[Firebase] FirestoreのみでorderByが使える全文検索
はじめに
結.JAPANでnicodyという旅行計画アプリのiOSアプリとFirebaseによるサーバーサイドの開発を行なっている者です。
インデックス付与による高速クエリ処理が特徴的な一方でクエリの制約が多めなFirestoreですが、最近では様々な機能のプレビューが公開され少しずつ応用の幅が広がってきました!(特にベクトル検索はアツい)
ところで弊社では、これまでFirestoreで文字列の全文検索をするためにtokenMapを用いた検索方法を使用してきたのですが、公開されたプレビューの機能のうちの複数のフィールドに対する不等号フィルタの使用が可能になったことで、orderByが併用できる全文検索が可能になったのでこの記事にまとめます。
(※tokenMapについての参考を記事最後に記載)
要件・仕様
この記事で用いる仕様例について記載します。
- ユーザが入力したキーワードによって検索対象のコレクション(以下、"コレクションA"とします)の
nameフィールドを全文検索する - 検索結果をお気に入り数
favoriteCountで降順に並び替える
全文検索の方法
1. サブコレクションの作成
コレクションAのドキュメントの下にサブコレクションを生成していきます。フィールドはnameと検索優先度を表すpriorityで、nameはドキュメント.nameを先頭から順に一文字ずつ削除した値にします。ドキュメント数はドキュメント.nameの長さと同じになります。
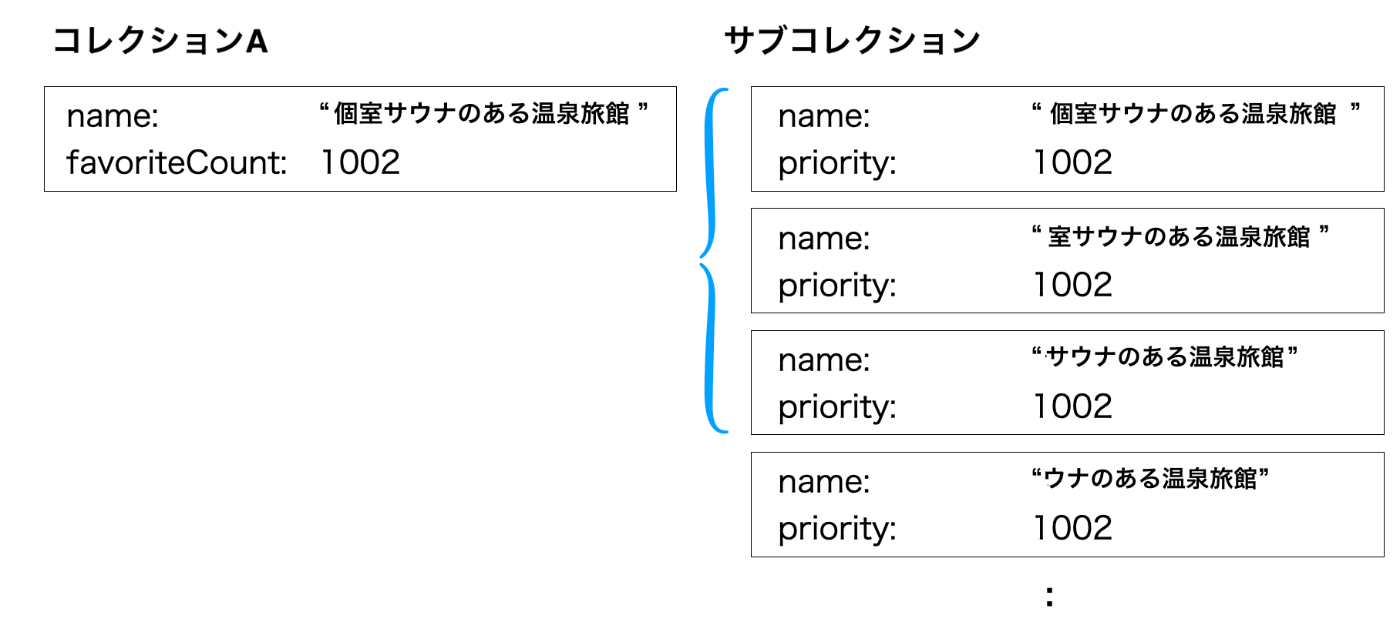
2. 検索
下記のようなコレクショングループのクエリで検索が可能です。("サウナ"の検索例)
※インデックスの生成が必要になるので、初回発生時のエラーのURLからインデックスを生成してください。
db.collectionGroup('サブコレクション')
.where('name', '>=', 'サウナ')
.where('name', '<', 'サウナ\uf8ff')
.orderBy('priority', 'desc')
.get()
.then((querySnapshot) => {
// ...
