【Omeka S モジュール紹介】Advanced Search adapter for Solr
概要
「Advanced Search adapter for Solr」はOmeka Sのモジュールであり、Apache Solrの高度な検索アダプタを提供します。これにより、Omeka内で完全な検索エンジンの力を活用することができます。これは一般のユーザー向けや管理者向けに、関連性(スコア)による検索、インスタント検索、ファセット、オートコンプリート、提案などの機能を提供します。
Apache Solrのセットアップ
Javaをインストール可能な環境で、Apache Solrのセットアップを行います。Ubuntuの場合、以下のサイトなどが参考になりました。
以下のようなコマンドでApache Solrを起動できます。
# Javaのインストール
sudo apt update && sudo apt install -y default-jdk
# ダウンロード
wget https://dlcdn.apache.org/solr/solr/9.3.0/solr-9.3.0.tgz
# 展開
tar xzf solr-9.3.0.tgz solr-9.3.0/bin/install_solr_service.sh --strip-components=2
# インストール
sudo bash ./install_solr_service.sh solr-9.3.0.tgz
# 起動
sudo systemctl start solr
また、mycol1というコアを作成しておきます。
sudo su - solr -c "/opt/solr/bin/solr create -c mycol1 -n data_driven_schema_configs"
モジュールのインストール
以下のページからモジュールをダウンロードおよびインストールします。
インストール時に、以下のように、AdvancedSearchが必要、というアラートが表示されることがあります。
