Unity 最適化 メモ2

メモしたの書きなぐります。
・Normals Mode
Unity による法線の計算方法を定義。Normals、Blend Shape NormalsがCalculateのみ場合適用される。
①Unweighted Legacy
古い計算方法。
②Unweighted
法線にウェイトしない
③Area Weighted
法線は面の範囲をウェイトとして使用
④Angle Weighted
法線は各面の頂点角度をウェイトとして使用
⑤Area and Angle Weighted
法線は各面の表面範囲と頂点角度をウェイトとして使用
Blenderとかにある重みつき法線のこと指していると思われる。正直よくわからない。。。
一応どんな見た目とパフォーマンスになるのか実験してみた。
陰影の違いやソフトエッジとハードエッジで分けられていることが分かる。
CPUとGPUの負荷が低いのは、
Unweighted Legacy、Unweighted、Area Weighted≒Area and Angle Weighted、Angle Weighted
の順である。
Unweighted Legacy
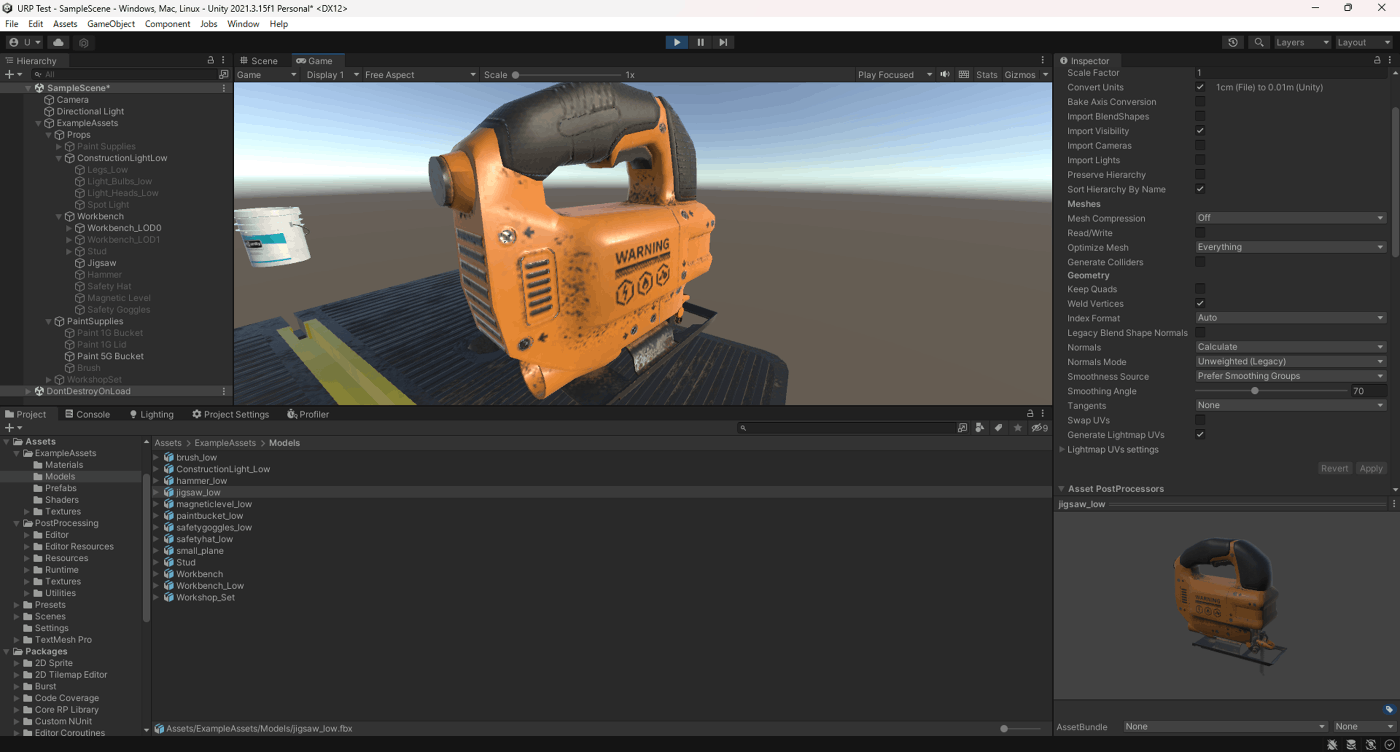

Unweighted


Area Weighted
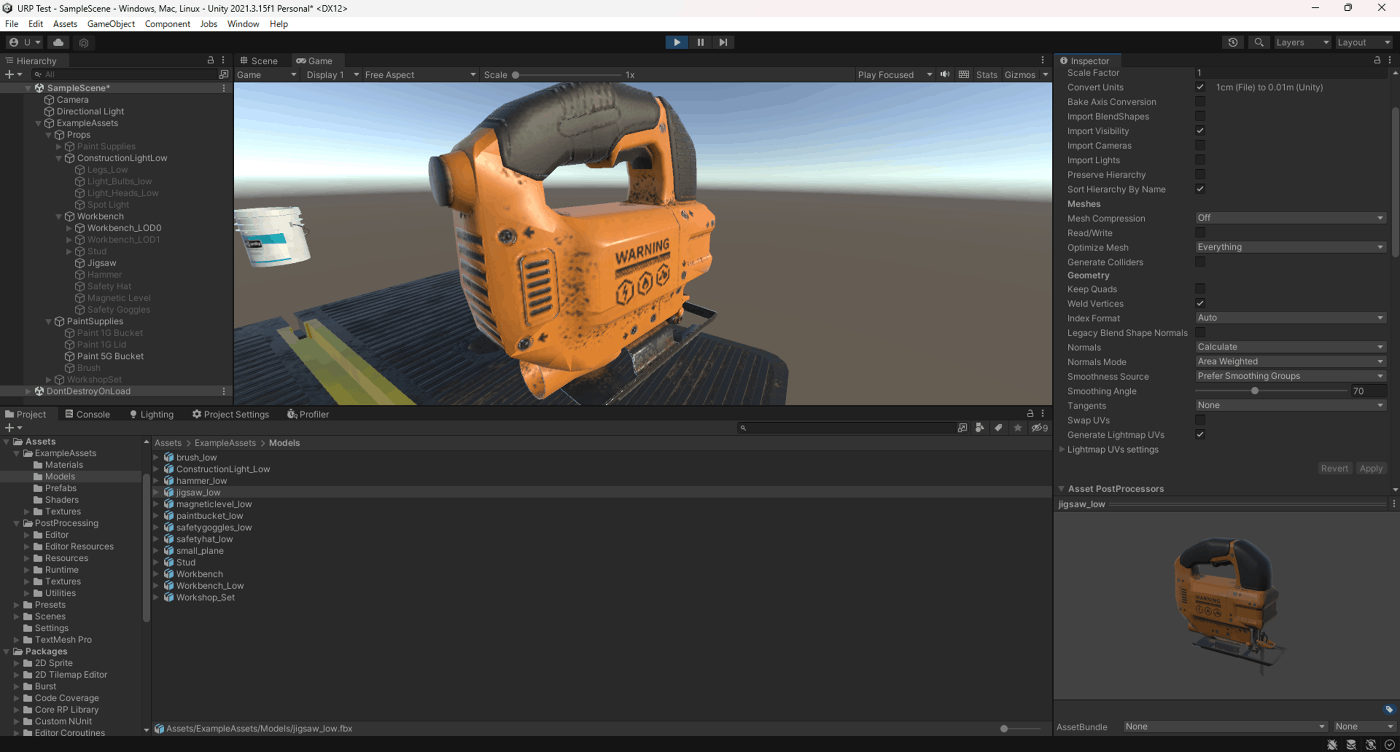

Angle Weighted
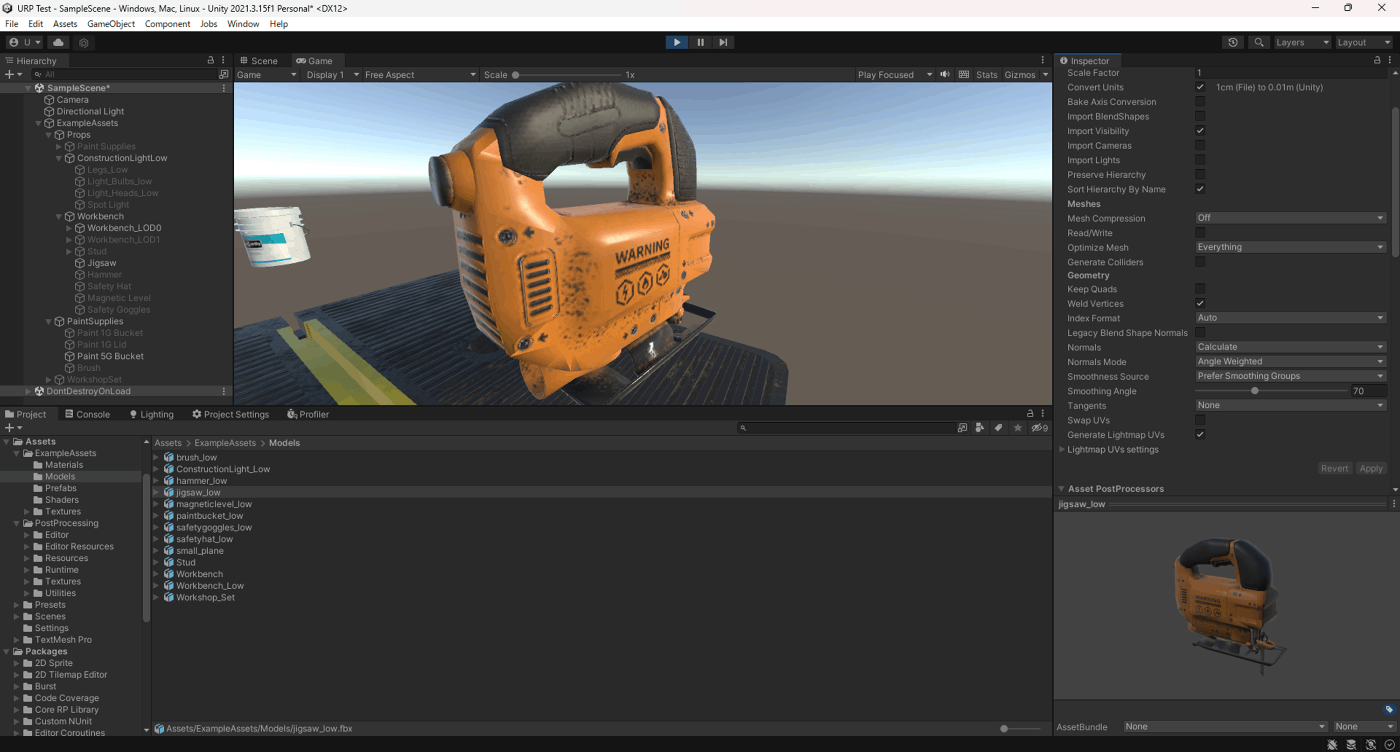

Area and Angle Weighted


参照サイト、参照サイト、参照サイト
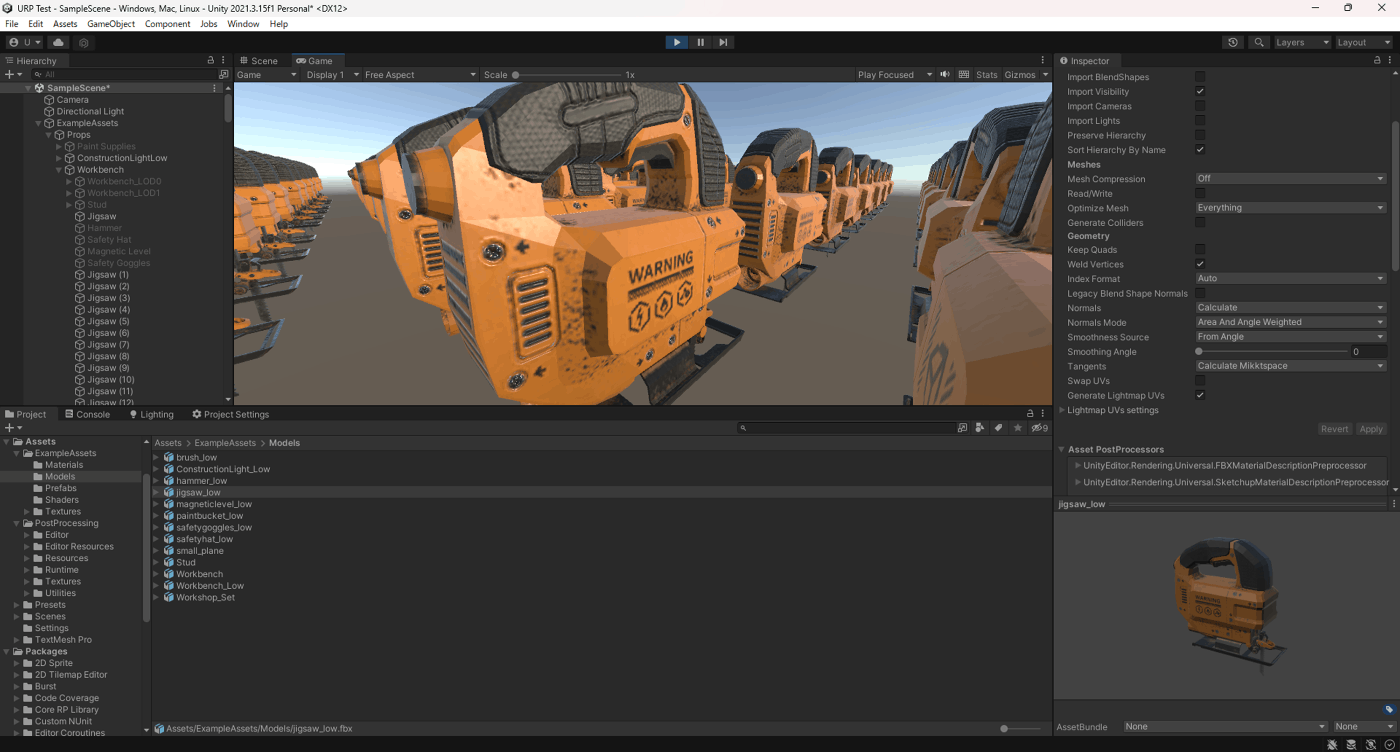
・Smoothness Source
エッジの調整を行う。Normals、Blend Shape NormalsがCalculateのみ場合適用される。
①Prefer Smoothing Groups
可能であれば、モデルファイルからスムージンググループを使用します。
②From Smoothing Groups
モデルファイルからのスムージンググループのみを使用します。
③From Angle
Smoothing Angle の値を使って、滑らかにするエッジを決定します。
④None
ハードエッジで頂点を分割しません。
一応実験してみた。
見た目は、
Prefer Smoothing GroupsとFrom Smoothing Groupsはほかの二つと比べてエッジがないことが分かる。
From Angleは、Noneよりエッジがないこと分かる。
パフォーマンスは、
GPU以外は誤差である。
GPUに関しては、From Smoothing Groupsはファイルから参照しているためランタイムで処理せずにすむので負荷がかかってないのかもしれない。
| PreferSmoothingGroups | FromSmoothingGroups | FromAngle | None | |
|---|---|---|---|---|
| CPU | 502ms | 492ms | 490ms | 493ms |
| GPU | 27,184ms | 6,319ms | 47,218ms | 39,379ms |
| メモリ | 3.67GB | 3.67GB | 3.67GB | 3.66GB |
| ディスク | 89.5MB | 89.5MB | 89.5MB | 89.6MB |
Prefer Smoothing Groups

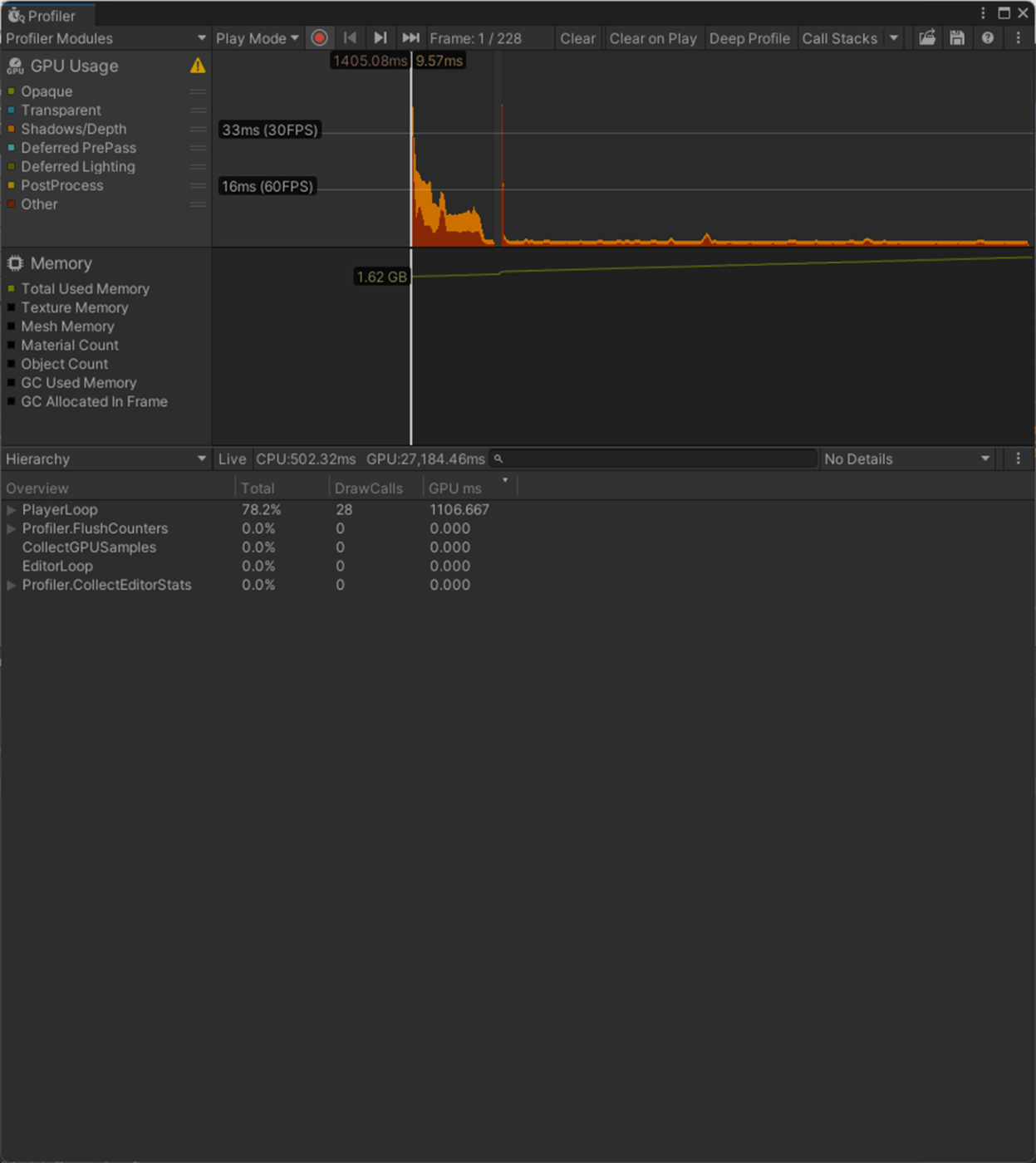
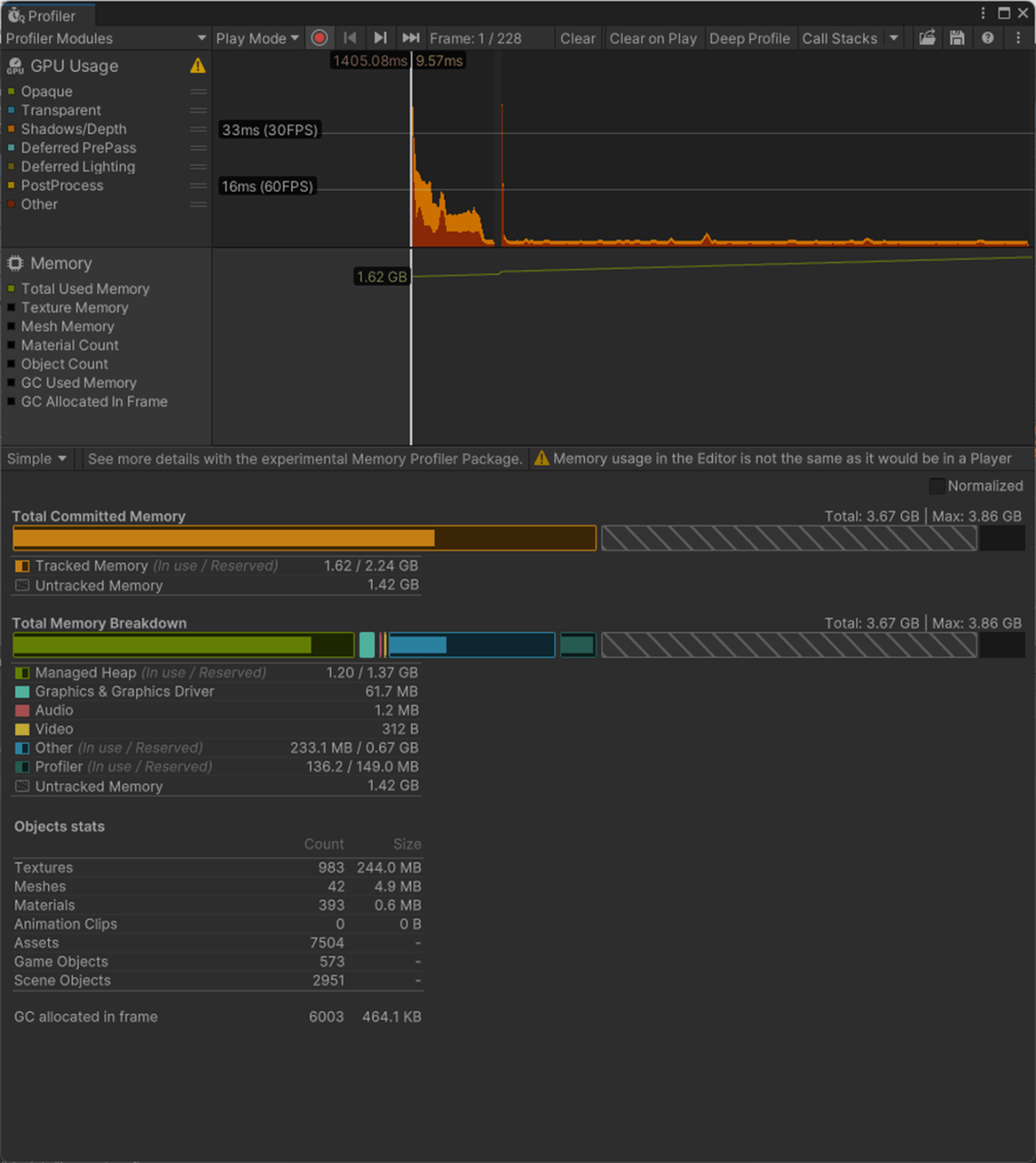

