LINUX, OSの知見
OSとはコンピュータのハードウェアリソースを管理して、プログラムが動作する環境を提供するソフトウェア(カーネル)と定義
カーネルは一番ハードウェアに近いソフトウェア
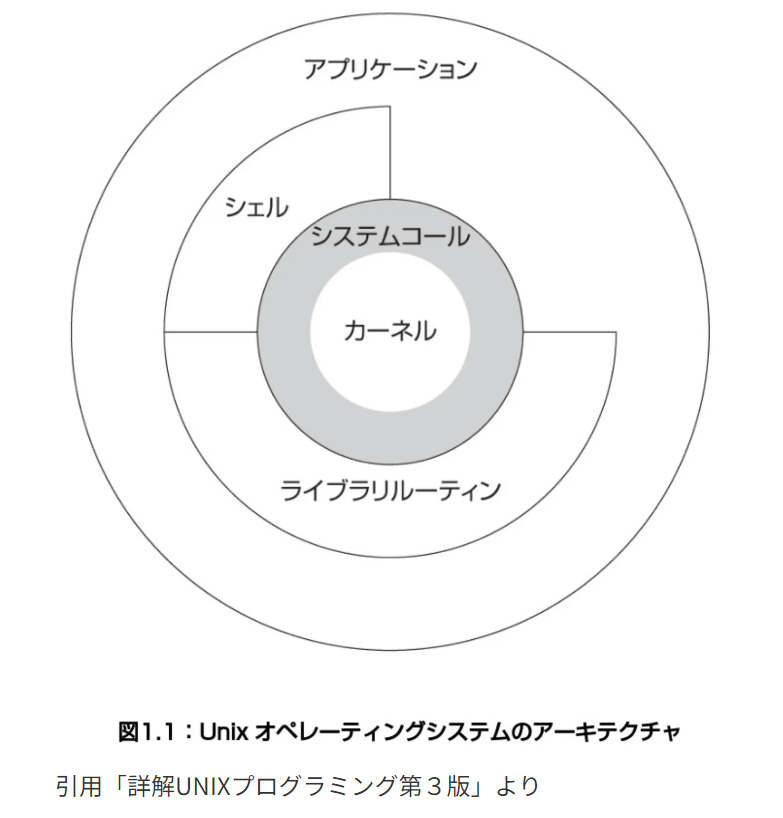
ユーザー⇆シェル⇄カーネル の関係
コンピュータアーキテクチャとcpuファミリは同義
- x86アーキテクチャ:x64, x86_64はIntel64bit、x86はIntel32bit
- ARMアーキテクチャ
カーネルの主なコンポーネントは以下の5つ
- プロセス管理
- メモリ管理
- ネットワーク
- ファイルシステム
- デバイスドライバ
tty:制御ターミナル
セッションにはセッションID(SID)
プロセスグループにはプロセスグループID(PGID)
プロセスにはプロセスID(PID)
スレッド、タスク
セッションには1つ以上のプロセスグループを持つ
プロセスの状態は以下の5つのうちのいずれかに該当する。
- 作成
- 実行待機
- 待ち状態
- 実行中
- 終了
仮想メモリ:実際にシステムに搭載されている物理メモリ以上のメモリを持っているように見せる機能
物理メモリと仮想メモリは共にページと呼ばれる固定長のチャンク(塊)に分割されている。1ページは4KB(ただし、環境によって異なる?)