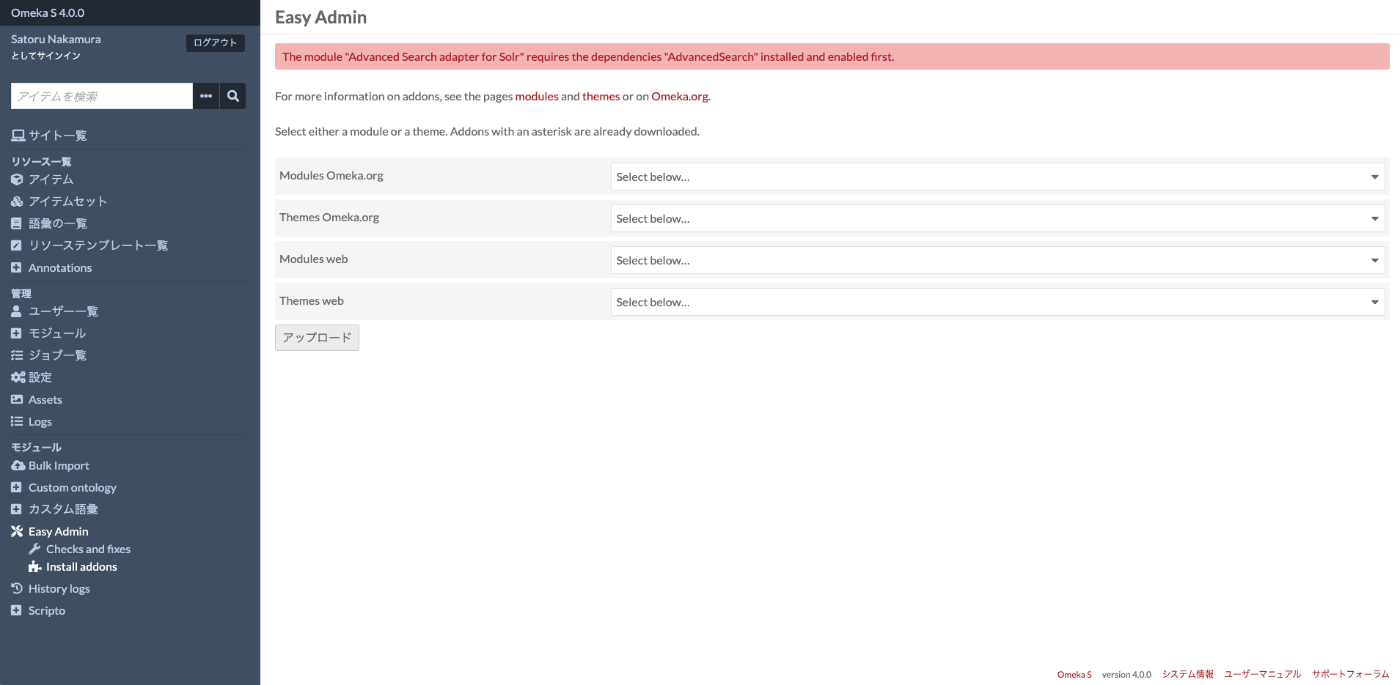
その場合、以下のモジュールを事前にインストールおよび有効化してから、再度Advanced Search adapter for Solrのインストールをお試しください。
Apache Solrとの接続
管理画面左側の モジュール > Search manager から以下の画面にアクセスします。
</admin/search-manager>
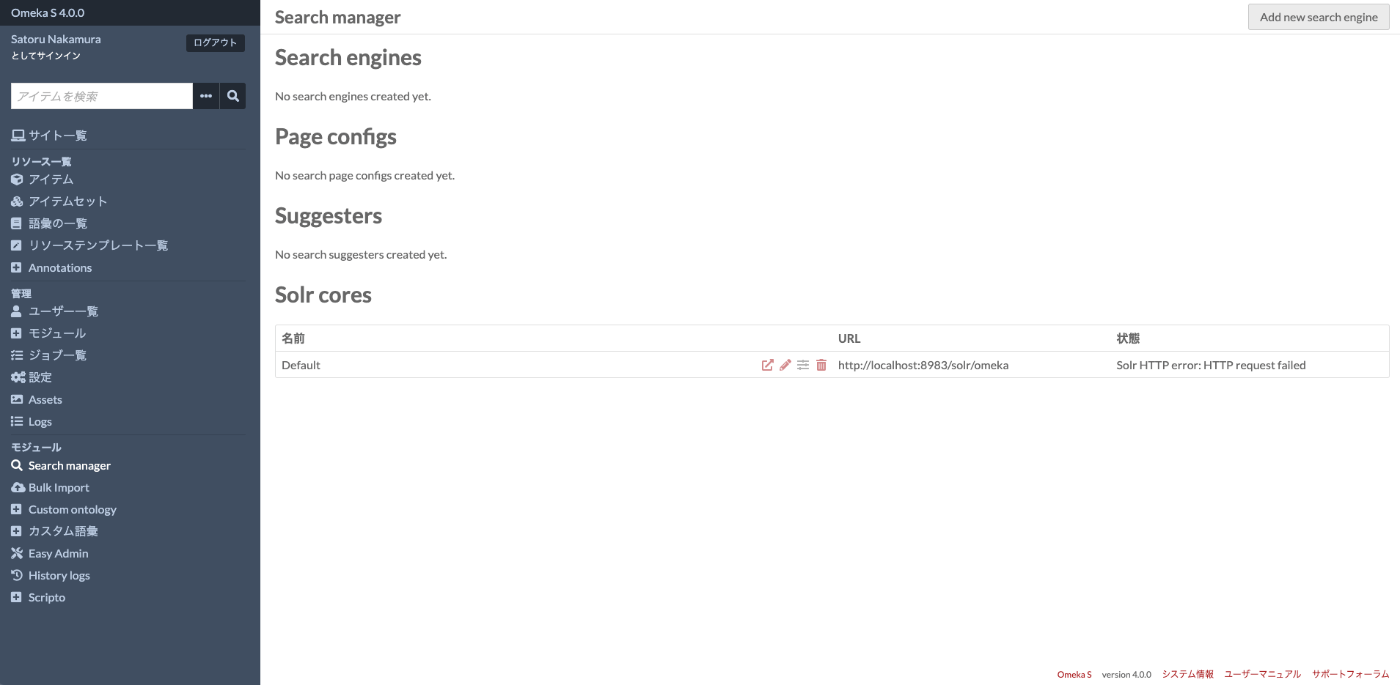
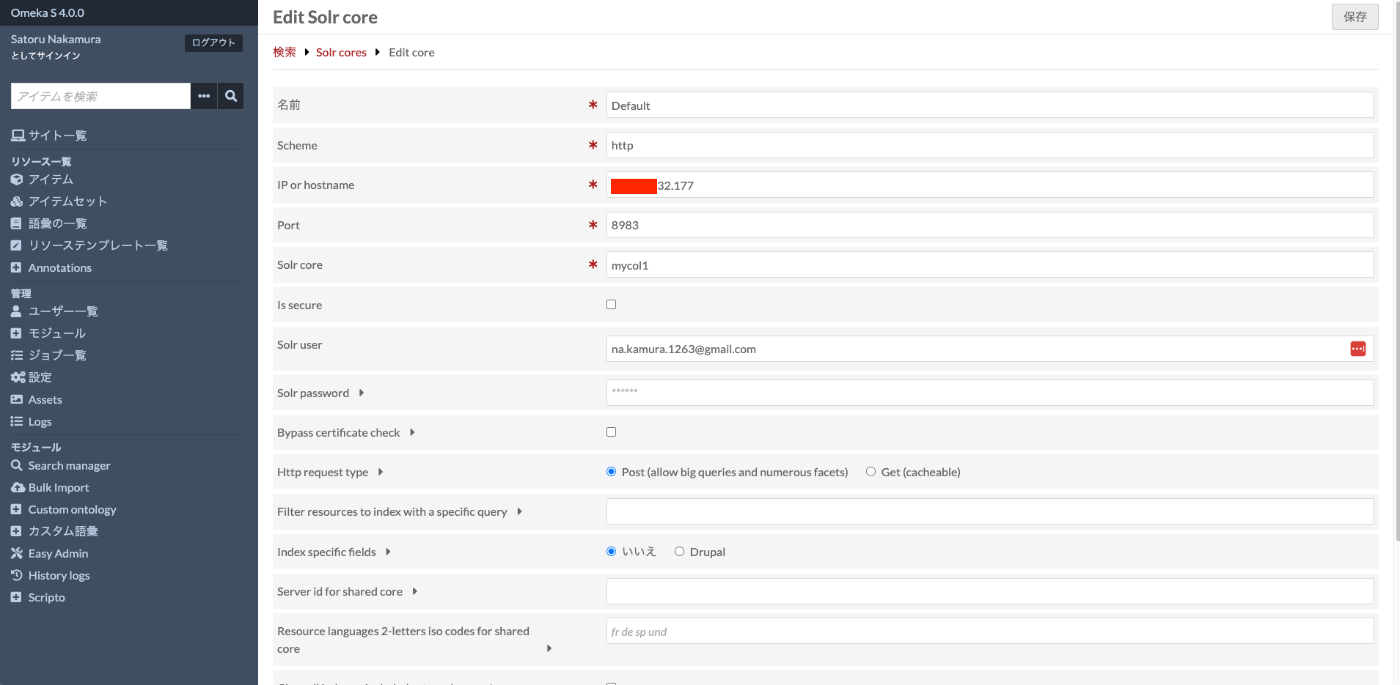
「Solr cores」にあるデフォルトのコアについて、鉛筆ボタンを押して、以下のページにアクセスします。このページにおいて、「IP or hostname」のフォームに、Apache SolrをインストールしたサーバのIPアドレスまたはホスト名を入力します。また「Solr core」には、先ほど作成したコア(ここでは、mycol1)を入力します。
</admin/search-manager/solr/core/1/edit>
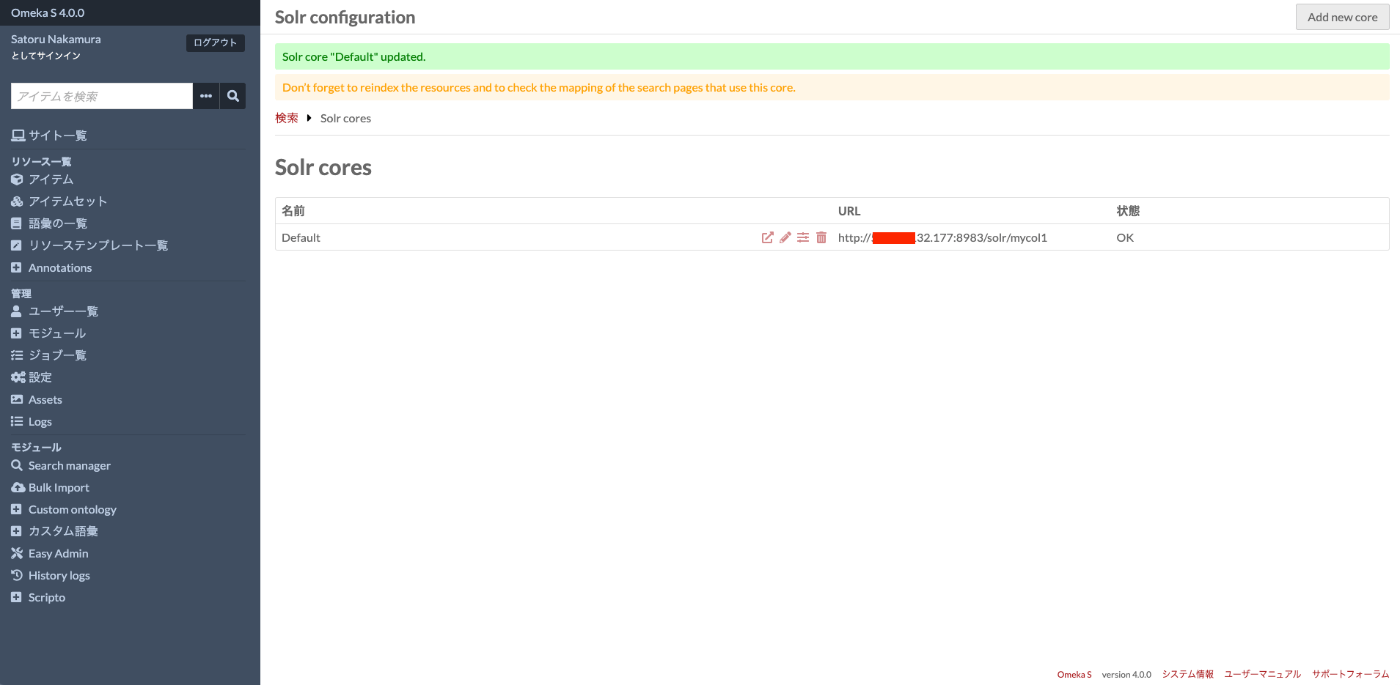
正しく設定できた場合、以下の画面のように、「状態」がOKになります。これで、Omeka SとApache Solrの接続が接続されたことになります。
インデックスとページの作成
ここでは、インデックスやページの作成を行い、Omeka Sでの検索画面の表示までを行います。
In Search admin
再度、以下の画面にアクセスします。
</admin/search-manager>
Add search engine
上記の画面において、画面右上の「Add new search engine」ボタンを押します。以下の画面において、適当な名前を入力して、「Adapter」項目で「Solr」を選択します。

