Raspberry Pi Pico (RP2040) のSPIマスタ/スレーブ検証
RP2040 で SPI のマスタとスレーブの通信について検証したのでわかったことをまとめておく。
前提条件
- ボード: Raspberry Pi Pico
- フレームワーク: arduino-pico v3.6.0 (earlephilhower版Arduinoライブラリ)
サンプルプログラムと結線
この項目は先駆者の検証を参考にした。
RP2040 は SPI バスを2系統、さらにコアも2つ持っているのでそれぞれにマスタとスレーブに担わせることで1台のみで検証ができる。arduino-pico にある SPItoMyself というサンプルプログラムがあるのでそれを実行する。
このサンプルプログラムではクロック周波数 1MHz、ビットオーダーは MSBFIRST、SPIモードは 0 (CPOL=0, CPHA=0 つまり CK の立ち上がりエッジでラッチ、立ち下がりでシフト[1])である。以降、これを前提として進める。
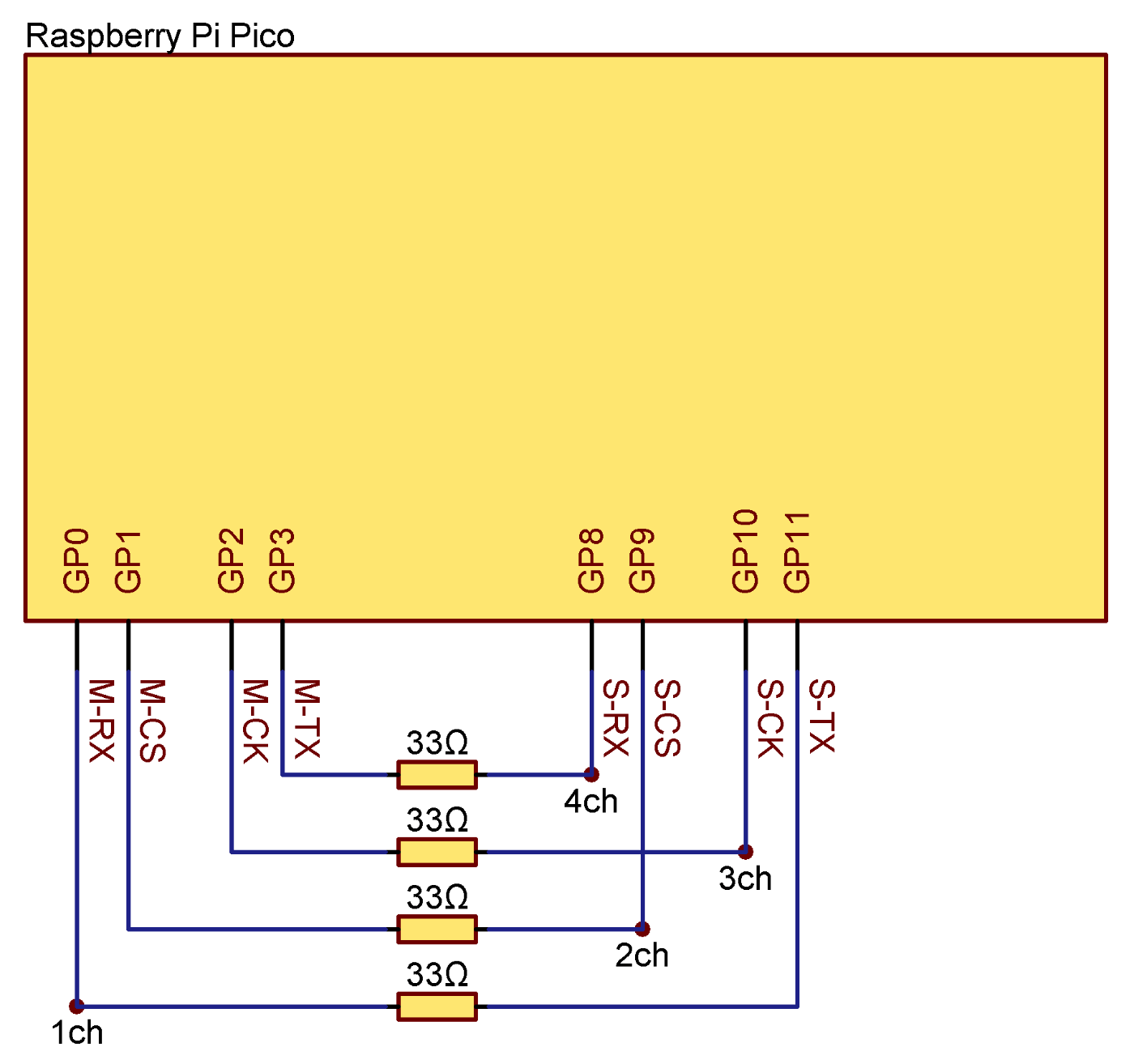
結線についてはサンプルプログラムの冒頭に示されているとおり、以下のように行ったが、ダンピング抵抗として 33Ω を直列に接続した。
| マスタ側 | スレーブ側 |
|---|---|
| RX / GP0 | GP11 / TX |
| CS / GP1 | GP9 / CS |
| CK / GP2 | GP10 / CK |
| TX / GP3 | GP8 / RX |
回路図で示すと以下のようになる。丸印の位置にオシロスコープのプローブを接続した。
サンプルプログラムの動作
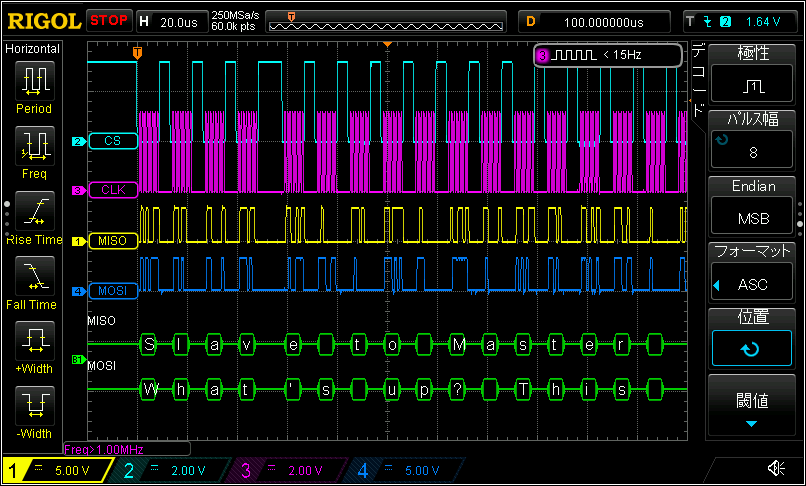
通信は5秒ごとに発生する。うまくいくと以下のような信号が出力される。
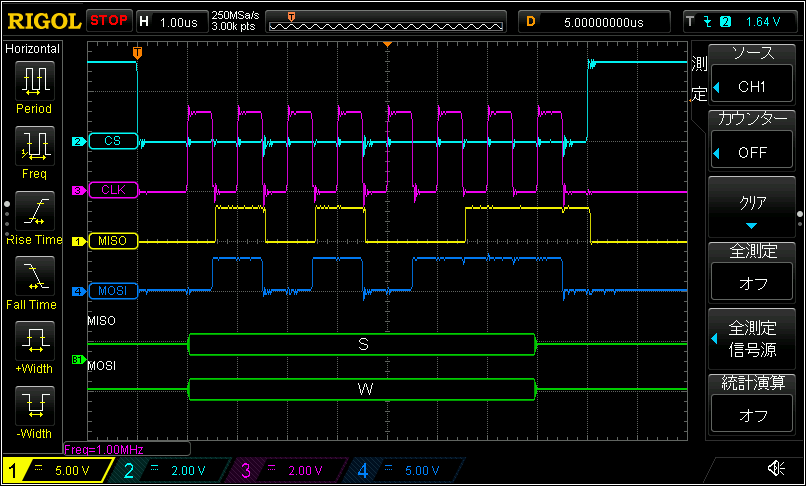
CS が low になった直後を拡大したもの(最初の1バイト目)
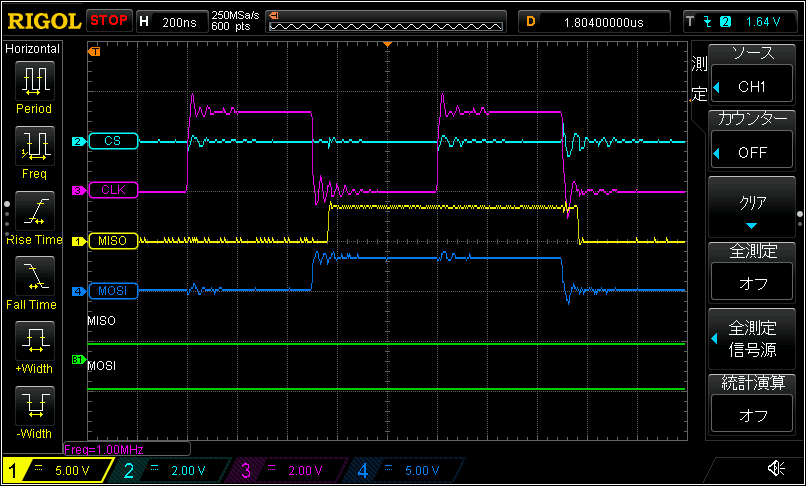
CK が high になった直後を拡大したもの(最初から1~2ビット目)
サンプルプログラムの考察
転送は8ビットずつ
基本的に転送は8ビットずつ行われ、その都度 CS が low → high → low に切り替わる。サンプルプログラムでは SPI.transfer(msg, sizeof(msg)) と配列が渡されているが 内部 では SPI.transfer(uint8_t data) が呼ばれており、8ビットずつの転送が行われる。
