マイコンで実行できるローカルLLMに関する情報をまとめるよ!
Google Colabでりんなちゃんと会話してみる
ローカルLLMの話題とはちょっと外れるかもしれないけど、LLMモジュールがまだ手に入らないから、Google Colabを使用してりんなちゃんと会話してみたよ。クラウドでもPCでもLLMモジュールでも、たぶん動かし方は似たようなものだよね?
Hugging faceでりんなちゃんのモデルが公開されているよ。会話をするならInstructionと書かれているモデルを使用するよ。Instructionと書かれているものは会話用にチューニングされているよ。今回使用したモデルはこちら:
LLMを動作させるには高性能なコンピュータが必要になるから自分のPCでは使えないね..と思っているみんな、Google Colabというサービスを使用すると手元に高性能なコンピュータがなくてもクラウド上でAIを動かすことができるよ。
りんなちゃんの実行手順:
- Google Colabでノートブックを新規作成
- 以下のコードを貼り付ける
- ランタイムメニューからランタイムの変更を選択しT4 GPUを選択
- 貼り付けたコードの左にある実行ボタンを押す
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "rinna/gemma-2-baku-2b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
attn_implementation="eager",
)
chat = []
while True:
user_input = input("あなた: ")
if user_input == "exit":
break
chat.append({"role": "user", "content": user_input})
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
chat.append({"role": "assistant", "content": response})
print("りんな: ", response)
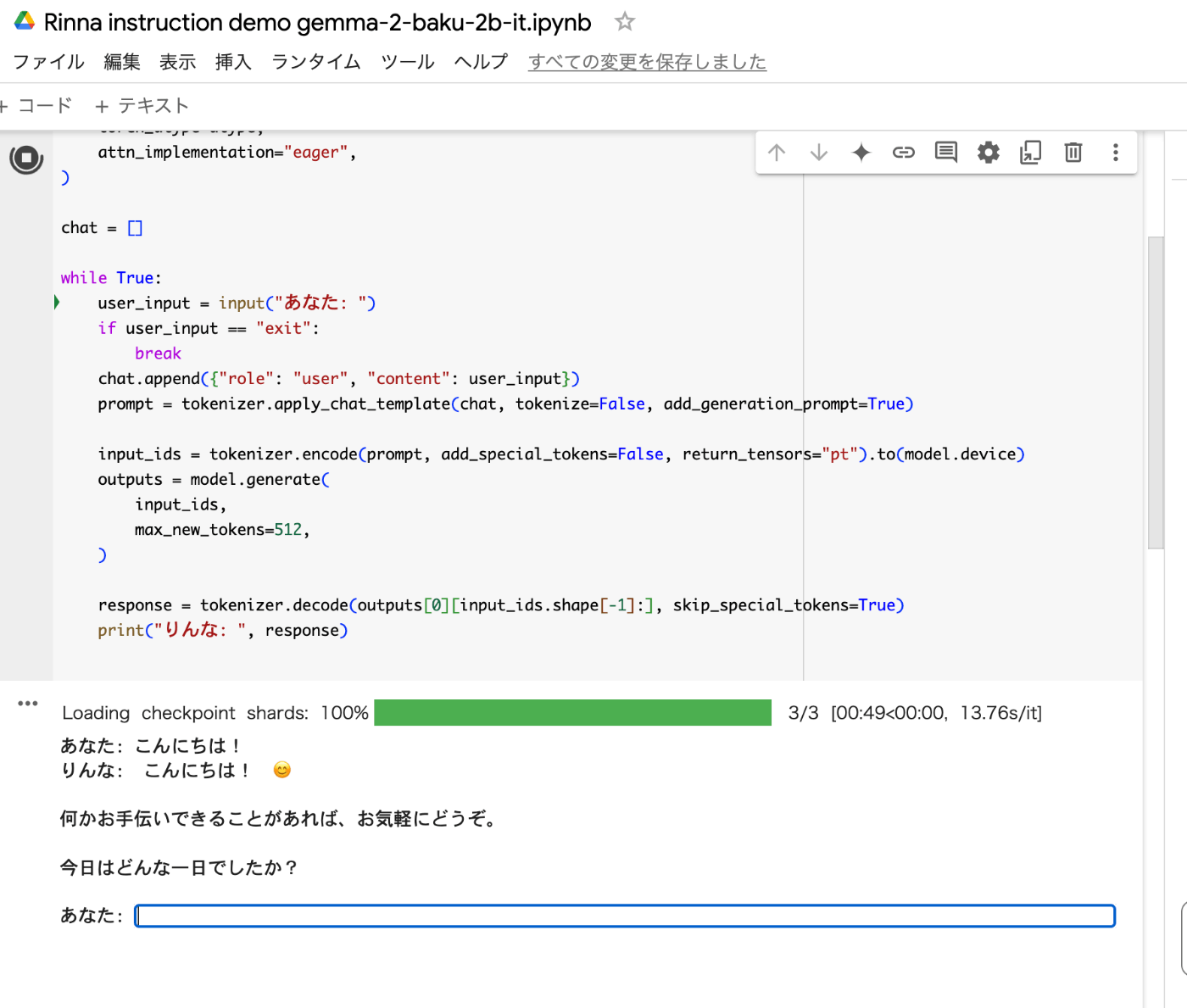
最初はモデルデータのダウンロードに少し時間がかかるよ。
モデルがダウンロードされて実行されると以下のような感じで会話ができるよ。
2024/10/31のM5Stackさんの投稿:
これを使うとローカルで動作可能なLLM(大規模言語モデル)を実行することができるよ。ということはChatGPTに頼らないエッジAIスタックチャンも実現可能になるかもしれないってことだね!
