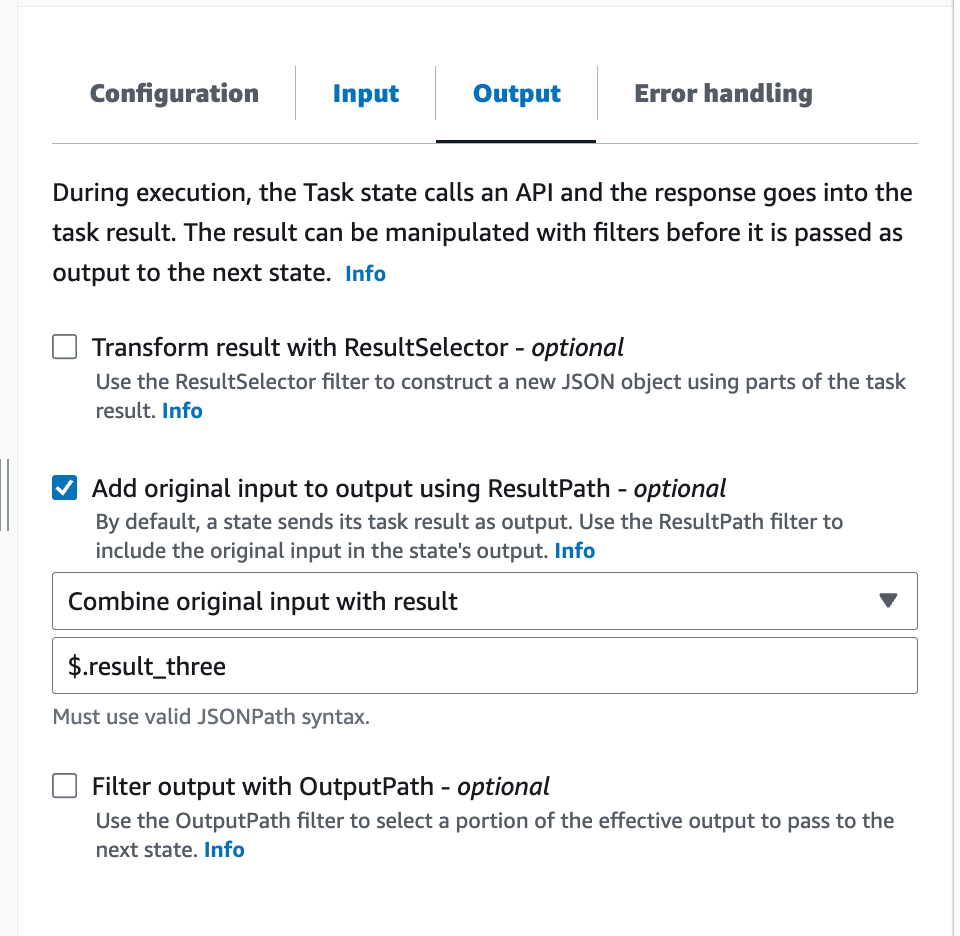
ここでは単に、以前の結果を残しながら今回の結果も JSON に追加したいので、Add original input to output using ResultPath だけを設定します。値は $.result_map としておきます。
2-2 Retrieve
次に、Retrieve の設定を行います。
Bedrock Runtime Agents: Retrieve のタスクを選択し、Map ステートの内側に配置します。

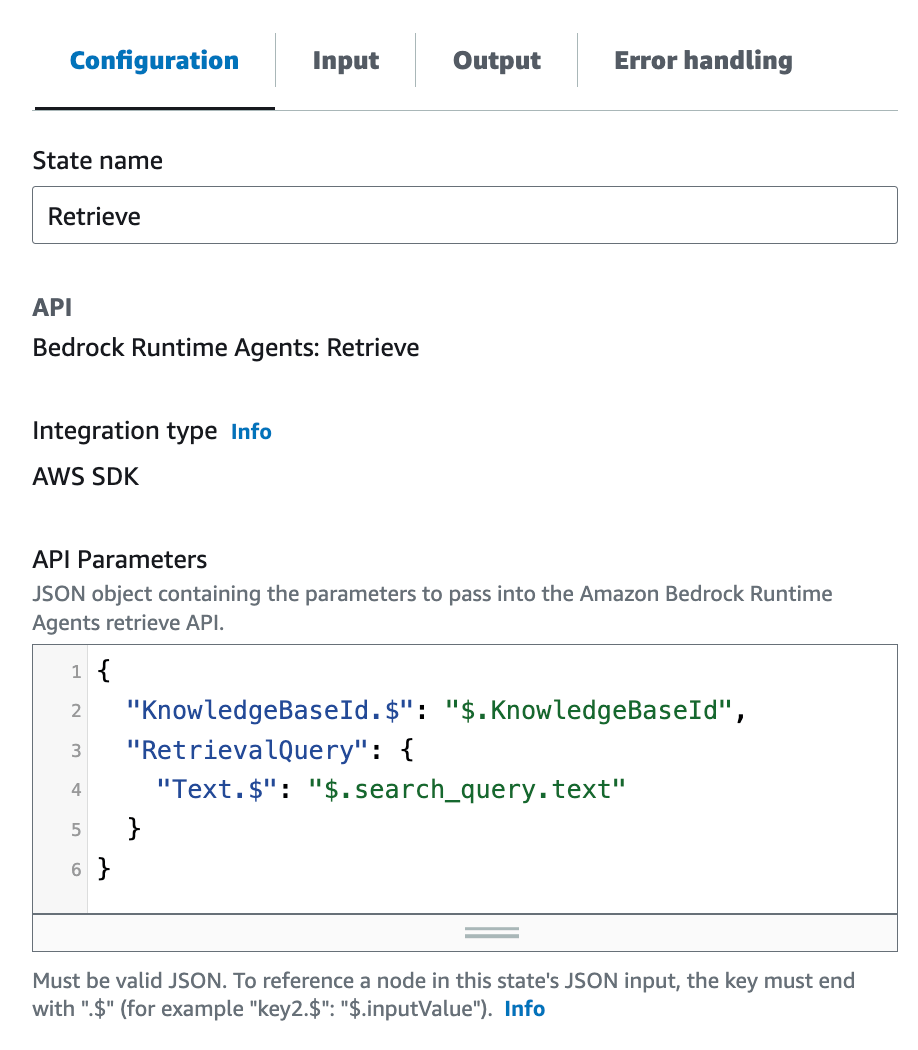
Retrieve タスクの設定を行います。
API Parameters に
{
"KnowledgeBaseId.$": "$.KnowledgeBaseId",
"RetrievalQuery": {
"Text.$": "$.search_query.text"
}
}
と設定します。
これで、KnowledgeBase の ID と、検索クエリが設定できます。基本的に Map ステートから引っ張ってきた値を、API リクエストの形に合うように再配置しているだけです。