arduino-pico としては16ビットずつ転送する SPI.transfer16 関数が用意されている。このほか、pico-sdk としては任意長のビット幅で転送する spi_write_read_blocking 関数が用意されており、arduino-pico としては SPI.transfer(const void *txbuf, void *rxbuf, size_t count) 関数から利用できる。
つまり、SPI.transfer 関数の引数によってどの pico-sdk 側関数が使われるかが変わる。 上記をまとめると以下のように対応している。
| arduino-pico 側関数 | pico-sdk 側関数 | 転送単位 |
|---|---|---|
| SPI.transfer(uint8_t data) | spi_write_read_blocking | 8ビット |
| SPI.transfer16(uint16_t data) | spi_write16_read16_blocking | 16ビット |
| SPI.transfer(void *buf, size_t count) | spi_write_read_blocking | 8ビット |
| SPI.transfer(const void *txbuf, void *rxbuf, size_t count) | spi_write_read_blocking | 任意長 |
| SPI.transfer(nullptr, void *rxbuf, size_t count) | spi_write_blocking | 任意長 |
| SPI.transfer(const void *txbuf, nullptr, size_t count) | spi_read_blocking | 任意長 |
任意長の転送のとき
上記の表の任意長の書込みを試した。マスタ側の転送に nullptr を入れると転送単位が8ビットから任意長になる。
- SPI.transfer(msg, sizeof(msg));
+ SPI.transfer(msg, nullptr, sizeof(msg));
条件を合わせてオシロスコープで観察した。

CS が low になった直後を拡大したもの(最初の1バイト目)

以下のような変化があった。
- 8ビットずつの転送ではあるが CS が low → high → low に戻るまでの時間が短縮された。8ビット単位では約 4μs であったが、任意長の転送では約 0.5μs になった。その結果、全体の転送時間も短縮されている。
- 8ビットずつの転送時は途中で割り込みなどによりさらに間隔が開く。任意長での転送では割り込みなしで最後まで転送される。
- スレーブ側から転送されたデータが1バイト分遅れてやってくる。8ビットずつの転送時は期待通りに
Slave to...から始まるデータが送信されてくるが、任意長では\0Slave to...となっている。