そして、以下の画面で、「Reindex」のアイコンをクリックします。以下の画面右のように、再インデックスに関するブロックが表示されるため、「Confirm reindex」ボタンを押します。

これにより、Omeka SとApache Solrの同期が行われます。再インデックス完了後、Apache Solr側の管理画面を見てみると、(ここでは、3件の)ドキュメントが登録されていることが確認できます。
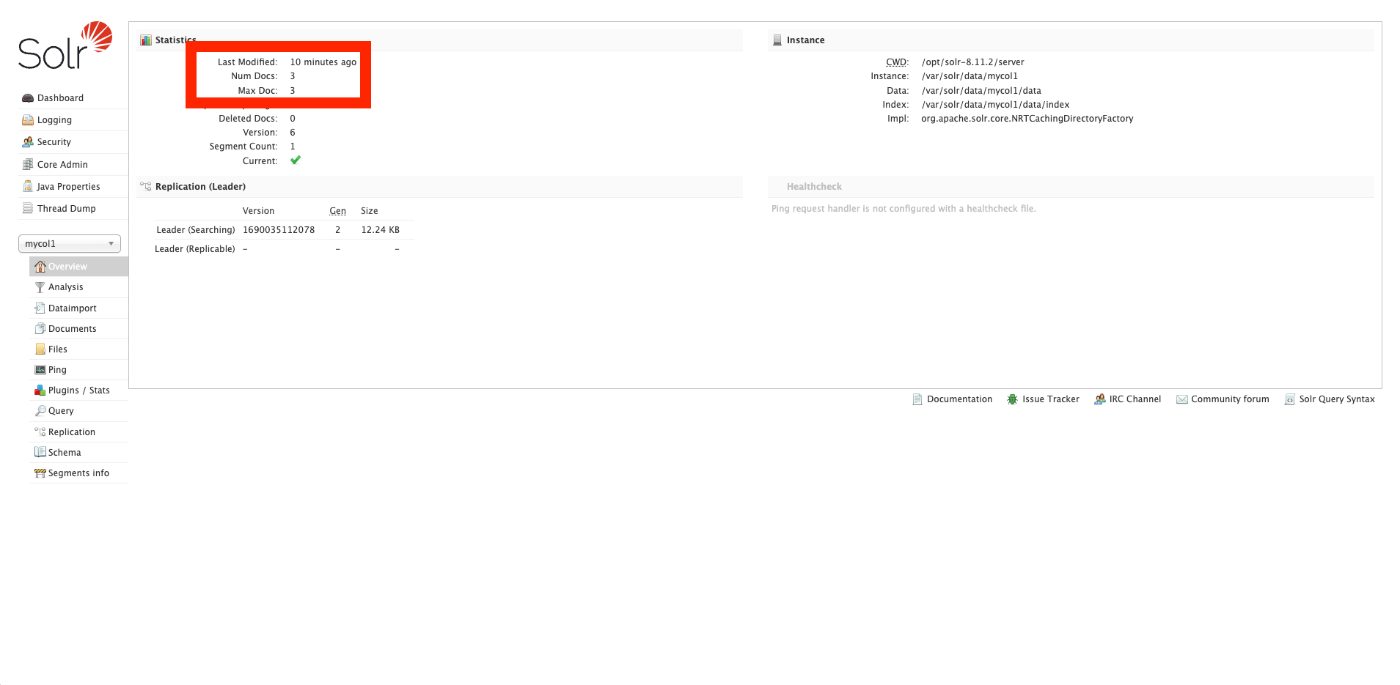
Create a page
次に、ページを作成します。再度、Search managerの管理画面にアクセスして、画面右上の「新規ページを追加」ボタンを押します。
以下の画面に遷移後、必須項目を入力します。以下が例です。
| 項目 | 値 |
|---|---|
| 名前 | page1 |
| Path | find |
| Search engine | engine1(先ほど作成したengineの名前) |
| Form | Main |
また、「Availability on sites」はとりあえず「Make available in all sites」を選択しておきます。
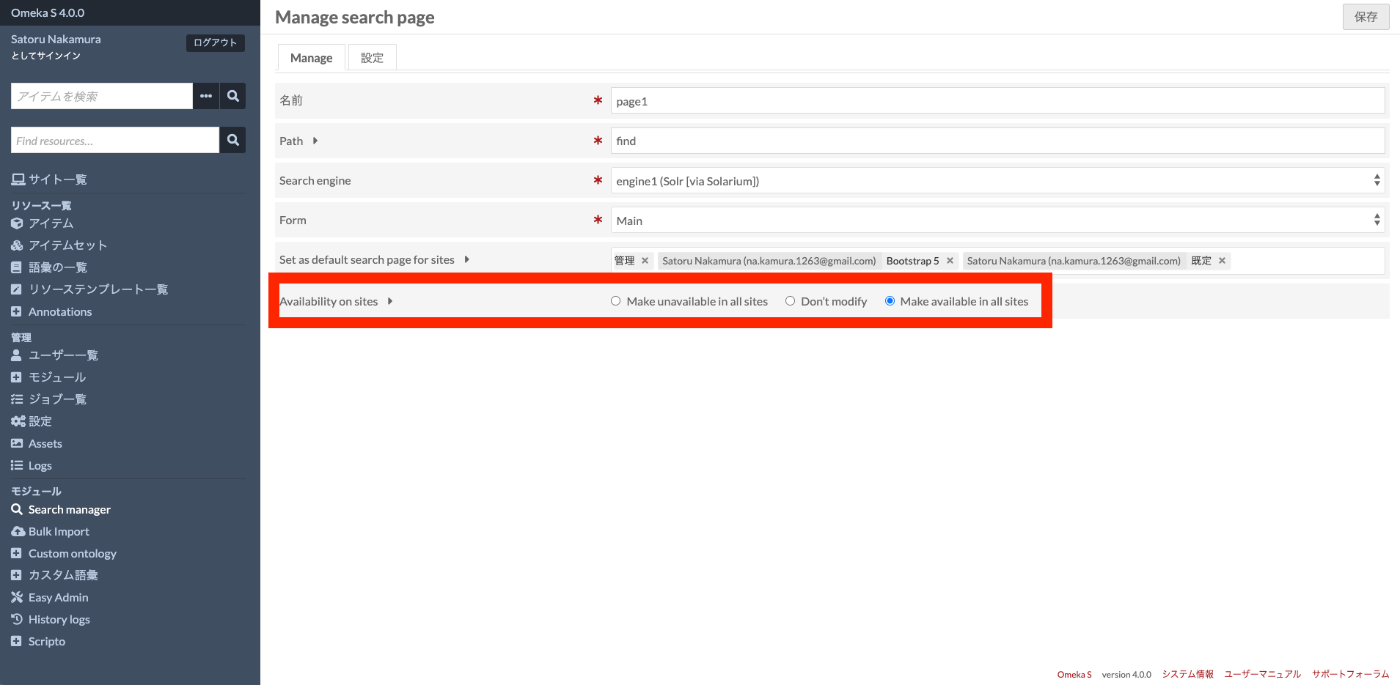
In admin or site settings
次は、Omeka Sのサイトに、作成したページを追加します。作成済みのサイト一覧から特定のサイトを選択して、「ナビゲーション」を選択します。以下の画面において、画面右側の「カスタムリンク追加」から「Advanced search page」を選択して、先ほど作成したページの名前(ここでは、page1)を選択します。
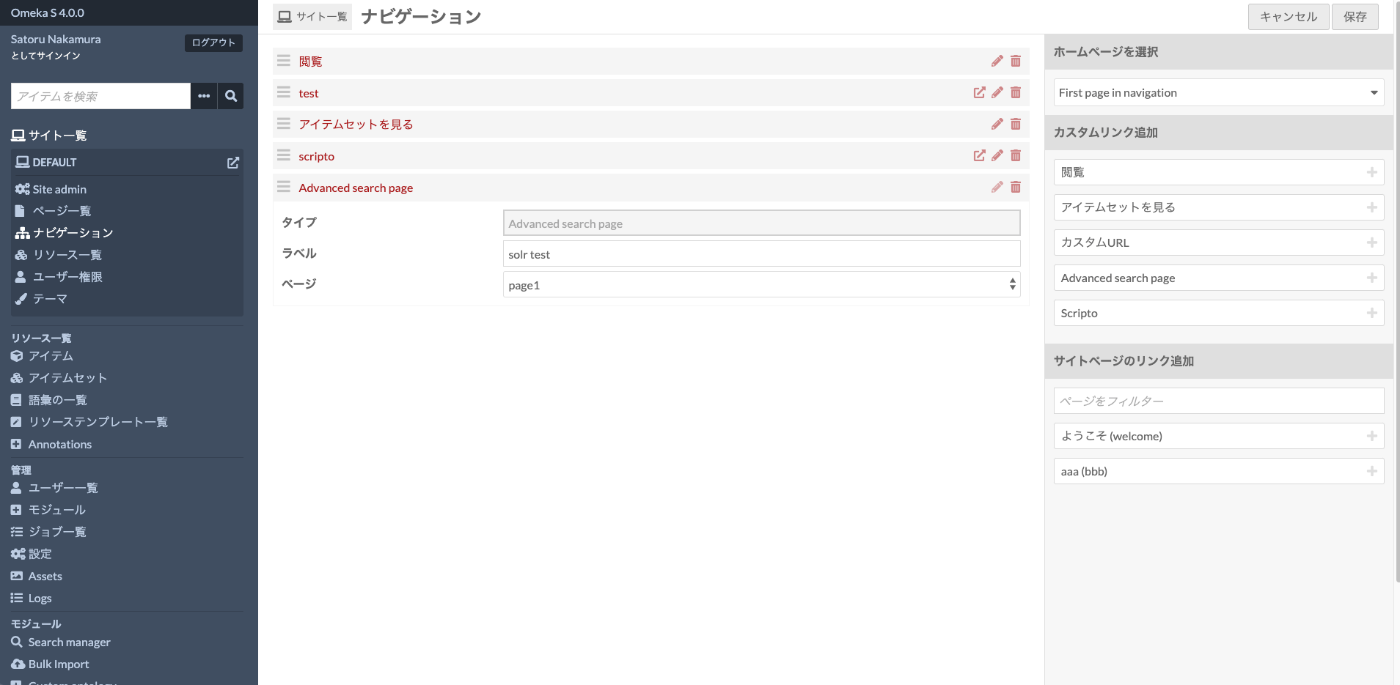
結果、以下のようなパス(先ほど設定したPath)で、Apache Solrへの問い合わせ結果を表示する検索ページにアクセスすることができます。
https://omekas.aws.ldas.jp/omeka4/s/default/find