ソケット:通信を抽象化するためのもの
KernelNewbies : カーネル初心者向けのサイト。カーネルのchangelogの情報やパッチ投稿、カーネルハッキングについてなど、より実践的な案内がある。
CLIの観点からLinuxと対話する方法は以下の2つ
- 手動でターミナルから操作
- シェルスクリプト実行
XKCDの自動化
引用元:https://xkcd.com/1319/
ターミナル内でシェルが起動する
infocmpコマンドでターミナルでサポートされている出力を表示することができる
現在の環境でどのシェルを使用しているかを確認するコマンドは以下の3つ
- file -h /bin/sh
- echo $0
- echo $SHELL
ビルトイン関数、外部関数
which {ビルトイン関数}で何も返ってこない
which {外部関数(外部プログラム)}でその実行ファイルの場所がわかる
type {コマンド}でそのコマンドがビルトインか外部かわかる
モノリシックカーネルの教育用OS:xv6
マルチスレッドプログラミングでは複数のスレッドが同時にデータにアクセスしないようでロックをかける必要がある。偶発的なバグに遭遇し、デバッグが困難である。
osが起動後、起動中のプログラムのことをプロセスと言う
ただし、動作中のプロセスのことを指してプログラムという場合もある。
プログラムはプロセスより広義である。
プロセスが直接デバイスにアクセスすることはなく、緩衝材としてカーネルを間に挟み、プロセス > カーネル > デバイス という流れでプロセスはデバイスにアクセスする
システムコールはプロセスがカーネルに処理を依頼する際に使用される
Linuxにはユーザーモードとカーネルモード実行がある
ユーザーモードで実行するプロセスは特定の命令が実行できない。
カーネルモードでのみデバイスにアクセスすることができる。
Linuxではカーネルのみがカーネルモードで実行されるプログラムである。
プロセスは基本的にはユーザーモードで実行されているが、システムコールを発行するとCPUが例外というイベントを発生し、CPUモードがユーザーモードからカーネルモードに遷移して、システムコールに応じた処理を実行し、システムコールが終了すると再びユーザーモードに遷移し、プロセスの動作が継続される。
静的ライブラリは実行ファイル作成時にその内部に組み込まれるが、動的ライブラリは内部にその本体は組み込まれず、どのライブラリのどの関数を呼び出す旨が記述され、実行時にそのライブラリがメモリにロードされる。
Go言語は基本的にライブラリを全て静的リンクしている
Linuxのforkを実行して作成された子プロセスは親プロセスのメモリ領域をコピーする。これはコピーオンライト(Copy-on-Write)という機能によって非常に低コストでコピーを実現することが可能である。
実行ファイルからプログラムを呼び出して、メモリ常に配置することをメモリマップという
ASLR:Linuxカーネルが持つAdress Space Layout Randomization(ASLR)というセキュリティ機能のことで、プログラムを実行するたびにELFの各セクションを異なるアドレスにマップするという機能
Linuxの実行ファイルはELF(Executable and Linking Forma)に準拠している。
あるプロセスから異なるプロセスを生成するために、fork()関数とexecve()関数を順番に呼ぶのは冗長に見える。これを解決するものが、UNIX系OSのC言語インターフェース規格であるPOSIXに定義されているposix_spawn()という関数を使用することで解決可能である。
ただし、シェルの実装など、凝った実装をする場合はfork()とexecve()を順に実行する方が複雑にならない場合が多い。
fork()関数を実行したのちに何もせずexecve()関数を呼び出す場合はposix_spawn()を使用するのはありだが、それ以外ではfork()、execve()を順に実行する方がいい
アイドルプロセスと言う何もしない特殊なプロセスが存在する。