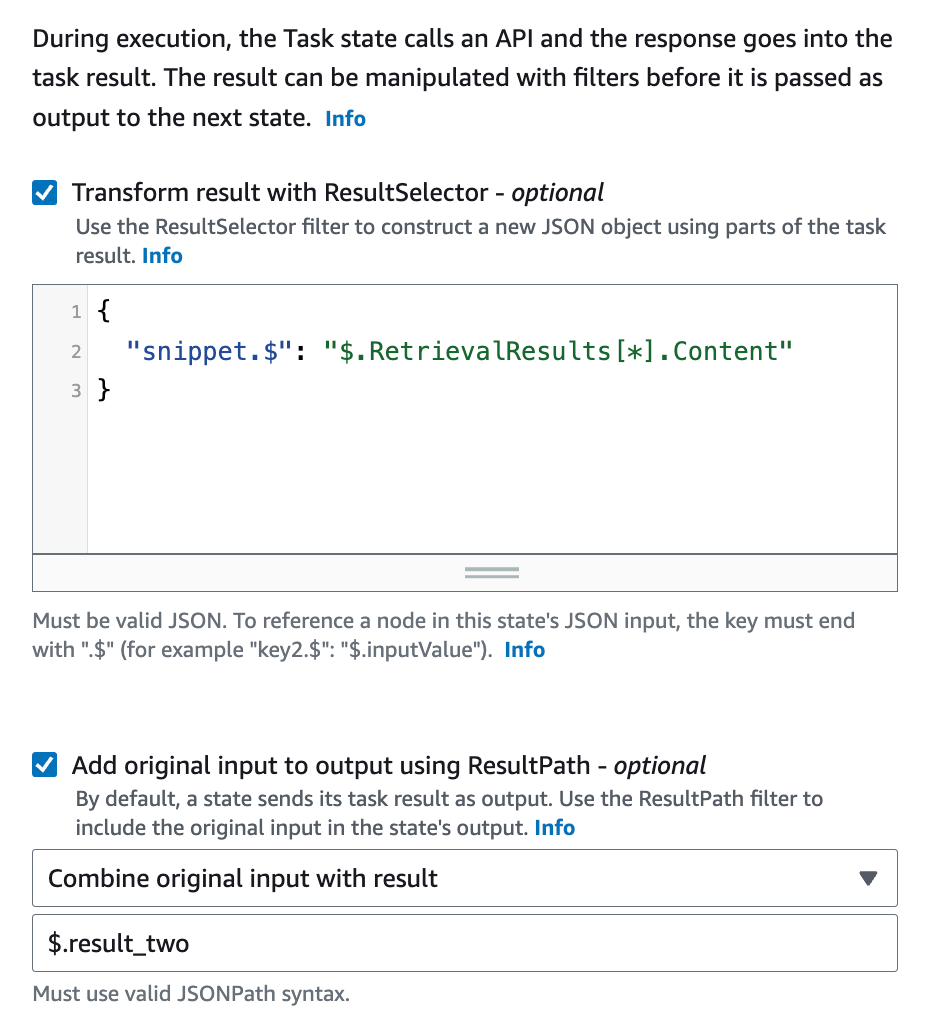
Output も設定します。
Transform result with ResultSelector で、API からのレスポンスを加工します。
{
"documents.$": "$.RetrievalResults[*].Content"
}
この [*] は新登場ですが、配列の全ての要素にアクセスすることを示します。つまり、RetrievalResults は Object の Array(配列)なので、その全てに対して Content というキーでアクセスしています。
そしていつも通り Add original input to output using ResultPath を Combine original input with result として、$.result_two を入力します。以前のステートの結果を破棄しないためです。
3. ドキュメントをもとに質問する
最初と同様、Bedrock: InvokeModel を配置して、モデルに cohere.command-r-plus-v1:0 を選択します。
Bedrock Model Parameters には、以下のように設定します。