From Smoothing Groups

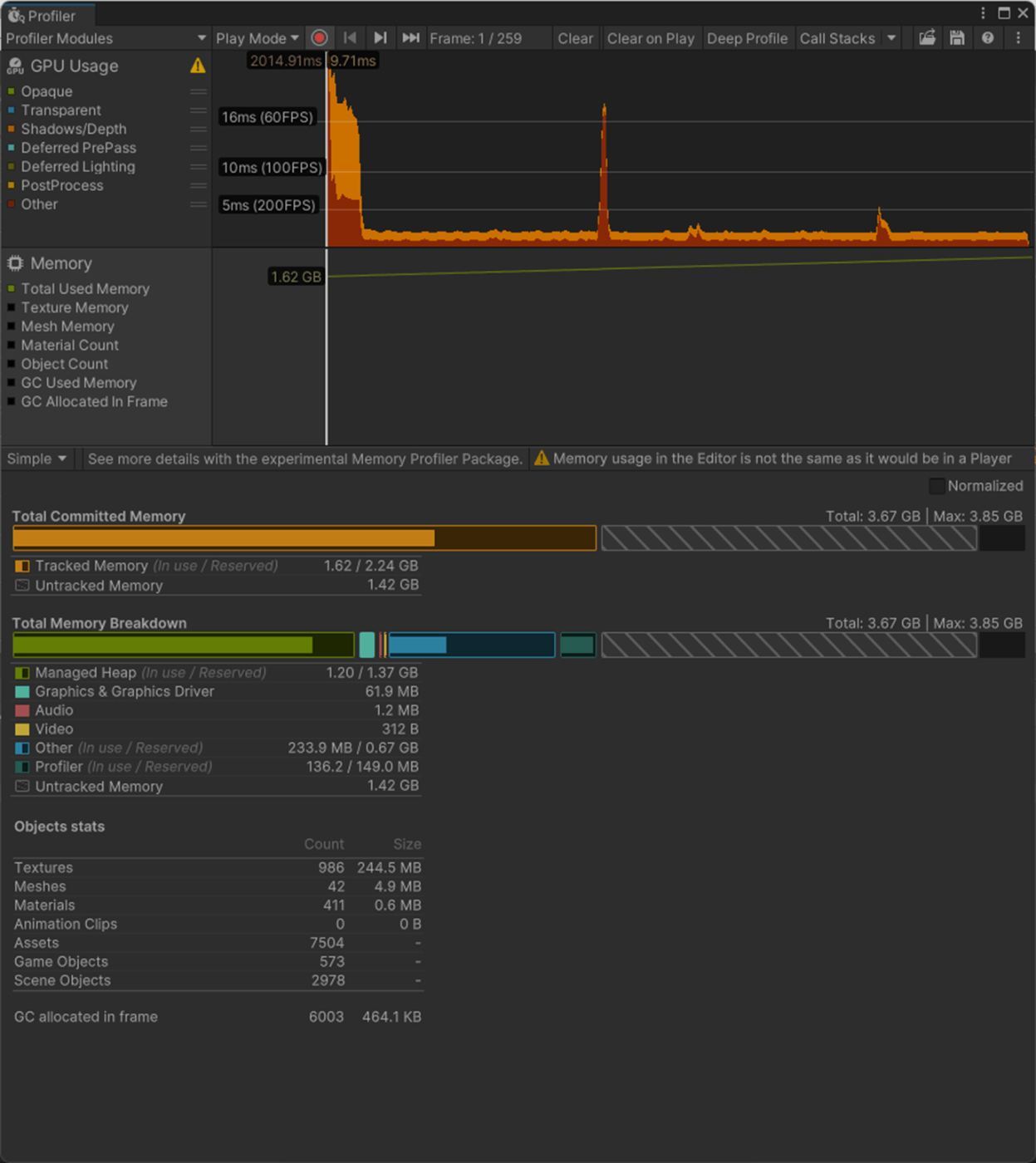

From Angle

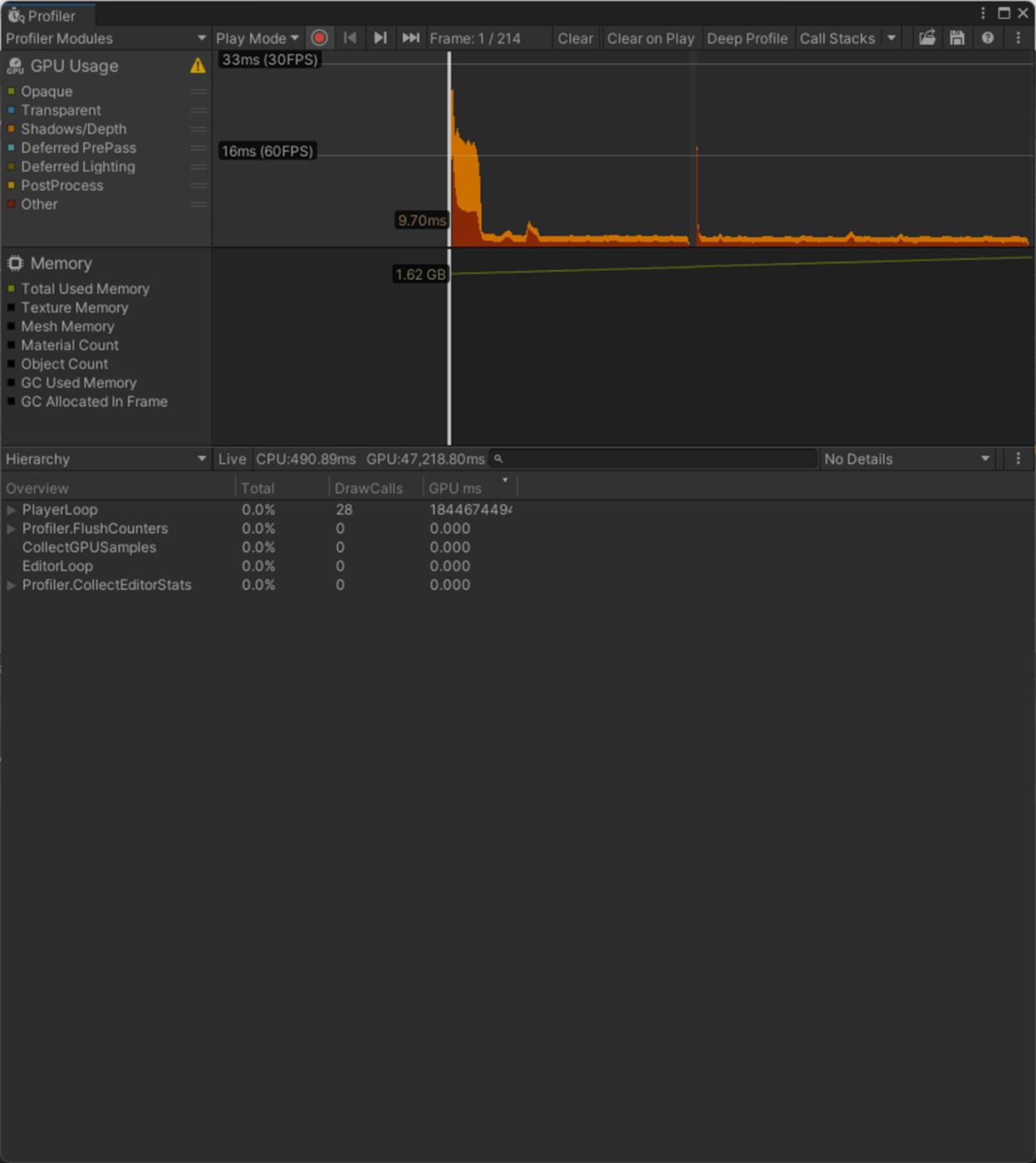


None


参照サイト、参照サイト、参照サイト
・Smoothing Angle
頂点がハードエッジに分割されるかどうかを制御します。
実験してみた。
この値が大きいほど、ハードエッジになっていることが分かる。
また、パフォーマンスはこの値が大きいほどGPUに負荷がかかっていないことが分かる。
Smoothing Angleが0

Smoothing Angleが30


参照サイト
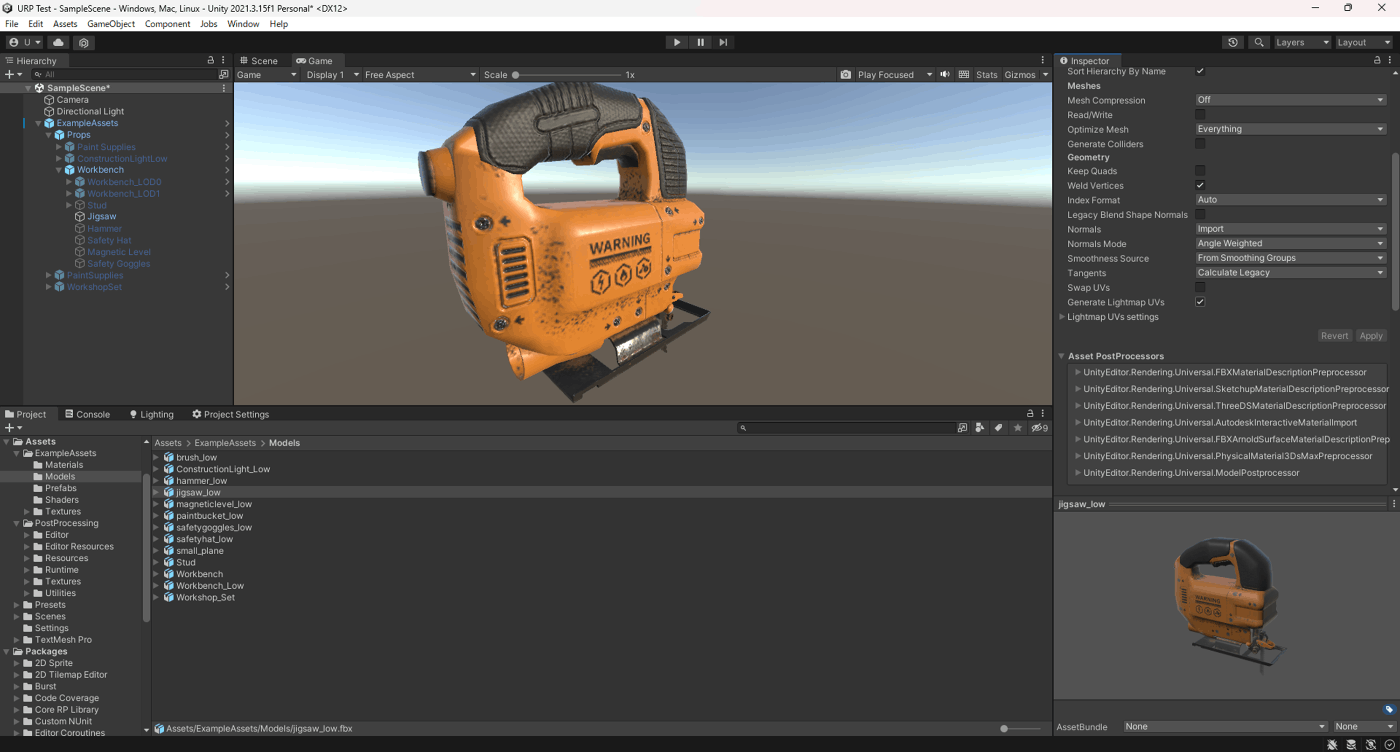
・Tangents
Unity による接線の計算方法を定義する。
NormalモードがCaculateの場合は、Normalモードで設定された法線とTangentsで(Import 以外)設定された設定で従法線を算出する。
NormalモードがImportの場合は、fbxの法線とTangentsで設定された設定で従法線を算出する。
①Import
NormalsがImport に設定されている場合、FBX ファイルから頂点接線をインポートします。メッシュに接線がない場合は、法線マップしたシェーダーとは使用できません。
②Calculate Legacy
以前のアルゴリズムで接線を計算します
③Calculate Legacy With Split Tangent
UV チャート全体を分割して、古い非推奨のアルゴリズムで接線を計算します。法線マップのライトがメッシュの継ぎ目によって壊れている場合はこれを使用します。 これは通常キャラクターにのみ適用されます。
④Calculate MikkTSpace
MikkTSpace を使って接線を計算します。
⑤None
頂点接線をインポートしません。メッシュに接線がないため、法線マップしたシェーダーとは使用できません。
一応実験してみた。
見た目は、
このモデルはImportとNoneだとFBXファイルに、RenderDocで確認したところメッシュに接線ないので法線マップが適用されていないので凸凹がないのが分かる。

それ以外の設定では、Unity側で接線を計算しているので、法線マップが適用されているので凸凹があるのが分かる。
パフォーマンスは、
GPU以外は軒並み同じである。
Importの場合は、メッシュに法線がないので負荷が低いのかと思われる、
Calculate MikkTSpaceは、Calculate LegacyとCalculate Legacy With Split Tangentと比べて新しい接線の計算方法で推奨されているものなので負荷が低い、
| Import | Calculate Legacy | Calculate Legacy With Split Tangent | Calculate MikkTSpace | None | |
|---|---|---|---|---|---|
| CPU | 498ms | 492ms | 506ms | 509ms | 503ms |
| GPU | 37,980ms | 147,561ms | 1,554,638ms | 103,760ms | 114,797ms |
| メモリ | 3.61GB | 3.82GB | 3.75GB | 3.76GB | 3.76GB |
| ディスク | 89.4MB | 89.5MB | 89.5MB | 89.5MB | 89.4MB |
Import




Calculate Legacy



Calculate Legacy With Split Tangent

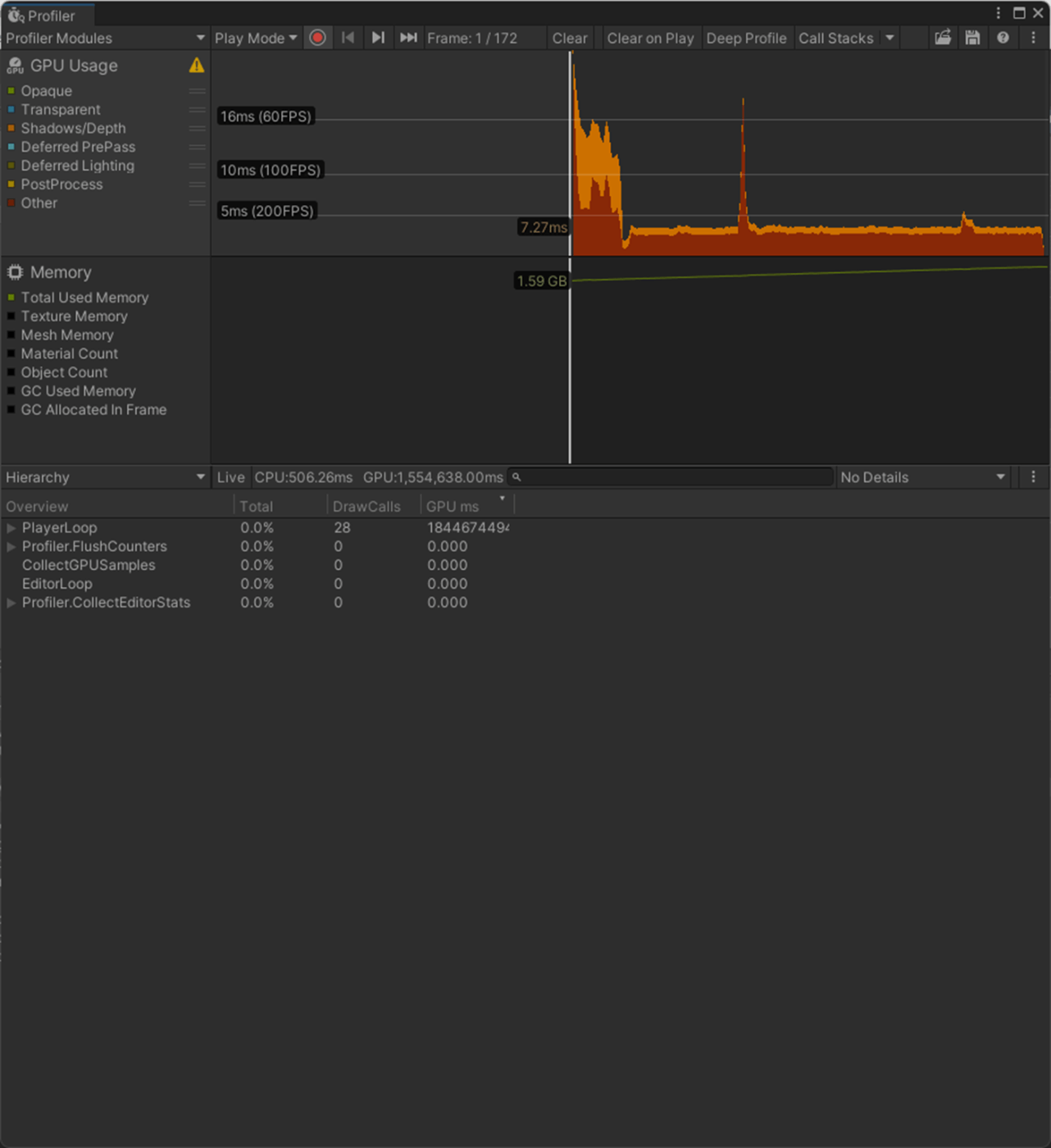


Calculate MikkTSpace




None




・アニメーションのループの最適化していないと、不自然なアニメーションになる。 参照サイト
・Max Bone Weight
ボーンウェイト (重み) を考慮するための最低のしきい値を設定します。ウェイトの計算でこの値より小さいものは無視される。
一応、実験してみた。
0.001のほうが負荷が低いことが分かる。
①Max Bone Weightが0.001