このプロセスはpsコマンドでは確認できない
プロセスの状態
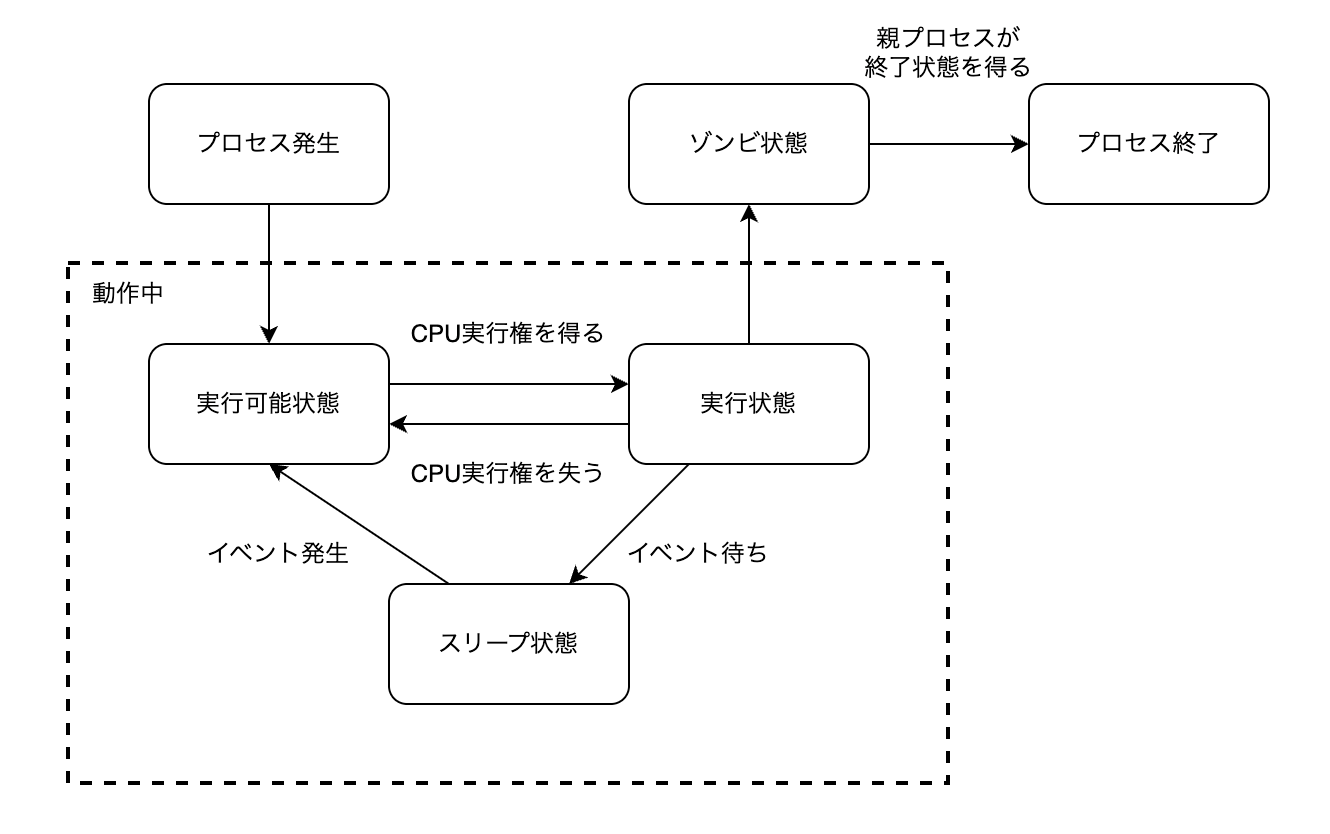
プロセスを終了させるにはexit_group()というシステムコールを呼び出す。
exit()関数を呼び出すことで内部できにこの関数が呼び出されるが、プログラムから明示的に呼び出さない場合でも、libcなどが内部的に呼び出してくれる。
これにより、カーネルはメモリなどのプロセスに使用したのリソースを回収する。
子プロセスが終了した後に、親プロセスがwaitやwaitpidのシステムコールを呼び出すことにより、終了した子プロセスの情報を取得することができる
つまり裏を返せば、子プロセスが終了してから親プロセスが上記のシステムコールを呼ぶまで、子プロセスはなんらかの形で存在していることになる。
このようにプロセスは終了したが親プロセスが終了状態を得ていないというプロセスのことをゾンビプロセスと言う。
シグナルとは任意のプロセスが別のプロセスに対して何かを通知し、強制的に外部から実行の流れを変える仕組み
LinuxでSIGINTシグナルはデフォルトではこれを受け取ったプロセスは実行が終了する
kill -INT <pid> でシェルからSIGINTシグナルをpidのプロセスに対して送信することができる
シグナルの内容はman 7 signalを実行することで確認することができる
SIGINTシグナルはあくまでデフォルトではこれを受け取ったプロセスが強制終了する。
プロセスには各シグナルに対して、それを受け取った場合にどのような処理をするかをあらかじめ決めておくことができる。これをシグナルハンドラという
SIGTERM シグナルを受信したプロセスはクリーンアップ処理を実行して終了し、 SIGKILL シグナルを受信したプロセスはシグナルを捕捉できないためクリーンアップ処理を実行できずに終了する。
両方ともプロセスを終了するためのシグナルであるが、SIGTERMはプロセスがこれを受け取ってからでも動くことができる、SIGKILLはプロセスがこれを受け取るとすぐに強制終了させる。
SIGKILLはシグナルハンドラによってこのシグナルを受け取った後の処理を変更することはできない
ただし、プロセスが長時間シグナルを受け付けない状態(uninterruptible sleep)の場合はSIGKILL自体を受け付けないのでプロセスを終了することができない
ジョブとはシェルがバックグラウンドで実行したプロセスを制御するための仕組み
セッションはシステムにログインした時のログインセッションに対応するものになる。
セッションにはセッションリーダーというプロセスが1つ存在していて、通常はbashなどのシェルになる。
tty
プロセスグループは複数のプロセスをまとめてコントロールするための機能。
セッションの中に複数のプロセスグループが存在する。
基本的にはシェルが作ったジョブがプロセスグループに相当する
プロセスグループを使用すると、当該プロセスグループに所属するすべてのプロセスに対してシグナルを送信することが可能になる。
シェルはこの機能を使用してジョブを制御している。
killコマンドのプロセスIDを指定する引数に-をつけるとプロセスグループに対してシグナルを送信することができる kill -100
セッション内のプロセスグループは2つに分けることができる
- フォアグラウンドプロセスグループ:シェルにおけるフォアグラウンドジョブに対応。セッションに一つだけ存在し、セッションの端末を操作することができる。
- バックグラウンドプロセスグループ:シェルにおけるバックグラウンドジョブに対応。
デーモンはメモリに配置される常駐プロセスのこと。普通のプロセスは一連の処理を行って終了するが、デーモンは場合によってはシステムの開始から終了まで存在し続ける。
デーモンの特徴として
- 端末から入出力する必要がないので、端末が割り当てられない
- あらゆるログインセッションが終了しても影響を受けないように独自のセッションを保有している
