Claude + MCP でBigQueryのデータをあれこれ
0. 対象読者
「MCP触ってみよう」っていうPythonユーザ
1. はじめに
こんにちは!なおずみです!
今回は最近話題のMCPについて触ってみようってことで、Claudeとfastapiでbigqueryのデータをあれこれしたいと思います。
2. 今回やること
今回のスコープは以下の通り
- claude desktop
- fastapi-mcp
- poetry
- Docker
- pytest
3. 前提
- 開発環境はMac
- Docker入ってること
- poetry入ってること
- uv入ってること
- Claude Desktop入ってること(無料プランで大丈夫)
4. poetryで新しくプロジェクトの作成
以下コマンドで、プロジェクトを作る
poetry new fast_api
5. 必要なものを追加していく
poetry add fastapi-mcp
poetry add google-cloud-bigquery
6. fastapiファイルの作成
fastapiで以下のようにmcpサーバを立ち上げる
ほとんどHugging Faceのまんまだが、Dockerで動かすので、uvicorn.run()とかは省いとく(重複実行になってまうため)
from fastapi import FastAPI
from fastapi_mcp import FastApiMCP
# Your existing FastAPI application
app = FastAPI()
# Define your endpoints as you normally would
@app.get("/items/{item_id}", operation_id="get_item")
async def read_item(item_id: int):
return {"item_id": item_id, "name": f"Item {item_id}"}
# Add the MCP server to your FastAPI app
mcp = FastApiMCP(
app,
name="My API MCP", # Name for your MCP server
description="MCP server for my API", # Description
base_url="http://localhost:8000", # Where your API is running
describe_all_responses=True, # Describe all responses
describe_full_response_schema=True # Describe full response schema
)
# Mount the MCP server to your FastAPI app
mcp.mount()
7. Dockerで立ち上げる
以下のようにDockerfileを記述する
FROM public.ecr.aws/docker/library/python:3.13.0-slim-bookworm
WORKDIR /app
COPY pyproject.toml poetry.lock ./
ENV POETRY_REQUESTS_TIMEOUT=10800
RUN python -m pip install --upgrade pip && \
pip install poetry --no-cache-dir && \
poetry config virtualenvs.create false && \
poetry install --no-interaction --no-ansi --no-root && \
poetry cache clear --all pypi
COPY src /app/src
EXPOSE 8000
CMD ["poetry", "run", "uvicorn", "src.fast_api.server:app", "--host", "0.0.0.0", "--port", "8000"]
コマンド叩く
docker build -t fastapi .
docker run -p 8000:8000 fastapi
以下URLにアクセスして動作確認→よさそ〜
http://localhost:8000/docs

8. mcpのプロキシを立ち上げる
ターミナルで以下のコマンド叩く
uv tool install mcp-proxy
9. Claude Desktopの設定ファイルに立ち上げたプロキシを登録する
Claude Desktopで、設定>開発者から、claude_desktop_config.jsonファイルに以下のように追記する
※ commandのところは、which mcp-proxyで探して、絶対パスで指定する
{
"mcpServers": {
"my-api-mcp-proxy": {
"command": "/Users/naozumi/.local/bin/mcp-proxy",
"args": ["http://127.0.0.1:8000/mcp"]
}
}
}
うまくいくと以下のようになる
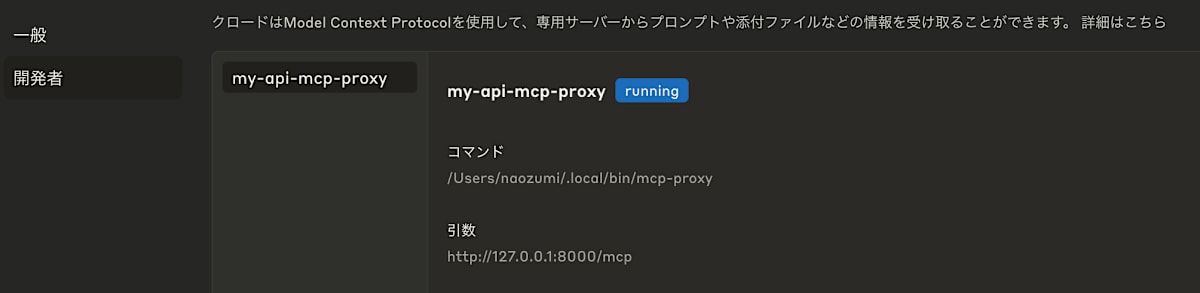
10. 動作確認
Claude Desktopを開いて、チャット中央のトンカチのアイコンに利用できるmcpサーバが追加されていることを確認

