[HashiCorp Vault]オレオレBetter Practice集
コレは何?
HashiCorp Vaultを(ハンズオンではなく)プロダクト開発/運用の一部として導入するために検証した際のツラミと良さそうだなと思ったTIPSをまとめました。Vaultを利用されている方/導入を検討されている方の助けになれば幸いです。
*Vault公式が推奨している事例だけではなく、N=1でやっていることもあるので Best Practice ではなく Better Practiceとしています。
前提
- あくまでもN=1の個人的な意見なので、Vaultがもっと便利な機能を提供していたり、もっと良い方法をご存知の方は是非とも教えて下さい!
- Kubernetes上で
hashicorp/vault-helmを利用することを前提として収集した情報です
ツラミ
Seedデータ投入のためにはVaultにログインが必要
Vaultでは「hashicorp/vault-helm を使ってhelm chart上にSeedデータ(例えばRoleや外部認証連携などの設定情報)を定義しておけばPod起動時に勝手に全部設定してくれる」ということはできない。
もちろん、Vaultを利用するための基本中の基本の設定(storageやlistenerなど)はhelm chart上に定義することで自動で読み込んでくれるが、肝心の運用で必要な類の登録は対応していない。
つまり、Vaultを操作するために必要なRoleやPolicyの登録や外部認証連携などの設定を行うためには、必ずVaultにログインする必要がある。
Vaultにログインするためには(少なくとも初回ログインのためには)Root Tokenを発行する必要があり、またこの値は機密情報であるため厳重に管理する必要がある。
さらにSeedデータの投入処理を自前で実装する必要があり、大変めんどくさい。
Seal機能
Vaultはサーバーが起動した際、必ず sealed 状態となっている。Vaultに対して何らかの操作を行うためにはまず unseal (シールを剥がす)必要がある。
また、既に unseal にした状態であってもサーバー再起動すると sealed 状態になる。
*何故このような仕組みを取り入れているかは公式にまとまっているため、そちらを参照するのがオススメ。
このシール剥がしをするためには初回のサーバー起動後に vault operator init コマンドを実行して発行されるkeyを利用する必要がある。
このkeyを使ってsealを剥がす手順としては、サーバーの状態(より正確にはstorageに保存されたVaultの状態)に応じて以下のように分かれる。
- 初回サーバー起動時
- initを実行してkeyを発行
- unsealする
- keyをどこかに保存する
- 2回目以降のサーバー起動時
- 初回に発行したkeyを使ってunsealする
サーバーの状態(より正確にはstorageに保存されたVaultの状態)に応じて実施する内容が変わる上にkey(機密情報)を適切に管理する必要があり非常に面倒である。
Better Practice
Auth Methods(外部認証連携)を使う
既述の通りVaultではSeedデータを登録するためにVaultにログインする必要がある。しかし初回のサーバー起動時にはログインするためのRoleは存在しないためRoot Tokenを利用せざるを得ない。
機密情報を発行するということはその情報の適切な管理が必要となり、非常に面倒である。
そのため初回サーバー起動時にのみRoot Tokenを利用してVaultへログインし、Auth Methods を設定して次回以降の操作は Auth Methods 経由でVaultへログインするのが良さそう。
Auth Methods を設定することで認証をAWS/Azure/GCP/GitHub/Oktaなどに移譲することができるため、以降の認証では新たに管理対象の機密情報が増えることはない。
またこれによりRoot Tokenは初回のセットアップ時にのみ利用しそれ以降は不要になるため、必要なくなったらすぐに vault token revoke コマンドを利用してTokenを破棄するのが良さそう。
Auto Unsealを使う
Vaultは仕様上サーバー起動時にSeal状態になっている(Unseal状態でサーバーを再起動した場合も同じ)。Seal状態ではVaultログインや各種操作は何もできないため、Sealを剥がす必要がある。
Auto Unsealを使うことで、Vaultサーバー起動後にVaultが自動的にSealを剥がしてくれるようになる(ユーザーは明示的にunseal作業を一切する必要がない)。
Audit logを暗号化しない
デフォルトではVaultのAudit logにおける文字列はすべてHMAC-SHA256で暗号化された状態で出力される。
自分が調べた範囲ではVaultはこの暗号化された値をいい感じに解凍する機能を持っておらず、Vaultに対する特定の操作に対して「誰が、いつ、どのような操作を行ったか」を通知したい場合などには不向きであると考えた。そのため、そういったケースではAuditをenableにする際に log_raw=true を付与することでAudit logの出力を暗号化しないようにするのが良いと思う。
もちろんaudit logに含まれる機密情報が平文で出力されるため、ログの管理には十分に注意する必要がある。
log_raw (bool: false) - If enabled, logs the security sensitive information without hashing, in the raw format.
