DHConvalidatorにおける'ref'に関する不具合への対応
本記事は、一部AIが執筆しました。
概要
DHConvalidatorは、デジタル人文学(DH)会議の抄録を一貫したTEI(Text Encoding Initiative)テキストベースに変換するためのツールです。
このツールの利用において、Microsoft Word形式(DOCX)からTEI XML形式への変換処理中に以下のようなエラーが発生するケースがありました:
ERROR: nu.xom.ParsingException: cvc-complex-type.2.4.a: Invalid content was found starting with element 'ref'
この原因と対処方法について共有します。
原因の特定
調査の結果、問題の原因はWord文書内に埋め込まれた INCLUDEPICTUREフィールドコード であることが判明しました。
具体的には、Googleドキュメントから画像をコピー&ペーストした際に、以下のようなフィールドコードが文書内に残存していました:
INCLUDEPICTURE "https://lh7-rt.googleusercontent.com/docsz/..." \* MERGEFORMATINET
これらの外部画像参照リンクがTEI変換プロセスで適切に処理されず、XML検証エラーを引き起こしていました。
解決方法
この問題を解決するため、DOCXファイル内の問題のあるフィールドコードを自動的に除去するPythonスクリプトを開発しました。
スクリプトの特徴
- 安全な処理: 画像コンテンツ自体は保持し、フィールドコード部分のみを削除
- ZIP形式対応: DOCXファイルの内部構造(ZIP + XML)を適切に処理
- 名前空間対応: Word文書のXML名前空間を考慮した正確な要素検索
主要な処理ロジック
- DOCXファイルを一時ディレクトリに展開
-
word/document.xml内のフィールドコード構造を解析 -
INCLUDEPICTUREを含むフィールドを特定 - フィールド制御要素(begin/separate/end)のみを削除し、画像要素は保持
- 修正されたXMLで新しいDOCXファイルを生成
実装のポイント
フィールドコード判定
def is_includepicture_field(field_runs, ns):
for run in field_runs:
instr_text = run.find('.//w:instrText', ns)
if instr_text is not None and instr_text.text:
if 'INCLUDEPICTURE' in instr_text.text:
return True
return False
削除対象の選別
def should_remove_run(run, ns):
# フィールド制御要素を持つか確認
has_field_control = (run.find('.//w:fldChar', ns) is not None or
run.find('.//w:instrText', ns) is not None)
# 実際の画像コンテンツを持つか確認
has_image_content = (run.find('.//w:drawing', ns) is not None or
run.find('.//w:pict', ns) is not None)
# フィールド制御要素があり、画像コンテンツがない要素を削除
return has_field_control and not has_image_content
結果
このスクリプトにより、問題のあるフィールドコードが除去され、TEI変換プロセスが正常に完了するようになりました。画像は適切に文書内に埋め込まれた状態で保持されます。
使用方法
python fix_docx_fields.py input.docx [output.docx]
出力ファイル名を指定しない場合、input_fixed.docxとして保存されます。
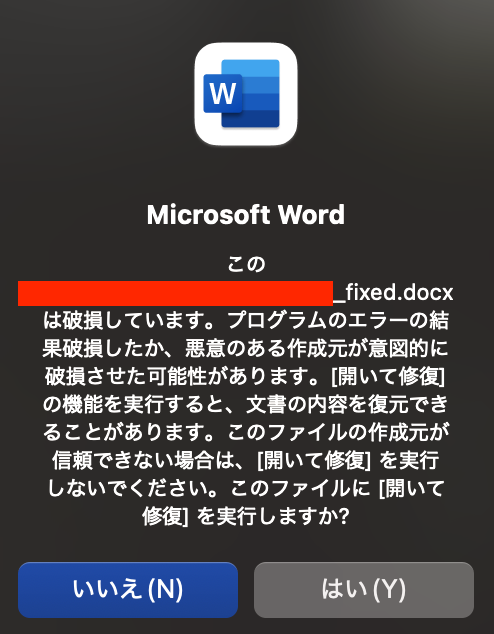
ただし、ファイルを開く際に以下の警告が表示されました。スクリプト側の修正方法がわからなかったのですが、「はい」ボタンを押すことで無事に開くことができました。
まとめ
GoogleドキュメントやWebブラウザから画像をコピーする際は、このような外部参照リンクが埋め込まれる可能性があります。
この問題は他のDOCX処理システムでも発生する可能性があるため、類似のエラーに遭遇した際の参考になれば幸いです。
スクリプト
#!/usr/bin/env python3
"""
DOCX Field Code Processor
Removes problematic field codes (like INCLUDEPICTURE) from Word documents
that cause TEI conversion issues.