{
"message.$": "$.user_prompt",
"documents.$": "$.result_map[*].result_two.documents[*]"
}
message には最初のユーザーの入力をそのまま渡します。さらに、documents として、先ほど取得したコンテンツを Cohere Command R+ に渡してみます。
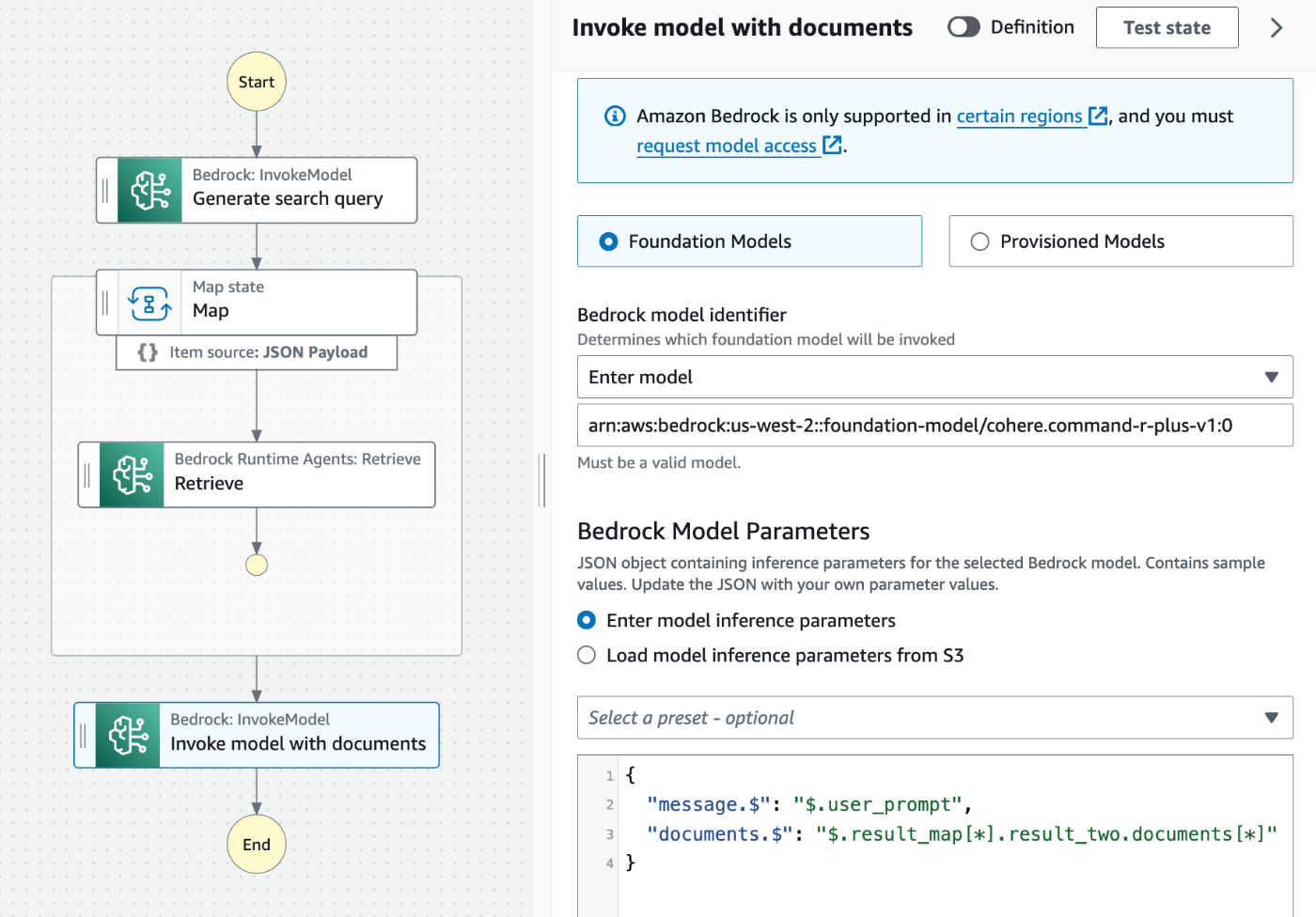
RAGの実行
IAM の設定
ワークフローを初めて保存するときにこんな表示が出ます。

ここでは、ワークフローの内容から IAM ロールを自動作成してくれるのですが、Amazon Bedrock Runtime Agents は SDK 統合[1]という仕組みで呼び出しており、自動で権限が付与されません。
この画面で一度 Confirm を押した後、IAM の画面に移動して、IAM ロールを編集します。最初に作成された時は画面上部に以下のような表示が出るので、このボタンで遷移すると便利です。

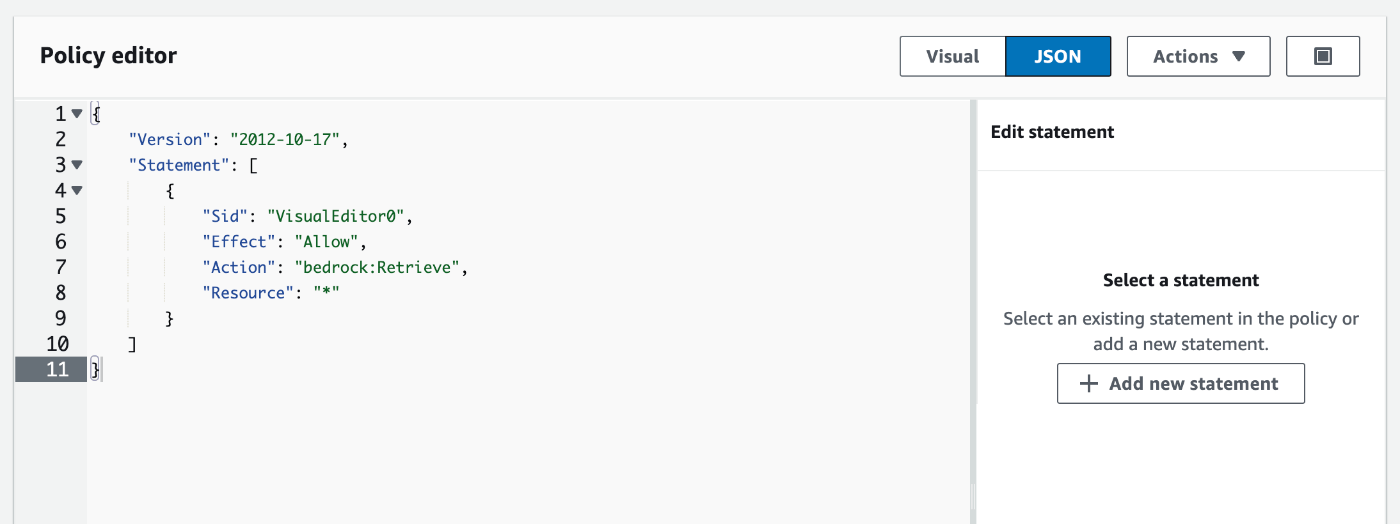