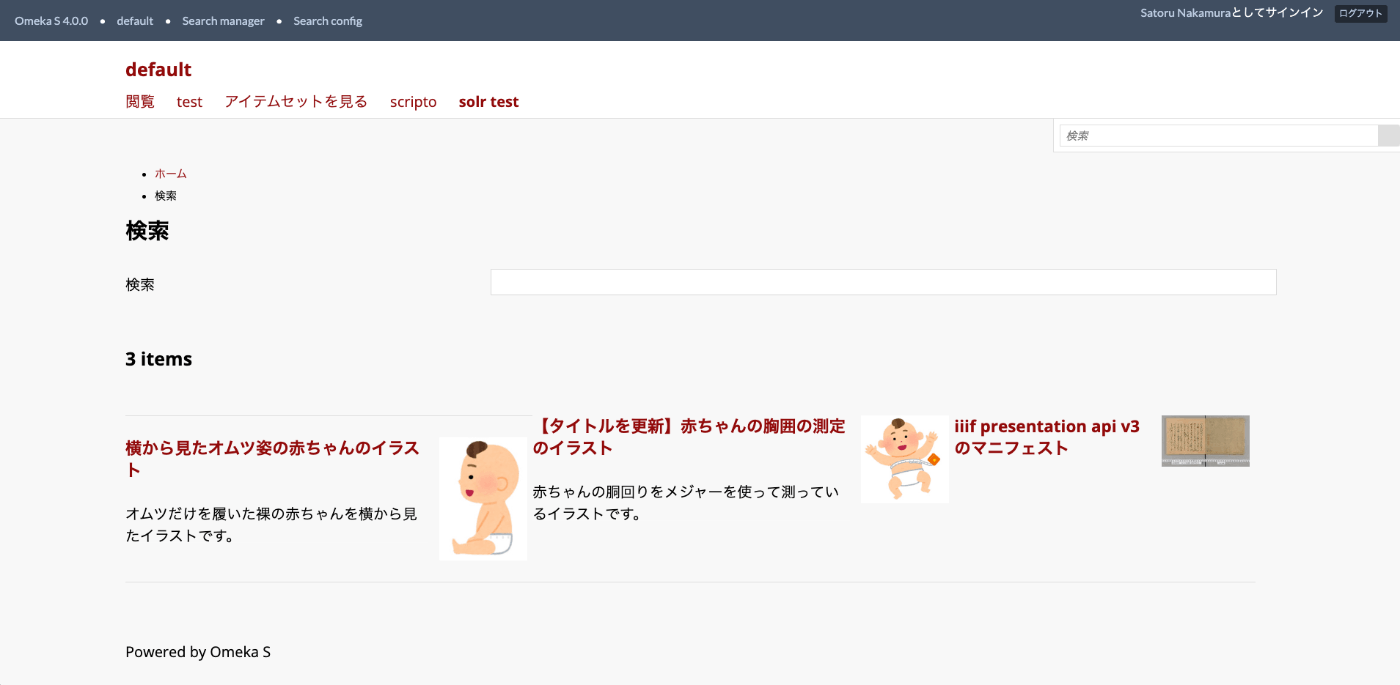
ただし、ここまでの設定では、ファセットなどの設定ができていないため、以後、各種設定を行います。
設定
Facet
まずファセットの設定方法について説明します。
Search managerページから、先ほど作成したページ(ここでは、page1)の鉛筆アイコンをクリックします。
以下の画面において、画面上部のタブ「設定」を選択します。
</admin/search-manager/config/1/configure>

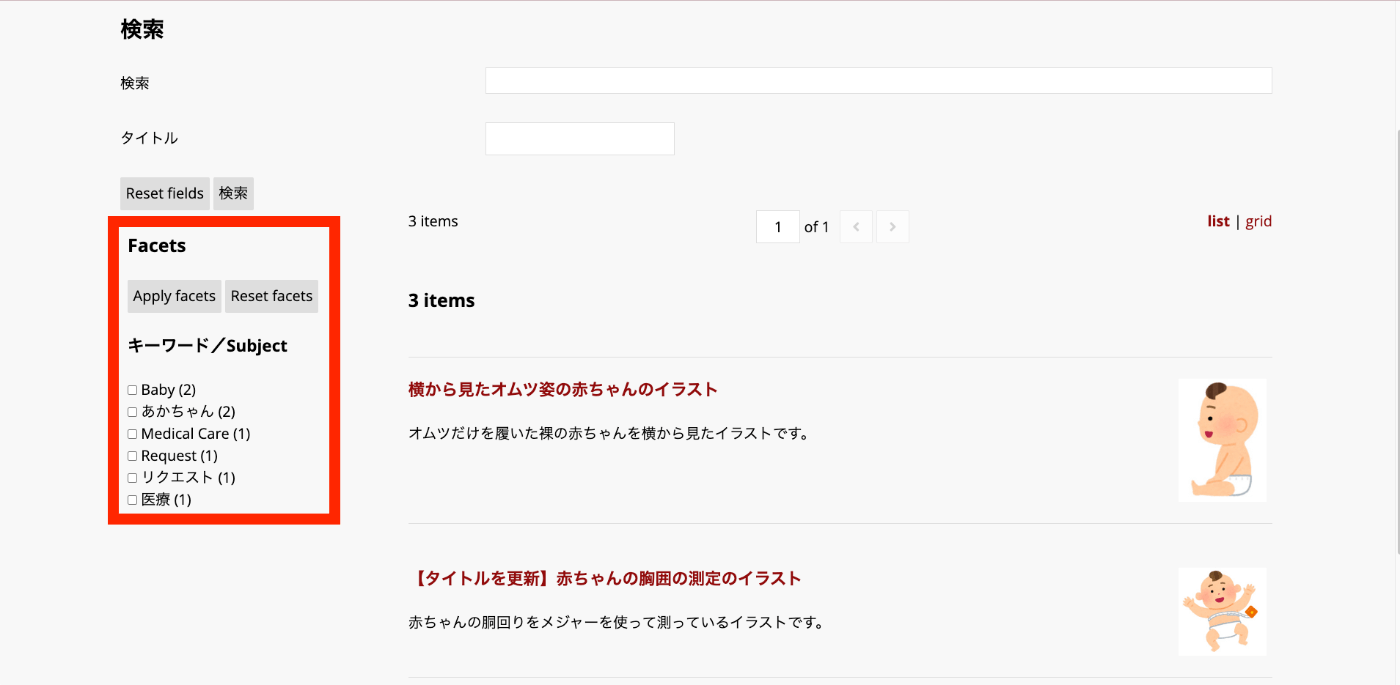
そして、以下のように、「Facets」と表示されている項目を編集していきます。
「Available facets」に表示されている行から、必要な行をList of facetsにコピペします。ここでは、以下のフィルタを追加してみます。
dcterms_subject_ss = Subject =

結果、先ほど作成したOmeka Sのサイトのページにファセットが表示され、値に基づく絞り込みができるようになります。

フィルター
次に、検索条件を指定するフィルタの設定方法です。
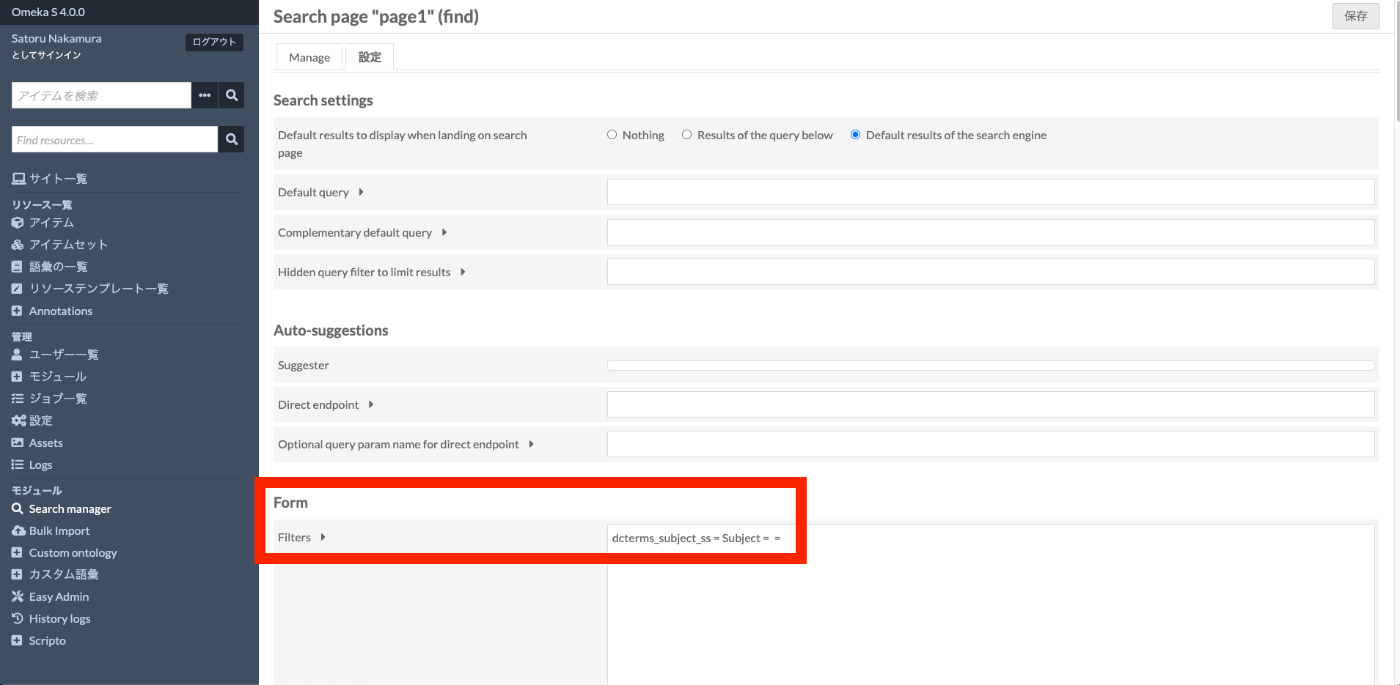
先のファセットと同様、「Available filters」に表示されている行から、必要な行をFiltersにコピペします。ここでは、以下のフィルタを追加してみます。
dcterms_subject_ss = Subject = =
</admin/search-manager/config/1/configure>
結果、以下のように、「キーワード/Subject」のフォームが追加されました。
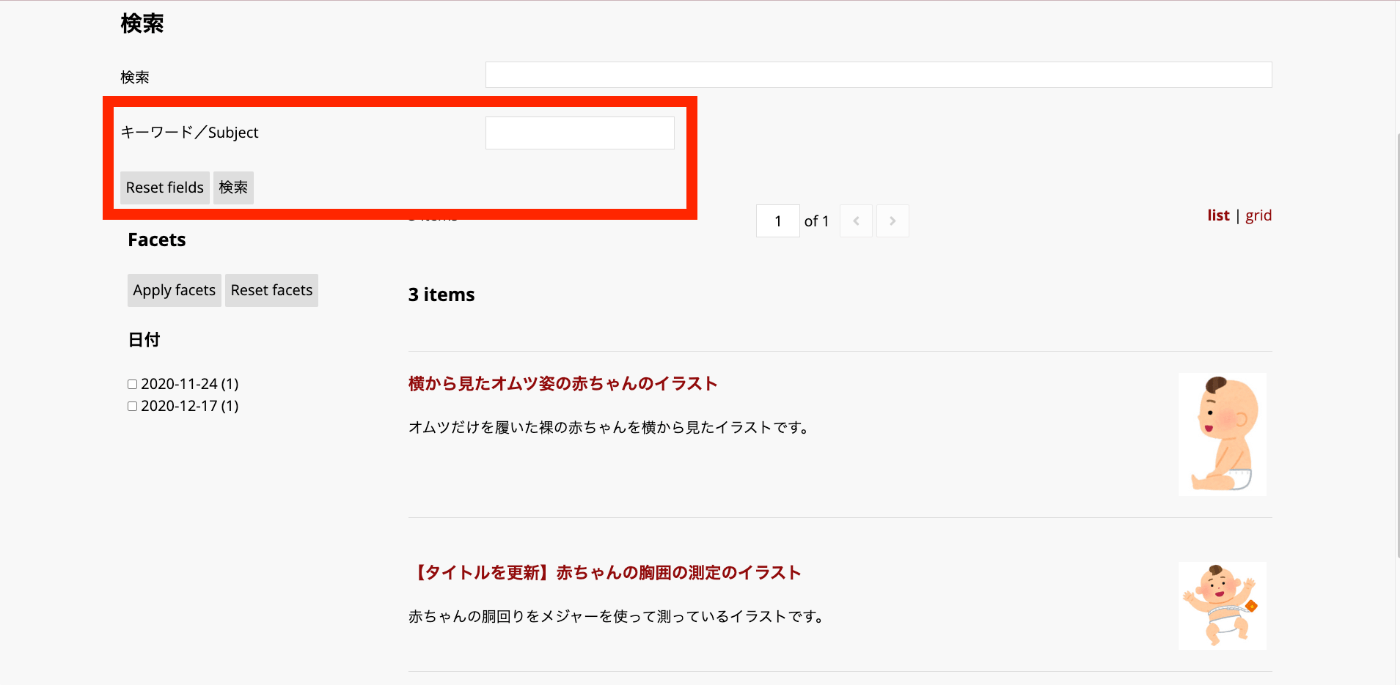
Advanced filters
「Advanced filters」は、利用者がフィルタの条件を動的に変更可能なフォームです。例えば、「Subject」と「Date」を「Advanced filters」に追加してみます。

