Unity 最適化 メモ3

メモしたのを書きなぐります
・MaterialPropertyBlock
MaterialPropertyBlockとは、C#のスクリプトからシェーダー側の値を設定できる機能である。
これを使用することで動的にシェーダーの値を変えられるのはもちろんであるが、同じようなマテリアルを複製せずにいいのでドローコールの節約にもなる。
例えば以下のように色だけ変えたオブジェクト作成したい場合、マテリアルを複製し色だけ変えてしまうと、その分ドローコールも増えるし色の数だけ色を変えないといけない。
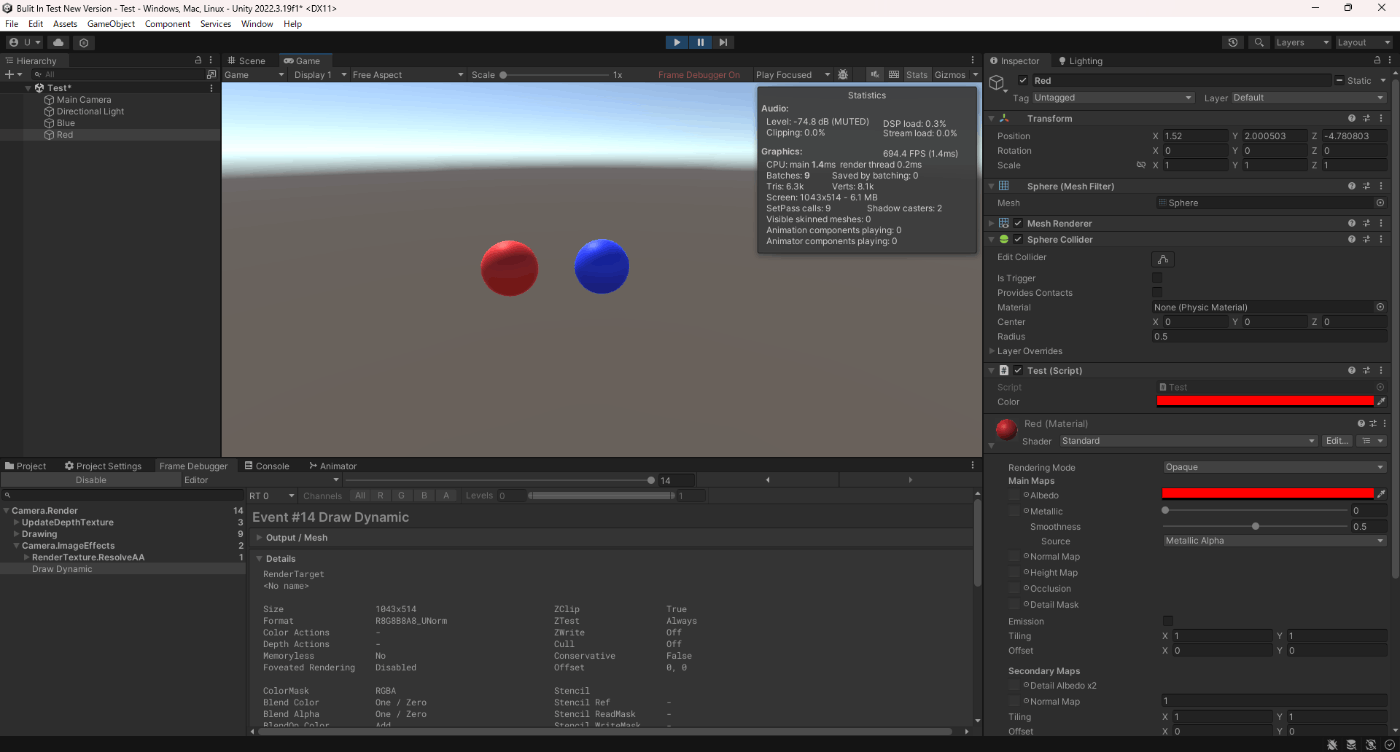
そこでMaterialPropertyBlockを使用すると、これらを解決できる。
C#のソースコードである。
using UnityEngine;
public class Test : MonoBehaviour
{
[SerializeField]
private Color _color;
private MeshRenderer _renderer;
private MaterialPropertyBlock _materialPropertyBlock;
private void Start()
{
_renderer = GetComponent<MeshRenderer>();
_materialPropertyBlock = new MaterialPropertyBlock();
}
private void Update()
{
_renderer.GetPropertyBlock(_materialPropertyBlock);
// MaterialPropertyBlockに対して色をセットする
_materialPropertyBlock.SetColor("_Color", _color);
_renderer.SetPropertyBlock(_materialPropertyBlock);
}
}
シェーダーである。
Shader "Example"
{
Properties{
}
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
float4 _Color;
float4 vert(float4 vertex : POSITION) : SV_POSITION
{
return UnityObjectToClipPos(vertex);
}
fixed4 frag() : SV_Target
{
return _Color;
}
ENDCG
}
}
}
実験した結果である。
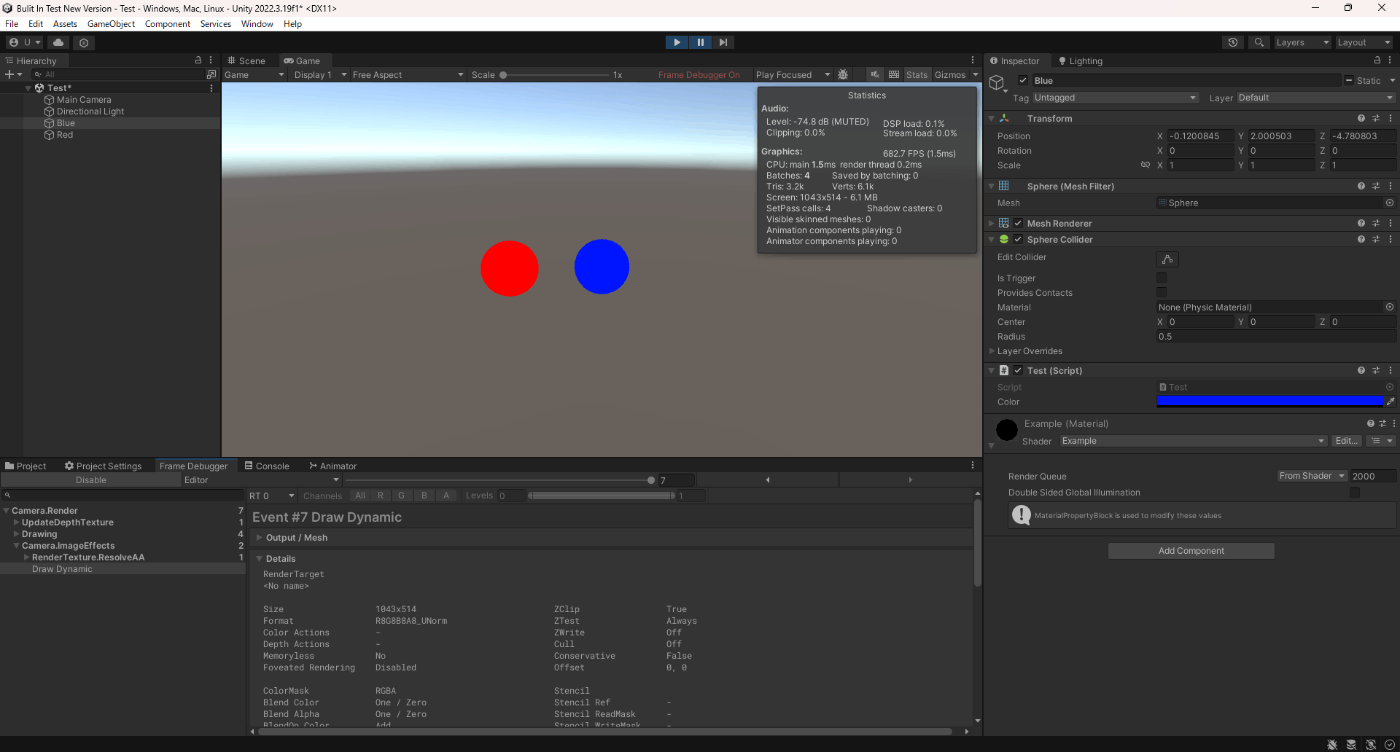
ドローコールは減っているし、同じマテリアルでC#スクリプトの設定で色を変更できているのが分かる。
参照サイト
・ドローコールの最適化
画面にジオメトリを描画するために、Unity はグラフィックス API に対してドローコール (draw call、描画呼び出し) を送信します。ドローコールはグラフィックス API に対して、何をどのように描画するかを指示します。各ドローコールには、テクスチャ、シェーダー、バッファに関する情報など、グラフィックス API が画面に描画するために必要なすべての情報が含まれています。ドローコールはリソースを消費しますが、多くの場合、ドローコール自体よりも、ドローコールの準備の方に多くリソースが消費されます。
ドローコールに備えるため、CPU はリソースを準備し、GPU の内部設定を変更します。これらの設定はまとめてレンダー状態と呼ばれます。レンダー状態の変更 (例えば、別のマテリアルに切り替えるなど) は、グラフィックス API が実行する中で最もリソースを消費する操作です。
レンダー状態の変更はリソースを消費するためそれらを最適化することが重要です。レンダー状態の変更を最適化する主な方法は、レンダー状態の変更の回数を減らすことです。これには 2 つの方法があります。
①ドローコールの総数を減らします。ドローコールの数を減らすと、それらの間のレンダー状態の変化の数も減ります。
②レンダー状態の変更回数を減らす方法でドローコールを整理します。グラフィックス API が同じレンダー状態を使用して複数のドローコールを実行する場合、ドローコールをグループ化し、レンダー状態の変更をそれほど多く実行する必要がなくなります。
ドローコールとレンダー状態の変更を最適化することは、アプリケーションにとって多くの利点があります。主にフレーム時間が改善されますが、それ以外にも以下のような利点があります。
①アプリケーションが必要とする電力量を削減します。電池駆動のデバイスでは、電池の消耗を抑えることができます。また、アプリケーションの実行時にデバイスが発する熱も減らすことができます。
②アプリケーションの今後の開発における保守性を向上させることができます。ドローコールやレンダー状態の変更を早期に最適化し、最適化されたレベルで維持することで、パフォーマンスの大きなオーバーヘッドを発生させることなく、シーンにゲームオブジェクトを追加できるようになります。
Unity では、ドローコールとレンダー状態の変更を最適化して減らすために、いくつかの技術を提供している。
それがGPU インスタンシング、静的バッチ処理、動的バッチ処理、手動でメッシュを結合、SRP バッチャーである。
今回はこれらをを紹介していく。
■GPU インスタンシング
同じマテリアルで、同じメッシュを描画する際にそれらを一回のドローコールとする技術である。
樹木や茂みなど、シーンに何度も現れるジオメトリを描画するのに便利です。
実際にやってみる。
①シンプルなパターン
ソースコードはこちら。
Shader "Test"
{
Properties
{
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
//必要な記述
#pragma multi_compile_instancing
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(v);
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
return float4(1, 1, 1, 1);
}
ENDHLSL
}
}
}
GPU インスタンシング無効

GPU インスタンシング有効
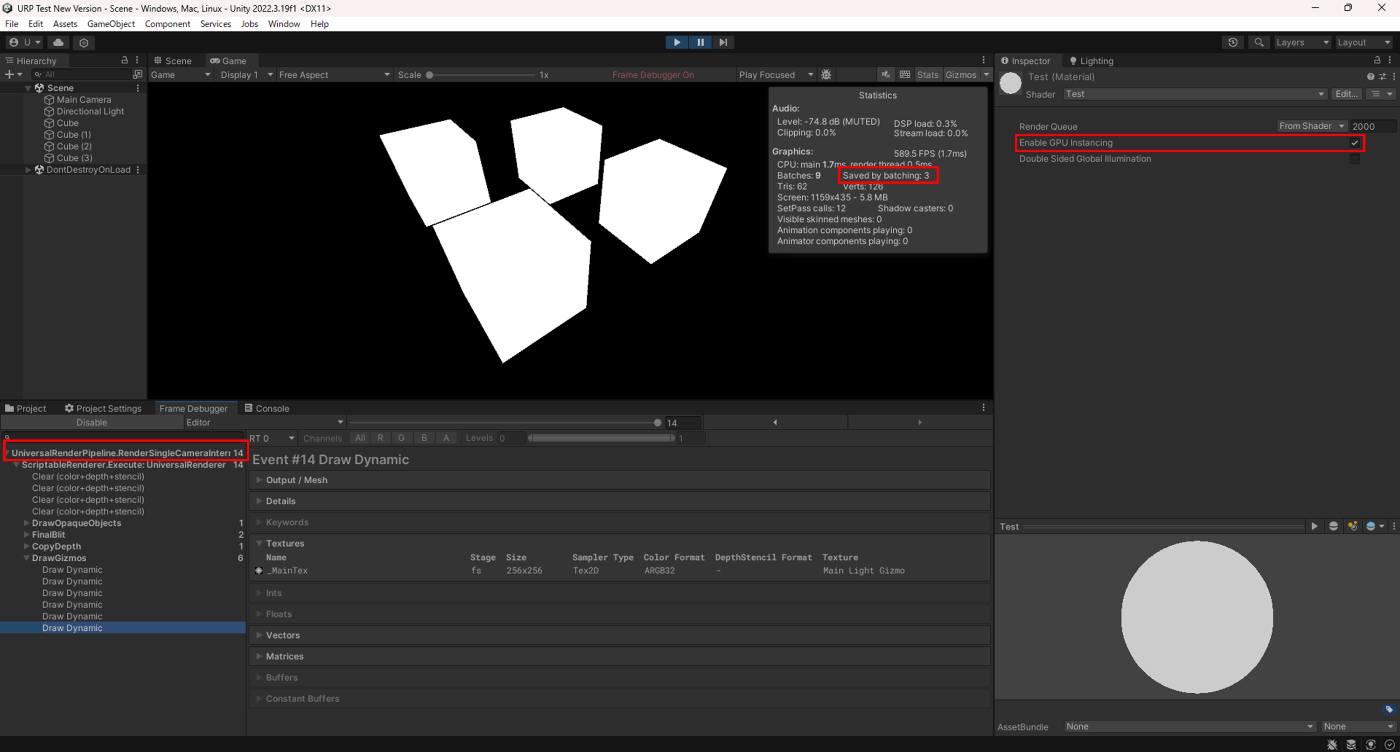
確かにドローコールが少なくなっているのが分かる。
一応、違うメッシュでGPUインスタンシングできないかやってみる

GPU インスタンシングが適用されていないのが分かる。
②インスタンスIDを頂点シェーダーで使用するパターン
インスタンスIDとは、各オブジェクトに割り当てられるユニークな値である。
0から始まり、オブジェクトの数に応じて+1でカウントアップされていく。
ソースコードはこちら。
Shader "Test2"
{
Properties
{
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
//必要な記述
#pragma multi_compile_instancing
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : POSITION;
};
struct v2f
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(v);
uint id;
//GPUインスタンシングが有効の場合
#ifdef UNITY_INSTANCING_ENABLED
//各オブジェクトごとのインスタンスID取得
id = UNITY_GET_INSTANCE_ID(v);
#else
id = 0;