それっぽい質問を投げて動作確認する

いい感じ!以上でMCP使うまでの設定はおしまい!
11. BQでサービスアカウントを作成
サービスアカウントを作成し、以下の権限を付与する
- BigQuery ジョブユーザー
- BigQuery データ閲覧者
キーを発行してfastapiから繋がるようにする
12. bqにアクセスできるようにserver.pyを書き換える
データを探すとこからできるようにしたいので、以下の5つのメソッドに書き換える
- プロジェクトリストの取得
- データセットリストの取得
- テーブルリストの取得
- テーブルのスキーマの取得
- クエリを流してデータの取得(一応データにupdateとかdeleteとかdropとか、物騒なものが含まれていないことをチェックしておく)
from fastapi import FastAPI
from fastapi_mcp import FastApiMCP
from google.cloud import bigquery
# Your existing FastAPI application
app = FastAPI()
# define your BigQuery client
client = bigquery.Client.from_service_account_json(
"/app/secrets/bq-sample-project-456713-ef11d647744f.json",
project="bq-sample-project-456713"
)
# Define your endpoints as you normally would
@app.get("/get_data_from_bigquery/{query}", operation_id="get_data_from_bigquery")
async def get_data_from_bigquery(query: str):
# Comfirm the query is safe to execute
if "DROP" in query or "DELETE" in query or "UPDATE" in query:
return {"error": "Unsafe query detected. Query execution aborted."}
# Execute the query
query_job = client.query(query)
# Wait for the job to complete
results = query_job.result()
# Process the results
print(f"Query results: {results}")
return {"query_results": [dict(row) for row in results]}
@app.get("/get_project_list_from_bigquery", operation_id="get_project_list_from_bigquery")
async def get_project_list_from_bigquery():
# Get the list of projects
projects = client.list_projects()
# Process the projects
project_list = [project.project_id for project in projects]
return {"projects": project_list}
@app.get("/get_dataset_list_from_bigquery/{project_id}", operation_id="get_dataset_list_from_bigquery")
async def get_dataset_list_from_bigquery(project_id: str):
# Get the list of datasets for the given project
datasets = client.list_datasets(project=project_id)
# Process the datasets
dataset_list = [dataset.dataset_id for dataset in datasets]
return {"datasets": dataset_list}
@app.get("/get_table_list_from_bigquery/{project_id}/{dataset_id}", operation_id="get_table_list_from_bigquery")
async def get_table_list_from_bigquery(project_id: str, dataset_id: str):
# Get the list of tables for the given project and dataset
dataset_id = f"{project_id}.{dataset_id}"
tables = client.list_tables(dataset_id)
# Process the tables
table_list = [table.table_id for table in tables]
return {"tables": table_list}
@app.get("/get_table_schema_from_bigquery/{project_id}/{dataset_id}/{table_id}", operation_id="get_table_schema_from_bigquery")
async def get_table_schema_from_bigquery(project_id: str, dataset_id: str, table_id: str):
# Get the schema for the given project, dataset, and table
table_ref = client.dataset(dataset_id, project=project_id).table(table_id)
table = client.get_table(table_ref)
# Process the schema with datatypes
schema = {field.name: field.field_type for field in table.schema}
return {"schema": schema}
# Add the MCP server to your FastAPI app
mcp = FastApiMCP(
app,
name="My API MCP", # Name for your MCP server
description="MCP server for my API", # Description
base_url="http://localhost:8000", # Where your API is running
describe_all_responses=True, # Describe all responses
describe_full_response_schema=True # Describe full response schema
)
# Mount the MCP server to your FastAPI app
mcp.mount()
13. BQにサンプルデータを入れてみる
今回は、kaggleのチュートリアルで有名なタイタニック号のデータを入れてみる。(生存するかどうか予測するやつ)
(次回とかに、BigQuery MLとかで推論とかまで行けたら面白いだろうな〜っていう目論見込みで、、)
csvでデータ落とせるので、落としたやつをBQに突っ込むだけでとっても簡単!
13. Claude Desktopからデータを見てみる
いよいよ準備が整ったので、Claude Desktopを再起動して色々話してみる
ますは、データ探すとこから

BQから探してくれそうなのでお願いする

すごい、、指示してないけど、期待した順番(プロジェクト>データセット>テーブル>スキーマ)で絞り込んどる、、
おすすめされた、乗船クラスと生存率についてお願いしてみる。せっかくなのでグラフ付きで。

ほんとすごいな。。うまくいかんかったら、修正して再実行してくれてる。
最終的なクエリと結果は以下のような感じ
{
`query`: `SELECT Pclass, SUM(Survived) AS survived_count, COUNT(*) AS total_count FROM `bq-sample-project-456713.titanic.train` GROUP BY Pclass ORDER BY Pclass`
}
{
"query_results": [
{
"Pclass": 1,
"survived_count": 136,
"total_count": 216
},
{
"Pclass": 2,
"survived_count": 87,
"total_count": 184
},
{
"Pclass": 3,
"survived_count": 119,
"total_count": 491
}
]
}
グラフも書いてくれるらしい


おお〜、それっぽいグラフが書けた
1等客室の乗客は最も高い生存率(約63%)を示しました。
一方、3等客室の乗客の生存率は最も低く(約24%)となっています。
このデータは、タイタニック号沈没時の社会的地位と生存率の関連を示唆しています。
世知辛い分析だ。。
14. 次のステップ??
すごすぎて、このまま機械学習もいける??と思って、ダメもとで頼んでみるw

色々話してみたが、結論、流石に厳しかったかw
よし、BigQueryMLのmcp作るか〜
追記(20250426):上記やってみたのでこっちも覗いてもらえると!
まとめ
いかがだったでしょうか??
今回はMCP + ClaudeでBQのデータを触ってみましたが、ただただすごいな〜っていう感じでした。
ぶっちゃけ、今回の内容であれば、Gemini in Lookerとかの方がパフォーマンスは良さそうですねw
ただ、Lookerは結構コストかかったりするので、API利用とかだったら意外とありかも??
何にしろ、MCPのお試しとしてはとっても面白かったです!
簡単な機械学習まで出来たら面白いので、いい感じに出来たら続きを書くかもです〜
誰かの何かの参考になっていたら幸いです!
ソースコード載せとくので、よかったら覗いてください〜
(キーの中身は出鱈目なので、正しいキーにしてね〜)
Discussion