転送速度
ここまでは CK の周波数(クロック周波数)を 1MHz に固定していた。速度の変化で転送速度や読み取りにどう影響するのか調べた。
SPI での通信は CK の1周期で1ビットを転送する。つまり CK の周波数と理想的な1秒あたりの転送ビットレートは同値である。CK の周波数に対する転送ビットレートの割合を効率(%)として表すこととする。当然ながら現実では関数呼び出しのオーバヘッドや上記にあるような CS の変化などにより、効率は 100% 以上にはならない。
CK の周波数を変えながら転送時間、1秒あたりのビットレート、効率を8ビット単位転送と任意長単位転送とで下記にまとめた。転送時間は CS が low になったのち42バイトを送信後、最後に high に戻るまでの時間である。スレーブ/マスタ受信は相手側から送信されたデータが正常に受信されてシリアル出力されたかどうかを表す。
8ビット単位転送
|
|
転送時間 (μs) | ビットレート (bits/s) | 効率 (%) | スレーブ受信 | マスタ受信 |
|---|---|---|---|---|---|
| 24.00 | 224.1 | 1,499.02 | 6.25 | ❌ | ❌ |
| 16.00 | 237.9 | 1,412.26 | 8.83 | ❌ | ❌ |
| 8.00 | 259.2 | 1,296.27 | 16.20 | ❌ | ❌ |
| 4.00 | 302.9 | 1,109.39 | 27.73 | ✅ | ✅ |
| 2.00 | 398.3 | 843.53 | 42.18 | ✅ | ✅ |
| 1.00 | 552.8 | 607.79 | 60.78 | ✅ | ✅ |
| 0.50 | 908.8 | 369.73 | 73.95 | ✅ | ✅ |
| 0.25 | 1,613.8 | 208.21 | 83.28 | ✅ | ✅ |
| 0.10 | 3,619.0 | 92.84 | 92.84 | ✅ | ✅ |
任意長転送
|
|
転送時間 (μs) | ビットレート (bits/s) | 効率 (%) | スレーブ受信 | マスタ受信 |
|---|---|---|---|---|---|
| 24.00 | 16.6 | 20,231.21 | 84.30 | ❌ | ❌ |
| 16.00 | 33.2 | 10,118.04 | 63.24 | ❌ | ❌ |
| 8.00 | 49.8 | 6,745.09 | 84.31 | ❌ | ❌ |
| 4.00 | 99.6 | 3,372.61 | 84.32 | ❌ | ✅ |
| 2.00 | 199.2 | 1,686.33 | 84.32 | ❌ | ✅ |
| 1.00 | 398.5 | 843.17 | 84.32 | ✅ | ✅ |