Audit logに出力される情報を拡張する
Audit機能をenableにすることで、Vault上で行われるすべての操作に対するAudit logが出力される。Auditをenableにすればすべての情報が取得できると思いきや、デフォルトの状態ではそうでもない。
例えばAuth Methods(今回はAWS認証)を用いた際、AssumeRole元の account_id (AWS Account ID) と auth_type (AWS IAM Roleを用いた場合には "iam"となる) しか表示されない。具体的な操作者の情報(例えばAssumeRoleしているSession名)は出力されず、履歴管理の観点では十分とは言えない。
アクセス元の情報をAudit logに表示するには Auth Methods の設定が必要となる(以下はAWS認証を利用した場合の例)。
iam_metadata (string: "default") - The metadata to include on the token returned by the login endpoint. This metadata will be added to both audit logs, and on the iam_alias. By default, it includes account_id and auth_type. Additionally, canonical_arn, client_arn, client_user_id, inferred_aws_region, inferred_entity_id, and inferred_entity_type are available. To include no metadata, set to "" via the CLI or [] via the API. To use only particular fields, select the explicit fields. To restore to defaults, send only a field of default. Only select fields that will have a low rate of change for your iam_alias because each change triggers a storage write and can have a performance impact at scale.
Vaultに対して以下のようなコマンドを実行することで、Audit logに表示される情報を拡張することができる。
vault write /auth/aws/config/identity iam_metadata=account_id,auth_type,canonical_arn,client_arn,client_user_id
{
"metadata": {
"account_id": "11111111111111",
"auth_type": "iam",
"canonical_arn": "arn:aws:iam::11111111111111:role/vault-role",
"client_arn": "arn:aws:sts::11111111111111:assumed-role/vault-role/aikawa",
"client_user_id": "HOGEHOGEHOGEHOGE",
"role_id": "FUGAFUGAFUGAFUGA"
},
.....
}
*そもそもAudit logに具体的にどのような情報が含まれているかは、以下のブログが非常に参考になる。
postStartを利用してSeedデータ投入を自動化する
Vaultは既述の通り、Seedデータの投入を行うためにはVaultにログインして登録や設定作業を行う必要がある(定義ファイルを置いておけば適応されるという感じではない)。
これに対してVaultは postStart というhookを提供しており、サーバー起動後にここに定義された処理が実行されるようになっている。そのため、Seedデータの投入処理などはここに定義するのが良さそう。
postStart (array: []) - Used to define commands to run after the pod is ready. This can be used to automate processes such as initialization or bootstrapping auth methods.