#endif
//インスタンスIDによってランダムで頂点を変更
v.vertex.xyz *= frac(sin(float3(dot(id+1, float3(127.1, 311.7, 542.3)),
dot(id+1, float3(269.5, 183.3, 461.7)),
dot(id+1, float3(732.1, 845.3, 231.7))))
* 43758.5453123);;
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
return 1;
}
ENDHLSL
}
}
}
インスタンスIDによってランダムで頂点を変更し、見た目が変わっていることが分かる。

③インスタンスIDをフラグメントシェーダーで使用するパターン
ソースコードはこちら。
Shader "Test1"
{
Properties
{
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
//必要な記述
#pragma multi_compile_instancing
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : POSITION;
};
struct v2f
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(v);
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
//必要な記述
UNITY_TRANSFER_INSTANCE_ID(v, o);
return o;
}
float4 frag(v2f i) : SV_Target
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(i);
uint id;
//GPUインスタンシングが有効の場合
#ifdef UNITY_INSTANCING_ENABLED
//各オブジェクトごとのインスタンスID取得
id = UNITY_GET_INSTANCE_ID(i);
#else
id = 0;
#endif
if (id == 0) {
return float4(1, 0, 0, 1);
}
if (id == 1) {
return float4(0, 1, 0, 1);
}
if (id == 2) {
return float4(0, 0, 1, 1);
}
if (id == 3) {
return float4(1, 1, 1, 1);
}
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
インスタンスIDによって色が変わっていることが分かる。

④C#スクリプトから、インスタンスIDを動的に変える
C#のソースはこちら。
using UnityEngine;
public class Test : MonoBehaviour
{
public GameObject oj;
private Renderer gameObjectRenderer;
MaterialPropertyBlock propertyBlock;
void Start()
{
propertyBlock = new MaterialPropertyBlock();
gameObjectRenderer = oj.GetComponent<Renderer>();
}
void Update()
{
if (Input.GetKey(KeyCode.A)) {
propertyBlock.SetInt("_Index", 0);
gameObjectRenderer.SetPropertyBlock(propertyBlock);
}
if (Input.GetKey(KeyCode.B))
{
propertyBlock.SetInt("_Index", 1);
gameObjectRenderer.SetPropertyBlock(propertyBlock);
}
if (Input.GetKey(KeyCode.C))
{
propertyBlock.SetInt("_Index", 2);
gameObjectRenderer.SetPropertyBlock(propertyBlock);
}
if (Input.GetKey(KeyCode.D))
{
propertyBlock.SetInt("_Index", 3);
gameObjectRenderer.SetPropertyBlock(propertyBlock);
}
}
}
シェーダーのソースはこちら。
Shader "Test3"
{
Properties
{
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
//必要な記述
#pragma multi_compile_instancing
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : POSITION;
};
struct v2f
{
//必要な記述
UNITY_VERTEX_INPUT_INSTANCE_ID
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(v);
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
//必要な記述
UNITY_TRANSFER_INSTANCE_ID(v, o);
return o;
}
//必要な記述
UNITY_INSTANCING_BUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(int, _Index)
UNITY_INSTANCING_BUFFER_END(Props)
float4 frag(v2f i) : SV_Target
{
//必要な記述
UNITY_SETUP_INSTANCE_ID(i);
//C#からの"_Index"の値を受け取る
int index = UNITY_ACCESS_INSTANCED_PROP(Props, _Index);
if (index == 0) {
return float4(1, 0, 0, 1);
}
if (index == 1) {
return float4(0, 1, 0, 1);
}
if (index == 2) {
return float4(0, 0, 1, 1);
}
if (index == 3) {
return float4(1, 1, 1, 1);
}
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
動的にインスタンスIDを変更した結果、色が変わっているのが分かる。
⑤対応プラットフォームとレンダリングパイプライン
WebGL 1.0 を除くすべてのプラットフォームで利用可能です。
また、全てのレンダリングパイプラインで利用可能だが、URPとHDRPの場合はSRPバッチャーと静的バッチ処理が利用していた場合、GPUインスタンシングは適用されない。このあたりの優先順位はのちほど後述する。
なお、プロジェクトが SRP バッチャーを使用していて、ゲームオブジェクトに GPU インスタンスを使用したい場合は以下の2つがある。
Graphics.RenderMeshInstancedを使用するか、SRP バッチャーの互換性を手動で削除する。
SRP バッチャーの互換性を手動で削除についてはのちほど後述する。
⑥ライティング
GPUインスタンシングは、ライトマップ、ライトプローブ、LLPVなどにも対応している。
ライトマップで試してみた。
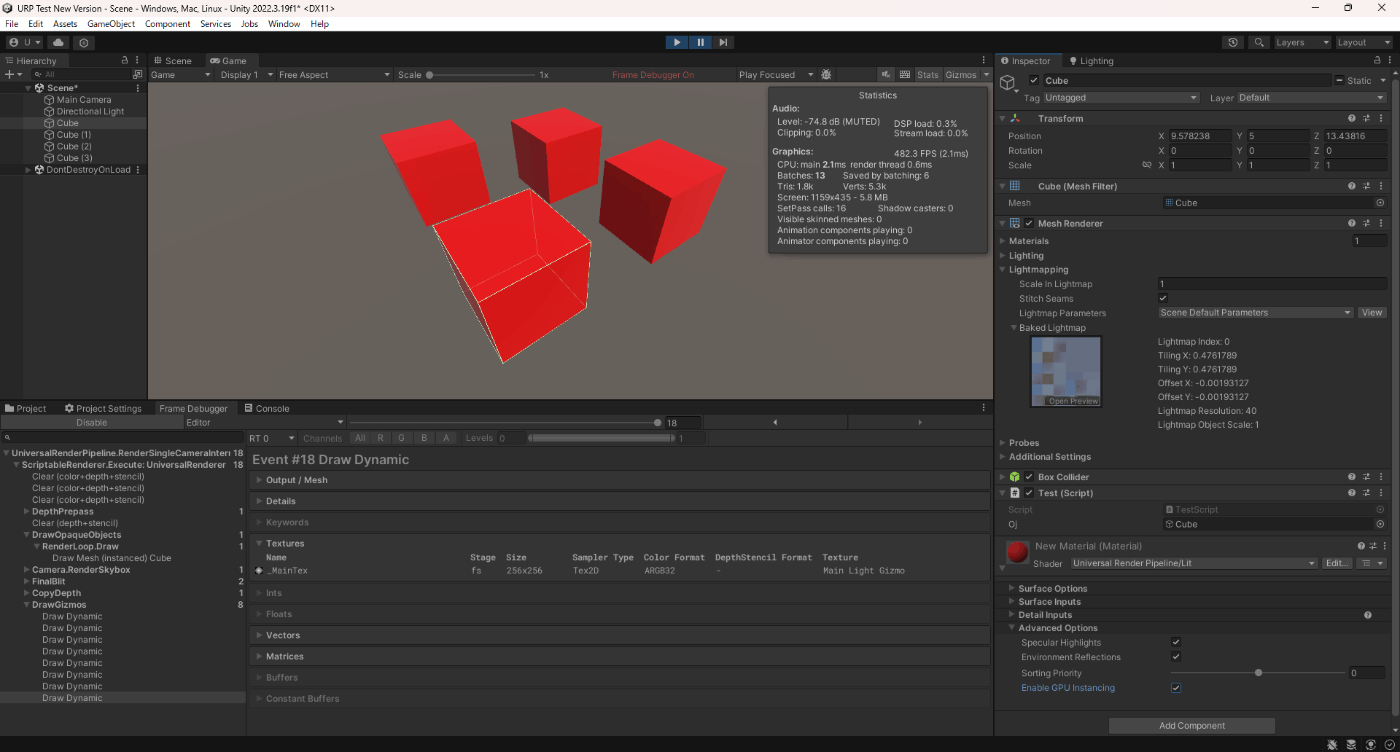