| 0.50 | 797.0 | 421.59 | 84.32 | ✅ | ✅ |
| 0.25 | 1,594.0 | 210.79 | 84.32 | ✅ | ✅ |
| 0.10 | 3,985.0 | 84.32 | 84.32 | ✅ | ✅ |
どちらの結果も 4MHz と 8MHz の間に壁があるように見える。
ping
SPItoMyself ではマスタから渡されたデータを使わずスレーブから送信している。マスタから送ったデータが正常にスレーブから返ってくるかを確かめるためのプログラムを書いた。
配線は SPItoMyself と変わらない。1秒ごとに結果を表示する。
#include <SPI.h>
#include <SPISlave.h>
// Wiring:
// Master RX GP0 <-> GP11 Slave TX
// Master CS GP1 <-> GP9 Slave CS
// Master CK GP2 <-> GP10 Slave CK
// Master TX GP3 <-> GP8 Slave RX
#define MAX_PING 12
SPISettings spisettings(1'000'000, MSBFIRST, SPI_MODE0);
void setup() {
Serial.begin(9600);
delay(5000);
SPI.setRX(0);
SPI.setCS(1);
SPI.setSCK(2);
SPI.setTX(3);
SPI.begin(true);
}
size_t ping(uint8_t data, uint8_t *ret) {
uint8_t send_buffer[MAX_PING];
uint8_t recv_buffer[MAX_PING];
memset(send_buffer, 0, sizeof(send_buffer));
memset(recv_buffer, 0, sizeof(recv_buffer));
send_buffer[0] = data;
SPI.beginTransaction(spisettings);
SPI.transfer(send_buffer, recv_buffer, sizeof(send_buffer));
SPI.endTransaction();
size_t i;
for (i = 0; i < MAX_PING; i++) {
if ((*ret = recv_buffer[i]) == data) {
break;
}
}
return i;
}
void loop() {
static uint64_t count = 0;
static uint64_t failed = 0;
for (size_t i = 0; i < 1; i++) {
