No.6 (1)機械学習の基礎 - ⅹ.検証集合
全体の流れ:なぜデータを分割する必要があるのか?
機械学習の最終目標は、未知のデータに対して高い性能を発揮するモデル(=汎化性能の高いモデル)を作ることです。
もし、手元にある全てのデータを使ってモデルを学習させ、その同じデータで性能を評価してしまうとどうなるでしょうか?
答えは、モデルの本当の実力を測ることができません。
特に過学習(Overfitting)したモデルは、学習に使ったデータ(カンニングペーパー)に対しては満点を取りますが、初見の問題(未知のデータ)は全く解けません。
この問題を解決するために、手元のデータを**「訓練データ」「検証データ」「テストデータ」**の3つに分割して、それぞれの役割分担を明確にするのです。
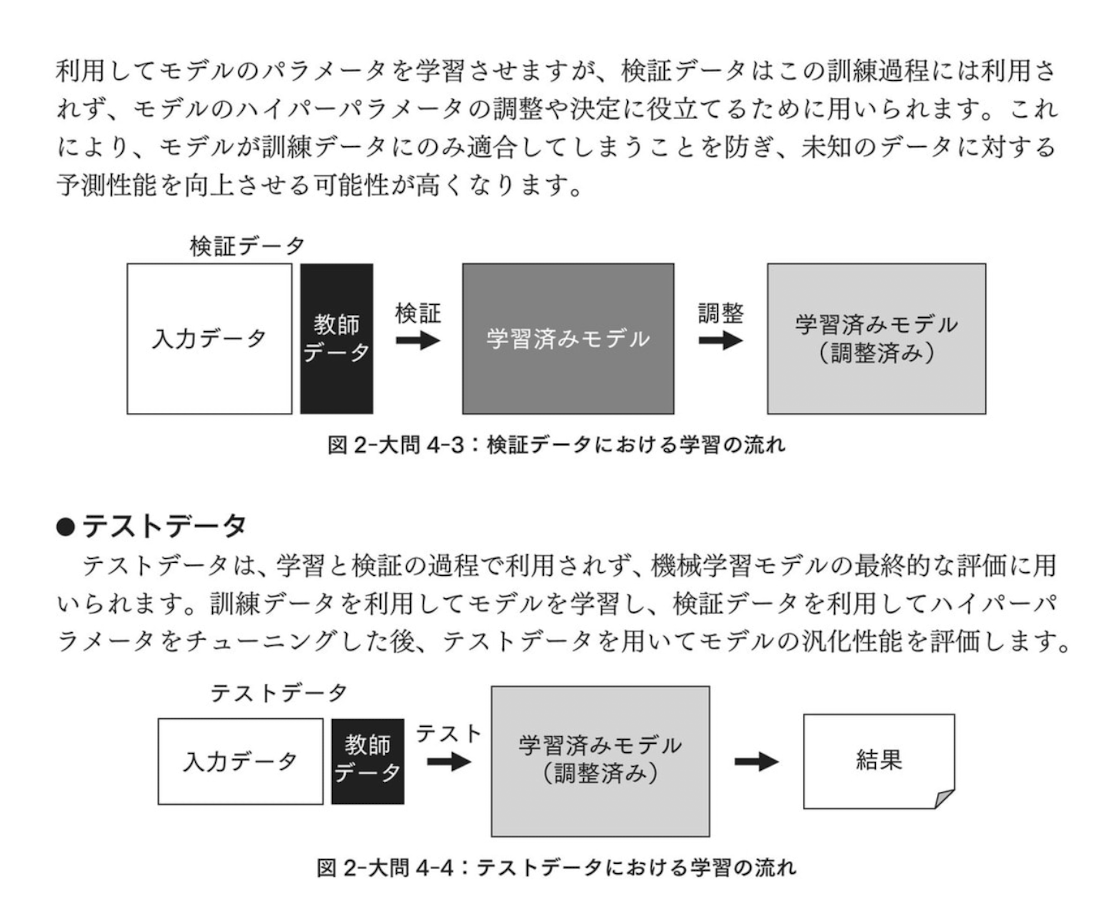
各データの役割と使い方
通常、手元のデータセットは以下のように分割して使います。(比率は例:60% / 20% / 20%など)

訓練誤差と汎化誤差
-
訓練誤差 (Training Error):
- 訓練データに対するモデルの誤差。
- この誤差が低いことは、モデルが少なくとも学習データを表現できていることを意味しますが、それだけでは良いモデルとは言えません。
-
汎化誤差 (Generalization Error):
- 未知のデータに対するモデルの誤差の期待値。
- 私たちが本当に小さくしたいのはこの誤差です。
- しかし、真の汎化誤差は計算できないため、代わりにテストデータに対する誤差(テスト誤差)をその推定値として用います。
E資格対策のポイント
-
各データの役割を正確に覚える:
- 訓練データ → パラメータ学習
- 検証データ → ハイパーパラメータ調整、モデル選択
- テストデータ → 最終的な汎化性能の評価
- なぜ分割が必要かを理解する: 過学習したモデルを正しく評価し、真の汎化性能を測定するため。
- テストデータの扱いに注意: テストデータは「最後の最後まで使わない、神聖なデータ」と覚えること。テストデータを使ってハイパーパラメータを調整するような選択肢は間違いです。
- 交差検証 (Cross Validation): 左の「x. 検証集合」は交差検証を指している可能性があります。これはデータが少ない場合に、データを複数に分割し、訓練データと検証データの役割を入れ替えながら複数回評価を行う手法です。これにより、データの分割方法に依存しない、より頑健なモデル評価が可能になります。特に「k-分割交差検証」は必須知識です。