実際にGPUインスタンシング出来ていることが分かる。
⑥頂点数が少ないメッシュは、GPU インスタンシングを使用する場合
頂点数が少ないメッシュは、GPU インスタンシングを使用は、逆にパフォーマンスに影響を与える可能性がある。
公式ドキュメントだとGPUの種類によるが、原則として、256 より少ない頂点のメッシュには GPU インスタンシングを使用しないことをおすすめされている。
頂点数の少ないメッシュを何度も描画する場合は、すべてのメッシュの情報を含むバッファを 1 つ作成し、それを使ってメッシュを描画するのが効率的。
■静的バッチ処理
静的バッチ処理とは、同じマテリアルの静的オブジェクト同士(ランタイムでTransformが変えても変わらない)のメッシュをあらかじめ結合しておきドローコールを最適化する技術のことである。
やり方としては簡単で、PlayerのStatic Batchingを有効にし、静的バッチしたいオブジェクトのBatching Staticを有効にすることである。
実際にやってみる。
静的バッチ処理なし

静的バッチ処理あり
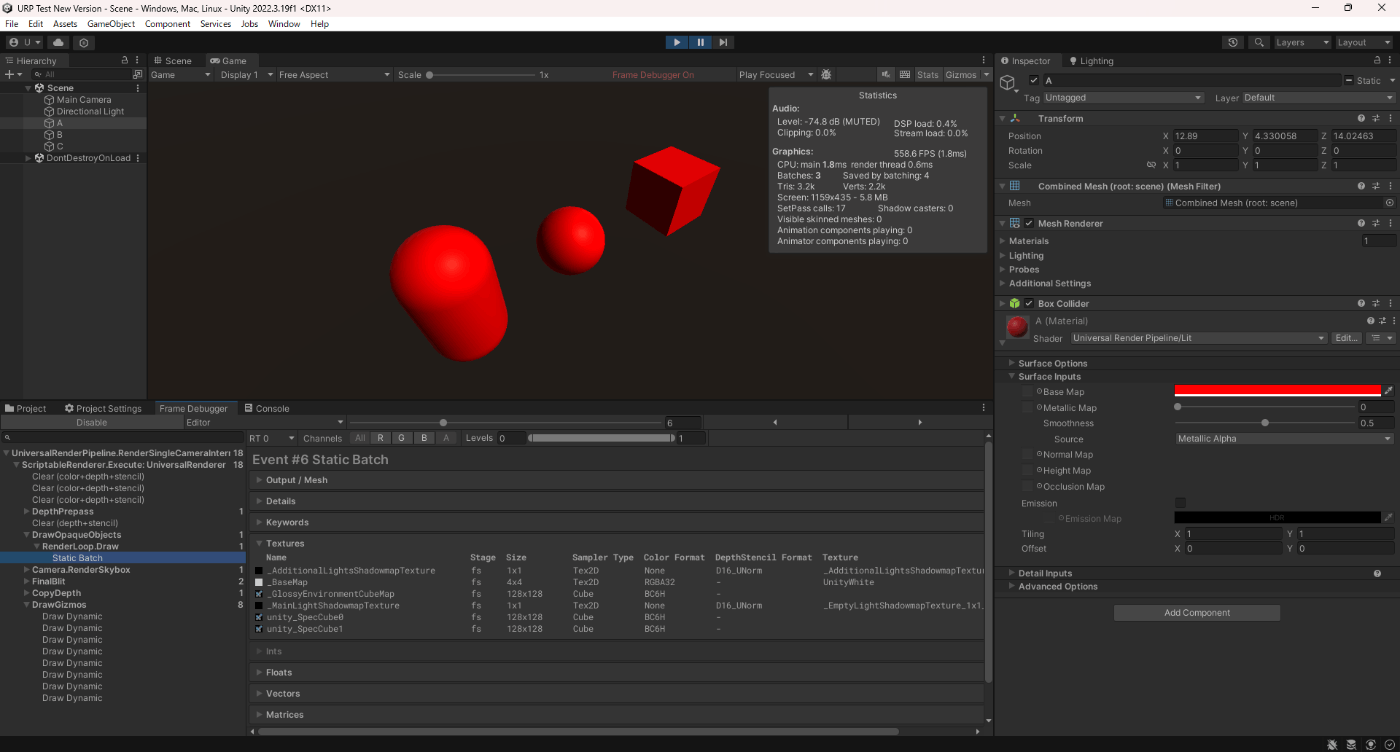
確かに静的バッチ処理ありだと、ドローコールが少なくなっているのが分かる。
なお、Transformの値を変更しても変化しない。
①レンダーパイプラインの互換性
すべてのレンダーパイプラインで利用可能。
②対応しているコンポーネント
メッシュレンダラー、トレイルレンダラー、ラインレンダラー、パーティクルシステム、スプライトレンダラー は静的バッチ処理に対応
③静的バッチ処理になる条件
公式ドキュメントから抜粋。
・同じマテリアルであること
・ゲームオブジェクトがアクティブである。
・ゲームオブジェクトは Mesh Filter コンポーネントを持ち、そのコンポーネントは有効である。
・Mesh Filter コンポーネントには、Mesh への参照がある。
・メッシュの頂点数が 0 より大きい。
・そのメッシュがまだ他のメッシュと結合されていない。
・ゲームオブジェクトは Mesh Renderer コンポーネントを持ち、そのコンポーネントは有効である。
・Mesh Renderer コンポーネントは、DisableBatching タグが true に設定されているシェーダーを持つ マテリアルを使用しない。
・まとめてバッチ処理するメッシュは、同じ頂点属性を使用する。例えば、Unity は、互いに頂点位置、頂点法線、1 つの UV を使用するメッシュどおしはバッチ処理できますが、頂点位置、頂点法線、UV0、UV1、頂点正接を使用するメッシュとは一括処理できません。
・ランタイムの静的バッチ処理を使用するには、メッシュの読み取り/書き込みも有効に設定する必要があります。
・1 つの静的バッチに加えることができる頂点の数には制限があります。各静的バッチは最大 64000 個の頂点を含むことができます。それ以上の場合は、別のバッチを作成します。
④ランタイムの静的バッチ処理
StaticBatchingUtilityクラスを使用して可能である。
実際にやってみる。
以下が動的生成するソースコード
using UnityEngine;
public class Test : MonoBehaviour
{
public Material material;
public bool combime;
void Start()
{
GameObject quad = GameObject.CreatePrimitive(PrimitiveType.Quad);
quad.transform.position = new Vector3(1.25f, 0, 0);
quad.GetComponent<Renderer>().material = material;
quad.isStatic = true;
if (!combime)
{
return;
}
GameObject quadRoot = GameObject.CreatePrimitive(PrimitiveType.Quad);
quadRoot.transform.position = new Vector3(1.25f, 1.25f, 0);
quadRoot.GetComponent<Renderer>().material = material;
quadRoot.name = quadRoot.name + "(Root)";
StaticBatchingUtility.Combine(new GameObject[] { quad, quadRoot }, quadRoot);
}
}
確かに動的生成しても静的バッチされていることが分かる。
また、動的生成したrootオブジェクトのTransformを変更すると反映されて、カメラから見えない位置まで移動するとrootじゃないオブジェクトは初期値に戻っていることが分かる。
ビルド時の静的バッチ処理とは異なり、ランタイムのバッチ処理では、Static Batching Player 設定を有効にする必要はない。
また、ビルド時の設定(Static BatchingとBatching Static・有効)と比べてランタイムに CPU 負荷がかかることに注意
⑤パフォーマンスの影響
静的バッチ処理を使用すると、結合されたジオメトリを保存するために追加の CPU メモリが必要になります。
■動的バッチ処理
動的バッチ処理とは、同じマテリアルの動的オブジェクト同士(ランタイムでTransformが変えても変わる)のメッシュをあらかじめ結合しておきドローコールを最適化する技術のことである。
古いローエンドデバイスでのパフォーマンスを最適化するために設計されました。最近の消費者向けハードウェアでは、動的バッチ処理が CPU で行う作業が、ドローコールのオーバーヘッドよりも大きくなることがあります。これはパフォーマンスに悪影響を及ぼします。
やり方としては簡単で、URPだとPipeline AssetのDynamic Batchingを有効にすれば可能。
実際にやってみる。
動的バッチ処理なし

動的バッチ処理あり
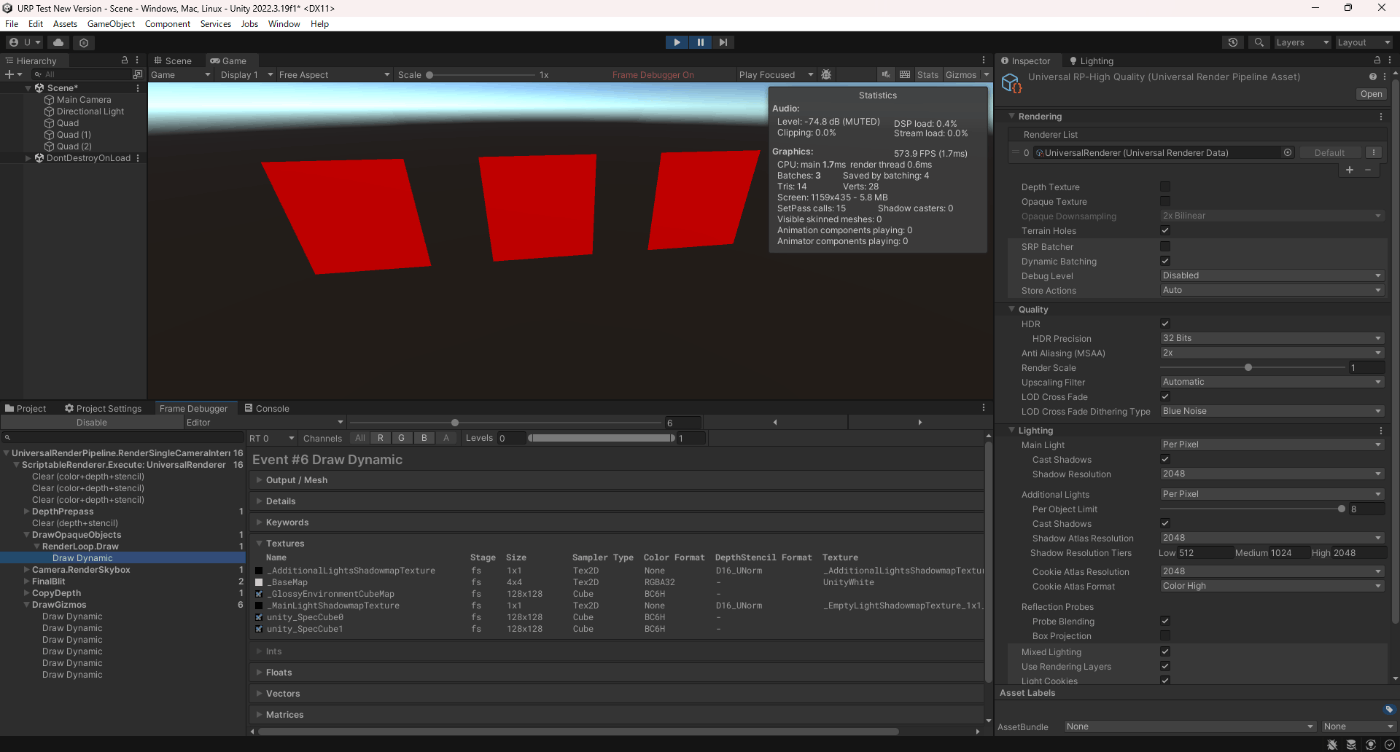
確かに静的バッチ処理ありだと、ドローコールが少なくなっているのが分かる。
なお、Transformの値を変更可能。
①レンダーパイプラインの互換性
HDRP以外利用可能。
②対応しているコンポーネント
メッシュレンダラー、トレイルレンダラー、ラインレンダラー、パーティクルシステム、スプライトレンダラー は動的バッチ処理に対応
③どのタイミングで使用するのか
メッシュの動的バッチ処理は、GPU ではなく CPU ですべての頂点をワールド空間に変換して行われます。つまり、動的バッチ処理が最適化となるのは、変換作業がドローコールを行うよりもリソースを消費しない場合のみです。
ドローコールのリソース要件は、多くの要因、主にグラフィックス API に依存します。例えば、コンソールや Apple Metal のような最新の API では、一般にドローコールのオーバーヘッドははるかに低く、多くの場合、動的バッチ処理ではパフォーマンスの向上は望めません。アプリケーションで動的バッチ処理を使用することが有益かどうかを判断するには、動的バッチ処理を使用した場合と使用しない場合で、アプリケーションを プロファイル してください。
④制限
以下のシナリオでは、Unity は動的バッチ処理を全く使えない、または限定的にしか適用できません。
公式ドキュメントから抜粋。
・Unity では、900 を超える頂点属性と 225 の頂点を含むメッシュに動的バッチ処理を適用することができません。理由は、メッシュの動的バッチ処理には、頂点ごとのオーバーヘッドがあるためです。例えば、シェーダーが頂点位置、頂点法線、1 つの UV を使用する場合、Unity は最大 225 頂点までバッチ処理できます。しかし、シェーダーが頂点位置、頂点法線、UV0、UV1、および頂点接線を使用する場合、Unity は 180 頂点しかバッチ処理できません。
