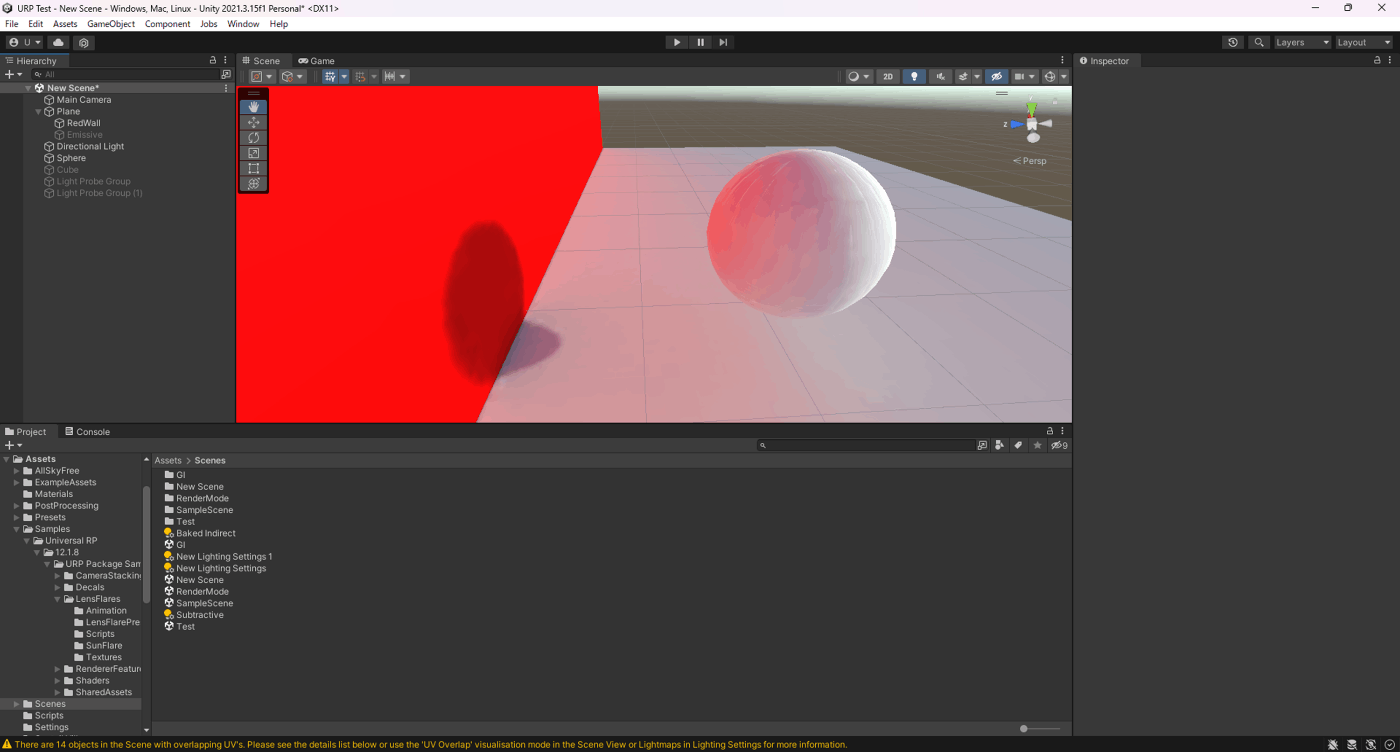
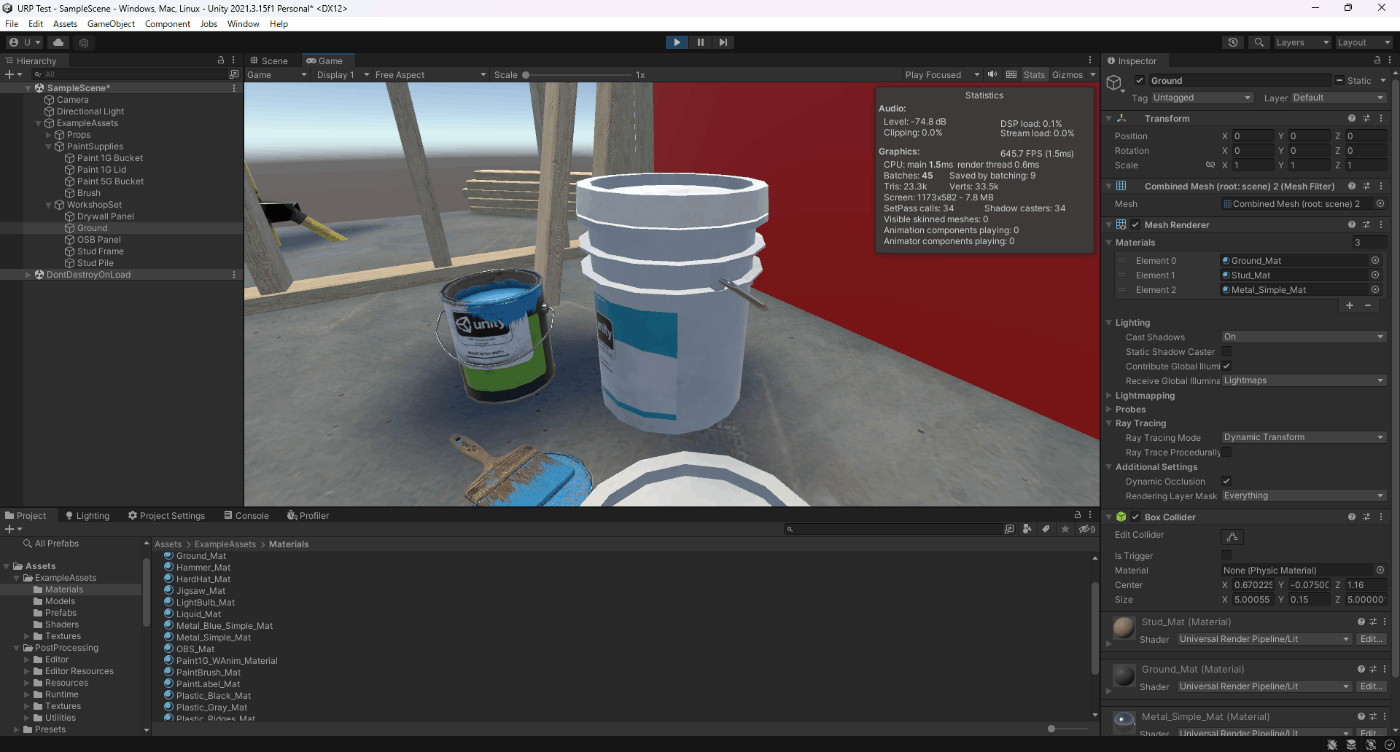
Unity 最適化1
メモしたのを書きなぐります
・Adaptive Performance
Galaxy端末で、端末温度やCPU/GPUのボトルネック状態のイベントを受け取り、端末の負荷が下がる処理(LOD、解像度、フレームレートの変更など)を行う
参照サイト
・Scaleは基本1で設定
参照サイト
・アプリサイズ削減
参照サイト
・インポート時間削減 Accelerator
参照サイト
・インポート時間とプラットフォーム切り替えの時間削減
参照サイト
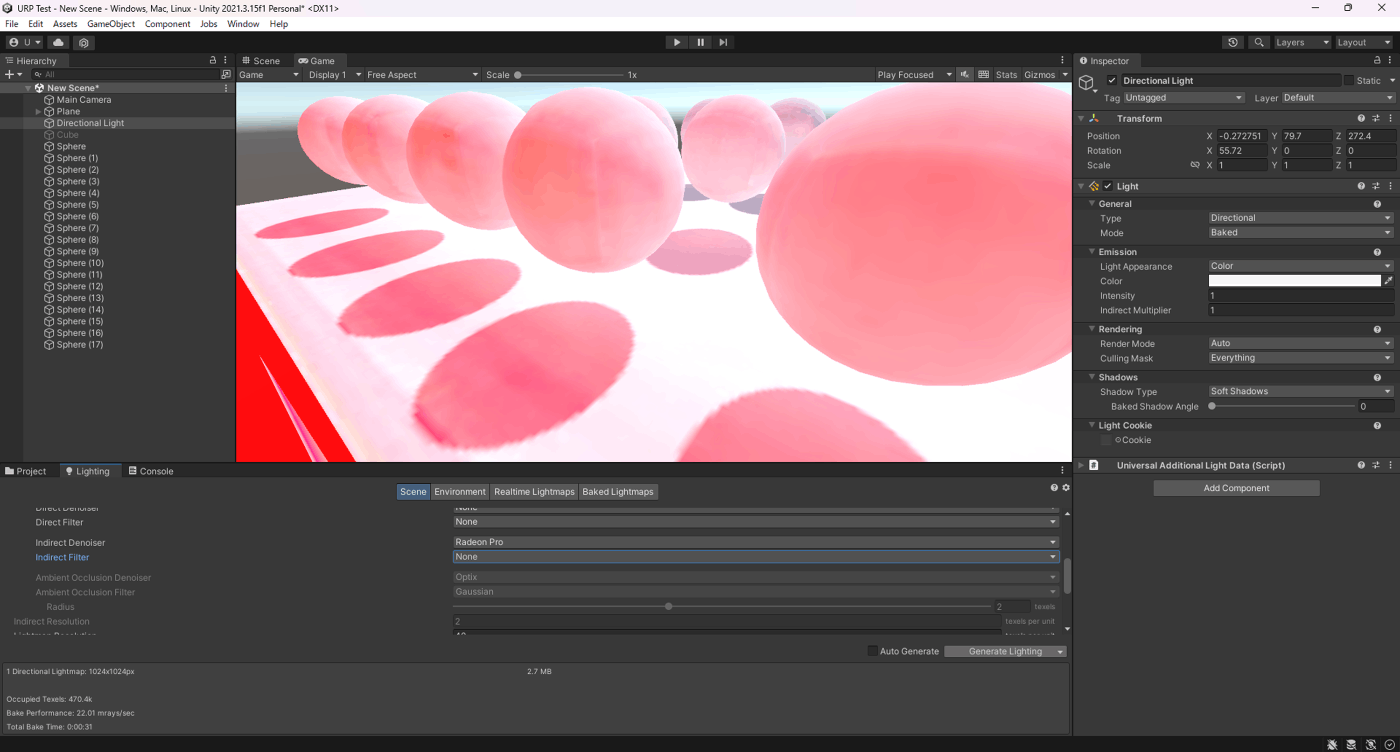
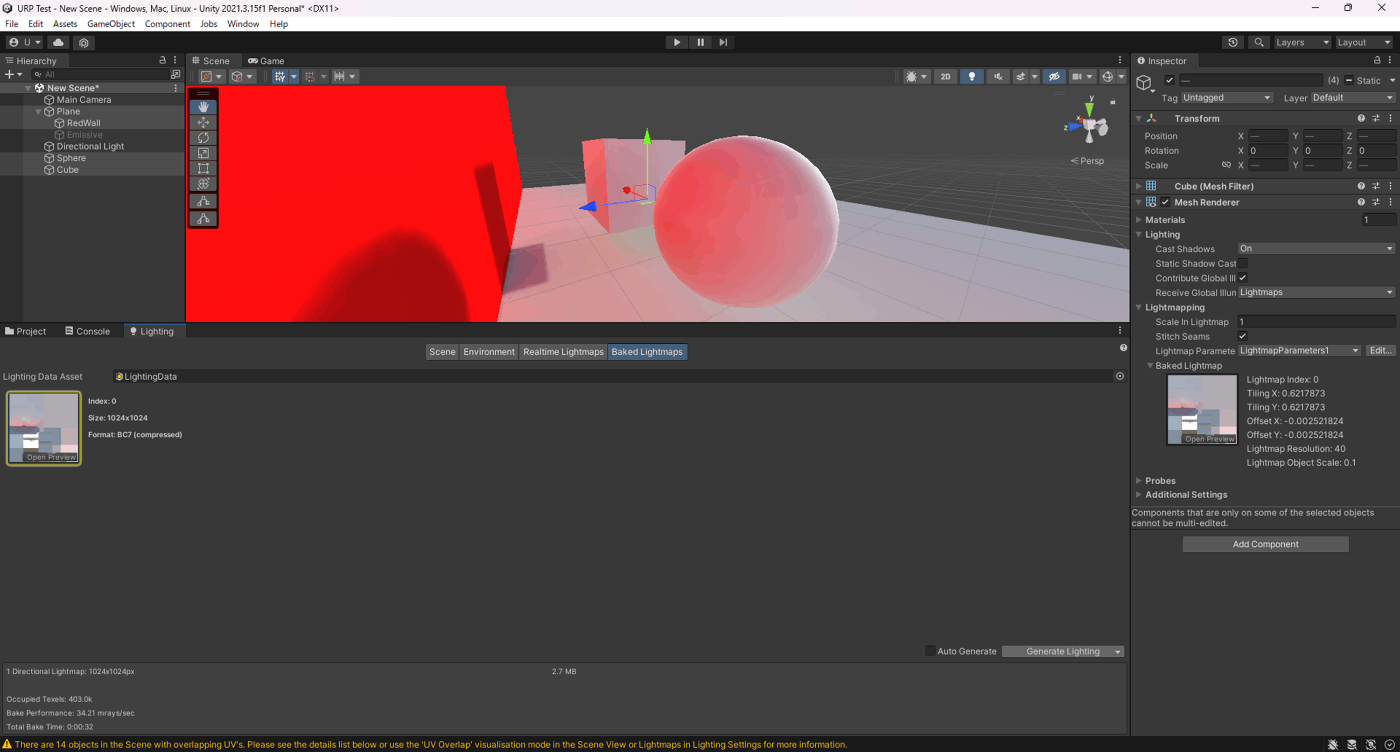
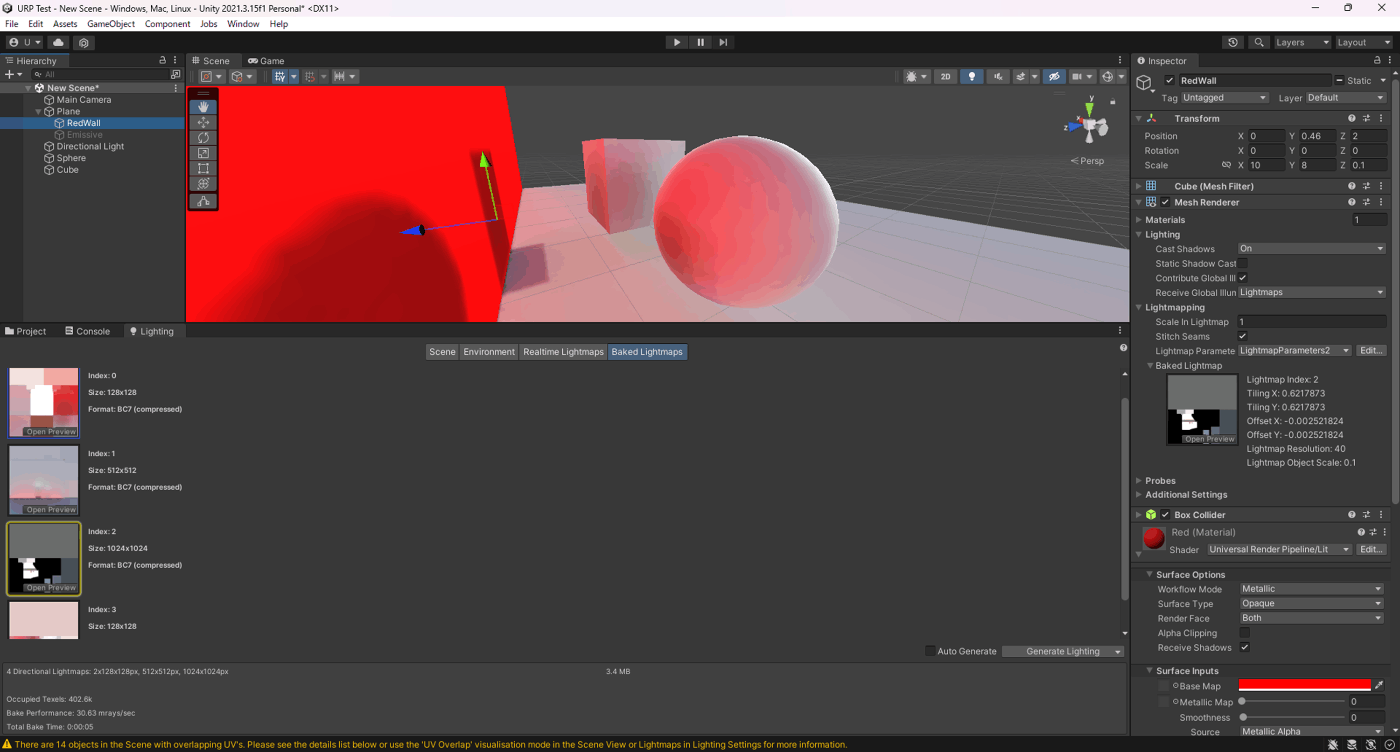
・GIキャッシュを使用して、エディタ内の速度アップ
参照サイト
起動時間とアプリインストール後のサイズの削減。Compression Method
参照サイト、参照サイト、参照サイト
・Parallel Importをオンにして、インポート時間を短縮
参照サイト、参照サイト
・Lightmap modes、Fog modes、Instancing Variantsを調整して、ShaderVariantを削除し、ビルドサイズとメモリ使用量を削減。
参照サイト、参照サイト、参照サイト、参照サイト
・Compiling shader variantsで、ShaderVariantを削除し、ビルドサイズとメモリ使用量を削減。
参照サイト、参照サイト
・ShaderVariantCollectionを使用して、シェーダを事前にロードしておき、かくつきを抑える
参照サイト、参照サイト、参照サイト、参照サイト
・ShaderVariant切替時に発生するCreateGPUProgramの負荷を、ShaderVariantCollectionと
ShaderVariantCollection.Warmupで削減
参照サイト
・URP Global SettingsのShader Strippingを変更して、ビルド時間・サイズを少なくしよう
参照サイト
・Sleep Thresholdの値を大きくしてスリープしやすくし、CPUの負担を減らす
参照サイト、参照サイト
・Auto Simulationをオフにして、毎フレームの物理演算をなくす
参照サイト
・Auto Sync Transformsをオフにして、Transfrom反映後にRigidbody、Collider 、Physicsに即座に反映させるのを辞め、CPUの負荷を下げよう
参照サイト
・Reuse Collision Callbacksをオンにして、コリジョンした際のインスタンスを再利用し、メモリを節約しよう
参照サイト、参照サイト
・スリープ状態が多い場面だとSAP、動くオブジェクト多い場合はMBP。正直よくわからん。Broadphase Type
参照サイト、参照サイト、参照サイト
・Friction Typeで摩擦の計算方法を調整してCPUの負荷を減らす。
Patch Friction Type>One Directional Friction Type>Two Directional Friction Type
の順で負荷低いが、CPUの負荷がかからない
参照サイト
・Optimized Frame Pacingをオンにして、フレームレートを安定させよう
参照サイト
・Resolution Scaling ModeのFixedDPIで、dpiを設定し、フレームレートや電力消費を悪化させるのを防ごう
参照サイト、参照サイト、参照サイト
・Blit Typeで、フレームバッファの書き込み方を調整して早くしよう
NeverはAlwaysより早いが、リニアレンダリングでは暗くなってしまう
また、Vulkanの場合は、こちらの設定は無視される
参照サイト、参照サイト、参照サイト
・Use 32-bit Display Bufferでオフにすると、マッハバンドの発生やアルファが必要なポストエフェクト(ビルトインだとDOFとTAA?)などでビジュアルが悪くなる可能性がある。なので基本はオンでOK。
Use 32-bit Display Bufferはディスプレイバッファが 16 ビットカラー値ではなく 32 ビットカラー値を保持するかの設定。
参照サイト、参照サイト、参照サイト
・Disable Depth and Stencilオンにすると、深度バッファとステンシルバッファが無効になるので、CPU/GPUの負荷とメモリの使用量が減る。
参照サイト、参照サイト
・Multithreaded Renderingをオンにして、グラフィックAPIの呼び出しをマルチスレッドにして、CPUの負荷を減らそう
参照サイト、参照サイト、参照サイト
・Static Batchingで、CPUの負荷を下げよう(メモリは増加する)
なお、Dynamic BatchingはURPでは使用不可
メッシュレンダラー、トレイルレンダラー、ラインレンダラー、パーティクルシステム、スプライトレンダラーで可能
参照サイト、参照サイト、参照サイト、参照サイト
・Compute Skinningを使用して、スキニングの処理をGPU側で行いCPUの負荷を減らそう
ただ、OpenGL ES 3.1 または Vulkan のみ
参照サイト
・Graphics Jobsを使用して、マルチスレッドで描画コマンドを生成し、CPUの負荷を減らそう
ただ、Vulikanのみで、Experimentである
参照サイト、参照サイト
・Normal Map Encodingで、法線マップのエンコードを設定して負荷を減らそう
参照サイト
・Lightmap Encodingで、ライトマップのエンコーダーを調整し、ファイルサイズとメモリ使用量削減しよう。Higtだと、HDRライトマップ、Middle・Lowだと非HDRライトマップ
参照サイト、参照サイト、参照サイト
・HDR Cubemap Encodingで、HDR キューブマップのエンコーダーを調整し、ファイルサイズとメモリ使用量削減しよう。
参照サイト
・Lightmap Streamingをオンにして、ライトマップのテクスチャストリーミングを適用させ、メモリの消費量を削減しよう
また、初めのロード時間を短縮できる効果もある
ただ、CPUの負荷が少し増え、見た目が悪く見えるときがある
参照サイト、参照サイト
・Frame Timing Statsをオンにして、CPUとGPUの負荷をリアルタイムで計測して、画面に情報を表示したり、動的に対処したりできる
参照サイト、参照サイト、参照サイト
・Virtual Texturingをオンにして、GPU メモリの使用量とテクスチャのロード時間を削減する
ただ、MacとWindowsとLinuxしか対応していない
参照サイト
・Shader precision modelで、シェーダーのサンプラーの精度を変更しよう
参照サイト、参照サイト
・SRGB Write Modeをオフにして、パフォーマンスを下げよう
参照サイト、参照サイト、参照サイト
・Number of swapchain buffersで、トリプルバッファにしてFPSを安定させよう
ただ、トリプルだとメモリを食うので注意
参照サイト、参照サイト
・Acquire swaichain image late as possibleをオフにすることで、Android のメモリ帯域幅の追加コストを回避
参照サイト
・Apply display rotation during renderingをオンにして、フレームバッファの書き込み時に回転させておき、パフォーマンスを上げよう。
アプリケーションのフレームバッファの向きがデバイスの元からのディスプレイの向き (ほとんどのデバイスでは縦) と一致しない場合、Android はアプリケーションのフレームバッファをフレームごとに、デバイスのディスプレイに合わせて回転させます。デバイスのハードウェア機能によっては、この追加の回転がパフォーマンスに悪影響を及ぼすことがあります。
アプリケーションが Vulkan Graphics API を使用し、デバイスが Vulkan をサポートする場合、Unity はレンダリング中にこの回転を適用し、回転によるパフォーマンスへの影響を軽減することができます。これは pre-rotation (事前回転) と呼ばれます。
Apply display rotation during renderingをオンにすれば、この事前回転を実現できる。
参照サイト、参照サイト、参照サイト、参照サイト
・Recycle command buffersをオンにすると、CommandBufferを実行後再利用
CommandBuffer使用しないならオフにした方がよい?
参照サイト
・パフォーマンス、セキュリティの観点から、IL2CPPに方が良い。ただビルド時間とアプリサイズは増える。
また、ストリッピングも使用して、コードのサイズを縮小できる。(Monoはできない)
アノテーションを付けて特定のコードをストリッピングしないようにできる。
あとAndroidは、IL2CPPでしかアプリを公開する際はだめらしい
2021.2だとパフォーマンスが向上してる
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト
・IL2CPP のビルド時間の最適化
IL2CPP を使用するプロジェクトのビルド時間は、Mono を使用する場合よりも大幅に長くなることがあります。しかし、ビルド時間を短縮するためにいくつか工夫できます。
■マルウェア対策ソフトのスキャンからプロジェクトを除外する
プロジェクトをビルドする前に、Unity のプロジェクトフォルダーとターゲットのビルドフォルダーをマルウェア対策ソフトのスキャン対象から除外します。
■プロジェクトとターゲットビルドフォルダーをソリッドステートドライブ (SSD) に保存する
■IL2CPP Code Generation
Faster runtimeと Faster (smaller) buildsがある。
Faster runtimeは実行時の速度は速くなるがビルド時間が長くなる。
Faster (smaller) buildsはその逆。
■スクリプトの制限
一方で使用できないクラスなどがある。こちら
参照サイト
・API Compatibility Levelで、.Netのバージョン指定することでアプリサイズとビルド時間減らそう。
なお、Standardを使用した方が良い。
理由は以下である。
・.NET Standard は API サーフェスが小さいため、実装も小さくなります。 これにより、最終的な実行可能ファイルのサイズが小さくなります。
・.NET Standard はクロスプラットフォームのサポートが優れているため、コードがすべてのプラットフォームで動作する可能性が高くなります。
・すべての .NET ランタイムは .NET Standard をサポートしているため、.NET Standard を使用すると、コードはより多くの VM/ランタイム環境 (.NET Framework、.NET Core、Xamarin、Unity など) で動作します。
・.NET Standard では、より多くのエラーがコンパイル時に移動されます。 .NET Framework の多数の API はコンパイル時に使用できますが、一部のプラットフォームでは実行時に例外をスローする実装があります。
・C++ Compiler Configurationで、C++のコンパイラーの設定を行い、ビルド時間と実行時間を調整しよう
参照サイト、参照サイト
・Use incremental GCでインクリメンタルガベージコレクションをオンにし、GCスパイクを防ごう
参照サイト、参照サイト、参照サイト
・Target Devicesで、APK の実行を許可する対象デバイスを指定し、アプリサイズ・ビルド時間を減らそう
参照サイト
・Sustained Performance Modeで、サーマルスロットリングを調整してCPUの負荷を調整
オンにするとサーマルスロットリングを停止して、一定のパフォーマンスを維持する
オフにするとサーマルスロットリングをオンにする。
これにより、温度上昇に伴いCPUの性能が低下したり、温度上昇がなくなると性能が戻ったりするのでパフォーマンスが安定しない
参照サイト、参照サイト
・Prebake Collision Meshesがオンで、事前にMeshCollider計算しておくことで実行時のCPU負荷を減らす。ただ、ビルド時間やアプリサイズの増加する
参照サイト、参照サイト、参照サイト
・Keep Loaded Shaders Aliveをオンにすると、シェーダがアンロードされない
参照サイト
・ゲームの起動時にアセットをプリロードしておき、メモリに常駐するものをシンプルに管理する
マテリアル、テクスチャ、モデル、スクリプトなど
参照サイト、参照サイト
・コード サイズは、ディスク容量とランタイム メモリに直接影響を及ぼす。
Strip Engine Codeで、Unityエンジン機能側の使用していないネイティブコードの機能を削除し、ビルド時間・アプリサイズを削減しよう
ただ、IL2CPPのみで、いくつか注意が必要である
また、Managed Stripping Levelでマネージドコードのストリップするレベル感を変えることができ、レベルが大きくなるにつれて
アプリサイズが小さくなるが、その分削除されるコードが多くなるので不具合の原因も増えてしまう
参照サイト、参照サイト、参照サイト
・Script Call Optimizationをオンにすると、デバイスの例外処理を行わない
これによりパフォーマンスが上がる
ただ、IL2CPPだとパフォーマンスに影響がない
参照サイト、参照サイト
・Vertex Compressionでメッシュの頂点情報を圧縮して、ランタイムメモリとディスクサイズを削減
ただ、Meshの設定を有効・ReadWriteを有効にしていると無効になる
参照サイト、参照サイト
・Optimize Mesh Dataをオンにすることで、シェーダーで使用されていない頂点情報をビルド時に削除する
これにより、ディスクサイズ削減と実行時のパフォーマンスを良くする
参照サイト、参照サイト、参照サイト
・Texture MipMap Strippingをオンにして、不要なミップマップを削減し、ディスクサイズを削減しよう
参照サイト、参照サイト、参照サイト
・Metal Write-Only Backbufferで、デフォルトではないデバイスの向きでパフォーマンスを向上させます。
これにより、バックバッファに frameBufferOnly フラグを設定します。これは、バックバッファからの読み直しを防ぎますが、ドライバ-の最適化が可能になることもあります。iOSのみ
参照サイト
・Force hard shadows on Metalをオンにすると、影をポイントサンプリングすることで影の品質は落ちるが、パフォーマンスがよくなる。iOSのみ
参照サイト、参照サイト
・Memoryless Depthで、深度テクスチャをCPU/GPUのメモリに格納しないことでメモリ量を削減
ただ、このレンダーテクスチャに読み書きができない。iOSのみ
参照サイト、参照サイト
・VSync Countで垂直同期をオンかオフにする
参照サイト、参照サイト、参照サイト
・Texture Qualityでミップマップ解像度が適用される優先順位を調整して、 GPU メモリと GPU 処理時間が少なくしよう
ただし、ミップマップを使用している時に有効となり、ミップマップを使用していないとフル解像度となる
参照サイト
・Texture Streamingで、ミップマップのデメリットであるメモリ消費量を削減
ただ、CPU負荷とロード遅延で見た目が悪くなる場合がある
参照サイト、参照サイト
・Particle Raycast Budgetでエフェクトのコリジョン判定の正確さ調整
正確さを求めていないなら少ない数値でCPUのパフォーマンスをアップ
参照サイト
・Shadowmask Modeで、Lighting ModeがShadowmask の時(他のモードは変化なし)の影の挙動やパフォーマンスを調整しよう
Distance Shadowmaskは、動的オブジェクトから静的オブジェクトへの影がつき、Shadow Distance内では、静的オブジェクトはリアルタイムのシャドウで(動的オブジェクトはリアルタイムシャドウ)、Shadow Distance外では、静的オブジェクトはベイクシャドウになる(動的オブジェクトの影は消える)。
Shadowmaskは、動的オブジェクトから静的オブジェクトへの影がつかず、Shadow Distance内では、静的オブジェクトはベイクシャドウで(動的オブジェクトはリアルタイムシャドウ)で、
Shadow Distance外では、静的オブジェクトはベイクシャドウになる(動的オブジェクトの影は消える)。
参照サイト、参照サイト
・Async Asset Upload(AAU)の、Time Slice、Buffer Sizeを調整してテクスチャ・メッシュのロード時のカクツキを防ぐ
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト
・非同期でアンマネージドで画像を読み込ませることでローディングのかくつきを減らす
参照サイト、参照サイト、参照サイト
・Maximum LOD Levelで、最高LODを調整し、ストレージとメモリ使用料を削減
参照サイト
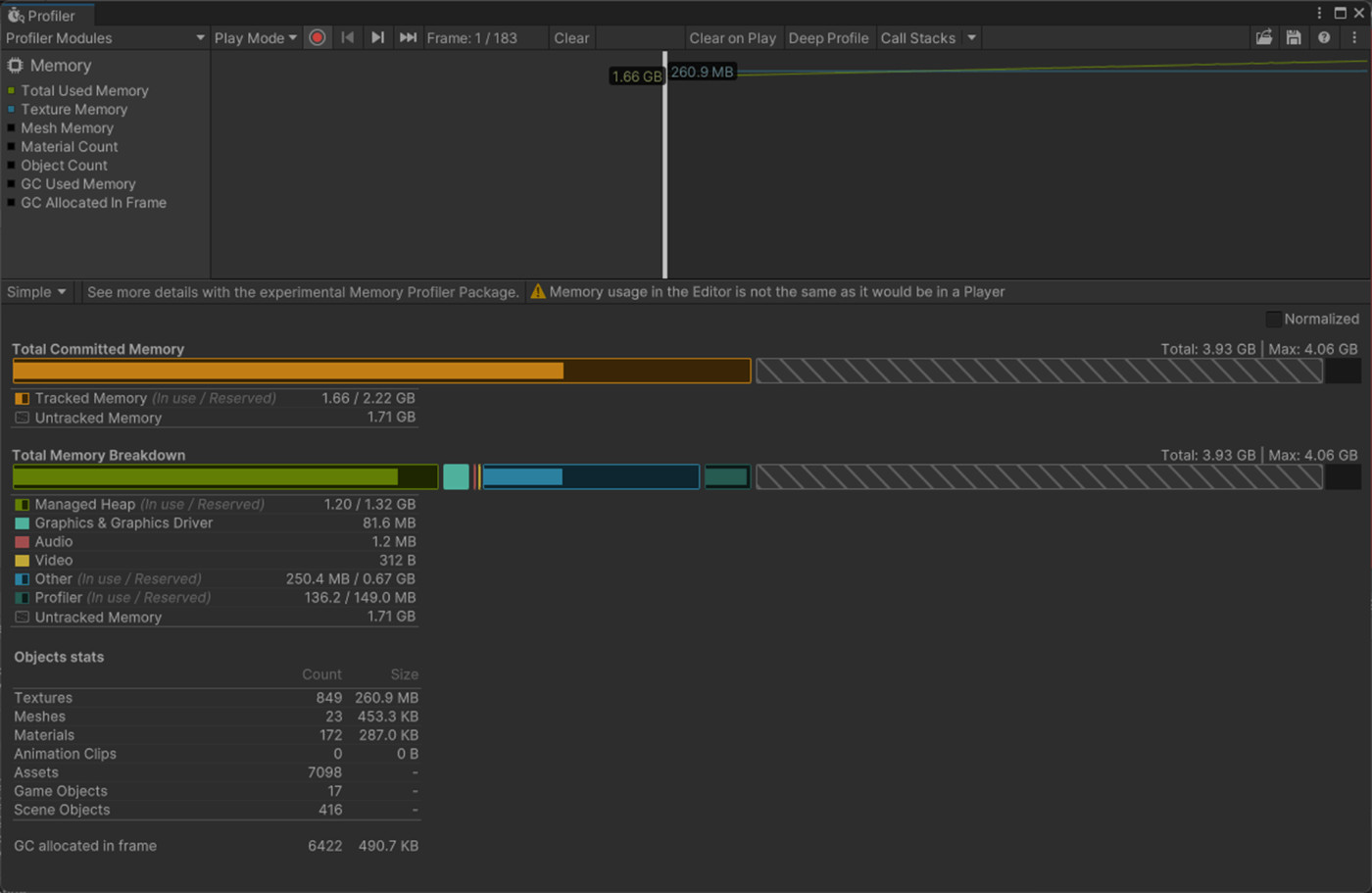
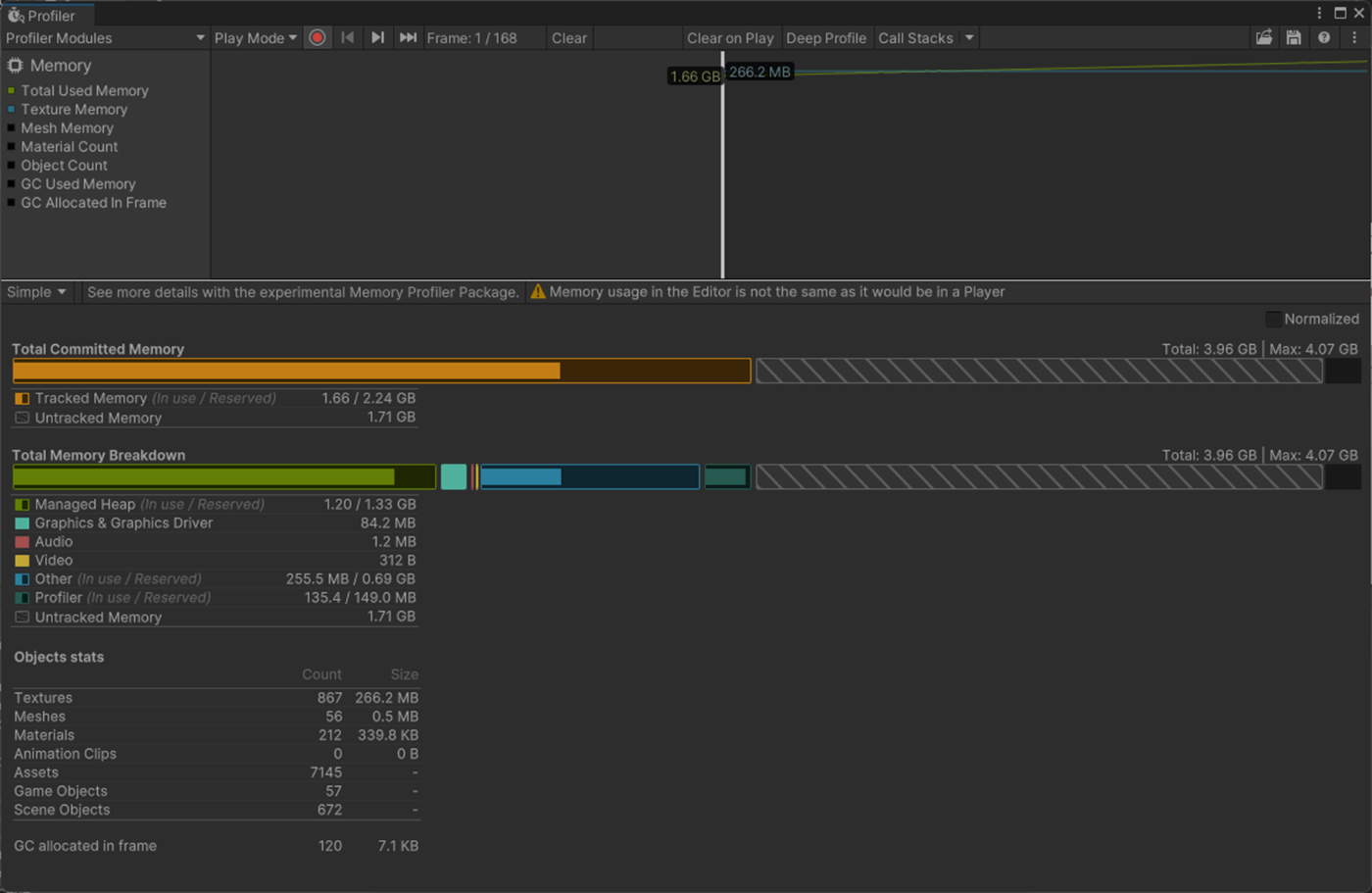
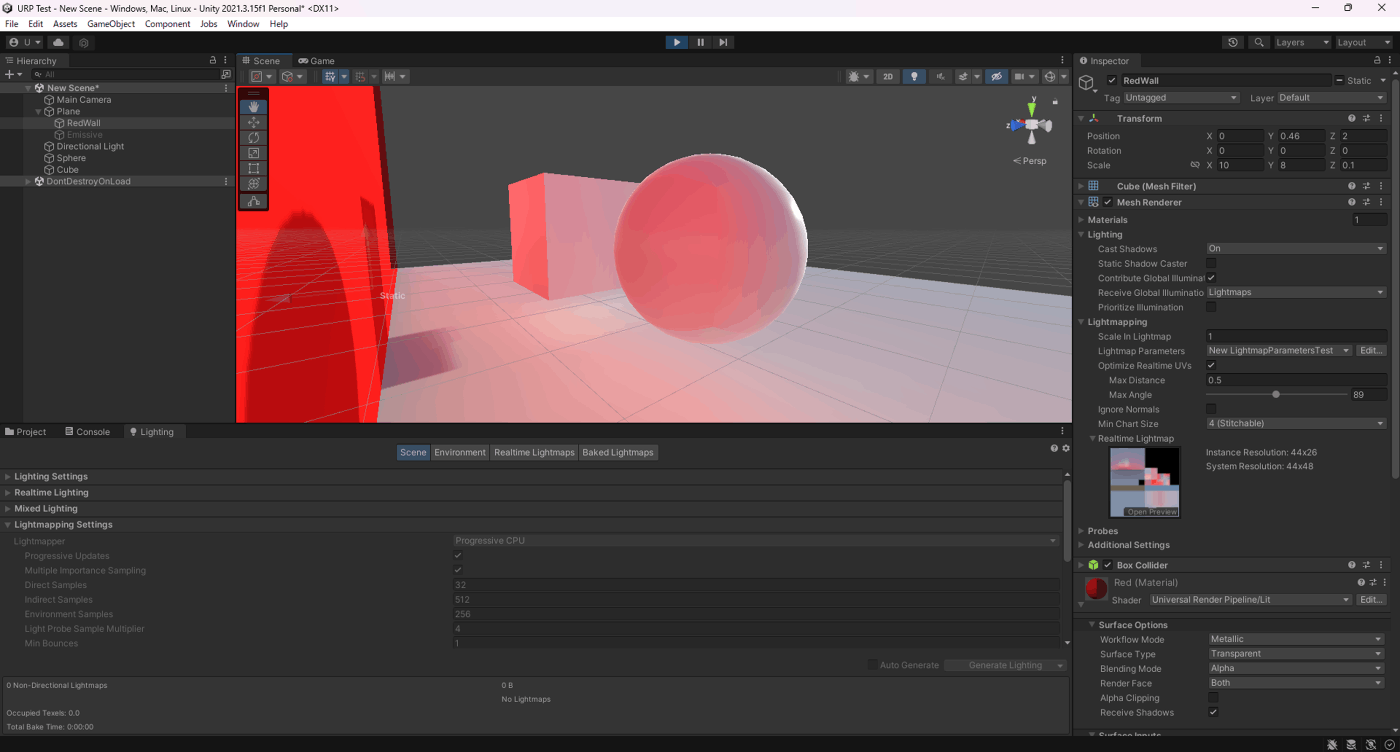
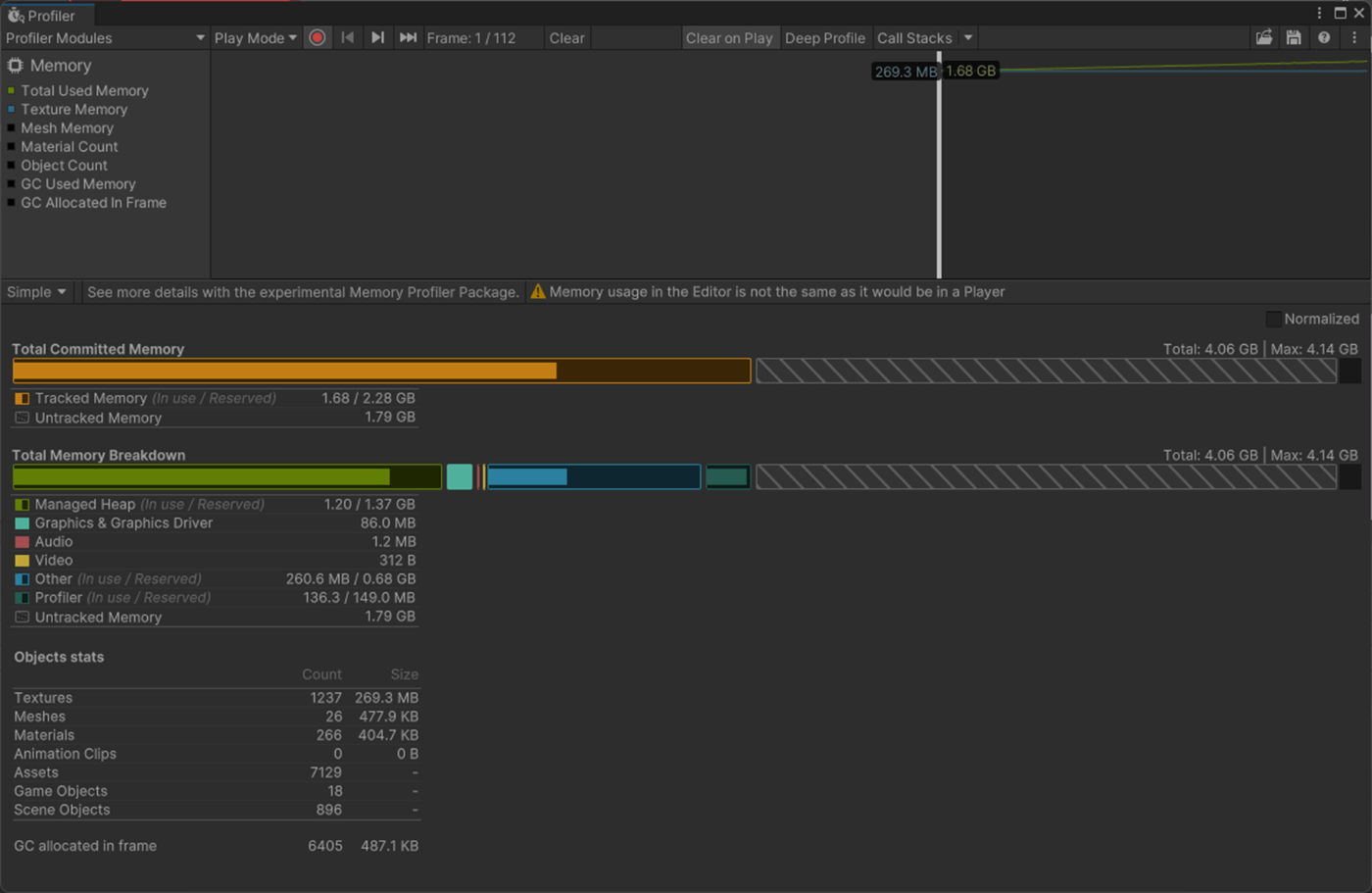
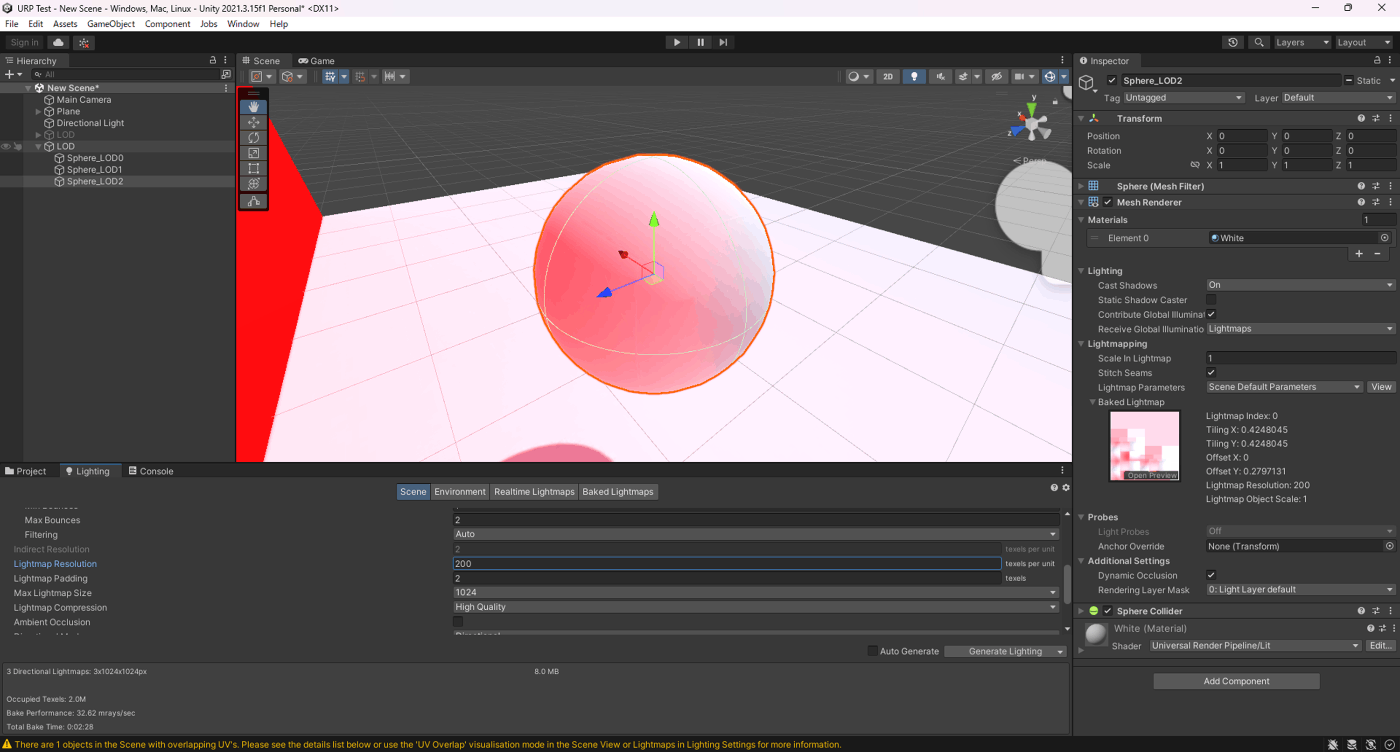
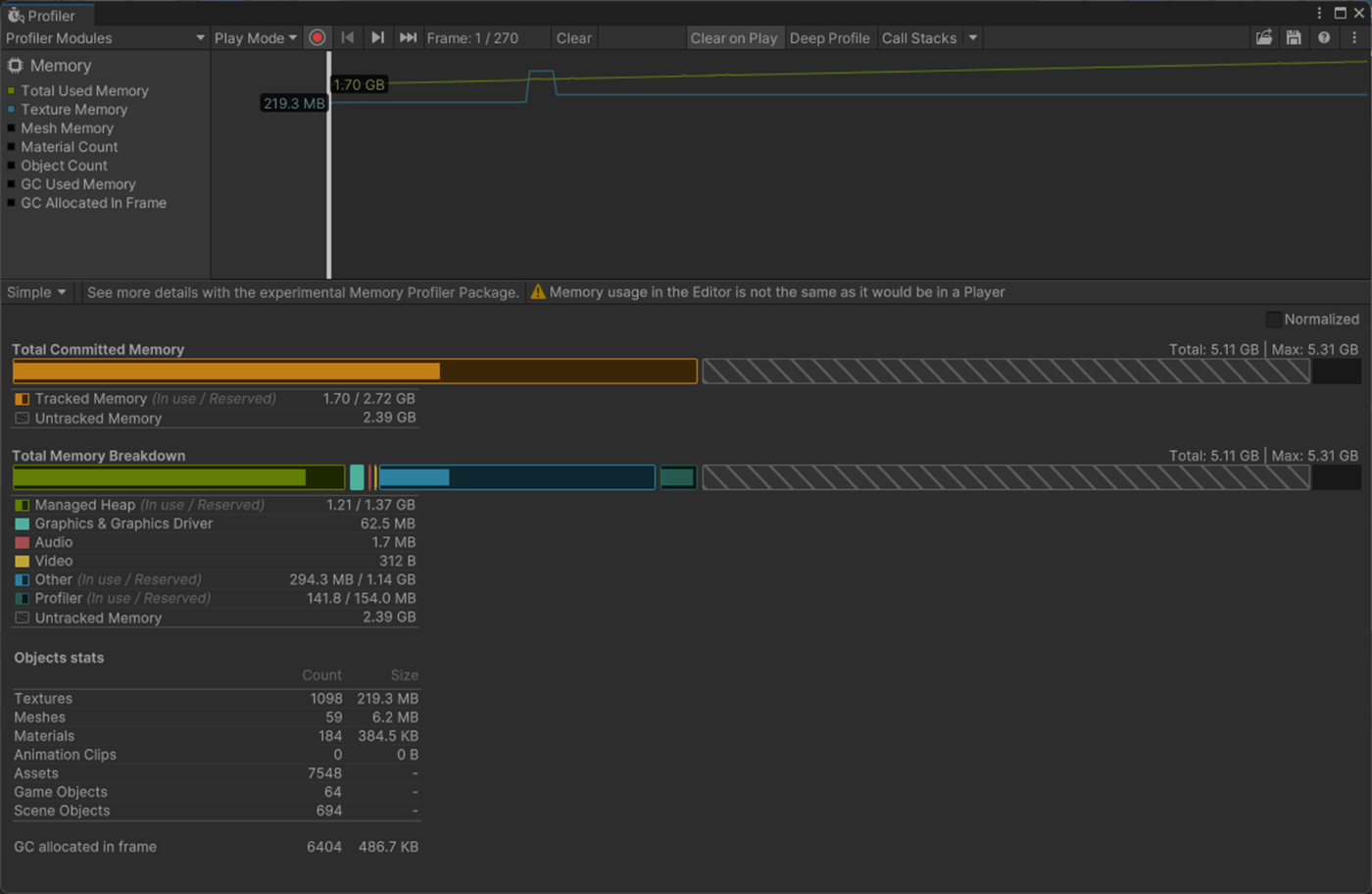
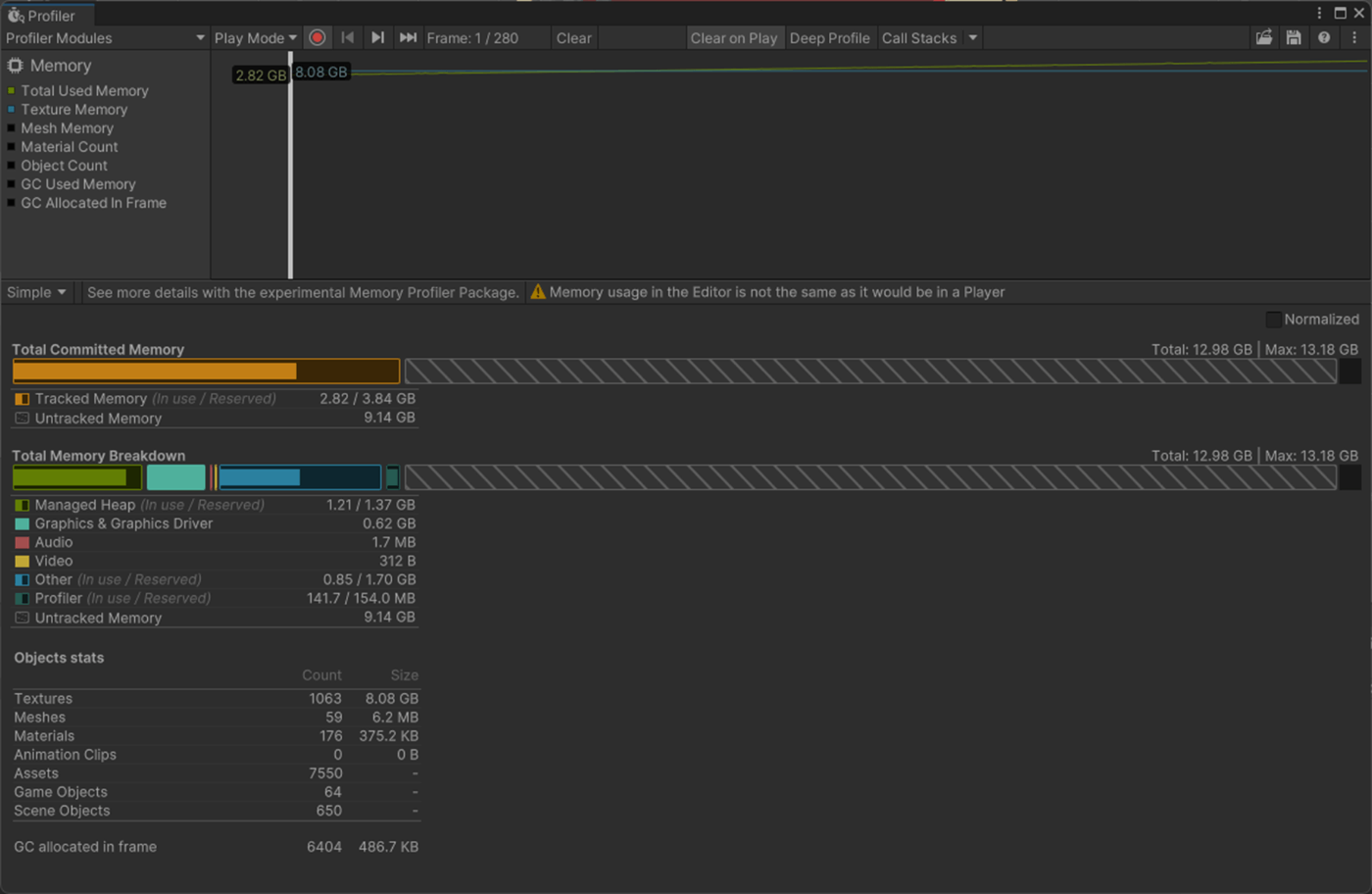
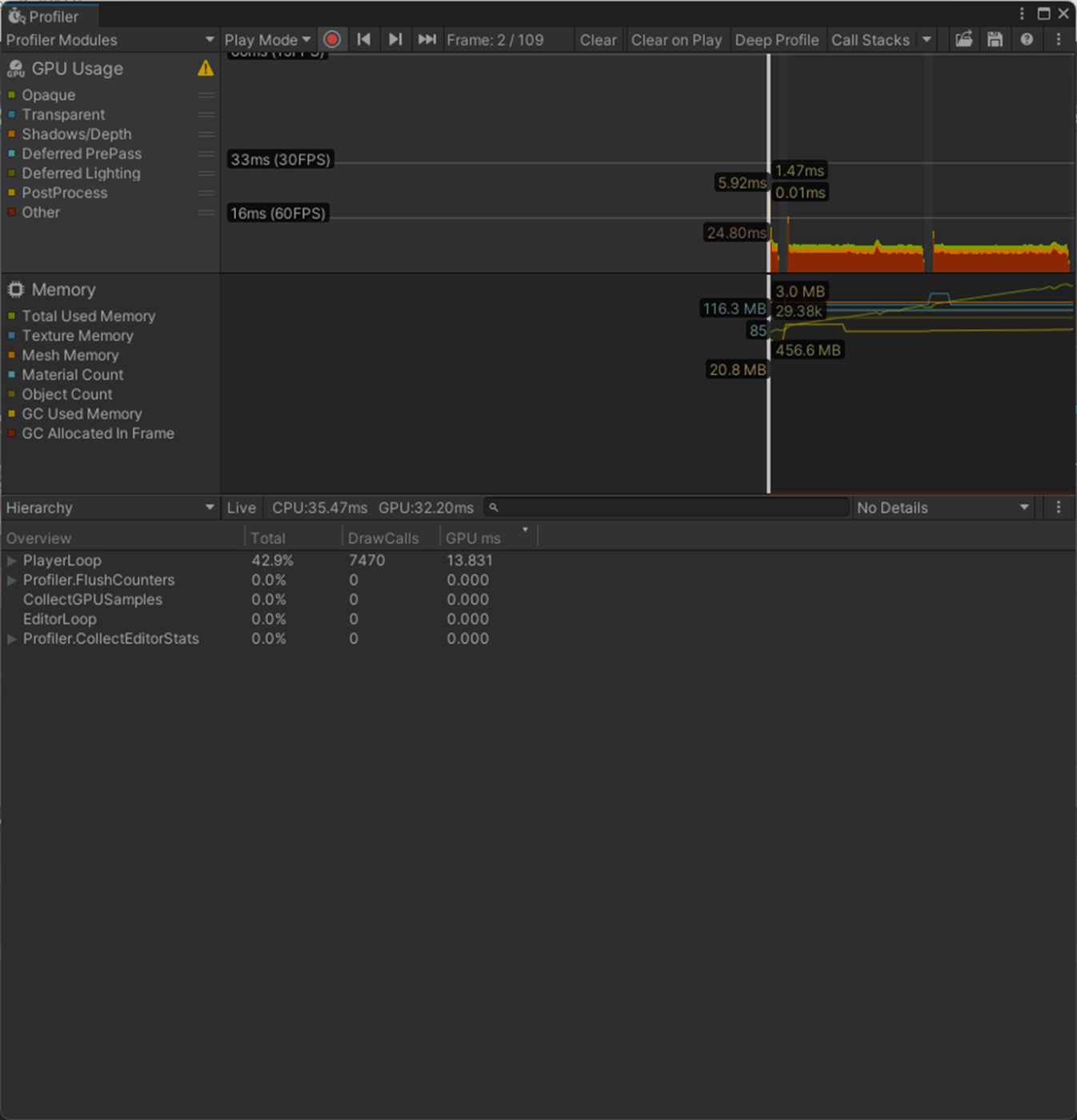
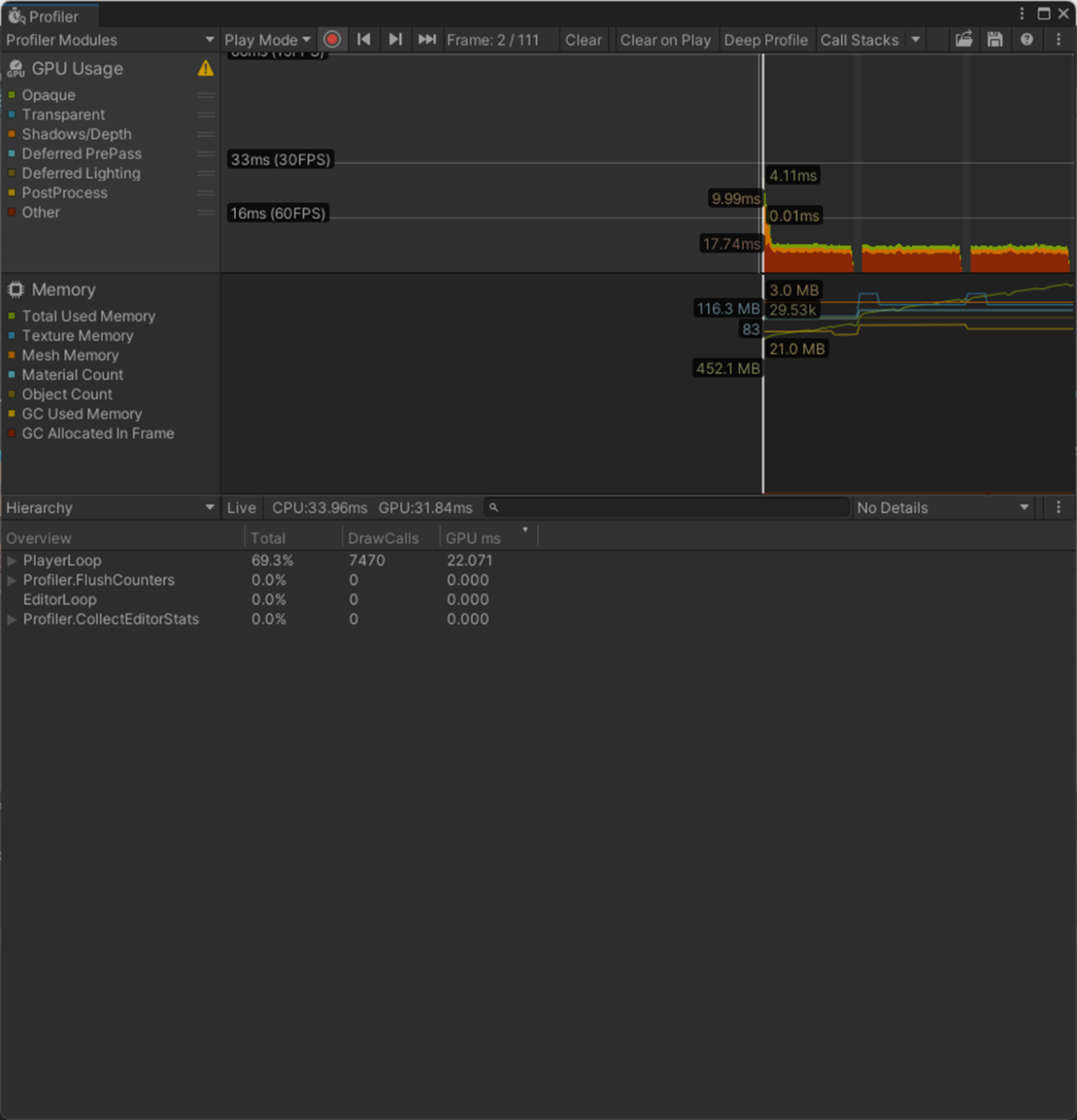
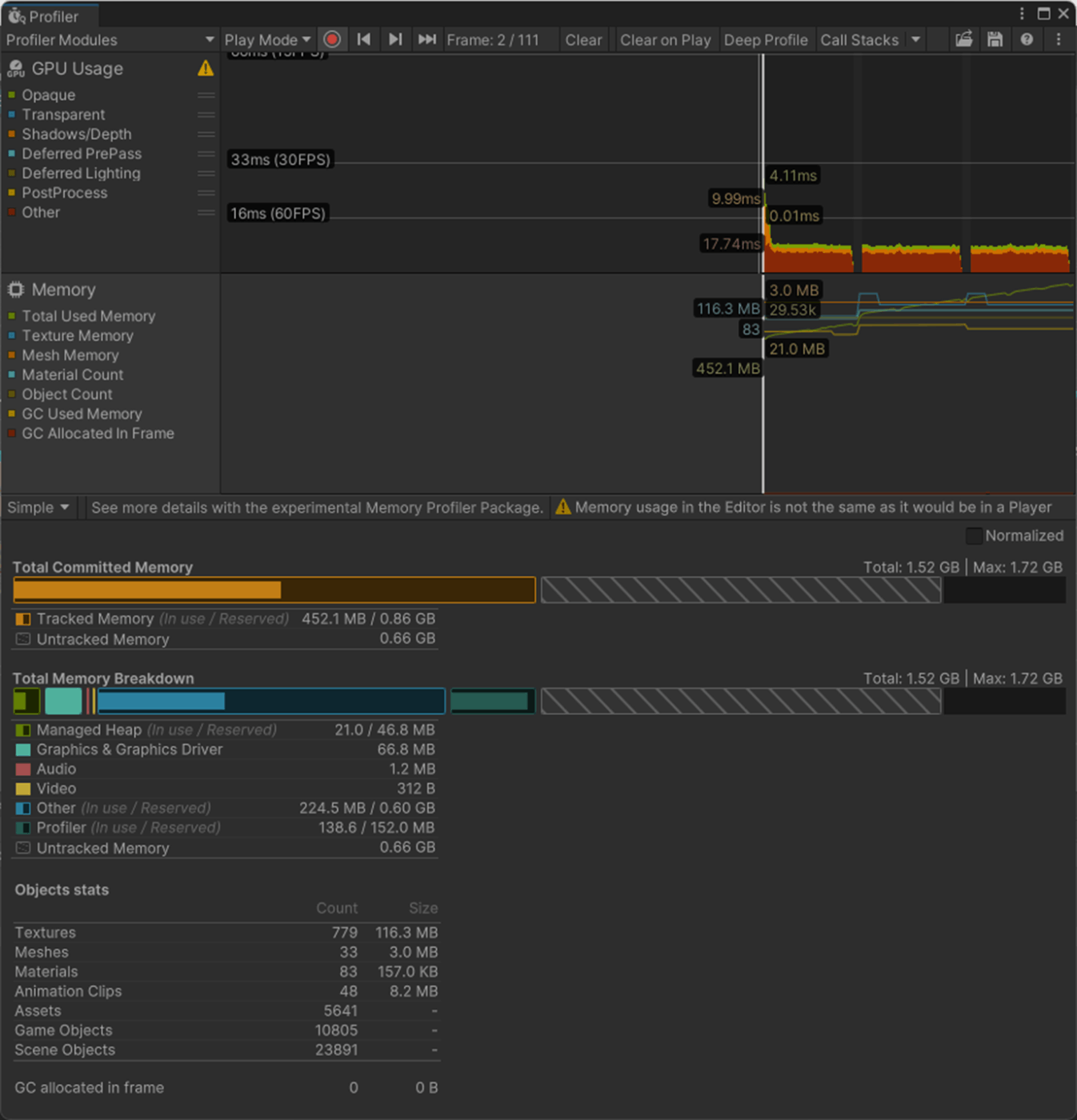
・Skin Weights、Max Bones/Vertexで、頂点が影響を受けるボーン数を調整し負荷を削減使用
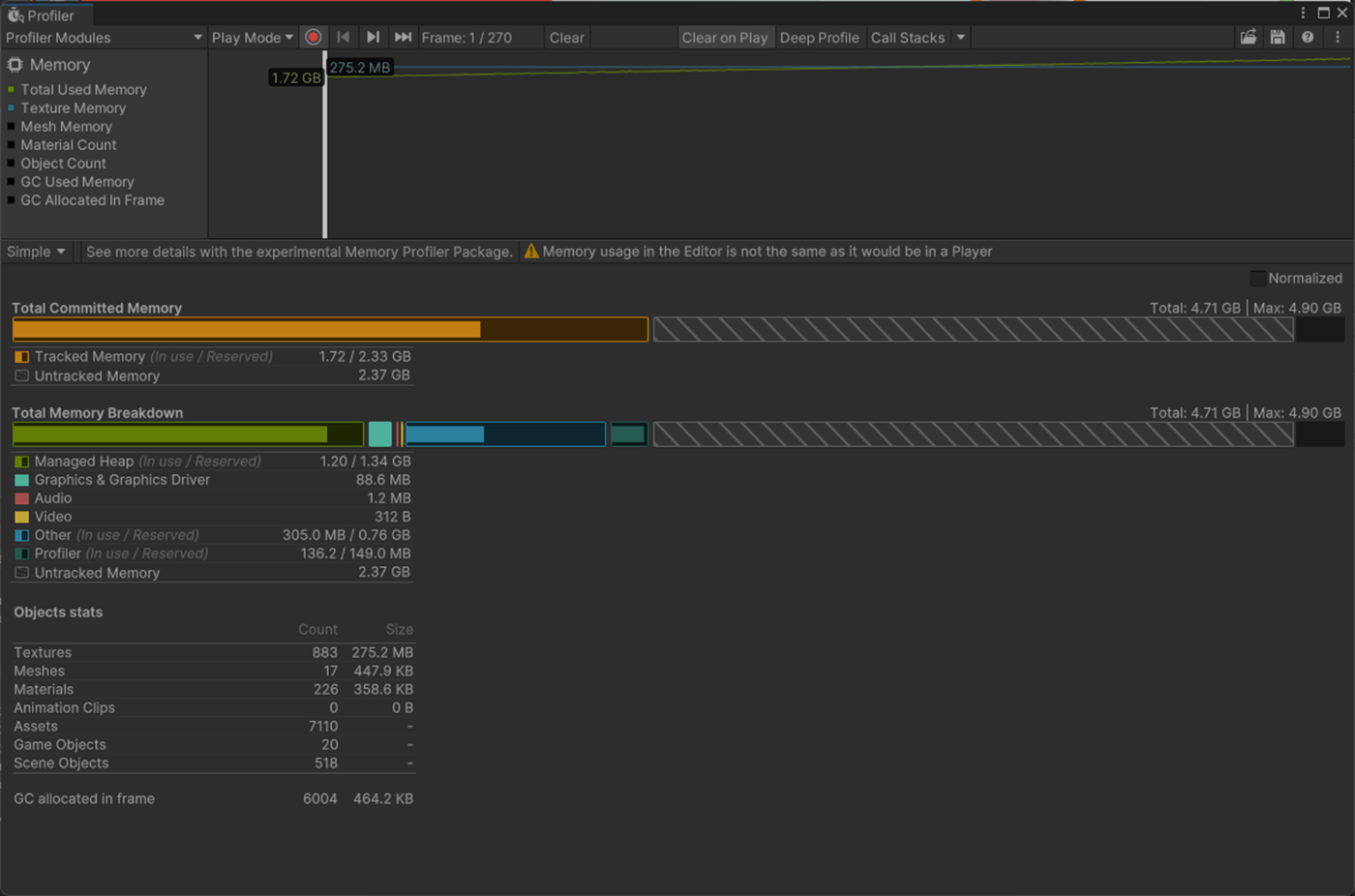
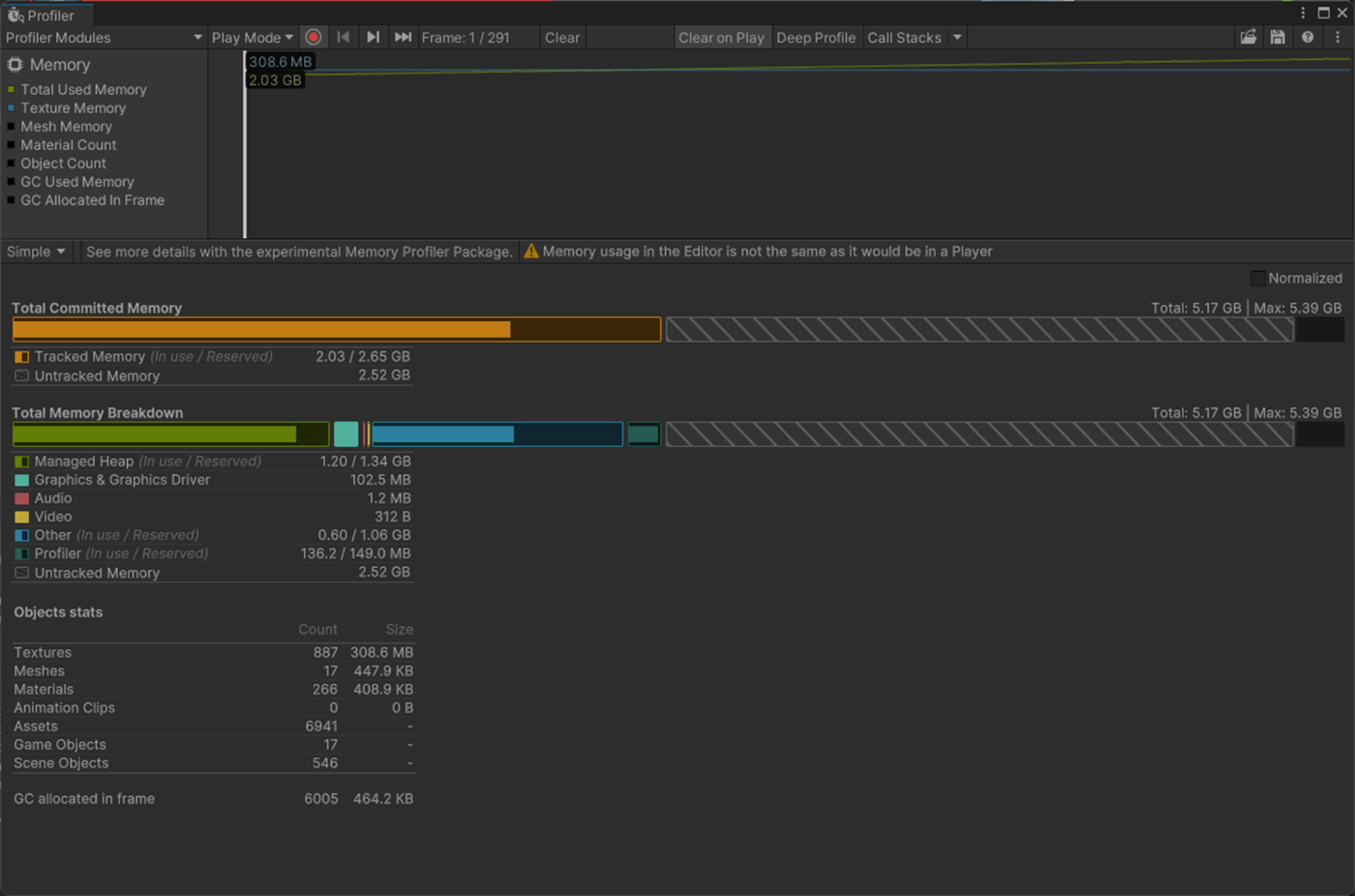
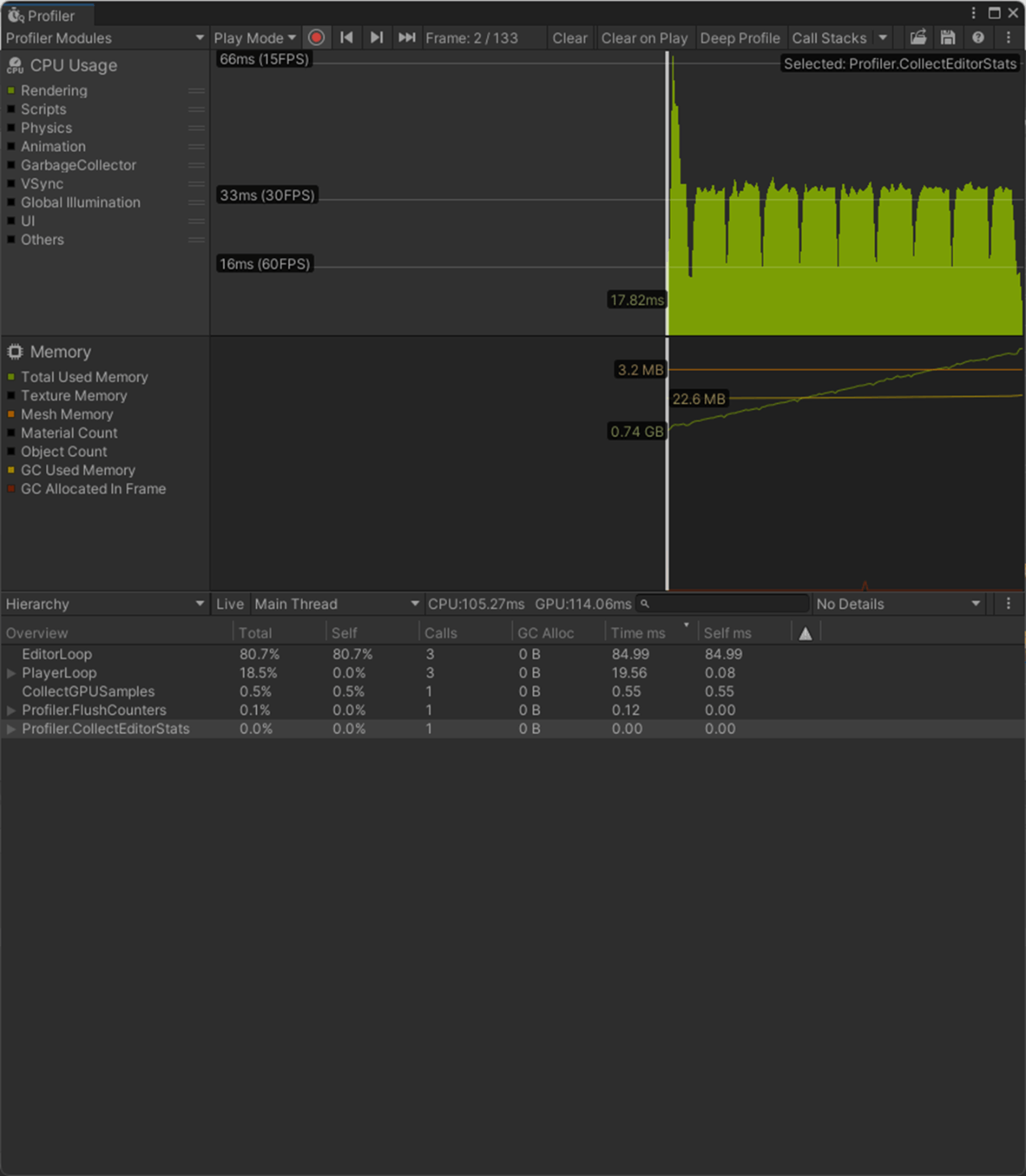
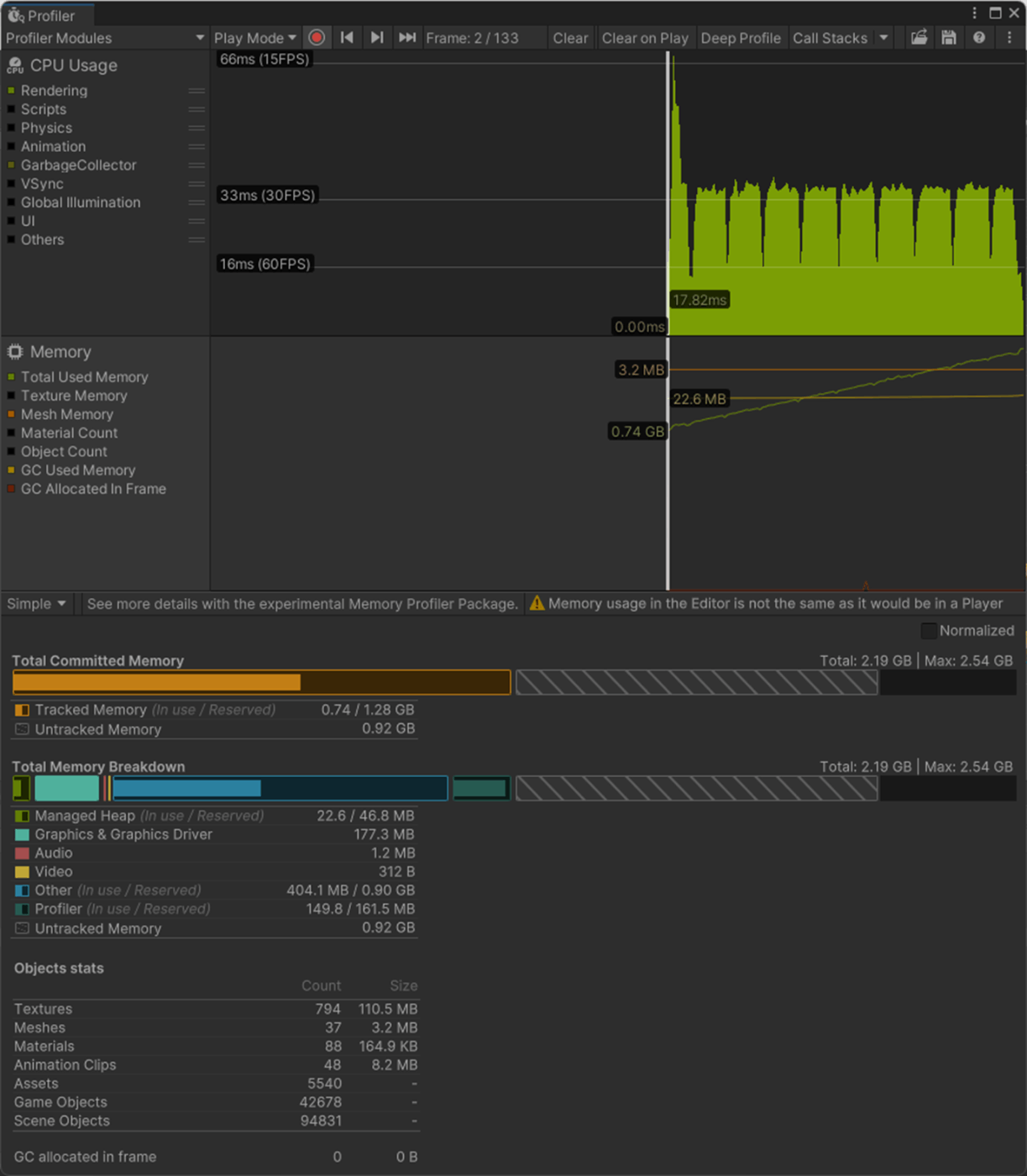
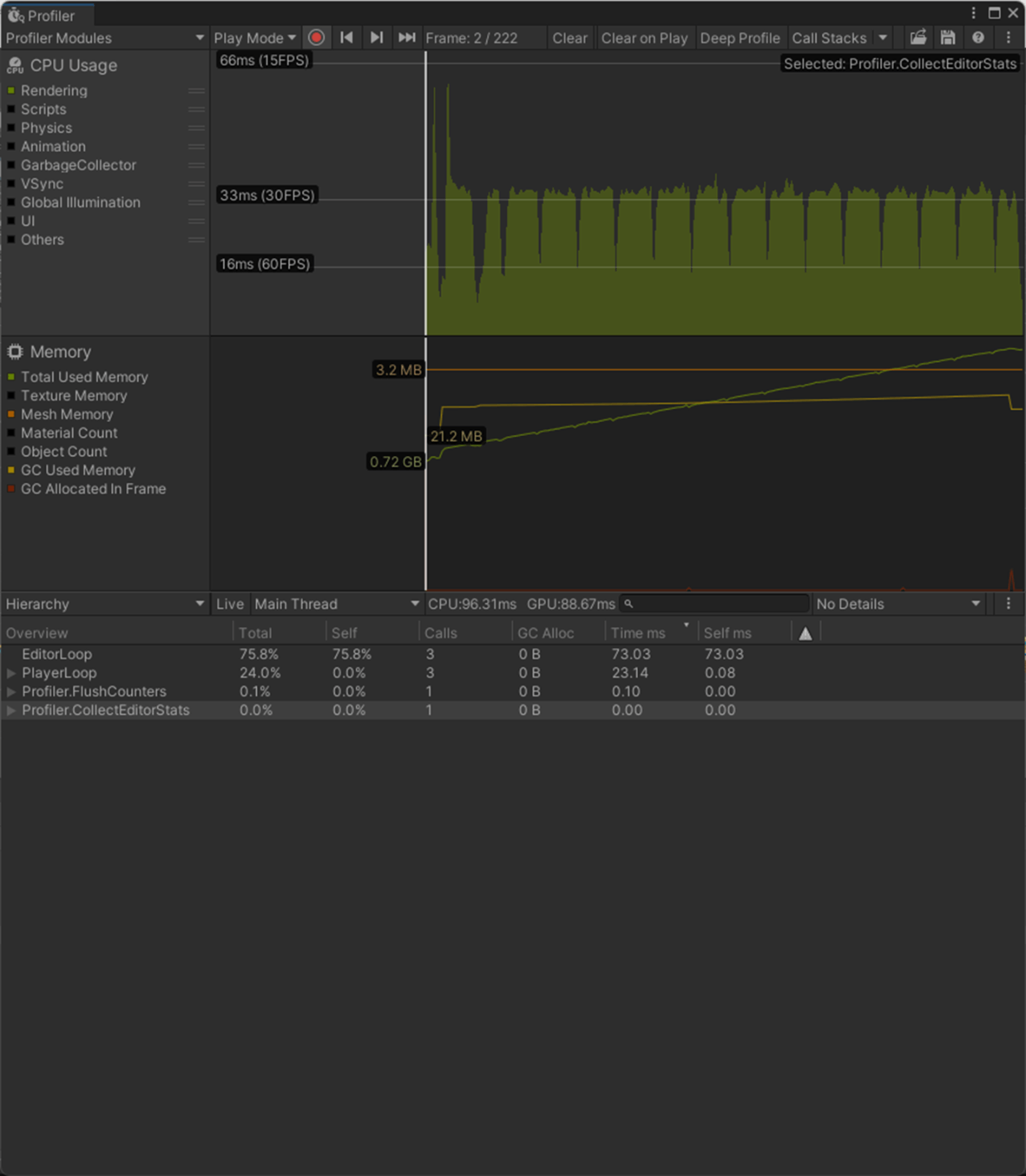
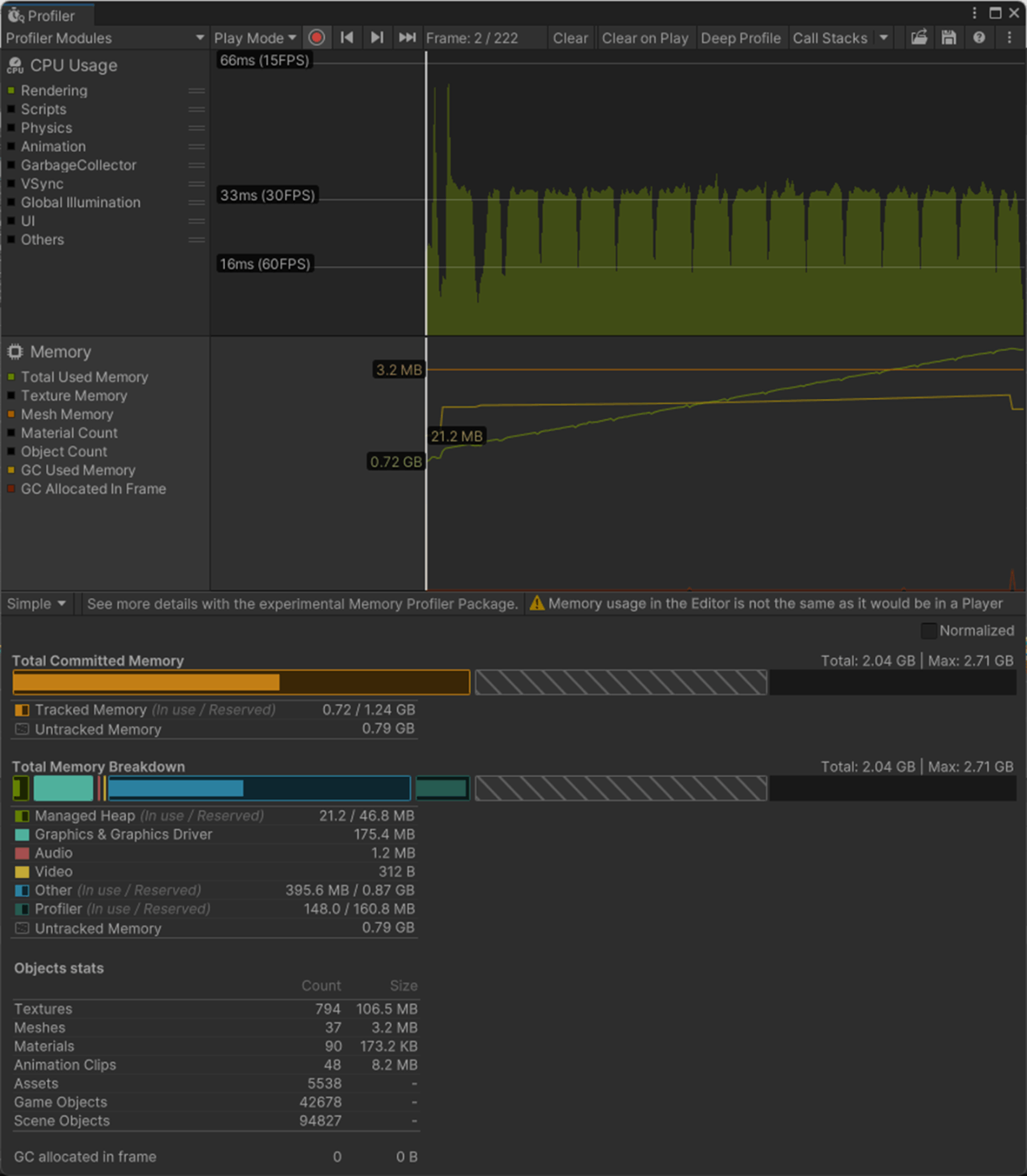
一応実験してみた。
以下のようにいくつかオブジェクトを置いて実験してみた。
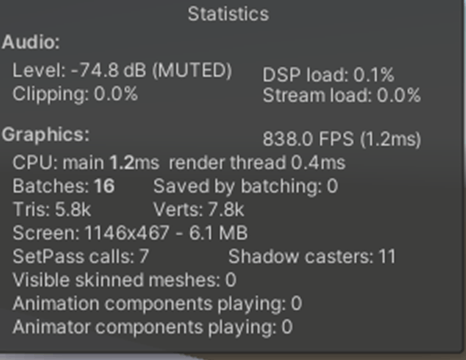
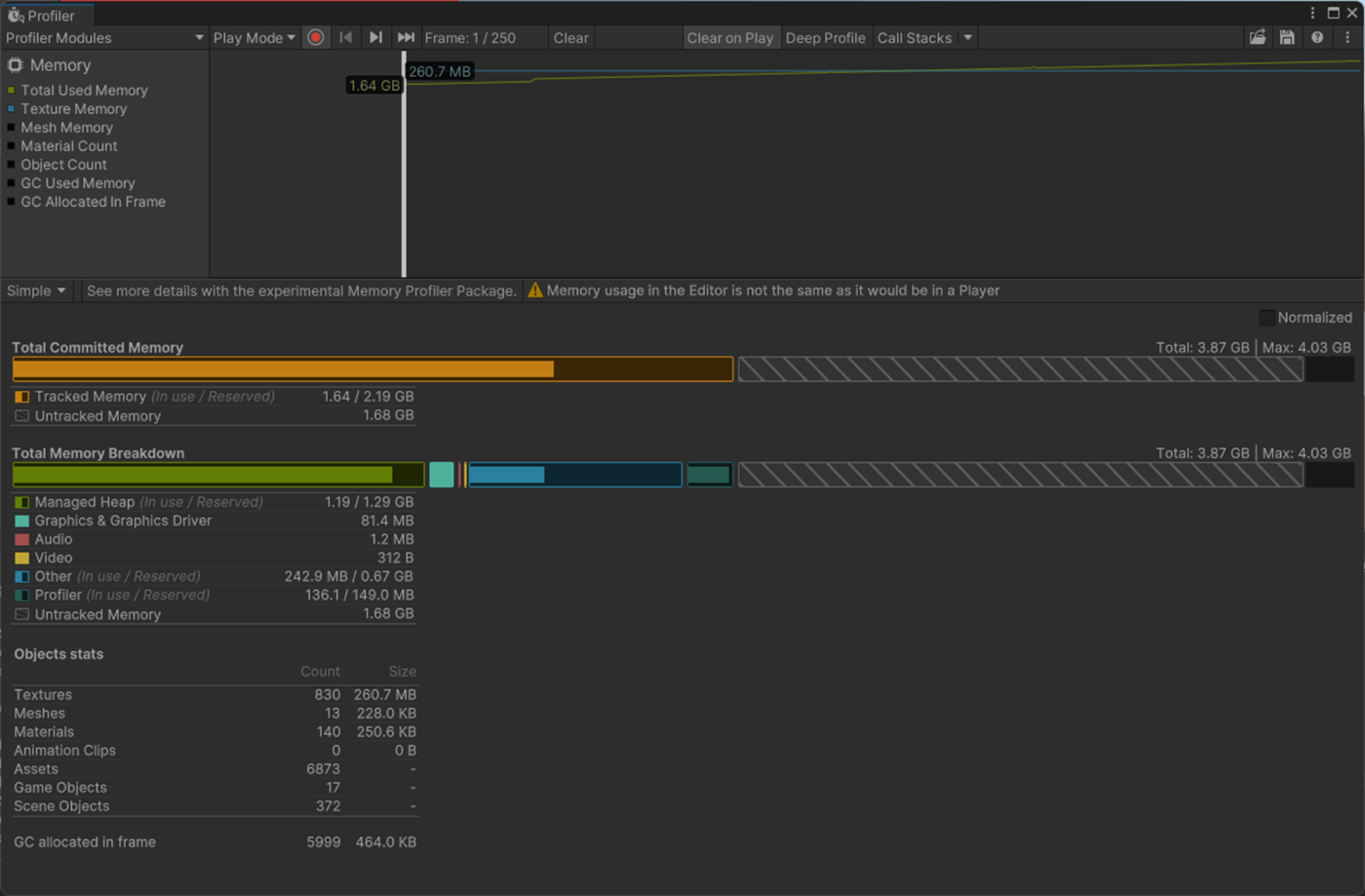
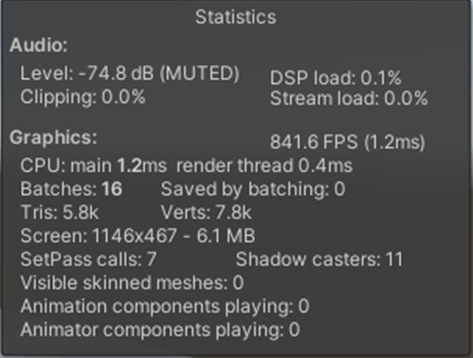
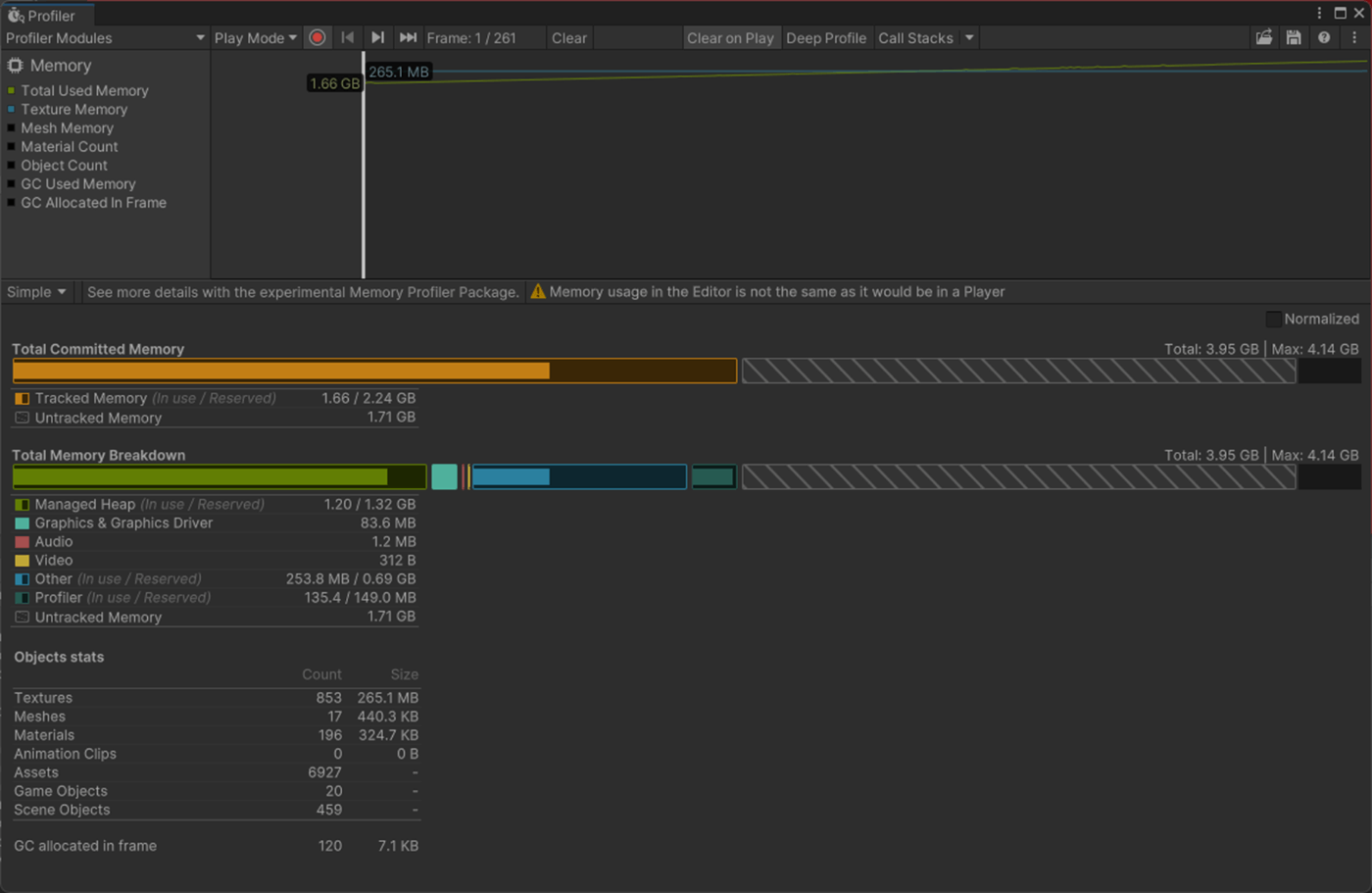
Max Bones/Vertexが1のほうが、CPUとGPUで負荷が削減されていることが分かる。
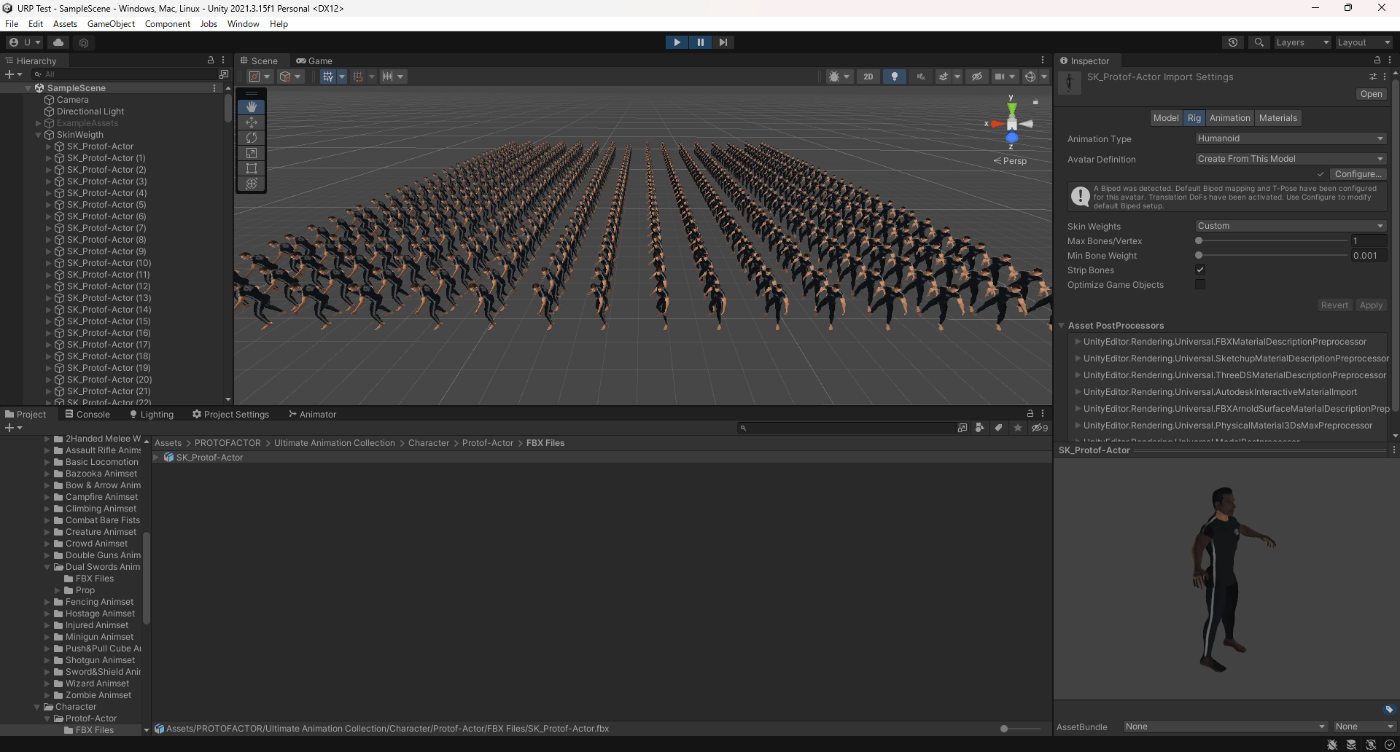
①Max Bones/Vertexが1
1フレーム
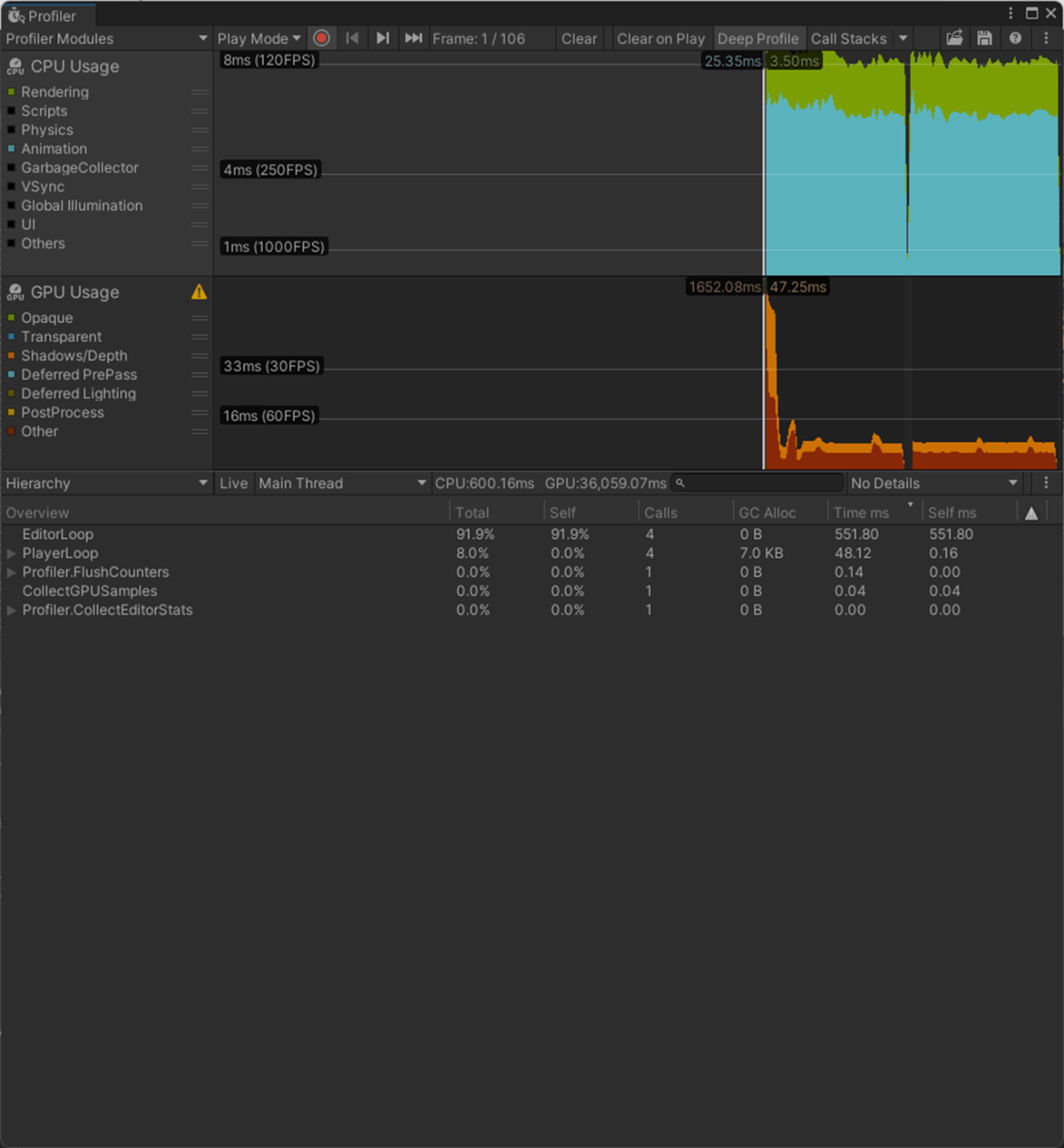
2フレーム
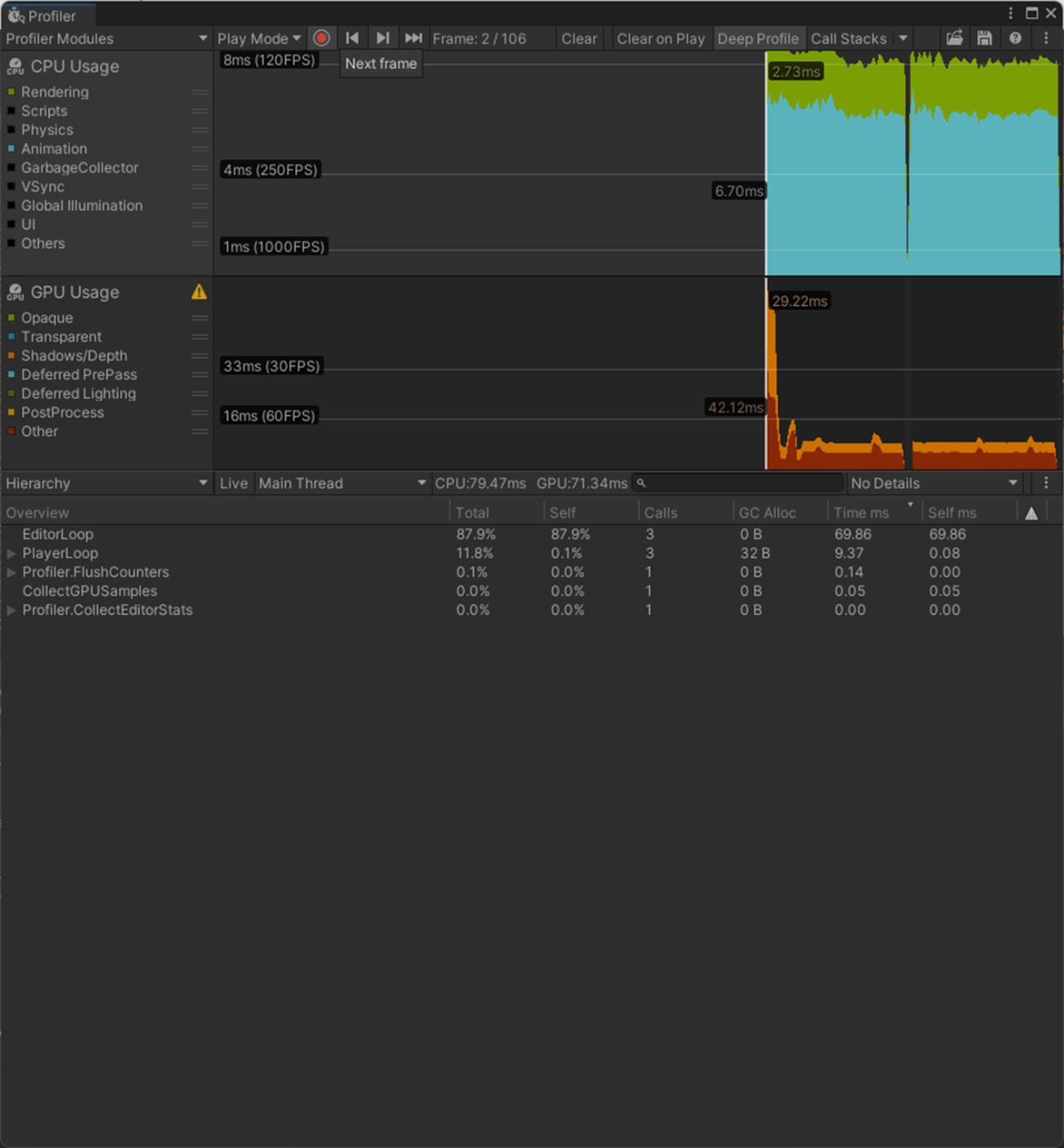
②Max Bones/Vertexが16
1フレーム
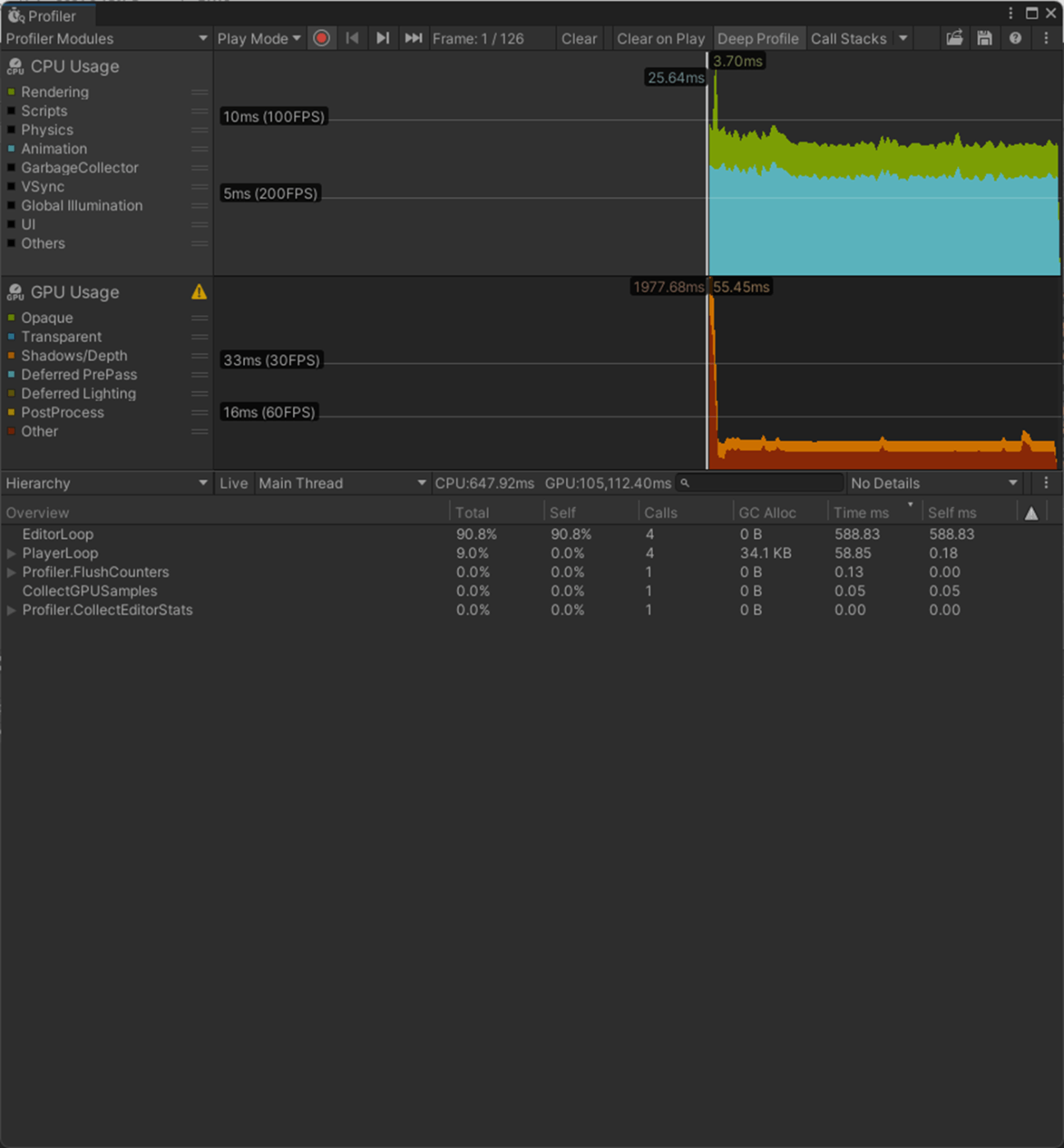
2フレーム
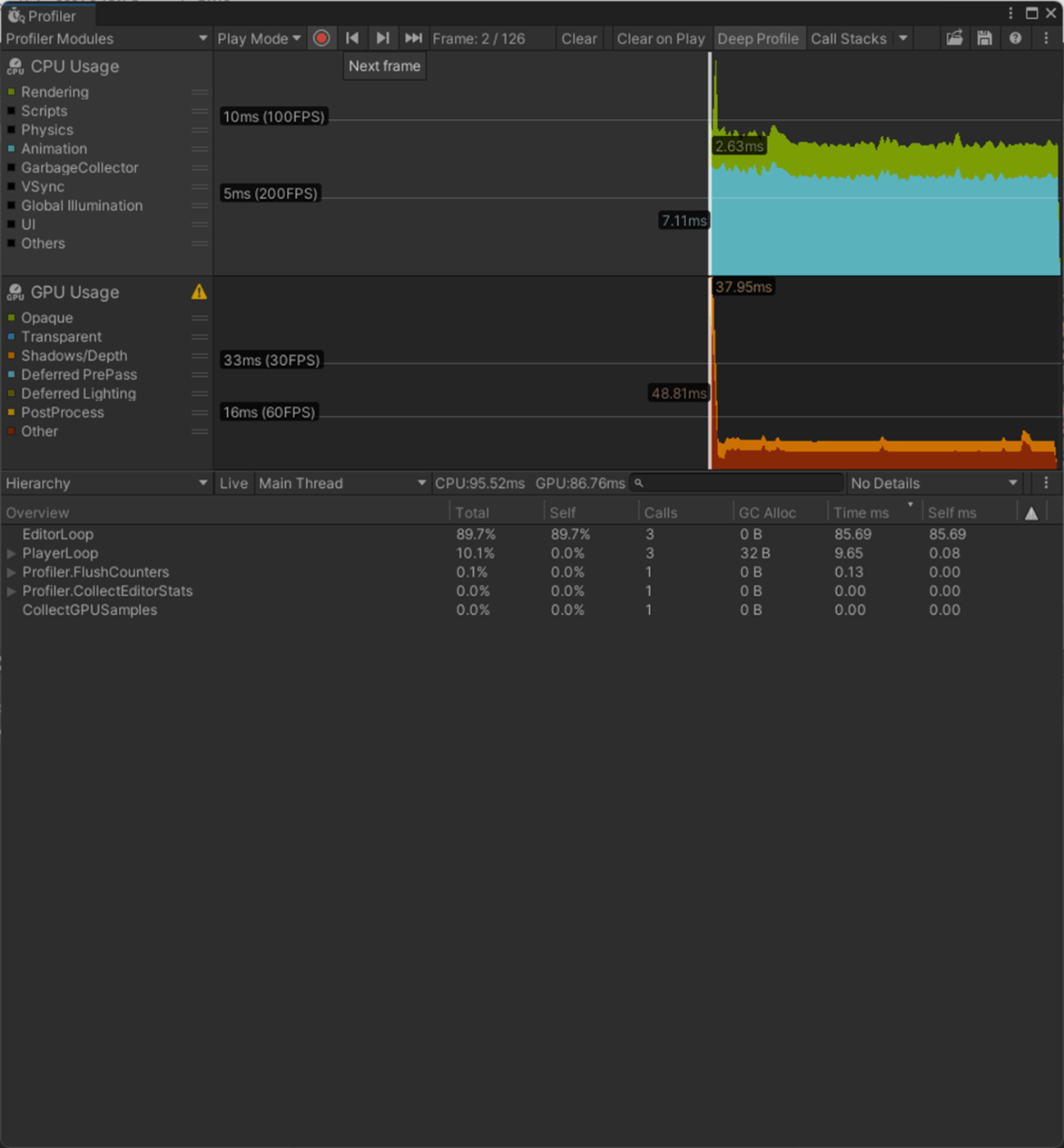
Skinned Mesh Renderer のQualityでランタイムでも、頂点に影響を与えることができるボーンの最大数を設定できる。
また、Project SettingsのSkin Weightsでグローバルに設定できる。
参照サイト、参照サイト、参照サイト
・Fixed Timestepで、FixedUpdateの間隔を調整してCPUの負荷を下げよう
物理演算多用するゲームでは、フレームレートが下がるとFixedUpdateを呼び出す回数が増えるためさらにフレームレートが下がる
フレームレートと同じにしておくと見た目が良くなる
参照サイト、参照サイト
・Maximum Allowed Timestepで、フレームレートが低下した際のFixedUpdateを呼び出す回数を制限し、CPUの負荷を軽減しよう
ただ、物理演算処理が実行されなくなり正確な結果が得られなくなる可能性がある
参照サイト
・Maximum Particle Timestepで、パーティクル処理の間隔を調整してパフォーマンスをあげよう
参照サイト
・メモリアロケーターをカスタマイズしてパフォーマンスを向上させよう
参照サイト
・GCを無効化して、CPUの負荷を下げよう。
場面としては、パフォーマンスが重要な部分で、メモリへの割り当てが全て完了し、以降割り当てが発生しないケースがおすすめ
参照サイト
・Animation.DestroyAnimationClip、Animation.AddClip、Animation.RemoveClip、Animation.Clone、Animation.Deactivate
これらのメソッドは、ランタイムで行うと大量のリソースを使用するのでなるべく避ける
参照サイト
・AssetBundle の読み込みが完了していないと、メインスレッドでストール (stall) が発生し、読み込み操作が完了するのを待機してしまう
参照サイト
・バッチングされない原因
UI-ProfilerのBatch Breaking Reasonや、
Frame DebuggerのWhy this draw call can't be batched with the previous one
で原因が表示されているのでそれをもとにバッチングされるように修正する
参照サイト、参照サイト、参照サイト
・Virtualize Effectで、CPU負荷を減らし、Virtualize Effectオフにする
参照サイト
・シーンテンプレートで効率的にゲーム開発しよう
参照サイト
・ShaderのSorting Priorityを調整して、オーバードローを防ぐ
参考サイトの1時間18分〜、参考サイト
・PartcleSystemのGPUInstancingオン
通常、PartcleSystemのエフェクトは、CPU側でメッシュを結合させてその情報をGPUへ送りエフェクトを描画させている。ただそれだとCPU側の負荷が掛かってしまう。なのでPartcleSystemのGPUInstancingオンにすることでそのメッシュの結合をせずとも、エフェクトを描画できCPU側の負荷が減るというもの。
WorkerThreadのParticleSystem.GeometryJobというのがProfier上であれば、CPU側でメッシュを結合していることを意味している。なのでこちらの処理が重ければPartcleSystemのGPUInstancingオンにすることでCPU側の負荷を減らせる。