- デーモンを生成したプロセスがデーモン終了を気にしなくていいようにinitが親プロセスになっている
最上位の親プロセスはinit(systemdと表記されることもある)プロセスである
プロセススケジューラーとは、プロセスへのCPUリソースの割り当てを担当するLinuxカーネルの機能
1つの論理CPU上で実行できるプロセスは1つだけ
実行可能な複数のプロセスにタイムスライスと呼ばれる単位で順番にCPU使用権を付与し、CPUを使用する
プロセスに関して経過時間と使用時間という概念がある。
経過時間:プロセスが開始してから終了するまでの時間
使用時間:プロセスが実際に論理CPUを使用した時間
タイムスライスの仕組みとしてレイテンシーターゲットで定義している値(秒数)ごとにCPU時間を取得することができる
カーネルのバージョンがv5.13未満であれば
sysctl kernel.sched_latency_nsを実行することでレイテンシータゲットを確認することができ、これを論理CPU上で実行中または実行可能状態のプロセス数で割った値(ナノ秒)がタイムスライスである
カーネルv5.13以上であればrootのみがアクセス可能な /sys/kernel/debug/sched/latency_ns が同じ意味を持つファイルになる
プロセスの優先度を表すnice値が存在する
nice値は-20から19の間の整数値をとる。値が小さいほど優先度が高い。
nice値が低い(優先度が高い)ほどプロセスに多くのタイムスライスを付与することができる
論理CPU上で動作するプロセスが切り替わることコンテキストスイッチという
タイムスライスが切れるとプロセスがいかなる場合でもコンテキストスイッチは発生する
つまり、1プログラム内で呼び出される1連の関数は必ずしも直前の関数が実行されたのちにすぐに呼び出されるというわけではない。コンテキストスイッチが発生し別のプロセスにCPU使用権が移り、プロセスの実行状態が一時待機の状態になる可能性があるからだ。
性能に関して、ターンアラウンドタイムやスループットなどが挙げられる
- ターンアラウンドタイム:システムに処理を依頼してから個々の処理が終わるまでの時間
- スループット:単位時間あたりに処理が完了する数
マルチスレッド環境ではスレッドの数が論理CPUの数
例えば8コア4スレッドであれば、論理CPUの数は32個
近年はCPUのシングルスレッドの大幅な向上は見込めないため、その代わりにCPUコア数の増加するなどしてCPUのトータル性能を上げる流れが見られる
そのため、コア数が増えた時のスケーラビリティを向上させる必要があり、プログラムの並列実行が重要視されている
Simultaneous Multi Threding(SMT)の有効化の有無は下記のファイルを確認することで確認することができる。
/sys/deveices/system/cpu/smt/control
この中身がonであれば、有効化されている。offであれば、無効化されている。
ファイルが存在しない場合はCPUがSMTをサポートしていない。
Linuxではシステムに搭載されているすべてのメモリをカーネルのメモリ管理システムと呼ばれる機能によって管理する。
freeコマンドで確認できるフィールドに関して、buff/cacheはページキャッシュやバッファキャッシュに使用されるメモリ容量、availableはfreeとbuff/cacheのカーネルが解放可能なメモリ容量を足した容量
回収可能なメモリを回収してもメモリ不足が解消されない場合、システムはOut Of Memory(OOM)という状態になり実行できない状態になる
メモリ管理システムには、OOM killerという機能が備わっている。OOM killerは、このようにOOM状態になった場合に、無作為にプロセスを強制終了させてメモリに空きを確保するという機能である。
これが実行されるとdmesgコマンドから得られるカーネルログrに以下のような記述が確認される。
[XXX] oom-kill:constraint=CONSTRAINT_NONE.nodemask=(null)...