既述のTIPSを踏まえて、postStart内では以下のようなフローを作るのが良いのではないかと思っている。
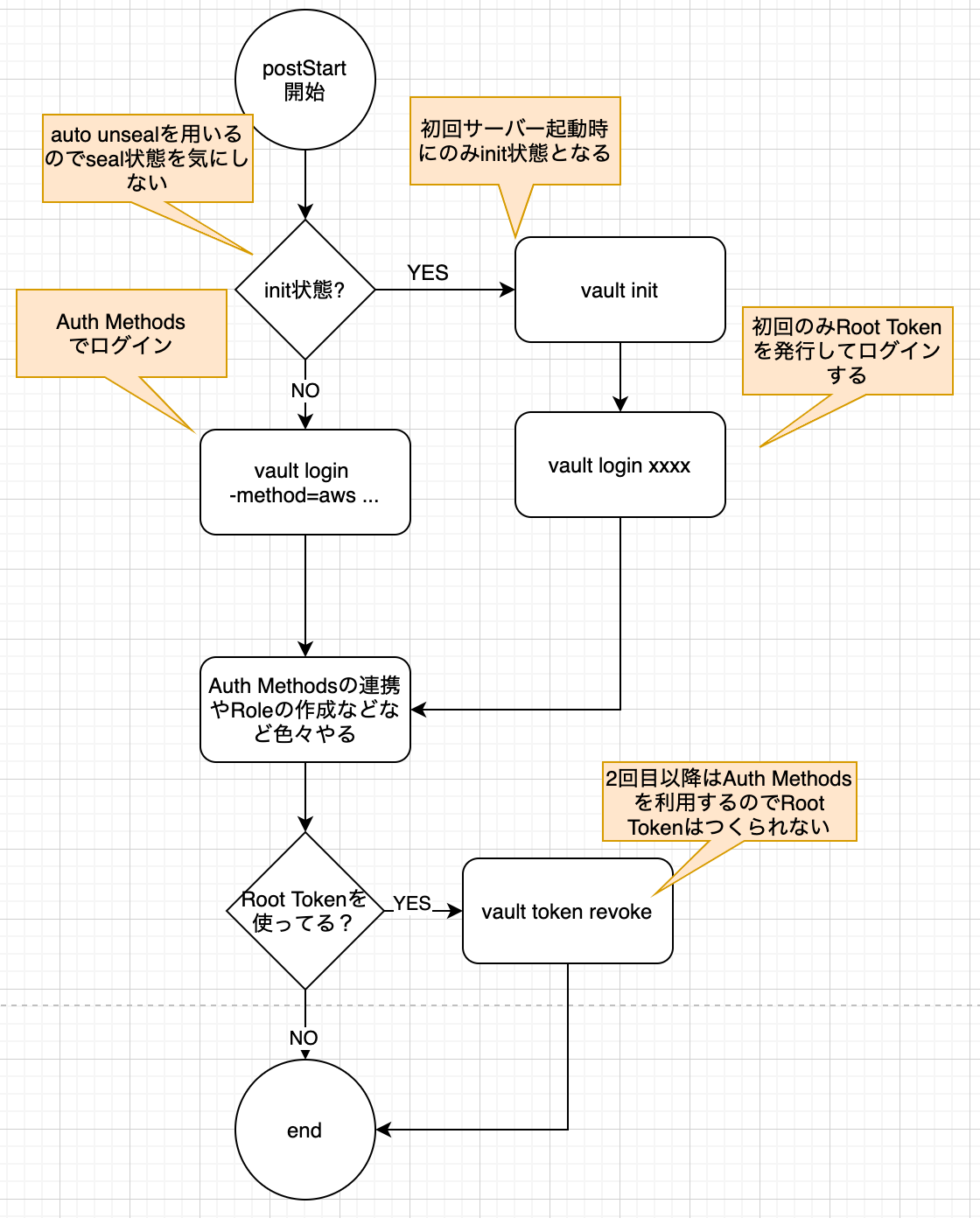
理想としてはサービス運用で必要な登録などはここですべて実行し、Vaultの利用者は既存のデータの変更や更新は行わないようにするのが良いのではないかと思いっている。
*Vaultの利用者は機能を利用することで結果として裏側ではデータの作成/更新などが行われるが、設定値の変更などは利用者が行うとインフラが状態を持ってしまうためpostStartで整備するのが良いと考えている。
そのほか参考
Vault公式では以下のようにProductionで利用する場合に向けたTIPSを提供しているので是非ご覧あれ。
所感
- Vault自体は非常に便利な機能を備えているが、実運用のために自前で工夫して整備する必要がありなかなか大変
- あくまでも自分で調べた範囲での情報なので「実はもっと良い方法があるのではないか?」というのは思う一方で、「これだけ調べて画期的な情報の1つや2つ出てこないことを鑑みるに、結局はみんな頑張って自前で工夫しているんだろうなぁ」と思ってる
Discussion