具体的なオンの仕方は、RenderModeがMeshの時かつ、Enable Mesh GPU Instancingにチェックを入れることで実現できる
参照サイトの19分40秒~
・Dynamic Resolution(動的解像度)
こちらをオンにすることでGPUの負荷を検知して、解像度の見た目が変にならない程度に変えて、GPU負荷を減らしフレームレートを安定させることができる。
またいくつか特徴がある
①カメラごとに設定できる
②レンダーテクスチャごとに設定ができる
③解像度が変更された際に大きな CPU パフォーマンスオーバーヘッドが発生することはない
④Unityエディタ上ではテストが出来ない
⑤UIには適用できない
⑥スマホだと、Android (Vulkanのみ)、iOS対応
⑦GPU 負担が大きい部分を見越して、FrameTimingManager を使用してGPU負荷を計測し、スクリプト上から解像度を変更することが可能。ただ、FrameTimingManagerは、スマホだと、iOS(Metal)は対応しているが、Andoridでは一部のモバイルGPUでは対応していないとのこと
実際にやってみた。
はまったことは、WindowsだとDirextx12しか対応してないので、それを設定しないといけない
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト
・オンデマンドレンダリングで、描画処理をスキップさせることで、パフォーマンスや省電力性・発熱防止を大幅に向上できる。
従来は、Application.targetFrameRateを利用して対処してきたが、これだと入力判定など色々な機能に影響してしまい、少々使いずらかった
しかし、オンデマンドレンダリングだと、入力判定などを行うPlayLoopはフレームレートを維持しつつ、レンダリングスキップすることが可能。
使いどころとしては、ローディング画面や一時停止UIなど画面の更新が遅れても問題なさそう場面、ターンゲーム性のゲームで相手のターンなどに適用したりするのがおすすめ
参照サイト、参照サイト
・テクスチャのRead/write を無効にする
有効だとCPUのメモリにもテクスチャのデータを格納するためメモリ容量が増えてしまう
なので、C#のスクリプトからランタイムでテクチャを参照したい場合以外は、Offにした方が良い
参照サイト、参照サイト
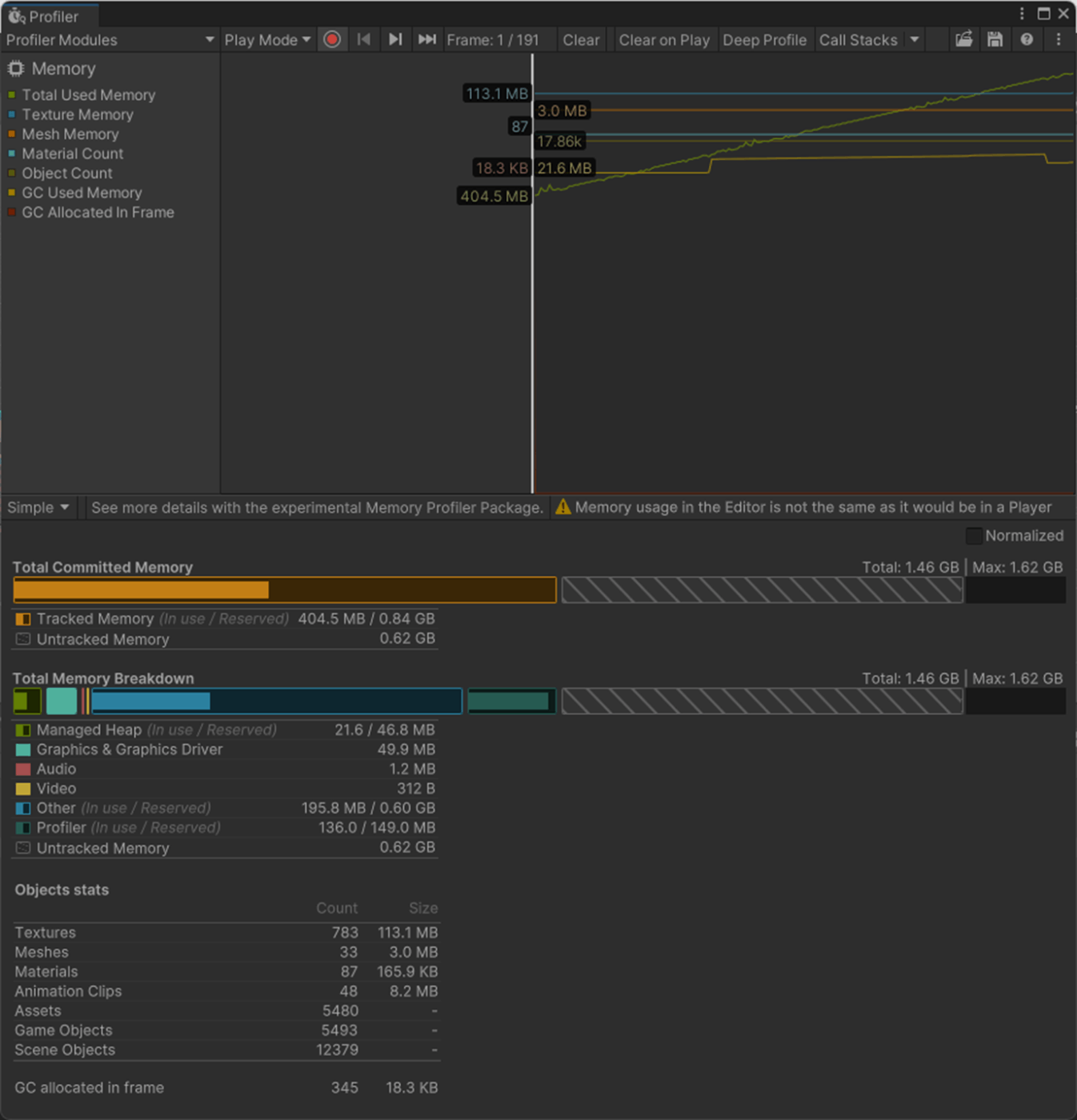
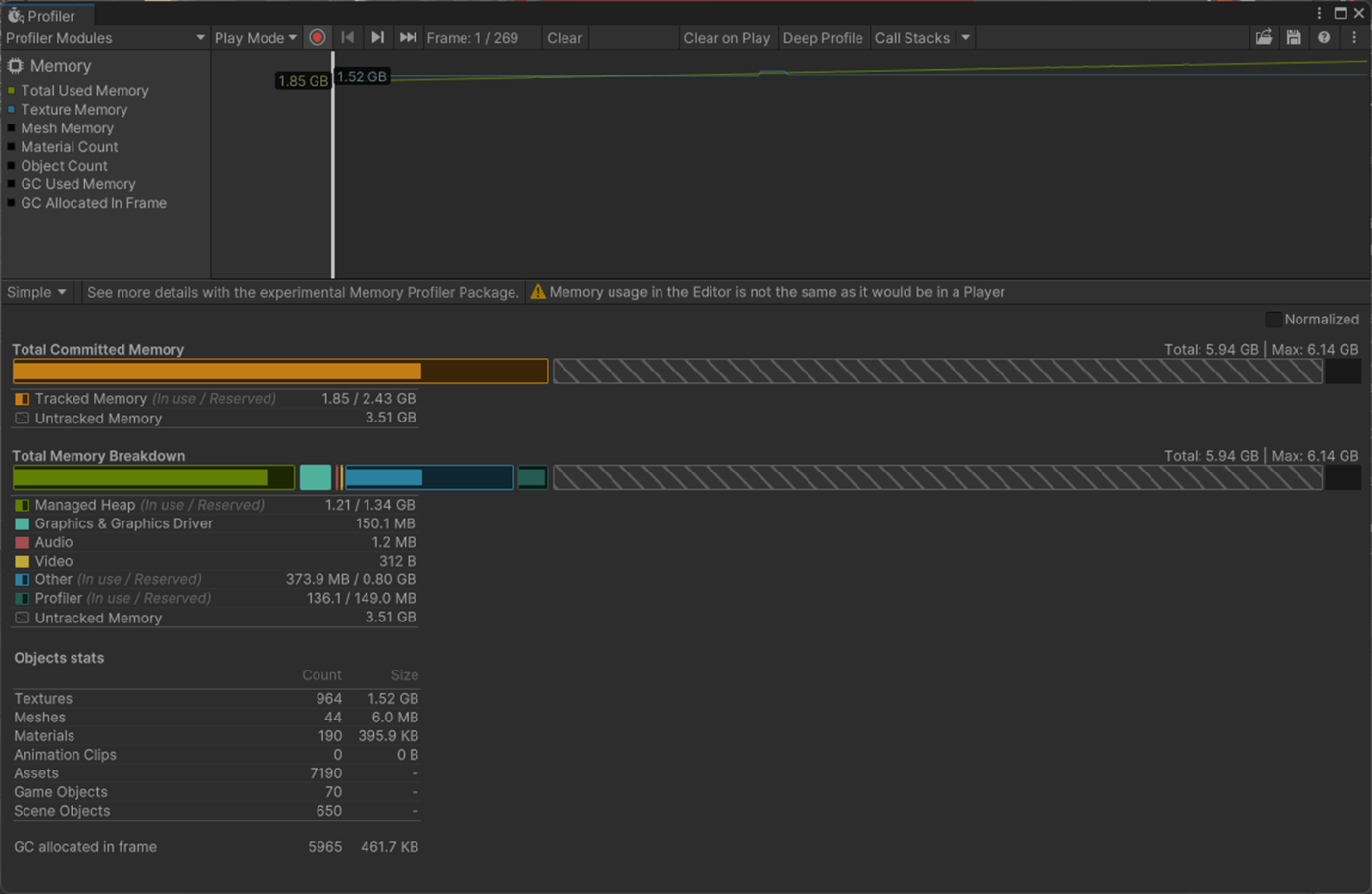
・モデルのRead/write を無効にする
有効だとCPUのメモリにもモデルのデータを格納するためメモリ容量が増えてしまう
なので、C#のスクリプトからランタイムでモデルデータを参照し、修正を行いたい場合(他の場合は、下記の参照サイト参照)など以外は、Offにした方が良い
例えば、プロシージャルにメッシュを生成している場合や、メッシュからデータをコピーしたい場合などに便利です。
一応、実験してみた。
オフのほうが、ManagedHeapが低いことが分かる。
Read/Writeオフ
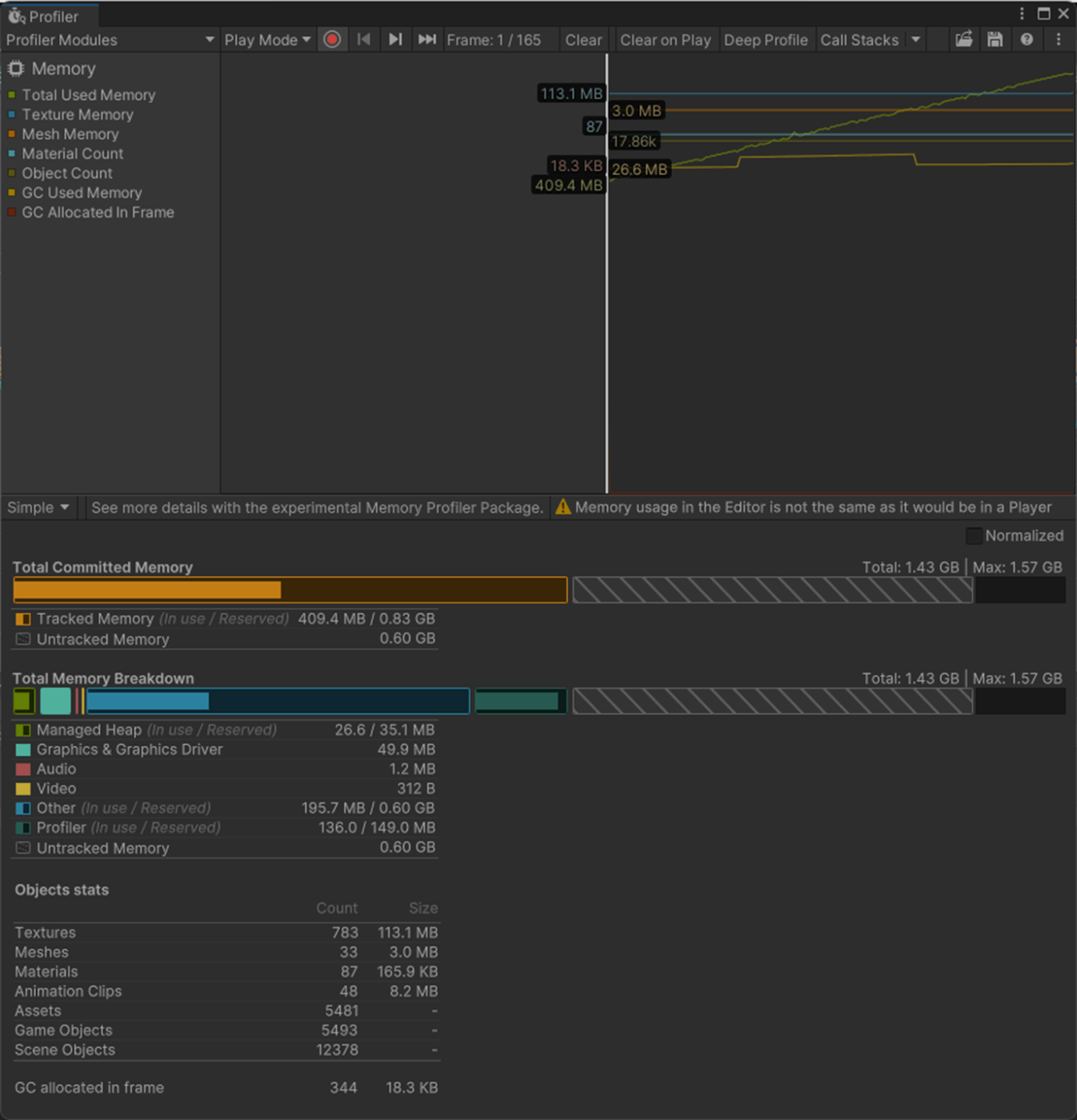
Read/Writeオン
・UIなどを、Zバッファの値によって、大きさが変わらないもの関してはMipmapはオフにするメモリの容量が削減される
Mipmapは、Zバッファの値によって、テクスチャの解像度変えるもで、これによりGPUのパフォーマンスを向上させるが、テクスチャを複数メモリに格納するためメモリ容量が増えてしまう
ちなみに、MipMapにする方法は、Generate Mip Mapsにチェックを入れる
参照サイト
・テクスチャを圧縮することで、メモリ容量・ディスク容量を節約できる
ただ、プラットフォームに適した圧縮形式を選択しないと、テクスチャがメモリに読み込まれた際、解凍のために CPU 時間と過剰な量のメモリが消費される
Androidの端末は、様々な端末が存在する分圧縮形式も多様であるため、このような事象が起こりやすい
テクスチャのFormatで圧縮形式を変更できる
参照サイト、参照サイト
・MaxSizeでテクスチャの解像度を調整し、ディスク容量・メモリ容量・GPUの負荷を減らす
参照サイト
・アニメーションさせないモデルは、Animation TypeをNoneにすることで、Animatorコントローラが追加されない。なので、Animatorコンポーネントがアタッチされると毎フレームチェックする処理が入るので、アニメーションさせないモデルにこれを行っても無駄であるため、誤ってAnimatorコンポーネントが追加されるのを防ぐため、Animation TypeをNoneにすべきである
参照サイト
・Load TypeのDecompress On Load、Compressed In Memory、Streamingで音声の読み込みと展開方法を調整して、CPUとメモリのパフォーマンスを調整しよう。
参照サイト、参照サイト
・Compression FormatでPCM、ADPCM、Vorbis/MP3で圧縮フォーマットを指定する。
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト
・オーディオは、非圧縮したものをインポートする(wav、aiffなど)
Compression Formatの設定で再度圧縮するので、品質が落ちてしまうため
参照サイト
・オーディオのSample Rate SettingとSample Rateで、サンプリングフレート(Hz)を調整して、ディスク容量とメモリ使用量を減らす
ただ、Compression FormatがPCMとADPCMでないと効果がない
参照サイト、参照サイト、参照サイト、参照サイト
・ステレオスピーカーを搭載したスマホは少数なので、Force To Monoでモノクロにすることでメモ使用量とディスク容量節約できる
この設定は、 UI サウンドエフェクトなどの、ステレオエフェクトのないオーディオ全てに適用できる。
参照サイト、参照サイト
・Load In Backgroundで、音声の非同期読み込みを設定。メインスレッドを止めずに音声読み込み可能であるが、ファイルサイズが大きい場合再生が遅れる場合がある。
参照サイト、参照サイト
・Max Virtual Voices、Max Real Voicesはデフォルトのままが、モバイル デバイスに最適な値である。
参照サイト
・DSP Buffer Sizeは、音の再生遅延を調整する機能で、パフォーマンスとトレードオフの関係がある。
参照サイト
・Destroy(myObject)を使用してオブジェクトを破棄し、そのメモリを解放する。Object への参照を null に設定しても、オブジェクトは破棄されない。
参照サイト
・不要な頂点情報を削除することで、GPUとメモリの負荷をなくす
Unityでは、頂点情報を、座標、UV、法線、接線、頂点カラー、ブレンドインデックスとボーンウェイト持つことが可能。
場面に応じて削除すればパフォーマンスが向上する。
例えば、座標とUVはどの場面でも必要である。
法線の場合は、一定の方向の平行光源で動かないオブジェクトであれば法線は不要でも良い。法線はライティングで使用するが、一定の方向の平行光源で動かないオブジェクトであれば表面の明暗が変わらないので不必要である。(ただ頂点カラーやテクチャで明暗つけない場合見た目としては不自然)
もちろん平行光源でも、方向が一定でないならば角度によって明暗が変わらないとおかしいので法線は必要である。
接線の場合は、Normalマッピングする際、従法線を求めるのに必要であるが、Normalマッピングしないのであれば不要である。
頂点カラーの場合は、色は基本的にテクスチャで表現するので、草の揺れや水の塗れの表現など特別な用途で用いる以外は必要なさそうである。
ブレンドインデックスとボーンウェイトは、アニメーションしないオブジェクトであれば不要である。
参照サイト、参照サイト
・不要なキーフレームアニメーション削除することで、CPUの負荷がなくなる
参照サイト
・法線マップはディフューズマップほど解像度高くなくても良い。これによりメモリとディスク容量を節約できる
参照サイト
・Renderer.material(s)を使用すると、呼び出すたびにGCAlloc起きるのと、OnDestroy()・シーンの変更・Resources.UnloadUnusedAssets()しないかぎりずっとヒープに残り続け、メモリリークなどを起す。なので、Renderer.sharedMaterial使用した方が良い。
ただ、Renderer.sharedMaterialを使用して、マテリアルの値を変更した全てに適用されてしまうため注意。Renderer.material(s)の場合は、別々に値を変更可能。
※MeshFilter.meshもnDestroy()・シーンの変更・Resources.UnloadUnusedAssets()しないかりぎりヒープにに残り続ける。
参照サイト、参照サイト
・Andoridメモリ回り
参照サイト
・Listや配列を利用する場合は、なるべく再利用かプールをする
Listや配列を宣言するたびに、GCAllocが発生するのでなるべく再利用できるところはしたほうが良い。特にたくさん呼ばれる関数など。
参照サイト
ダメなパターン
void Update()
{
var myList = new List<int>();
myList.add("1")
}
改善したパターン
private List<int> myList = new List<int>();
void Update()
{
myList.Clear();
myList.add("1")
}
・匿名メソッドでクロージャを使用すると、GCAllocが起きる。なのでクロージャはできるだけ避けた方が良い
参照サイト、参照サイト
ダメなパターン
class Program
{
static void Main(string[] args)
{
// ローカル変数を参照する匿名関数
int x = 0;
Func<int> f3 = () => ++x;
f3();
Console.Write(x);//0
}
}
・ボックス化すると、GCAllocが起きる。なのでボックス化はできるだけ避けた方が良い。
Equalsのような既にライブラリとしてあるようなメソッドでボックス化がどうしても起きる場合は、自前で実装する必要がある。
また、ボックス化しているかどうか特定するには、 ReSharper に搭載の IL Viewer ツールや、 dotPeek 逆コンパイラーなど使用すれば可能。 IL 命令は「box」。
参照サイト、参照サイト、参照サイト
パターン1
class Program
{
static void Main()
{
ObjectWriteLine(5);
IntWriteLine(5);
}
ダメなパターン
static void ObjectWriteLine(object x)
{
// object.ToString が呼ばれる
// 値型に対してはボックス化が必要
Console.WriteLine(x.ToString());
}
OKなパターン
static void IntWriteLine(int x)
{
// こういう場合は、int.ToString が直接呼ばれる
// virtual メソッドだからといって、必ず virtual に呼ばれるわけじゃない
// コンパイルの時点で型が確定してるなら、非 virtual にメソッドを呼ぶ
Console.WriteLine(x.ToString());
}
}
パターン2
class Program
{
static void Main()
{
Console.WriteLine(CompareTo((IComparable)5, 6));
Console.WriteLine(CompareTo((IComparable<int>)5, 6));
}
ダメなパターン
static int CompareTo(IComparable x, int value)
{
// IComparable.CompareTo(object) が呼ばれる。
// value がボックス化される
return x.CompareTo(value);
}
OKなパターン
static int CompareTo(IComparable<int> x, int value)
{
// IComparable<int>.CompareTo(int) が呼ばれる。
// value は int のまま渡される
return x.CompareTo(value);
}
}
・enumをキーにすると、ボックス化が起きGCAlloc発生する。例えばDictionaryなどでenumをキーにした場合などが挙げられる。
解決方法は、IEqualityComparerを継承したクラス作成し使用する方法がある。詳しい内容は参照サイトをチェック。
参照サイト、参照サイト
・forEach文を避ける
Unity 5.5以前では、ループするたびにボックス化が起きていたが、5.5以降はボックス化が起きない。ただ、foreach文は関数呼び出しのオーバヘッドが起きるので、for文を使用した方が速度が速い。
参照サイト、参照サイト
・配列型 Unity APIをUpdateやfor文などので何回も呼び出さない。再利用して使い回す。
また、配列型API使用せずとも実現できるAPIがあるのでそっちを使用するとなお良い
参照サイト
・文字列の連結は、StringBuilderを使用しよう
+の方で文字列の連結を行うと、GCAllocが割り当てが多くなる。
参照サイト、参照サイト
・String.Compare、String.Equals、String.IndexOf、String.LastIndexOf、String.StartsWith、String.EndsWithは、StringComparison.Ordinalを指定するとCPU負荷を削減できる。
デフォルトだと、StringComparison.CurrentCultureであるがこれだと、Ordinalと比べてだいぶ遅い。公式ドキュメントだと10倍くらい違うとあったが100回ループで検証したところ確かに10倍くらいの違いがあった。
言語に合わせた表示順となるようにしたいといった場合以外は、Ordinal使用したほうがよさそう。(詳しくは、参照サイト3つ目の「CurrentCultureとOrdinalの違い」参照)
参照サイト、参照サイト、参照サイト
・正規表現で、Regex.Match やRegex.Replaceを使用すると呼び出すたびに、GCAllocが発生する。なのでできるだけ正規表現は使用しない方がよい。
どうしても使用したい場合は、再利用した方法で使用した方が良い。
やり方は参照サイトを参考
参照サイト
・XML、 JSON、およびその他の長文式テキスト構文解析は、場合によってはアセットの読み込みなどよりも時間がかかることがあるため、速度の速いパーサを選択する必要がある。
実際にプロダクションで使用されているJSONパーサを以下に記す。どれが速いかは未調査。
miniJSON、Json.NET、MessagePack、LitJSON、SimpleJSON、RappidJSON、PicoJSON、JsonFx、Utf8Json、JSONUtilityなどがある。
パーサを使用してパフォーマンスに問題が生じた場合の対処方法を以下に記す。
1.構文解析の負荷を減らす最も良い方法は、パーサを使用しないことである。
敵のHPなどが記載されたマスターデータから値を取得する際は、ScriptableObjectを使用したほうがパーサ使用するよりも読み込み速度が速い。
ただ、ScriptableObjectは値を保存できないのと、暗号化対策しないと素っ裸の状態であるため注意が必要。
もちろんサーバーとデータをやり取りする際は、上記で挙げたJSONパーサを使用しないといけない。(ScriptableObjectは、パーサではないただのアセット)
2.マスターデータは、場面場面で必要なマスターデータを使用すること。
例えば、Aというダンジョンの敵のパラメータが必要な場合、一つのマスタ―データにA、B、Cのダンジョンの敵のパラメータをまとめるのではなく、A専用のマスターデータを使用して読み込んだ方が読み込む速度が速くなる。
3.メインスレッドではなく、別スレッドで処理する
最近のiphoneだと6つ以上、Andoridだと8以上あるので問題なく別スレッドで処理が可能
参照サイト、参照サイト、参照サイト、参照サイト
・Resourcesを使用して、アセットを読み込まない。
アプリの起動時間や長くなったり、ビルドする時間が長くなったり、メモリ過剰使用など様々な問題が発生するためである。
本番環境用に切り替える際ソースの修正が必要であるため、プロトタイプ作成時にも使用せず、Addressableを使用したほうが良い。
参照サイト、参照サイト
・シェーダ―のプロパティやMecanimでアニメーションを変更する際は、文字列でキーを指定せず、ハッシュ値で指定すると速くなる。
参照サイト
ダメなパターン
material.SetColor(“_Color”, Color.white);
animator.SetTrigger(“attack”);
改善したパターン
int material_Color = Shader.PropertyToID(“_Color”);
int anim_Attack = Animator.StringToHash(“attack”);
material.SetColor(material_Color, Color.white);
animator.SetTrigger(anim_Attack);
・GCAllocが発生しない物理演算 API を使用する
Unity 5.3 以降は、Physics クエリ API の割り当てなしのAPIが提供されていることが多いのでそれを利用する。
例えば RaycastAll コールは RaycastNonAlloc に置き換え、 SphereCastAll コールは SphereCastNonAlloc に置き換えることができる。
参照サイト
・整数、浮動小数点、Vector、Matrix、Quaternion同士を計算する際は、順序に気を付けて計算を行う。
計算する際の速さは、整数演算>浮動小数点演算>Vector、Matrix、Quaternionである。
なので、計算結果順番を変えても結果が変わらないかぎり、計算が速いほうで行う
参照サイト
Vector3 x;
int a, b;
// 非効率的(ベクターの乗算が 2 回発生する)
Vector3 slow = a * x * b;
// 効率的(整数の乗算が 1 回、 ベクターの乗算が 1 回)
Vector3 fast = a * b * x;
・カラーコードを取得する際は、ColorUtilityを使用した方が以前のUnityで提供されていたAPI(調べても出てこない)よりもCPUの負荷軽減とGCAllocが発生しない。
参照サイト
・Find、FindWithTag、FindObjectOfType、FindObjectsOfType、FindGameObjectsWithTag、
FindGameObjectsWithTagは負荷が高いので、たくさん呼ばれるUpdateなどでは避ける。
Startメソッドで初期化して再利用するか、シングルトンしようして使い回すのが良い。
参照サイト、参照サイト
・Debug.Logを本番のアプリで入れる際は、#if UNITY_EDITORを使用せず、 [Conditional("UNITY_EDITOR")]を使用した方が、Debug.Logの呼び出しコストがかからない。
参照サイト
・1次元配列 >ジャグ配列 >多次元配列の順で早い。可能な限り、1次元配列を使用した方が良い。
参照サイト
・Particle Systemをオブジェクトプールすると、最低でも3500バイトのメモリが消費される。
メモリ消費量は、アクティブになっているモジュールの数に応じて増える。
Particle Systemが終了してもメモリから解放されず、Destoryして初めてメモリから解放される。
多数の異なるパーティクル全てに、オブジェクトを適用するとメモリの消費量が多くなる。
なので、汎用的なパーティクルをプールし、そこにパラメータ専用のクラスなどでパラメータを変えて、異なるパーティクルを表現できればメモリの消費量が節約できる。
参照サイト
・Updateなど頻繁に呼び出される関数をスキップすることで、CPU負荷を削減
参照サイト
パターン1
flg = false;
void Update(){
if (flg) {
for (int i = 0; i < 10000; i++)
{
Debug.Log("テスト");
}
}
// do something...
}
パターン2
private int interval = 3;
void Update(){
if (Time.frameCount % interval == 0){
for (int i = 0; i < 10000; i++)
{
Debug.Log("テスト");
}
}
// do something...
}
・Updateなど頻繁に呼ばれるメソッドで、デリゲードの登録・削除を何回も行うと、パフォーマンスが悪くなる。
参照サイト
・CullingGroupsで、カメラから見えている場合や、見えている距離に応じて、アニメーションをスキップしたり、AIの更新度下げたりと色々な機能を制御し、負荷を減らす。
参照サイト、参照サイト、参照サイト
・無駄なメソッド呼び出しのオーバヘッドを防ぐ
参照サイト
ダメなパターン
int Accum { get; set; }
Accum = 0;
// List::getCount を呼び出す
for(int i = 0; i < myList.Count; i++) {
Accum += myList[i];
// set_Accum を呼び出す
// get_Accum を呼び出す
//List::get_Value を呼び出す
}
改善したパターン
int accum = 0;
int len = myList.Count;
for(int i = 0; i < len; i++) {
accum += myList[i];
// List::get_Value を呼び出す
}
・ Unity がメソッドのインライン化をほとんど行わない。
IL2CPP 下であっても、多くのメソッドは現在、適切なインライン化を行わない。これは特にプロパティに関して言える。さらに、 virtual および interface メソッドのインライン化は一切行わない。
参照サイト3つめでメソッド分割したのと、していないのを比較していたが確かに性能に差が出ている。
参照サイト、参照サイト、参照サイト
・SpriteEditorのCustom Outlineで、余分な透明部分を削除し、パフォーマンスを上げる
透明な部分が多いとオーバードローする確率が上がるため、余分な箇所は削除したほうが良い。
参照サイト、参照サイト
・SpriteAtlasを使用して、ドローコールの数を減らす。
参照サイト、参照サイト
・SpriteAtlasのVariantを使用して、解像度の異なるSpriteAtlasを作成し、プラットフォームや状況に応じてメモリを節約する。
参照サイト、参照サイト
・SpriteAtlasに含まれるスプライトを表示すると、メモリにSpriteAtlasが読み込まれるので表示したシーンでSpriteAtlasに含まれるスプライトをそこまで表示しない場合はメモリの無駄遣いが生じてしまう。
なので、なるべくSpriteAtlasにはすべて表示するスプライト同士分類すべきである。
①5つのスプライトをSpriteAtlasにまとめた


