Closed5
CyberAgentLM2-7B-ChatをGoogle Colabでとりあえず動かす方法
model
リリース記事
ランタイムをGPUにする
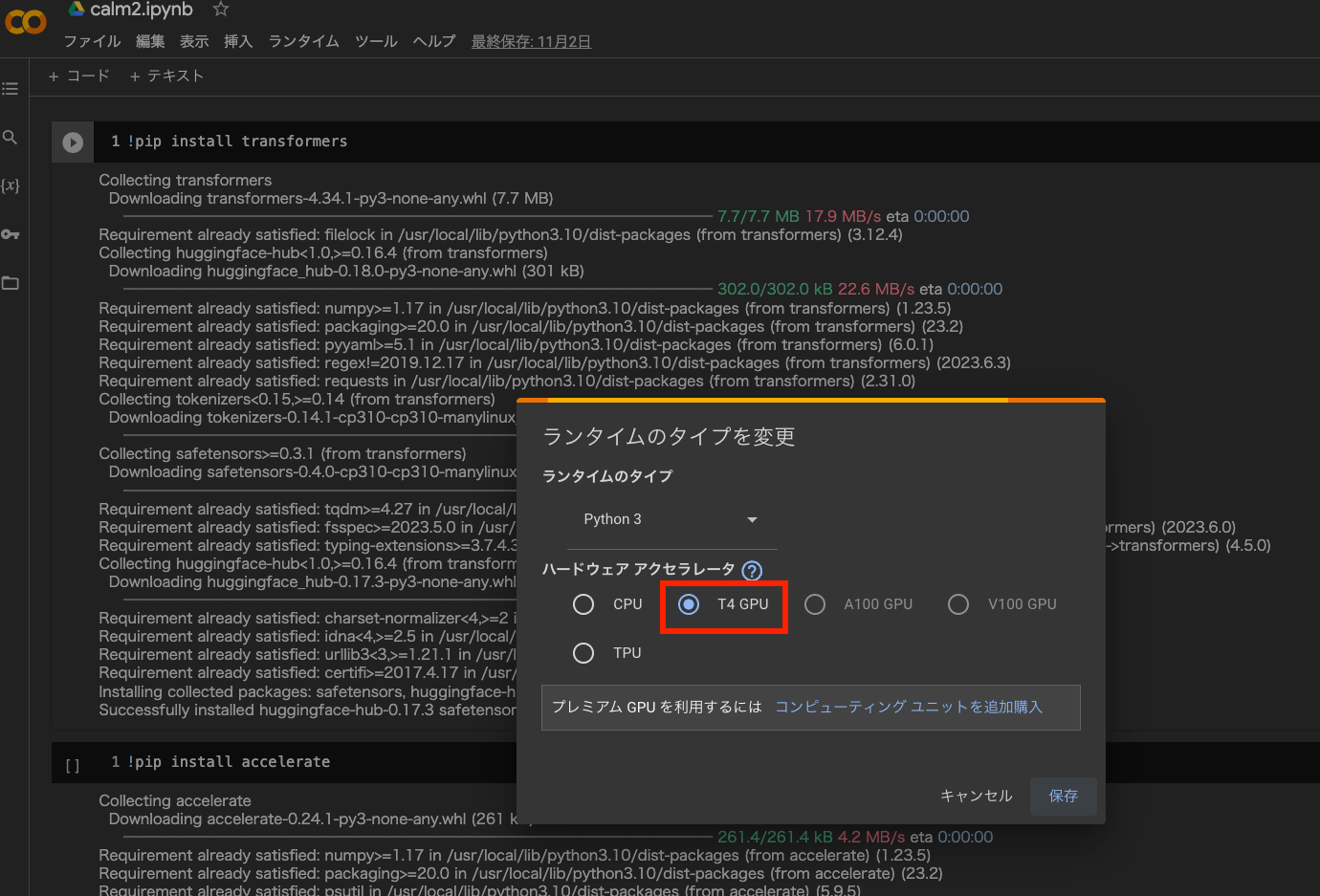
Google Colab > ランタイム > ランタイムのタイプを変更 > T4 GPUを選択。
デフォルトではCPUが選択されており、CPUだとmodelの読み込みでエラーになる。
基本ライブラリをinstall
!pip install transformers
- google colabではコマンド実行するときに先頭に「!」をつける
- transfomersのinstall
!pip install accelerate
- accelerateのinstall
あとはhugging faceのコードを貼り付ければ良い。
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
assert transformers.__version__ >= "4.34.1"
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = """USER: AIによって私達の暮らしはどのように変わりますか?
ASSISTANT: """
token_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(
input_ids=token_ids.to(model.device),
max_new_tokens=300,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
Google colabにはおそらく使用メモリの制限があり、promptが長くなるとout of memoryになる。自分の場合はgoogle colab無課金ユーザーなのでそこまでメモリが割り当てられていないと予想。
このスクラップは2023/11/03にクローズされました