サイトの検索ページにおいて、以下のようなフォームが表示されます。
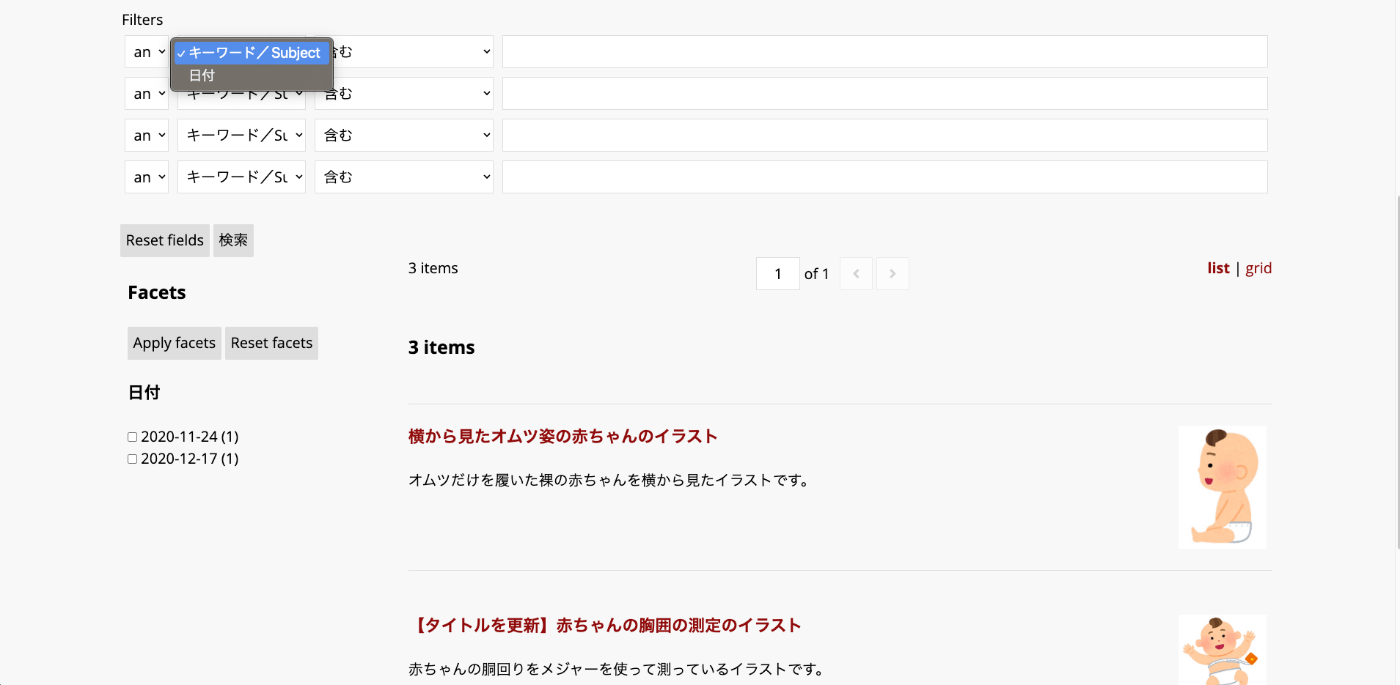
日付に11を含むで検索した例です。2020-11-24を日付にもつアイテムのみが取得できました。

その他
以下のような形で登録してみます。
dcterms_subject_ss = Subject = Select = あかちゃん |医療
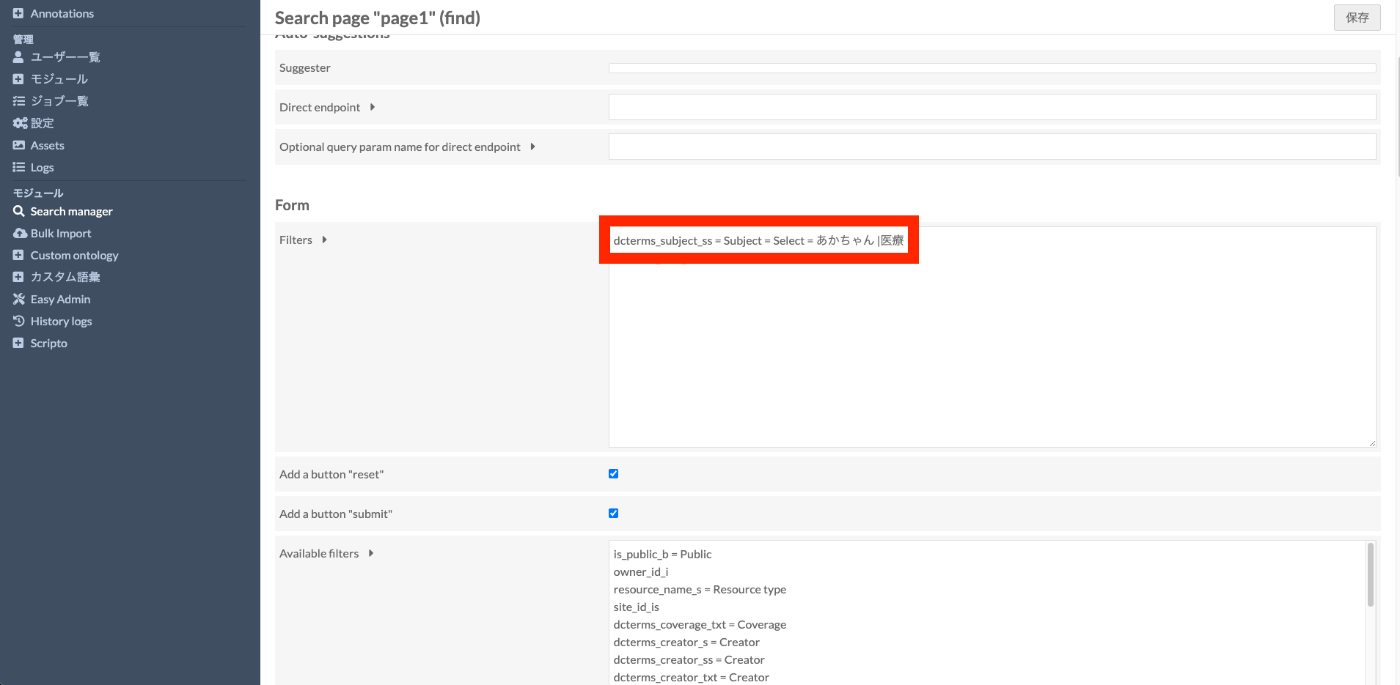
すると、以下のような形で、セレクトボックスとして利用できるようになりました。

ソート

https://omekas.aws.ldas.jp/omeka4/s/default/find

日本語対応
はじめに
上記の設定において、例えば、タイトルだけでも、以下の3種類のありました。これらは、Apache Solrへのインデクシングのされ方の違いを示しています。
- dcterms_title_s = Title
- dcterms_title_txt = Title
- dcterms_title_txt_ja = Title
例えば、文字列「横から見たオムツ姿の赤ちゃんのイラスト」を例とした場合、以下のようになります。
| 項目 | タイプ | ターム |
|---|---|---|
| dcterms_title_s | string | 横から見たオムツ姿の赤ちゃんのイラスト |
| dcterms_title_txt | text_general | 横,か,ら,見,た,オムツ,姿,の,赤,ち,ゃ,ん,の,イラスト |
| dcterms_title_txt_ja | text_ja | 横,見る,オムツ,姿,赤ちゃん,イラスト |
| dcterms_title_txt_cjk | text_cjk | 横か,から,ら見,見た,たオ,オム,ムツ,ツ姿,姿の,の赤,赤ち,ちゃ,ゃん,んの,のイ,イラ,ラス,スト |