②1つのスプライトをSpriteAtlasにまとめた
5つにまとめたときと比べてSpriteAtlasのモリ使用量が減っていることが分かる
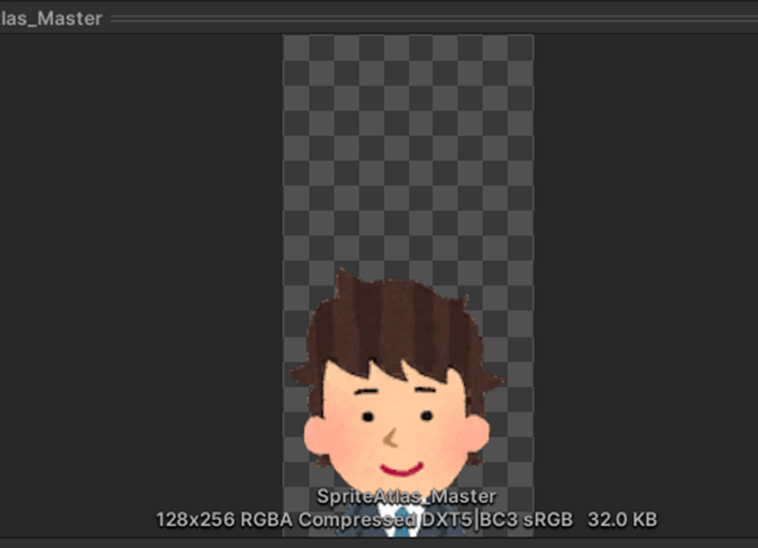
参照サイト
・2Dで当たり判定を有効・無効にする際は、Rigidbody 2DコンポーネントのSimulatedを有効無効にしたほうがコライダーコンポーネントを有効無効にするよりもCPUの負荷が軽い。(メモリ的にもいいらしい)
実際に試してみたが、確かにSimulatedを有効無効する方が処理が軽い
①Simulatedを有効無効