IAM ロールの画面に遷移したら、Add permissions から Create Inline Policy を選択します。

JSON view に切り替えて、以下のポリシーを貼り付けます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "bedrock:Retrieve",
"Resource": "*"
}
]
}
いざ実行!
ワークフローを保存し、ステートマシンの画面に戻ったら、Start execution をクリックします。

input に以下のような値を入れます。
{
"user_prompt": "Amazon Bedrock クライアントを使用して利用可能な基盤モデルを一覧表示する方法を教えてください。",
"KnowledgeBaseId": "ABCDEFGH"
}

Start execution をクリックします。
Execution input and outputを確認すると、RAG が実行されていることがわかります!
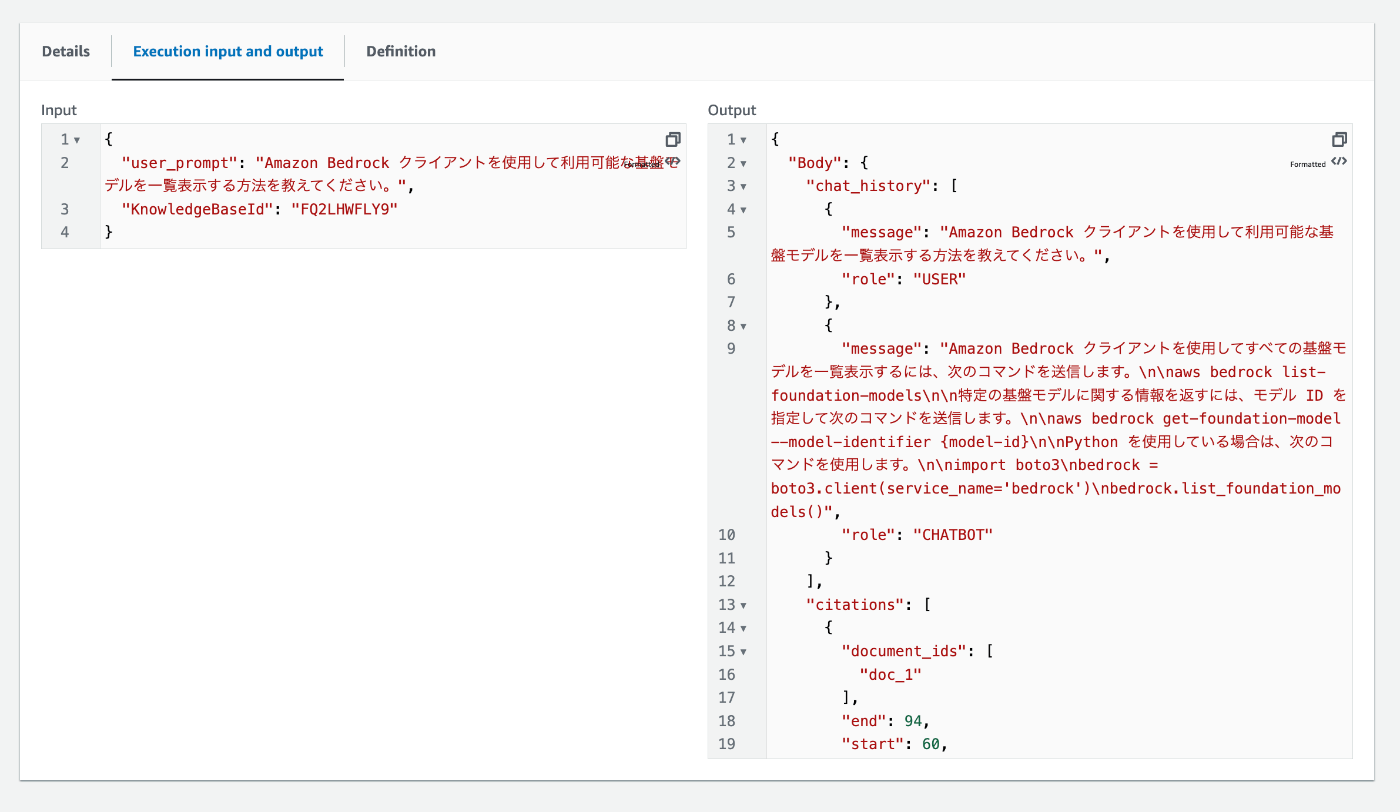