-
*_txtはStandardTokenizerFactoryトークナイザー(?)が適用され、連続するカタカナは1ターム、その他は1文字単位でインデックスされるようでした。(あまり自信がありません。) -
*_txt_jaはJapaneseTokenizerFactoryトークナイザーなどが適用され、形態素でインデックスされています。 -
*_txt_cjkはCJKBigramFilterFactoryフィルタが適用されるため、2文字ずつインデックスされます。
上記のような違いがあるため、Omeka SのフィールドをApache Solorでどのように扱うかを、目的に応じて設定する必要があります。
CJKフィルタ
solr map
例えば、タイトルの値を2文字ずつインデックスする*_txt_cjkを追加してみます。
Search managerの画面で、Solr coreの「Map Omeka metadata and Solr fields」を選択して、「Resource(またはItem)」を選択して、画面右上の「Add new map」ボタンを押します。
以下のような画面に遷移するので、「Solr field」で「*_txt_cjk」を選択します。
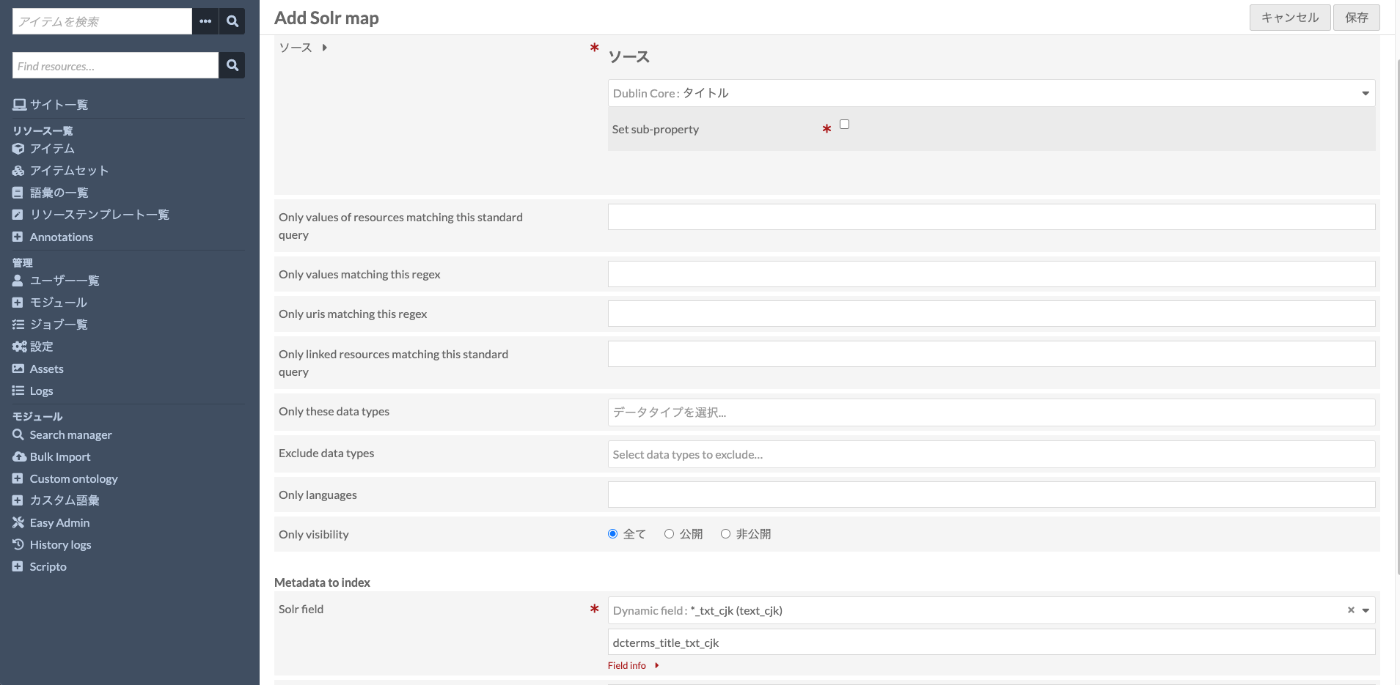
その後、再インデックスなどを行います。
Filters
そして、先ほどのFiltersの設定を参考に、「dcterms_title_txt_cjk」を以下のように追加してみます。
</admin/search-manager/config/1/configure>

サイト
この結果、以下のような違いが生まれます。
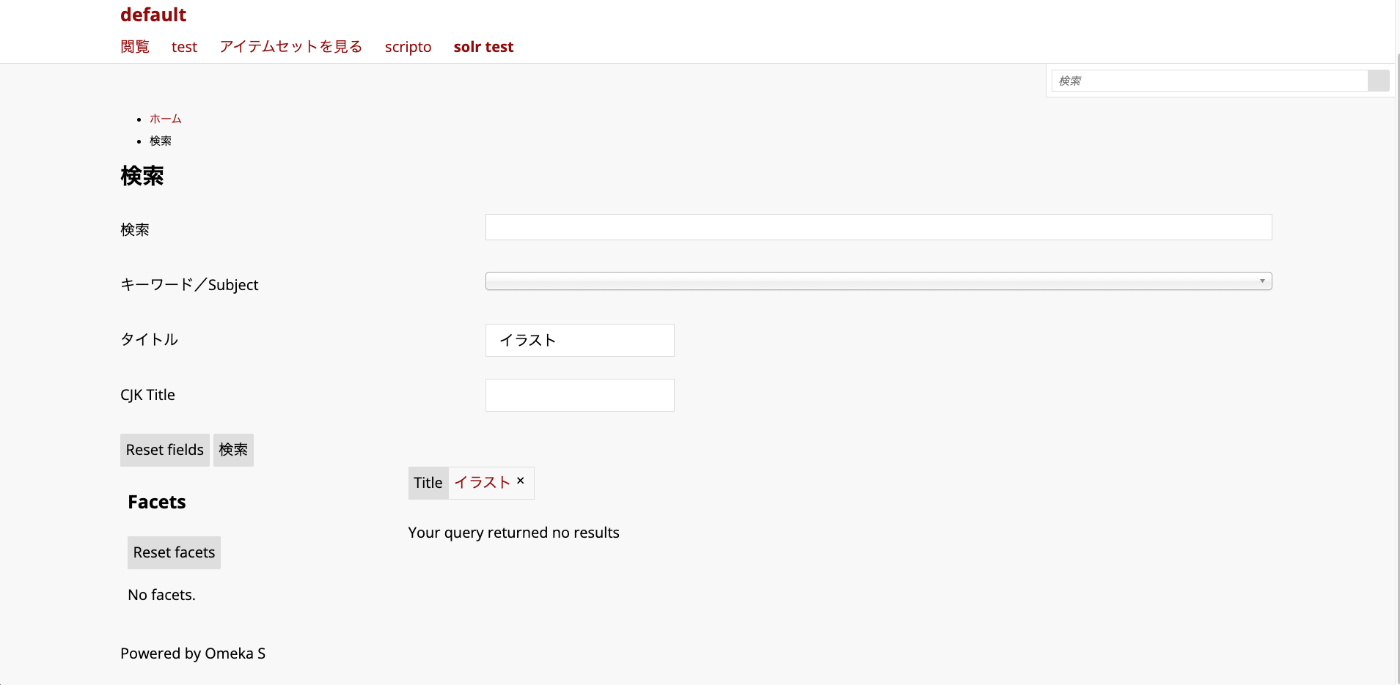
dcterms_title_s=イラストによる検索では、横から見たオムツ姿の赤ちゃんのイラストなどの文字列でインデックスされるため、完全に一致するアイテムがなく、結果が0件になります。