②コライダーコンポーネントを有効無効

参照サイト
・当たり判定の検出方法を変更するCollision Detectionを変えてCPU負荷を調整する
Discrete > Continuous > Continuous Speculative > Continuous Dynamicの順で軽いが、精度が低くなる。
参照サイト
・物理演算を行うタイミングを指定するSleeping Modeを変えてCPU負荷を調整する
Start Asleep > Start Awake > Never Sleepの順で軽い
参照サイト
・物理演算の方法を変えるBody Typeを変えてCPU負荷を調整する。
Static > Kinematic > Dynamicの順で軽い。
①Dynamic

②Kinematic

③Static

参照サイト、参照サイト
・ディレクショナルライト、スポットライト、ポイントライト
ディレクショナルはこのライトは方向性が均一で、減衰しません。 ディレクショナル ライトは、最も低コストなリアルタイム ライトです。
スポット:はスポットライトはその円錐の外側にあるオブジェクトを除外して光を当てません。 これにより、スポットライトは球形のポイントライトよりも計算コストが抑えられます。最高のパフォーマンスを得るには、円錐の幅を狭くして、目的のオブジェクトのみを照らすようにします。
ポイントは全方向に光を放ちます。全方向への照明は便利ですが、非常にコストがかかります。ポイントライトは広い領域にわたるため高コストです。さらに、シャドウの計算はライティングの中で最もコストがかかる部分です。全方向に光を当てればシャドウが多くなり、計算量が増えます。
参照サイト
・スクリーンスペースシャドウ
カスケードシャドウマップでボトルネックがある場合、スクリーンスペースシャドウを使用すればパフォーマンスが上がるかもしれない。ただ、メモリ使用量は増える。
参照サイト、参照サイト
・影のMaxDistanceを調整してパフォーマンスを上げる。
URPではこのような項目がないが、MaxDistanceで実現できると考えている。
下記表のシャドウマップの箇所でMaxDistanceを調整して影の描画距離を変えてパフォーマンスを上げる。
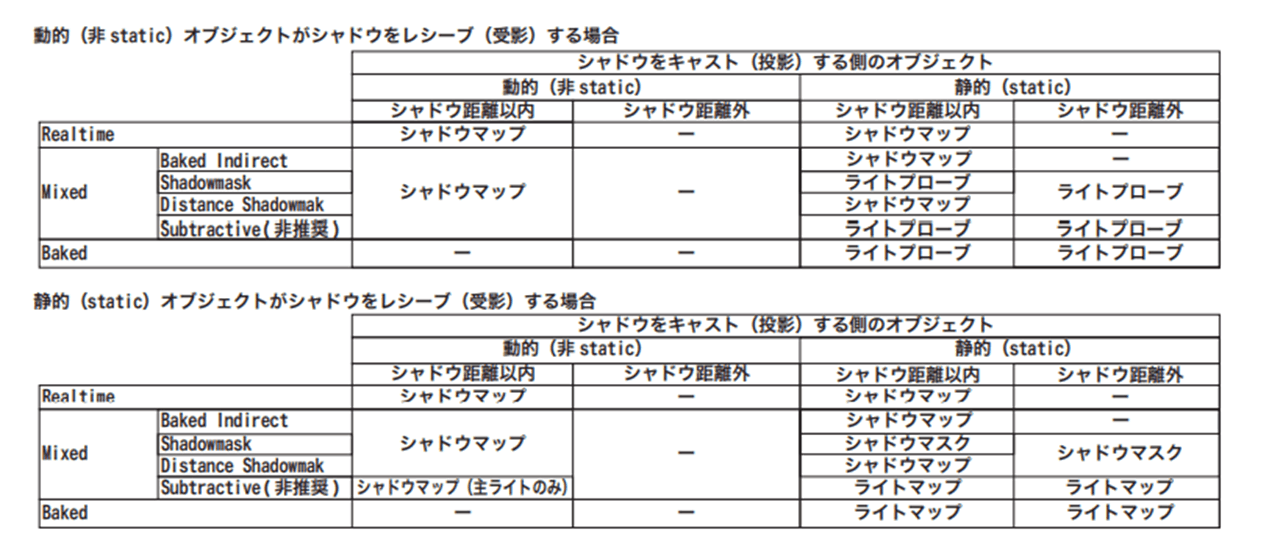
また、MaxDistanceを超えて欠落している影を隠すには、フォグなどの視覚効果を使用するのも良い。
参照サイト
・Denoiseで、品質を保ちつつライトマップのベイク時間を抑える。
参照サイト
・リアルタイムシャドウは高コスト。シャドウ マッピングと呼ばれる手法を使用して生成される。シーンのジオメトリをシャドウマップにレンダリングするコストは、シャドウを有効にして描画された頂点の数に比例する。シャドウを投影するジオメトリの量とリアルタイムのシャドウを投影するライトの数を制限することをおすすめする。
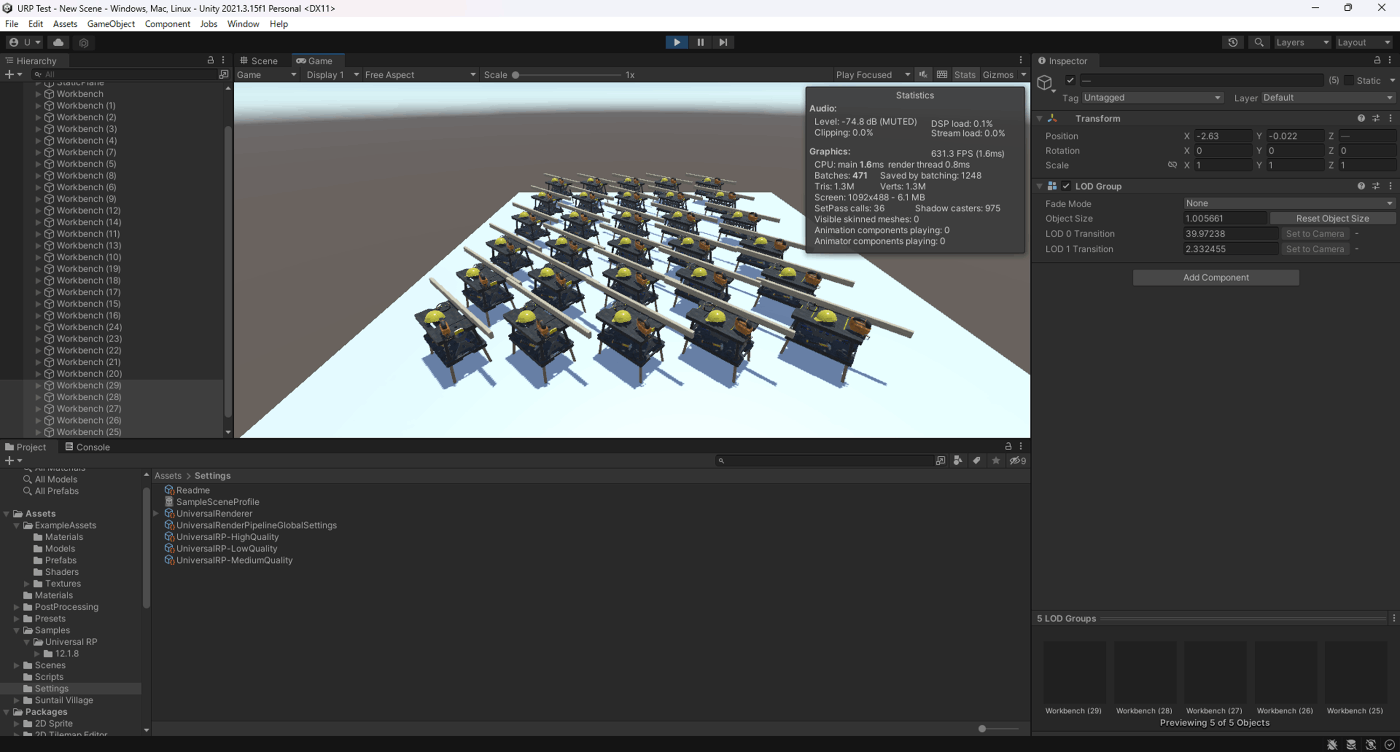
今回はリアルタイムシャドウの負荷下げるために
プリミティブオブジェクトのShadow Onlyを使用したパターンとURP Decal Projectorを使用したパターンで、影を描画する際のBatchesを減らしCPUの負荷を減らす。
実際にやってみたが、Shadow Onlyのパターンは負荷を減らせたがURP Decal Projectorのパターンは負荷が逆に上がった
①通常の状態で影を描画
Batchesが471
CPUが1.6ms
FPSが631
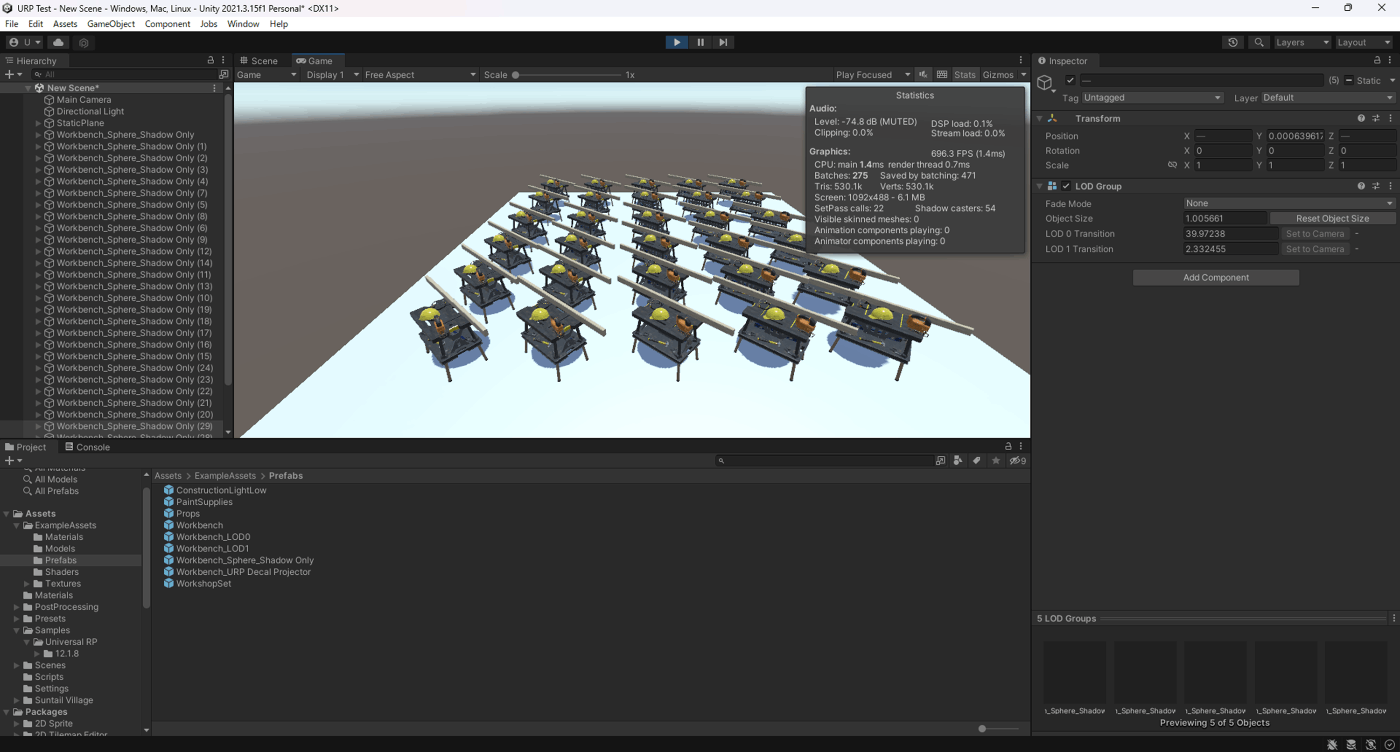
②Shadow Onlyを使用して影を描画
Batchesが275
CPUが1.4ms
FPSが696
③URP Decal Projectorを使用して影を描画
Batchesが415
CPUが1.7ms
FPSが579
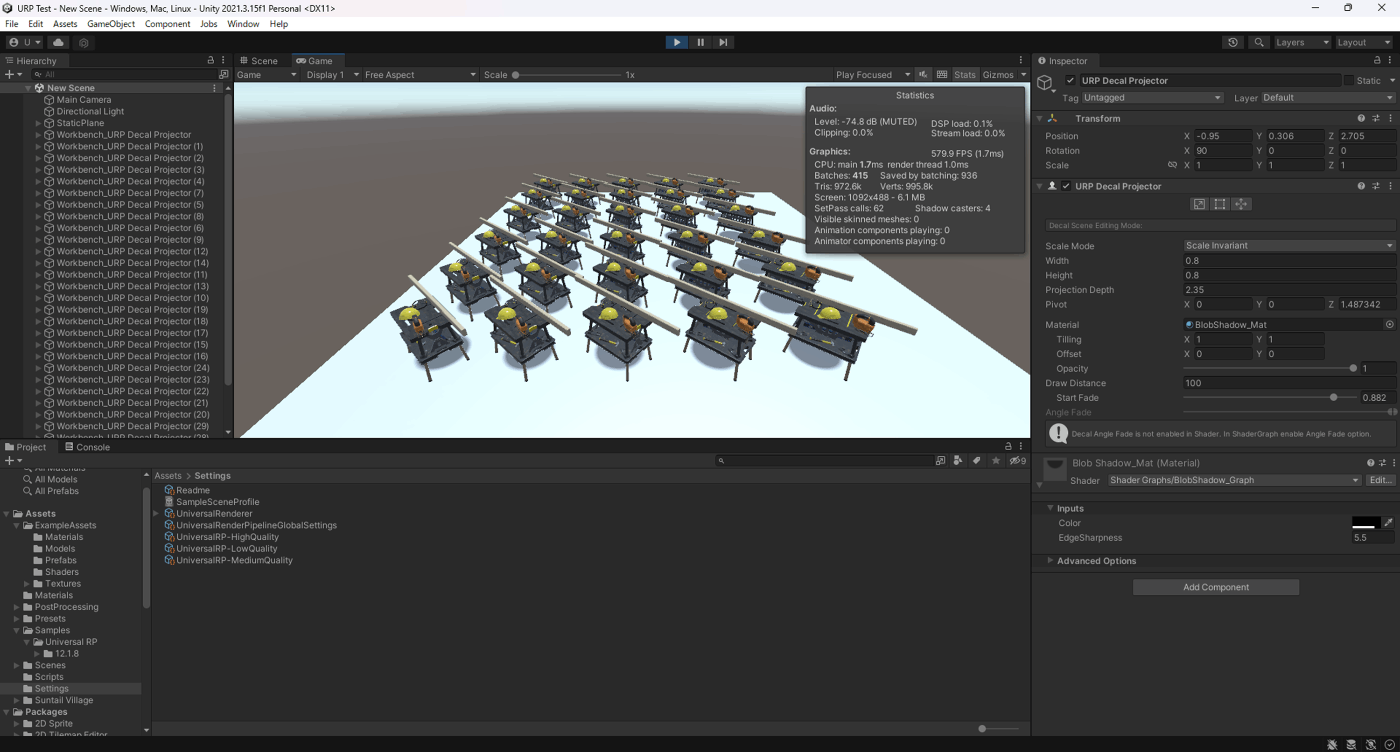
ただ、Shadow OnlyとURP Decal Projectorだと詳細な影ではなくなるし、セルフシャドウがなくなる
また、公式ドキュメントだと低 LOD メッシュを使用するパターン、自作のカスタムシェーダで行う方法で影を描画する方法が紹介されている。
参照サイト、参照サイト、参照サイト、参照サイト、参照サイト、参照サイト
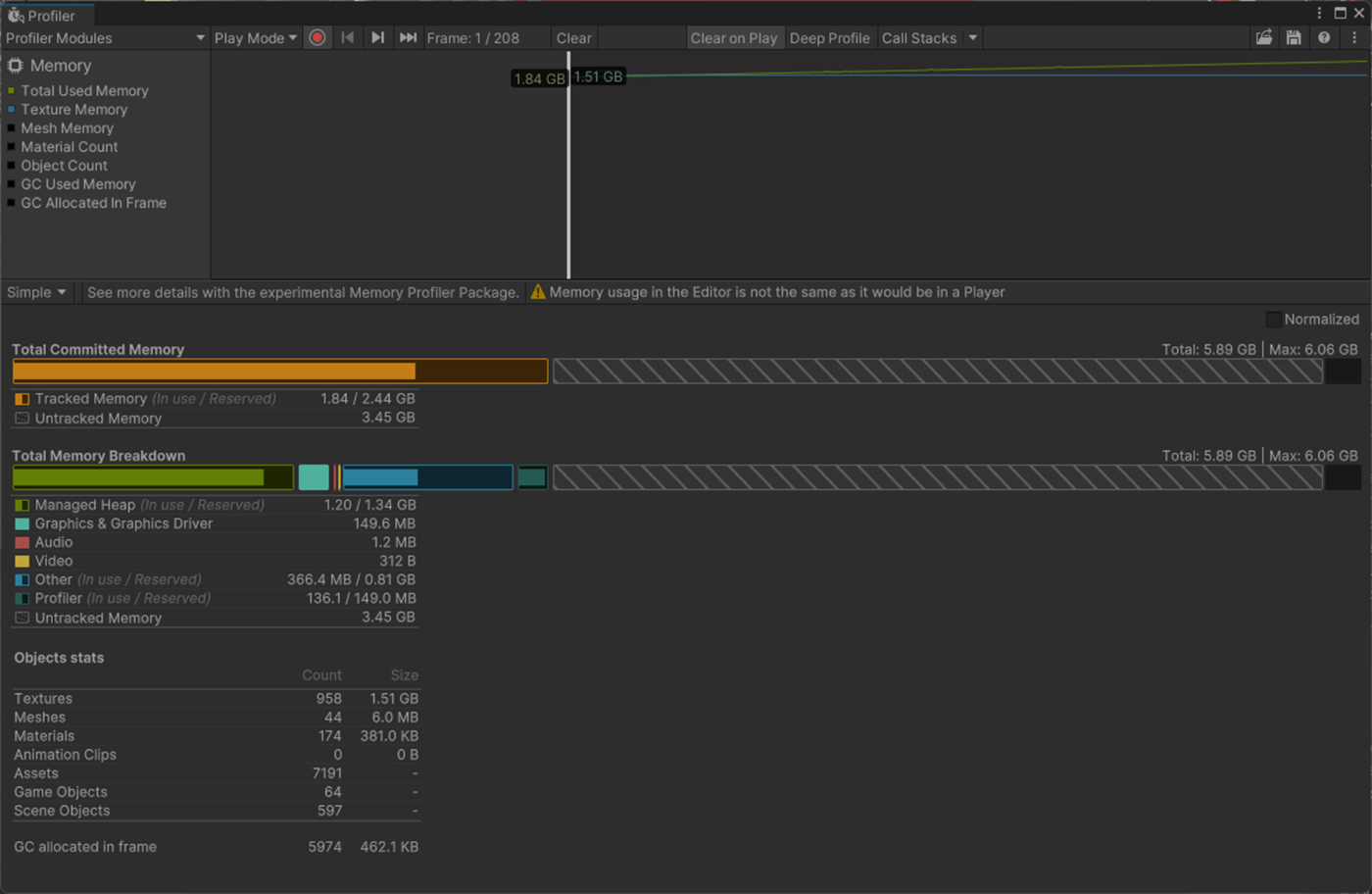
・Environment ReflectionsのResolutionの検証
Resolutionを高く設定すると見た目は綺麗になるが、ベイク時間やメモリ使用量が増える。
①Resolutionが2048