①Max Bone Weightが0.5
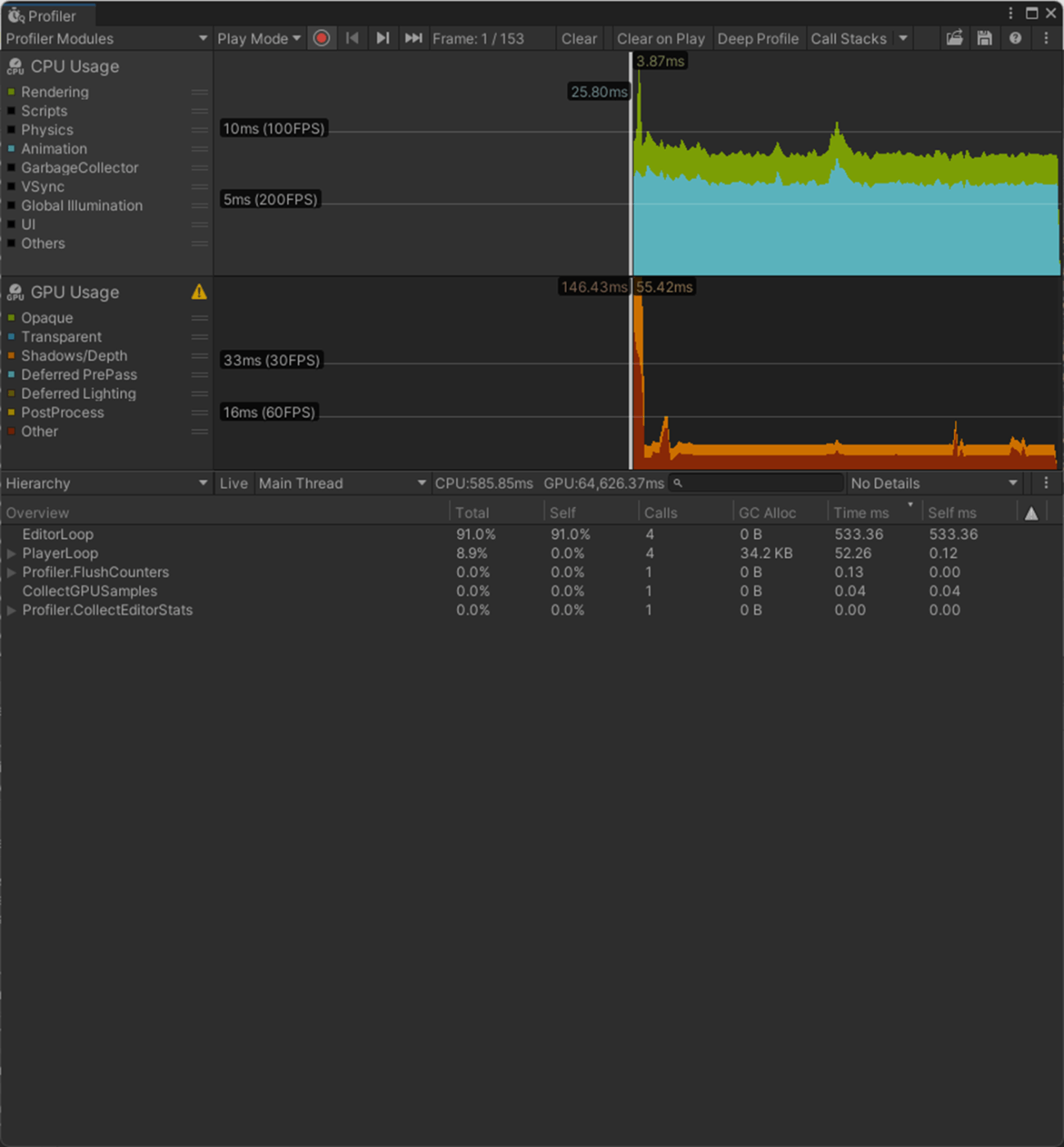
参照サイト
・Strip Bones
公式ドキュメントにのっていない。
おそらく不要なBoneを削除するもので、パフォーマンスに影響ありそう。
一応実験してみた。
GPUがかなりパフォーマンス改善されていることがわかる。
Strip Bonesオフ
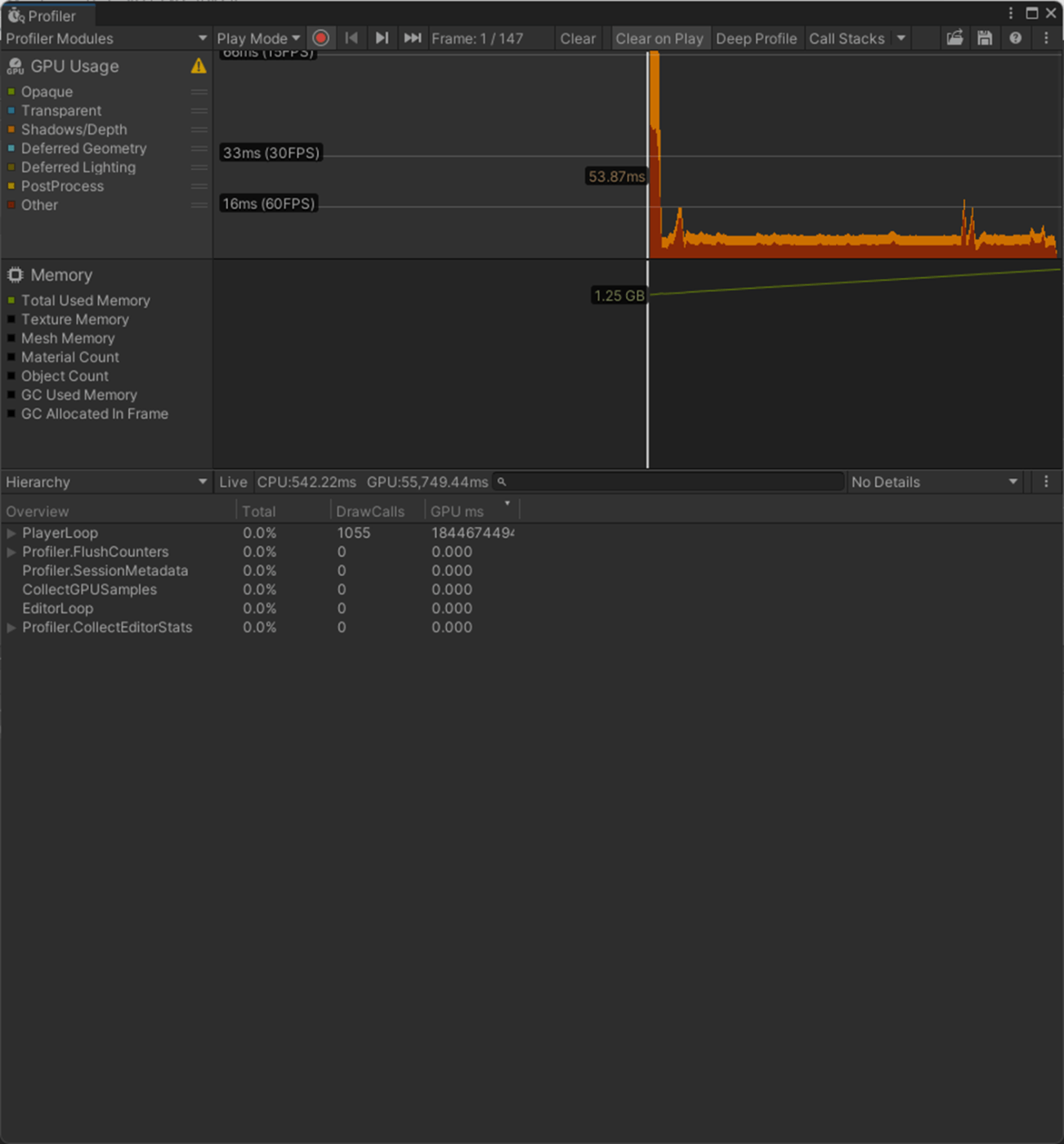
Strip Bonesオン
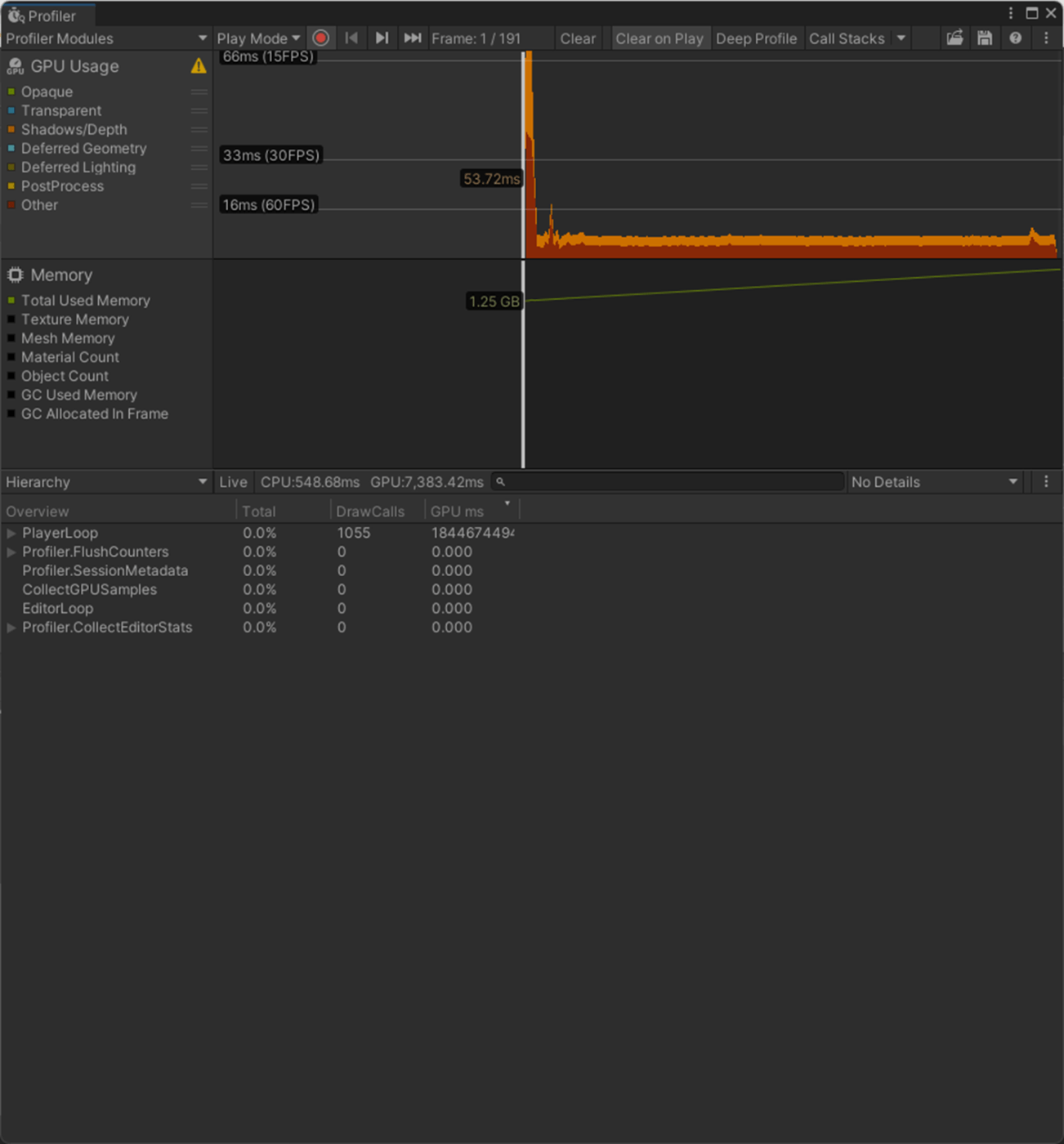

参照サイト
・Optimize Game Objectsをオンにして、コンポーネントがついていないオブジェクトを削除し、アニメーションの負荷(CPU)を軽減させよう
このオプションが無効になっている場合、 Unity は、モデルがインスタンス化されるたびに、そのモデルのボーン構造をミラー (反転) する大きな Transform ヒエラルキーを作成します。この Transform ヒエラルキーの更新には高い負荷が掛かります。特に、(Particle System や Collider などの)別のコンポーネントが添付されている場合はなおさらです。またこれにより、Unity の、メッシュ スキニングやボーンアニメーション計算をマルチスレッド処理する能力に制限が掛かります。
ただ、手に別メッシュの武器などを持たせたい場合は、 Extra Transforms to Exposeで削除しないオブジェクトを指定することが可能
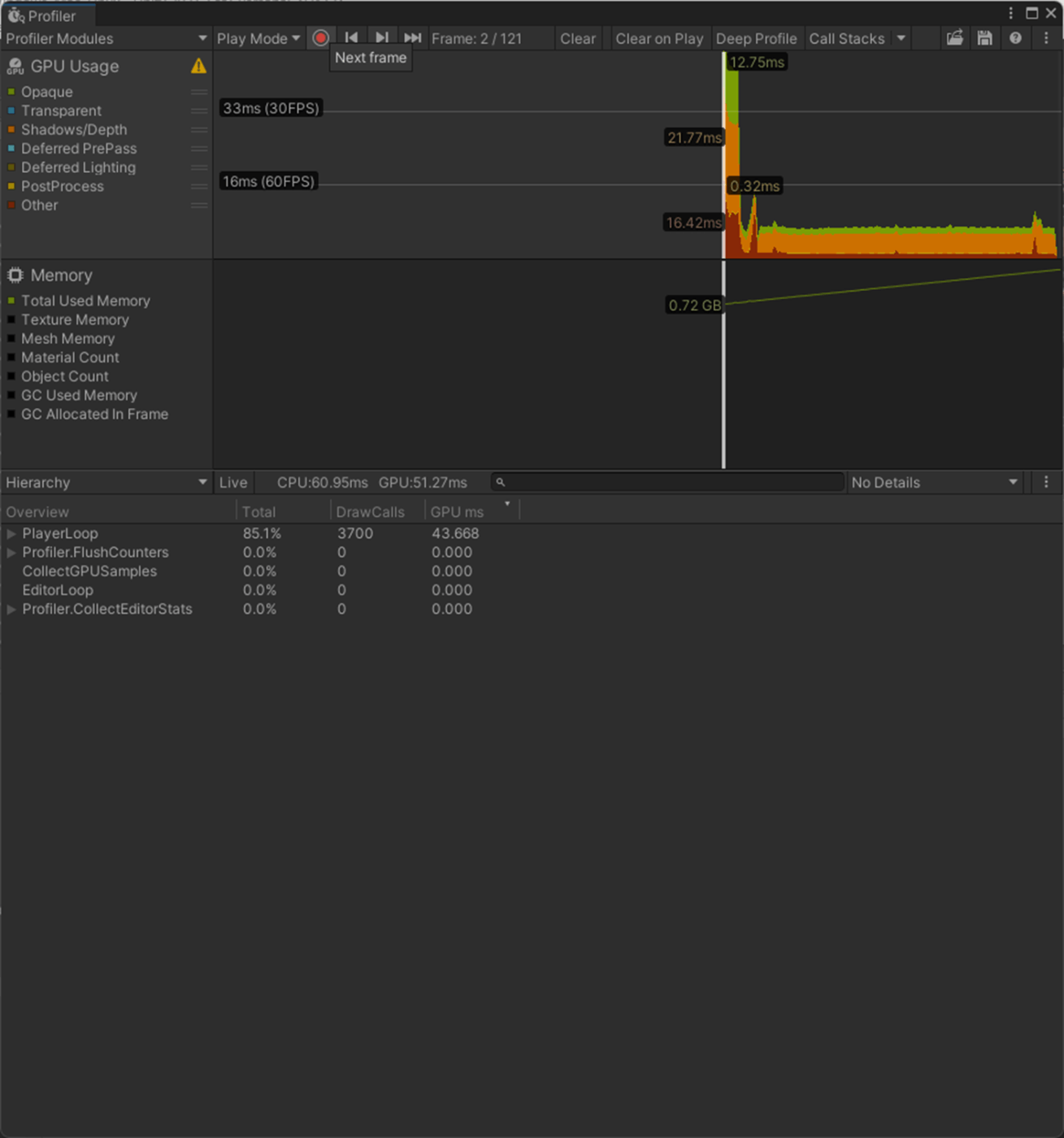
一応、実験してみた。
Optimize Game ObjectsがオンのCPU、GPU、メモリでパフォーマンス改善されていることが分かる。
①Optimize Game Objectsをオフ
1フレーム
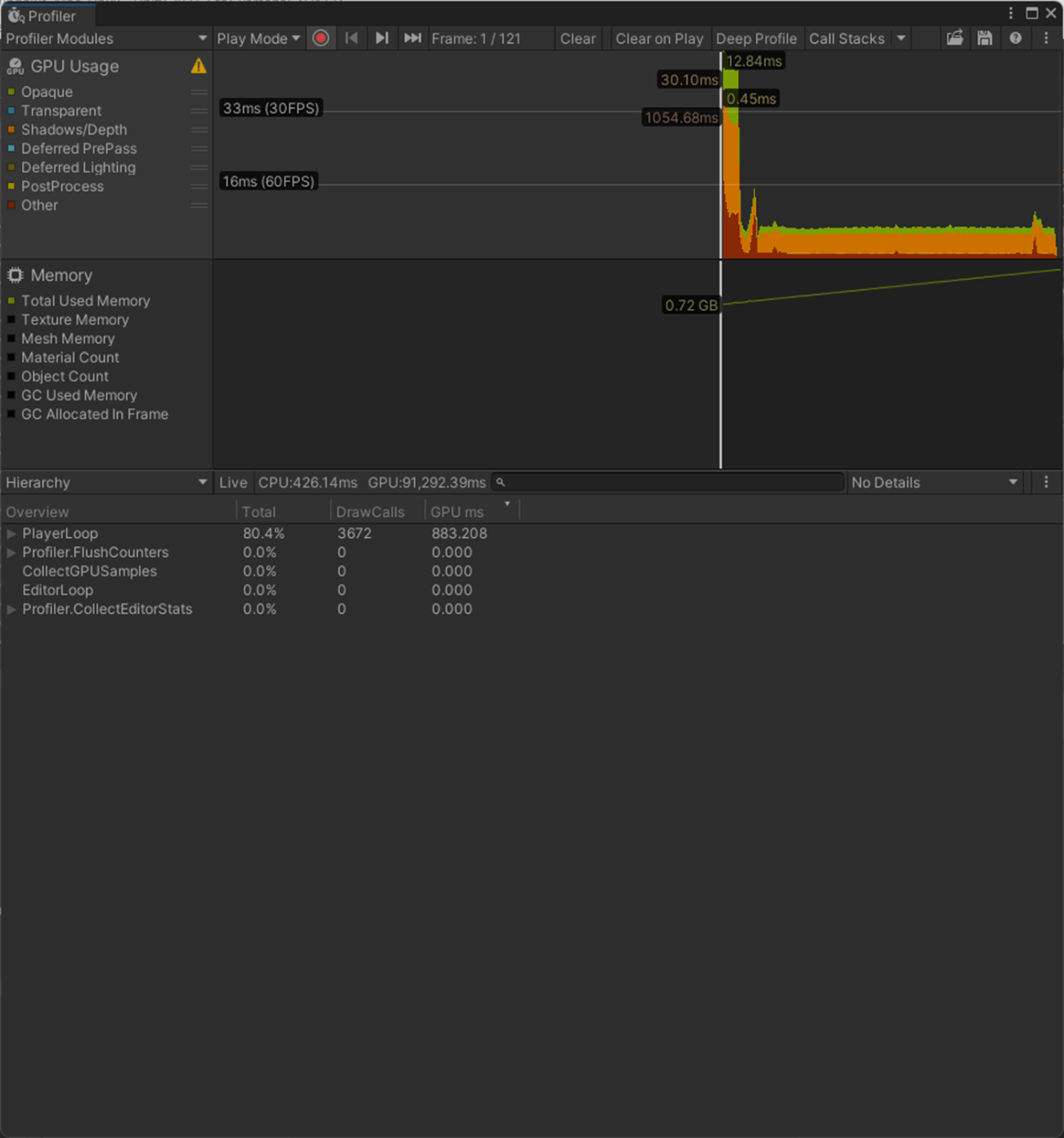
2フレーム
階層確認

②Optimize Game Objectsをオン
1フレーム

2フレーム

階層確認

参照サイト、参照サイト
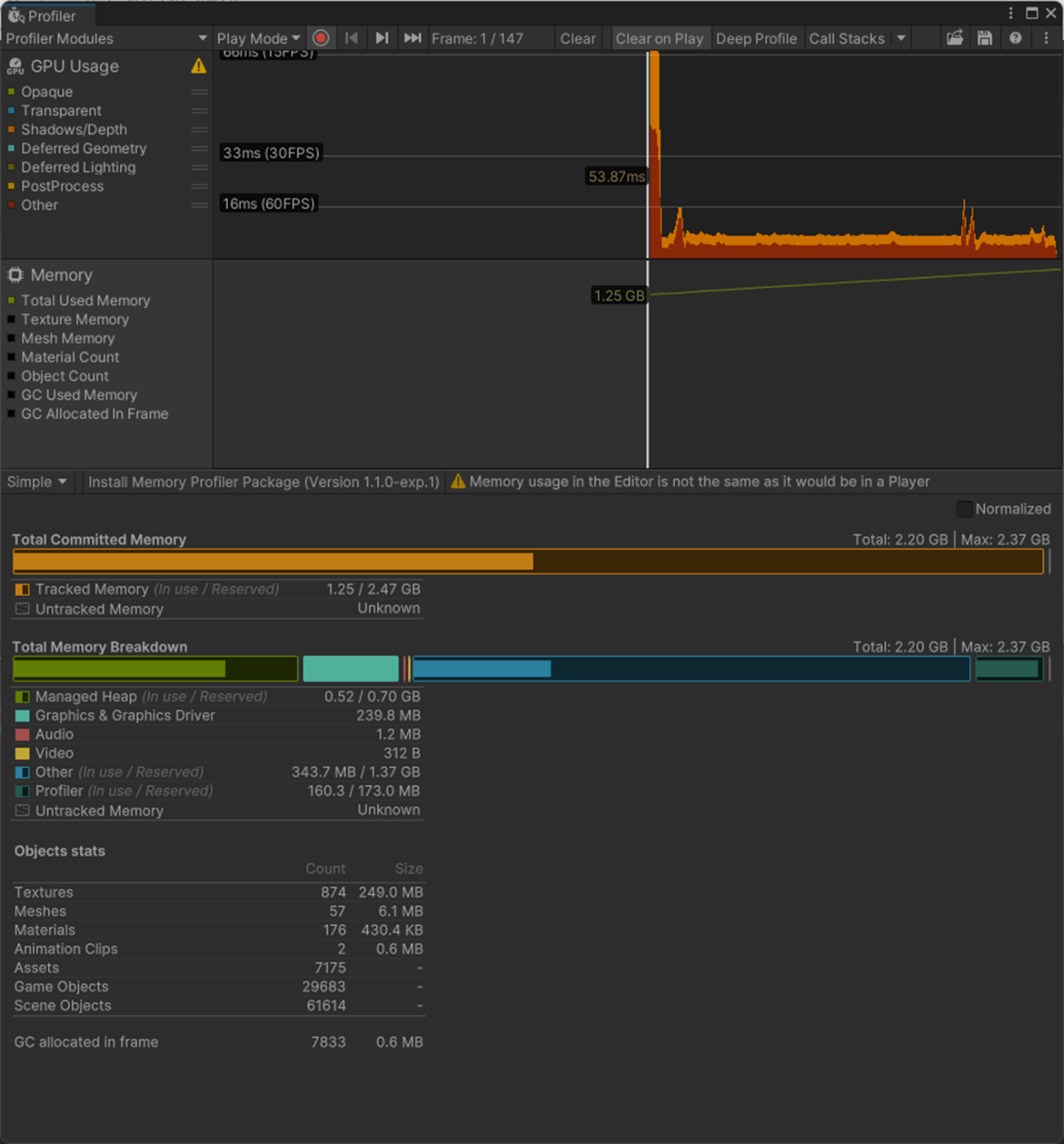
・Mesh Compressionでメッシュの頂点を圧縮し、ディスク容量、メモリ容量を減らす
ただ、圧縮を行うと見た目が崩れたりしてしまうので注意
一応、実験してみた。
ランタイムのメモリ、アプリ容量、見た目が多少変わっている
①Mesh Compression off
ランタイムのメモリ
10.9MB