LLMモジュールで何ができるかは、M5Stackさんの製品紹介動画や商品ページを見てね。
LLMモジュールを使って開発するためのリソースは👇こちらのDevelopment Resourcesから。
このスクラップではマイコンのような制約のある環境で実行できるLLMの情報をまとめていくよ。って書いてるけどほとんどがM5StackさんのLLMモジュールの情報になっているよ。
このページを見ておいた方がいいよ!ってTwitterで書かれていたのでシェアします。チップ用にモデルを最適化するコンパイラらしいです。(ページに合わない場合は削除ください)
AXera Pulsar2 Toolchain Instructions Manual
Pulsar2 is an all-in-one new generation neural network compiler independently developed by AXera(e.g. AX630C)
Note on Model Replacementに以下の記述があるから、Hugging Faceとかで公開されているモデルをそのまま使うことはできなくて、このPulsar2でAxera用に変換する必要がありそうだね。
The LLM Module supports models in a proprietary format requiring special processing to function properly. Therefore, existing models on the market cannot be used directly.
Axera AX630C
M5StackさんのLLMモジュールに採用されているAxeraさんのチップに関する情報だよ。LLMモジュールはAX630Cを使用。
検証済みモデル
Githubから引用
- Qwen1.5-0.5B/1.8B/4B
- Qwen2-0.5B/1.5B/4B
- Qwen2.5-0.5B/1.5B/3B
- ChatGLM3-6B
- MiniCPM-1B/2B
- MiniCPM-V 2.0
- TinyLLaMa-1.1B
- Llama2-7B
- Llama3-8B
- Llama3.2-1B/3B
- Phi-2
- Phi-3-mini
- SmolLM-135M/360M
- OpenBuddy-3B
AX630Cの概要
用語
M5StackさんのLLMモジュールやローカルLLM関係の用語をまとめているよ。
KWS
Keyword Spotting
ウェイクワード
「アレクサ」、「OK, グーグル」のような、アシスタントを起動するためにあらかじめ決められた単語を認識する機能や技術のことだよ。
ASR
Automated Speech Recognition
自動音声認識
人間の喋った言葉を認識して文字に変換する機能や技術のことだよ。
LLM
Large Language Model
大規模言語モデル
ChatGPTのような生成AIで使用されている言語モデルのことだよ。膨大なデータを入力して深層学習させたモデルで、命令に対してタスクを実行したり自然な言葉で応答したりすることができるよ。
TTS
Text-To-Speech
文字を音声に変換する機能や技術のことだよ。VOICEVOXもそうだし、PCやスマホで文字を読み上げてくれる機能もTTSだね。
これらの4つの機能、技術はAIアシスタントで使用される基本的な機能だよ。
KWS(アシスタントを起動)→ ASR(入力された音声を文字に変換)→ LLM(入力された命令に対する回答を生成)→ TTS(回答を音声に変換して出力)
エッジAIスタックチャンを作るまでの流れ(想像)
KWS, ASR, LLM, TTSを使用してエッジAIスタックチャンを作る流れをまとめているよ。ボクはAIのことあんまり分かっていないから間違いもあると思うよ。間違いがあればコメントで指摘してくれると嬉しいな。
最終的にはマイクから入力した音声に対してスタックチャンが音声で応答してくれることが目標だけど、一気にそこまでやるよりは段階を踏んだ方が理解も深まりそうだから、まずはKWS, ASR, LLM, TTSの各機能の使い方をそれぞれまとめてみるよ。
テキストを入力して応答させる (LLMによる推論)
LLMモジュールで日本語のテキストを入力して、それに対してAIによる回答を生成するための手順はたぶんこんな感じ:
- 使用するモデルを決める
- Hugging Faceでモデルを探す
- モデルの変換&量子化 (Pulsar2)
- 推論環境の実装
使用するモデルを決める
AX630Cでは色んな種類のLLMが使えるみたいだから、まずはどのモデルを使うかを選ばないといけないね。ここでのモデルはQwenとかLlamaとかのことだよ。
Hugging Faceでモデルを探す
LLMでは学習って作業が必要だけど、学習はスペックの高いPCとか学習用データが必要だったりするから、まずは公開されているモデルを使用するっていうのがいいんじゃないかな。Hugging Faceというサイトには色んな人が作ったモデルが無料で公開されているよ。ここから、自分の使いたいモデルを探してみてね。
みんなのまとめ
Text-To-Speech
テキストから音声を合成するText-To-Speechの情報をまとめているよ。
OpenJTalkでLLMモジュールを喋らせている方:
OpenJTalkを初音ミクの声で喋らせているからあげ先生の記事。音響モデルはまだ入手できるのかな?
AquesTalkでLLMモジュールを喋らせているタカヲさん。