メモリ量が十分な際にOOM killerが確認されたらいずれかのプロセスがメモリリークを起こしているかもしれない。
仮想記憶はハードウェアとカーネルの連携によって実現される機能で、プロセスがメモリにアクセスする際に、システムに搭載されているメモリに直セスアクセスさせるのではなく、仮想アドレスというアドレスを用いて、間接的にアクセスさせるという機能。
システムに実際に搭載されているアドレスを物理アドレス、アドレスによってアクセス可能な範囲をアドレス空間と呼ぶ。
ページテーブルは、仮想アドレスから物理アドレスへの変換をマッピングした、カーネルのメモリ内に保存されている表のこと。
ページテーブルに対応付されていな仮想アドレスにアクセスするとページフォールとなり、ページフォールトハンドラーという処理が実行され、SIGSEGVというシグナルをプロセスに送信する。これはカーネルの役割。
仮想記憶の機能によって、メモリの断片化、マルチプロセス実現が困難、メモリの不正領域にアクセスする課題を解決している
ページテーブルはそれ自体のメモリ使用量を削減するために階層化されている
さらに、ヒュージページという仕組みにより、通常よりも大きなサイズのページでもメモリ効率がよくなるようにページテーブルが作成される。
Linuxにはトランスペアレントヒュージページという機能により、ページサイズが所定のサイズを超過する場合にユーザーが意図的にヒュージページを要求しなくてもヒュージページが使用される機能が存在する。
malloc関数を実行した際に場合によってシステムコールmmapが呼び出される。
mmapは動作中のプロセスが新規にメモリ領域を確保するシステムコールである。
mmapシステムコールを呼び出し後には、新規メモリ領域(仮想メモリ領域)は確保するが、それに対応する物理メモリ領域は確保されない。つまり、ページテーブルエントリは作成されるが、当該ページに物理メモリ割り当てはされない。
メモリ管理システムにはページごとに、ページに対応する物理メモリが割り当て済みかという状態を持っている。まだ、物理メモリが割り当てられていない仮想メモリ領域(ページ)にアクセスすると、ページに対応する物理メモリが割り当てられる。これをデマンドページングという。デマンドページングは直前でページフォールトが発生し、ページフォールトハンドラーが実行されるが、ページテーブルにエントリが存在するものの、対応する物理アドレスが存在しない場合はSIGSEGVシグナルを送るのではなく、新規メモリを割り当てる処理が実行される。
fork関数の高速化を実現するための機能にコピーオンライト(CoW)が存在する
fork関数が実行されて親プロセスのメモリを子プロセスにすべてコピーするのではなく、ページテーブルだけをコピーする。また、ページテーブルエントリ内のページへの書き込み権限を親子共に無効化する。
子プロセスが書き込み権限のないメモリにアクセスした場合にページフォールトが発生し、ページフォールトハンドラーが起動し、子プロセスが書き込みをしようとしたメモリに該当するページのみを新しい、仮想記憶に割り当てる。このようにして、fork関数実行時にはメモリ領域を親プロセスから子プロセスにすべてコピーするのではなく、共有メモリに書き込み処理が走った時にのみ、新規メモリ割り当てが実行されるため、コピーオンライトによってforkの高速化を実現している。
execveにもデマンドページングが適応されている
複数のプログラムを協調動作させるためには、各プロセス間でデータを共有したり、お互いの処理の実行タイミングを同期させる必要がある。この場合にプロセス間通信の機能が使用される。
プロセス間通信を実現するためには複数の手段が提供されている。具体的な例をいくつか列挙する。
- 共有メモリ:複数のプロセスで共有されたメモリ領域を使用する
- シグナル:送信先にシグナルが届いたという情報しか送れないのでデート送受信には不向き