アプリ容量
282MB

見た目

②Mesh Compression High
ランタイムのメモリ
11.5MB
アプリ容量
280MB

見た目
参照サイト、参照サイト、参照サイト
・Anim. Compression
アニメーションの品質を設定する。
Offは、アニメーションの品質を損なわないが、メモリとファイルサイズが多くなる。
Keyframe ReductionとOptimalは、アニメーションの品質を損なうがメモリとファイルサイズを削減する。
Keyframe Reductionは、Rotation ErrorとPosition ErrorとScale Errorでキーフレームを削減する。
Optimalは、アニメーションが短い場合やノイズが多い場合は、 dense format で圧縮する。
そうでない場合は、Rotation ErrorとPosition ErrorとScale Errorでキーフレームを削減する。
一応、実験してみた。
検証した結果は以下である。
Optimalの方がパフォーマンスが良いことが分かる。
今回は1アニメーションしか実験していないが、複数のアニメーションだとこの数字はかなり変わると思う。
| off | Keyframe Reduction | Optimal | |
|---|---|---|---|
| メモリ(Animation Clip) | 14.1MB | 12.6MB | 12.6MB |
| ディスク | 145,956,874B | 145,499,066B | 145,454,674B |
①off


②Keyframe Reduction


③Optimal


参照サイト、参照サイト、参照サイト、参照サイト
・Rotation Error
Rotation Errorは、回転カーブのキーを削除できるかどうかの指標でこの値が大きいとメモリとファイルサイズの負荷を削減できるが、回転アニメーションの品質は下がる。
一応実験してみた。
Rotation Errorが100のほうが、サイズが小さくなっていることがわかる。
今回は1アニメーションだけ確認したので、ランタイムでメモリを確認したら端数切れ0.1も100も変わらなかったが、複数のアニメーションだとかなり変わる思う
①Rotation Errorが0.1
②Rotation Errorが100

なお、アニメーション自体の品質の違いでいいサンプルがあった。
Rotation Errorが高い方が回転したときに地面にめりこんでいていることが分かる。
参照サイト、参照サイト
・Position Error
Position Errorは、位置カーブのキーを削除できるかどうかの指標でこの値が大きいとメモリとファイルサイズの負荷を削減できるが、位置アニメーションの品質は下がる。
一応実験してみた。
Position Errorが100のほうが、サイズが小さくなっていることがわかる。
今回は1アニメーションだけ確認したので、ランタイムでメモリを確認したら端数切れ0.1も100も変わらなかったが、複数のアニメーションだとかなり変わる思う。
また、アニメーション自体は見ての通り100のほうが品質が悪い。
①Position Errorが0.5
 ②Position Errorが100
②Position Errorが100
 参照サイト
参照サイト
・Scale Error
Scale Errorは、拡大拡縮カーブのキーを削除できるかどうかの指標でこの値が大きいとメモリとファイルサイズの負荷を削減できるが、拡大拡縮アニメーションの品質は下がる。
拡大拡縮するアニメーションのサンプルを持っていないので、確認できなかったがScale Errorの値を大きくすればメモリとファイルサイズの負荷は下がる。
参照サイト
・メッシュにサブメッシュよりも多くのマテリアルが含まれている場合
この場合、Unity は最後のサブメッシュを残りの各 マテリアル とともにレンダリングします。これにより、そのサブメッシュにマルチパスレンダリングを設定できます。ただし、これはランタイムのパフォーマンスに影響を与える可能性があります。完全に不透明な マテリアル は前のレイヤーを上書きするため、パフォーマンスが低下し、利点はありません。
参照サイト
・Skinned Mesh Renderer のUpdate When Offscreen
これを有効にすると、どのカメラからも見えない場合でも、すべてのフレームでバウンディングボリュームを計算します。このオプションを無効にすると、ゲームオブジェクトが画面上にないときにスキニングを停止し、ゲームオブジェクトが再び表示されるとスキニングを再開します。
有効にすると、負荷がかかる。
以下の場合だと、頂点やボーンが境界の外に押し出され、Unity がメッシュの可視性を正しく判断できず、表示されるべき時に表示されないことがあります。
なので、その場合に有効にする。
・アニメーションを追加する場合
・ランタイムにスクリプトからボーンの位置を変更する場合
・頂点位置を変更する頂点シェーダーを使用する場合
・ラグドールを使用する場合
・メッシュのLODでGPUの負荷を下げる
LODとはカメラの距離に応じて、メッシュを切り替えてGPUの負荷を下げるテクニックである。
参照サイト
・Maximum LOD Levelの値を大きくして、ビルド対象から外し、ストレージとメモリ容量が節約できる。 参照サイト
・メッシュの圧縮
メッシュを圧縮する方法は、2種類存在する。
Vertex CompressionとMesh Compressionである。それぞれメリットデメリットがある。
なお、同じプロジェクトで両方の圧縮方法を使用することはできますが、同じメッシュに使用することはできません。メッシュに Mesh Compression を適用した場合、Unity はそのメッシュに Vertex Compression を適用しません。
①Vertex Compression

プロジェクト内のすべてのメッシュに影響する設定です。
メリットは、
■メモリ内のメッシュデータのサイズが小さくなる
■ファイルサイズがわずかに減少、
■GPU パフォーマンスが向上する可能性がある
デメリットは、
■見た目の精度が落ちる
■メッシュが以下の要件を満たしている必要があり、これを満たさない場合Unity は圧縮しない
Read/Write Enabled プロパティを無効。
Skinned Meshでないこと。
ターゲットプラットフォームが Float16 値をサポートしている.
メッシュを含むモデルがMesh Compression の値が “Off ” に設定されている。
動的バッチの対象ではない。
また圧縮できる対象は、頂点、法線、接線、頂点カラー、UVで、未圧縮はFloat32で圧縮はFloat16である。
②Mesh Compression

個々のメッシュに影響する設定です。
メリットは、
■ディスク上のメッシュデータを圧縮し、Vertex Compressionよりもファイルサイズを小さくします
デメリットは、
■ロード時間の増加(CPUに負荷)
■ロード時の一時的なメモリ使用量の増加
■圧縮によるアーティファクトの可能性
各設定による圧縮率を以下に示す。

参照サイト
・Async Asset UploadのBuffer SizeとTime Sliceを調整して、パフォーマンス上げる。

Async Asset UploadのBuffer SizeとTime Sliceの説明の前に触れておくことがある。
①テスクチャとメッシュのロード
Unity は、同期と非同期の 2 種類の方法で、テクスチャやメッシュのデータをディスクから読み込み GPU にアップロードします。
この 2 つの処理は “同期アップロードパイプライン” と “非同期アップロードパイプライン” と呼ばれます。
Unity が同期型アップロードパイプラインを使用すると、
データをロードしてアップロードしている間は、他のタスクを実行できません。これにより、アプリケーションに目に見える一時停止が発生することがあります。
Unity が非同期アップロードパイプラインを使用すると、
バックグラウンドでデータのロードとアップロードを行いながら、他のタスクを実行できます。
テクスチャやメッシュに対して非同期アップロードパイプラインを使用できる場合、Unity は自動的に非同期アップロードパイプラインを使用します。テクスチャやメッシュに非同期アップロードパイプラインを使用できない場合、Unity は自動的に同期アップロードパイプラインを使用します。
②同期アップロードパイプライン” と “非同期アップロードパイプライン”の仕組み
同期アップロードパイプラインでは、
Unity は、1 つのフレームで、テクスチャやメッシュのメタデータ (ヘッダーデータ) と、テクセル/頂点データ (バイナリデータ) の両方を読み込む必要があります。
非同期アップロードパイプラインでは、
Unity は 1 つのフレームでヘッダーデータのみをロードする必要があり、その後のフレームでバイナリデータを GPU にストリーミングすることができます。
同期型アップロードパイプラインでは、以下が行われます。
■ビルド時に、Unity はメッシュやテクスチャのヘッダーとバイナリデータの両方を 1 つの .res ファイルに書き込みます。
■ランタイムに、アプリケーションがテクスチャやメッシュを必要とするとき、Unity はそのテクスチャやメッシュのヘッダーデータとバイナリデータの両方を .res ファイルからメモリにロードします。すべてのデータがメモリに入ると、Unity はバイナリデータをメモリから GPU にアップロードします。ロードとアップロードの作業は、主にメインスレッドで、1 フレーム内で行われます。
非同期のアップロードパイプラインでは、以下が行われます。
■ビルド時に、Unity はヘッダーデータを .res ファイルに、バイナリデータを別の .res ファイルに書き込みます。
■ランタイムに、アプリケーションがテクスチャやメッシュを必要とすると、Unity は .res ファイルからヘッダーをメモリにロードします。ヘッダーがメモリに入ったら、Unity は、サイズを固定したリングバッファを使って、.res ファイルから GPU にバイナリデータをストリーミングします。Unity は、複数のスレッドを使って数フレームに渡って、バイナリデータをストリーミングします。なお、Unity がすでに GPU ハードウェアを知っている一部のコンソールプラットフォームでは、リングバッファをスキップして直接 GPU メモリにロードします。
③非同期アップロードパイプラインの対象になるためには
テクスチャは、以下の条件を満たすと、非同期アップロードパイプラインの対象となります。
■Read/Writeがオンでない
■Resources フォルダーに入っていない
■ビルドターゲットが Android の場合、プロジェクトのビルド設定で Compression MethodがLZ4 圧縮が有効になっている。
なおLoadImage(byte[] data) を使用してテクスチャをロードする場合、上記の条件が満たされていても、強制的に同期アップロードパイプラインが使用されます。
メッシュは、以下の条件を満たすと、非同期アップロードパイプラインの対象となります。
■Read/Writeがオンでない
■Resources フォルダーに入っていない
■BlendShape ではない
■動的バッチ処理の対象でない
■頂点/インデックスデータが、パーティクルシステム、Terrain (地形)、メッシュコライダーで必要とされていない
■ボーンウェイトがない
■トポロジーがクワッド ではない
■メッシュアセットのMesh Compression が Off に設定されている。 ビルドターゲットが Android の場合、プロジェクトのビルド設定で Compression MethodがLZ4 圧縮が有効になっている
それ以外の状況では、Unity はテクスチャとメッシュを同期してロードします。
④Unity が使用するアップロードパイプラインを特定する方法
Profiler または他のプロファイリングツールを使用して、スレッドのアクティビティとプロファイラーのマーカーを観察することによって、Unity が非同期アップロードパイプラインを使用していることを特定できます。
以下は、Unity がテクスチャやメッシュのアップロードに非同期アップロードパイプラインを使用していることを示しています。
■AsyncUploadManager.ScheduleAsyncRead、AsyncReadManager.ReadFile、Async.DirectTextureLoadBegin プロファイラーマーカー。
■AsyncRead スレッドでのアクティビティ。
このアクティビティが表示されない場合、Unity は非同期アップロードパイプラインを使用していません。
④Buffer SizeとTime Sliceについて
ようやく本題に入れる。
■Buffer Size
リングバッファのサイズ(最小サイズは 2 メガバイト、最大サイズは 2047 メガバイト)を指定できる。
Unity は、現在ロードしている最大のテクスチャやメッシュに合わせて、自動的にリングバッファのサイズを変更します。これは時間のかかる操作です。例えば、デフォルトのリングバッファサイズより大きいテクスチャを多数ロードしている場合など、Unity が複数回実行しなければならない場合は特に時間がかかります。Unity がバッファサイズを変更しなければならない回数を減らすために、この値を、ロードすると予想される最大の値に合わせて設定してください。
■Time Slice
CPU が GPU にテクスチャやメッシュデータをアップロードするのに費やす時間(最小値は 1、最大値は 33)を、フレームあたりのミリ秒で表したものです。
値が大きいほど、データが GPU 上ですぐに準備できることを意味しますが、CPU はそれらのフレームの間、アップロード操作に多くの時間を費やします。Unity がこの時間をアップロードに使うのは、GPU へのアップロードを待っているデータがバッファにある場合だけです。待機中のデータがなければ、Unity はこの時間を他の操作に使うことができます。
この値が小さすぎると、テクスチャやメッシュの GPU アップロードが遅くなる場合があります。逆に値が大きすぎるとフレームレートの低下が起きることがあります。
参照サイト、参照サイト
・テクスチャのサイズは、2 の累乗 (2、4、8、16、32、64、128、256、512、1024、2048)にすべき
Unity でテクスチャサイズの NPOT (2 の累乗以外) を使用することは可能です。ただし、NPOT のテクスチャサイズは一般的にわずかに多くメモリを消費し、GPU がサンプリングするのが遅くなるため、パフォーマンスをよくするためには 2 の累乗を使用します。
プラットフォームまたは GPU が NPOT テクスチャサイズをサポートしていない場合、Unity はテクスチャに対しスケーリングやパディングをして次に近い 2 の累乗にします。このプロセスは、より多くのメモリを使用し、読み込みを遅くします (特に古いモバイルデバイスでは)。一般的には、GUI 用にだけ NPOT サイズを使用します。
テクスチャインポーターの Advanced セクションの Non Power of 2 オプションを使用して、インポート時に NPOT テクスチャアセットを拡大することができます。
また、 あるプラットフォームでは最大テクスチャサイズが指定される場合があります。
Androidとiosは、2017年度時点で、 4096 x 4096に対応してるらしい。
参照サイト、参照サイト
・テクスチャのインポート設定 Max Size
テクスチャのサイズを指定できる。インポートしたサイズよりも大きくしても見た目は変わらない。
Max Sizeを小さくするとパフォーマンス上がるが、見た目は悪くなる。
下の画像のとおりMax Sizeを小さいと、サイズは小さいが見た目は悪いことが分かる。
①Max Size 32

②Max Size 512

参照サイト
・テクスチャのインポート設定 Format

上の図にように、品質などに合わせて選択するのが良い。
■デスクトップ
上の図にように、品質などに合わせて選択するのが良い。
ただ、DirectX 10 クラス GPU (2010 より前の NVIDIA GPU、2009 より前の AMD、2012 より前の Intel) をサポートする必要がある場合、これらの GPU は BC7 も BC6H もサポートしないため、BC7 ではなく DXT5 が推奨されます。
対応していないフォーマットを選ぶと、ロードもメモリに負荷がかかるので注意。
■iOSとtvOS
上の図だとATSCとPVRTCが二つあるが、ATSCのほうが良い。
ただ、使用する為にはA8以上(iPhone6以降)のCPUが必要となります。
A7(iPhone5など)を使用する場合はPVRTC使用しないと、ロードもメモリに負荷がかかるので注意。
ATSCとPVRTCを比べると、ATSCの種類のよるがATSCの方が見た目が綺麗でなおかつサイズが小さくなる。
以下の画像だと、PVRTCとASTC6x6は大体消費メモリは同じくらいですが、内側に滲んでいるPVRTCと比較してASTC 6x6の方が綺麗に見えます。

ATSCにも種類があって、例えば8×8block、10×10blockなどがあり、サイズ大きくなればなるほどサイズは小さくなるがその分画質が劣化する。
■Android
ASTCかETC2のどちらかになるが、シェア率が、ETC2は95% 以上、ASTCは80% 以上であるのでETC2が無難におすすめ。
ただASTCはETC2に比べて、様々なフォーマット(4×4block~12×12block)があるのでパフォーマンスと品質を考慮して選択しやすい。
ETCは古い端末も対応しているが、アルファに対応していない。
①ASTC対応しているもの
LDR、RGB、RGBA テクスチャについては、OpenGL ES 3.1 または Vulkan をサポートする最新のAndroid GPU のほとんどが ASTC 形式もサポートしており、以下のようなものがあります。 Qualcomm GPU Adreno 4xx / Snapdragon 415 (2015) 以降、ARM GPU Mali T624 (2012) 以降、NVIDIA GPU Tegra K1 (2014) 以降、PowerVR GPUs since GX6250 (2014) 以降。
①ETC2対応しているもの
Vulkan、Metal、または OpenGL ES 3.0 を実行するすべての GPU は ETC2 形式をサポートします。
OpenGL ES 2 デバイスは ETC2 形式をサポートしないため、Unity はランタイムにテクスチャ ETC2 フォールバック が指定する形式に解凍します。
さらに古いデバイスの場合、通常は ETC 形式のみが使用可能です。
③ASTC HDR
ASTC HDR は、Android デバイスで HDR テクスチャに使用できる唯一の圧縮形式です。
ASTC HDR には Vulkan またはGL_KHR_texture_compression_astc_hdr サポートが必要です。
デバイスが ASTC HDR をサポートしていない場合、テクスチャはランタイムに RGB9e5 または RGBA Half に解凍されますが、これはアルファチャンネルの使用状況によって異なります。
ASTC HDR に対応していないデバイスでは、Vulkan、Metal、OpenGL ES 3.0 を搭載したすべてのデバイスが RGB9e5 に対応しており、アルファチャンネルのないテクスチャに適しています。
アルファチャンネルやさらに広い範囲のサポートが必要な場合は、RGBA Half を使用します。これは、RGB9e5 の 2 倍のメモリを必要とします。
④テクスチャーフォーマット (品質別)

⑤サポートされるテクスチャ形式 (プラットフォーム別)
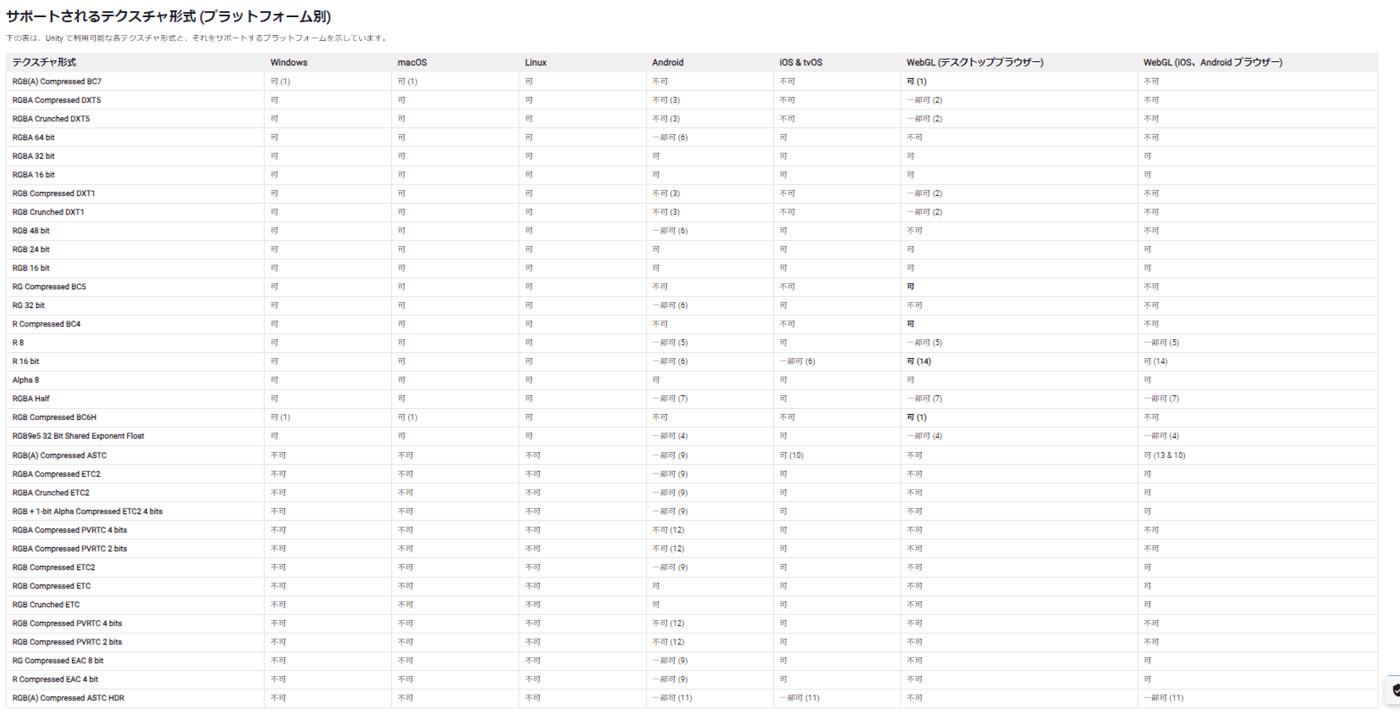
⑥設定方法
以下で設定可能
AndroidのPlayer 設定 内の Texture compression format
Android のビルド設定 内の Texture Compression
テクスチャのFormat
参照サイト、参照サイト、参照サイト
・テクスチャのインポート設定 Compression
テクスチャの圧縮タイプを選択します。
None、Low Quality、Normal Quality、High Qualityが設定可能で、高いクオリティほどサイズは小さくなるがその分見た目が悪くなる。
下の画像のとおりCompressionのクオリティが高いと、サイズは小さいことが分かる。
見た目は変化がないのは、PCで実施している影響かと思われる。ドキュメントだと
プラットフォームや圧縮形式の使用可否によって、異なる設定でも、結果的に内部的に同じ形式になる場合があります。例えば、 Low Quality Compression はモバイルプラットフォームに効果的ですが、デスクトッププラットフォームには効果がありません。
と記載されているのでこのためだと思われる。
①Compression None
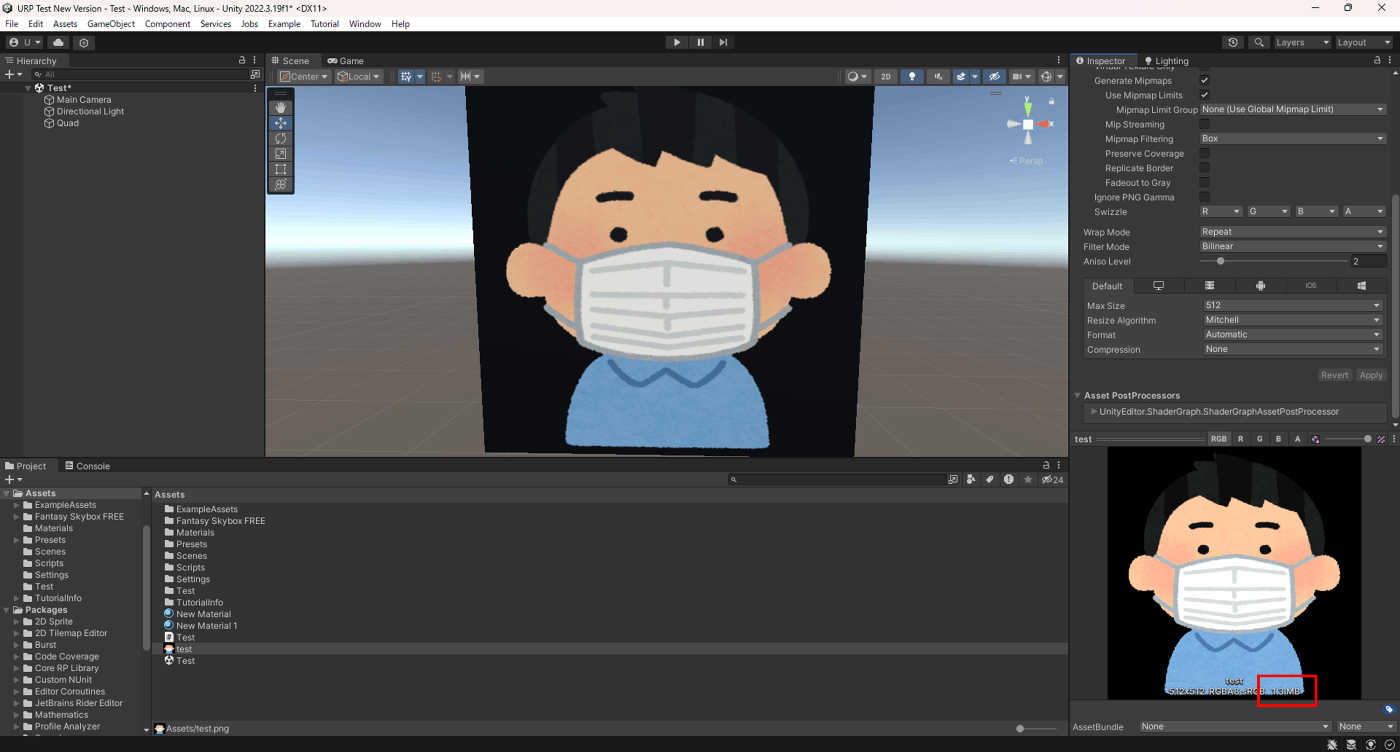
②Compression High Quality