・ゲームオブジェクトがさまざまなマテリアルのインスタンスを使用すると、たとえ基本的に同じものであっても、まとめてバッチ処理できません。シャドウキャスターのレンダリングは唯一の例外です。
・ライトマップをもつゲームオブジェクトには追加のレンダラーパラメーターが含まれます。つまり、ライトマップされたゲームオブジェクトをバッチ処理したい場合は、同じライトマップの位置を示す必要があります。
・Unity は、マルチパスシェーダーを使用するゲームオブジェクトに動的バッチ処理を完全に適用することはできません。
ほぼすべての Unity シェーダーは、フォワードレンダリングで複数のライトをサポートします。これを実現するために、シェーダーは、各ライトに対して追加のレンダーパスを処理します。Unity は最初のレンダーパスのみをバッチ処理します。追加のピクセル単位のライトのドローコールをバッチ処理することはできません。
⑤パフォーマンス
動的バッチは、静的バッチと比べて実行時にバッチング対象を判定し、それから必要な情報を処理しますから、その分だけCPUに負荷がかかる。
■静的バッチ処理と動的バッチ処理の補足
①Renderer.materialから値を変更すると、異なるインスタンスが生成されるのでバッチの対象にならない。
②MaterialPropertyBlock を使っても、異なる値が与えられるときは、バッチの対象にならない。
③透過を含むバッチング
バッチングは描画順を細かく制御することができません。
透過を含むとき、シーンにある他のオブジェクトとの前後関係が破綻しないように一層気をつける必要があります。
パーティクルなどの前後関係が多少は破綻しても問題にならないものを除けば、透過を含むオブジェクトの大量なバッチングは、難しいことが多い。
④動的バッチか静的バッチどちらを使用するべきか
動的バッチングは、限定的な条件でのみ使えるという認識でよさそうです。動的に処理するためのオーバーヘッドが大きく、頂点数は最大300までです。
また頂点に与えられる値(頂点属性)は最大900までで、たとえば1つの頂点に座標、法線、UV0、UV1の4つが与えられるとき、900 / 4 = 225頂点までのメッシュしかバッチングの対象になりません。
したがって、動的バッチングはどちらかというとパーティクルやラインレンダラーなどの、エフェクトに寄った限定的な用途でのみ効果的と言えます。
■手動でメッシュを結合
手動で 複数のメッシュを 1 つに結合することができます。Unity は、メッシュごとに 1 回のドローコールを送信する代わりに、結合したメッシュを 1 回のドローコールでレンダリングします。
そもそもメッシュを結合とは、下記画像のCullingオブジェクトのように1つのオブジェクトであるがモデルが複数あるようなオブジェクトのことである。
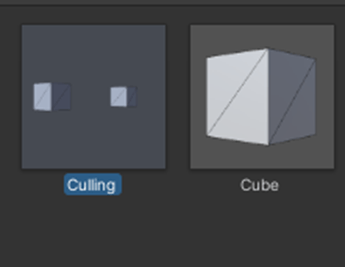
実際にやってみる。
結合していないメッシュ
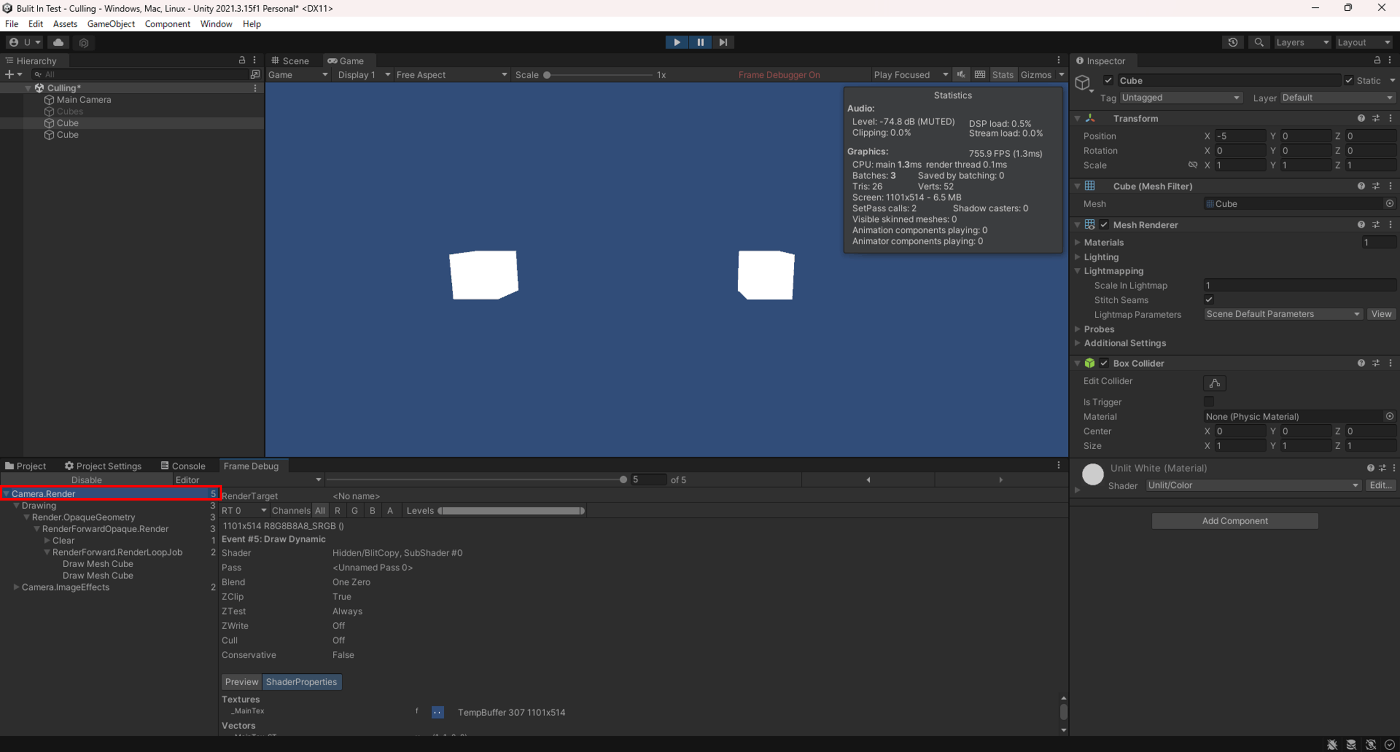
結合したメッシュ
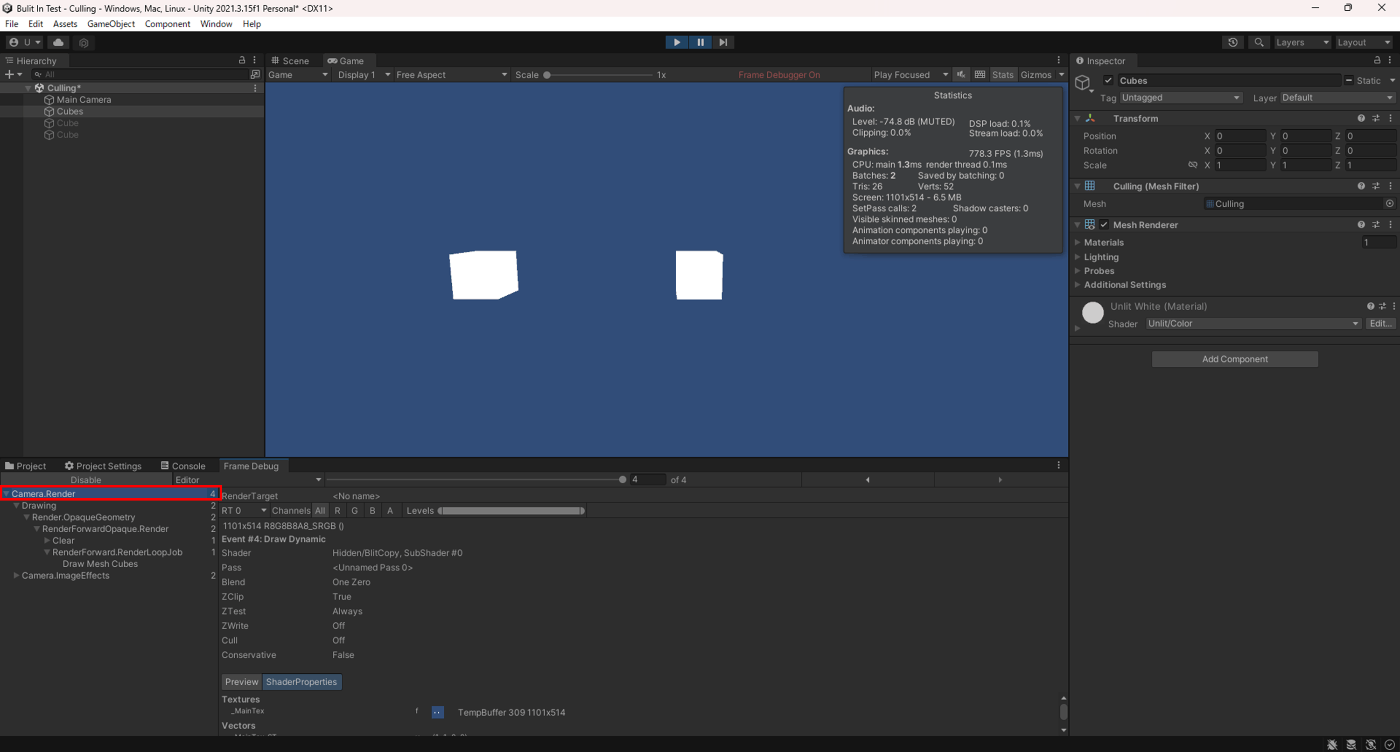
結合したメッシュの方がドローコールが少ないことが分かる。
①静的バッチとメッシュ結合の使い分け
静的バッチの場合は、カメラに映らないオブジェクトの不要な情報もGPUに送らない。
静的バッチ
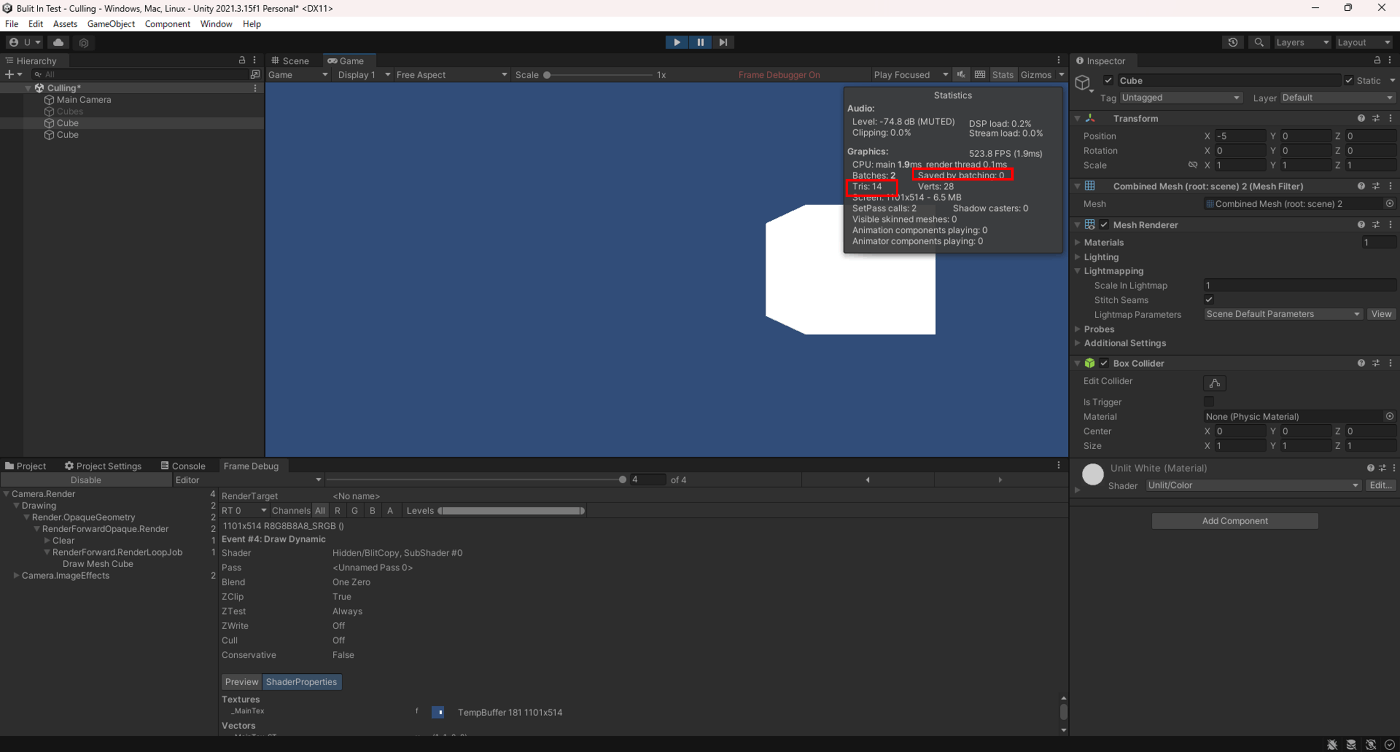
Cube1個のTrisは12で、Trisは14なのでカメラに写っていないCubeのTrisはGPUに送らていないことが分かる。
一方で、
メッシュ結合
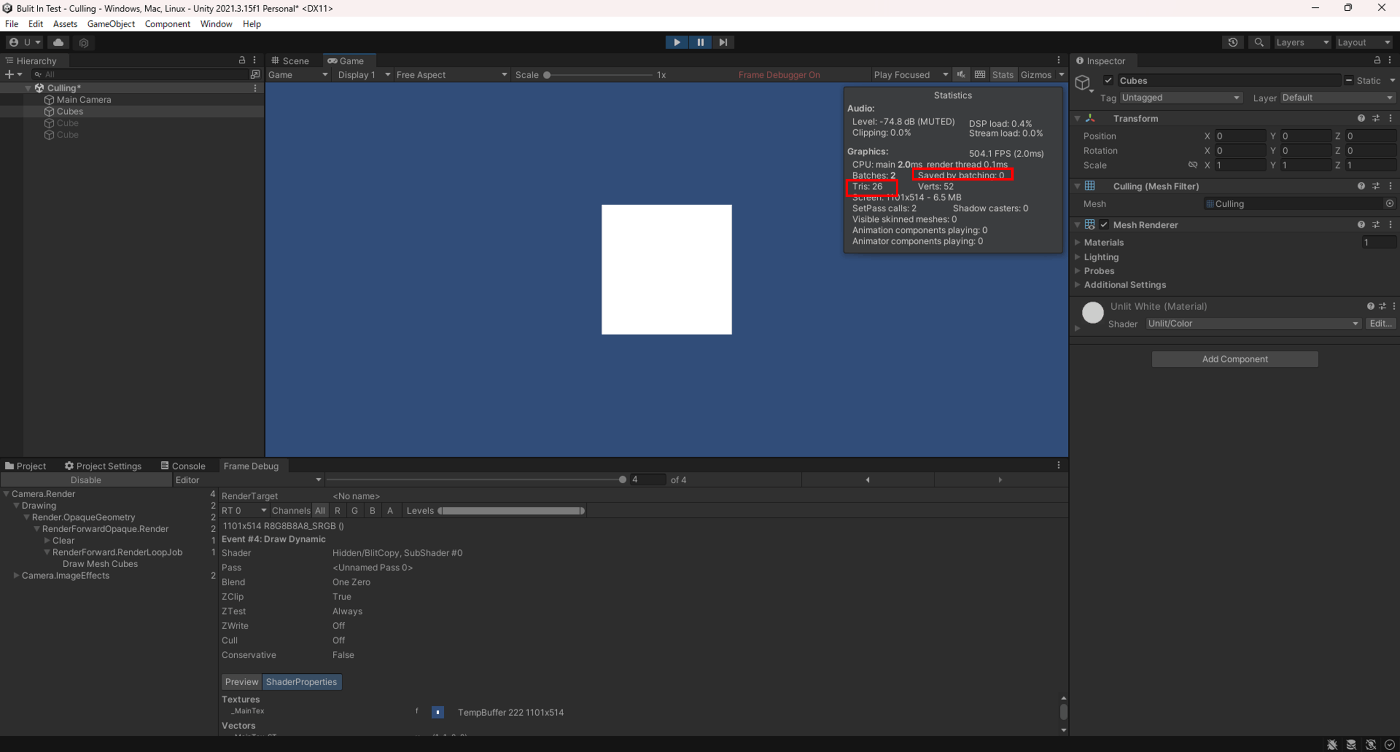
Trisは26なのでカメラに写っていないオブジェクトもGPUに送らていることが分かる。
なので、
大量のメッシュが結合された状態で、その内の少しだけがカメラに収まるとき、不要な情報が多くレンダリングパイプラインに渡されてしまうので、結合されたオブジェクトを使用する際はそこをパフォーマンス面で注意する必要がある。
また、メッシュ結合を使用する際は、メッシュのLODを使用するときもパフォーマンス面で注意が必要である。
なぜなら、結合されているメッシュ同士が離れている場合、遠くあるオブジェクトを高ポリゴンで描画するのは、見た目がそこまで気にしない割に負荷がかかるため。
なので、基本的にはもしメッシュをあらかじめ結合するなら、同時にカメラに収まる可能性が高そうなメッシュを選ぶべきです。それ以外は静的バッチングを検討したほうが良い。
ただ、静的バッチは、メッシュ結合よりもメモリ容量が大きくなることも注意。
静的バッチ
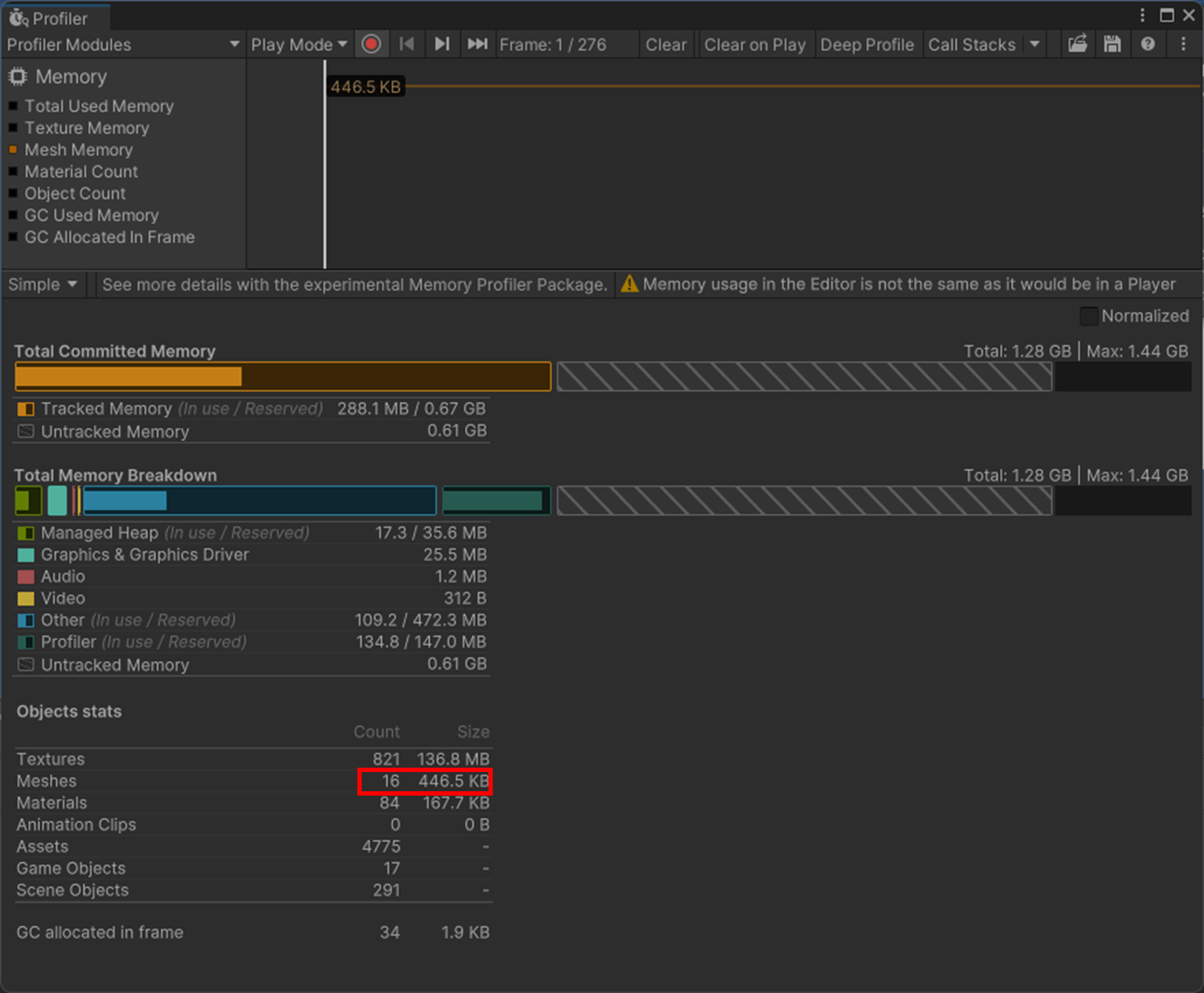
メッシュ結合
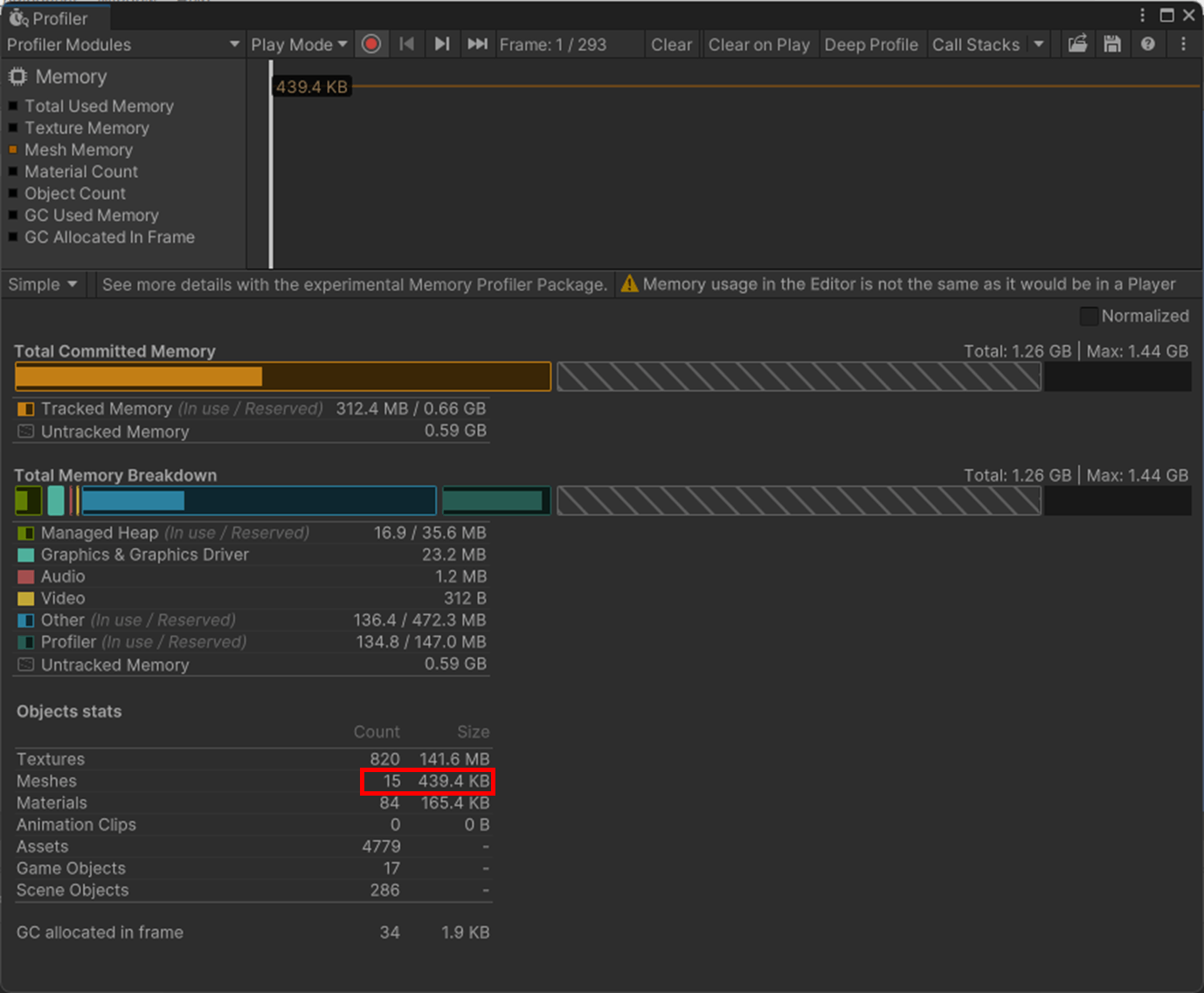
静的バッチのほうが、メッシュのメモリ容量が多いことが分かる。
なのでメモリ容量がボトルネックの場合、これを考慮する必要がある。
②メッシュを結合する方法
アセット生成ツールで、メッシュのオーサリング中に行うか、Unity で Mesh.CombineMeshes を使用する。
■SRP Batcher
SRP Batcherとは、DrawCallを減らすのではなく(DrawCallは同じ)、SetPassCallを減らす技術である。
静的バッチ・動的バッチなどはDrawCall自体を減らす目的の技術であるが、SRP BatcherはSetPassCallを減らすのが目的である。
実際にところ、DrawCallはリソースを消費しますが、多くの場合、DrawCall自体よりも、DrawCalの準備(SetPassCall)の方に多くリソースが消費されます。
なので、このDrawCallの準備(SetPassCall)を最適化を図ることでCPUのパフォーマンスを上げようというのがこのSRP Batcherの目的である。
実現方法としては、Pipeline AssetのSRP Batcherを有効にすれば可能である。
では実際にやってみる。
三つ別々のマテリアル(Lit、SimpleLit、Complex Lit)を用意し、それを色ごとのオブジェクトにアタッチして実験してみる。(色ごとに複製も行う)
まずは動的バッチのパターンを見てみる。
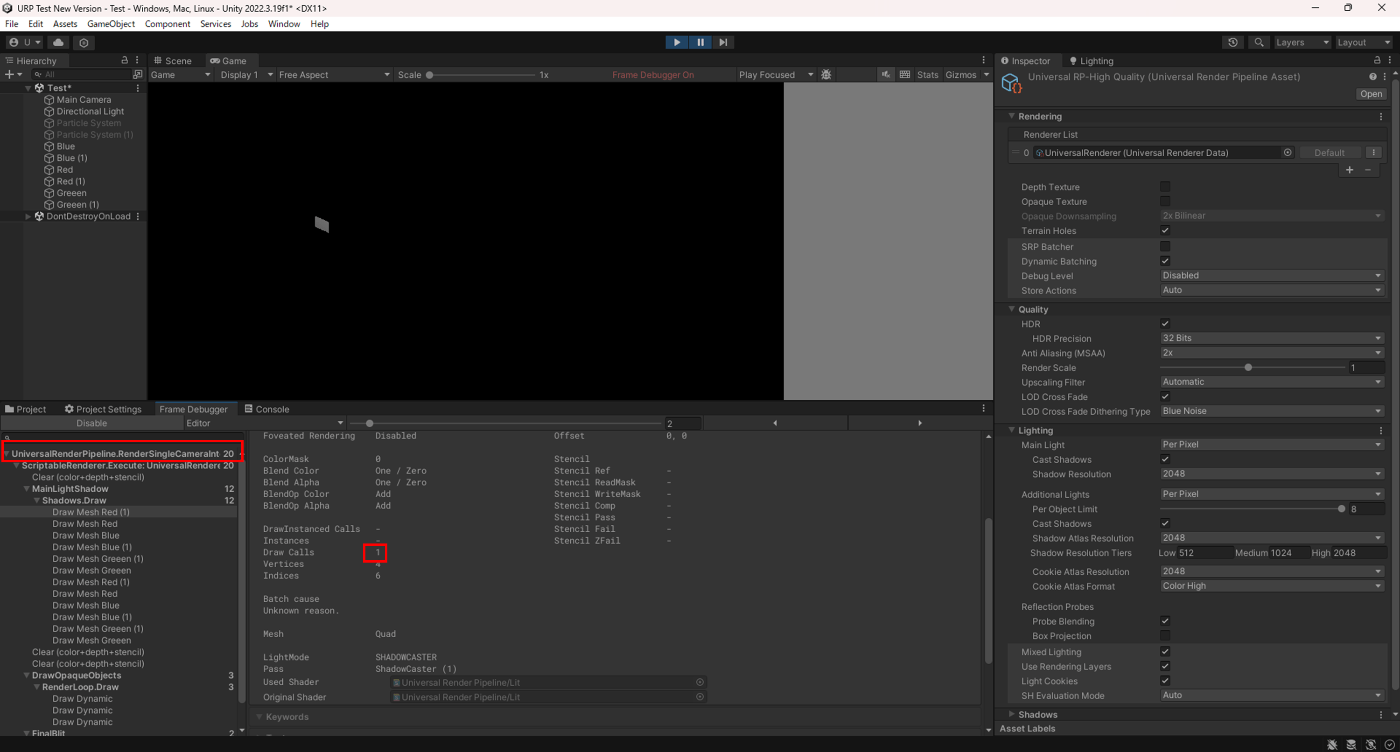
SetPassCallは20で、SetPassCallごとに1DrawCallが実行されているのが分かる。
では次はSRP Batcherを見てみる。
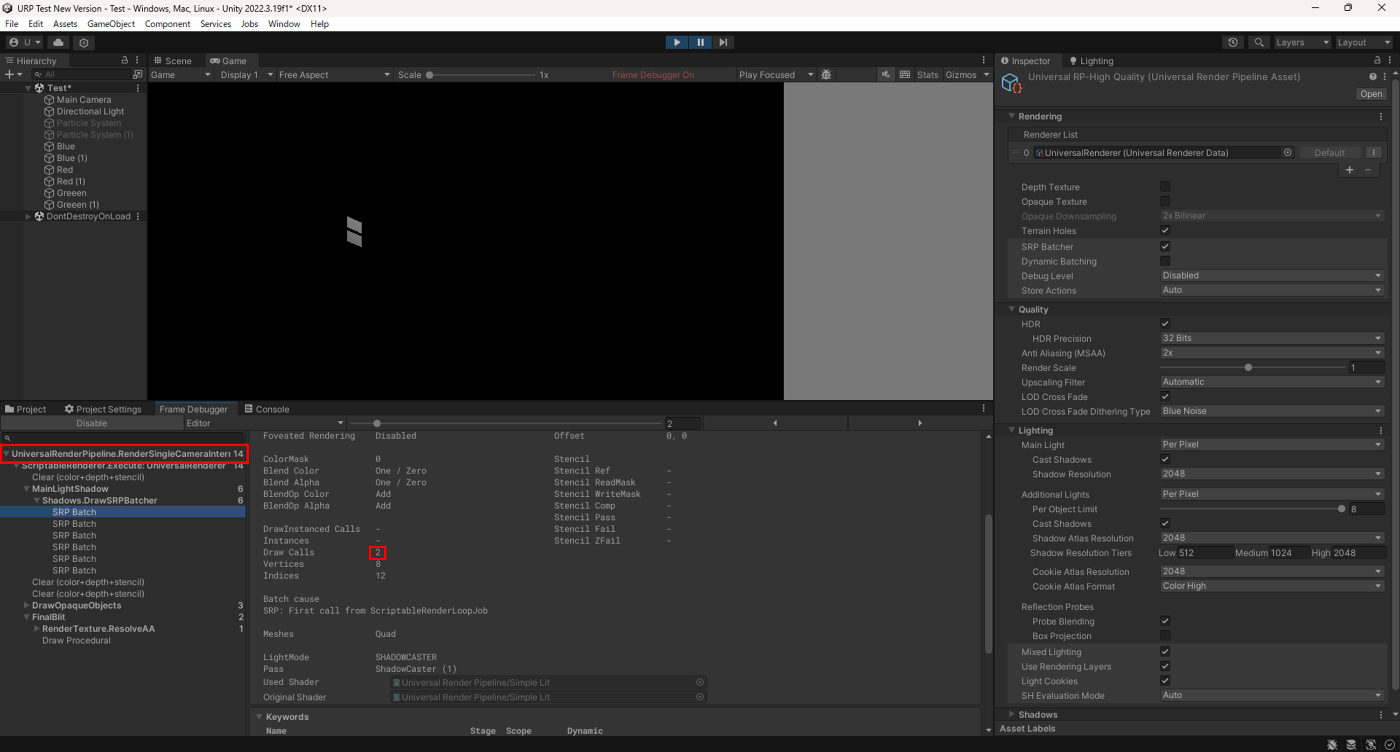
SetPassCallは14で、SetPassCallごとに2DrawCallが実行されているのが分かる。
つまり、SRP Batcherは動的バッチと比べて、SetPassCallの数は減っているがDrawCall自体は変わらないという結果となっている。
①SRP Batcherのしくみ
そもそもSRP Batcherのしくみとしては、constant buffer (cbuffer) を使用して同一Shader Variantを使用する描画をまとめて描画するというもの。
constant buffer (cbuffer) というのは、GPU上のメモリにあるシェーダから値を読み取る際必要なキャッシュメモリで、ShaderVariantが切り替わらない限りはそのキャッシュメモリの値を使用する。
これによりSetPassCallの削減を図っている。
上の「同一Shader Variantを使用する描画をまとめて描画する」というのを実際にどういうことなのか確認してみる。