- パイプ:プロセス間の相互通信が可能。ファイルを介したプロセス間通信も可能。
- ソケット:大きく分けてUNIXドメインソケットとTCPソケット・UDPソケットが存在する
UNIXドメインソケットでは1つのマシン上のプロセス間通信を実現することが可能。
TCPソケット・UDPソケットでは、UNIXドメインソケットよりは低速になるが、複数マシン上の存在するプロセス間での通信が可能になる。
排他制御:あるリソースに同時に1つの処理しかアクセスできなくすること
Mutex、セマフォ、P操作、V操作
排他制御の簡単な例にファイルロックというものがある
クリティカルセクション:同時に実行されると困る一連の処理のこと
アトミック処理:システムの外から見て1つの処理に見える一連の処理のこと
排他制御を実現するためにC言語のような高級言語の層ではなく、機械語の低レイヤーで実現される
低レイヤーで排他制御を実現するための詳細はcompare and exchangeあるいはcompare and swapで検索する。高級言語レベルでの排他制御実現はCPUの命令に時間がかかるやメモリ負荷がかかることが知られているが、このレイヤーでの排他制御はピーターソンのアルゴリズムで検索するといい
マルチプロセスとマルチスレッド
1つのスレッドしか持たないプログラムをシングルスレッドプログラ、2つ以上のスレッドを持つプログラムをマルチスレッドプログラムという
双方ともプログラムの並列動作を実現するための機能
スレッドにはカーネルスレッドとユーザースレッドが存在する
カーネルがデバイスへのアクセスを代行する。この際にデバイスファイルという特殊なファイルを操作する。NICは速度の問題でデバイスファイルを使用しない。その代わりにNICの操作にはソケットという仕組みが使用される。
デバイスファイルにアクセスできるのは通常rootのみ、デバイスファイルにはファイルの種類、デバイスのメジャー番号、マイナー番号が記述されている。
デバイスファイルはLinuxでは/dev配下に格納されており、ls -l /dev/ でデバイスファイルを一覧を確認すると第一フィールドに記載される値の先頭の文字がcであればキャラクタデバイス、bであればブロックデバイスである。
キャラクタデバイス:読み出しと書き込みはできるがデバイス内のアクセス場所を変更するシーク操作はできない。例として端末、キーボード、マウスなどがキャラクタデバイスとして挙げるられる。
ブロックデバイス:ファイルの読み書き以外にシークが可能である。代表例としてHDDやSSDなどのストレージデバイスが挙げられる。
ループデバイス:ファイルをデバイスファイルのように扱うことが可能になる
デバイスのレジスタはCPUのレジスタと名前は同じであるが全くの別物。
デバイスドライバはデバイスファイルを介して各デバイスに内蔵されているレジスタに読み書きをするもの。
現代のデバイスはメモリマップトI/O(MMIO)という仕組みによってデバイスのレジスタにアクセスする。Linuxカーネルは自身の仮想アドレス空間に物理メモリをすべてマップしている。
ポーリングは定期的になんらかの状態を確認する機能。
各種デバイスはデバイスファイルを介してアクセスできるがストレージデバイスはほとんどの場合、ファイルシステムを介してアクセスする。
ファイルシステムが存在しなければ、データをディスク上のどの位置に保存するかを自分で決める必要がある。また、様々なデータ領域の把握をする必要がある。
ファイルシステムはこのような管理を代行してくれ、ユーザーにとって意味のある一塊のデータをファイルという単位で管理する。
「ファイル形式でデータを管理しているストレージの領域」と「そのストレージ領域を扱う処理」のどちらもファイルシステムと呼ぶ。
ファイルシステムにはデータとメタデータという2つの種類のデータが存在する。
ファイルシステム操作用の関数を呼び出すと次のような順番で処理が進む。
- ファイルシステム操作用の関数が、内部的にファイルシステム操作をするシステムコールを呼ぶ。