参照サイト
・テクスチャのインポート設定 Use Crunch Compression
クランチ圧縮(DXTかETC)を使用します。
クランチ圧縮は、ディスク上やダウンロード時に使用するスペース量をできるだけ少なくしたいときに役立ちます。
クランチテクスチャは、圧縮するのにかなり時間がかかりますが、ランタイムでの解凍は高速です。
Use Crunch Compressionオンのほうがサイズが小さくなっていることが分かる。
見た目は変化がないのは、PCで実施している影響かと思われる。ドキュメントだと
プラットフォームや圧縮形式の使用可否によって、異なる設定でも、結果的に内部的に同じ形式になる場合があります。例えば、 Low Quality Compression はモバイルプラットフォームに効果的ですが、デスクトッププラットフォームには効果がありません。
と記載されているのでこのためだと思われる。
①Use Crunch Compression オフ

②Use Crunch Compression オン
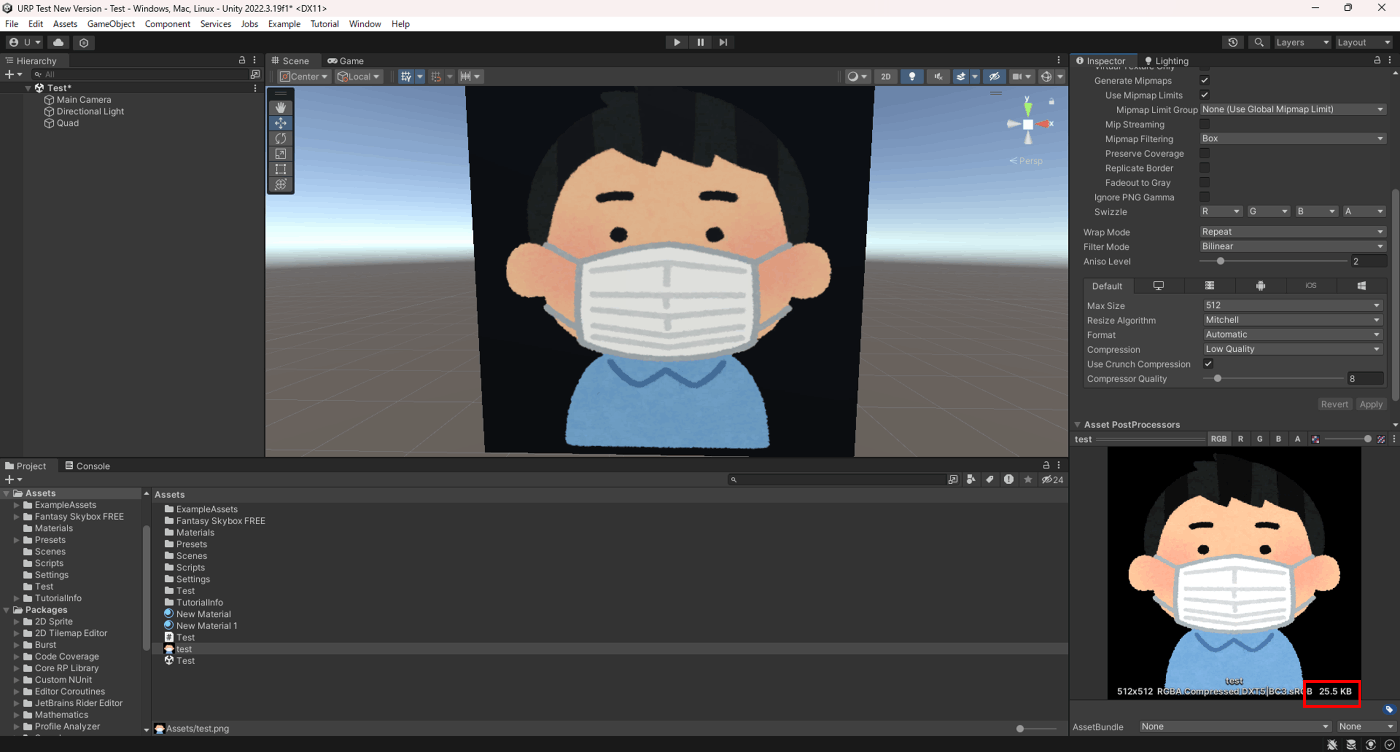
Compressor Qualityで圧縮率を変更でき、数値が大きいほどサイズが小さくなる分品質が落ちる。
参照サイト
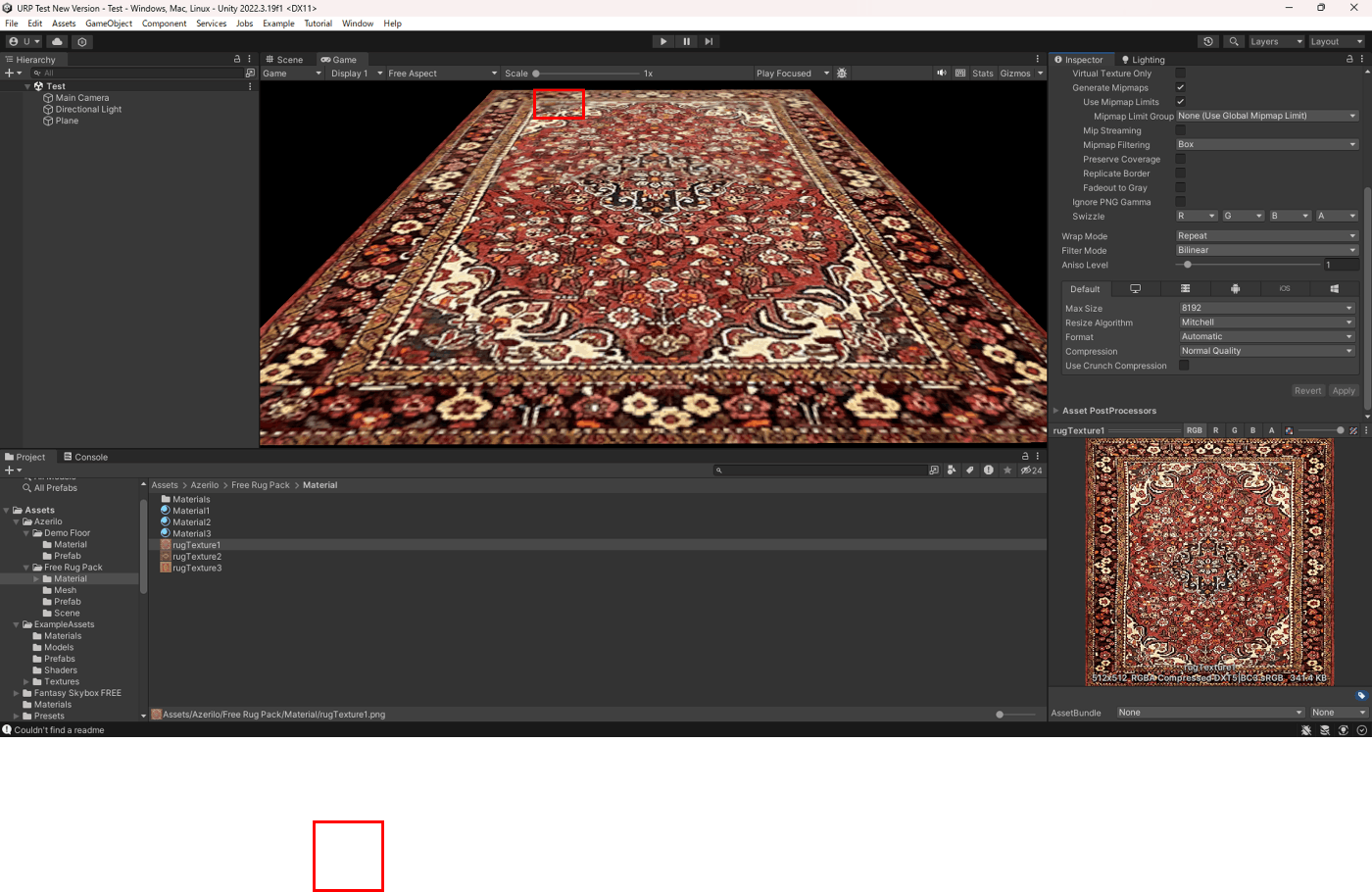
・テクスチャのインポート設定 Filter Mode
Filter Modeはテクスチャにどのようにフィルタリングするかを選択できる。
負荷は、
Point (no filter) < Bilinear < Trilinear
右にいくほど高くなるが、その分品質が良い。
実際にFilter Modeがどういうものかも実験してみる。
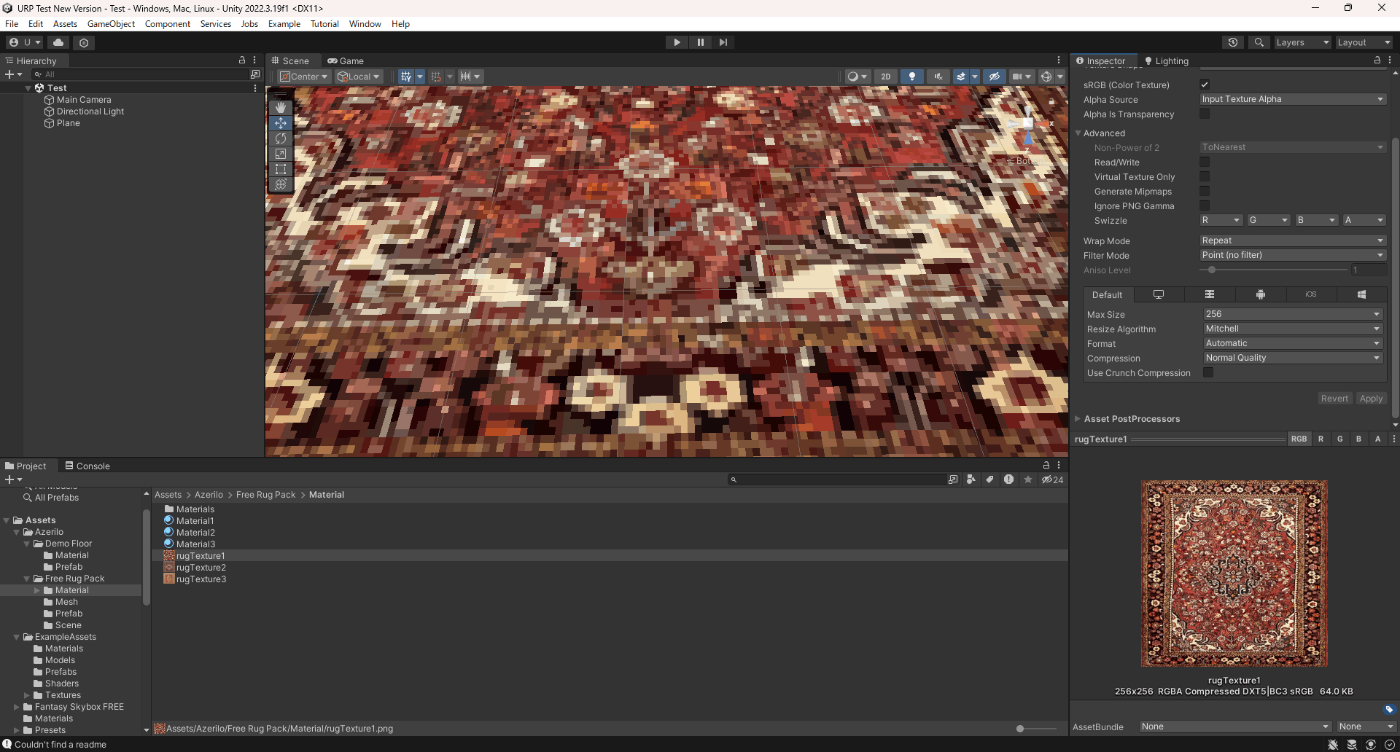
■Point (no filter)
Point (no filter) は、フィルタリングを行わずそのまま描画する設定。
ジャギーがあるのが分かる。
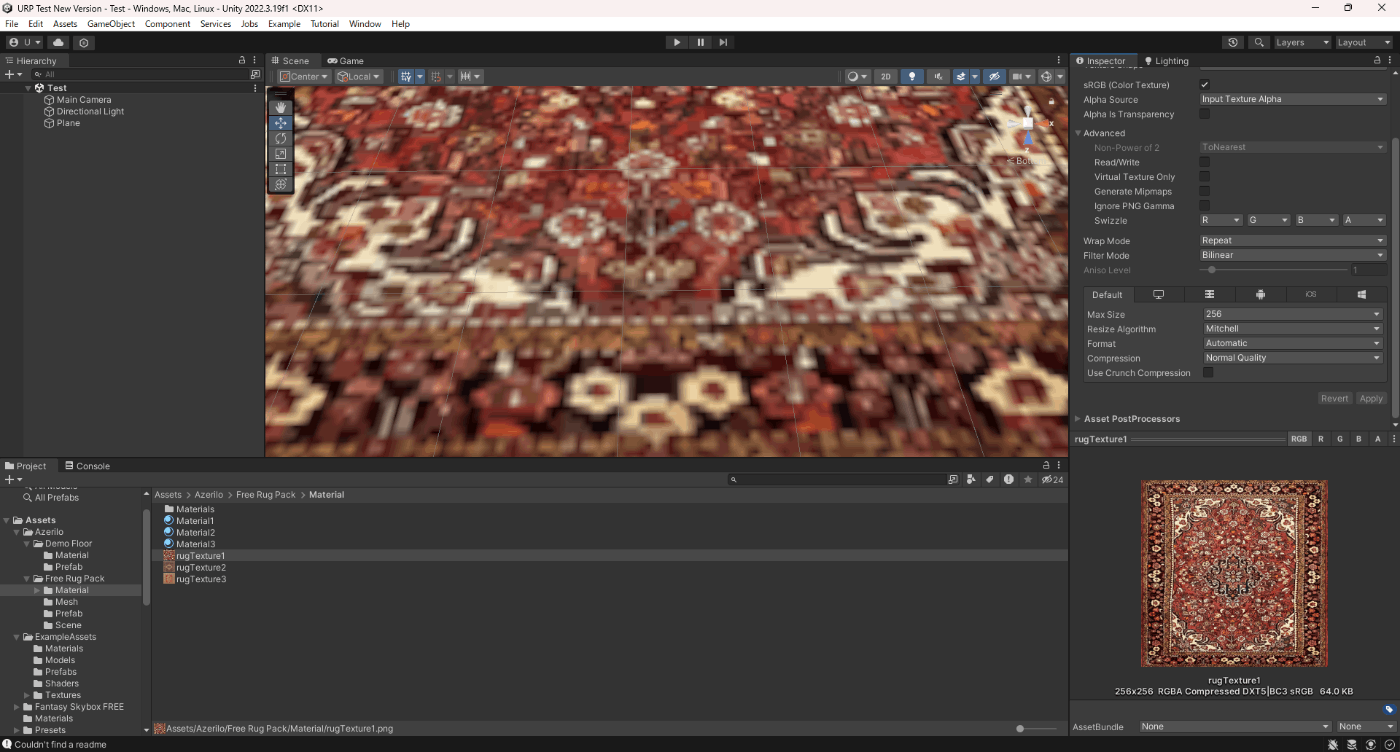
■Bilinear
Bilinearは、ピクセル4点を平均化する設定である。
Point (no filter) はではなかったジャギーがなくなっている。
ただ、Bilinearはカメラを動かすと、法線とカメラの角度が大きい場合(画面の奥)とちらつく現象が起きる。
下記の動画を見ると、画面の奥でカメラを動かすとちらつきを確認できる。
このちらつきを解消するために、ミップマップを使用する。Generate MipMapsをオンにすることで、ミップマップ(2のべき乗をダウンスケールした複数枚のテクスチャ)を生成できる。
下記動画を見ると、さきほどのちらつきが解消されている
■Trilinear
Trilinearは、ピクセル8点を平均化する設定である。(ミップマップ同士で行う)
Bilinearとミップマップを使用するとちらつきは確かになくなるが、ミップマップが切り替わるところがどうしても目立つ箇所が出てくる。
これを解決するのがTrilinear。
下記の赤枠が示した箇所で、ミップマップの切り替わりがTrilinearだと軽減されていることが分かる。
Bilinear
Trilinear
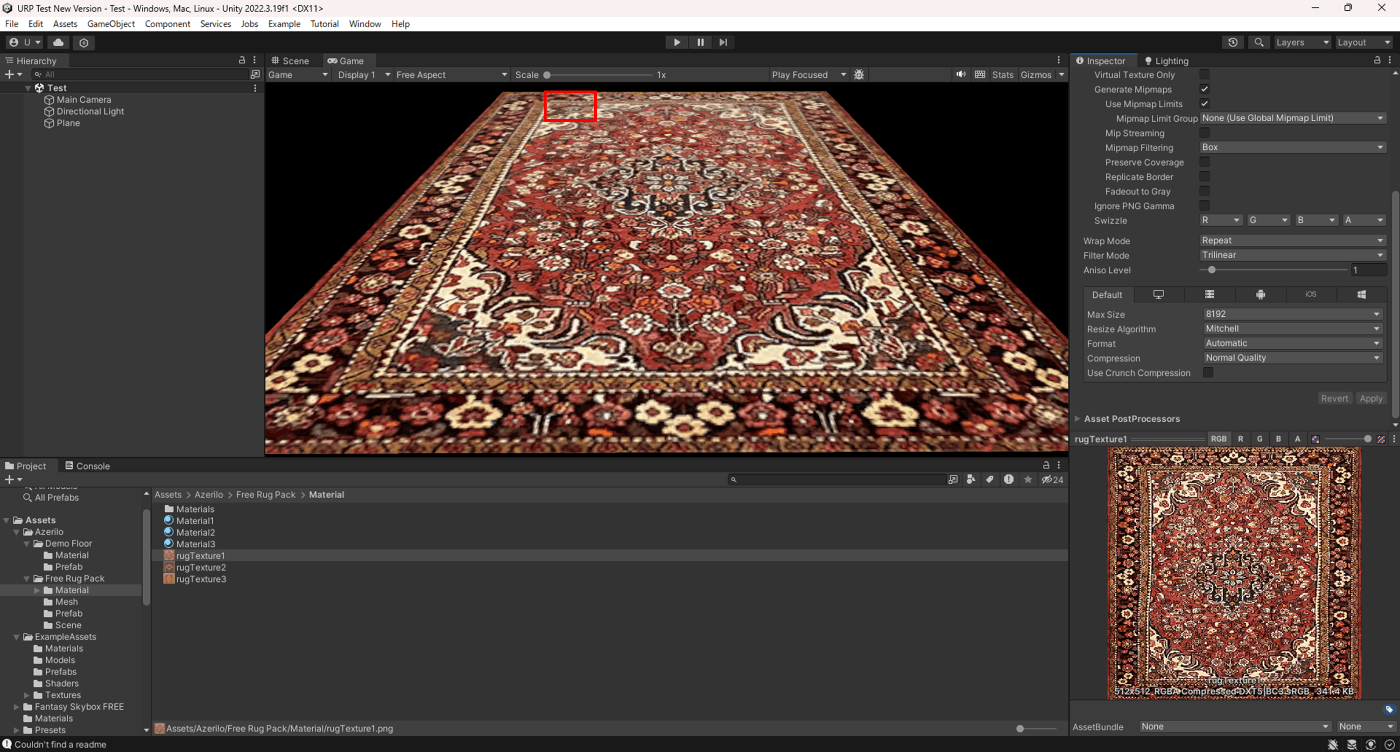
参照サイト、参照サイト、参照サイト
・テクスチャのインポート設定 Aniso Level
Trilinearでも綺麗に描画されない箇所を綺麗に描画する手法(異方性フィルタリング)。
この値が大きいほど綺麗に描画されるが、その分負荷がかかる。
下記の画像を見ると、Aniso Level16方が赤枠の箇所が綺麗に描画されているのが分かる。
■TrilinearでAniso Levelが1