②Resolutionが16
参照サイト
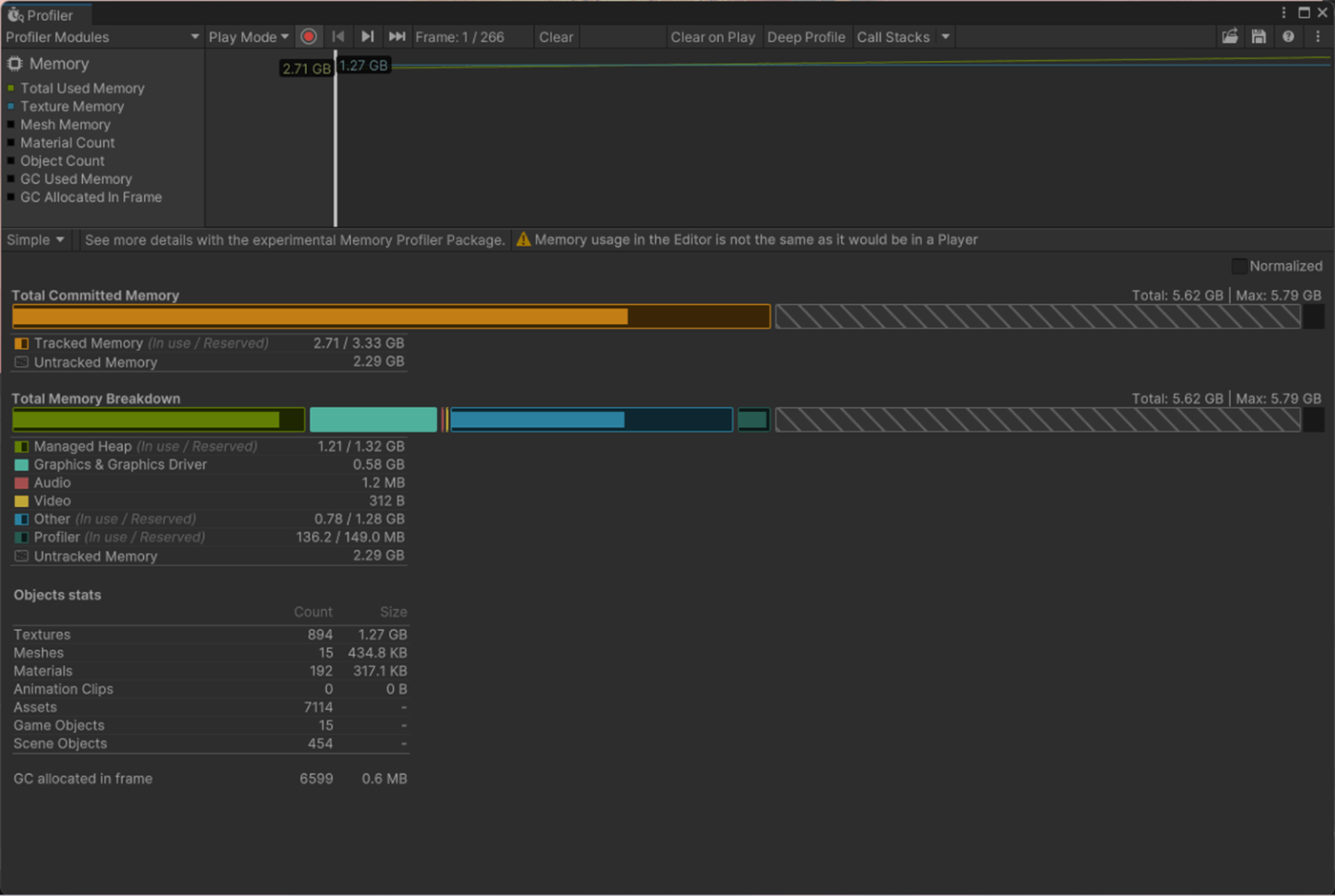
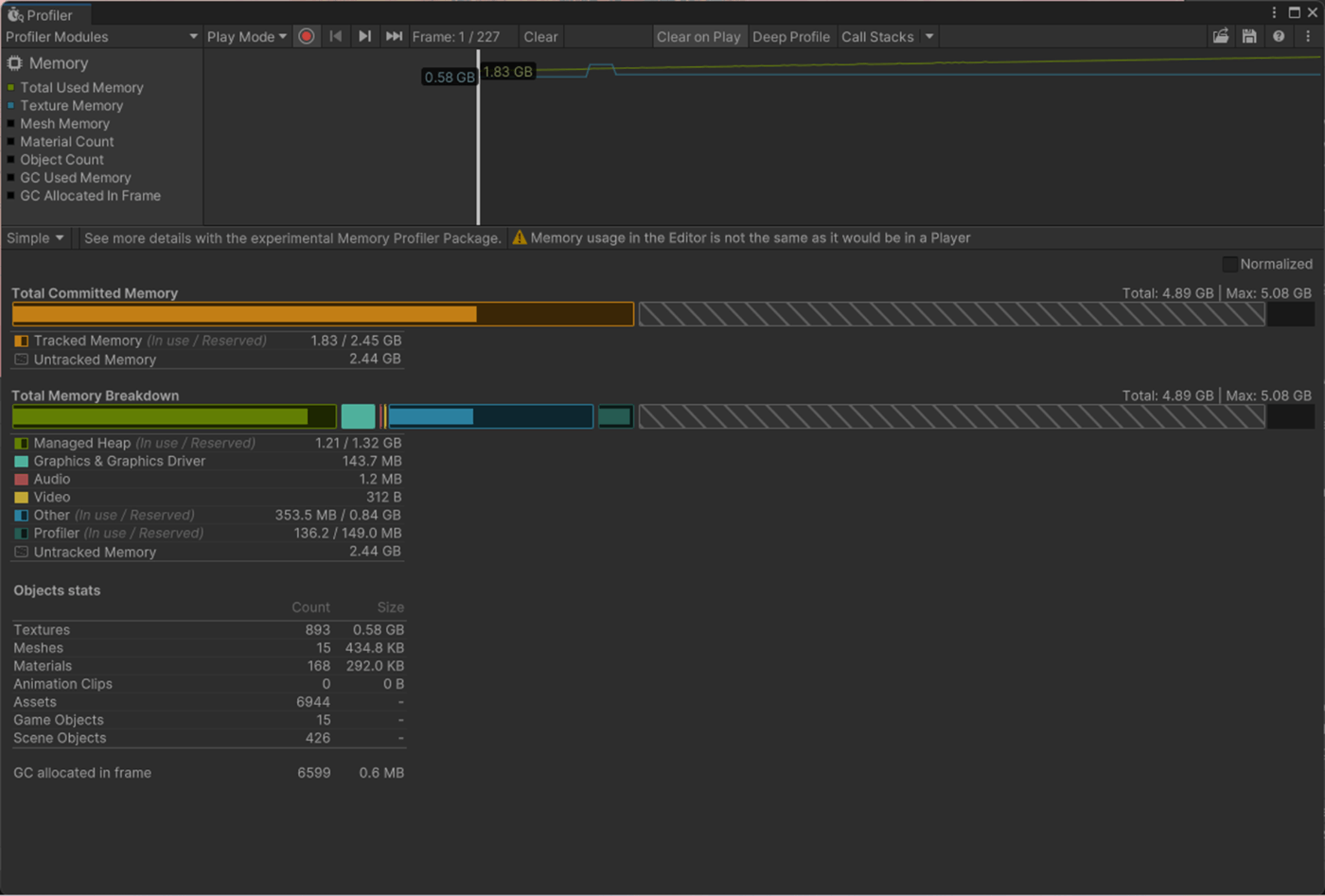
・Environment ReflectionsのCompressionの検証
リフレクションのテクスチャを圧縮するかどうか決定する項目
Uncompressedの方がメモリ使用量が多いことが分かる。
基本的にはテクスチャ圧縮させると画質が下がるが、検証したところ特に画質が変化していないことが分かった。
なお、余談であるがリアルタイムのリフレクションプローブは、メモリ内で圧縮されず、メモリ内のサイズは解像度と HDR の設定に依存する。
①Uncompressed
圧縮しない

②Compressed
圧縮する
③Auto
圧縮形式が適切な場合は、リフレクションテクスチャを圧縮する。
参照サイト、参照サイト、参照サイト
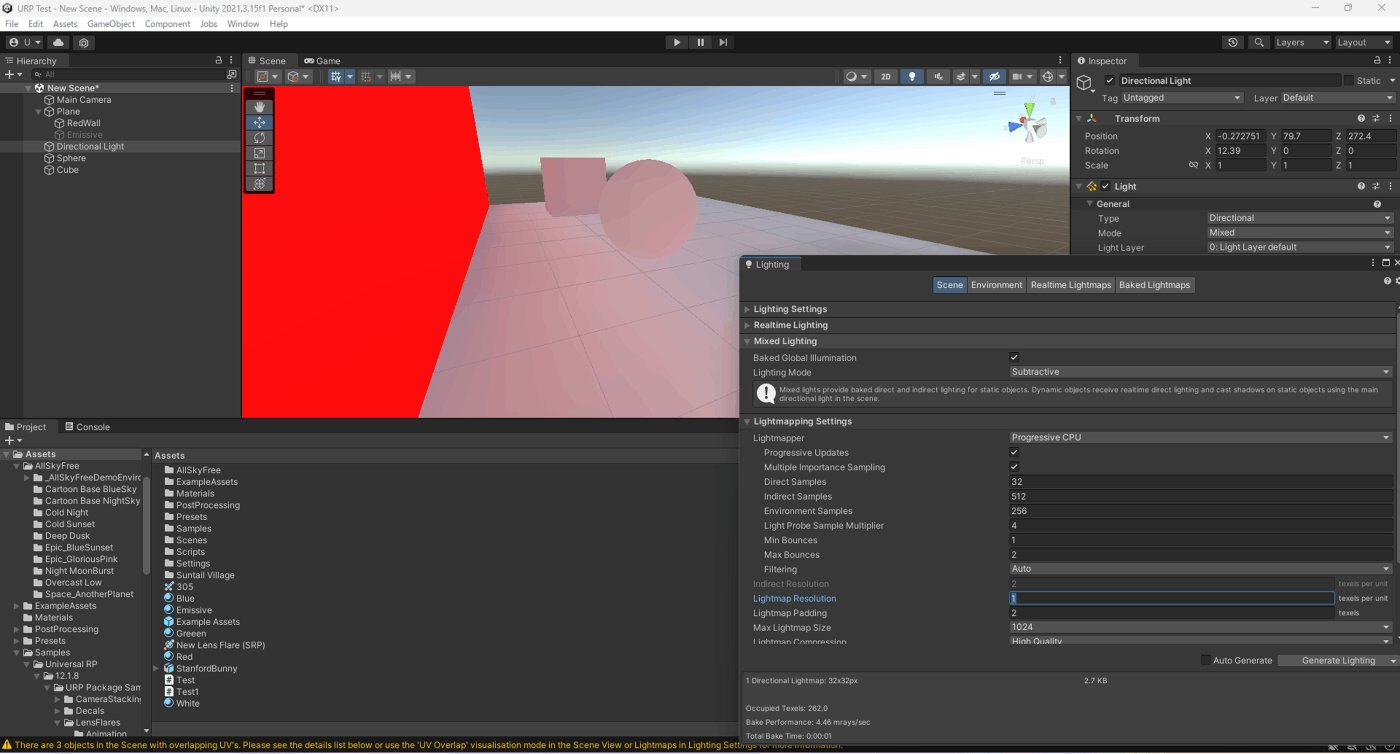
・可能であれば、静的ライトを使用し、動的ライトを使わないようにする
ライトマップ テクスチャのレンダリング コストは常に、動的ライティングよりもはるかに低くなる。モバイルゲームに実装する場合は、ベイクしたライティングを第一候補とすることをおすすめ。
参照サイト
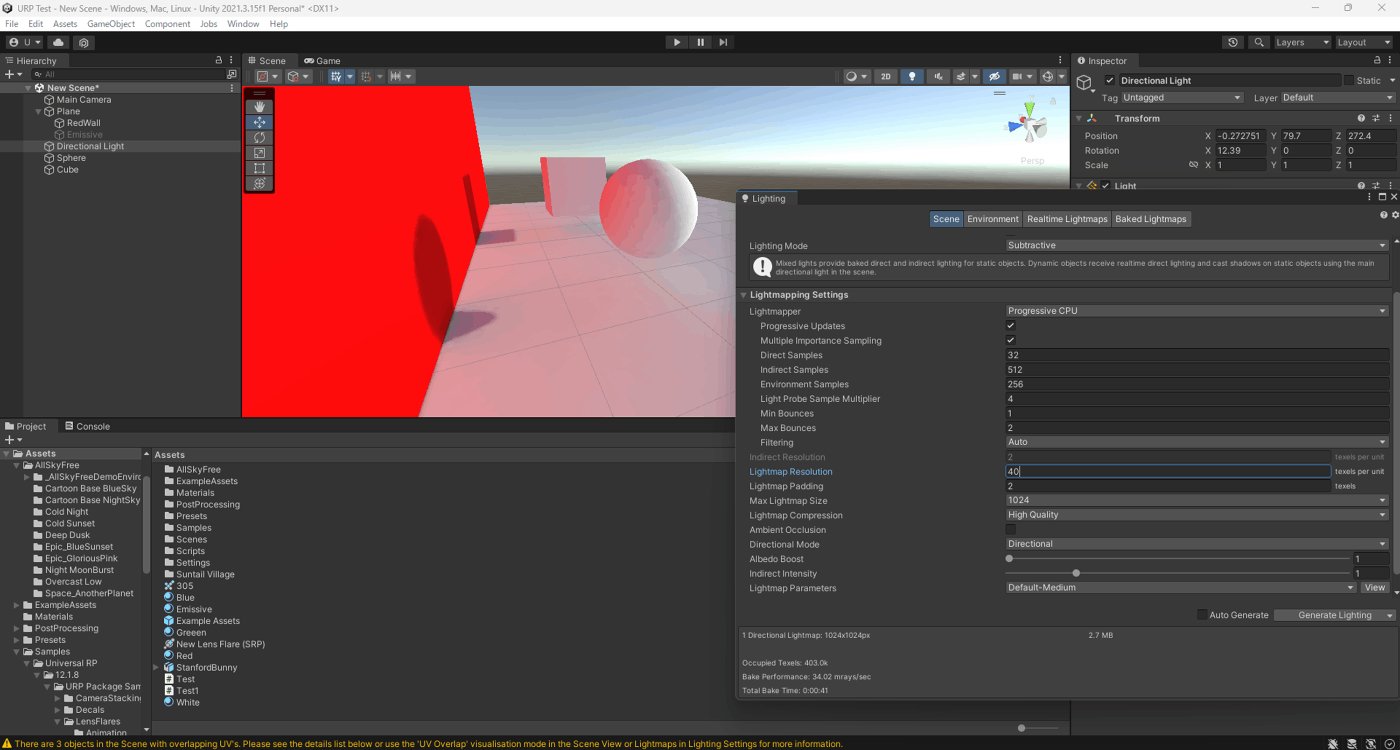
・LightMapperの設定項目の分類
黄色箇所が調整次第で、メモリ容量などが重くなる。
青色箇所が青色ほどパフォーマンスに影響しない。

参照動画の20:00
・Progressive Updates(Prioritize View)の検証
これを有効にすると、ライトマップのベイク時に、シーンビューに映る範囲を優先的に計算して画面に反映し、その後に他の範囲を処理する。
これによってベイクの終了を待たずに、絵作りの大まかな確認できるようになる。
これをチェックを外せばベイク時間が短くなる。
①Progressive Updatesオフ

①Progressive Updatesオン
参照サイト、参照サイト
・ライトマップが直接光と間接光と環境光をベイクするしくみ
参照動画の5:10
・環境光を使用する大きな利点は、レンダリングが安価であり、シーン内のライトの数を最小限に抑えることが望ましいモバイル アプリケーションに特に役立つこと。
参照サイト
・Direct Samplesの検証
テクセルごとの直接光のサンプリング数(テクセルから飛ばすレイの本数)を指定する。
この場合の直接光とは、そのテクセルに直接光を当てているライトを指す。
この値を大きくすると、ライトマップの質は向上するが、ベイク処理に要する時間が長くなる。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目や影に変化が見られなかった
①Direct Samplesが1
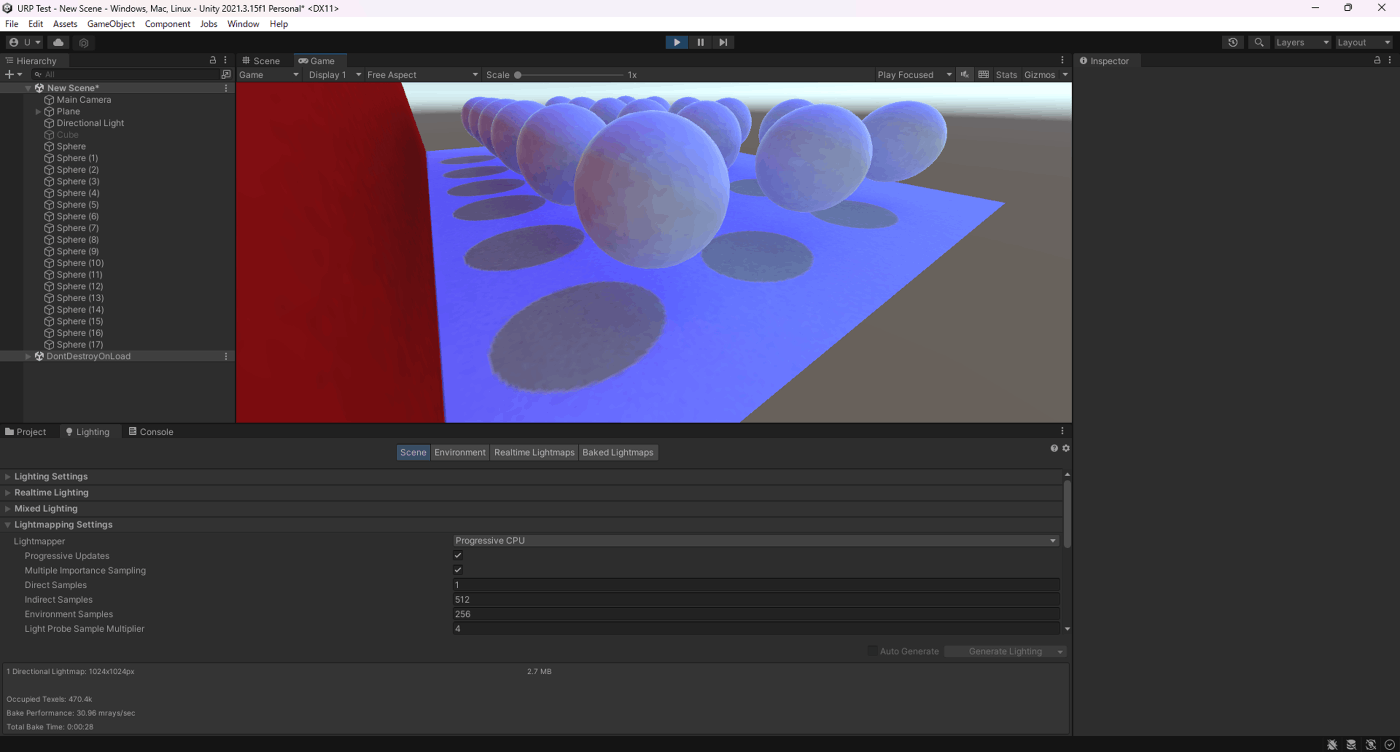
②Direct Samplesが500

また、フォーラムには以下のような記載がある。
シーン内のソフト シャドウにノイズが多い場合を除き、この値を低く保ちます。
・Indirect Samplesの検証
テクセルごとの間接光のサンプリング数(テクセルから飛ばすレイの本数)を指定する。
この場合の間接光とは、周囲のオブジェクトとリフレクションプローブから放射される光を指す。
この値を大きくすると、ライトマップの質は向上するが、ベイク処理に要する時間が長くなる。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目が汚くなっていることが分かる。
公式ドキュメントによると、
一部のシーン、特に屋外のシーンでは、100 サンプルで十分です。エミッシブジオメトリのある屋内シーンでは、望む結果が得られるまで値を増やします。
フォーラムによると、
間接的に照らされた領域にノイズがあり、放射オブジェクトが大量のノイズを生成しない限り、この値は低く保ってください
①Indirect Samplesが8
②Indirect Samplesが512

参照サイト、参照サイト
・Environment Samplesの検証
テクセルごとの環境光のサンプリング数(テクセルから飛ばすレイの本数)を指定する。
この値を大きくすると、ライトマップの質は向上するが、ベイク処理に要する時間が長くなる。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目が汚くなっていることが分かる。
公式ドキュメントによると、
HDR スカイボックスを使用するシーンでは、最終的なライトマップやプローブのノイズを減らすために、より多くのサンプルが必要になることがあります。また、太陽のような明るい特異点や、逆光の雲のようなコントラストの強い高周波のディテールを含むスカイボックスを持つシーンでも、サンプル数を増やすと効果的です。
フォーラムによると、
環境によって照らされた領域にノイズが多い場合を除き、この値を低く保ちます。
①Environment Samplesが8
②Environment Samplesが1000

参照サイト、参照サイト
・Light Probe Sample Multiplierの検証
ライトプローブに使用するサンプル数を制御する。値を大きくすると、ライトプローブの品質が向上するが、ベイクにより長く時間がかかる。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目が変わっていないのが分かる(こちらのサイトでは変わっている)
フォーラムによると、
隣接するプローブの色がある程度均一になったら、この値を増やすのをやめます。
①Light Probe Sample Multiplierが1

②Light Probe Sample Multiplierが1000

参照サイト、参照サイト
・Min Bouncesの検証
間接光のサンプリングに飛ばしたレイがあるオブジェクトの表面に到達した時、何回まで反射するかの最小数を設定する。値を小さくするとベイク時間が短縮されるが、ライトマップのノイズが増加する可能性がある。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目が変わっていないのが分かる。
①Min Bouncesが1

②Min Bouncesが9
参照サイト
・Max Bouncesの検証
間接光のサンプリングに飛ばしたレイがあるオブジェクトの表面に到達した時、何回まで反射するかの最大数を設定する。
値を小さくするとベイク時間が短縮されるが、ライトマップのノイズが増加する可能性がある。
検証したところ、ライトマップのサイズは変わらずベイク時間は増えたことが分かる。
また、見た目が若干変わっている。
公式ドキュメント一部抜粋
屋内シーンには高いバウンス値を、屋外シーンや明るい面が多いシーンには低いバウンス値を使用します。Min BouncesとMax Bouncesの間の範囲が広がると、ライトマップに見えるノイズの量が増えます。
①Max Bouncesが10
②Max Bouncesが40
参照サイト
・Filterの検証
ライトマップに使用するフィルターを選択する。
ノイズが起きる原因は、テクセルから放たれたRayがまばらになりがちなのでむらがでるため。
Gaussianフィルターだとベイク時間も短く、ノイズ少ないことが分かる。
なお、GaussianとA-Trousフィルターの違いは、異なるジオメトリにフィルターをかけるかどうかで、A-Trousは異なるジオメトリにフィルターをかけるない
また、フィルタリングはUVチャートごとに適用されるので、あるチャート(メッシュ)にフィルタリングをかけたくないときなどは、Generate LightMap UVsで独自ライトマップを使用するとよい。
①None

②Gaussian
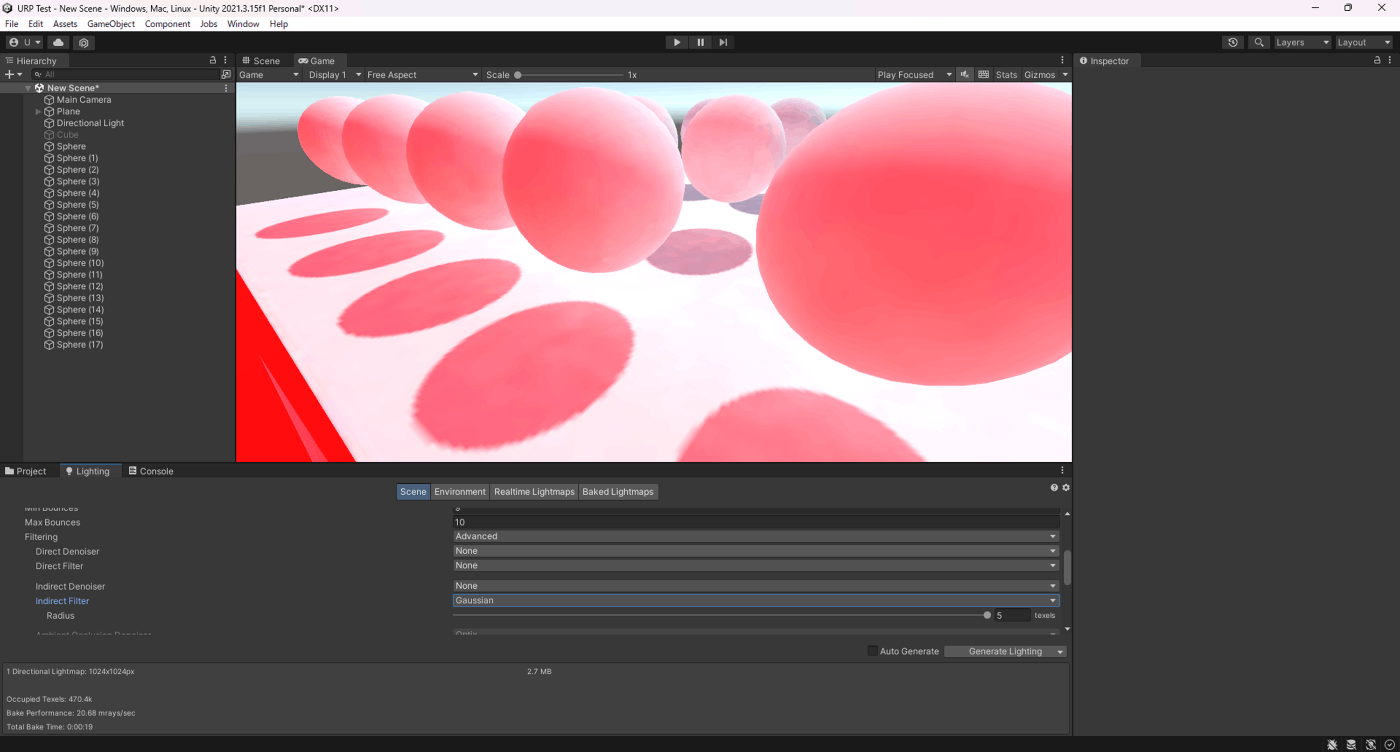
③A-Trous
参照サイト、参照動画の8:50と10:05と11:40
・Radiusの検証
Gaussian時のぼかし具合を調整できる。
検証したところ、ベイク時間は変わらずノイズがなくなっていることが分かる。
①Radiusが1