(今回は、https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/what-is-bedrock.html の PDF 版を Bedrock Knowledge Base に読み込ませています。)
さらに細かく、どういったクエリが生成されたのか、どういったデータが取得されたのかなどはEvents を読むことで確認できます。

こんなクエリが生成されていた
また、最後のステートでもしっかり Output を設定してあげることで、生成されたクエリや取得されたデータなどを最終結果に残しておくことも可能です。
まとめ
今回は RAG の実装を通じて、AWS Step Functions の魅力を伝えつつ、Amazon Bedrock で利用できる新しいモデルである Cohere Command R+ を紹介しました。
70 行程の ASL で RAG システム全体が構築されるのは、ノーコードという縛りを抜きにしてもかなり短く書けているのではないでしょうか?
完成した ASL はシンプルなものですが、拡張していくことで実用することも可能です。
例えば:
- API Gateway に接続してフロントエンドから呼び出せるようにする
- Step Functions は Lambda などを介さず、直接 API Gateway と接続できます!
- Web 検索の API を呼び出すステートを追加して、Webからの情報を参照できるようにする
- KnowledgeBaseId が渡されなかった時は Web を見に行く
- KnowledgeBase の検索結果の Score が低かった場合、 Web にも情報を取りに行く
などの発展系が考えられます。
ぜひ RAG 以外でも Step Functions を活用してみてください!
途中から滲み出ていましたが、RAG をネタにして Step Functions のことを知ってもらおうという記事でした
-
Step Functions から AWS API を呼び出すには、SDK 統合と最適化統合があります。SDK 統合はほとんどの AWS API をサポートしますが、最適化統合は一部の AWS API のみをサポートします。代わりに最適化統合は各サービスのユースケースに合わせて仕様が最適化されており非常に便利です。https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/connect-to-services.html ↩︎
Discussion