});
メリット・デメリット
この検索方法において個人的に考えるメリット・デメリットを一覧でまとめます!
- メリット
- 全文検索ができる
- orderByが使える
- 一回のクエリで検索できる
- OR検索が可能
- 前方一致検索に基づく方法のため、結果の重複がしにくい
- デメリット
- ドキュメント数が大きく増大する
- それぞれname長分のドキュメントが増えるため
- 親(コレクションA)のドキュメントの状況(例ではfavoriteCount)の伝播が大変
- 例えば、priorityの初期値はfavoriteCountを使用し運用は別管理、などの工夫も良いかと思います
- AND検索は困難
- 不可能ではないですが、処理速度を考慮するとこちらは従来通りにtokenMapを用いた検索方法で良いかもしれません
- ドキュメント数が大きく増大する
おわりに
最後に少しnicodyの宣伝をさせていただきます。
nicodyは、旅行に行く友達やカップル、同僚、家族などと一緒に旅のしおりが作れるアプリです!
共同編集が可能なので重要な点として、旅行計画における幹事さんの負担が減ります!しおりを旅行前に綿密に組むも良し、ざっくり計画して宿で翌日の計画を決めていくのも良し
ほか、例えば"旅行の思い出が写真だけだと勿体無い"や"学生時代の旅行のしおりのようなものを手軽に作りたい"と思われる方にもおすすめです!

参考: tokenMapについて
tokenMapは、firestoreで擬似的な全文検索を実現するために用いられる手法です。手法概要としては、検索される/する文字列を2文字ずつで区切ったtokenを生成しそれぞれのtokenの一致を見るものとなっております(bi-gramと呼ばれる)。
例えば 個室サウナのある温泉旅館 という文字列に対して サウナ の検索をヒットさせたいとします。それぞれを2文字ずつで区切ると、
"東京ディズニーランド" → ["個室", "室サ", "サウ", "ウナ", "ナの", "のあ", "ある", "る温", "温泉", "泉旅", "旅館"]
"サウナ" → ["サウ", "ウナ"]
となり、今回は "サウナ" のtokenを全て含んでいる "個室サウナのある温泉旅館" を部分一致として引っ張ってきたいということになります。
ただ、"tokenを全て含んでいる"ことを確認するためには "個室サウナのある温泉旅館" のtokenの配列に対し、 array-contains のフィルタを複数掛ける必要性があります。しかし、Firestoreのクエリではarray-contains を使えるのは一度だけという制約があります。
この問題を解決するためにtokenの配列を辞書型に変換したのがtokenMapです。配列の値を辞書型のキーとし、値はなんでもいいので同じ値を設定します(trueがよく用いられる)。これにより検索はarray-containsではなく、 tokenMap.<token> = true の等号検索のみで書けるようになり、クエリ制約を満たせます。
tokenMap = {
"個室": true, "室サ": true, "サウ": true, "ウナ": true, "ナの": true, "のあ": true, "ある": true, "る温": true, "温泉": true, "泉旅": true, "旅館": true,
}
// Before (配列tokensによる検索)
query
.where("tokens", "array-contains", "サウ")
.where("tokens", "array-contains", "ウナ") // ここで制約にかかる
// After (辞書tokenMapによる検索)
query
.where("token.サウ", "=", true)
.where("token.ウナ", "=", true) // 最後まで行ける!
(参考: Firestore だけで Algolia を使わず全文検索 - Qiita)
問題点
が、この手法には色々な問題点があります。特に今回の話で問題になるのが、orderByが出来ないことです。つまり、検索結果をお気に入り数や生成日時などで並び替えできないということになります。
これはfirestoreのクエリにインデックスが必須であることが関係しています。例えば、 "サウナ" というワード検索とお気に入り数 favoriteCount による並び替えをクエリとして通すためには、 tokenMap.サウ、tokenMap.ウナ、favoriteCount のキーに基づくインデックスを生成しなくてはいけません。もちろん、生成すると "サウナ" の検索は通るようになります。
「ではそれでいいのでは?」と思うかもしれません。しかし、次に "サウナー" で検索しようとした場合今度は tokenMap.サウ、tokenMap.ウナ、tokenMap.ナー、favoriteCount のインデックスを生成しなくてはいけません。つまり検索キーワード毎にインデックス生成をする必要があり、実質対応不可能となります。
 (※添付画像はイメージです)
(※添付画像はイメージです)
この問題に対する一番シンプルな解決方法はその並び替えをクライアント側でやってしまうことですが、検索結果が1,000や10,000件を超える場合はこちらも現実的ではありません。
Discussion