②Radiusが5
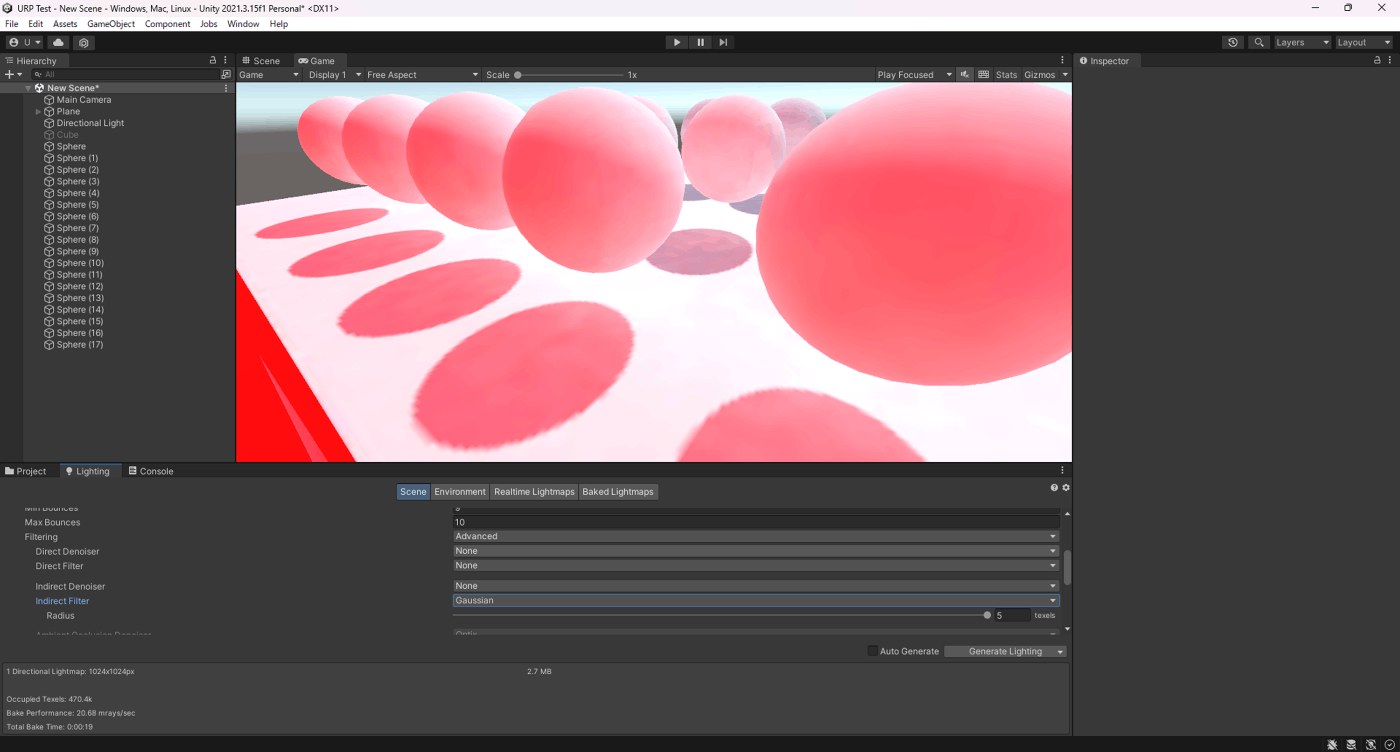
参照サイト
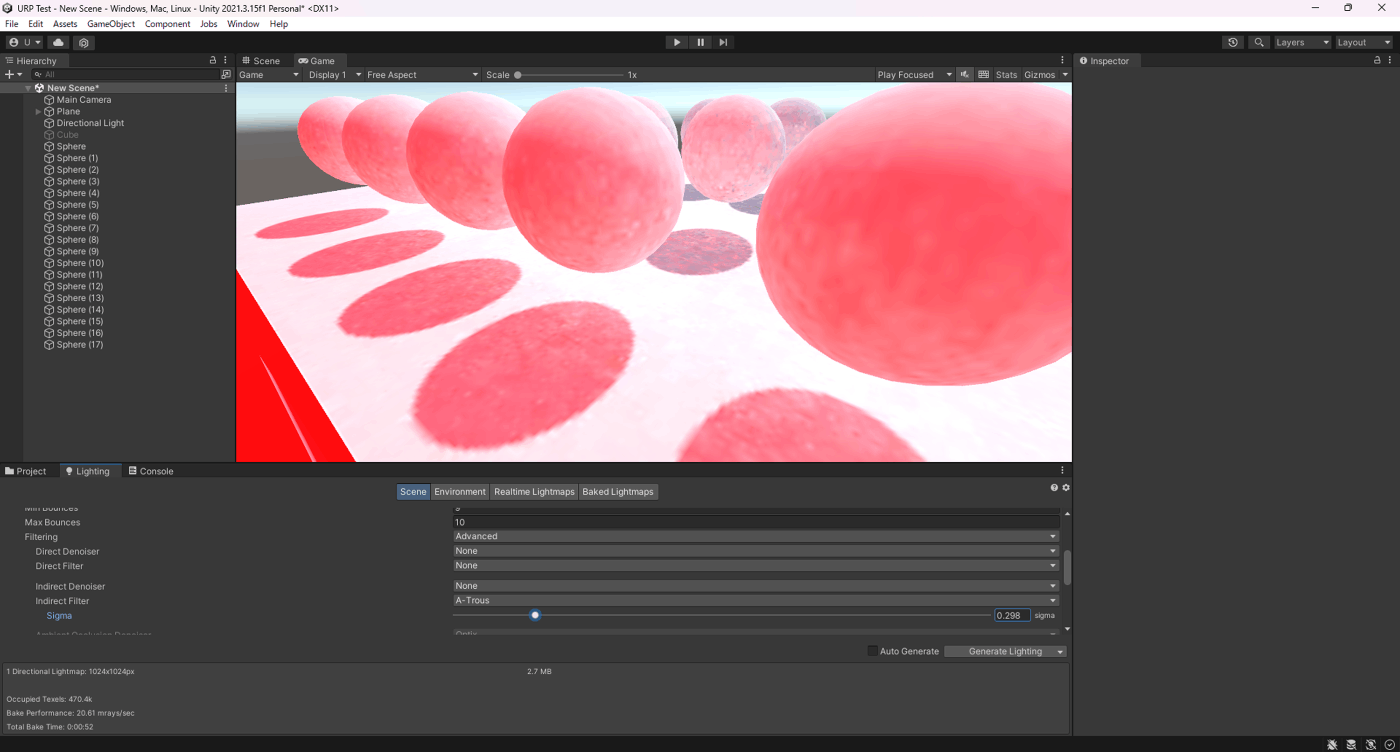
・Sigmaの検証
A-Trousのぼかし具合を調整できる。
検証したところ、値が大きいほうがベイク時間が長く、ノイズはそこまで差がないことが分かる
①Sigmaが0.298
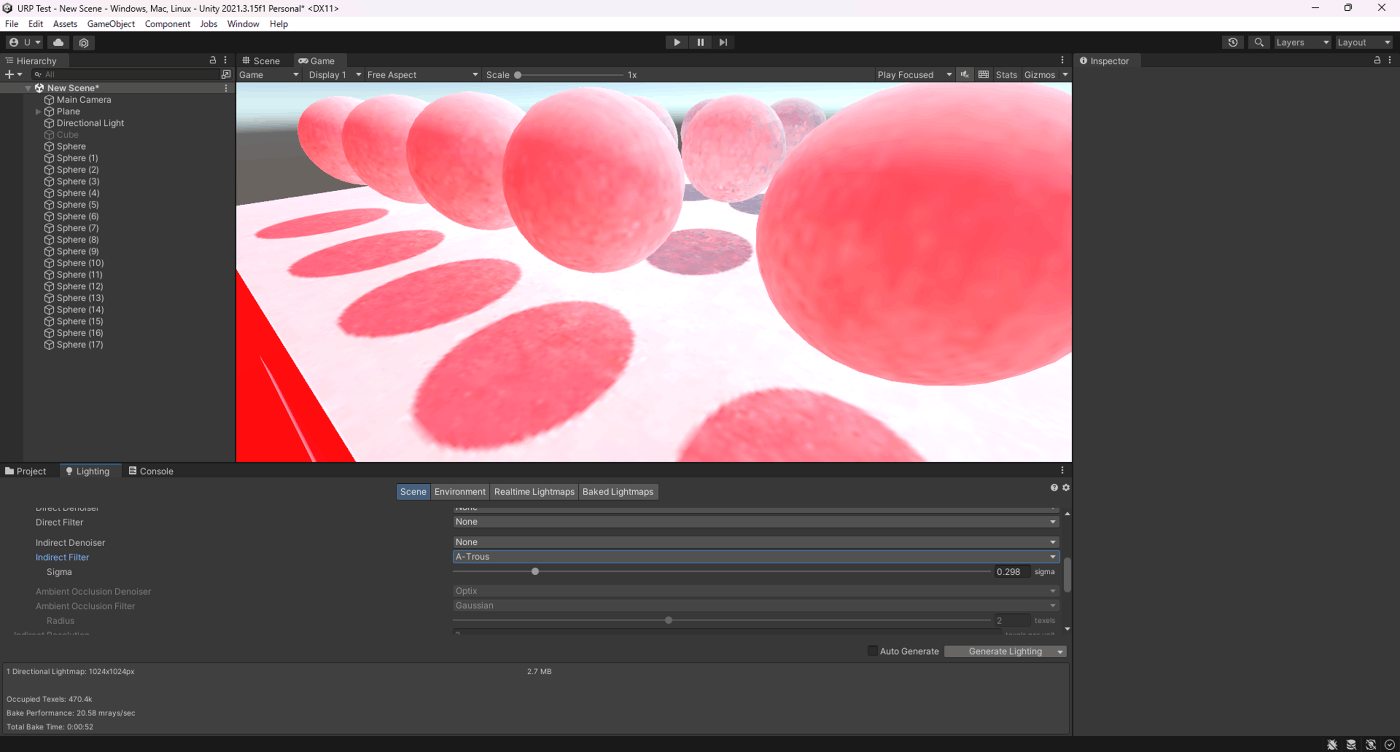
②Sigmaが2
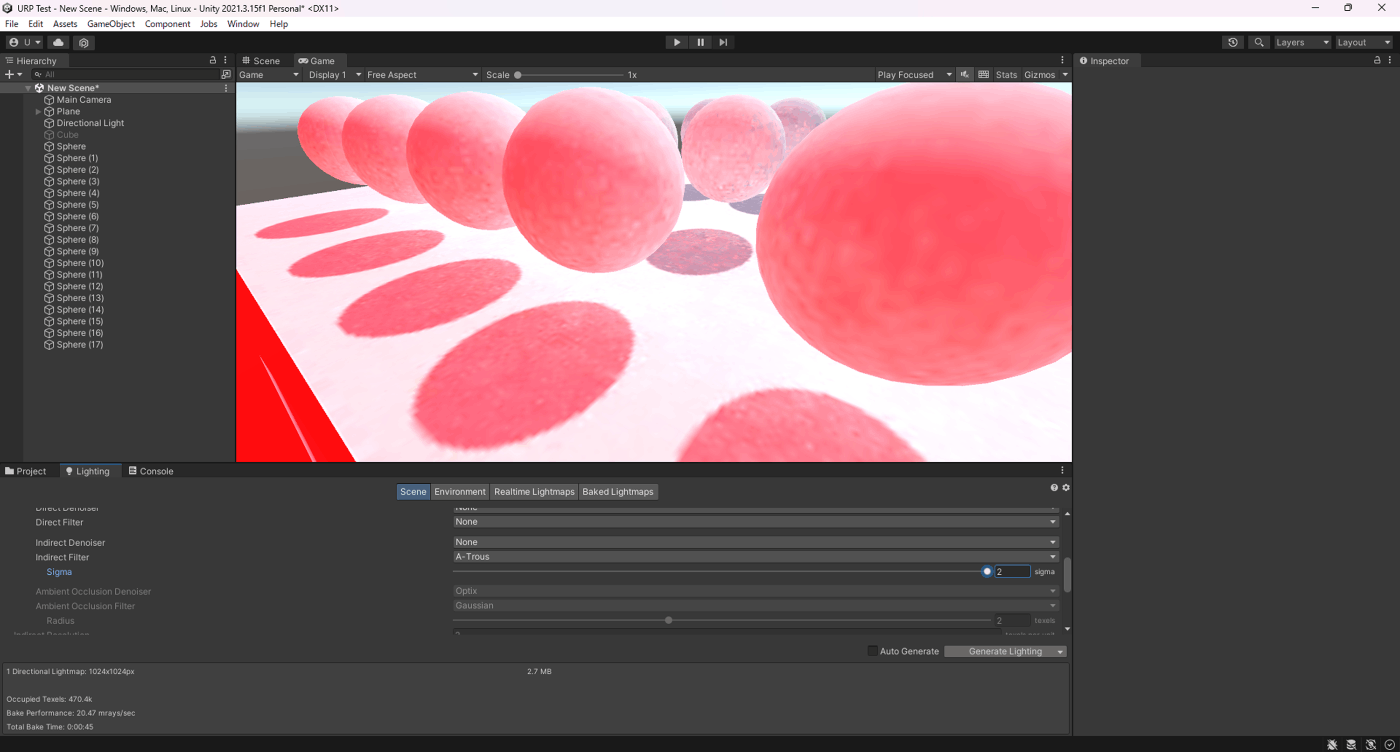
参照サイト
・Denoiserの検証
ライトマップに使用するノイズ除去を選択する。
検証したところ、ベイク時間は、RadeonPro > OpenImageDenoise > Optix > Noneで長い
見た目は、Optix > OpenImageDenoise > RadeonPro > Noneは綺麗
少ないサンプリング数だとFilterだけだとノイズが残りやすいが、Denoiser使用することでノイズを削除できる
①None
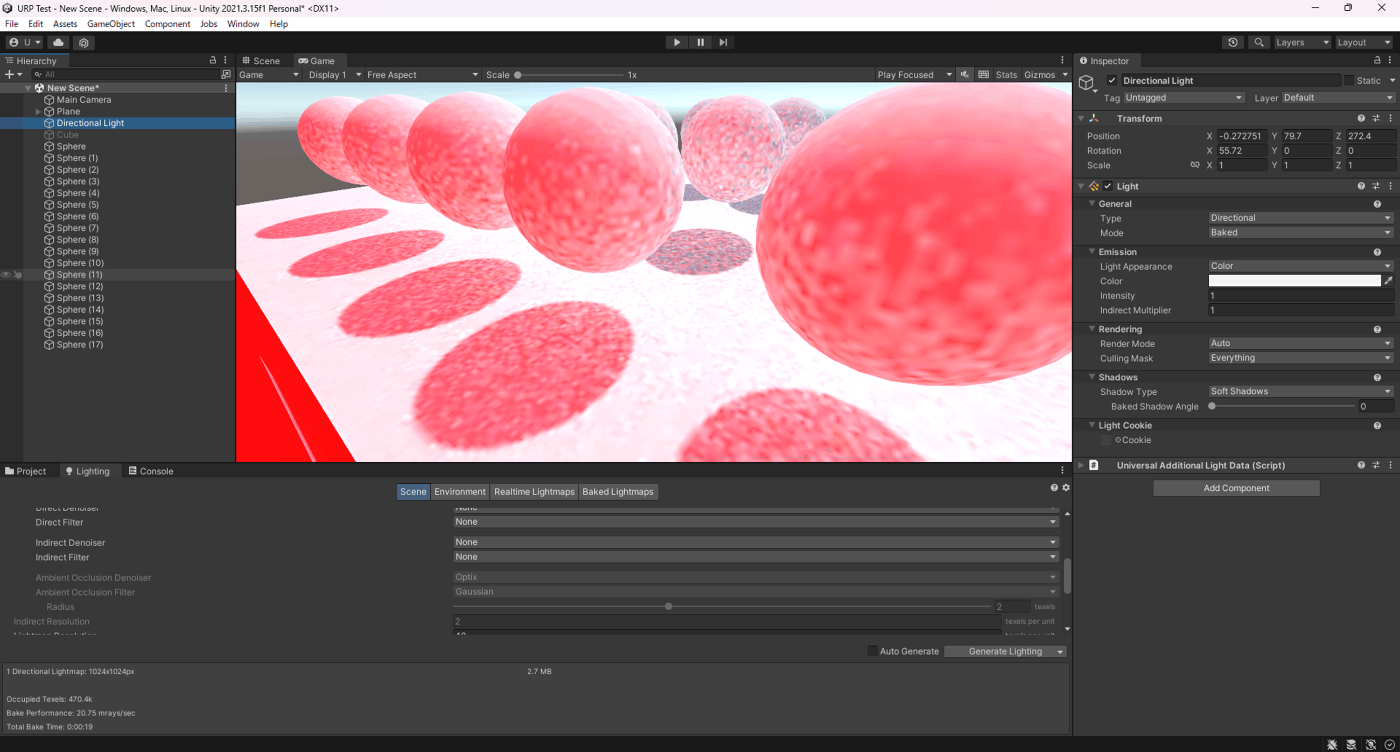
②Optix
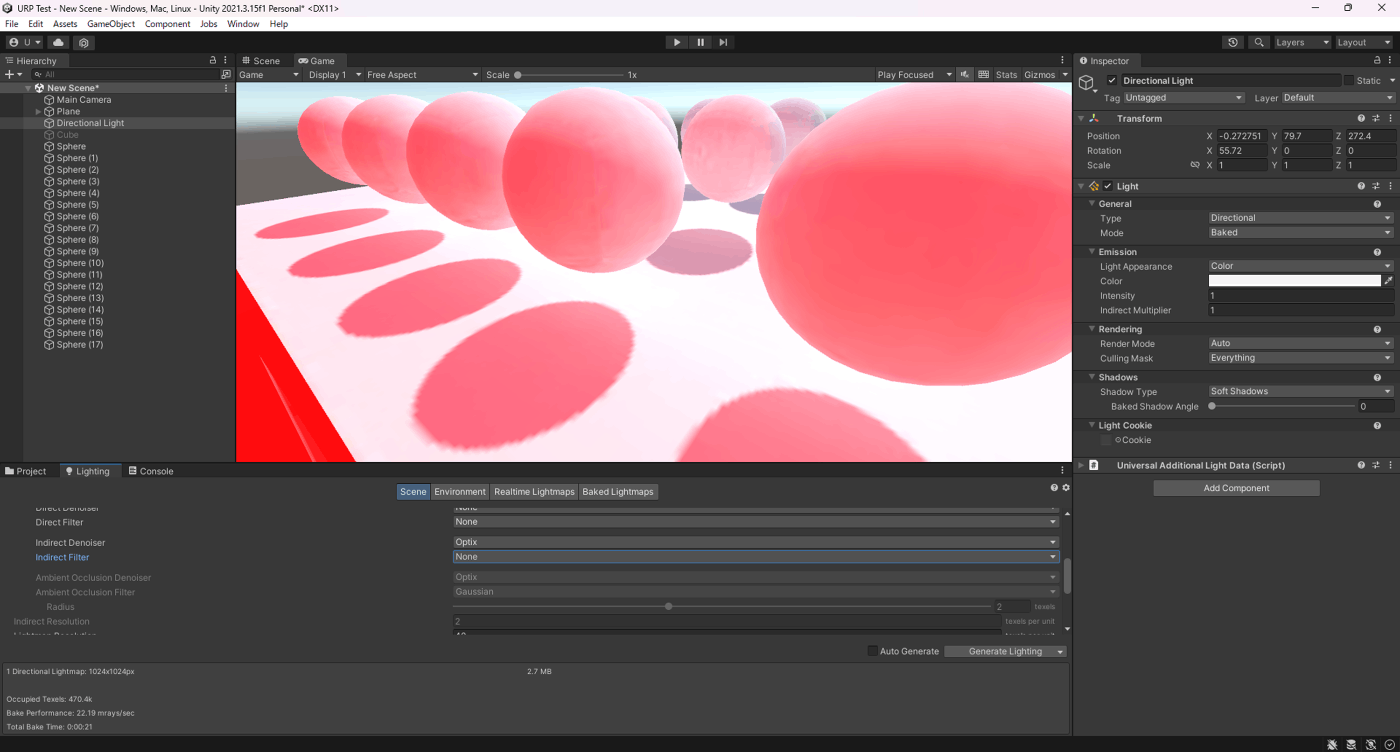
③OpenImageDenoise
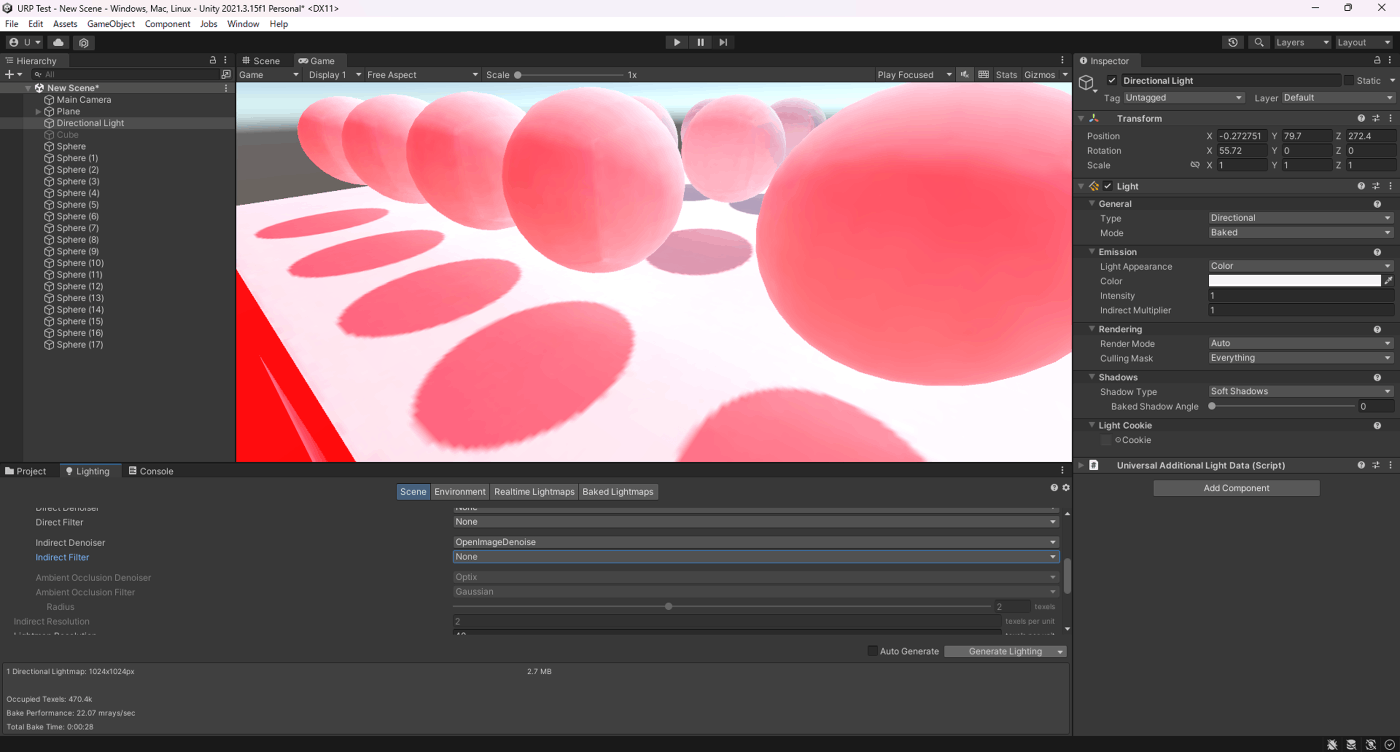
④RadeonPro
参照サイト、参照サイト
・Lightmap Resolutionの検証
ライトマップの解像度を 1Unit あたりのテクセル数を設定する。
Lightmap Resolutionを上げることでライトマップの品質が上がるが、ベイクする時間が長くなるし、メモリ負荷も増える。
①Lightmap Resolutionが40
①Lightmap Resolutionが1
参照サイト、参照サイト
・Lightmap Paddingの検証
ライトマップ上に UV を展開する時、異なるオブジェクトをどれだけ距離を離して配置するかを設定する。
無駄な隙間をなくすことでライトマップ容量を減らすことができ、ディスク容量やメモリ容量やベイク時間を削減できる。
ただし、シーン内に小さなオブジェクトが無数にあり、テクセルが無駄に使われている可能性のある状況でこのパラメーターを使用すると、問題を引き起こす可能性があることに注意。
多数の UV アイランドの間にパディングを追加すると、さらに多くのスペースを浪費することになってしまいます。このスペースは、「Lightmap Size」を使用して制限することができる。
①Lightmap Paddingで2
ライトマップが1.3MB
②Lightmap Paddingで100
ライトマップが2.0MB
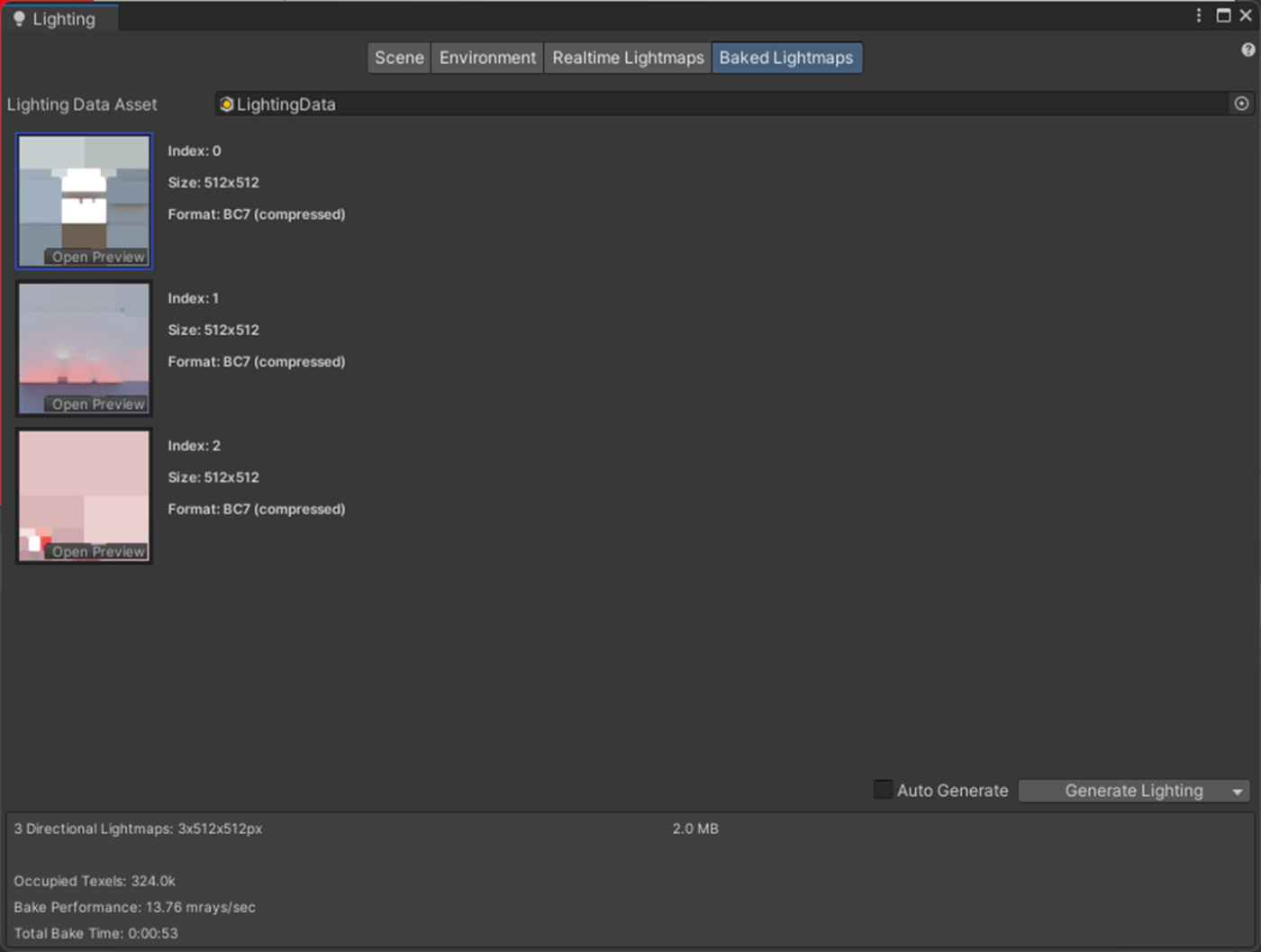
参照サイト、参照サイト
・Max Lightmap Sizeの検証
ライトマップ一枚当たりの最大サイズです。
この値が大きいほど見た目はよくなるが、ベイクに時間かかるし、ディスク・メモリ使用量も多くるなる。
実際に比較してみたが、ライトマップが4096のほうが見た目がきれいだが、ベイク時間やライトマップの容量が多いことが分かる。
①Max Lightmap Sizeが4096
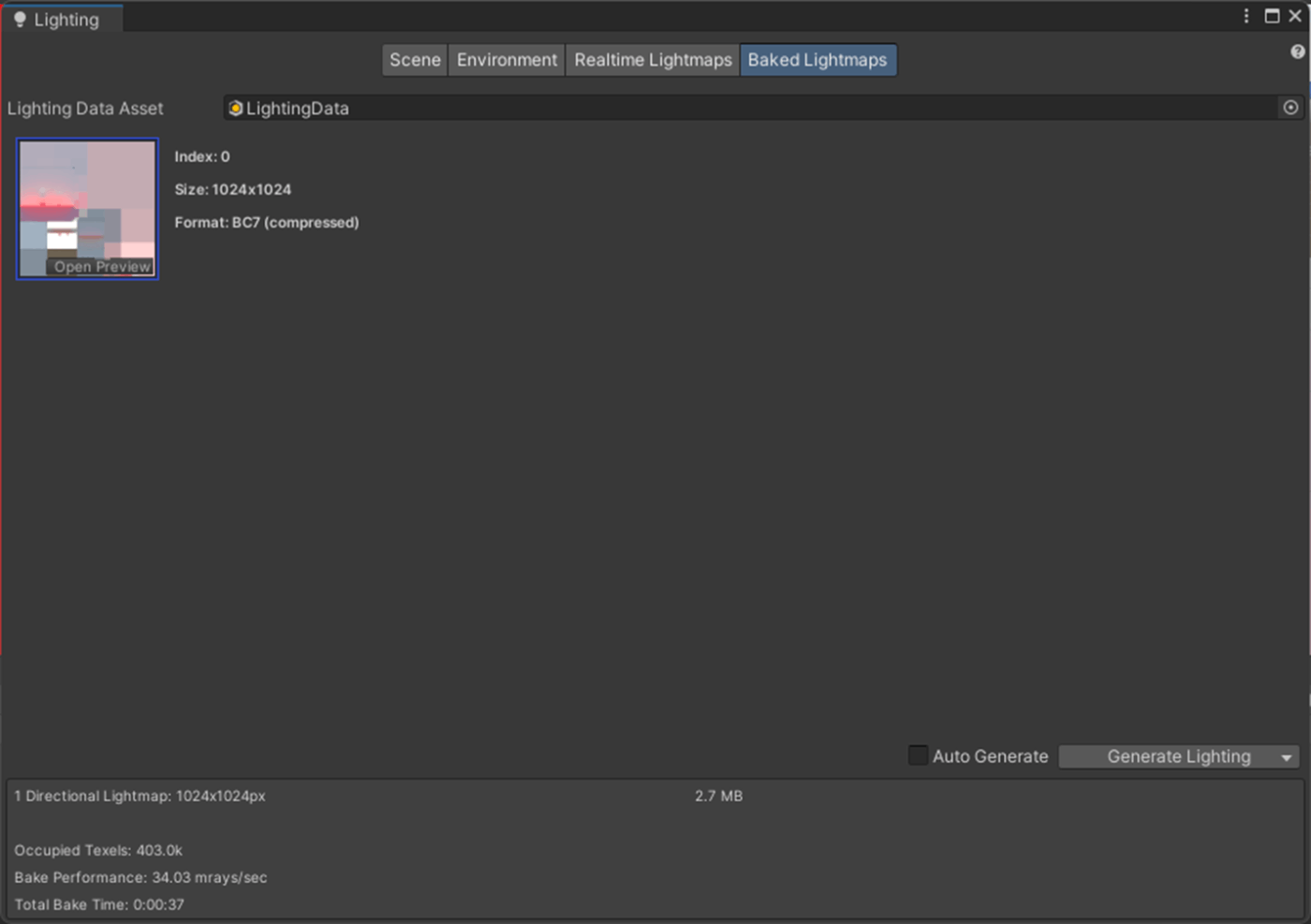
②Max Lightmap Sizeが32
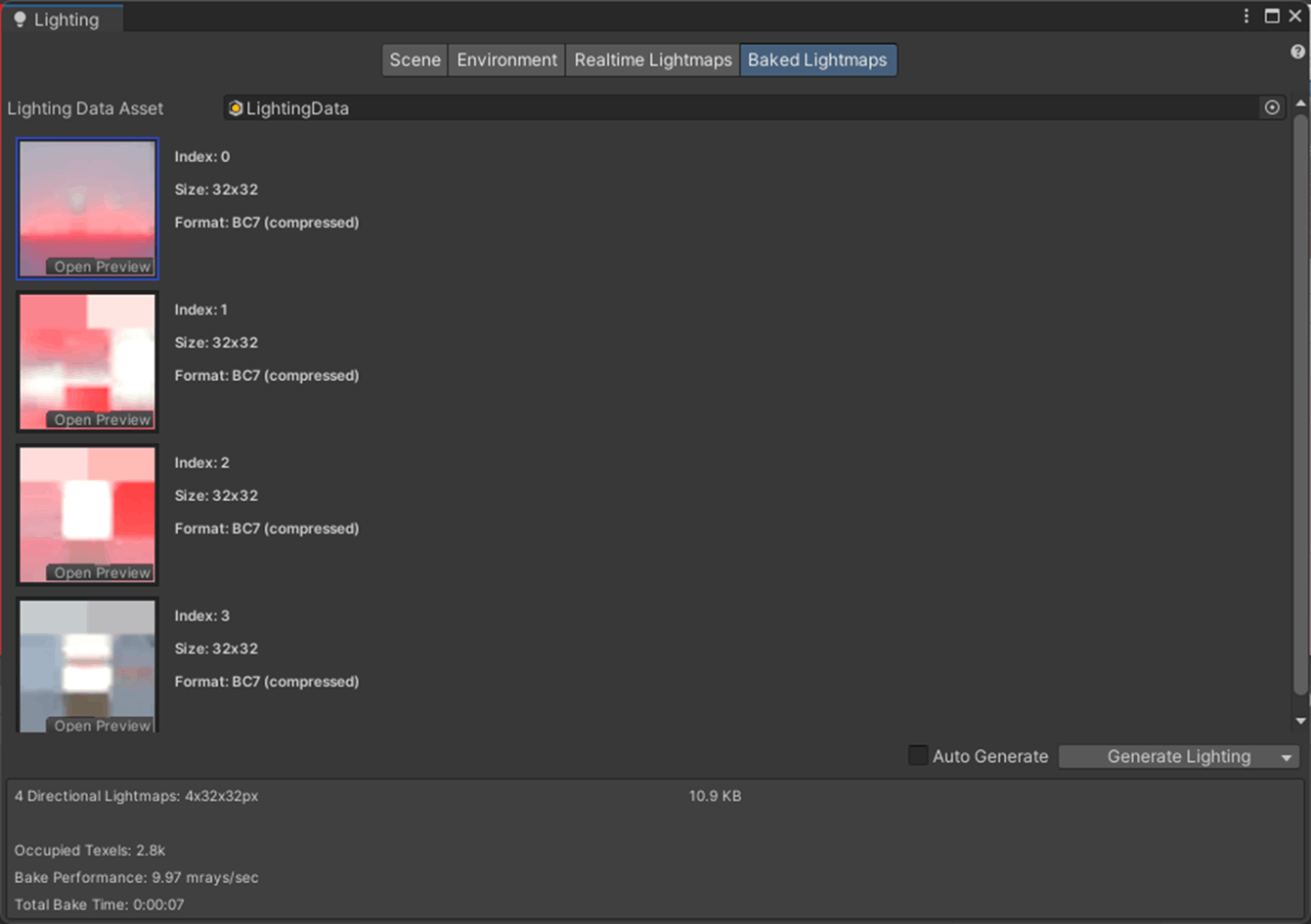
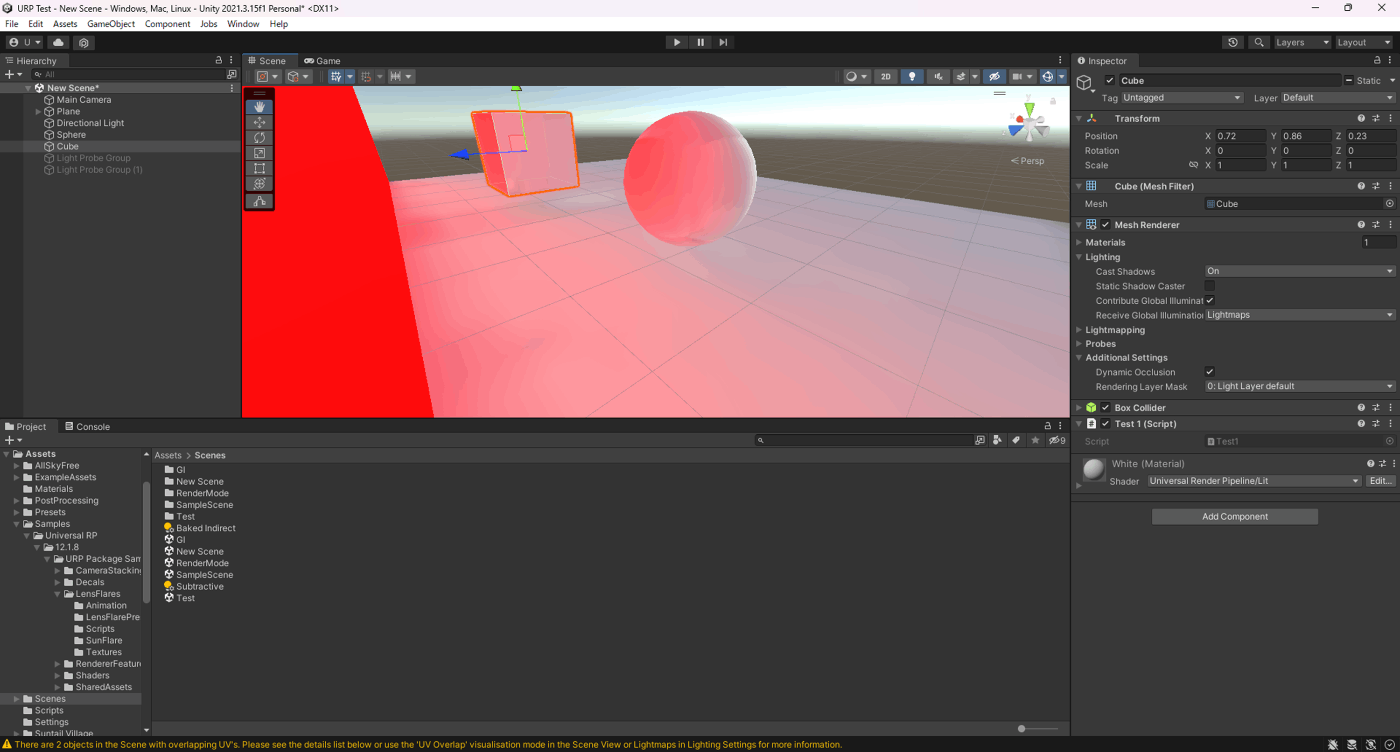
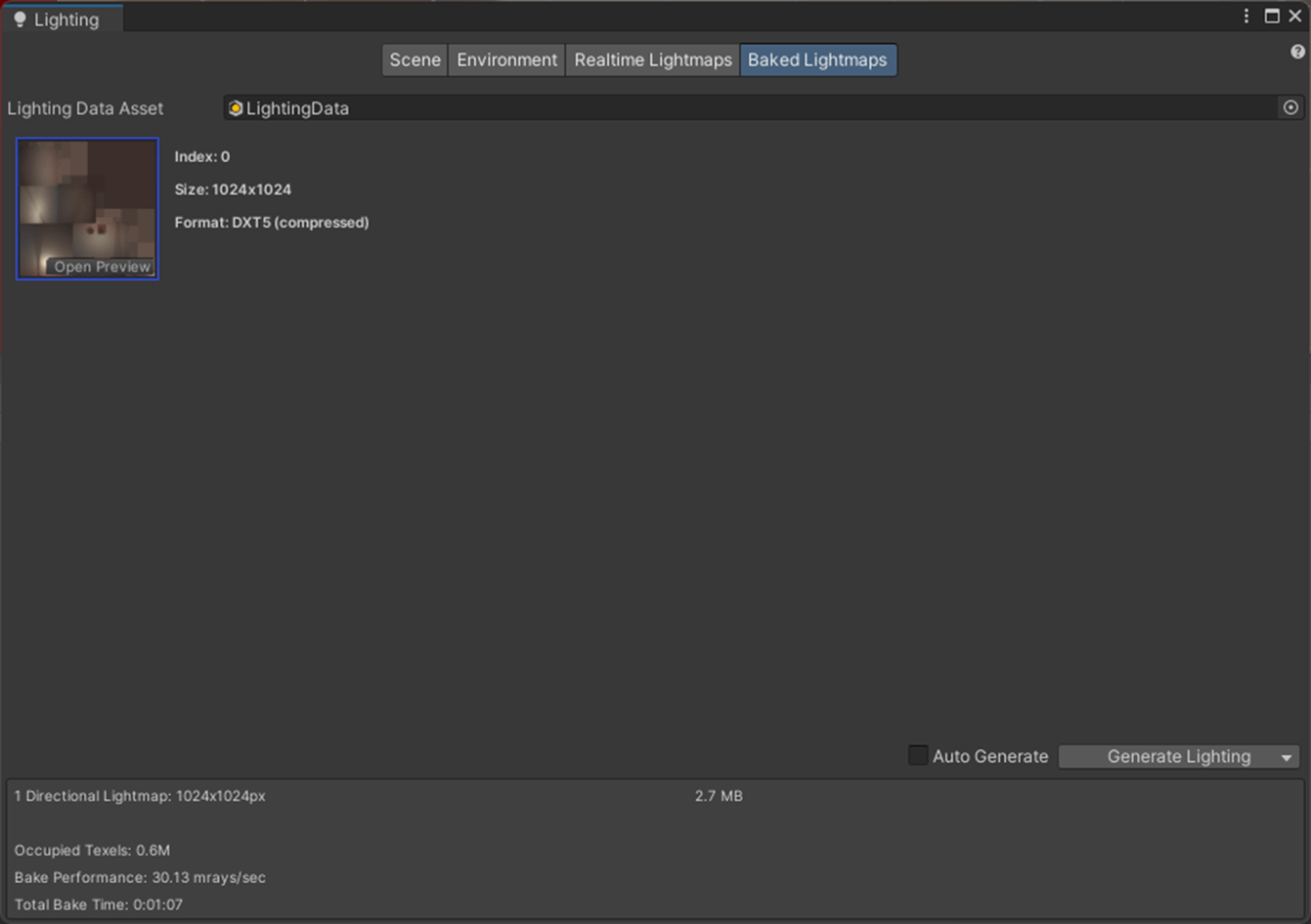
・Lightmap compressionの検証
ライトマップの圧縮を設定できる。
以下のような結果となった。
| Lightmap compression | サイズ | ベイク時間 | 見た目 |
|---|---|---|---|
| None | 10.7MB | 1分10秒 | 影も間接光も綺麗 |
| High Quality | 2.7MB | 1分11秒 | 影も間接光も汚い |
| Normal | 2.7MB | 1分07秒 | Noneと比べても変わらないくらい綺麗 |
①None
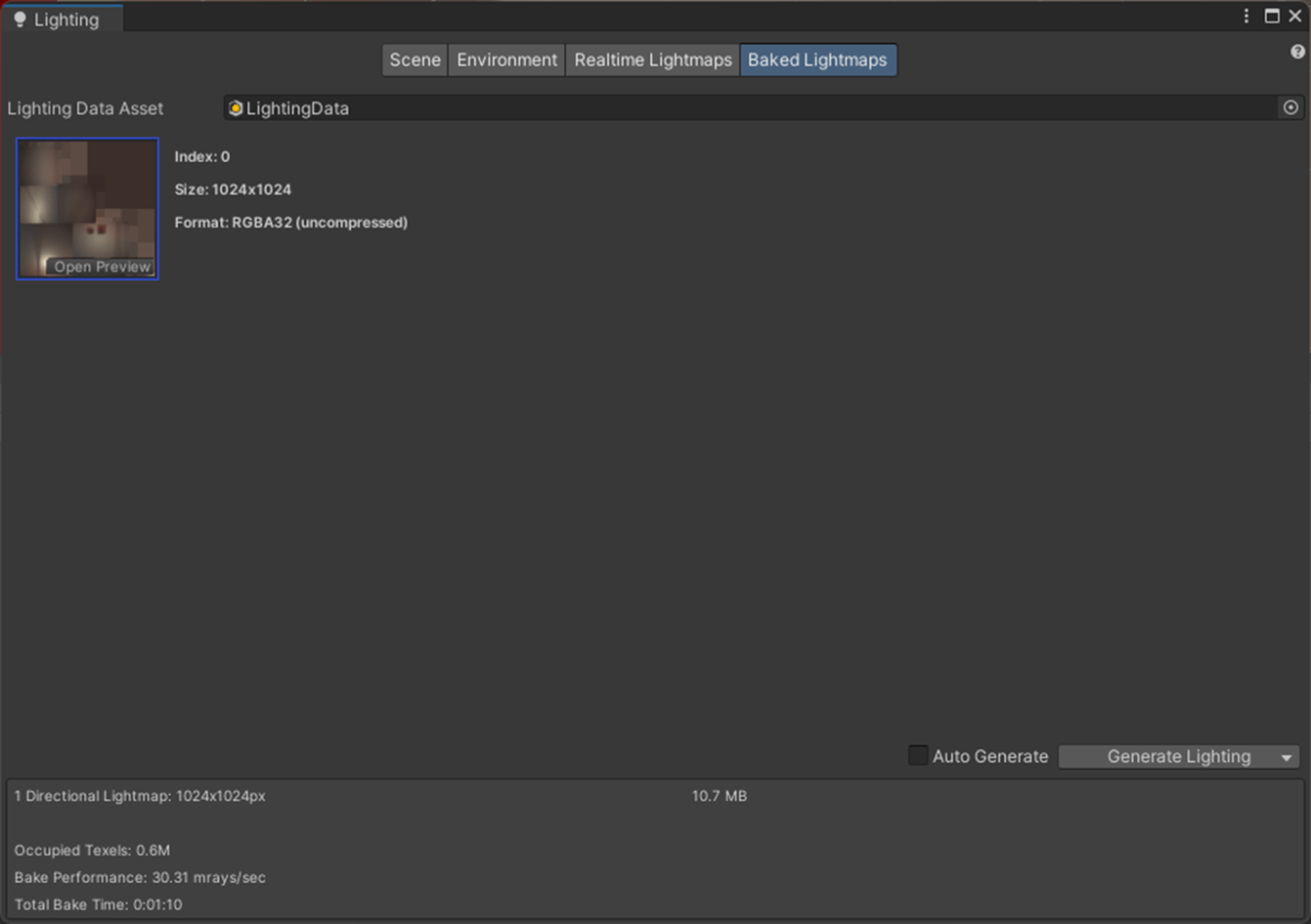

②High Quality


③Normal

参照サイト
・Directional Modeの検証
Directional にするとライトマップに、主なライトの方向と、その主な方向から受けた光が全体のどのくらいの割合を占めるかを表す係数が格納される。
Directional にすることで、ノーマルマップの情報などが反映される。
ただ、ベイク時間とメモリ・ディスク容量が増えてしまう。
①Directional

②Non-Directional

参照サイト
・Lightmap Parameters アセットのResolutionの検証
これはリアルタイムライトマップの解像度をスケールで指定する。この値が1であれば、ライトマップ1テクセルを1unit、2であれば2テクセルを1unit に割り当てる。
値を大きくすれば、1unit に割り当てるテクセル数が大きくなるので解像度が上がりますが、その分テクスチャマップのサイズが大きくなる。
実際に検証してみたが、Resolutionが大きい方がメモリ容量が多いことが分かる。
ただ検証してみた感じだと、Resolutionが大きいと間接光がうまく反映されていないことが分かる
①Resolutionが1
③Resolutionが70

参照サイト
・Lightmap Parameters アセットのCluster Resolutionの検証
クラスターは、GIを計算するときに必要なものである。
以下ドキュメント抜粋。正直よく分からない。
スケールが正しく設定されていないとメモリを大量に消費する可能性があります。 メモリの消費率が高い場合、またはベイク時間が長い場合は、シーンの静的ジオメトリが必要以上に多くのクラスターに分割されている可能性があります。
通常、この解像度は、使用する照明環境の種類によって異なりますが、最終的な品質を大幅に低下させることなく、リアルタイム ライトマップの解像度よりわずかに低くすることができます。小さくて明るい光源を正確にキャプチャするには、Enlighten Realtime Global Illumination の clusterResolution を高くする必要があります。
クラスターの解像度は、リアルタイムのライトマップの解像度で乗算されます。値が大きいほど、クラスターの解像度が高くなります。1 の値は、リアルタイム ライトマップの各テクセルを 1 つの入力クラスターと一致させます。
非常に小さなクラスター解像度を使用すると、出力テクセル全体に光がにじみます。値を大きくしても品質は大幅に向上しませんが (最終的な出力テクセルのために平均化する必要があるため)、時間とメモリ フットプリントが不必要に増加する可能性があります
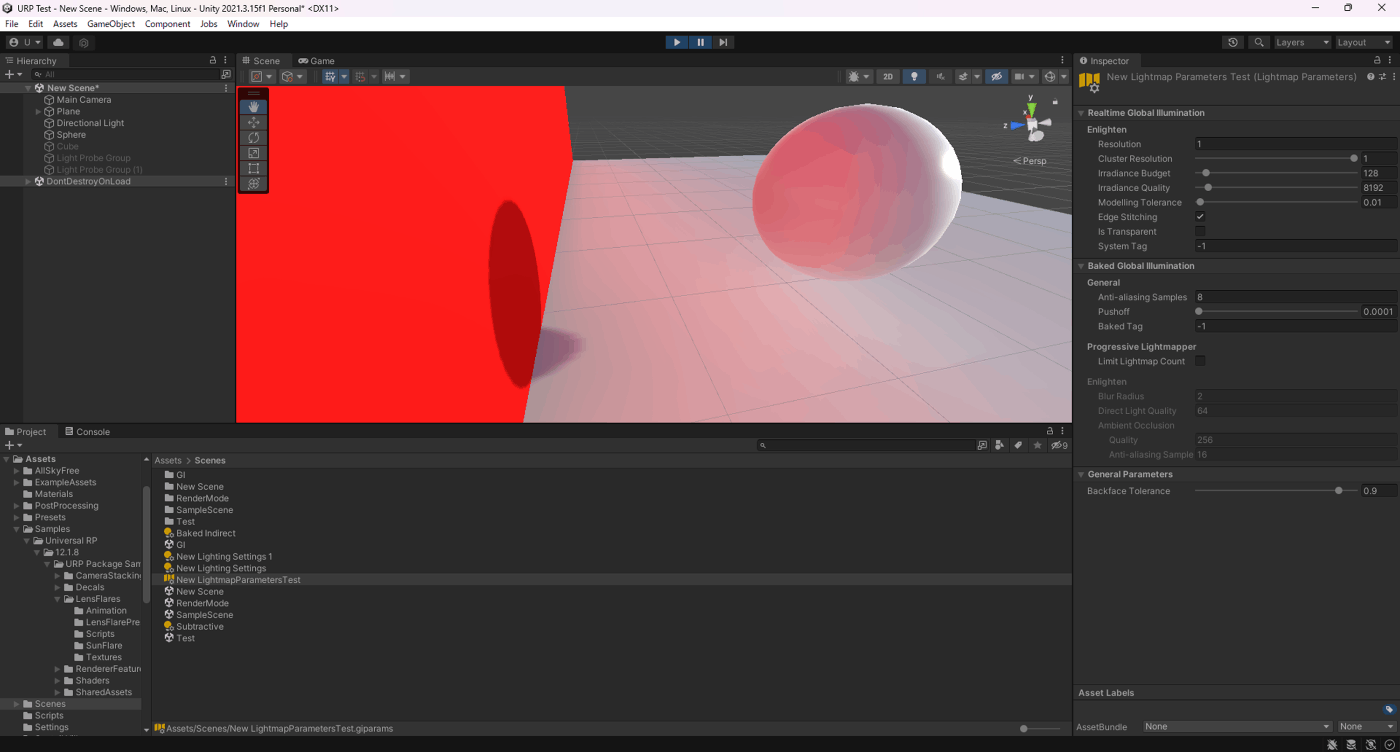
①Cluster Resolutionが0.1
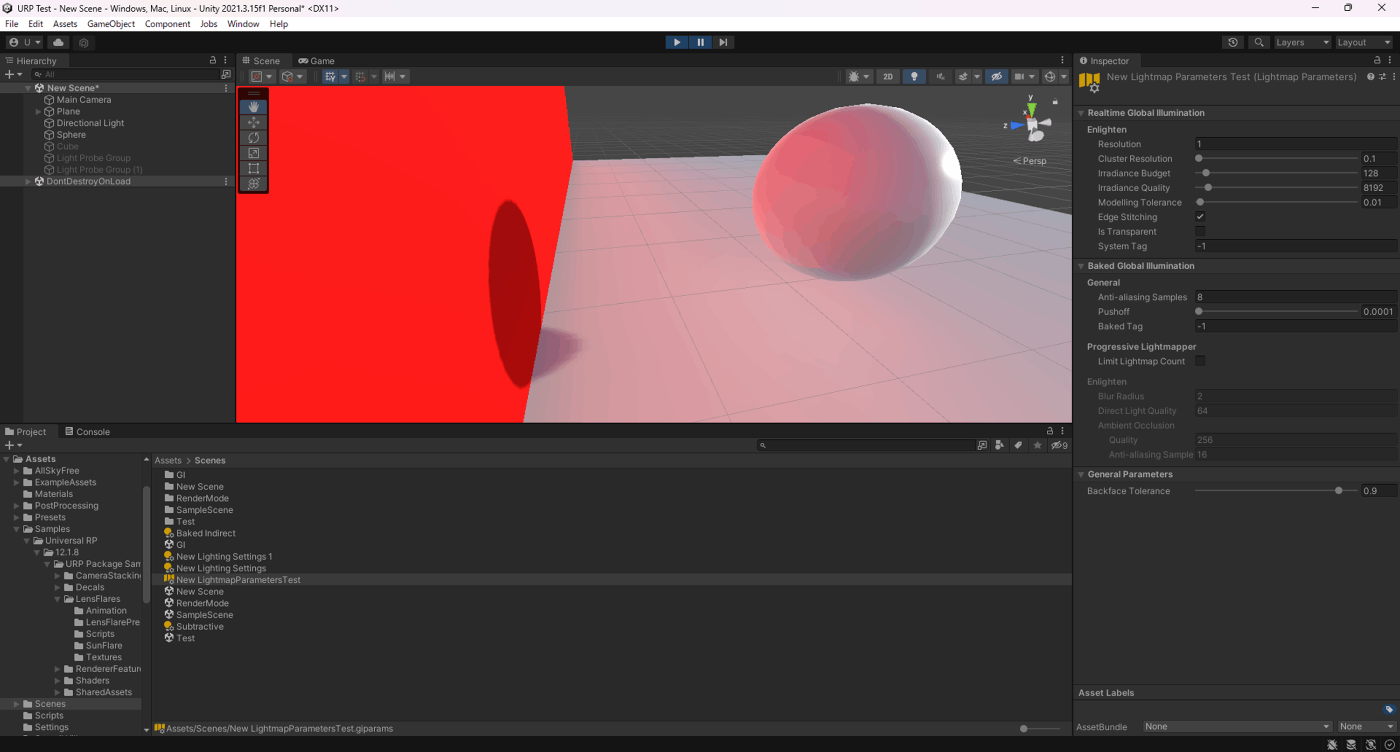
①Cluster Resolutionが0.5