- カーネル内の仮想ファイルシステム(Virtual Filesystem, VFS)という処理が動作し、そこから個々のファイルシステムの処理を呼ぶ。
- ファイルシステムの処理がデバイスドライバを呼ぶ。
- デバイスドライバがデバイスを操作する。
メモリマップトファイル:ファイル領域を仮想アドレス空間上にマップする機能。システムコールmmap関数を所定の方法で呼び出すことで、ファイルの内容をメモリに読み出して、その領域を仮想アドレス空間にマップすることができる。
Linuxでは、ext4, XFS, Btrfsというファイルシステムが一般的である。これらはストレージデバイス上に作るデータ構造とそれを扱うための処理が異なるので、以下のような差異が挙げられる。
ファイルシステムの最大サイズ、ファイルの最大サイズ、最大ファイル数、ファイル名の最大長、各処理の処理速度、標準によって定められていない追加機能の有無が異なる。
ファイルシステムの容量を制限する機能をクォータという。
クォータには下記の種類のクォータが存在する。
- ユーザークォータ
- ディレクトリクォータ
- サブボリュームクォータ
ファイルシステムの不整合を防ぐ「ジャーナリング」と「コピーオンライト」。
ジャーナリング:ファイルシステム内にジャーナル領域という特殊なメタデータ領域を用意する。
- 更新に必要なアトミックな処理の一覧をジャーナル領域に書き出す。この一覧をジャーナルログという。
- ジャーナル領域の内容に基づいて、実際にファイルシステムの内容を更新する。
もし、実データ更新中に強制電源断が発生した場合はジャーナルログの再生によって、再度ジャーナルログを辿って処理を実行し、処理を完了状態にする。
ファイルシステムの不整合を減らす手段は存在するが、完全位ファイルシステムの不整合をなくすことは難しい。そのため、定期的なバックアップを取得する必要がある。
fsckと呼ばれるコマンドはファイルシステム復旧用のコマンド。
ext4やXFSにはLinuxの元になるUNIXが作られた頃から存在する基本的な機能のみが存在するが、Btrfsには高度なファイルシステム機能があり、その一つにスナップショット機能が挙げられる。
スナップショットはデータのフルコピーではなく、データを参照するメタデータの作成だけで済む。また、元のファイルシステムとデータを共有するため、空間的コストも低い。Btrfsのコピーオンライト形式のデータ更新という特性も備えている。
スナップショットは採取元のファイルシステムでデータ領域を共有しているため、バックアップとしては機能しない。
ファイルシステムレベルでバックアップを取得する場合は一般的にファイルシステムへのI/Oを停止する必要がある。スナップショットを使用することでこのI/Oを停止する時間を短縮することができる。
スナップショットを作成し、そのスナップショットからバックアップを取得することでI/O停止の時間を短縮化できる。
マルチボリューム
Btrfsは従来のファイルシステムと考えるよりも、ファイルシステム+LVMのようなボリュームマネージャーと考える方がわかりやすい。
Btrfsは1つ以上のストレージデバイス/パーティションからストーレジプールを作成し、そのの上に、マウント可能なサブボリュームという領域を作成する。
ストレージプールはLVMにおけるボリュームグループ、サブボリュームはLVMにおける論理ボリュームとファイルシステムを足したものに近い。
Btrfsは全てのデータにチェックサムを持つことによって、データの破損を検知することができる。
データ読み出し時にチェックサムエラーを検知すると、そのデータを捨てて、読み出しを依頼したプログラムにはI/Oエラーを通知する。RAID構成にして入れば、チェックサムエラー検知後にデータを復元することが可能となる。
チェックサムとは誤り検出符号の一つ。
署名からデータが改竄されていないか確認している。