uint8_t value = (uint8_t)rp2040.hwrand32();
uint8_t ret;
if (value == 0) {
value = 1;
}
size_t d = ping(value, &ret);
count++;
if (d >= MAX_PING) {
failed++;
}
Serial.printf("#%llu, error: %llu (%.2f%%)\n",
count, failed, (double)failed / count * 100.0);
}
delay(1000);
}
uint8_t sendBuff = 0;
void recvCallback(uint8_t *data, size_t len) {
size_t i = 0;
for (; i < len; i++) {
if (*data == 0x00)
data++;
else
break;
}
if (i >= len) {
return;
}
if (*data != 0x00) {
sendBuff = *data;
SPISlave1.setData(&sendBuff, 1);
}
}
uint8_t emptySendBuff = 0;
void sentCallback() {
SPISlave1.setData(&emptySendBuff, 1);
}
void setup1() {
SPISlave1.setRX(8);
SPISlave1.setCS(9);
SPISlave1.setSCK(10);
SPISlave1.setTX(11);
sentCallback();
SPISlave1.onDataRecv(recvCallback);
SPISlave1.onDataSent(sentCallback);
SPISlave1.begin(spisettings);
delay(300);
Serial.println("S-INFO: SPISlave started");
}
void loop1() {}
波形
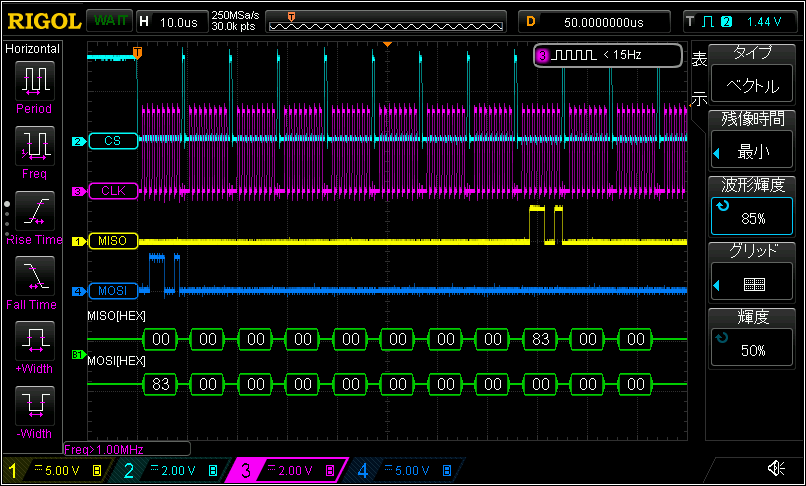
スレーブからマスタにデータが返されるまでに8バイト分の 0x00 が渡されている。RP2040 の SPI の FIFO バッファは8バイト分あり、このバッファを消化してからデータ送信が開始される。
SPI with DMA
arduino-pico v3.6.0 時点では DMA を使った SPI 通信はサポートされていない。ここまでに挙げた SPI 通信はすべてブロッキングである。
DMA 対応の要望はすでに出されているが、earlephilhower氏曰く、FIFOバッファが空になったことを示す割り込みや転送が完了したことを示す割り込みが存在せず、実装上ビジーポーリングせざるを得ないとのこと。