【開発編】国立国会図書館「次世代デジタルライブラリー」で公開されているOCR結果をIIIFビューアで閲覧するアプリを作成しました。



概要
国立国会図書館「次世代デジタルライブラリー」で公開されているOCR結果をIIIFビューアで閲覧するアプリを作成しました。使用方法を以下の記事にまとめています。
今回は、上記アプリの構築方法について説明します。
構築方法
バックエンド
AWSを利用しました。また、主にSAM(Serverless Application Model)を用いて構築しています。
IIIFマニフェスト&キュレーションリストの作成
次世代デジタルライブラリーで公開されているOCR結果を反映したIIIFマニフェストおよびキュレーションリストを生成する流れは以下です。
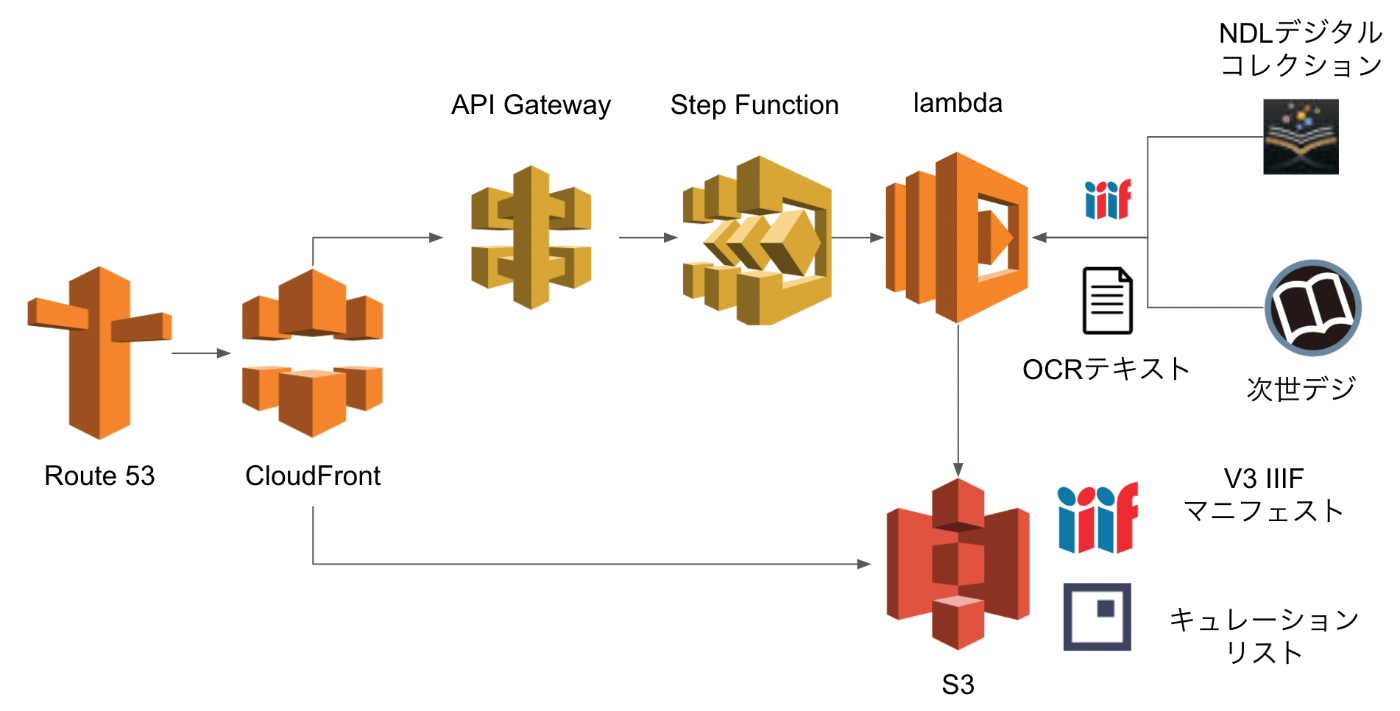
ポイントとして、AWS Lambdaが担う処理に時間がかかっため、AWS Step Functionsを導入しています。
具体的には、AWS Lambdaは、OCR結果をIIIFマニフェストおよびキュレーションリストに変換する処理、およびその変換結果をS3にアップロードする処理を行いますが、これがAPI Gatewayのタイムアウト(29秒)に引っかかってしまいました。そのため、以下の記事を参考に、Step Functionsを組み合わせた非同期処理を採用しています。
IIIF Content Search APIの構築
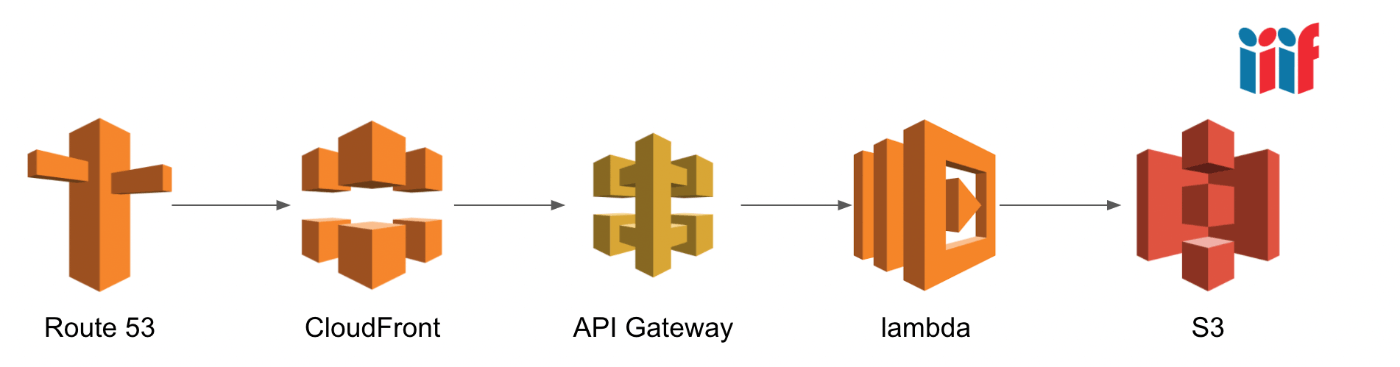
本アプリのもう一つの工夫点として、IIIF Content Search APIを構築しています。
こちらについては、以下に示すシンプルな構成をとっています。S3から取得したIIIFマニフェストに対して、検索語に対応したデータ(文字列および座標情報)を返却するAWS Lambda関数を作成しました。
フロントエンド
フロントエンドはNuxt.jsを用いて開発しています。ソースコードは以下です。GitHub Pagesを用いて公開しています。
Step Functionsを実行後、定期的(3秒ごと)にステータスを取得し、SUCCEEDEDとなれば、MiradorとCuration Viewer(CODH提供)へのリンクを表示します。
Miradorについては、以下に示すように、デフォルトですべてのアノテーションを表示するhighlightAllAnnotations: true、かつ、サイドパネルでアノテーションを表示するdefaultSideBarPanel: 'annotations'ようにしています。
まとめ
AWS勉強中の身ですが、他の方の参考になる部分がありましたら幸いです。
Discussion