shasumコマンドを使用してファイルやストリームのハッシュ値を計算する。計算されたハッシュ値はファイルの生合成を確認するデジタル署名としてよく使用される。
メモリベースのファイルシステムとしてtmpfsというものがある。これはメモリ上にファイルシステムを構築することで、ストレージデバイスへのアクセスが一切必要なく、高速にアクセスすることができる。その一方で、揮発性のため、電源を落とすとデータが削除される。/tmpや/var/run内のデータは再起動時にそのデータを残す必要がないので、tmpfsが使用されている。
ネットワークを介してリモートホスト上のデータにファイルシステムのインターフェースを使用してアクセスするネットワークファイルシステムも存在する。代表例としてNFSやCIFSなどが挙げられる。主に前者はLinuxを含むUNIX系のファイルシステムへのアクセス、後者はWindows系のファイルシステムにアクセスする際に使用される。
複数のマシンを束ねて大きなファイルシステムを作るCephFSのようなファイルシステムも存在する。
システムに存在するプロセスの情報を得るためのファイルシステムとしてprocfsが存在する。
procfsは通常/proc以下にマウントされる。/proc/pid/以下のファイルにアクセスすると、pidに対応するプロセスの情報を得られる。
詳細はman 5 proc
カーネルが保持する雑多な情報が/proc配下に保存されてきた。この/proc配下の乱用を防ぐためにsysfsが導入され、通常、/sys以下にマウントされる。
詳細はman 5 sysfs
レジスタとは
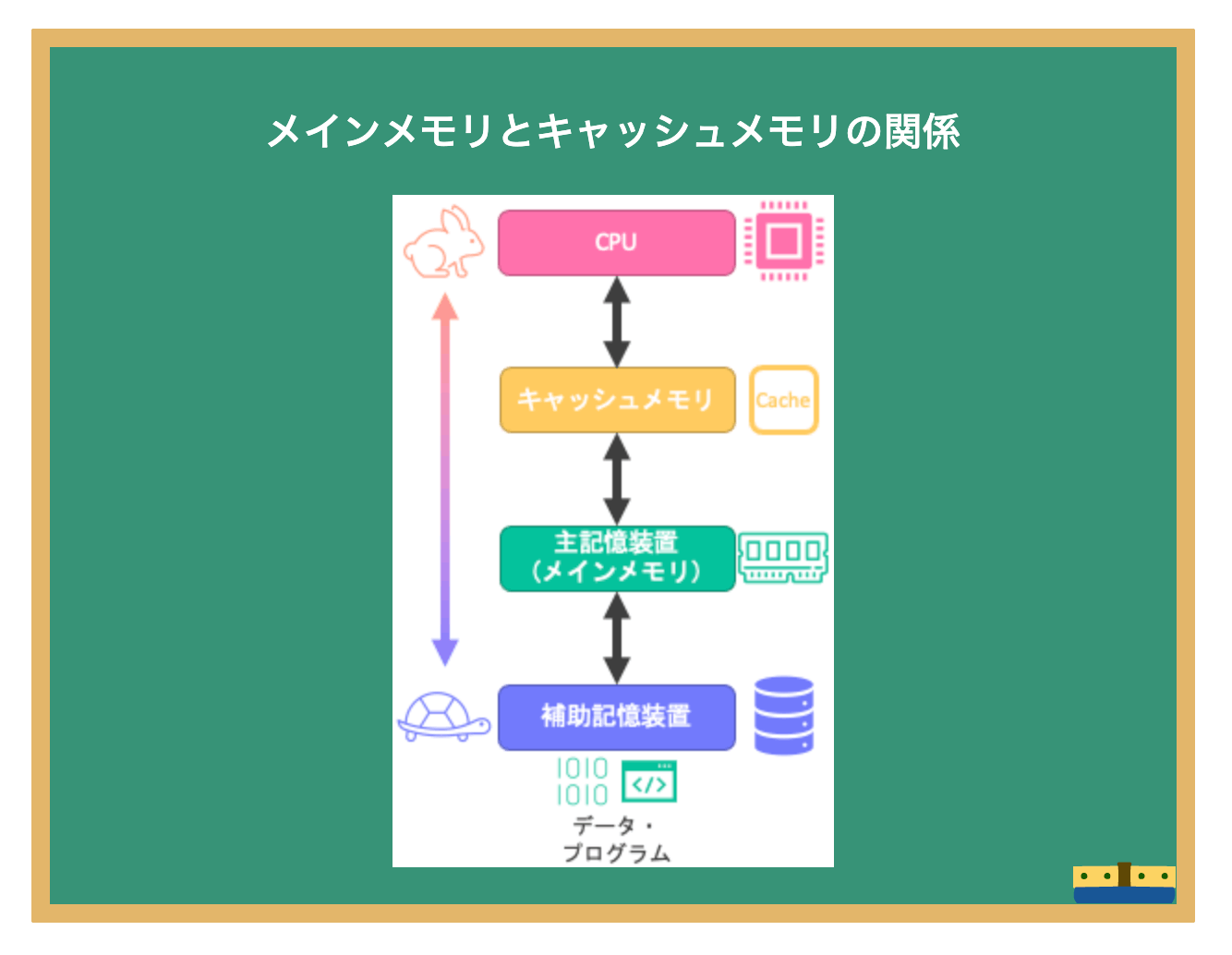
レジスタもキャッシュメモリもCPUに内蔵されている高速な記憶装置。
CPUはレジスタ上のデータを計算する。
レジスタはメモリからデータを読み出す。
メモリとキャッシュメモリではレジスタへのデータ読み出し速度に数倍から数十倍の差があり、キャッシュメモリからレジスタへの読み出しの方が早い。
CPUからキャッシュメモリに書き出しが発生すると、キャッシュラインにはダーティであるというサインを付与する。
レジスタからメモリへの書き込みにはライトスルー方式とライトバック方式がある。
ライトスルー方式の方が実装が簡単であるが、ライトバック方式の方がCPUからメモリへのデータ書き込み命令の実行のたびにメモリアクセスをせずに済むため、処理を高速化することが可能である。
キャッシュメモリがいっぱいになっている状態でキャッシュに入っていない領域へのメモリアクセスが頻繁に発生すると、スラッシングという性能劣化状態に陥る。
破棄するキャッシュラインがダーティな場合にはキャッシュからメモリに書き出す処理を行なってからキャッシュラインが削除される。
最近のCPUではキャッシュメモリが階層化されている場合が多い。
L1キャッシュ、L2キャッシュ、L3キャッシュと表記する。(LはLevelのL)
CPUに近いキャッシュからL1, L2 L3キャッシュであり、CPUに近いほど容量が少なく、高速、CPUから遠いほど容量が多く、レジスタへのアクセスは低速である。
キャッシュメモリは/sys/devices/system/cpu/cpu0/cache/index0といったディレクトの中身から確認することができる。
CPUの処理時間に比べてメモリアクセスの所要時間の方がはるかに長い、この際のCPUの処理空き時間をSMTという機能を活用して有効活用することができる。
2つのスレッドとそれぞれのスレッドで動作する2つのプロセスがあるとする。
SMTの機能として、例えば、片方のプロセスであまりスレッド(論理CPU)を使用していない場合はもう一方のプロセスの処理にあまり使用していないスレッドを追加して処理を進めることができることが挙げられる。これによりあるプロセスがCPU処理をあまり使用していない時間を別のプロセスの処理にそのCPUを割り当てることができ、処理が高速化される。