ソースコードが以下である。
Shader "Test"
{
Properties
{
[KeywordEnum(Red, Green, Blue)]
_Color("Color Keyword", Float) = 0
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _COLOR_RED _COLOR_GREEN _COLOR_BLUE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
float4 _Color;
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert(appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
#ifdef _COLOR_RED
return float4(1, 0, 0, 1);
#elif _COLOR_GREEN
return float4(0, 1, 0, 1);
#elif _COLOR_BLUE
return float4(0, 0, 1, 0);
#endif
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
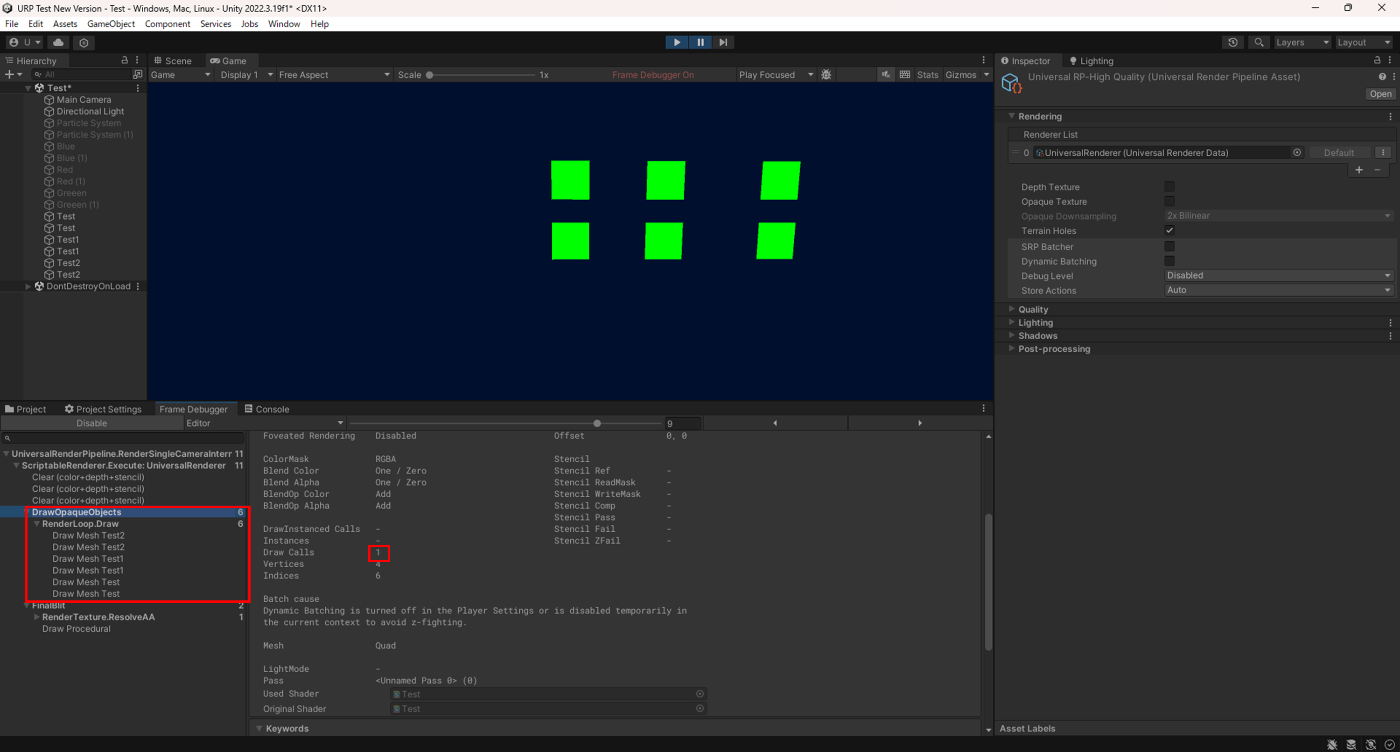
今、このシェーダを6つのQuadにアタッチ。
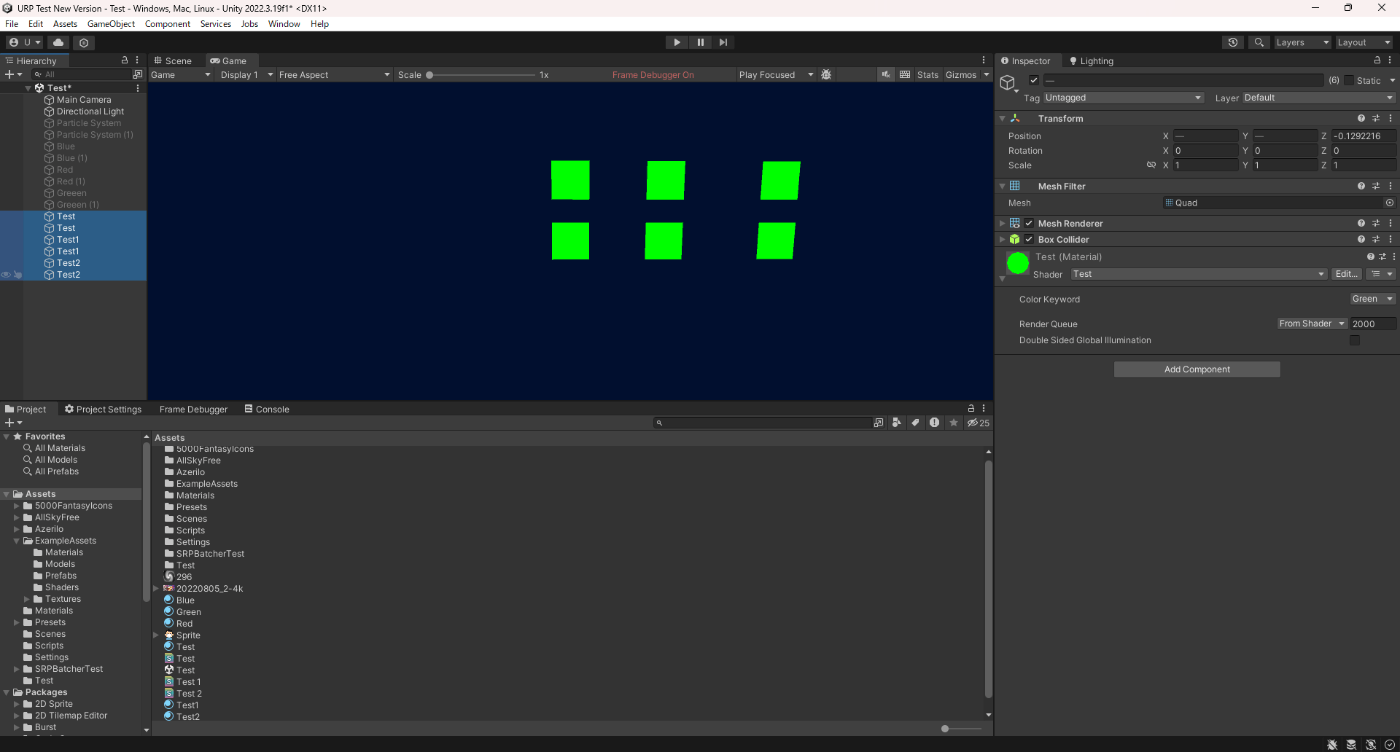
SRP Batcherオフ
SRP Batcherオン
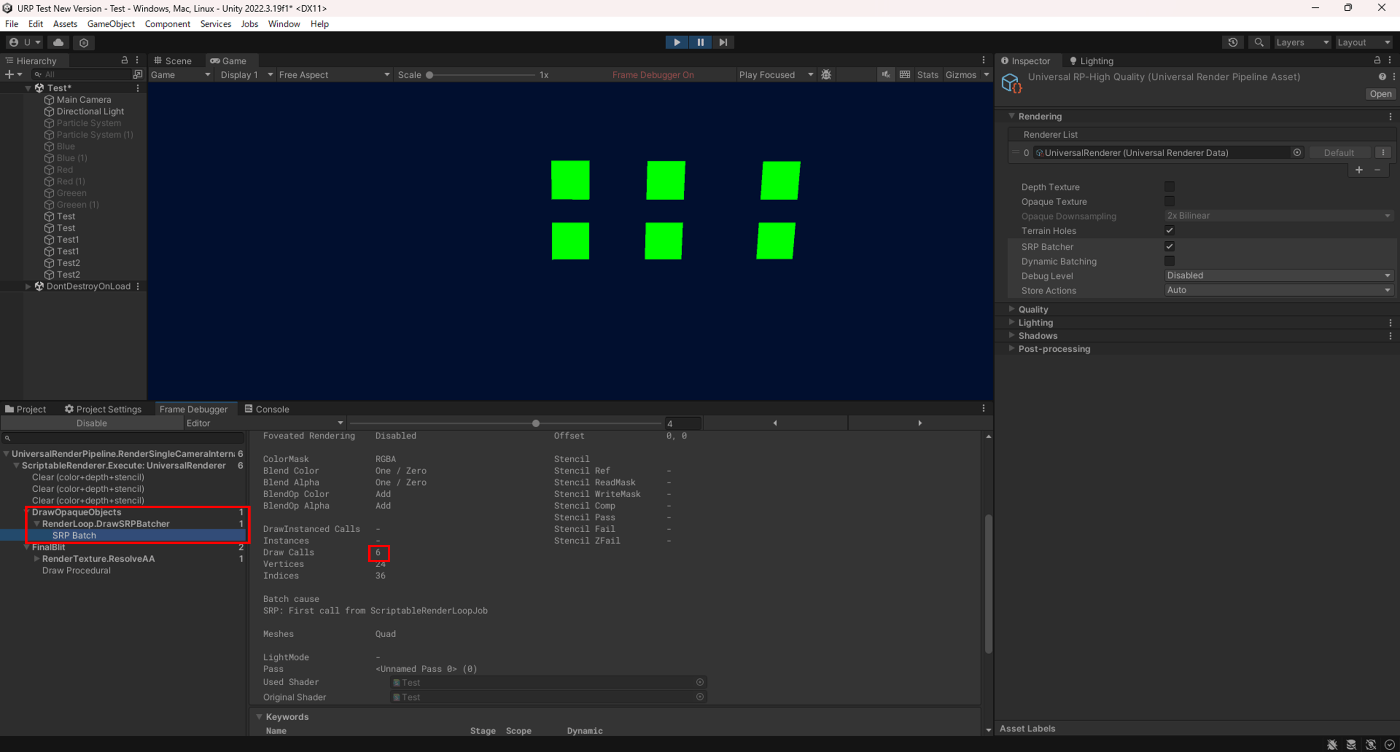
SRP Batcherオンの場合は、6つのQuadは同じShaderVariantなのでまとめて描画されていることが分かる。ただ、上でも書いたようにDrawCallの数は変わりません。削減されるのはSetPassCallだけです。
②シェーダーのプロパティをSRP Batcher対応
ソースコードは以下である。
Shader "Test"
{
Properties
{
[KeywordEnum(Red, Green, Blue)]
_Color("Color Keyword", Float) = 0
_BaseColor("Base Color", Color) = (1, 1, 1, 1)
_Integer("Integer", Int) = 1
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _COLOR_RED _COLOR_GREEN _COLOR_BLUE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
//この記述がないとSRP Batcherは適用されない
CBUFFER_START(UnityPerMaterial)
half4 _BaseColor;
int _Integer;
float _Color;
CBUFFER_END
v2f vert(appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
#ifdef _COLOR_RED
return _BaseColor;
#elif _COLOR_GREEN
return float4(0, 1, 0, 1) * _Integer;
#elif _COLOR_BLUE
return float4(0, 0, _Color, 1);
#endif
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
コメントにあるように、プロパティにCBUFFER_START(UnityPerMaterial)と CBUFFER_ENDを記載しないとSRP Batcherは適用されない。
実際にやってみる。
確かにプロパティにCBUFFER_START(UnityPerMaterial)と CBUFFER_ENDの記載がないと、SRP Batcherは適用されないことが分かる。
なお、シェーダーがSRP Batcher対応しているかは、以下でシェーダ上で確認できる
SRP Batcher対応
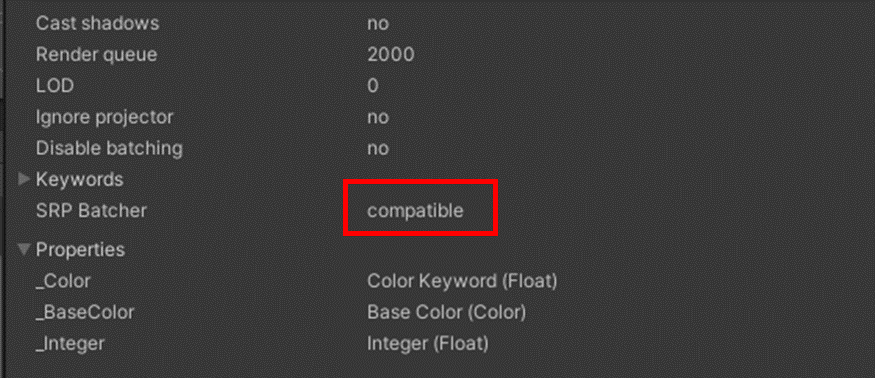
SRP Batcher対応なし
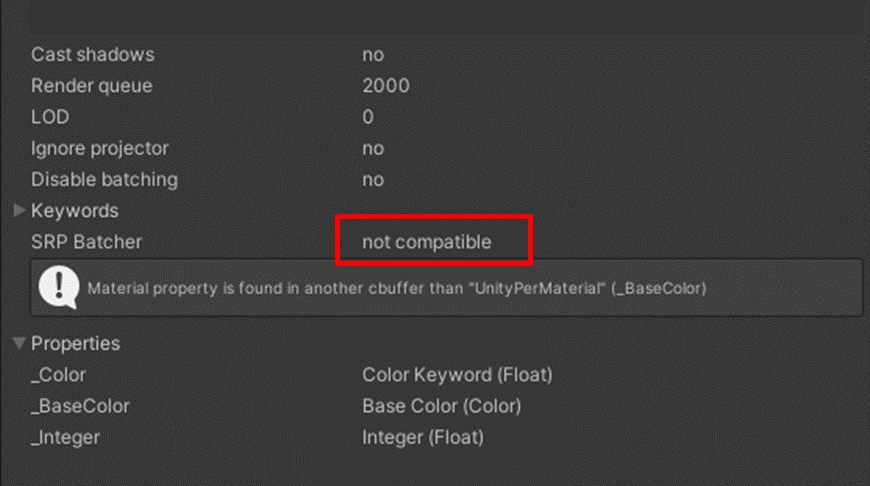
③ランタイムに SRP バッチャー を有効または無効
GraphicsSettings.useScriptableRenderPipelineBatching = true;
で可能
④レンダーパイプラインの互換性
ビルトイン以外すべて利用可能
⑤制限
公式ドキュメントを抜粋。
・ゲームオブジェクトはメッシュかスキンされたメッシュを含む必要があります。パーティクルは不可
・ゲームオブジェクトは MaterialPropertyBlocks を使ってはいけません。
・ゲームオブジェクトが使用するシェーダーは、SRP バッチャーに対応している必要があります。
実際にやってみる。
パーティクルは不可の場合
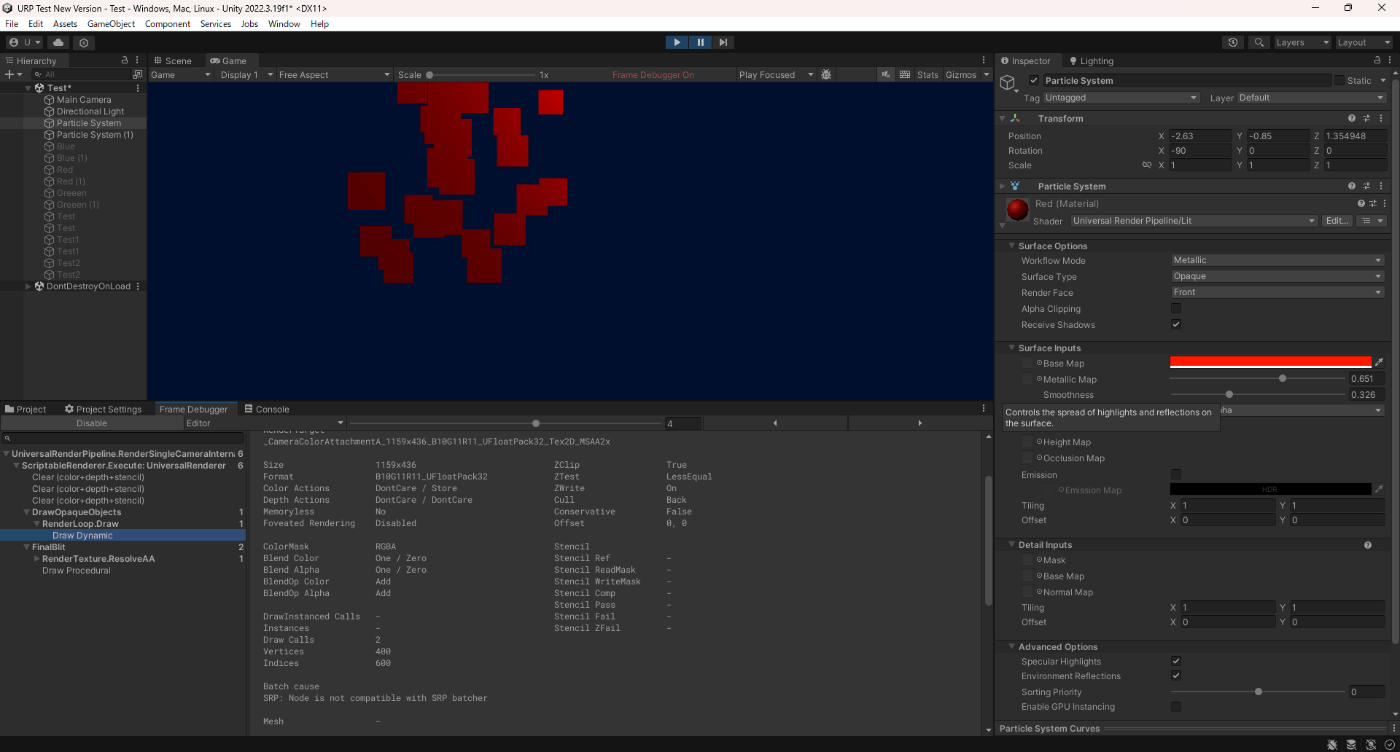
確かにSRP Batcherが適用されていない。
MaterialPropertyBlocksした場合を見てみる。
C#のソースコードはこちらである。
using UnityEngine;
public class Test : MonoBehaviour
{
[SerializeField]
private Color _color;
private MeshRenderer _renderer;
private MaterialPropertyBlock _materialPropertyBlock;
private void Start()
{
_renderer = GetComponent<MeshRenderer>();
_materialPropertyBlock = new MaterialPropertyBlock();
}
private void Update()
{
_renderer.GetPropertyBlock(_materialPropertyBlock);
// MaterialPropertyBlockに対して色をセットする
_materialPropertyBlock.SetColor("_ColorMaterialPropertyBlock", _color);
_renderer.SetPropertyBlock(_materialPropertyBlock);
}
}
シェーダーのソースコードはこちらである。
Shader "Test"
{
Properties
{
[KeywordEnum(Red, Green, Blue,Yellow)]
_Color("Color Keyword", Float) = 0
_BaseColor("Base Color", Color) = (1, 1, 1, 1)
_Integer("Integer", Int) = 1
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _COLOR_RED _COLOR_GREEN _COLOR_BLUE _COLOR_YELLOW
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
//この記述がないとSRP Batcherは適用されない
CBUFFER_START(UnityPerMaterial)
half4 _BaseColor;
int _Integer;
float _Color;
float4 _ColorMaterialPropertyBlock;
CBUFFER_END