■TrilinearでAniso Levelが16

なお、Project SettingsにあるAnisotropic Texturesでグローバル設定で有効・無効にするのか、テクスチャ毎に設定するのか設定できる。
Disabledは異方性フィルタリング無効。
Per Textureはテクスチャごとに設定。ただしAniso Levelが2から異方性フィルタリングが有効
Forced Onは、
0だと異方性フィルタリングが無効
1~8だと異方性フィルタリングが有効で、Aniso Levelが9として扱われる。
9~16だとそのままLevelで扱われる。
参照サイト、参照サイト、参照サイト
・ミップマップ
上で画面のちらつき解消のために、ミップマップを使用する方法を紹介したが、ミップマップを使用することでGPUのパフォーマンスも改善できる。
カメラから遠く離れているオブジェクトは解像度の高いテクスチャを使うのは、勿体ない。
なので、ミップマップを使用することでカメラから離れているオブジェクトのテクスチャは低解像にしてGPUの負荷は低減することができる。
Generate MipMapsをオンにすることで、2のべき乗をダウンスケールした複数枚のテクスチャを生成し、それをミップマップとして使用できる。
ただ、テクスチャを複数枚生成するのでディスクとメモリの両方で、テクスチャのサイズを 33% 増加する。
また、元のテクスチャサイズは2のべき乗でなければならない。
余談だが、
ミップバイアスを使用することで、ミップマップのレベルを制御できる。
公式ドキュメントによると以下である。
個々のテクスチャにミップバイアスを設定するには、Texture.mipMapBias を参照してください。ハンドコードシェーダーでテクスチャサンプリング操作のミップバイアスを設定するには、tex2dbias などの HLSL 関数を使用します。Shader Graph でテクスチャサンプリング操作のミップバイアスを設定するには、Sample Texture 2D Array node または Sample Texture 2D node を参照してください。
ついでにミップマップ周りの設定項目も紹介していく。
■テクスチャのインポート設定 Use Mipmap Limits
QualityのGlobal Mipmap Limitの設定に従うか従ないかの設定。
オフにすると、Global Mipmap Limitの設定に関係なく常に最高解像度のミップを使用する。
オンにすると、Global Mipmap Limitの設定に従う。
ちなみに、Global Mipmap Limitは使用する最高解像度のミップマップレベルを選択するものである。
0: Full Resolution→ダウンスケールなし
1: Half Resolution→1/2の解像度を使用
2: Quarter Resolution→1/4の使用
3: Eighth Resolution→1/8の使用
実際に試してみる。
■テクスチャのインポート設定 Mipmap Limit Groups
QualityのMipmap Limit Groupsで作成したグループを設定できる。
以下が選択できるミップマップ。
Offset Global Mipmap Limit: –3
Offset Global Mipmap Limit: –2
Offset Global Mipmap Limit: –1
Use Global Mipmap Limit
Offset Global Mipmap Limit: +1
Offset Global Mipmap Limit: +2
Offset Global Mipmap Limit: +3
Override Global Mipmap Limit: Full Resolution
Override Global Mipmap Limit: Half Resolution
Override Global Mipmap Limit: Quarter Resolution
Override Global Mipmap Limit: Eighth Resolution
実際に見た方が早い。
■Mip Streaming(古いバージョンだとStreaming Mip Maps)
ミップマップストリーミングを行うときに必要な設定。
ミップマップストリーミングについては後述しているので割愛。
■Mip Map Priority
おそらくミップレベルのオフセット変える設定だと思うがうまくできず。
■Mipmap Filtering
ミップマップフィルタリングを設定する。
BoxとKaiserとあるが、ミップマップがあまりにもぼやけている場合はKaiserを使用したほうが良いと公式ドキュメントで記載されているが実際に試したらBoxのほうがぼやけがなくなっている印象があった。
Box

Kaiser

■Preserve Coverage(古いバージョンだとMip Maps Preserve Coverage)とAlpha Cutoff
低解像度のミップマップだとうまくアルファテストできずに思った見た目にならないことがあるのでそれを解消するためにこの設定を使用する。
以下はカメラから離れたところをズームした画像で、あるSpriteにマスクテクスチャを適用させた例である。
Preserve Coverageオフ

Preserve Coverageオン

■Replicate Border(古いバージョンだとBorder Mip Maps)
解像度の低いミップマップだとのエッジに色がにじみ出るのを防ぎます。クッキーなどで使われる。
下記画像のように解像度の低いミップマップのせいで外周がうまく描画されていないのが分かる。

Replicate Borderをオンにすると下記よううまく描画される。

■Fadeout to Gray(古いバージョンだとFadeout Mip Maps)
ミップマップが切り替わるときフェードアウトして切り替わる。
参照サイト、参照サイト、参照サイト
・ミップマップストリーミング
ミップマップは、メモリにすべてのミップマップをロードするのでメモリに負荷がかかってしまうのがデメリットである。
ミップマップストリーミングすることで、カメラの距離に合わせて最適なミップマップをロード・アンロード行うことでメモリ負荷を軽減できる。(シーンのロード時間の短縮)
カメラから近い場合は、解像度の高いミップをロードし、カメラから離れたら解像度の高いミップはアンロードし解像度の低いミップをロードする。
ただ、少量のCPU負荷がかかってしまうし、ストリーミングが間に合わないと解像度の低いミップマップがロードされる可能性もあるので注意。
ミップマップストリーミングの細かな調整は、QualityのAdd All Cameras、Memory Budget、Renderers Per Frame、Max Level Reduction、Max IO Requestsで行う。
■ミップマップストリーミングの有効化するには
QualityのTexture Streamingをオンにする。
テクスチャのインポート設定のMip Streamingをオン。
■Androidでの設定方法
Build Settings (ビルド設定) を開き、Compression Method を LZ4 か LZ4HC に設定する必要があります。
■Add All Cameras
オンにするとすべてのカメラにミップマップストリーミングを適用する。
個別のカメラにミップマップストリーミングを適用させたい場合は、Streaming Controllerコンポーネントをカメラにアタッチする。
■Memory Budget(Max Level Reduction)
Memory BudgetはUnity がシーンのテクスチャに使用するメモリの最大量を決定する。
シーン内のテクスチャのメモリがMemory Budgetより大きい場合、Max Level Reductionの値に応じてどのミップをアンロードするか決める。
Max Level Reduction(最大7まで設定可能)が
1なら、どのミップもアンロードもしない。
2なら、一番目、二番目の解像度のミップをアンロードする。
3なら、一番目、二番目、三番目の解像度のミップをアンロードする。
のような挙動である。
実際にシーン内のテクスチャがMemory Budgetより大きい場合で実験してみる。
なお、Memory Budgetはミップマップストリーミングを適用しないテクスチャも含めたメモリ容量である。
なので、例えば、Memory Budgetが 100MB で、90MB の非ストリーミングテクスチャがある場合、テクスチャストリーミングシステムは、残りの 10MB にすべてのストリーミングテクスチャを収めようとします。
また、Memory Budgetを超える場合でも非ストリーミングテクスチャは常にフル解像度で描画される。
左の画像が非ストリーミングテクスチャで、右がミップマップストリーミングのテクスチャである。

■Renderers Per Frame
1フレームにどれだけのメッシュレンダラーを制御するか設定できる。
メインスレッドと関連するジョブの CPU 処理オーバーヘッドを制御できる。
■ Max IO Requests
同時使用可能なテクスチャストリーミングシステムからのテクスチャファイルイン/アウト (IO) 要求の最大数を設定。
シーンテクスチャコンテンツが大幅に短時間で変化すると、システムはファイル IO が追いつける数より多くのテクスチャミップマップを読み込もうとします。この値を小さくすると、テクスチャストリーミングシステムが生成する IO 帯域幅が小さくなります。その結果、ミップマップ要件の変更に対するより迅速な対応が可能になります。
■シーン内の適切なメモリバジェットの算出方法
公式ドキュメントによると以下である。
1.プロジェクトの実行中に Texture.destatedTextureMemory の値を確認します。
2.Memory Budget の値を Texture.destablishedTextureMemory の値よりもわずかに高く設定します。
これにより、シーンの中で最もリソースを必要とする領域に利用できる十分なテクスチャメモリが確保され、テクスチャが低解像度に落ちるのを防ぐことができます。メモリに余裕がある場合は、メモリバジェットを大きく設定することで、シーンで表示されていないテクスチャデータをストリーミングキャッシュに残すことができます。
■ストリーミングライトマップ
ライトマップも、PlayerのLightmap Streaming EnabledとStreaming Priorityで可能。
■ミップマップストリーミングのデバッグ
ビルトインのみでデバッグできるが、独自で作成できるAPIもある。
シーンビューの描画モードのドロップダウン をクリックし、Texture Streaming を選択で、デバッグ可能。
Green - ミップマップストリーミングシステムによってミップマップが減少したテクスチャ。
Red - ミップマップストリーミングシステムにすべてのミップマップをロードするのに十分なリソースがないため、ミップマップがほどんどないテクスチャ。
Blue - ストリーミングに設定されていないテクスチャ、またはミップレベルを計算するレンダラーがない場合。
■手動でミップマップストリーミングを行わないといけないもの
Unity のレンダラーコンポーネントが使用するマテリアルにテクスチャを割り当てる場合、Unity は自動的にミップレベルを計算するので特に気にする必要ないが、レンダラーコンポーネントを使用できんないものに関しては、Texture2D.requestMipmapLevelを使用して手動でミップレベルを計算する必要がある。
以下が手動でミップレベルを計算する必要があるものである。
・デカールプロジェクターテクスチャ
・リフレクションプローブテクスチャ。解像度の低いミップは、粗さ (roughness) のルックアップテーブルになります。そのため、Unity が低いミップマップレベルを使用すると誤った粗さでマテリアルをレンダリングしてしまいます。
・Mesh.uv (UV0 とも呼ばれる) 以外のチャンネルで UV テクスチャ座標を使用するシェーダー、またはシェーダーでテクスチャ座標を変更するシェーダー。唯一の例外は、スケールとトランスレーションの変更 (下記参照)。
■制限
・Unity はTerrain (地形) テクスチャ のミップマップストリーミングをサポートしていません。これは、Unity がテクスチャをタイル化してブレンドするために、Terrain (地形) テクスチャが常にフル解像度で利用可能である必要があるためです。
・Renderer コンポーネントがアクティブな場合、そのメッシュは、望ましいミップレベルを計算するために有効な UV 分布メトリクスを必要とします。Unity はメッシュのインポート処理の一部として、自動的に分布メトリクスを計算します。
コードからメッシュを作成する場合、Unity は分配メトリクスを自動的に計算しないため、間違ったミップレベルがロードされます。UV 配分メトリクスの計算を手動でトリガーするには、Mesh.RecalculateUVDistributionMetrics を使用します。
・Unity がストリーム化されたテクスチャを API (Graphics.DrawMeshNow など) で直接レンダリングする場合、システムにはミップレベルを計算するためのレンダラー境界や他の情報がありません。つまり、テクスチャのミップレベルを手動で設定するか、このテクスチャのミップマップストリーミングを無効にする必要があります。Unity がロードするミップレベルを手動で設定する方法について詳細は、Texture2D.requestedMipmapLevel を参照してください。
・Unity がテクスチャのミップレベルを計算する場合、シェーダーでフラグが立てられたテクスチャと同じ名前の _ST 値でそのテクスチャの scale と translation を探します。例えば、テクスチャを _ MainTex を使用してシェーダーで参照する場合、Unity は _ MainTex_ST を探します。
■スクリプトで細かく制御
これは、Unity が特定のテクスチャを完全にロードする必要がある場合に便利です。例えば、大きな距離をすばやく移動するゲームオブジェクトに関連する場合、または瞬間的なカメラカットを使用する場合などです。
Memory BudgetやRenderers Per Frameなどの設定、事前にストリーミングさせるカメラの制御、特定のミップレベルのロード、デバッグなどが主にある。
こちらを参照すると良い。
参照サイト、参照サイト、参照サイト
・ストリーミング仮想テクスチャリング
ストリーミング仮想テクスチャリングは、大まかにいえば上のミップマップストリーミングと似ているが、違うところはGPU上でカメラから距離に応じてどのミップを使用するのか、またミップ内のどの部分を詳細に使用するのかが違う。
ストリーミング仮想テクスチャリングのメリットはGPU メモリの使用量とテクスチャのロード時間を削減するできるところにある。
詳しい説明は、こちらのサイトが非常に分かりやすい。
ただ、公式ドキュメントを見るとストリーミング仮想テクスチャリングは、
この機能は実験的なものであり、運用環境で使用する準備ができていません。 機能とドキュメントは将来変更または削除される可能性があります。
と記載されており、とりあえず一旦は使用しないほうが良さそう。
参照サイト
・テクスチャのインポート設定 Sprite Mode
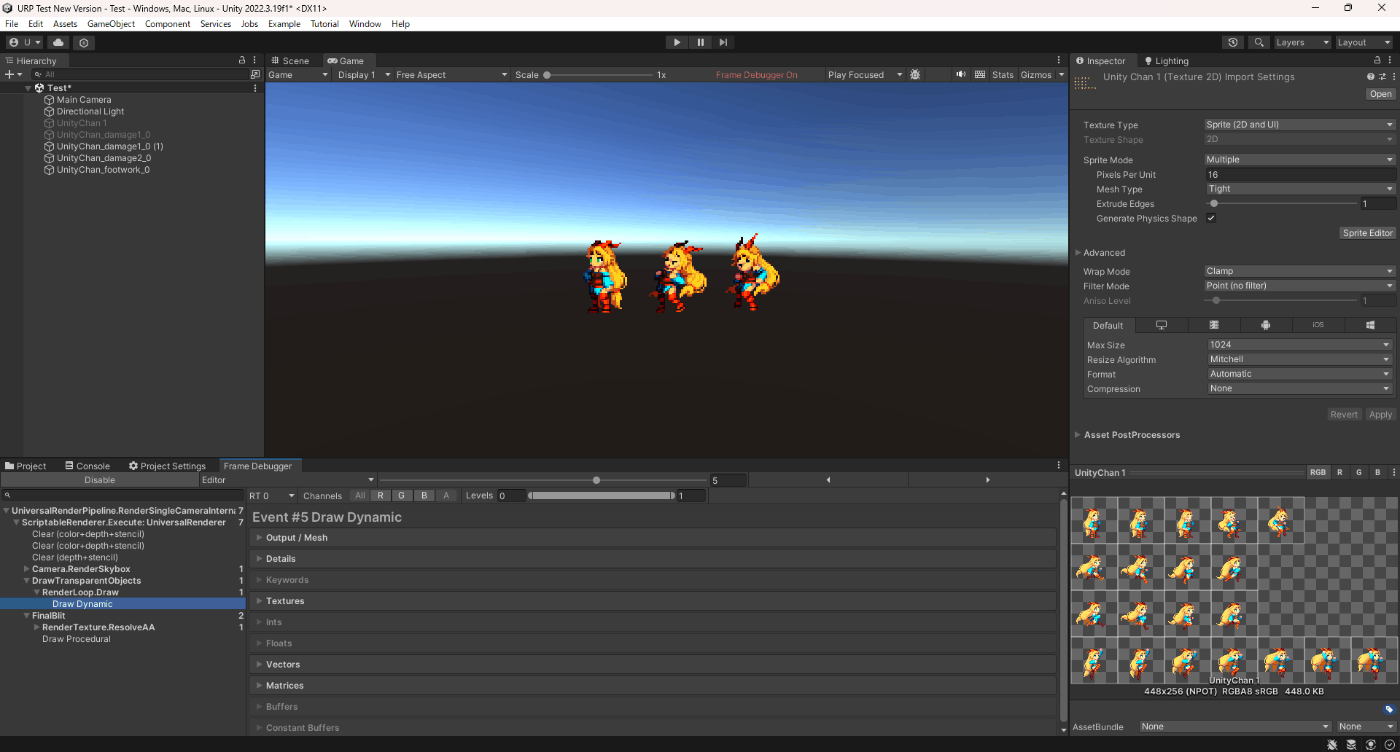
上のようなSpriteを一個一個を描画するとその分ドローコールが発生するが、Sprite ModeのMultipleを使用するとドローコールは1になるのでパフォーマンスが良くなる。
下記画像はSprite ModeをMultipleにしてフレームデバッガーで確認したもの。
分割された画像を配置してもドローコールが1であることが分かる。
なお、分割された画像生成するには、Sprite Editorで行う。
また、Sprite Modeは、Texture TypeがSprite (2D and UI)のとき表示される。
ついでにSprite Modeの各々の設定も紹介する。
■Single
作成画像をそのまま表示する。

■Multiple
画像を分割して使用できる。
赤枠が分割された画像でそれを使用できる。

■Polygon
SpriteEditor開くと、左上にSidesの項目があるので数値を入れてChangeするとSidesの数値の値に合わせてエッジが変わる。
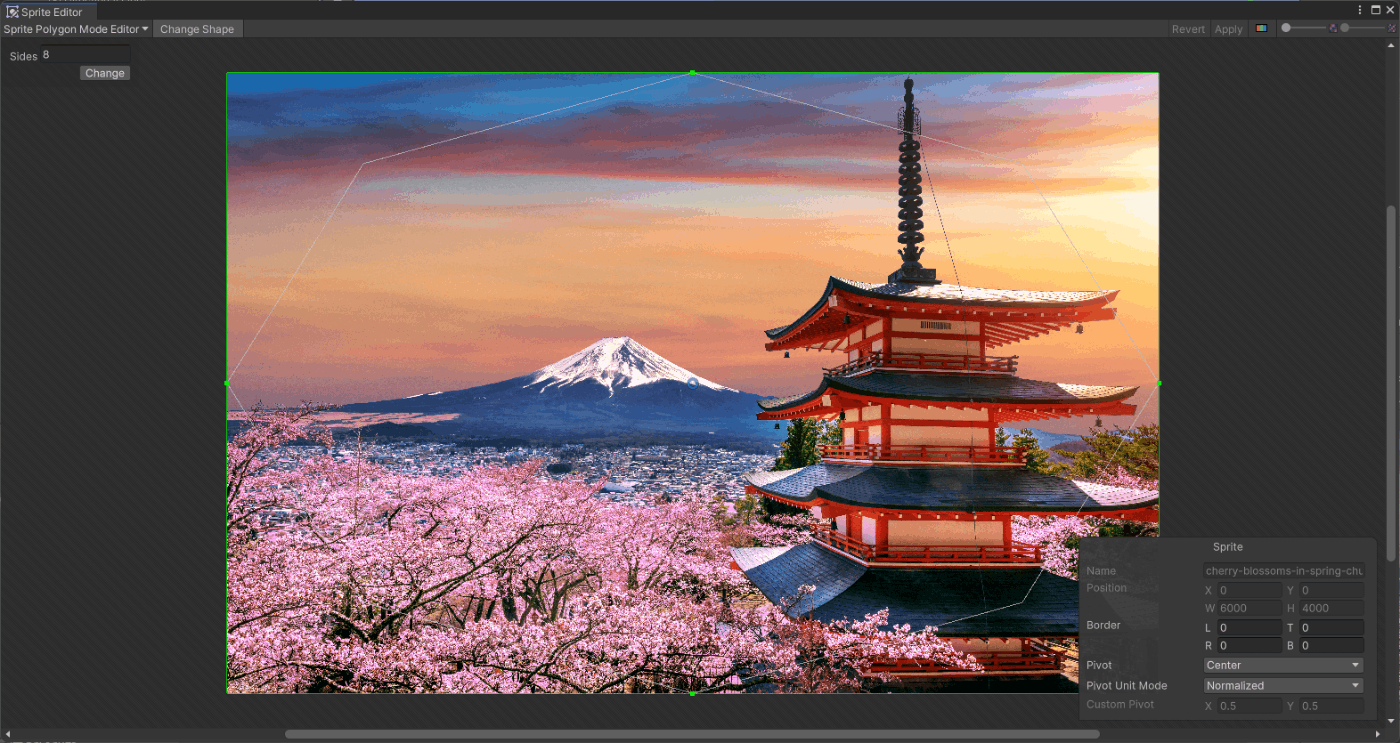

参照サイト
・テクスチャのインポート設定 Mesh Type
生成するスプライトのメッシュタイプを設定する。
TightとFill Rectがあるがどちらを選ぶかは場合による。
Mesh Typeは、Texture TypeがSprite (2D and UI)のとき表示される。
また、Tight を指定している場合でも、スプライトが 32x32 より小さい場合は Full Rect が使用されます。
下記のTightとFill Rectを比べると
TightはFill Rectに比べてポリゴン数・頂点数が多く、オーバードローが起きていないのが分かる。
なので、
ポリゴン数・頂点数がボトルネックならFill Rect。
オーバードローがボトルネックならTight。
■Tight
Tightは、不透明な部分のメッシュだけを描画する。