③Cluster Resolutionが1

参照サイト、参照サイト、参照サイト
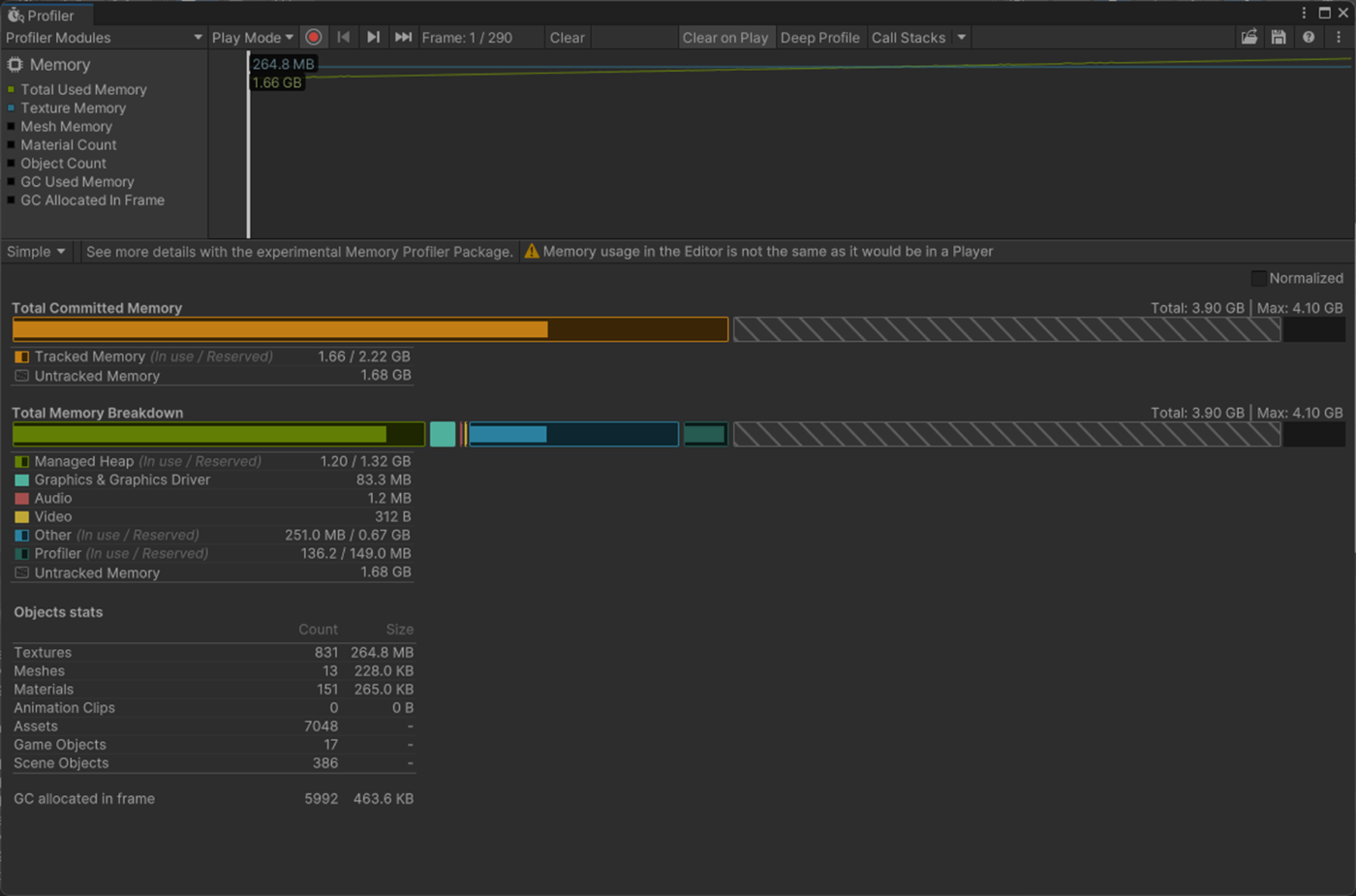
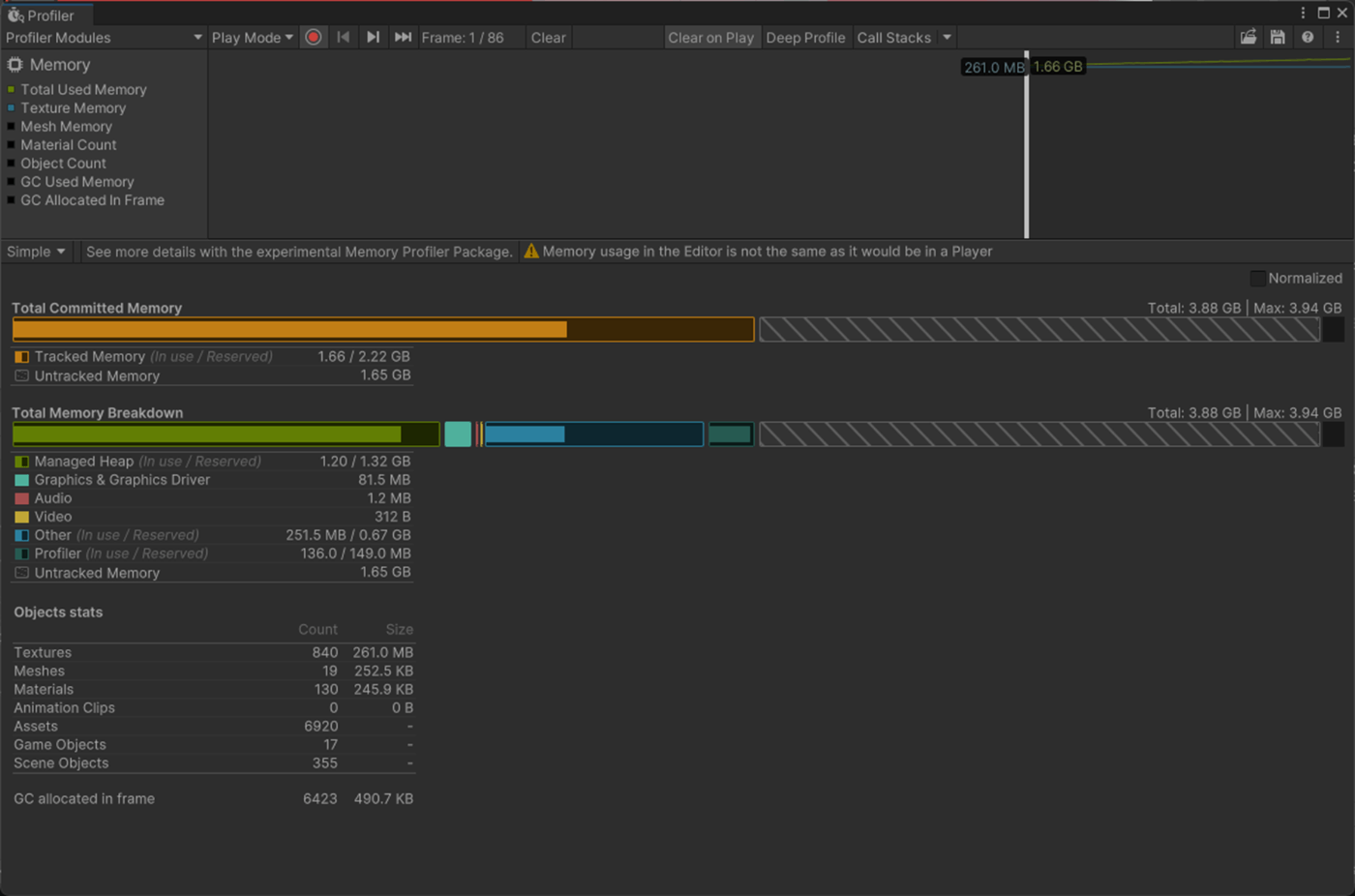
・Lightmap Parameters アセットのIrradiance Budgetの検証
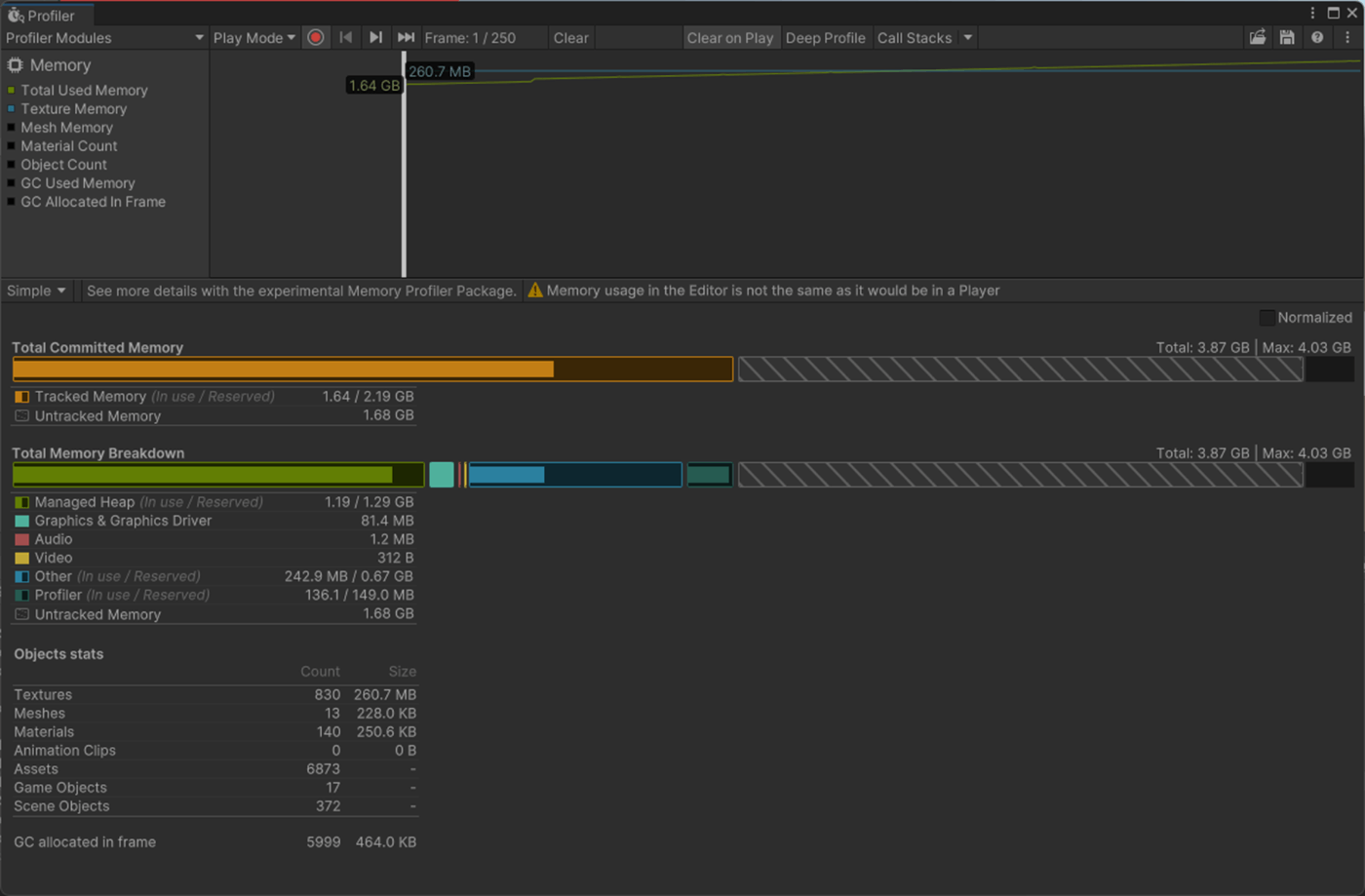
これはライトマップの各テクセルを照らすために使用される入射光のデータの精度を設定する。
これを大きくすると実行時のメモリとCPU コストが増え、見た目が良くなるとドキュメントに書いているが検証したかんじそこまで変化が見られなかった。
①Irradiance Budgetが128
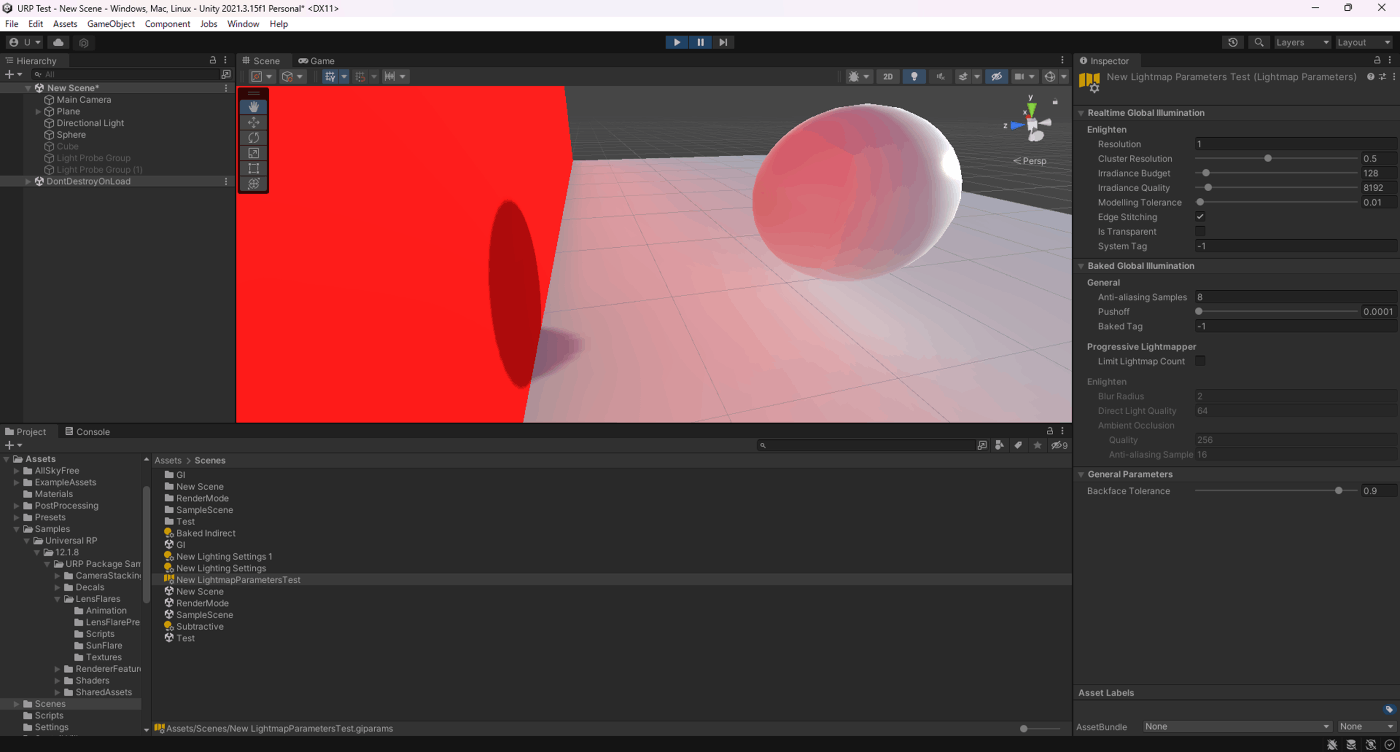

②Irradiance Budgetが2048
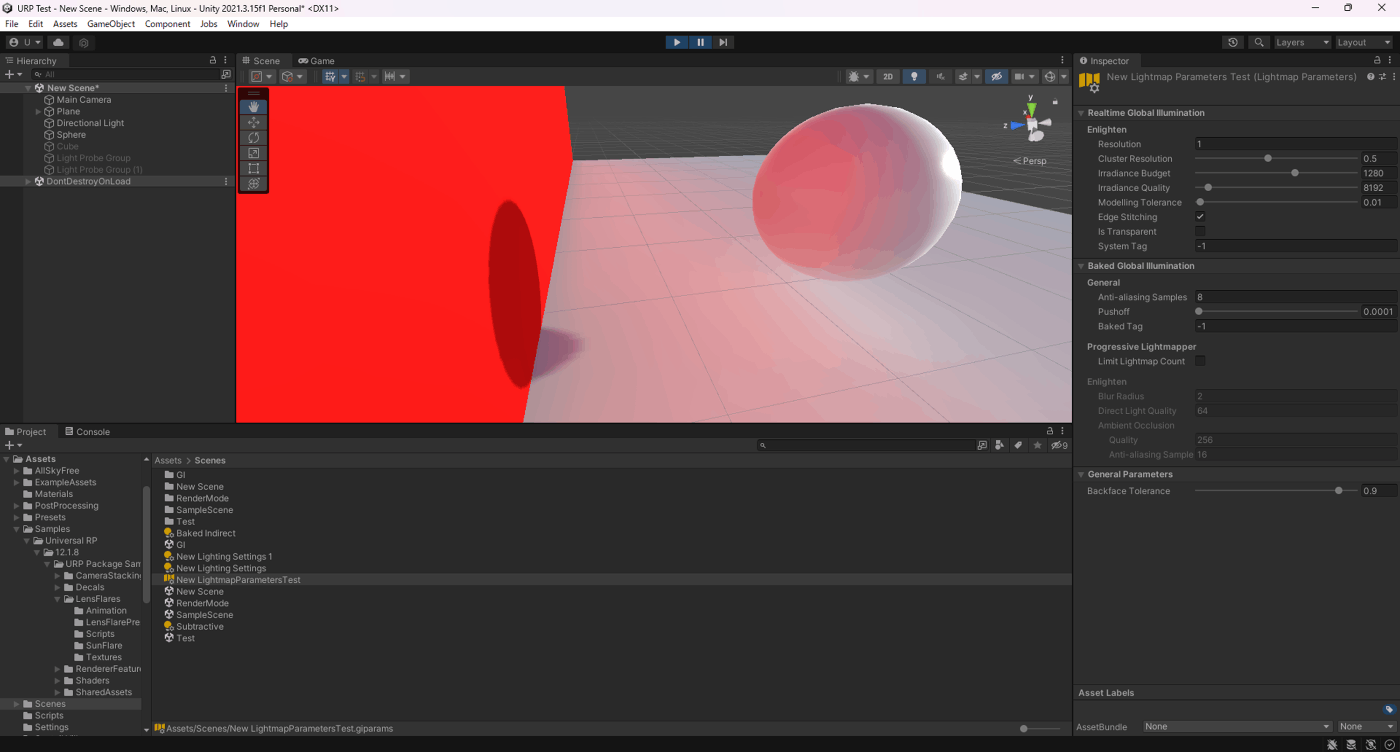
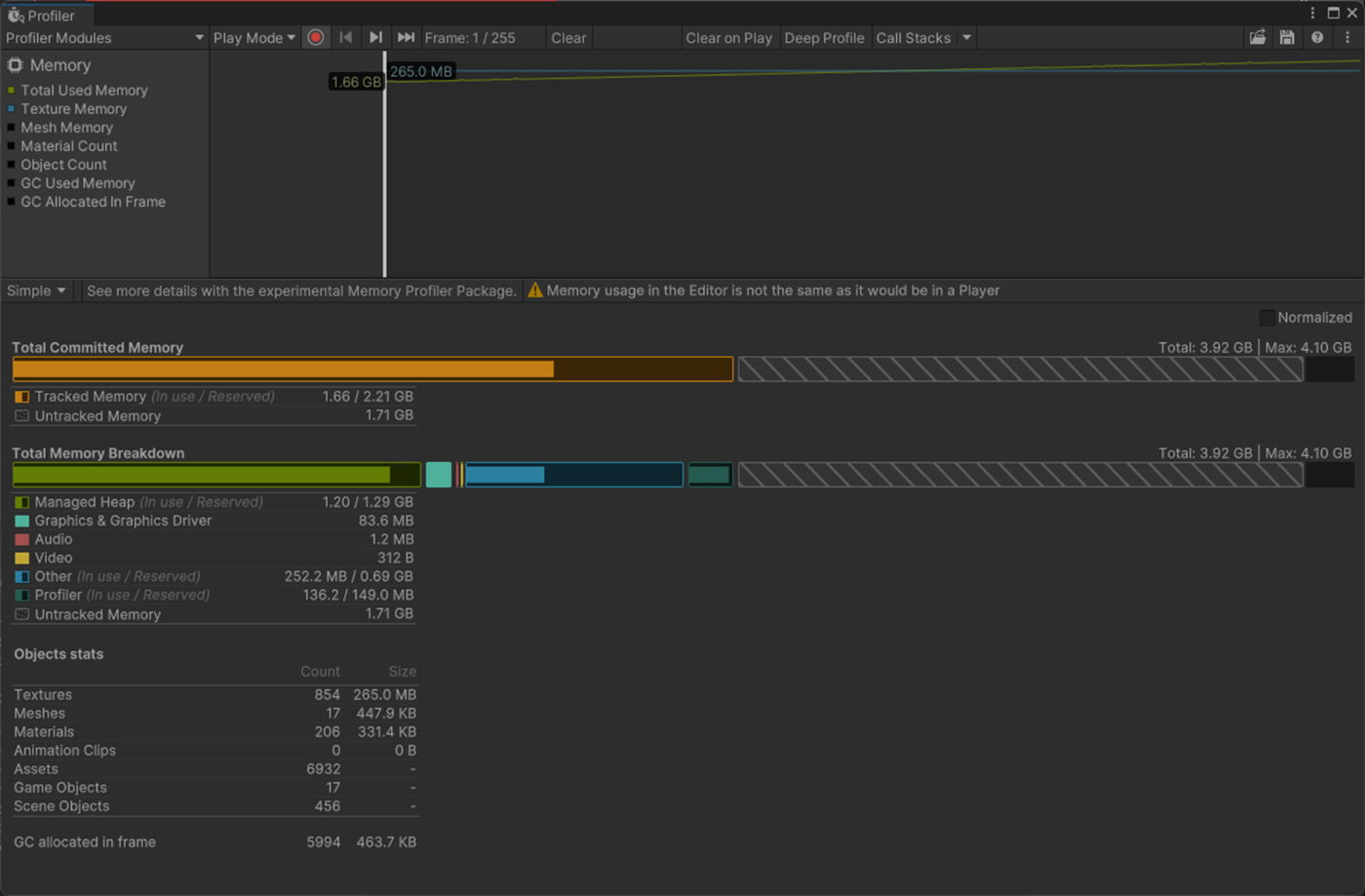
参照サイト
・Lightmap Parameters アセットのIrradiance Qualityの検証
レイの数を定義する。そのレイはキャストし、指定した出力ライトマップのテクセルに影響するクラスターを計算するために使われる。
公式ドキュメントでは、以下のように書かれている。
実際検証したところ、見た目もそこまで変わらず、パフォーマンスもそこまで変わらなかった。
値を大きくすると、ライトマップの見た目が向上しますが、Unity エディターの事前の計算時間が増加します。この値は、ランタイムのパフォーマンスには影響しません。
①Irradiance Qualityが8192

①Irradiance Qualityが131072



参照サイト
・Lightmap Parameters アセットのModelling Toleranceの検証
間接光が反射する際のオブジェクト同士の隙間の最小サイズを指定する。
その隙間がとても狭い場合、そもそもユーザーに見えない空間の計算にベイク時に無駄な時間を消費することになる。
なので、こういう場合Modelling Toleranceを大きくすることでメモリ使用量を削減できる。
実際に検証してみたが、メモリは若干であるがModelling Toleranceが大きい方がメモリ容量が少ないのが分かる。
また、間接光が通らないので黒くなっていることが分かる。
①Modelling Toleranceが0.01

②Modelling Toleranceが1

参照サイト
・Lightmap Parameters アセットのEdge Stitchingの検証
ゲームオブジェクトの不要な尖ったエッジを滑らかにする機能。(詳しい詳細はこちら)
検証してみたかんじ、若干メモリ容量がオンのほうが多いことが分かる。
①Edge Stitchingをオン
②Edge Stitchingをオフ

参照サイト
・Lightmap Parameters アセットのIs Transparentの検証
対象のメッシュを透明にして間接光の計算させないこと?。(あまり自信ない)
透明にしたいメッシュ用にLightmapParametersアセットを用意し、MeshRendarer で個別に設定すると良い。
オフだとメッシュを透明にしている影響か間接光がオンに比べて反映されていないことが分かる。
また、オフだと間接光の計算をしていないので、CPUとメモリの負荷がわずかながら削減されていることが分かる。
①Is Transparentがオフ

②Is Transparentがオン
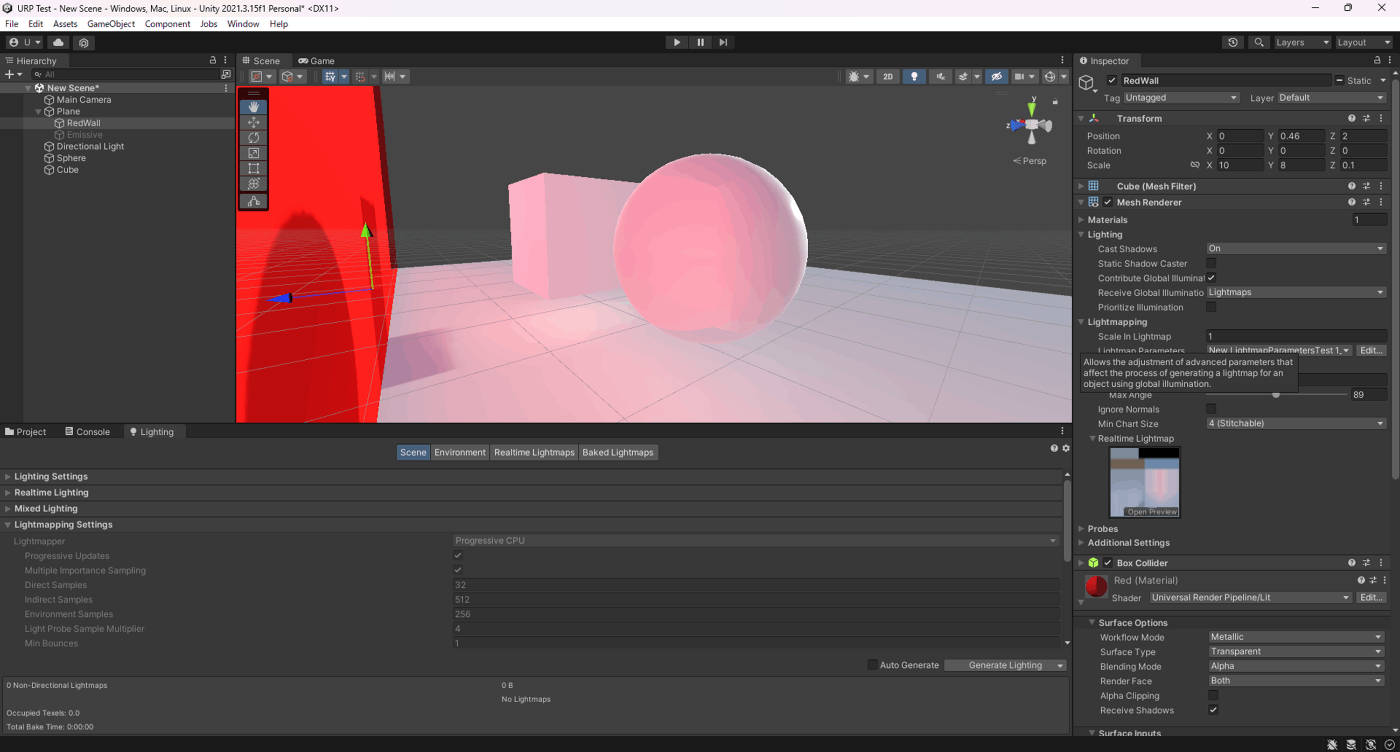

参照サイト
・Lightmap Parameters アセットのBlur Radiusの検証
直接光のぼかし具合を調整する設定。
ライトマップサイズは変わらなかった。
この値を大きくすると、陰影がぼかされていることが分かる。
なお、Enlighten Baked Global Illuminationのみ対応している。
①Blur Radiusが2

②Blur Radiusが8

参照サイト
・Lightmap Parameters アセットのAnti-aliasing Samplesの検証
エイリアシングを減らすためにテクセルをスーパーサンプリングする回数を設定する。
256段階で値を調整できるが、1~3はサンプリングなし、4~8は2×スーパーサンプリング、9~256は4×スーパーサンプリングとなる。
ドキュメントには、サンプリング回数を増やせばメモリ使用量が増えると記載されているが、検証したところライトマップのサイズは同じでベイク時間が違っている。
①Anti-aliasing Samplesが1

②Anti-aliasing Samplesが256
参照サイト
・Lightmap Parameters アセットのPushoffの検証
レイの反射を計算する際に、法線方向にジオメトリを押し出す量を指定する。表面に細かな凹凸を持つジオメトリの場合、それらの間でレイが反射してしまい、表面に不自然な陰影が生まれる場合がある。計算時のみ押し出すことで、その凹凸を無視することができる。直接光、間接光、AOすべての計算で使用される。
検証したかんじで、ライトマップサイズは変わらず、Pushoffが大きいほど黒くなくなっている。
①Pushoffが0.0001

②Pushoffが1
参照サイト、参照サイト
・Lightmap Parameters アセットのBaked Tagの検証
別の数字を設定すると、それらは同じテクスチャマップにパックされなくなる。
ただし、同じ数字にしても必ず同じマップにマージされるわけではない。
メッシュごとに異なっているほうは、メモリ容量が多く、ベイク時間が短く、不自然な間接光が見える。
①Baked Tagがメッシュごとに同じ
②Baked Tagがメッシュごとに異なる
参照サイト
・Lightmap Parameters アセットのBackface Tolerance
以下の設定の詳細は、こちらを抜粋
ライトマップはプリミティブの表面についてのみ UV 展開されており、GI 計算時に放射されるレイはプリミティブの背面に衝突することを想定していません。実際にそれが起きた場合、プリミティブの裏面は常にカラー値として黒を返す(つまり、そこに到達した光はすべて吸収されたものとみなす)ことになっていて、これが意図しないアーチファクトを発生させます。
このアーチファクトを回避するために、GI計算では、放射したレイの中でプリミティブ背面に到達し
たレイの割合に応じて、その演算を無視し、近隣のテクセルから計算結果を流用する仕組みが用意されています。
この演算を無視する際のレイの割合の許容範囲を表すのが Backface Tolelanceです。0.0の時は、すべてのレイがプリミティブ背面に到達した場合のみ、その演算を無視します。逆に 1.0 の時は、1本でもレイがプリミティブ背面に到達した場合は、その演算を無視します。
・ライトマップのLODをScale In Lightmapで調整
MeshRenderのScale In Lightmapを調整してLODごとにライトマップのサイズを変えて、メモリ容量やベイク時間を削減する。
検証したところ、ライトマップのサイズとベイク時間が減っていることが分かる。
①全てScale In Lightmapが1
②Scale In Lightmapが1、0.1、0.01

なお、LODごとのライトマップの切り替わりは以下の動画にしてみた
また、描画モードで、解像度で差異が出るか確認してみた。
参照サイト、参照サイト、参照サイト
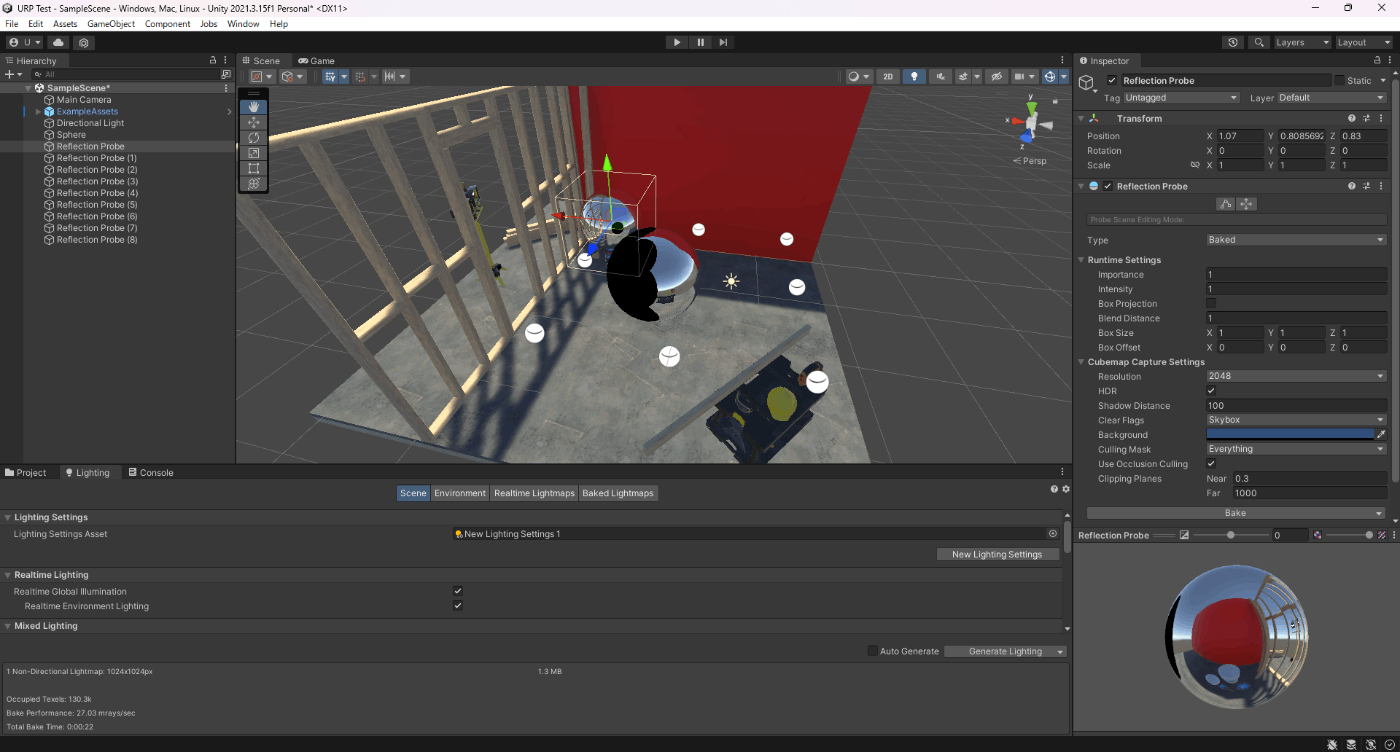
・リフレクションプローブのResolution
こちらは解像度を設定する
高い解像度を設定すると、品質が高くなるがベイク時間が長くなったり、メモリ容量が大きくなったりする。
使い分けは、映り込むオブジェクトが小さい、または、遠くにある場合、その詳細は自然と表示されなくなるので低解像度に。詳細をはっきり表示しようとする場合は、高解像度に。
①Resolutionが24
ベイク時間が0:19
②Resolutionが2048
ベイク時間が3:12
参照サイト
・リフレクションプローブのCulling Mask
リフレクションさせるオブジェクトを設定する。
反射しなくてもいいオブジェクトを除外することでパフォーマンスやベイク時間を節約できる。
以下のようにリフレクションプローブをたくさん配置して検証してみたところ、ベイク時間とメモリ容量が多少は減ったことがわかる。
①Everything
ベイク時間が1分30秒
②Nothing
ベイク時間が1分20秒
・リフレクションプローブのRefresh Mode
リアルタイムプローブの更新タイミングを設定できる。
一番重い処理は、Every Frame。Via Scripting で状況に応じて更新をせずに最適化を図ることができる。
一応挙動も見てみた。
①On Awake
こちらは、リフレクションプローブがアクティブになった開始フレームを更新タイミングとする。なので通常は一回のみ。
②Every Frame
こちらは、毎フレーム更新される。
③Via Scripting
スクリプトで更新タイミングを制御
using UnityEngine;
public class ViaScriptingTest : MonoBehaviour
{
public ReflectionProbe reflectionProbe;
void Update()
{
//右クリック
if (Input.GetMouseButtonDown(1))
{
reflectionProbe.RenderProbe();
}
}
}
リフレクションプローブのTime Slicing
リフレクションプローブを完全に更新するのを複数フレームにわたって分割できる。
処理の軽さは以下の順
Individual Faces>All Faces at Once >No Time Slicing
リフレクションの正確さは以下の順
No Time Slicing>All Faces at Once>Individual Faces
参照サイト、参照サイト
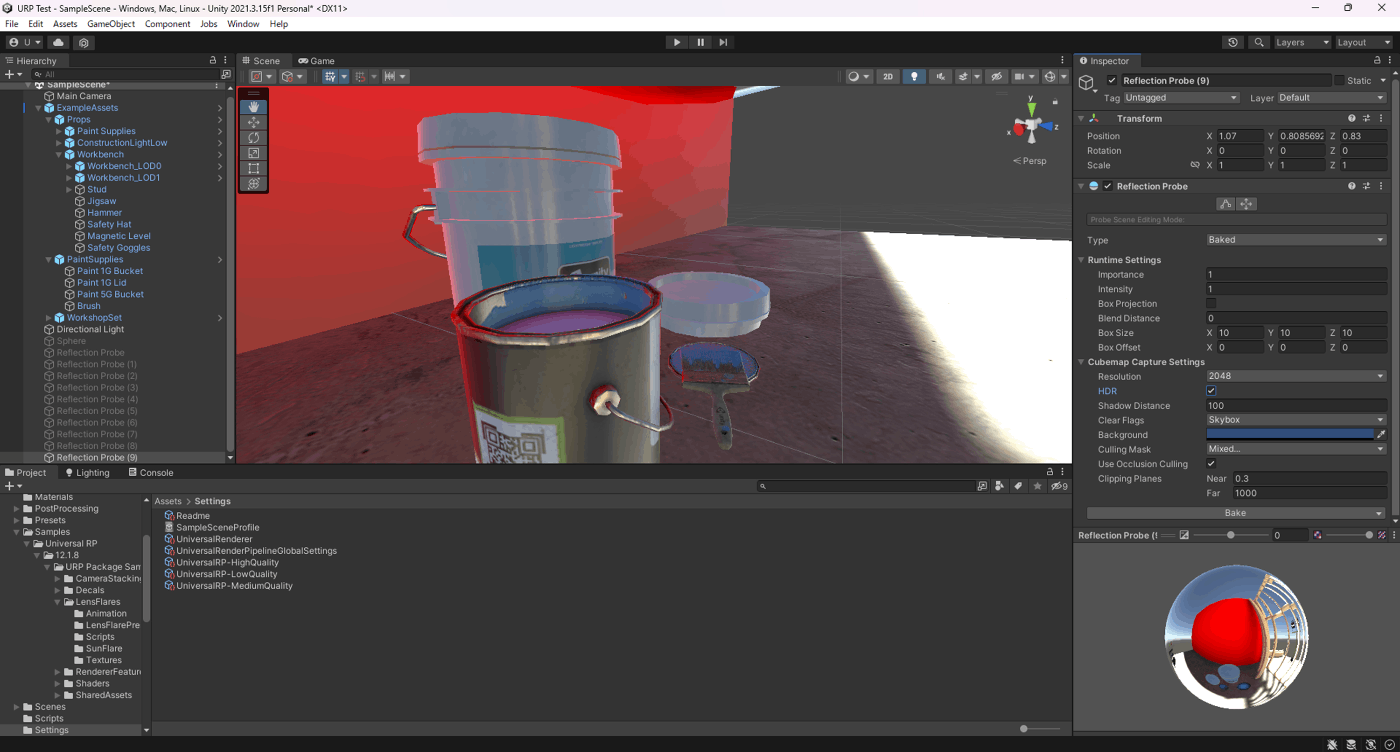
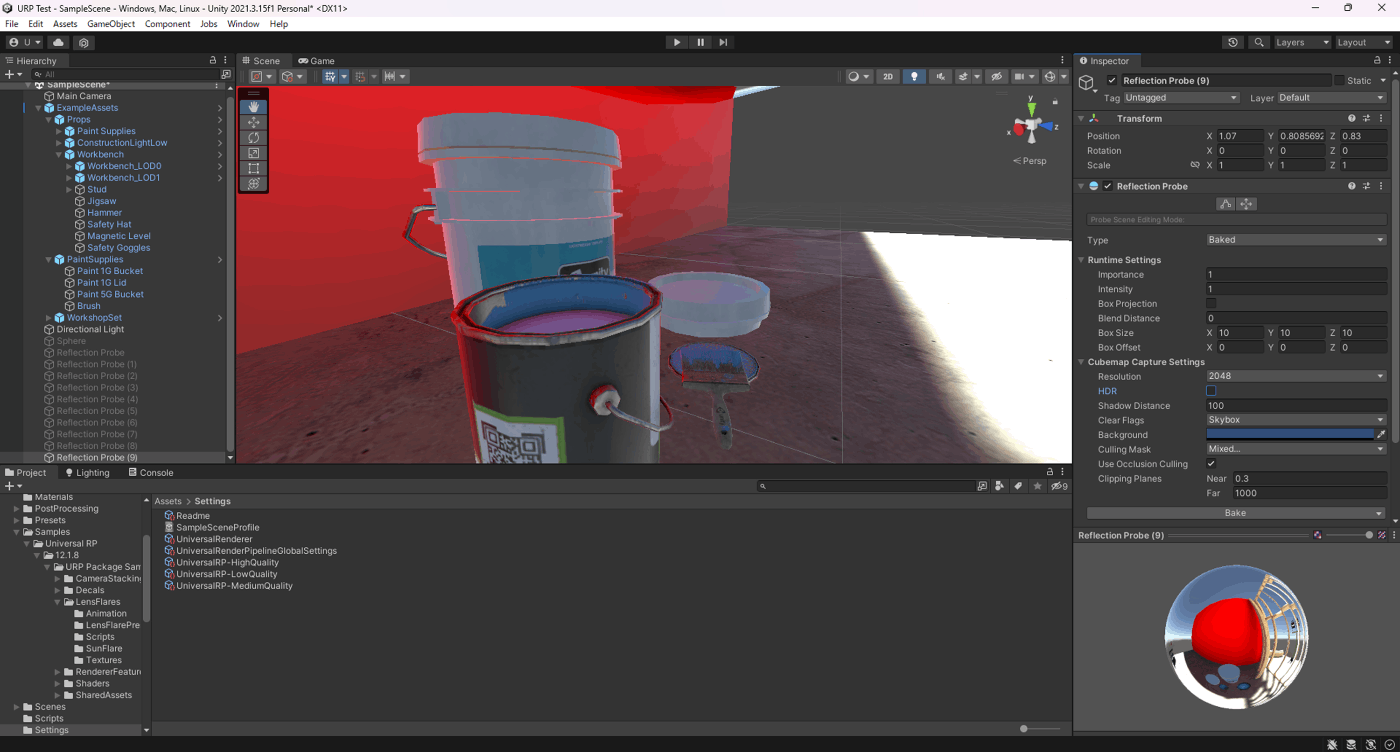
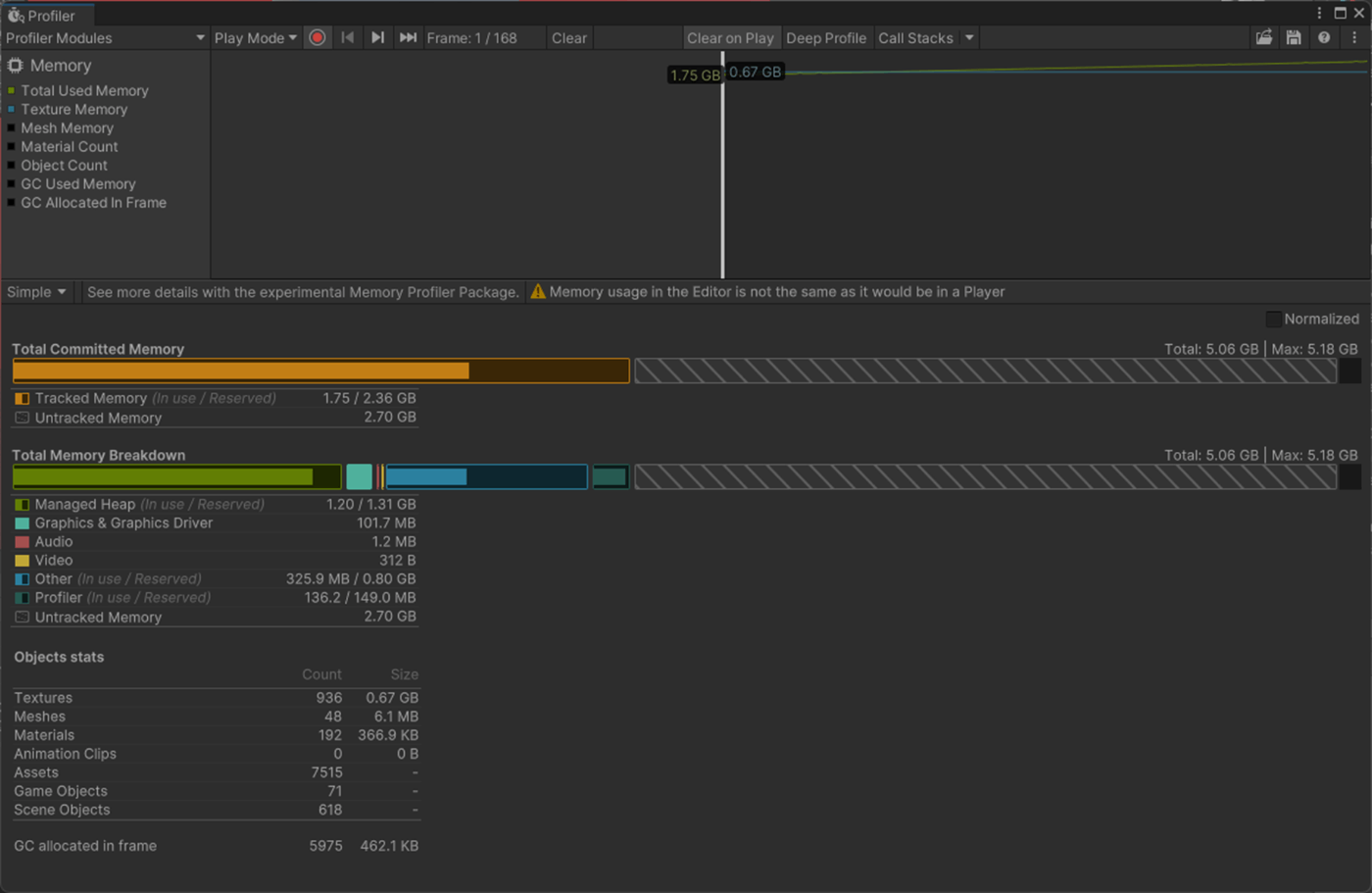
・リフレクションプローブのHDR
リフレクションプローブにHDRを適用させるか否か
適用させるとHDRで描画できるので見た目がリッチになるが、メモリ容量などが多くなる。
LightのIntesityを50ほどにして、ベイクのリフレクションプローブを検証してみた。
HDRオンのほうが、レンジの高いライトを正しく描画できているが、メモリとベイク時間が長くなっていることが分かる。
①HDRオン
ベイク時間1分