"""
import zipfile
import xml.etree.ElementTree as ET
import tempfile
import os
def process_docx_fields(input_file, output_file=None):
"""
Process DOCX file to remove problematic field codes.
Args:
input_file (str): Path to input DOCX file
output_file (str): Path to output DOCX file (optional)
"""
if output_file is None:
output_file = input_file.replace('.docx', '_fixed.docx')
# Create temporary directory
with tempfile.TemporaryDirectory() as temp_dir:
# Extract DOCX file
with zipfile.ZipFile(input_file, 'r') as zip_ref:
zip_ref.extractall(temp_dir)
# Process document.xml
doc_xml_path = os.path.join(temp_dir, 'word', 'document.xml')
if os.path.exists(doc_xml_path):
process_document_xml(doc_xml_path)
# Create new DOCX file
with zipfile.ZipFile(output_file, 'w', zipfile.ZIP_DEFLATED) as zip_out:
for root, dirs, files in os.walk(temp_dir):
for file in files:
file_path = os.path.join(root, file)
arc_path = os.path.relpath(file_path, temp_dir)
zip_out.write(file_path, arc_path)
print(f"Fixed DOCX saved as: {output_file}")
def process_document_xml(xml_file_path):
"""
Process the document.xml file to remove INCLUDEPICTURE field codes while preserving images.
"""
# Parse XML
tree = ET.parse(xml_file_path)
root = tree.getroot()
# Define namespaces
ns = {
'w': 'http://schemas.openxmlformats.org/wordprocessingml/2006/main'
}
# Find and remove field codes
removed_count = 0
# Process each paragraph
for para in root.findall('.//w:p', ns):
runs_to_remove = []
# Find all runs in this paragraph
runs = para.findall('.//w:r', ns)
# Look for INCLUDEPICTURE field patterns
i = 0
while i < len(runs):
run = runs[i]
# Check for field begin
fld_char = run.find('.//w:fldChar', ns)
if fld_char is not None and fld_char.get(f'{{{ns["w"]}}}fldCharType') == 'begin':
# Found field begin, look for the complete field structure
field_runs = [run]
j = i + 1
# Collect all runs until field end
while j < len(runs):
next_run = runs[j]
field_runs.append(next_run)
next_fld_char = next_run.find('.//w:fldChar', ns)
if next_fld_char is not None and next_fld_char.get(f'{{{ns["w"]}}}fldCharType') == 'end':
break
j += 1
# Check if this is an INCLUDEPICTURE field
if is_includepicture_field(field_runs, ns):
# Remove only field control runs, keep image content
for field_run in field_runs:
if should_remove_run(field_run, ns):
runs_to_remove.append(field_run)
removed_count += 1
# Skip to after the field
i = j + 1
else:
i += 1
# Remove the problematic runs
for run in runs_to_remove:
para.remove(run)
# Save the modified XML
tree.write(xml_file_path, encoding='utf-8', xml_declaration=True)
print(f"Removed {removed_count} INCLUDEPICTURE field codes while preserving images")
def is_includepicture_field(field_runs, ns):
"""
Check if the field runs contain INCLUDEPICTURE.
"""
for run in field_runs:
instr_text = run.find('.//w:instrText', ns)
if instr_text is not None and instr_text.text:
if 'INCLUDEPICTURE' in instr_text.text:
return True
return False
def should_remove_run(run, ns):
"""
Determine if a run should be removed (contains field codes but not image content).
"""
# Check if run has field control elements (begin, separate, end, instrText)
has_field_control = (run.find('.//w:fldChar', ns) is not None or
run.find('.//w:instrText', ns) is not None)
# Check if run has actual image content (drawing elements)
has_image_content = (run.find('.//w:drawing', ns) is not None or
run.find('.//w:pict', ns) is not None or
run.find('.//w:object', ns) is not None)
# Remove runs with field control elements but no image content
return has_field_control and not has_image_content
def main():
"""Main function for command line usage."""
import sys
if len(sys.argv) < 2:
print("Usage: python fix_docx_fields.py <input.docx> [output.docx]")
sys.exit(1)
input_file = sys.argv[1]
output_file = sys.argv[2] if len(sys.argv) > 2 else None
if not os.path.exists(input_file):
print(f"Error: Input file '{input_file}' not found")
sys.exit(1)
try:
process_docx_fields(input_file, output_file)
print("Processing completed successfully!")
except Exception as e:
print(f"Error processing file: {e}")
sys.exit(1)
if __name__ == "__main__":
main()
Discussion