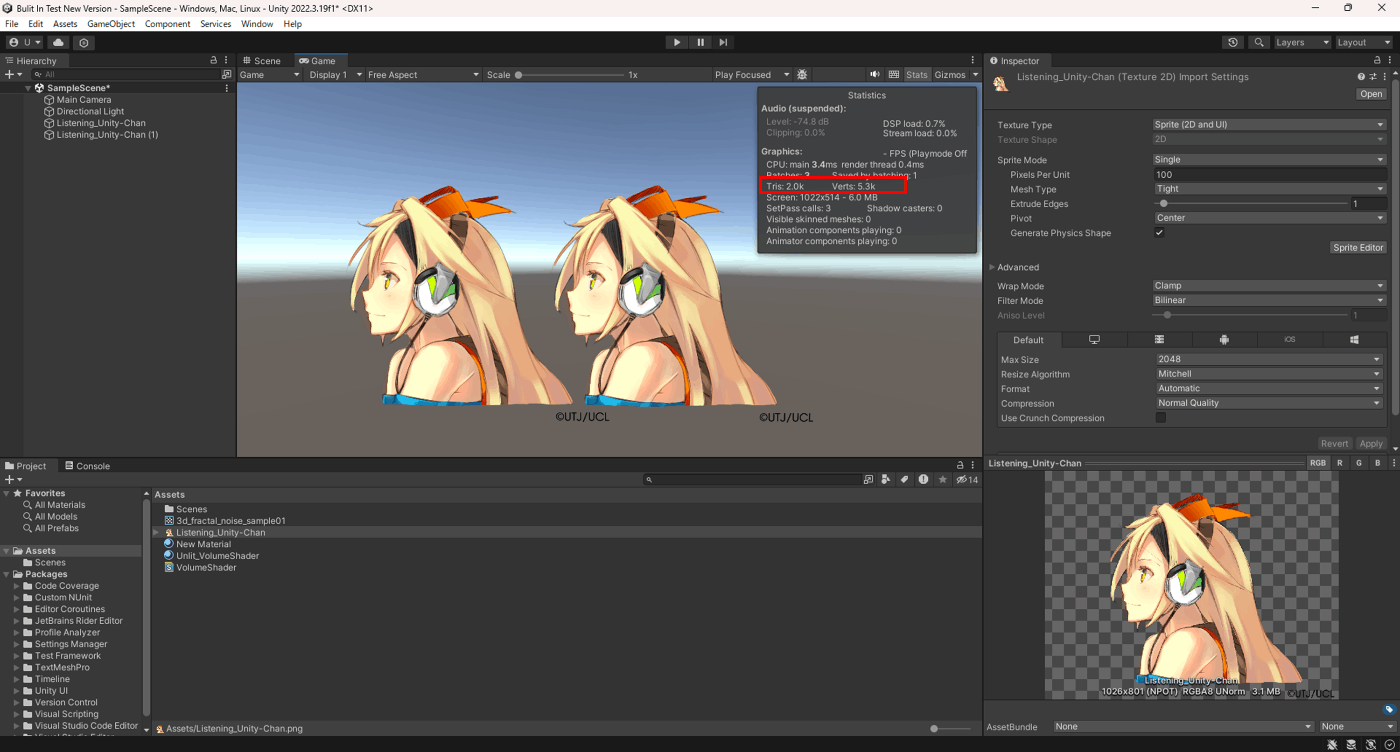
■Fill Rect
Fill Rectは、透明な部分があっても四角のメッシュを描画する。


参照サイト、参照サイト
・Asynchronous Shader Compilation 非同期シェーダーコンパイル
シェーダーオブジェクトには数百から数千の シェーダーバリアント が含まれている場合があります。シェーダーオブジェクトをロードするときにすべてのバリアントをコンパイルすると、インポートプロセスは非常に遅くなります。そのようにせず、エディターは最初にシェーダーバリアントに遭遇したときに、必要に応じてシェーダーバリアントをコンパイルします。
これらのシェーダーバリアントをコンパイルすると、グラフィックス API やシェーダーオブジェクトの複雑さに応じて、エディターがミリ秒から数秒にわたってストール (待機) することがあります。このようなストールを避けるために、非同期シェーダーコンパイルを使用してシェーダーバリアントをバックグラウンドでコンパイルし、その間プレースホルダーシェーダーオブジェクトを使用することができます。
なお非同期シェーダーコンパイルはエディターのみの機能である。
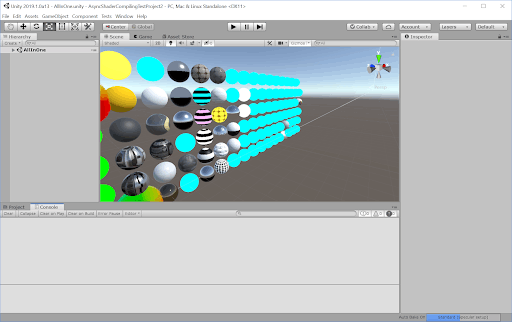
水色のオブジェクトがプレースホルダーシェーダーが適用されたオブジェクトで、シェーダーバリアントのコンパイルが終わるまでこの水色が表示される。
■例外
①DrawProcedural や CommandBuffer.DrawProcedural を使用してジオメトリを描画する場合、エディターはダミーのシェーダーを使用しません。代わりに、エディターはシェーダーバリアントをコンパイルし終わるまで、このジオメトリの描画をスキップします。
②Unity エディターは、Blit 操作による非同期シェーダーコンパイルを使用しません。これは、最も一般的な使用例で正しい出力を保証するためです。
■プロジェクトの非同期シェーダーコンパイルを有効/無効にする
Project SettingsのAsynchronous Shader Compilationを有効・無効にする。
参照サイト
・シェーダーの条件
シェーダーの条件には、静的分岐と動的分岐(シェーダーバリアント)の2種類がある。
この二つについて記載していく。
■静的分岐とは
コンパイラーがプログラムから不要なコードを除外するような条件である。
■静的分岐の使用方法
条件文に主にビルトインのマクロ使用する。
下記が静的分岐のコードである。
if SHADER_TARGET < 30
// 何の処理
#else
// 何の処理
#endif
SHADER_TARGETがビルトインのマクロでシェーダーターゲットモデルのバージョンを指定できる。
ビルトインのマクロには、グラフィックAPI、Unityのバージョン、フォワードレンダリングのベースパスなどほかにもたくさんある。ビルトインのマクロの全容はこちらを参照。
なお、ShaderGraphでは静的分岐はできなくて、あくまでもハードコーディングされたシェーダープログラムのみである。
■動的分岐(シェーダーバリアント)とは
シェーダープログラムにランタイムで評価される条件文が含まれている時に使用する条件である。
動的分岐には、均一 (uniform) 変数に基づく動的分岐と、それ以外のランタイム値に基づく動的分岐の 2 種類があります。
■動的分岐(シェーダーバリアント)の使用方法
主にmulti compile・shader feature・dynamic branchを使用する。
下記がそのmulti compileを使用した実際のシェーダープログラムである。
Shader "Sample/MultiCompile"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ RED GREEN BLUE
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
#ifdef RED
return fixed4(1, 0, 0, 1);
#elif GREEN
return fixed4(0, 1, 0, 1);
#elif BLUE
return fixed4(0, 0, 1, 0);
#endif
return fixed4(0, 0, 0, 1);
}
ENDCG
}
}
}
下記が、ランタイムで上のシェーダープログラムの色を動的に変えられるようにしたC#のプログラムである。
using UnityEngine;
public class MultiCompile : MonoBehaviour
{
private void OnGUI()
{
KeywordToggleGUI("RED");
KeywordToggleGUI("GREEN");
KeywordToggleGUI("BLUE");
}
private void KeywordToggleGUI(string keyword)
{
bool enabled = GUILayout.Toggle(Shader.IsKeywordEnabled(keyword), keyword);
if (enabled)
{
Shader.EnableKeyword(keyword);
}
else
{
Shader.DisableKeyword(keyword);
}
}
}
なお、Shader Graph では、Branch ノード を使用します
■エディタ中のコードブランチの切り替え
エディタ中のコードブランチの切り替えの場合は、shader_featureや静的分岐を使用する。
例えば、マテリアルの Inspector ウィンドウでプロパティを設定して、シェーダーに以下のような動作をさせることができます。
①マテリアルの一部のインスタンスに鏡面反射を追加し、他のインスタンスには追加しない。
②特定のオブジェクト (水中シーンに登場するオブジェクトなど) に、異なる外観を追加する。
このアプローチを用いることで、シェーダーコードの記述と管理が行いやすくなり、ビルド時間やファイルサイズ、パフォーマンスに悪影響を及ぼしにくくなります。
■ランタイムでのコードブランチの切り替え
ランタイムでのコードブランチの切り替えは、動的分岐(シェーダーバリアント)を使用する。
例えば、C# スクリプトを使ってシェーダーに以下のような処理をさせることができます。
①マテリアルを動的に変更して、特定の時間に雪が積もるようにする。
②ユーザーが品質設定を変更した時にマテリアルを変更する。例えば、フォグを表示するかどうかをユーザーが動的に制御できるようにする。
■静的分岐と動的分岐(シェーダーバリアント)のパフォーマンス
静的分岐を使用する場合、コンパイラーがシェーダープログラムから不要なコードを除外します。この結果、必要なコードのみを含む、小さく特化したシェーダープログラムが作成されるので、この結果、ロード時間が短くなりランタイムのメモリ使用量も少なくなる傾向にある。
一方で、動的分岐(シェーダーバリアント)は、この逆で全ての条件のコードが同じシェーダープログラムにコンパイルされるため、シェーダープログラムが大きくなる可能性があり、静的分岐に比べて、ビルド時間、ファイルサイズ、ロード時間、メモリ使用量が多くなる可能性がある。
参照サイト、参照サイト
・シェーダーバリアントの数を減らすためには必要なこと
シェーダーバリアントの数が多いと、ビルド時間と実行時のパフォーマンスの問題の両方につながる可能性がある。
なので今回その減らすために必要なことを述べていく。
■静的条件と動的条件を正しいケースで使う。
静的条件と動的条件(シェーダーバリアント)の使い分けは上で述べているため割愛。
■使用しないプラットフォームやグラフィックAPIは排除する
シェーダーバリアントは、プラットフォームやグラフィックAPIの数だけシェーダーバリアントをコンパイルする。
なので、プラットフォームやグラフィックAPIの数が多ければ多いほど、ビルド時間と実行時のパフォーマンスの問題が出てきてしまう。
そのために、使用しないプラットフォームやグラフィックAPIは避ける。
プラットフォームを排除するのは分かりやすいが、グラフィックAPIは若干分かりにくい。

Project SettingsのPlayerにグラフィックAPIを指定できる項目があるので必要のないグラフィックAPIを削除する。
■シェーダーバリアントの数の確認する
シェーダーバリアントの数を確認することもシェーダーバリアントの数を減らすためには必要なことです。
なので今回はそれを述べていく。
①エディタ上で確認
Graphics のCurrently trackedの数を確認できる。

また、その下のSave to asset…ボタンを押下してシェーダーバリアントコレクション作成できる
シェーダーバリアントコレクションについてはのちほど後述する。
②ビルド時に出力されるEditor.logを確認
ビルド時に出力されるEditor.logを確認すると、シェーダーバリアントの数とストリッピングしたシェーダーバリアントも数が分かる。
Compiling shader "Universal Render Pipeline/Lit" pass "ForwardLit" (fp)
320 / 786432 variants left after stripping, processed in 6.77 seconds
starting compilation...
finished in 29.72 seconds. Local cache hits 202 (0.24s CPU time), remote cache hits 0 (0.00s CPU time), compiled 118 variants (582.41s CPU time), skipped 0 variants
URP またはHDRPを使用している場合は、Unity がコンパイルおよび除去するバリアントの合計数をログに記録することも可能です。以下を開き、Shader Stripping > Shader Variant Log Level の下で、Disabled 以外のレベルを選択してください。
STRIPPING: Universal Render Pipeline/Lit (ForwardLit pass) (Fragment) - Remaining shader variants = 640/5760 = 11.11111% - Total = 2657/10169 = 26.12843%
Editor.logが出力場所はOSごとに違うのでこちらを参照。
③ランタイムの確認
GraphicsのLog Shader CompilationとBuild SettingsのDevelopment Buildをオンにして、ConsoleのEdotorを選択し、Full Log [Developer Mode Only] をオンにした状態で、ビルドしたゲームを起動すると確認できる。

④シェーダーが使用するメモリの量を確認
ProfileのMemoryとMemory Profilerのシェーダーが、大量のメモリを使用している場合は、そのバリアントを試しに除去してみることがおすすめ。
⑤ランタイムでストリップしたシェーダーバリアントをピンク色で表示する。
Other SettingsのStrict shader variant matchingをオンにすると、ストリップしたシェーダーバリアントをマテリアルが使用しようとする場合、ピンク色で表示される。
また、コンソールにも警告表示する。
■シェーダーバリアントの数は、積なので闇雲にシェーダーバリアント追加するの注意
Shader "Sample/MultiCompile"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ RED GREEN BLUE
#pragma multi_compile _ APPLE GRAPE BANANA
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
#ifdef RED
return fixed4(1, 0, 0, 1);
#elif GREEN
return fixed4(0, 1, 0, 1);
#elif BLUE
return fixed4(0, 0, 1, 0);
#elif APPLE
return fixed4(1, 0, 0, 1);
#elif GRAPE
return fixed4(0, 1, 0, 1);
#elif BANANA
return fixed4(0, 0, 1, 0);
#endif
return fixed4(0, 0, 0, 1);
}
ENDCG
}
}
}
上のシェーダーバリアントは8個あるように見えるが、実際は16個である。
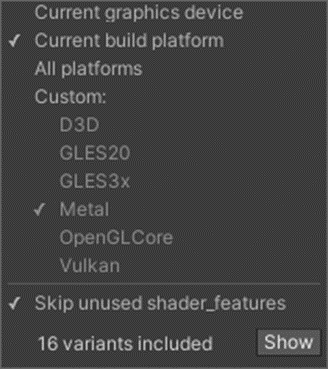
なので、闇雲にシェーダーバリアント追加していくと膨大なシェーダーバリアントになるので注意する必要がある。
■同一バリアントは避ける
Shader "Sample/MultiCompile"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ RED GREEN BLUE
#pragma multi_compile _ RED GREEN BLUE
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
#ifdef RED
return fixed4(1, 0, 0, 1);
#elif GREEN
return fixed4(0, 1, 0, 1);
#elif BLUE
return fixed4(0, 0, 1, 0);
#endif
return fixed4(0, 0, 0, 1);
}
ENDCG
}
}
}
上のソースコードだと、_ RED GREEN BLUEが二つあるがこれはUnityの機能の重複排除により、シェーダーバリアントの数が4である。
ただ、この重複排除されるからといって同一バリアントはできるだけ排除した方が良い。
なぜなら、重複排除により、同じパス内の同一のバリアントによるファイル サイズの増加が防止されるが、同一のバリアントを使用しても、コンパイル中に無駄な作業が発生し、実行時のメモリ使用量とシェーダのロード時間が増加するため。
■プリプロセッサーマクロを使用してプラットフォームごとにシェーダーバリアント数を制限する。
下記のように、プラットフォームがモバイルの場合は、multi_compileなので4つのシェーダーバリアントを生成するが、それ以外はshader_featureなのでシェーダーバリアントが1つである。
# ifdef SHADER_API_MOBILE
//プラットフォームがモバイルの場合
#pragma multi_compile _ RED GREEN BLUE WHITE
# else
#pragma shader_feature RED GREEN BLUE WHITE
# endif
ターゲットプラットフォームのプリプロセッサーマクロについては[こちら]
(https://docs.unity3d.com/ja/2023.2/Manual/SL-BuiltinMacros.html)を参照
■ユーザー制御の品質設定の作成してシェーダーバリアント数を制限する
メモリが制限されるコンソールやモバイルプラットフォーム用にビルドする場合、ユーザーが少数の品質設定の中での切り替えしか行えないようにすることで、シェーダーバリアントの数を制限することができます。
例えば、以下のコードサンプルの場合、ユーザーは、SHADER_API_DESKTOP プラットフォームでは 8 通りの設定を切り替えることができますが、SHADER_API_MOBILE プラットフォームでは 2 通りの設定しか切り替えられません。
# if SHADER_API_DESKTOP
#pragma multi_compile SHADOWS_LOW SHADOWS_HIGH
#pragma multi_compile REFLECTIONS_LOW REFLECTIONS_HIGH
#pragma multi_compile CAUSTICS_LOW CAUSTICS_HIGH
# elif SHADER_API_MOBILE
#pragma multi_compile QUALITY_LOW QUALITY_HIGH
#pragma shader_feature CAUSTICS
# endif
■Unityの設定項目でシェーダーバリアント数を削減する
①GraphicsのShader stripping
Lightmap modes(ライトマップ)、Fog modes(フォグ)、Instancing Variants(GPU インスタンシング)、BatchRendererGroup Variantsで細かく削除する項目を設定できる。

②GraphicsのAlways Included Shadersに必要のないシェーダーを含めない
③URPを使用している場合は、Universal Render Pipeline Assetで使用していない項目はオフにする
Universal Render Pipeline Assetで無効になっている項目は、シェーダーバリアントが削除されるので必要のない項目は無効にした方が良い。
ただし、URP Graphics settingsのStrip Unused Variantsがオンになっていないとダメ。
また、ビルド際に含まれるUniversal Render Pipeline Assetは、
GraphicsのScriptable Render Pipeline Settingsと、Qualityの各Levelsで設定したRender Pipeline AssetのUniversal Render Pipeline Asset。
④URPを使用している場合は、ボリュームの使用していないポストプロセスは削除する。
これも上のと同じで使用していないポストプロセス削除することで、シェーダーバリアントが削除される。
ただし、URP Graphics settingsがStrip Unused Post Processing Variantsがオンになっていないとダメ。
⑤Package ManagerのXRとVRの必要のないモジュールをインポートしない
Package ManagerのXRとVRのモジュールが必要がないならインポートしない
必要がないのに、これらをインポートするとシェーダーバリアントが増える。
⑥スクリプトでシェーダーバリアントを削除
上の方法以外でシェーダーバリアントを削除する方法は、スクリプト(スクリプタブルシェーダーバリアント)で行う。
IPreprocessShaders.OnProcessShaderとIPreprocessComputeShaders.OnProcessComputeShader
のコールバック関数を使用して行う。
例えばデフォルトでは、Unity は全てのグラフィックスシェーダープログラムに、
STEREO_INSTANCING_ON, STEREO_MULTIVIEW_ON、STEREO_CUBEMAP_RENDER_ON、UNITY_SINGLE_PASS_STEREO のシェーダーバリアント生成するが、スクリプタブルシェーダーバリアントを使用すればこれら削除できる。
詳しい内容はこちらを参照。
■一つのシェーダーに128個よりも多いキーワードを使用するとパフォーマンスが落ちるので注意
参照サイト、参照サイト、参照サイト、参照サイト
・C#スクリプトで、ランタイムでシェーダーを動的に変えるときはなるべくローカルシェーダーキーワードで変える。
ローカルシェーダーキーワードは、LocalKeywordを使用してシェーダーをランタイムで変える。
グローバルシェーダーキーワードは、GlobalKeyword を使用してシェーダーをランタイムで変える。
グローバルシェーダーキーワードの方がマテリアルをアタッチしなくて済むので簡単にシェーダーをランタイムで変えることができるが、その分CPUに負荷がかかってしまう。(対策としては、できるだけ、アプリケーションの開始後すぐに (アプリケーションのロード中に) 全てのグローバルキーワードを作成するのが良い)
ただ、ランタイムでシェーダーバリアントを扱うキーワードを有効化または無効化すると、負荷がかかってしまう。公式ドキュメントには以下のように記載されている。
シェーダーバリアントを扱うキーワードを有効化または無効化すると、Unity は別のシェーダーバリアントを使用します。ランタイムにシェーダーバリアントを変更すると、パフォーマンスに影響を与える可能性があります。キーワードを変更するために特定のバリアントを初めて使用する必要が生じる場合、グラフィックスドライバーがシェーダープログラムの準備をする間に、がたつきが発生する可能性があります。これは、大きなシェーダーや複雑なシェーダーで、あるいはグローバルキーワードの状態の変化が複数のシェーダーに影響する場合に、特に問題となる場合があります。これを回避するため、シェーダーバリアントでキーワードを使用する場合には、シェーダーのローディングと事前準備のアプローチを決定する際にキーワードバリアントのことを考慮してください。詳細は、Unity がシェーダーをロードして使用する方法 を参照してください。
こちらについては後述する。
では実際にローカルシェーダーキーワードとグローバルシェーダーキーワードを使用してみる。