v2f vert(appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
#ifdef _COLOR_RED
return _BaseColor;
#elif _COLOR_GREEN
return float4(0, 1, 0, 1) * _Integer;
#elif _COLOR_BLUE
return float4(0, 0, _Color, 1);
#elif _COLOR_YELLOW
return _ColorMaterialPropertyBlock;
#endif
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
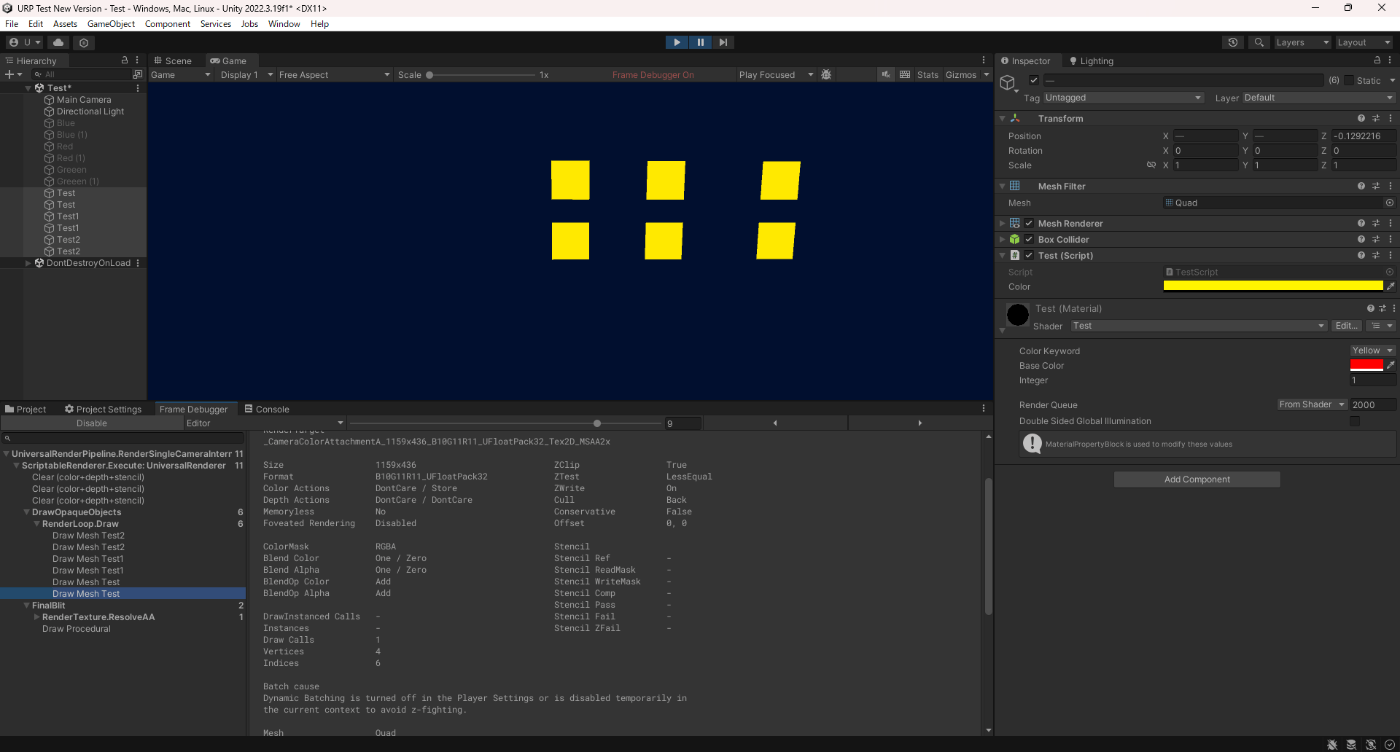
MaterialPropertyBlocksを使用した場合、SRP Batcherが適用されていないのが分かる。
⑥Frame DebuggerのBatch cause
Batch causeはSRP Batcherされなかった理由が記載されている原因が記載されている。
下記のNode use diffrent shader keywordsだと
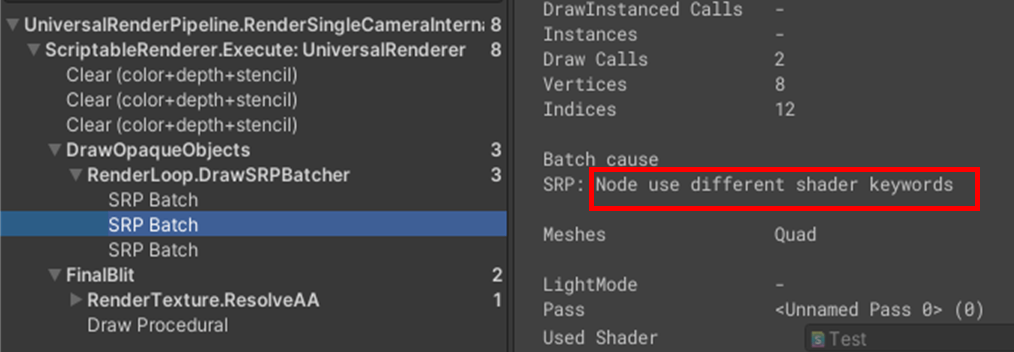
Frame DebuggerのNode use diffrent shader keywordsは、前のSRP Batchが異なるシェーダーバリアントであるためSRP Batchできなかったことを意味している。
実際にどういうことか試してみる。
シェーダーは以下である。
Shader "Test"
{
Properties
{
[KeywordEnum(Red, Green, Blue)]
_Color("Color Keyword", Float) = 0
}
SubShader
{
Tags
{
"RenderPipeline" = "UniversalPipeline"
}
Pass
{
Tags
{
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _COLOR_RED _COLOR_GREEN _COLOR_BLUE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
//この記述がないとSRP Batcherは適用されない
//CBUFFER_START(UnityPerMaterial)
//CBUFFER_END
v2f vert(appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex);
return o;
}
float4 frag(v2f i) : SV_Target
{
#ifdef _COLOR_RED
return float4(1, 0, 0, 1);
#elif _COLOR_GREEN
return float4(0, 1, 0, 1);
#elif _COLOR_BLUE
return float4(0, 0, 1, 1);
#endif
return float4(0, 0, 0, 1);
}
ENDHLSL
}
}
}
上のシェーダーのマテリアルを三つ用意して、KeywordEnumをそれぞれ変えてみた結果がこちら。
赤のQuad
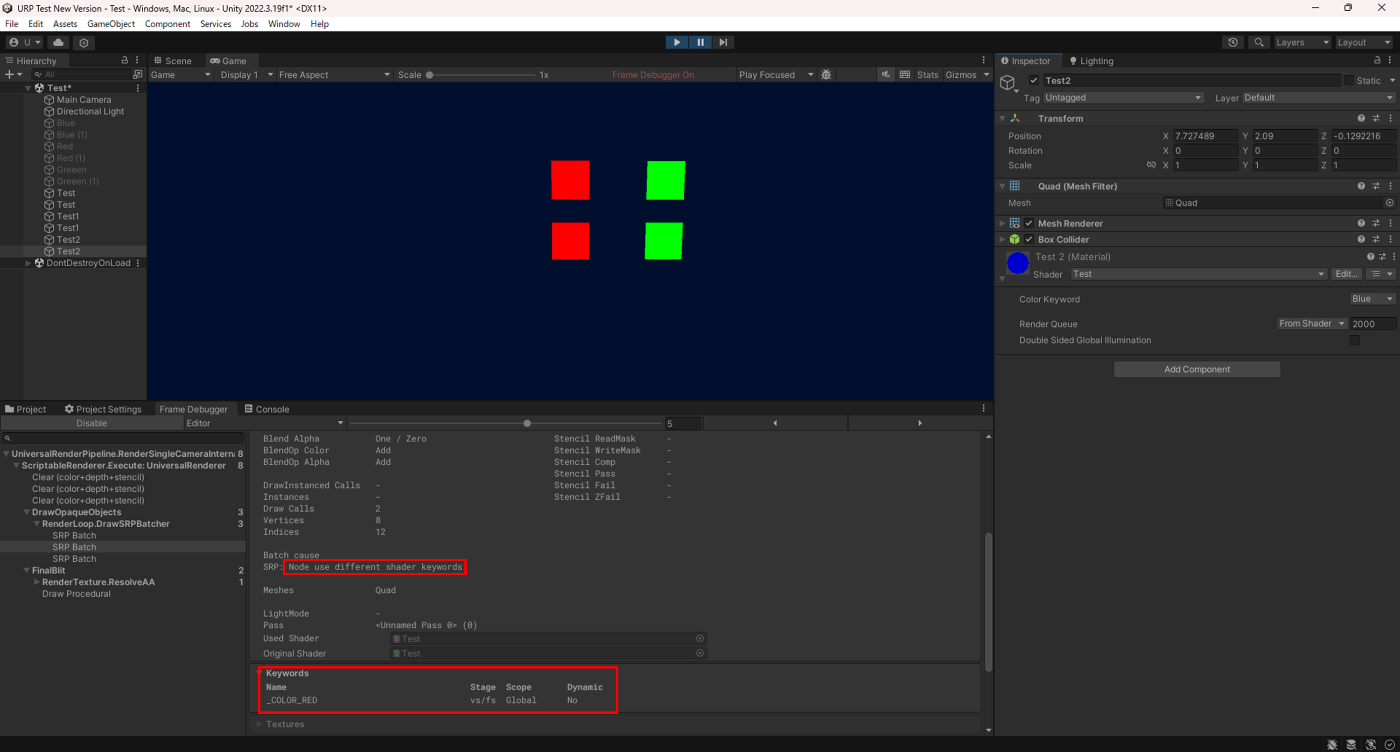
青のQuad
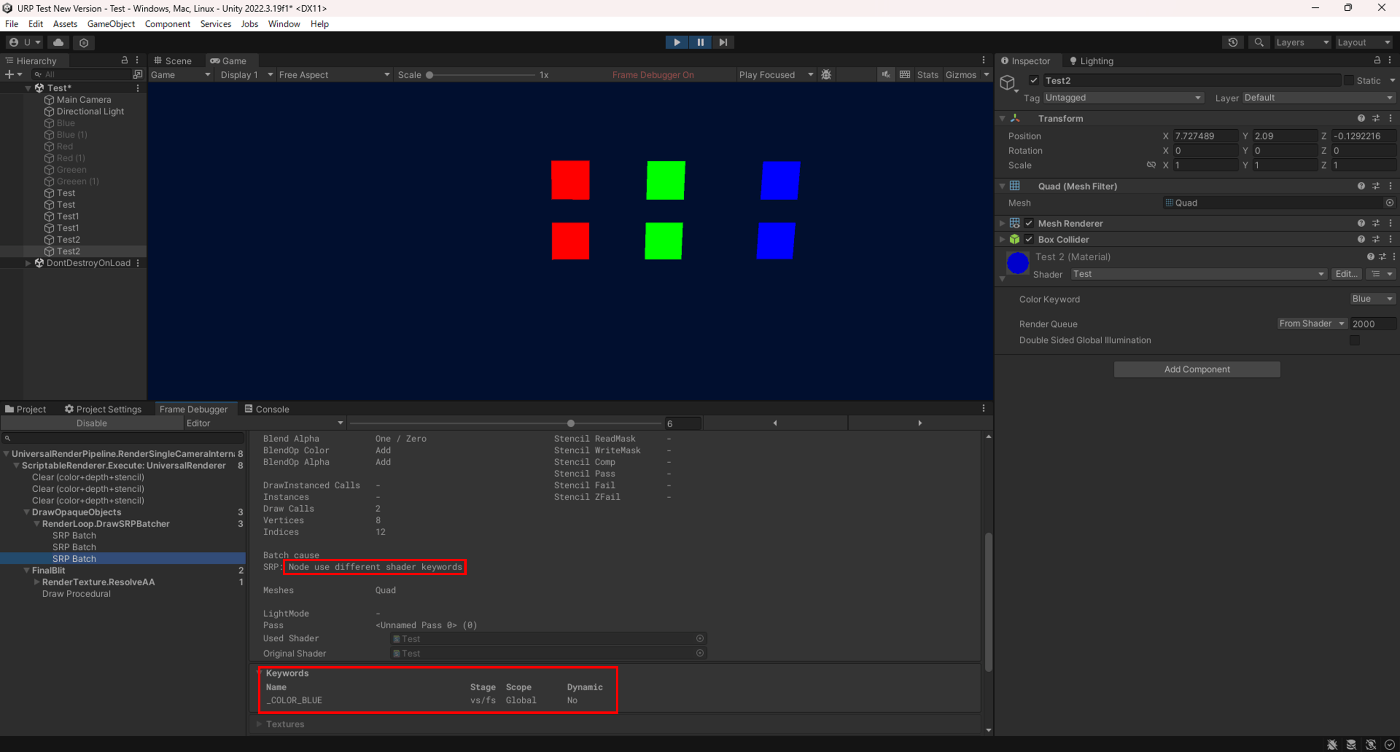
色ごとに異なるシェーダーバリアントを使用しているので、SRP Batchが適用されずNode use diffrent shader keywordsが表示されている。
■GPU インスタンシング、静的バッチ処理、動的バッチ処理、SRP Batcherの優先度
優先度は以下である。
1.SRP Batcherと静的バッチ処理
2.GPU インスタンシング
3.動的バッチ処理
実際にやってみる。
動的バッチ処理のみ適用
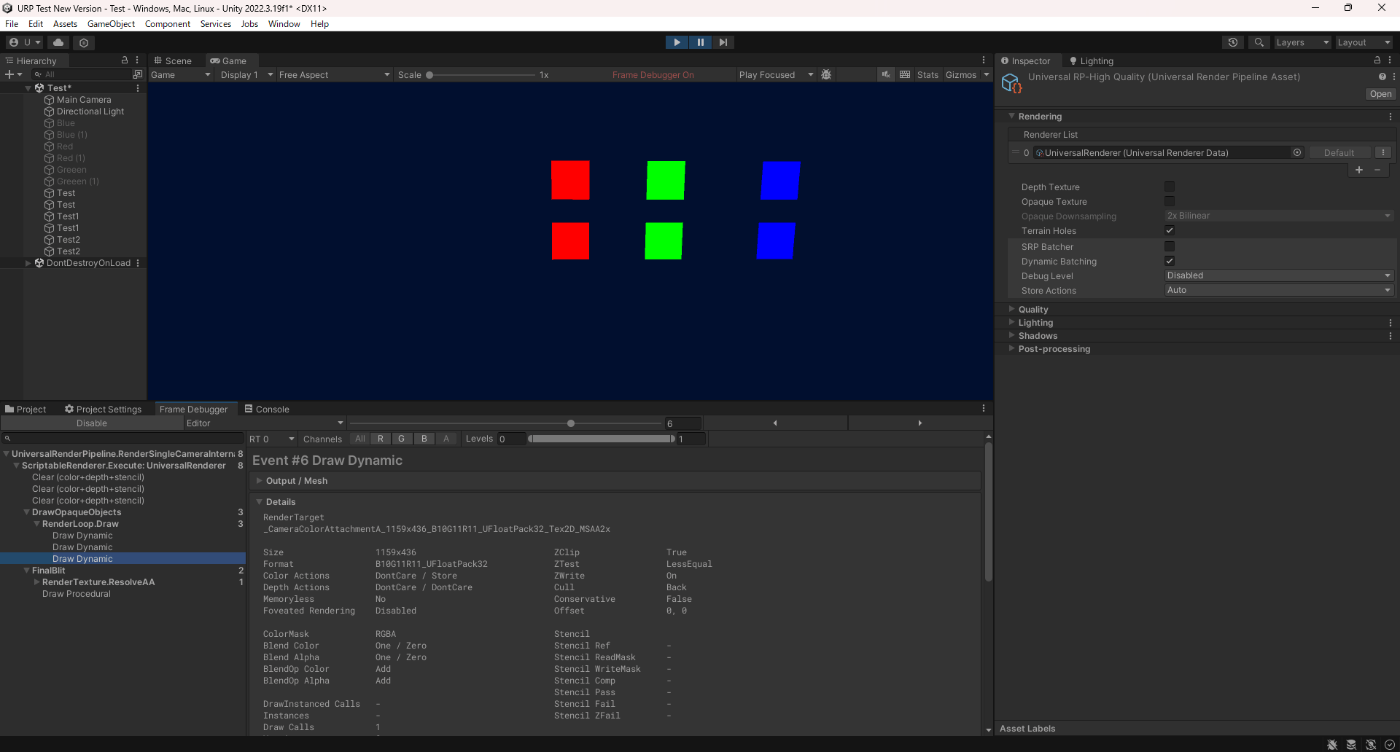
SRP Batcherと動的バッチ処理の両方を適用
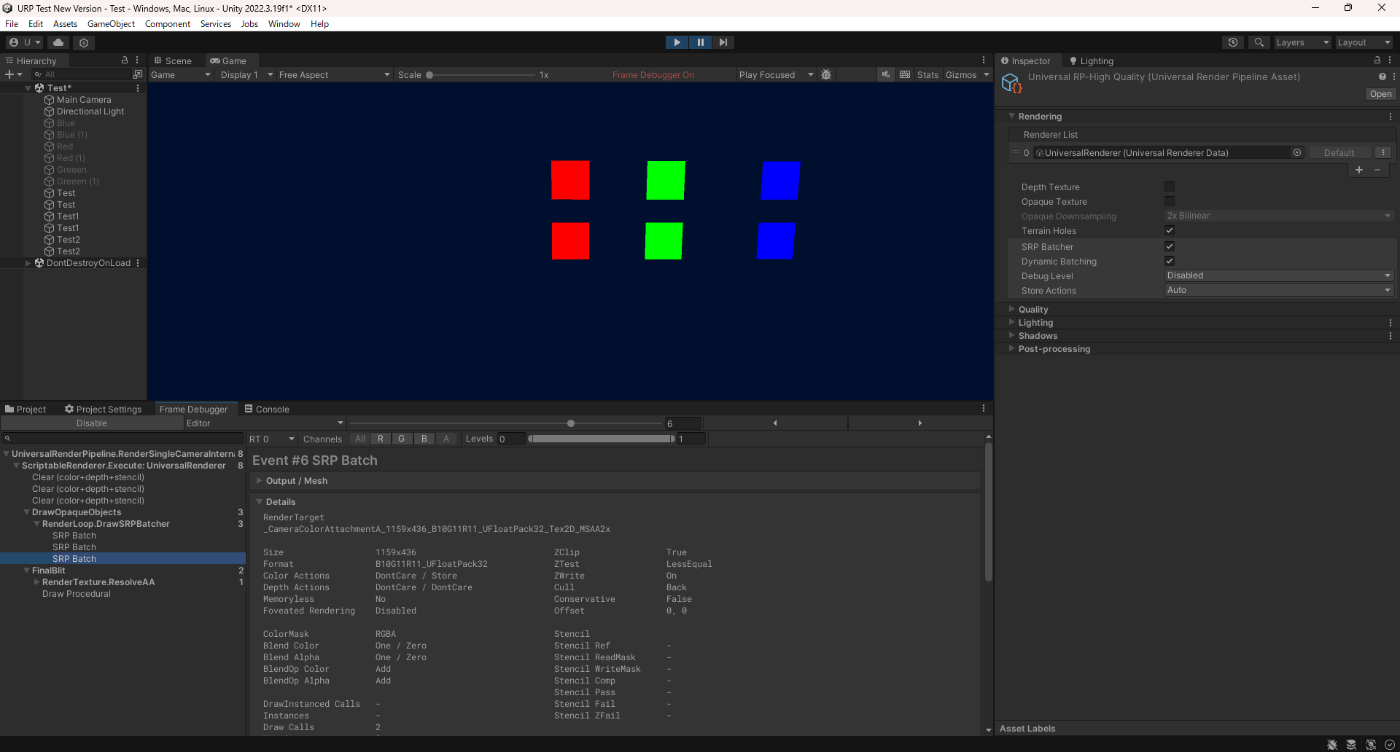
SRP Batcherと動的バッチ処理の両方を見ると、SRP Batcherが優先されているのが分かる。
次は、SRP Batcherと静的バッチ処理を併用してみる。
静的バッチを適用させたオブジェクト
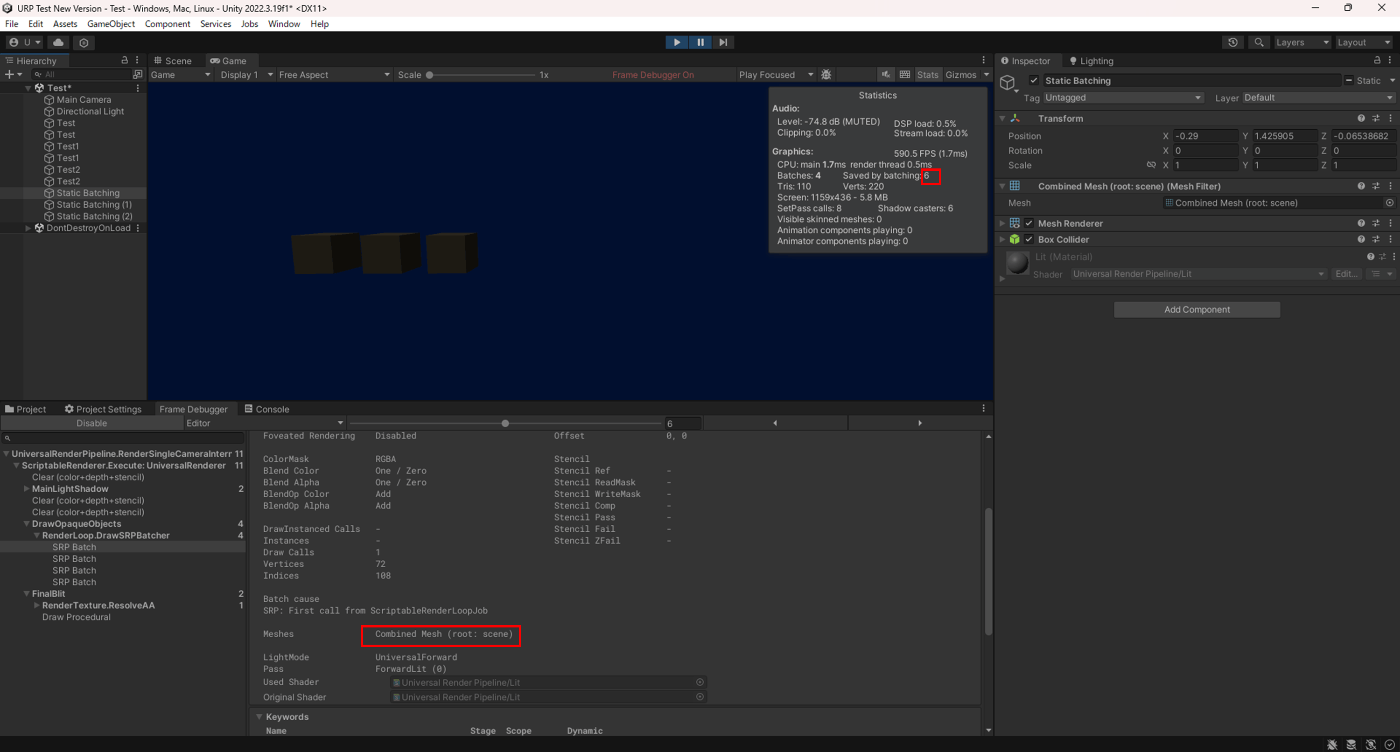
SRP Batcher適用させたオブジェクト
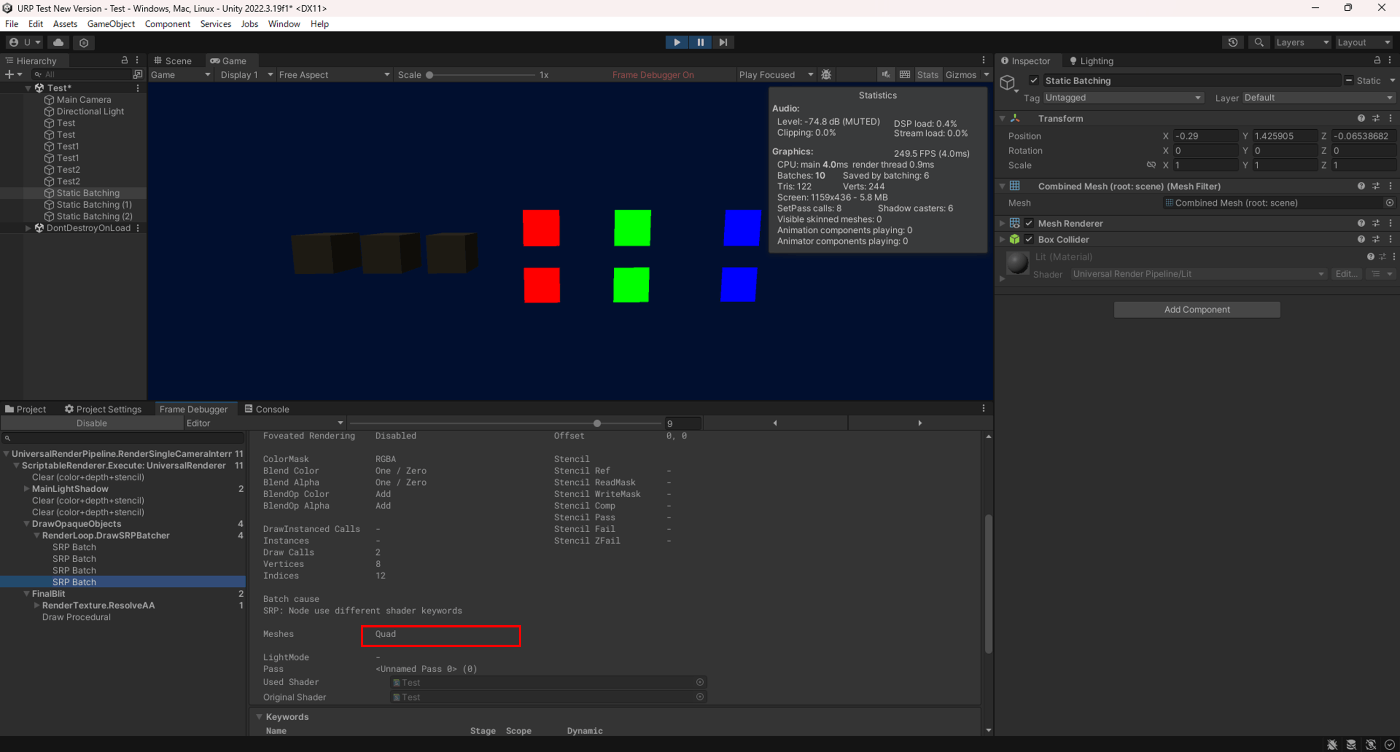
どちらも併用できていることが分かる。
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照動画、参照動画、参照サイト、参照サイト
・BatchRendererGroup (BRG)
大量のオブジェクトを描画する際に使われる技術。
Burst、JobSystem、DOTSの知識が必要であるため一旦は参照サイトだけ貼る。
参照サイト、参照サイト、参照サイト
・sqrMagnitudeとmagnitude
ベクトルの大きさを比較するときは、sqrMagnitudeの方が平方根の計算しないので負荷がかからない。
参照サイト
・Domain ReloadとReload Scene
Unityはシーンをロードすると、スクリプトのリセットとシーンのリセットを行う。
これは規模の大きいゲームを作成している場合などにシーンを再生開始が遅くなる傾向がある。
Domain Reloadは、スクリプトの状態をリセット。
Reload Sceneは、シーンを再ロードする。
この二つを無効にするとシーンの起動が早くなる。
なお、Enter Play Mode Optionsが無効だと、Domain ReloadとReload Sceneは有効になる
Domain ReloadとReload Sceneの有効・無効で試してみた
若干であるがDomain ReloadとReload Scene無効の方がシーンの再生が早いことが分かる。
■Reload Domainが無効の場合にスクリプトが初期化されるようにする。
Reload Domain有効だと自動でスクリプトが初期化されるが、無効だと初期化されない。
なので無効の設定で、スクリプトが初期化されるようにするにはスクリプトに少し手を加える必要がある。
①静的フィールド
例えば以下のソースを、Reload Domain無効で実行すると、シーンを中止して再度開始してもcounterの値が初期化されない。
using UnityEngine;
public class TestScript : MonoBehaviour
{
static int counter = 0;
void Update()
{
if (Input.GetKey(KeyCode.A)) {
counter++;
Debug.Log("Counter: " + counter);
}
}
}
手を加えたのこちら
この修正でシーン起動のたびにcounterが初期される。
using UnityEngine;
public class TestScript : MonoBehaviour
{
static int counter = 0;
[RuntimeInitializeOnLoadMethod(RuntimeInitializeLoadType.SubsystemRegistration)]
static void Init()
{
Debug.Log("Counter reset.");
counter = 0;
}
void Update()
{
if (Input.GetKey(KeyCode.A)) {