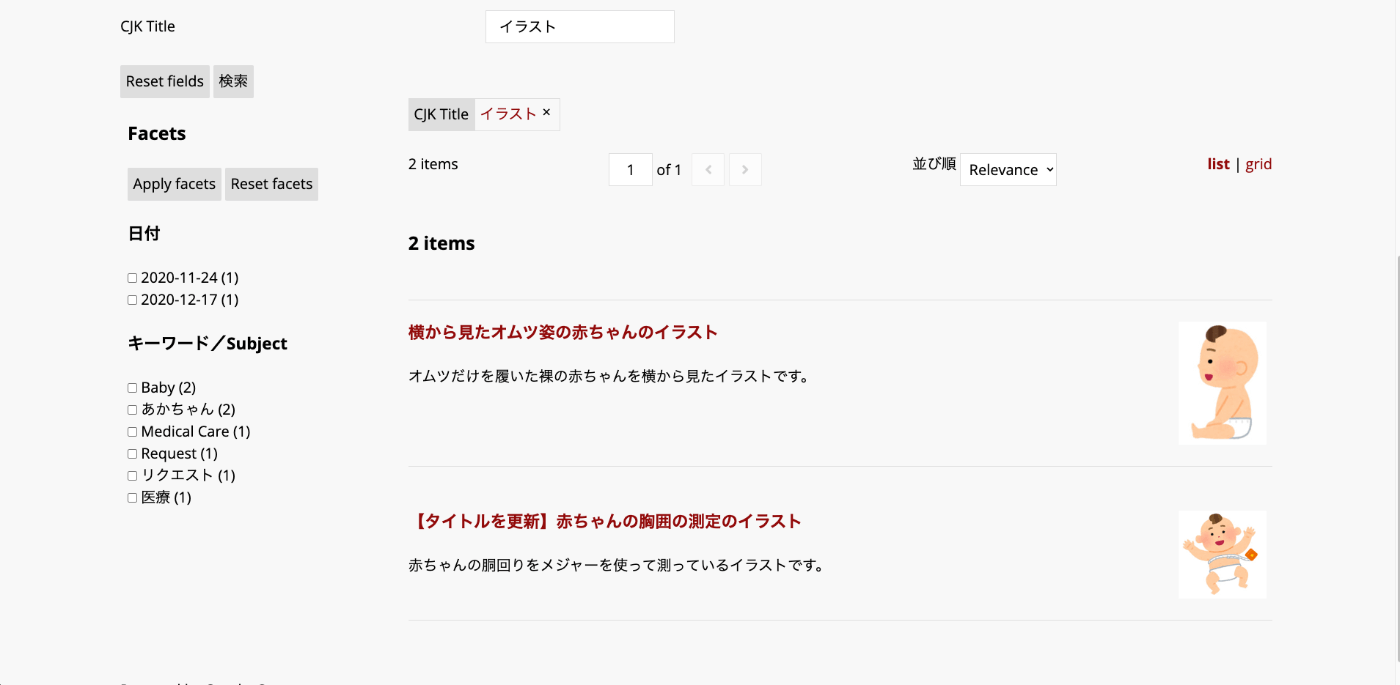
一方、dcterms_title_txt_cjk=イラストによる検索では、イラ,ラス,ストなどの文字列でインデックスされており、検索語のイラストも同様に処理されるため、文字列イラストを含む2件のアイテムがヒットします。
参考
_txt_cjkと_txt_ja、それぞれのインデックスのされ方を確認します。
_txt_cjk
対象文字列
- 横から見たオムツ姿の赤ちゃんのイラスト
- 【タイトルを更新】赤ちゃんの胸囲の測定のイラスト
- iiif presentation api v3のマニフェスト
結果
</solr/#/mycol1/schema?field=dcterms_title_txt_cjk>
| Term Frequency | Term |
|---|---|
| 3 | スト |
| 2 | イラ |
| ゃん | |
| んの | |
| のイ | |
| ラス | |
| 赤ち | |
| ちゃ | |
| 1 | ら見 |
| の赤 | |
| たオ | |
| フェ | |
| ムツ | |
| を更 | |
| presentation | |
| の胸 | |
| オム | |
| の測 | |
| から | |
| ェス | |
| タイ | |
| ツ姿 | |
| トル | |
| ニフ | |
| 測定 | |
| マニ | |
| のマ | |
| 更新 | |
| ルを | |
| 囲の | |
| 定の | |
| 姿の | |
| イト | |
| 横か | |
| v3 | |
| 胸囲 | |
| 見た | |
| iiif | |
| api |
英語を除き、2文字ずつに分割した文字列がインデクシングされていることが確認できます。
例えばストが3件になっていますが、イラスト、マニフェストの両方に含まれているためであることがわかります。
_txt_ja

対象文字列
- 横から見たオムツ姿の赤ちゃんのイラスト
- 【タイトルを更新】赤ちゃんの胸囲の測定のイラスト