Cubeには、ローカルシェーダーキーワードとグローバルシェーダーキーワード含んだ以下のShaderがアタッチされている
Shader "ShaderKeyWord"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ RED GREEN BLUE//ローカルシェーダーキーワード
#pragma multi_compile _ YELLOW WHITE//グローバルシェーダーキーワード
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
#ifdef RED
return fixed4(1, 0, 0, 1);
#elif GREEN
return fixed4(0, 1, 0, 1);
#elif BLUE
return fixed4(0, 0, 1, 0);
#elif YELLOW
return fixed4(1, 1, 0, 0);
#elif WHITE
return fixed4(1, 1, 1, 0);
#endif
return fixed4(0, 0, 0, 1);
}
ENDCG
}
}
}
CapsuleとSphereには、グローバルシェーダーキーワード含んだ以下のShaderがアタッチされている
Shader "ShaderKeyWord"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _ YELLOW WHITE//グローバルシェーダーキーワード
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
#ifdef YELLOW
return fixed4(1, 1, 0, 0);
#elif WHITE
return fixed4(1, 1, 1, 0);
#endif
return fixed4(0, 0, 0, 1);
}
ENDCG
}
}
}
LocalShaderKeyWordオブジェクトに、ローカルシェーダーキーワードをランタイムで切り替える以下のスクリプトがアタッチされている。
using UnityEngine;
using UnityEngine.Rendering;
public class LocalShaderKeyWord : MonoBehaviour
{
private LocalKeyword localKeywordRed;
private LocalKeyword localKeywordGREEN;
private LocalKeyword localKeywordBLUE;
public Material material;
void Start()
{
Shader shader = material.shader;
localKeywordRed = new LocalKeyword(shader,"RED");
localKeywordGREEN = new LocalKeyword(shader, "GREEN");
localKeywordBLUE = new LocalKeyword(shader, "BLUE");
}
void Update()
{
//赤色のローカルシェーダーキーワードを有効。それ以外は無効
if (Input.GetKey(KeyCode.R))
{
material.SetKeyword(localKeywordRed, true);
material.SetKeyword(localKeywordGREEN, false);
material.SetKeyword(localKeywordBLUE, false);
}
//緑色のローカルシェーダーキーワードを有効。それ以外は無効
if (Input.GetKey(KeyCode.G))
{
material.SetKeyword(localKeywordRed, false);
material.SetKeyword(localKeywordGREEN, true);
material.SetKeyword(localKeywordBLUE, false);
}
//青色のローカルシェーダーキーワードを有効。それ以外は無効
if (Input.GetKey(KeyCode.B))
{
material.SetKeyword(localKeywordRed, false);
material.SetKeyword(localKeywordGREEN, false);
material.SetKeyword(localKeywordBLUE, true);
}
}
}
GloballShaderKeyWordオブジェクトに、グローバルシェーダーキーワードをランタイムで切り替える以下のスクリプトがアタッチされている。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Rendering;
public class GloballShaderKeyWord : MonoBehaviour
{
private GlobalKeyword globalKeywordYELLOW;
private GlobalKeyword globalKeywordWHITE;
void Start()
{
globalKeywordYELLOW = GlobalKeyword.Create("YELLOW");
globalKeywordWHITE = GlobalKeyword.Create("WHITE");
}
void Update()
{
//黄色のグローバルシェーダーキーワードを有効。それ以外は無効
if (Input.GetKey(KeyCode.Y))
{
Shader.SetKeyword(globalKeywordYELLOW, true);
Shader.SetKeyword(globalKeywordWHITE, false);
}
//白色のグローバルシェーダーキーワードを有効。それ以外は無効
if (Input.GetKey(KeyCode.W))
{
Shader.SetKeyword(globalKeywordYELLOW, false);
Shader.SetKeyword(globalKeywordWHITE, true);
}
}
}
Rを押下
ローカルシェーダーキーワードがアタッチされたCubeが赤色になっていることが分かる。
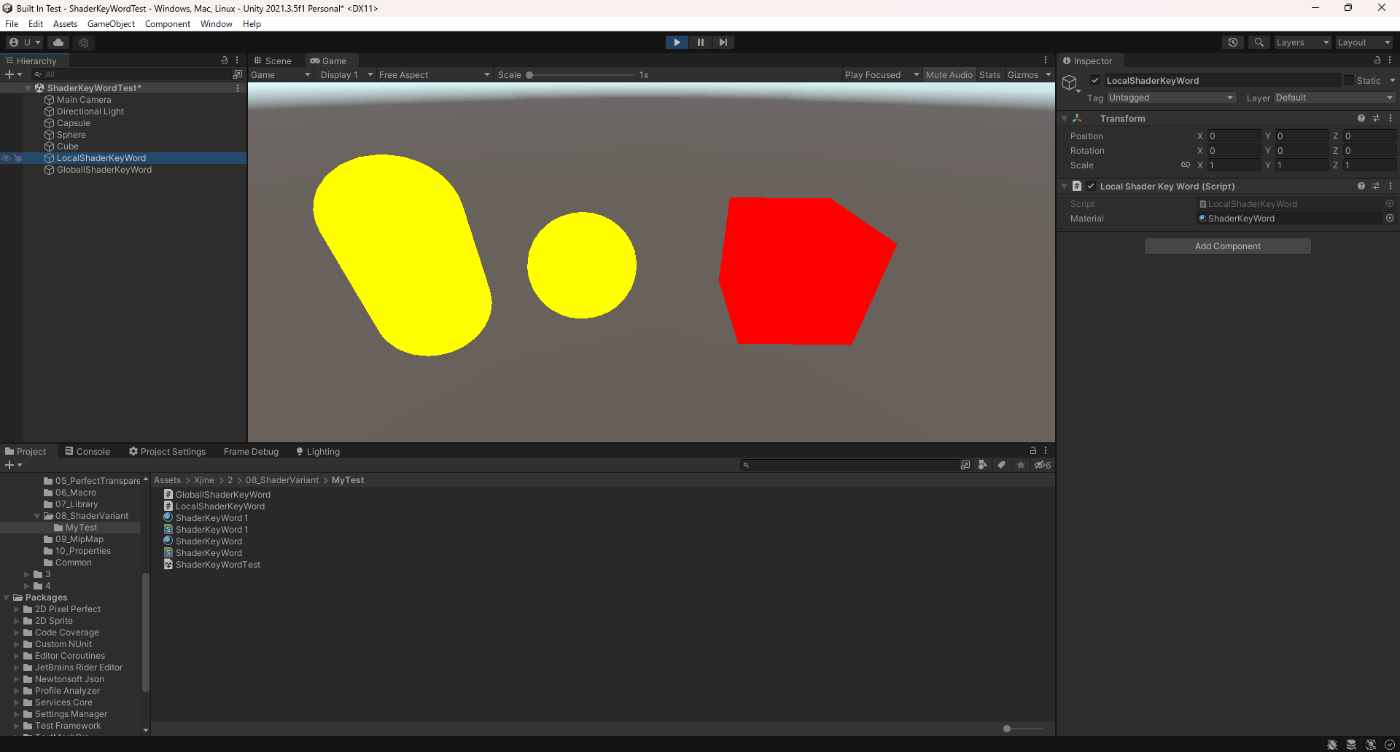
Gを押下
ローカルシェーダーキーワードがアタッチされたCubeが緑色になっていることが分かる。

Wを押下
グローバーキーワードがアタッチされたCapsuleとSphereが白色になっていることが分かる。
一方で、グローバーキーワードがアタッチされたCubeは白色になっていないことが分かる。
このことからシェーダーの中に、ローカルシェーダーキーワードとグローバーキーワードが混在していた場合ローカルシェーダーキーワードが優先されることが分かる。

参照サイト
・シェーダーバリアントの事前準備を行い、シェーダーバリアントが必要になった時の遅延をなくす
公式ドキュメントによるとシェーダーがロードされる方法は以下である。
1.Unity は、シーンや ランタイムリソース をロードする際に、シーンやリソース用にコンパイルされたシェーダーバリアントを全て CPU メモリにロードします。
2.デフォルトでは、Unity は、全てのシェーダーバリアントを CPU メモリの別の領域に解凍します。シェーダーのメモリ使用量をプラットフォームごとに制御する ことが可能です。
3.Unity がシェーダーバリアントを使ってジオメトリをレンダリングする必要が初めて生じた時、Unity は、シェーダーバリアントとそのデータをグラフィックス API とグラフィックスドライバーに渡します。
4.グラフィックスドライバーは、シェーダーバリアントの GPU 専用バージョンを作成して、それを GPU にアップロードします。
つまり、シェーダーが必要になったときにはじめてGPUへアップロードされるというわけだ。
ランタイムにシェーダーバリアントを変更(上の記事で紹介している)をしたりすると、GPUへアップロードなどが完了するまでに若干の遅延が起きる可能性がある。
これを、防ぐためにシェーダーバリアントの事前準備を行う必要がある。
その事前準備のやり方やその他について述べていく
■スクリプトを使用して事前準備を行う
Experimental.Rendering.ShaderWarmupとShaderVariantCollection.WarmUpとShader.WarmupAllShadersを使用すれば、シェーダーバリアントが初めて必要になる前に GPU 内に作成するようリクエストすることができます。
■エディタ上のPreloaded Shadersにシェーダーバリアントコレクションを設定し、事前準備を行う

Preload Shadersに事前準備したいシェーダーバリアントコレクションを設定するとUnity は、ビルド済みアプリケーションの起動時に、ShaderVariantCollection.WarmUp API を使用してシェーダーバリアントコレクションの事前準備を行います。
では、シェーダーバリアントコレクションについて少し触れておこうと思います。
①シェーダーバリアントコレクション(ShaderVariantCollection)の作成の仕方
作り方は2種類あって、
一つ目が、Create Asset メニューで、Shader > Shader Variant Collection で一から作成する方法。

二つ目が、GraphicsにSave to asset...ボタンがあるのでこれを押下するとUnityが自動的に作成してくれる方法。

②AssetBundle(ASS)運用時のストリッピングを防ぐためにも使用される
詳しい内容はこちらを参照
■DirectX 12、Metal、または Vulkan での事前準備には注意が必要
ただDirectX 12、Metal、または Vulkanの場合は、
グラフィックスドライバーは、正確な頂点データレイアウトとレンダー状態が分かる場合にのみ、シェーダーバリアントの正確な GPU 表現を作成できます。事前準備された GPU 表現が不正確な場合、Unity が正確な表現を作成しなければならない時点でストールが発生する可能性が残ります。
と公式ドキュメントに記載されているので、確実に事前準備するためには、
オフスクリーンでレンダリングするか、Experimental.Rendering.ShaderWarmup、ShaderVariantCollection.Warmup または Shader.WarmupAllShadersを使用しないといけない。
■シェーダーのメモリ使用量の制御
シェーダーがロードされる際は、Unityは全てのシェーダーバリアントを CPU メモリの別の領域に解凍する過程がある。
メモリ制限のあるプラットフォームでメモリ使用量を削減するために、Chunk sizeとChunk countを調整してメモリ使用量を削減することができる。

■Profilerでシェーダーのロード確認
①Shader.ParseThreaded と Shader.ParseMainThread (Unity の、シリアライズされたデータからのシェーダーオブジェクトのローディング)
②Shader.CreateGPU (Unity の、シェーダーバリアントの GPU 固有バージョンの作成)
参照サイト、参照サイト、参照サイト
・シェーダーの最適化
■必要なものだけ計算する
当たり前だがシェーダーコードが行う計算や処理が多ければ多いほど、ゲームのパフォーマンスに影響を与るので不要な計算は行わない。
■計算の頻度を意識する
例えば、頂点シェーダよりピクセルシェーダーのほうが計算数が多い。
なのでピクセルシェーダーで重い処理などを行うとその分パフォーマンスに影響が出てしまう。
もし頂点シェーダーで行っても問題ないようであれば頂点シェーダーで処理を行うのも検討してみるのもいいかも。
もしくは、C#のスクリプト上で計算してその結果をシェーダーに渡すことなんかもいいかもしれない。
■なるべく小さい型にする
Cg/HLSL でシェーダーを書く場合、3 つの基本的な数値タイプがあります。 float、half、fixedがある。
計算精度は、floatが一番精度が高くてfixedが一番精度が低く、halfが中間精度である。
当然、計算精度が高い型はその分負荷も高い。
なので、なるべく小さい型を使用したほうが良い。
Unityの公式ドキュメントだと、以下の場合で使い分けをしたらいいと記載されている。
・ワールド空間の位置とテクスチャ座標には、float 型を使用してください。
・上記以外 (ベクトル、HDR カラーなど) には、half で始めます。必要なときだけ、増加します。
・テクスチャデータのとても簡易な操作には、fixed を使用します。
一方で、プラットフォームやGPUの種類によっては型が変わる可能性がある。
例えば、PC (Windows/Mac/Linux) は常にfloatで計算する。
また、GPUによって以下の画像のように型が変わる。

■数学関数の使用を控える
such as pow, exp, log, cos, sin, tanといった数学関数はなるべく使用を控えたほうが良い。
もし使用したい場合は、LUTを使用するのがおすすめ。
また、独自の操作 (normalize、dot、inversesqrt など) を書くことを避けた方が良い。なるべくUnityが用意してくれているのであればそれを使用する。
■Unity側用意してくれてるシェーダーを使用する際、必要のない処理をなくす
Unity側用意してくれてるシェーダーはある特定の状況向けに最適化されているのではなく、一般的なケース向けに対応できるようになっています。なので多くの場合、それを微調整することでシェーダーの実行を速くするか、サイズを小さくすることができます。
Unityのサーフェイスシェーダーを実際に減らしたのが以下である。
・approxview ディレクティブは、ビュー方向を使用するシェーダー(鏡面)のためにあり、ピクセルごとでなく頂点ごとにビュー方向を正規化します。概算ですが、通常はこれで十分です。
・halfasview は鏡面シェーダータイプをさらに早くします。Half-vector (ライティング方向とビューベクトルの中間)が計算され頂点ごとに正規化され、ライティングの関数 はあらかじめ、中間ベクトルをビューベクトルの代わりに、引数として受け取ります。
・noforwardadd によりシェーダーは、フォワードレンダリングで指向性ライトのみ完全にサポートします。残りのライトは、頂点ライトや球面調和としてのエフェクトを、引き続き表現することができます。これはシェーダーを小さくすることに優れていて、複数のライトが存在していても、常にひとつのパスでレンダリングされます。
・noambient により、シェーダーの環境光ライティングおよび球面調和を、無効化しますこれによりわずかに速くなります。
■AlphaTestやclip()などでアルファテストを行うことの最適化は慎重に
アルファテストで、描画されない箇所はその分負荷がかからないのでパフォーマンスが上がる。
ただ、公式ドキュメントには以下のように記載されている。
しかし、iOS といくつかの Android デバイスでみられる PowerVR GPU では、アルファテストは高価です。ゲームがかえって遅くなるため、このプラットフォームでは、パフォーマンス最適化として使用しないでください。
とあるのでモバイルでもリリースする際は、アルファテストによる最適化は行わないほうがいいかも。
■カラーマスク(ColorMask)の使用はなるべく避ける
いくつかのプラットフォーム(たいてい、モバイル GPU は iOS と Android)では、カラーマスクを使用するのは負荷がかかるので必要であるときに使用する。
参照サイト、参照サイト
・Particle SystemのGPU インスタンシング
GPU インスタンシングとは同じモデルを大量にパフォーマンス良く描画できる技術のことである。
Particle System側でもGPU インスタンシングは可能である。
やり方としては、
Particle Systemだと以下の赤枠のRender ModeをMesh、Enable Mesh GPU Instancingを有効にすればできる。

ただ、シェーダー側もGPU インスタンシング側用にコードを書かないといけないが、デフォルトのマテリアルはすでにGPU インスタンシング側用に書かれているので今回は気にしない(のちほどシェーダー側の対応も記載する)。
GPU インスタンシングの対応なし

GPU インスタンシングの対応あり

GPU インスタンシングの対応ありのほうが圧倒的にFPSが高いことが分かる。
■GPU インスタンシング可能なグラフィックAPI
GPU インスタンシングは#pragma target 4.5以上でないと、使用できない。
つまり、以下のグラフィックAPIで可能。
DirectX 11 機能レベル 11 以降
OpenGL 4.3 以降
OpenGL ES 3.1
Vulkan
Metal
■GPU インスタンシングに対応したシェーダー
GPU インスタンシングに対応したシェーダー以下である。
コメントがある箇所がGPU インスタンシングする際最低限必要なもの。
Shader "Test"
{
Properties
{
}
SubShader
{
Tags { }
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
// インスタンシング用バリアントを作る
#pragma multi_compile_instancing
// プロシージャルインスタンシングを有効化
#pragma instancing_options procedural:vertInstancingSetup
#include "UnityCG.cginc"
// 上記のvertInstancingSetupが定義されているcgincをインクルード
#include "UnityStandardParticleInstancing.cginc"
struct appdata
{
float4 vertex : POSITION;
// 頂点情報にインスタンスIDを追加
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
v2f o;
// インスタンスIDを初期化
UNITY_SETUP_INSTANCE_ID(v);
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
return fixed4(1,1,1,1);
}
ENDCG
}
}
}
Enable Mesh GPU Instancingを有効・無効にして、GPU インスタンシングが機能しているか確認してみる。
Enable Mesh GPU Instancingオフ(GPU インスタンシング オフ)

Enable Mesh GPU Instancingオン(GPU インスタンシング オン)

確かにGPU インスタンシングが機能しているのが分かる。
他にもCustom Vertex Streamsなどもやりたい場合は参照サイトを参照。
参照サイト、参照サイト
・Particle Systemで、C# Job System
すこし重そうなので一旦参照サイトだけ記載。
参照サイト
・レンダリングの CPU コストの削減
通常、CPU のレンダリング時間に最も影響するのは、GPU にレンダリングコマンドを送信するためのコストです。レンダリングコマンドには、ドローコール (ジオメトリを描画するコマン ド) と、ジオメトリを描画する前に GPU の設定を変更するコマンドがあります。
今回はレンダリングの CPU コストの削減について書いていく。
なおこれらのアプローチの多くは、GPU で必要な作業も削減します。例えば、Unity が 1 フレームでレンダリングするオブジェクトの総数を減らせば、CPU と GPU の両方の作業負荷が軽減されます。
■レンダリングするオブジェクトの数を減らす
①シーン内のオブジェクトの全体的な数を減らすことを検討する。
例えば、スカイボックス を使用して遠景のモデルを描画しない工夫をするなど
②オクルージョンカリングを使用する
③Camera のファークリップ面を小さくする
Far100

Far1

ドローコールが少なくなっている。
④Camera.layerCullDistances でレイヤーごとにカリングの距離設定
まずレイヤーに、A、B、Cを用意する。

以下がソースである。
using UnityEngine;
public class Test : MonoBehaviour
{
public int aLayerDistance;
public int bLayerDistance;
public int cLayerDistance;
void Start()
{
Camera camera = GetComponent<Camera>();
float[] distances = new float[32];
distances[6] = aLayerDistance;//Aレイヤー
distances[7] = bLayerDistance;//Bレイヤー
distances[8] = cLayerDistance;//Cレイヤー
camera.layerCullDistances = distances;
}
}
A、B、Cのオブジェクト用意して設定したレイヤーに、A、B、Cを割り当てて実験してみた。
カリングされないパターン

Bのオブジェクトだけカリングされるパターン

確かにBのオブジェクトだけカリングされるパターンは、Bだけカリングされてドローコールが少なくなっているのが分かる。
■各オブジェクトをレンダリングする回数を削減する
①ライトマップを使用する
ビルド時間、ランタイムメモリー使用量、ストレージスペースが増加しますが、ランタイムのパフォーマンスを向上させることができます。
②フォワードレンダリングを使用する場合、ピクセル単位のライティングは避ける。
URPではこちらでピクセル単位か頂点単位かでライティングを設定できる。

ピクセル単位ライティングだと頂点単位ライティングと比べて見た目はよくなるが、負荷が高くなる
頂点単位(Per Vertex)

ピクセル単位(Per Pixel)

確かにピクセル単位ライティングだと頂点単位ライティングと比べて見た目はよくなるが、負荷が高いことが分かる。
③リアルタイムの影は負荷がかかるので、シャドウマップを使用する
④リフレクションプローブを使用する場合は、最適化を行う
最適化の仕方は、最適化1メモにある。
■レンダリングコマンドを準備し送信するのに必要な作業量を減らす
これを実現するには、Unityでは主に以下を提供している。
GPU インスタンシング、静的バッチ処理、動的バッチ処理、手動でメッシュを結合、SRP バッチャーで可能。
これらについては後述する。
参照サイト
・レンダリングの GPU コスト削減
GPU がフレームをレンダリングする時間内に作業を完了できない理由は主に 3 つあります。
■フィルレートによって制限されている場合
①オーバードローを削減する
オーバードローの最も一般的な原因は、UI、パーティクル、スプライトなどの重なり合った透明な要素である。
Unity エディターでは Overdraw モード を使用して、これが問題となる領域を特定できるが、ビルトインしか存在しない。
②フラグメントシェーダーの実行コストを削減する
③Dynamic Resolutionの検討
■メモリ帯域幅によって制限されている場合
①ミップマップ を使用する
テクスチャのメモリ使用量とストレージスペースが増えますが、ランタイムの GPU パフォーマンスを向上させることができます。
②適切な 圧縮形式 を使用して、メモリ内のテクスチャのサイズを削減する
ロード時間を短縮し、メモリフットプリントを縮小し、GPU レンダリングパフォーマンスを改善できます。
■頂点処理によって制限される場合
①頂点シェーダーの実行コストを削減する
②ジオメトリを最適化する
実際のやり方は、最適化メモ1の最適なパフォーマンスのためのモデル作成を参照
③LODを使用する
参照サイト
・OnDemandRenderingAPIで、レンダリングの頻度下げる
OnDemandRenderingAPIでレンダリングの頻度下げると、不必要な電力消費を防ぎ、バッテリーを長持ちさせ、サーマルスロットリングを防ぐことができます。
Application.targetFrameRateでFPSを変更できるが、その違いは以下の方が分かりやすくまとめてくれたの参照する。

つまり、レンダリングの頻度は下げて、Update内などの処理はそのままFPSで実施するというmこの。
使用する箇所としては、レンダリングの必要性があまりない、メニューやポーズ画面、入力待ちのターン制ゲームなどに負荷を減らす目的で採用してみるのもいいかも。
実際にやってみる。
ソースコードはこちら。
using UnityEngine;
using UnityEngine.Rendering;
public class Test : MonoBehaviour
{
// 最初のフレームが更新される前に Start を呼び出します
void Start()
{
QualitySettings.vSyncCount = 0;
Application.targetFrameRate = 60;
// メニューが起動したら、レンダリングのターゲットを 60fps に設定します
OnDemandRendering.renderFrameInterval = 1;
}
// 1 フレームに 1 回 Update が呼び出される
void Update()
{
if (Input.GetKey(KeyCode.A))
{
// マウスクリックやタッチ操作が検出されたら、(1フレームごとに)60fps でレンダリングします
OnDemandRendering.renderFrameInterval = 1;
}
if (Input.GetKey(KeyCode.B))
{
//マウスやタッチによる入力がない場合は(15 フレームごとに)4fps でレンダリングします
OnDemandRendering.renderFrameInterval = 15;
}
}
}
Discussion