counter++;
Debug.Log("Counter: " + counter);
}
}
}
②静的イベントハンドラー
例えば以下のソースを、Reload Domain無効で実行すると、シーンを中止して再度開始してもイベントハンドラーからメソッドの登録が解除されずに、2回イベントが実行される。
void Start()
{
Debug.Log("開始");
Application.quitting += Quit;
}
static void Quit()
{
Debug.Log("テスト");
}
手を加えたのこちら
この修正でイベントハンドラーからメソッドが一度実行する。
using UnityEngine;
public class TestScript : MonoBehaviour
{
[RuntimeInitializeOnLoadMethod]
static void RunOnStart()
{
Debug.Log("初期化");
Application.quitting -= Quit;
}
void Start()
{
Debug.Log("開始");
Application.quitting += Quit;
}
static void Quit()
{
Debug.Log("テスト");
}
}
■Reload Sceneは無効にしてもほとんど副作用はない
Reload Sceneは無効にしてもほとんど副作用はない。
ただ、エディターでアプリケーションを起動するのにかかる時間は、ビルドされたバージョンの起動時間を表すものではなくなります。したがって、プロジェクトの起動時に何が起こっているのかを正確にデバッグまたはプロファイルしたい場合は、Reload Scene を有効にして、ビルドされたバージョンで発生する実際のロード時間とプロセスをより正確に表す必要があります。
参照サイト、参照動画
・Assembly Definition
フォルトでは、Unity はほとんどすべてのゲームスクリプトを、定義済みの アセンブリ、Assembly-CSharp.dll にコンパイルします。
この方法は小規模なプロジェクトには適していますが、プロジェクトにさらに多くのコードを追加すると、いくつかの欠点があります。
①1 つのスクリプトを変更するたびに、Unity は他のすべてのスクリプトを再コンパイルする必要があり、反復的なコード変更を行うと全体のコンパイル時間が長くなります。
②どのスクリプトも他のスクリプトで定義された型に直接アクセスできるため、コードのリファクタリングや改善が難しくなる可能性があります。
③すべてのスクリプトは、すべてのプラットフォーム用にコンパイルされます。
アセンブリを定義することで、コードを整理してモジュール性や再利用性を高めることができます。プロジェクトで定義したアセンブリ内のスクリプトは、デフォルトのアセンブリには加えられず、指定した他のアセンブリのスクリプトにアクセスのみを行います。
少し複雑そうなので一旦参照サイトだけ貼る。
参照サイト
・ジョブシステム(Job system)
Unity のジョブ システムを使用すると、アプリケーションが使用可能なすべての CPU コアを使用してコードを実行できるように、マルチスレッド コードを作成できます。これにより、アプリケーションは 1 つの CPU コアですべてのコードを実行するのではなく、実行されているすべての CPU コアの容量をより効率的に使用できるため、パフォーマンスが向上します。
ジョブ システムは単独で使用できますが、パフォーマンスを向上させるには、 Unity のジョブ システム用にジョブをコンパイルするように特別に設計されたBurst コンパイラーも使用する必要があります。
少し複雑そうなので一旦参照サイトだけ貼る。
参照サイト
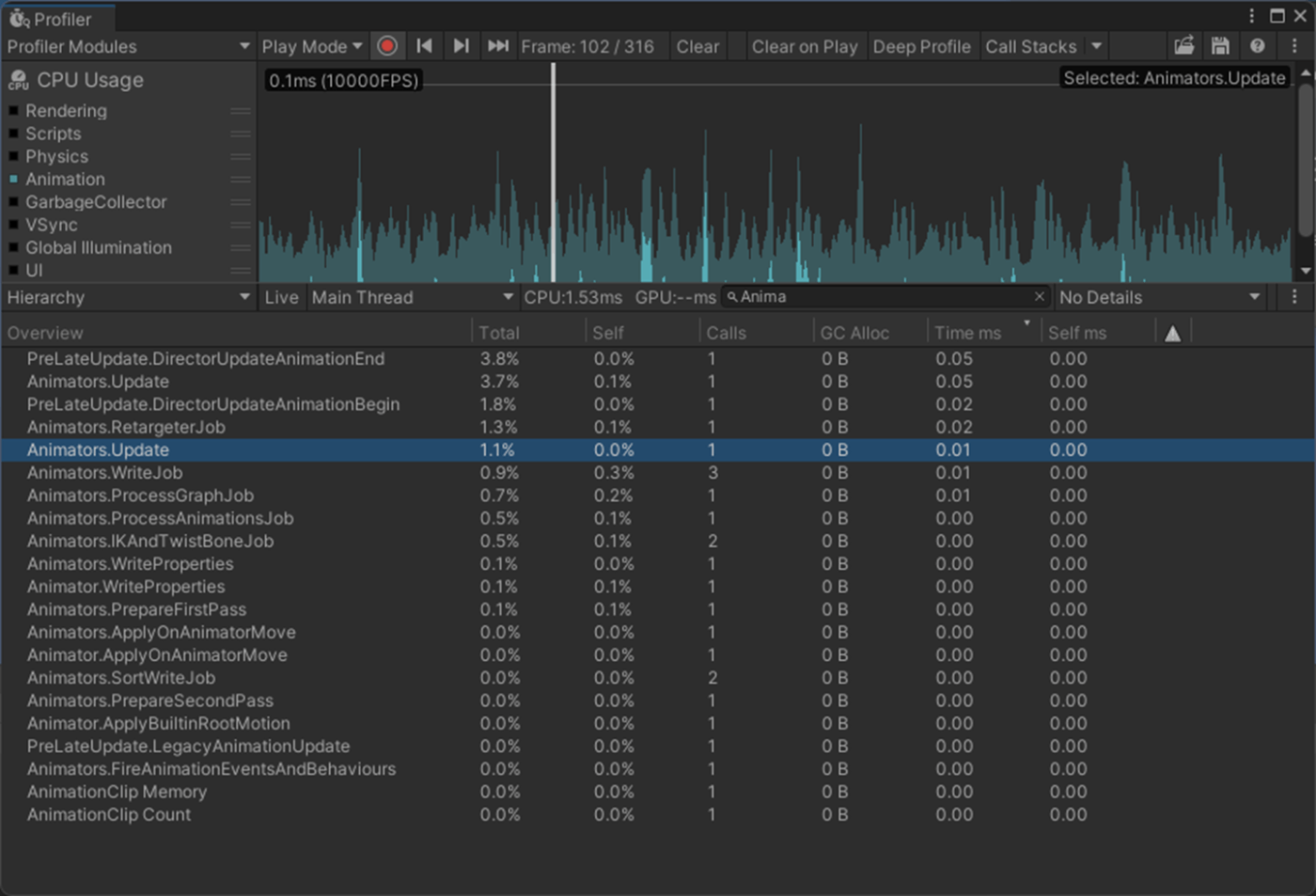
・AnimatorコンポーネントにAnimator Controllerが設定されていないと負荷がかからない
Animator Controllerが設定されている
Animator Controllerが設定されていない
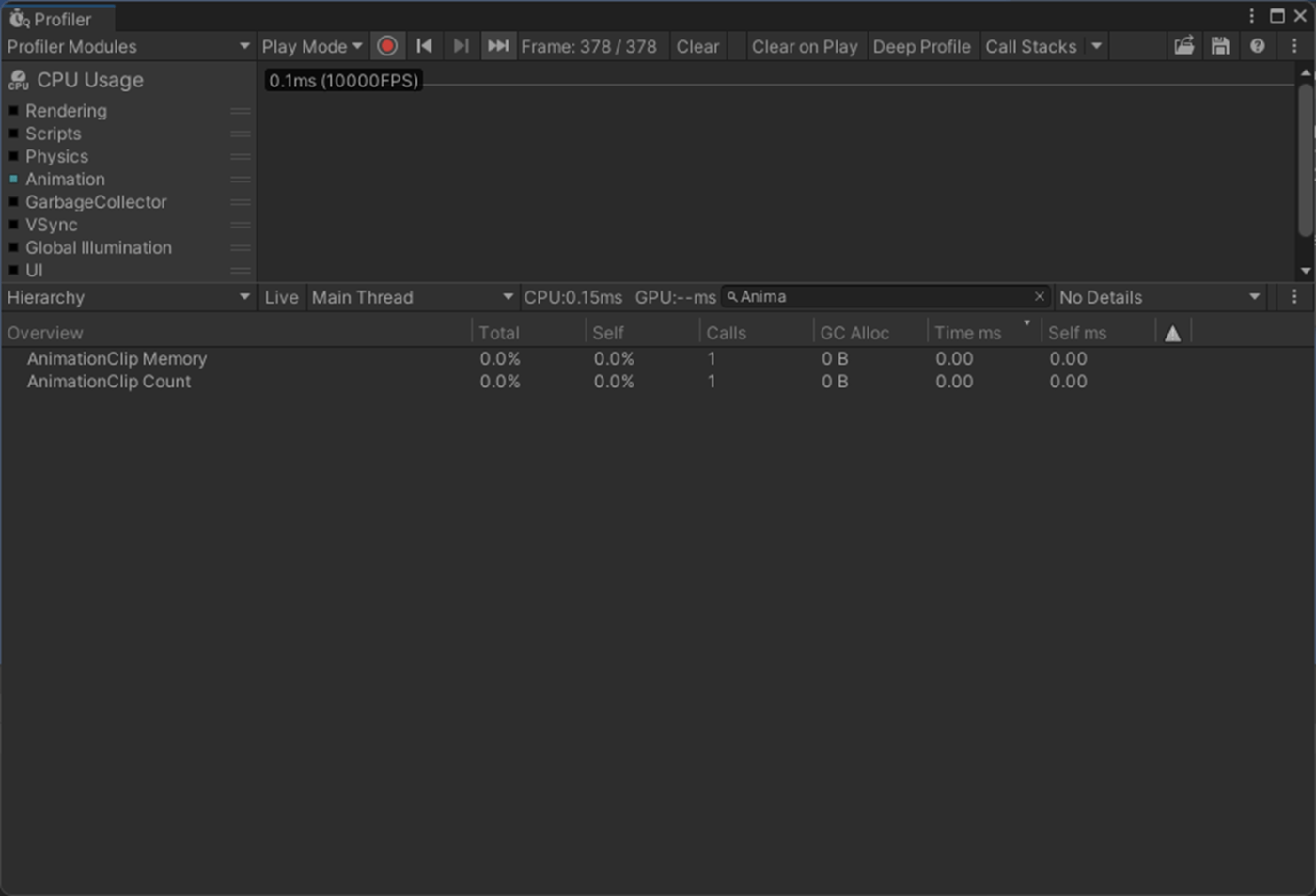
参照サイト
・ブレンディングなしで 1 つの アニメーションクリップ を再生すると、Unity は 古いアニメーションシステム を使うよりも遅くなる場合がある。
参照サイト
・Scaleのアニメーションは、移動や回転よりも負荷がかかる
ただ、公式ドキュメントでは定数のカーブは通常のカーブに比べて負荷がかからないと書いてある。
ここでいう定数カーブとは下の図の赤線のようなカーブだと思われる。
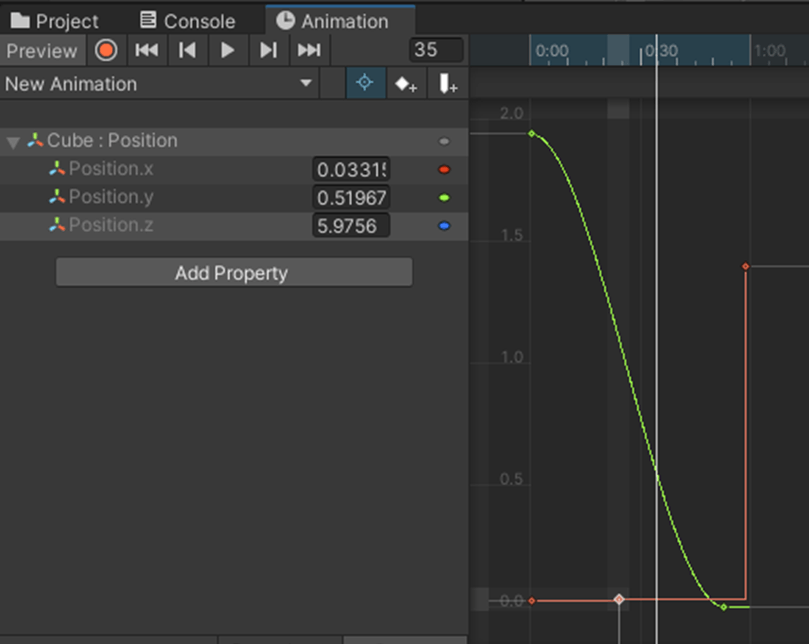
参照サイト
・レイヤーのWeightが0ならアニメーションの負荷はかからない。
参照サイト
・ヒューマノイドアニメーションをインポートするときに、必要がない場合は、アバターマスク (class-AvatarMask) を使用して IK ゴールや指のアニメーションを削除すると負荷を削減できる
参照サイト
・ジェネリックを使用する場合、ルートモーションを使用する方が、使用しない場合よりもコストがかかります。アニメーションがルートモーションを使用しない場合は、ルートボーンを指定していないことを確認してください。
参照サイト
・Animator コンポーネントのCulling Mode
カメラ外のオブジェクトがアニメーションするかどうかの設定。
Always Animateはカメラ外でもアニメーションを行う。
Cull Update Transform、Cull Completelyはカメラ外でアニメーションを行わない。
Cull Update Transform、Cull Completelyの方が負荷がかからない。
参照サイト、参照サイト
・Skinned Mesh RendererのUpdate When Offscreen
有効にするとUnity はメッシュが表示されないときでも、常にメッシュの境界を計算し続けます。パフォーマンスがあまり気にならない場合や、バウンディングボリュームのサイズを予測できない場合 (ラグドールを使用する場合など) にこのオプションを使用します。
無効にした場合、負荷が下がる。
参照サイト、参照サイト
・Enable Frame Timing Statsを使用して、CPUとGPUの処理時間を計測できる。
参照サイト、参照サイト
・Build SettingsのBuild App Bundle (Google Play)
Build App Bundle (Google Play)を有効にすると、AABでビルドされる。
Build App Bundle (Google Play)を無効にすると、APKでビルドされる。
AABの方が、アプリのダウンロードサイズが小さくなる・ビルド時間が短縮される。
参照サイト、参照サイト
・Shader Variant Loading
ランタイムにシェーダーが使用するメモリの量を制御できる。
Default chunk size (MB)、Default chunk count、Override、Chunk size (MB)、Chunk countで細かく制御できる。
参照サイト
・Android のスレッド設定
Unity は、デバイスの CPU トポロジーに基づいて スレッドアフィニティ と スレッド優先順位 を設定します。Unity のデフォルトのスレッド設定はほとんどのプロジェクトでうまく機能しますが、状況によってはスレッド設定の変更が必要になることも考えられます (例えば、特定のデバイス用に最適化したい場合や、アプリケーションを低電力消費にすることを目指していて、高フレームレートが不要な場合など)。