- iiif presentation api v3のマニフェスト
結果
</solr/#/mycol1/schema?field=dcterms_title_txt_ja>
| Term Frequency | Term |
|---|---|
| 2 | 赤ちゃん |
| イラスト | |
| 1 | iiif |
| v | |
| 横 | |
| オムツ | |
| マニフェスト | |
| タイトル | |
| 姿 | |
| 更新 | |
| presentation | |
| 測定 | |
| 胸囲 | |
| 見る | |
| api | |
| 3 |
助詞などが除外され、赤ちゃん、イラストといった形態素に分解されてインデクシングされていることが確認できます。
比較
dcterms_title_s=ストでは、0件の結果が得られます。イラストやマニフェストという形態素でインデックスされているためです。
一方、dcterms_title_txt_cjk=ストでは3件の結果が得られます。しかし、dcterms_title_txt_cjk=イラストだと検索結果数は2件になります。これは、イラ、ラス、ストの3つ全てがインデックスに含まれるデータのみがヒットするため、イラストという文字列を含むデータはヒットする一方、マニフェストという文字列を含むデータはヒットしないことになります。
まとめ
Omeka SとApache Solrの接続方法について紹介しました。Omeka Sで形態素解析などを含む高度な検索を行いたい場合には、有用な選択肢になるかと思います。
不正確な内容を一部含むかもしれませんが、参考になりましたら幸いです。
Discussion
Why can’t find the _txt_cjk and _txt_jp file in the solr field ,in the drop-down box of Settings Search manager—solr cores—add solr map—metdate to index?