これらの関係性を理解していれば、モデル評価に関するE資格の問題には自信を持って対応できるはずです。



交差検証(Cross-Validation)応用
そもそも、なぜ「交差検証」が必要なの?
まず、大前提からお話しします。
機械学習モデルを作ったら、そのモデルがどれくらい賢いか(性能が良いか)をテストする必要があります。
一番シンプルな方法は、持っているデータ(例:1000件の画像データ)を「訓練用データ(800件)」と「テスト用データ(200件)」に分けることです。
モデルは訓練用データだけを見て学習し、一度も見たことがないテスト用データで実力を試されます。
しかし、この方法には**「たまたま」**という運の要素が絡みます。
- たまたま簡単な問題ばかりがテスト用データに入って、実力以上に良い点数が出てしまう。
- たまたま難しい問題ばかりがテスト用データに入って、実力以上に悪い点数が出てしまう。
これでは、モデルの本当の実力を正しく評価できません。この「たまたま」をなくし、もっと信頼できる評価をするための方法が交差検証です。
1. K分割交差検証 (K-fold cross-validation)
画像の一番最初に説明されている、基本のテクニックです。
考え方: 「テストを1回だけじゃなくて、何回か違う問題でやって平均点を取れば、もっと信頼できるよね!」という考え方です。
やり方:
- データをK個のグループ(ブロック)に分割します。(よくK=5やK=10が使われます)
- そのうちの1グループを「テスト用」、残りの(K-1)グループを「訓練用」としてモデルを学習させ、性能を評価します。
- 次に、別のグループを「テスト用」にして、同じことを繰り返します。
- これを全グループが1回ずつテスト用になるまで、K回繰り返します。
- 最後に出てきたK個の評価スコアを平均して、最終的なモデルの性能とします。
メリット:
- 全てのデータを訓練とテストの両方に使うことができる。
- データの分割の仕方による「運」の影響を減らし、より安定した評価ができる。
2. 層化K分割交差検証 (Stratified K-fold cross-validation)
ここからが画像の本題です。これが「正解」と書かれている選択肢ですね。
問題点:
普通のK分割交差検証は、分類問題(例:犬と猫の画像を分類する)で、データの偏りがあると問題が起きることがあります。
例えば、データ全体で「犬: 90枚, 猫: 10枚」のように、クラスの割合が不均衡(偏っている)な場合を考えてみましょう。
運悪く、あるグループに「猫」の画像が1枚も入らなかったらどうなるでしょう?