ただ、可能な限り Unity のデフォルトの設定を使用してください。特定のデバイス用の最適化のためにスレッドの設定を変更すると (それがどのような変更であっても)、他のデバイスや、同じデバイスの将来の OS バージョンで、パフォーマンスに悪影響が及ぶ可能性があります。
参照サイト
・MinifyのReleaseとDebug
Minify とは、アプリケーションのコードを縮小、難読化、最適化するプロセスです。コードサイズを縮小し、コードを逆アセンブルしにくくすることができます。Minify の設定を使って、いつ、どのように Unity がビルドに小型化を適用するかを定義します。
ほとんどの場合、リリースビルドにのみ小型化を適用し、デバッグビルドには適用しないのが良い習慣です。小型化には時間がかかり、ビルドが遅くなる可能性があるからです。また、コードが小型化されることで、デバッグがより複雑になる可能性があります。
参照サイト、参照サイト
・AndroidのBuild SettingsのETC2 fallback
ETC2 をサポートしていない Android デバイスで Unity が使用する非圧縮 RGBA テクスチャ形式を指定します。これは、非圧縮テクスチャのメモリ使用量と画質に影響します。オプションは以下の通りです。
■32-bit
各ピクセルに 32 ビット (各カラーチャンネルに 8 ビット) 使用して、フル解像度で RGBA テクスチャを保存します。これは最高品質の非圧縮テクスチャ形式で、メモリ使用量が最も多くなります。
■16-bit
各ピクセルに 16 ビット (各カラーチャンネルに 4 ビット) 使用して、フル解像度で RGBA テクスチャを保存します。メモリ使用量は 32-bit の半分ですが、精度が低いため、テクスチャの重要な色情報が失われる可能性があります。
■32-bit, half resolution
各ピクセルに 32 ビット (各カラーチャンネルに 8 ビット) を使用して、半分の解像度で RGBA テクスチャを保存します。メモリ使用量は 32-bit の 4 分の 1 ですが、テクスチャが不鮮明になる可能性があります。
参照サイト
・Build SettingsのCompression Method
Unity がプレイヤーをビルドする際に、Project 内のデータの圧縮に使用する方法を指定します。これには、アセット、シーン、Player 設定、GI データ が含まれます。オプションは以下の通りです。
■Default
ZIP を使用します。LZ4 や LZ4HC より若干質が高くなりますが、データの解凍時間がより長くなります。
■LZ4
LZ4 を使用します。開発ビルドに便利な高速な圧縮形式です。ZIP の代わりに LZ4 圧縮を使用すると、Unity アプリケーションのロード時間が大幅に短縮される場合があります。詳細は BuildOptions.CompressWithLz4 を参照してください。
■LZ4HC
高圧縮タイプの LZ4 です。ビルド時間は長くなりますが、リリース版ビルド向けに、より質の高い結果が得られます。ZIP の代わりに LZ4HC 圧縮を使用すると、Unity アプリケーションのロード時間が大幅に短縮される場合があります。詳細は BuildOptions.CompressWithLz4 を参照してください。
参照サイト
・iOS 固有の最適化
■iOSのPlayer SettingsのScript Call OptimizationをFast but no Exceptions
UnityEngine 名前空間にあるほとんどの関数は C/C++ で実装されています。Mono スクリプトから C/C++ 関数を呼び出すと、パフォーマンスのオーバーヘッドが発生します。そのため、iOS Script Call Optimization の設定を使用して、1 フレームあたり約 1 - 4 ミリ秒節約できます。
iOS では、(内部的な、または、try/catch ブロックを使用した) 例外処理に決して依存しないことが良い開発方法といえます。デフォルトの Slow and Safe オプションを使用すると、Unity はデバイス上で発生するすべての例外をキャッチし、スタックトレースを提供します。 Fast but no Exceptions オプションを使用しない場合、発生した例外はすべてゲームをクラッシュさせ、スタックトレースは提供されません。さらに Unity は AppDomain.UnhandledException イベントを送信し、プロジェクト特有のコードが例外情報にアクセスできるようにします。
Mono スクリプティングバックエンドを使用すると、プロセッサーが例外処理しないため、ゲームはより高速で実行されます。IL2CPP スクリプティングバックエンドを使用する場合、Fast but no Exceptions オプションにはパフォーマンス上の利点はありません。ただし、ゲームを世界にリリースするときは、Fast but no Exceptions オプション付きで公開することを推奨します。
■iOSのPlayer SettingsのAccelerometer Frequencyの値を小さくする
Accelerometer Frequencyは、加速度センサーの処理周波数を設定する項目である。
この値を小さくすることでパフォーマンスが良くなる。
■インクリメンタルビルド
インクリメンタルビルドとはソースファイルが変更された部分だけをビルドすることで、ビルド時間を減らすというもの。
やり方としては、ソースファイルが変更された状態で、ビルドしたフォルダに再度ビルドするとダイアログで、Appendと押下すると可能。
実際にやってみた。
Appendが、11秒
Replaceが、12秒
1秒であるが変わってた。
なお、AndoroidでもiOSとやり方は少し異なるが可能らしい([こちら]
(https://unityletsgo.hatenablog.com/entry/2021/11/15/185846))
■TimeのFixed Timestepを小さくできる
これにより、物理演算の更新に費やす時間を削減できる。ただ精度が落ちるので注意。
■TimeのMaximum Allowed Timestepを小さくする
この値を下げると、パフォーマンスが低下したときに、物理演算やアニメーションが遅くなる可能性がありますが、同時にフレームレートへの影響も少なくなります。
■コライダーはメッシュコライダーでなく、なるべくプリミティブコライダーを使用する
参照サイト、参照サイト、参照サイト
・iOSアプリのサイズを小さくする
■Xcode 内で適切な リリース用ビルド を作成する
■アセットを最小化します: テクスチャで圧縮を有効化し解像度をできる限り下げます。
■Mono で iOS Stripping Level を Use micro mscorlib に設定するか、 IL2CPP で Strip Engine Code を有効にします。
■Script Call Optimization を Fast but no exceptions に設定します。
■コードの中で System.dll や System.Xml.dll に属するものは一切使用しないでください。これらのライブラリは micro mscorlib と互換性が ありません 。
■不要なコードの依存関係を取り除く。
■API Compatibility Level に .Net 2.0 subset を設定します。.Net 2.0 subset は他のライブラリと限られた互換性しかないことに注意してください。
■値型 (構造体も含む) との組み合わせでジェネリックコンテナーを使用することは避けます。
参照サイト
・シェーダー最適化入門 第1回目「条件分岐を使いこなせ」
参照サイト
・CyberAgentさんの最適化本
CyberAgentGameEntertainment
・URPのオーバードローを確認

Discussion