その回では、モデルは「猫」という存在を全く学習しないまま、テストに臨むことになります。これでは正しい評価はできません。
解決策(層化K分割):
「各グループを作るときに、元のデータのクラスの割合を保つように賢く分けよう!」というのが層化K分割です。
やり方:
上の例(犬90枚、猫10枚)で5分割する場合、
- 普通のK分割 → あるグループは犬20枚、猫0枚になるかもしれない。
- 層化K分割 → 全てのグループが「犬18枚、猫2枚」という構成になるように分割します。
これにより、どのグループでテストしても、必ず同じ割合で各クラスの問題を解くことになるため、分類問題、特にデータが不均衡な場合に非常に有効です。
3. その他の選択肢(画像の下半分)
画像では、比較対象として他の手法も紹介されています。これらもE資格では重要な知識です。
group k-fold CV
-
どんな時に使う?
- データに「グループ」の概念があるとき。例えば、「同じ患者さんから複数回撮った検査データ」や「同じ人物が写っている複数の写真」など。
-
考え方:
- 普通のK分割だと、同じ患者さんのデータが訓練用とテスト用の両方に分かれて入ってしまう可能性があります。すると、モデルは「この患者さんの特徴」を覚えてしまい、未知の患者さんに対する性能(本当に知りたい性能)を正しく評価できません。
- これを防ぐため、グループ単位で分割します。「Aさんのデータは全部訓練用」「Bさんのデータは全部テスト用」というように、同じグループのデータが訓練とテストにまたがらないようにします。
leave-one-out (LOOCV)
-
どんな時に使う?
- データが非常に少ないとき。
-
考え方:
- K分割交差検証の究極の形です。データがN個あるとしたら、N分割します。
- つまり、「1個だけをテスト用、残りの(N-1)個を訓練用」として、これをデータの個数分(N回)繰り返します。
-
デメリット:
- データの個数分だけ学習と評価を繰り返すので、計算コストが非常に高くなります。データが多い場合は現実的ではありません。
bootstrap (ブートストラップ法)
-
どんな時に使う?
- モデルの評価だけでなく、複数のモデルを作って性能を上げる「アンサンブル学習(バギングなど)」でよく使われます。
-
考え方:
- 元のデータセットから、重複を許して(復元抽出と言います)ランダムにデータを選び、新しい訓練データセットを作ります。
- (例)[A, B, C, D]というデータがあったら、[A, B, B, D]のようなデータセットを作るイメージです。
- これを何度も繰り返して、複数の異なる訓練データセットを作り出します。
まとめ
| 手法名 | キーワード・考え方 | 主な使い所 |
|---|---|---|
| K分割交差検証 | データをK個に分け、順番にテストしていく。評価の安定性を高める基本。 | 回帰、分類など、一般的なモデル評価。 |
| 層化K分割交差検証 | クラスの割合を保ったまま分割する。 | 分類問題。特にクラスの数が不均衡な場合。 |
| Group K-fold CV | グループが訓練とテストにまたがらないように分割する。 | 患者データなど、データにグループ構造がある場合。 |
| Leave-One-Out CV | 1個だけをテスト用にする。K分割の究極形。 | データセットが非常に小さい場合。 |
| Bootstrap | 重複を許してデータをサンプリングする。 | アンサンブル学習(ランダムフォレストなど)。 |
この画像が伝えたかったことは、「分類タスクでは、単純なK分割ではなく、クラスの割合を考慮した**層化K分割交差検証(stratified k-fold)**を使うのが望ましい」ということです。
これらの知識はE資格の試験だけでなく、実務でも非常に役立ちます。頑張ってください!