②HDRオフ
ベイク時間43秒
参照サイト
・GIで計算したデータを他のプロジェクトで共有するGI キャッシュ
参照サイト
・プレイヤーから見えないオブジェクトはライトマップの対象にしない
参照サイト
・ライトマッパー の使用中にベイク処理を高速化する際の注意点
・シーン内のベイクおよび混合ライトの数を制限します。
・ベイクしたライトを互いに遠く離れた場所に配置しないでください。他のライトから遠く離れたレベルの端に配置された 1 つのベイク ライトでも、ライト グリッドが引き伸ばされます。これにより、ベーキング速度が遅くなります。
・ピクセルライト、頂点ライト、球面調和関数 (SH)ライトのパフォーマンスについて
参照サイト
・オクルージョンカリングにおける最適化
①GPUで負荷がかかっている場合に大体パフォーマンスが改善される
②オクルージョンカリングのデータメモリに読み込まれるため、メモリ容量が増える
③オブジェクトごとにカリングされるため、オブジェクトが少しでも遮蔽されていないとカリングされない
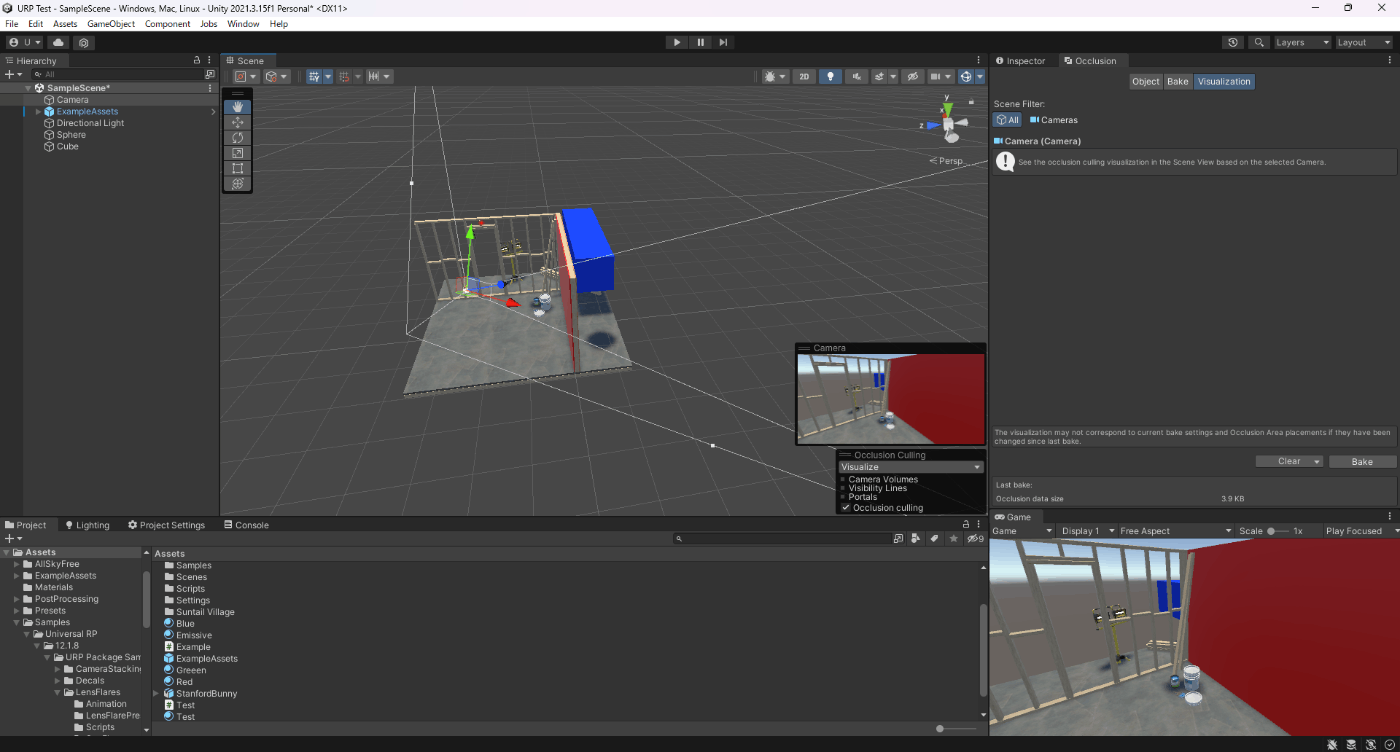
参照サイト、
・MeshRenderのDynamic Occlusionチェックを外して、CPU 使用率を削減できる
※余談
Dynamic Occlusionは、動的オブジェクトをオクルージョンカリングの対象にするものである。
ただ、Dynamic Occlusionオンをオフにして動的オブジェクトはオクルージョンカリングされていた。なぜ?
参照サイト、参照サイト
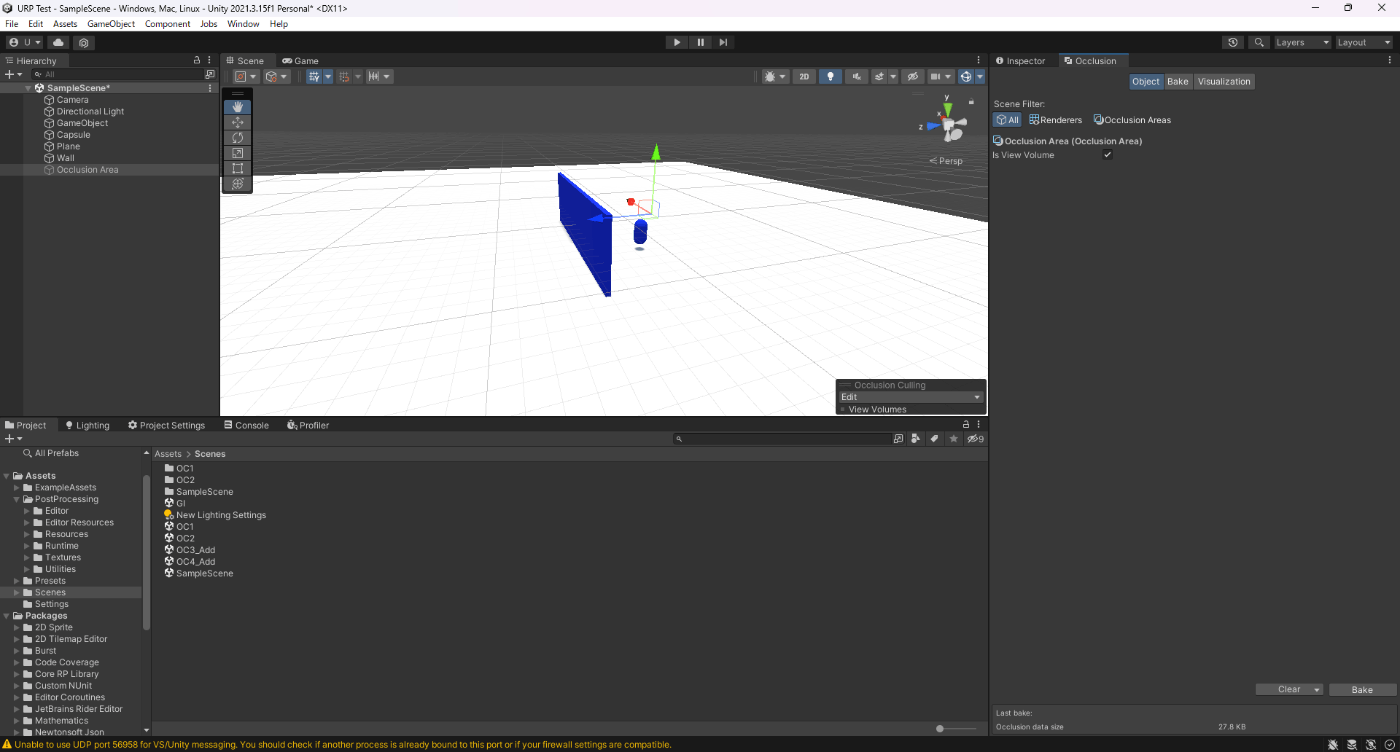
・Occlusion Areaコンポーネントを設定し、パフォーマンスを上げる
Occlusion Areaコンポーネントを使用しないと、Occluder StaticとOcludee Staticとマークされているオブジェクトすべてを均一にベイクする。
なので、オクルージョンカリングのベイクデータが大きくなることがある。
Occlusion Areaコンポーネントを設定すると、オクルージョンカリングしたい箇所だけ精度高くベイクするためベイクデータを小さくすることができる。
実際に検証してみた。確かにOcclusion Areaありのほうがベイクデータが小さいことが分かる。
①Occlusion Areaなし
②Occlusion Areaあり
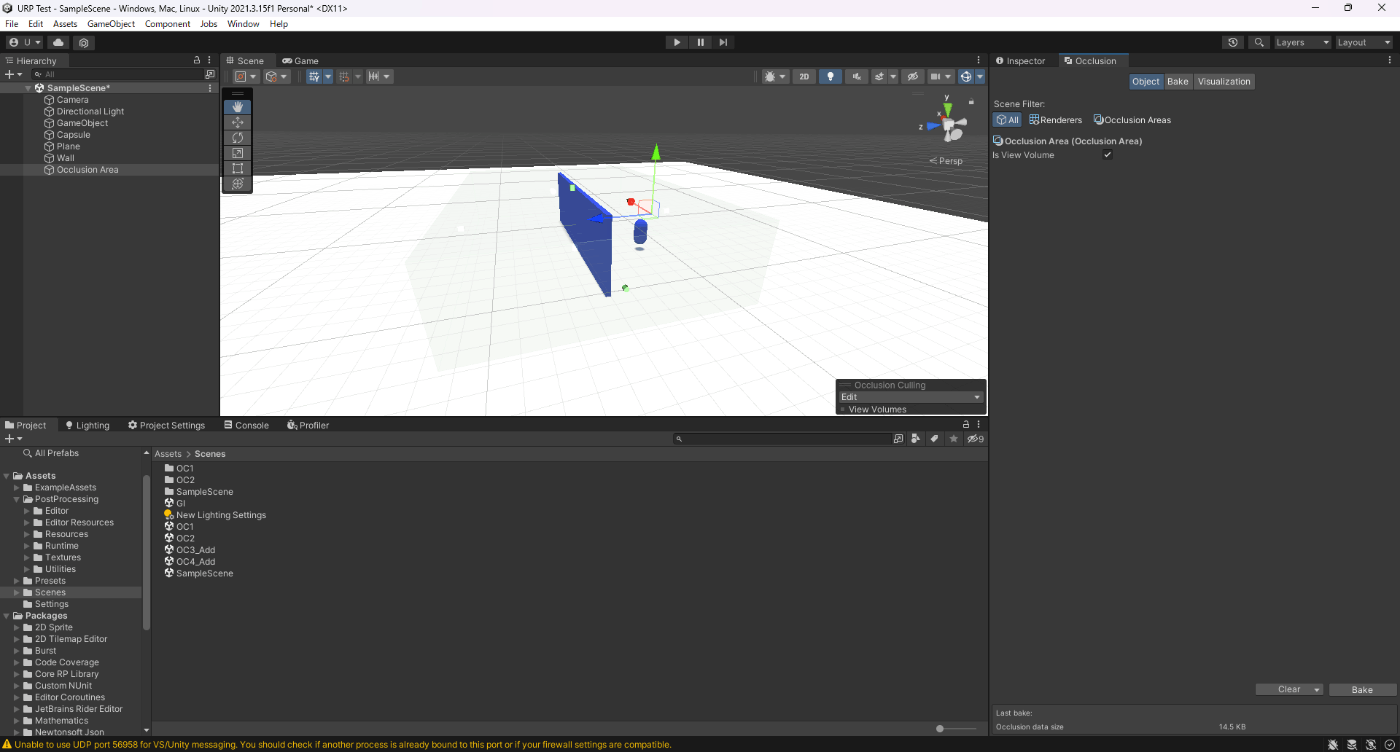
参照サイト、参照サイト
・オクルージョンカリングのSmallest Occluderの値を大きくして、ベイクサイズを小さくする。
遮蔽するオブジェクトがSmallest Occluderより大きくないと、オクルージョンカリングできない。
①Smallest Occluderが1
4.2KB

②Smallest Occluderが10
1.4KB
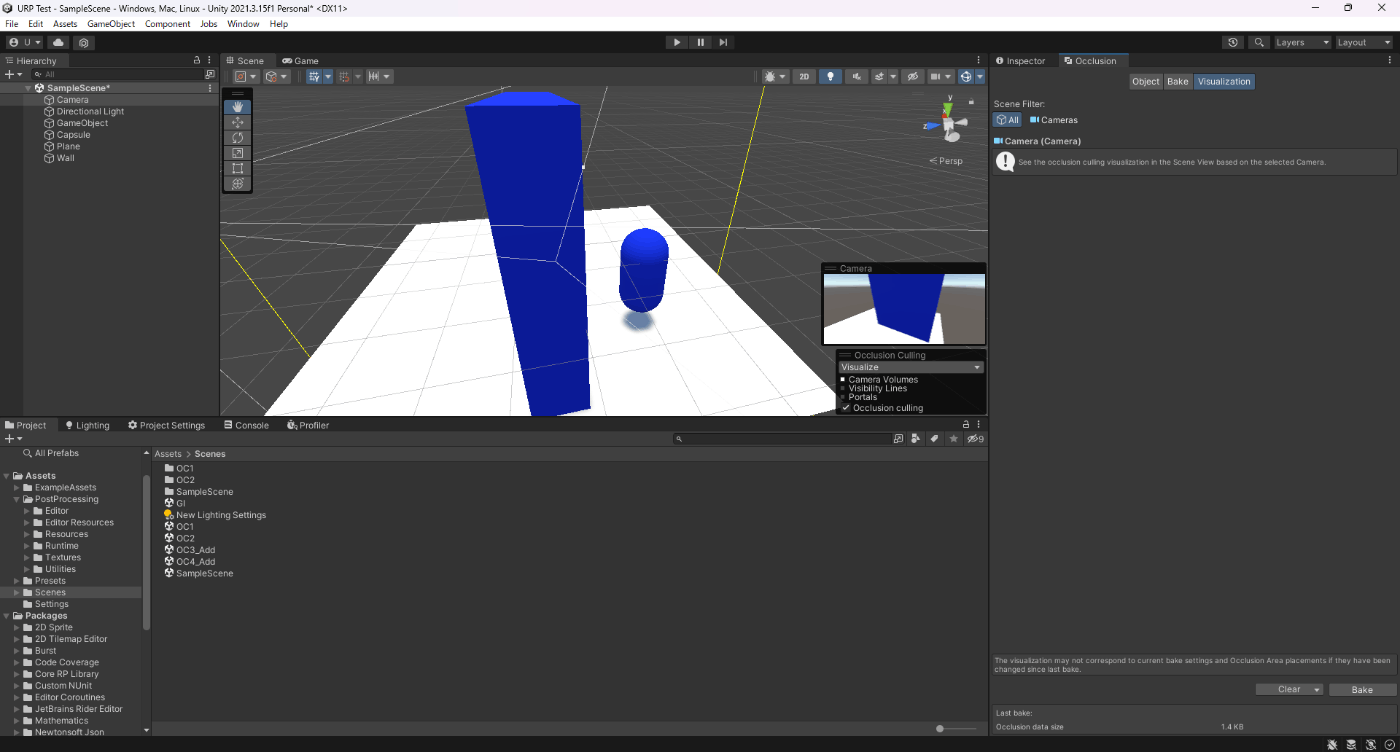
参照サイト、参照サイト
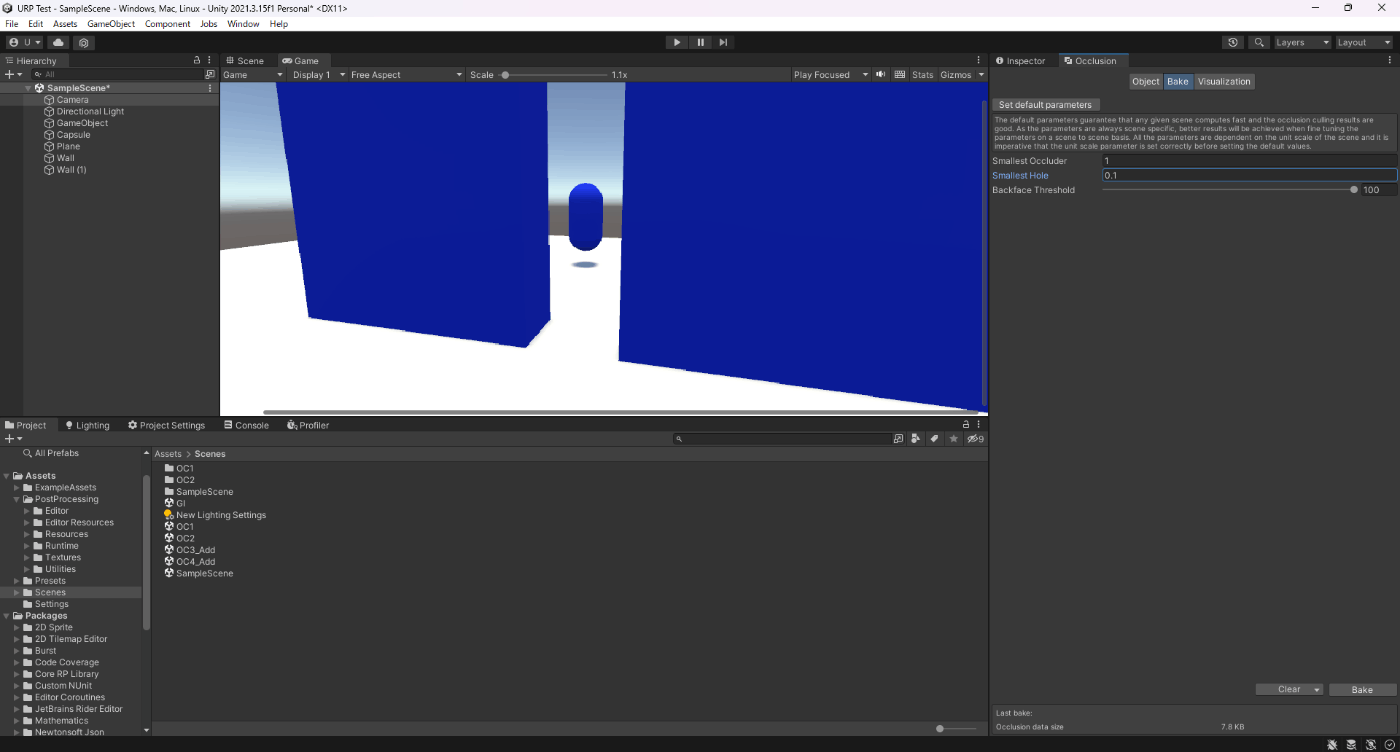
・オクルージョンカリングのSmallest Holeの値を大きくして、ベイクサイズを小さくする。
遮蔽するオブジェクト同士の隙間がSmallest Holeより大きくないと、オクルージョンカリングできない。
①Smallest Holeが0.1
7.8KB
②Smallest Holeが10
8.6KB
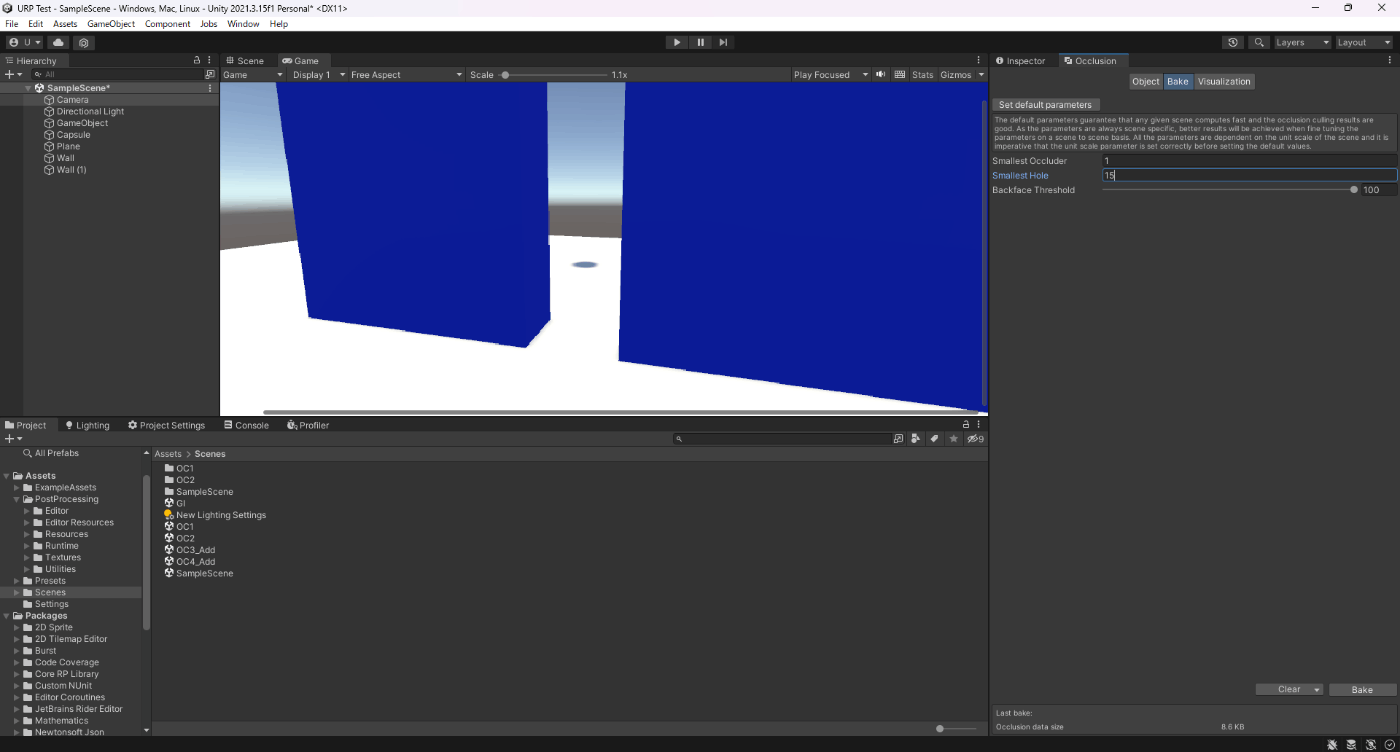
参照サイト、参照サイト
・オクルージョンカリングのBackface Thresholdの値を小さくして、ベイクサイズを小さくする。
参照サイトだと、カメラが遮蔽物にめり込んだ際の閾値と書いてあるが、値を変えても特に変化がなかったのでよくわからない。
①Backface Thresholdが5
28.3KB
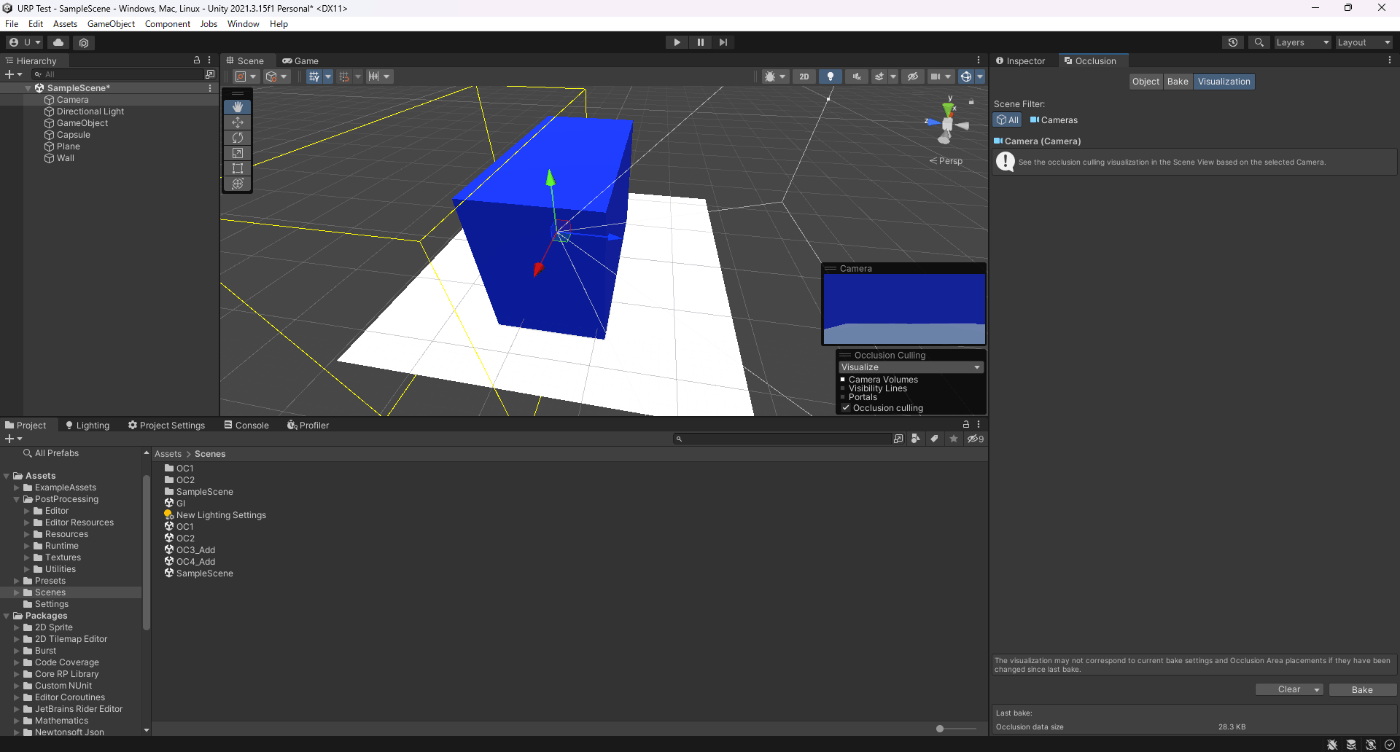
②Backface Thresholdが100
34.1KB
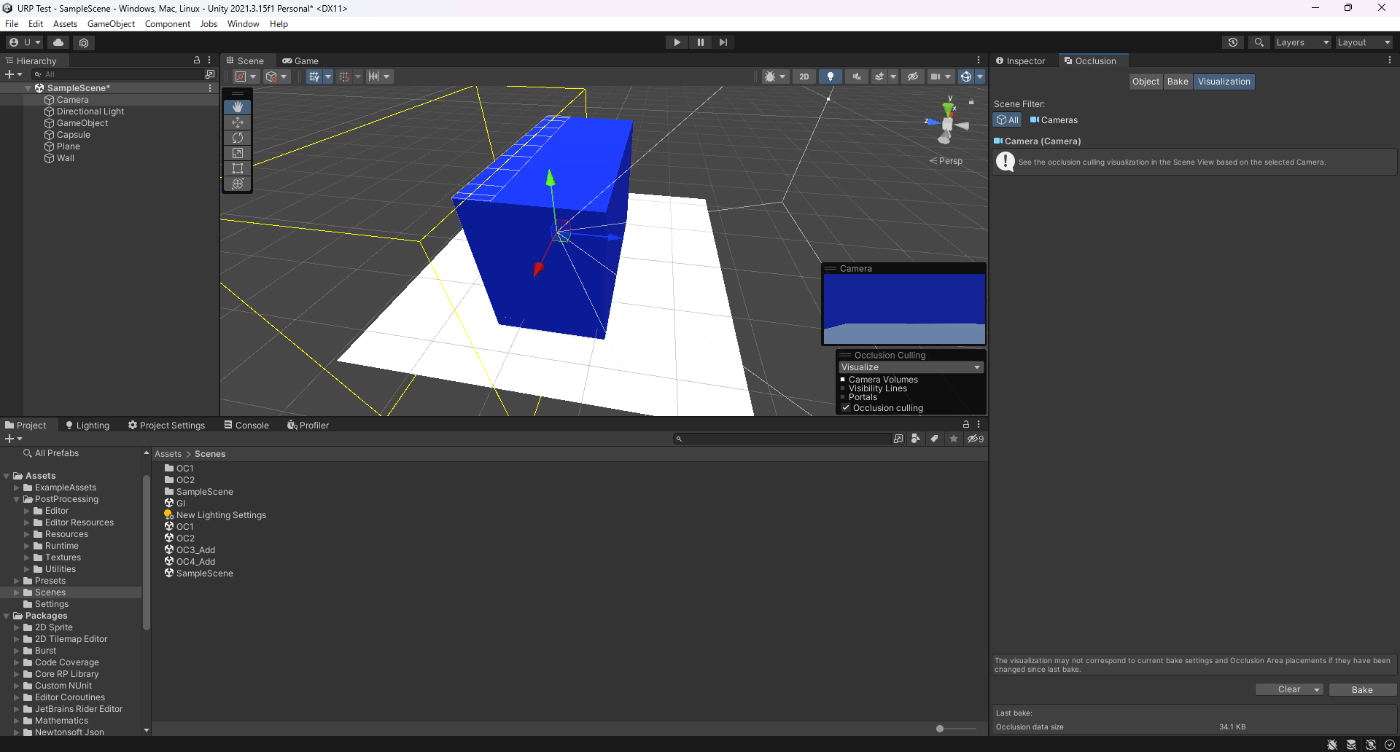
参照サイト、参照サイト
・最適なパフォーマンスのためのモデル作成
①ポリゴン数を最小にする
②マテリアルの数をできるだけ少なくする
マテリアルを少なくするとSet Pass Callが少なくなるので、マテリアルの設定値をCPUがGPUに教える処理が少なくなるので負荷が軽減される。
実際にそうなのか検証してみたところ、確かにSet Pass Callが減っていることがわかる。
通常のパターン
少なくしたパターン

③Skinned Mesh Rendererのメッシュはなるべく複数のメッシュにせず、一つのメッシュにまとめる
Skinned Mesh Rendererを使用するアニメーションキャラクタモデルでは、キャラクタごとにこれらのコンポーネントを1つだけ使用する必要があります。Unityのアニメーションシステムは、可視性のカリングとバウンディングボリュームの更新を使用してアニメーションを最適化します。1つのモデルで1つのAnimationコンポーネントと1つのSkinned Mesh Rendererを使用する場合にのみ、これらの最適化が有効になります。
1 つのメッシュの代わりに 2 つのスキンメッシュを使用すると、モデルのレンダリング時間が約 2 倍になり、複数のメッシュを使用することに実用的なメリットはほとんどありません。
④ボーンの数をできるだけ少なくする
⑤IKとFKを分ける
Unity がアニメーションをインポートするとき、モデルのインバースキネマティクス (IK) ノードをフォワードキネマティクス (FK) にベイクするため、Unity は IK ノードをまったく必要としません。ただし、それらがモデルに残っている場合は、アニメーションには影響しませんが計算には加えられます。Unity または 3D モデリングアプリケーションで、重複する IK ノードを削除できます。IK ノードの削除を容易にするために、モデリング中は IK と FK の階層を分けておきます。
参照サイト
・アバターの Muscle & Settings タブのTranslation DoF
Additional Settings の Translation DoF (変形の度合い) オプションを有効にすると、ヒューマノイドの変形アニメーションを有効にできます。このオプションを無効にすると、Unity は回転だけを使ってボーンをアニメーション化します。 Translation DoF は、Chest (胸)、UpperChest (胸の上部)、Neck (首)、LeftUpperLeg (左脚の上部)、RightUpperLeg (右脚の上部)、LeftShoulder (左肩)、RightShoulder (右肩) に使用できます。
Translate DoF を有効にするとパフォーマンスの要件が増加する場合があります。なぜなら、アニメーションシステムがヒューマノイドアニメーションをリターゲットするために追加処理を実行する必要があるためです。このため、このオプションは、キャラクターのボーンのアニメーション化された変形がアニメーションに含まれている場合にのみ有効にしてください
参照サイト
・Optimize Mesh
頂点とポリゴンの並びを変える。
Nothingは、並びを変えない。
Everythingは、ポリゴンと頂点の両方について、頂点とインデックスの並び替えをします。トライアングルストリップとインデックスバッファを利用した頂点の重複を解消のことだと思う。
Polygon Orderは、ポリゴンのみを並び替えます。インデックスバッファを利用した頂点の重複を解消させることだと思う。
Vertex Orderは、頂点だけを並べ替えます。トライアングルストリップのことだと思う。
Everythingを行えば、GPUのパフォーマンスが上がる。
一応、実験してみた。
Everithingのほうが、GPUとメモリーの負荷がかかっていないことが分かる。
ただ、インデックスバッファを利用する場合は、メモリを多く使ったり使わなかったりする場合があるみたい。
Optimize MeshがNothing

Optimize MeshがEverything
参照サイト、サイト、参照サイト、参照サイト
・Keep Quads
これを有効にすると、Unity が 4 つの頂点を持つポリゴンを三角形に変換するのを止めます。例えば、テッセレーションシェーダー を使用する場合、このオプションを有効にすると便利な場合があります。なぜなら、クアッドをテッセレーションする方がポリゴンをテッセレーションするより効率的な場合があるからです。
ちなみに、Unity はどんな種類のポリゴンでも (三角形から N 角形まで) インポートできます。4 つ以上の 頂点を持つポリゴンは、この設定に関係なく、常に三角形に変換されます。
参照サイト
・Weld Vertices
チェックすると同じ座標にある頂点が結合される。これにより、頂点は全般的に同じプロパティを共有できます (UV、法線、接線、頂点色など)。
これによって、メッシュの全体的な数を削減して頂点数を最適化できます。
オフする際の用途としては、あえて頂点を重ねた縮退ポリゴンを作って、アニメーション時などに使用するときとからしい。(正直よくわからない)
一応実験してみた。
オンのほうが、CPU、GPU、メモリのパフォーマンスが良いことが分かる。
Weld Verticesオフ
Weld Verticesオン
参照サイト、参照サイト
・Index Format
インデックスバッファのサイズを16bitか32bitかで指定。
通常は16bitのほうがパフォーマンスが良い。
32bit使う場合は、以下のように記載されている。
この設定は、GPU ベースのレンダリングパイプライン (例えば、コンピュートシェーダーの三角形のカリングを使用して) を行うときに、32 ビットインデックスを使用すると、すべてのメッシュが同じインデックス形式を使用するようになります。これにより、シェーダーで 1 つの形式だけを扱えばよいため、コンピュートシェーダーをより簡素化できます。
また、32bitはすべてのプラットフォームで対応されているわけではないらしい。例えば、Mali-400 GPU を搭載した Android デバイスはそれらをサポートしません。このようなプラットフォームで 32 ビット インデックスを使用すると、警告メッセージがログに記録され、メッシュがレンダリングされない。
一応、16bitと32bitで実験してみた。
16bitのほうが、CPU、GPU、メモリのパフォーマンスが良いことが分かる
Index Formatが16bit
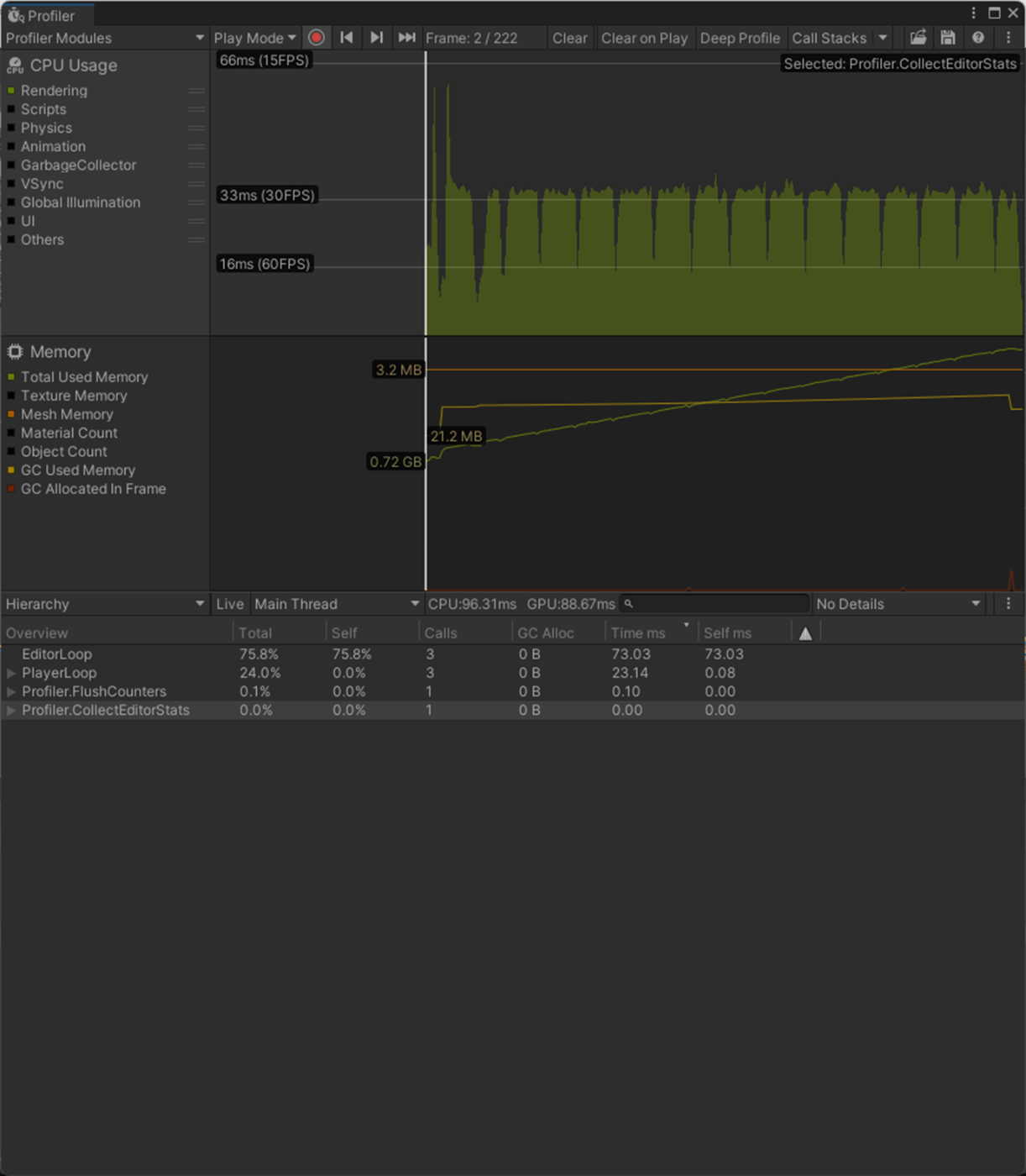
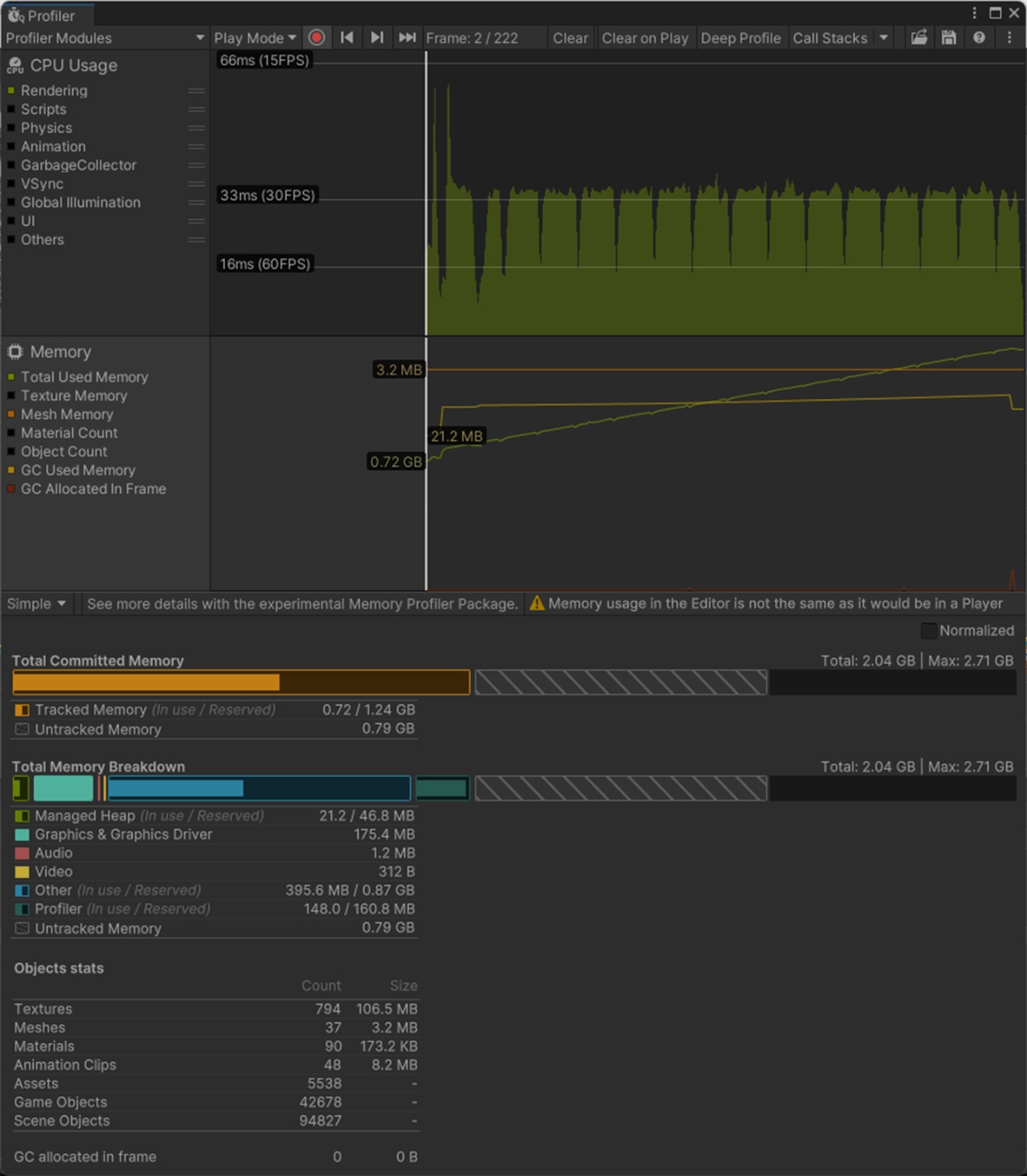
Index Formatが32bit
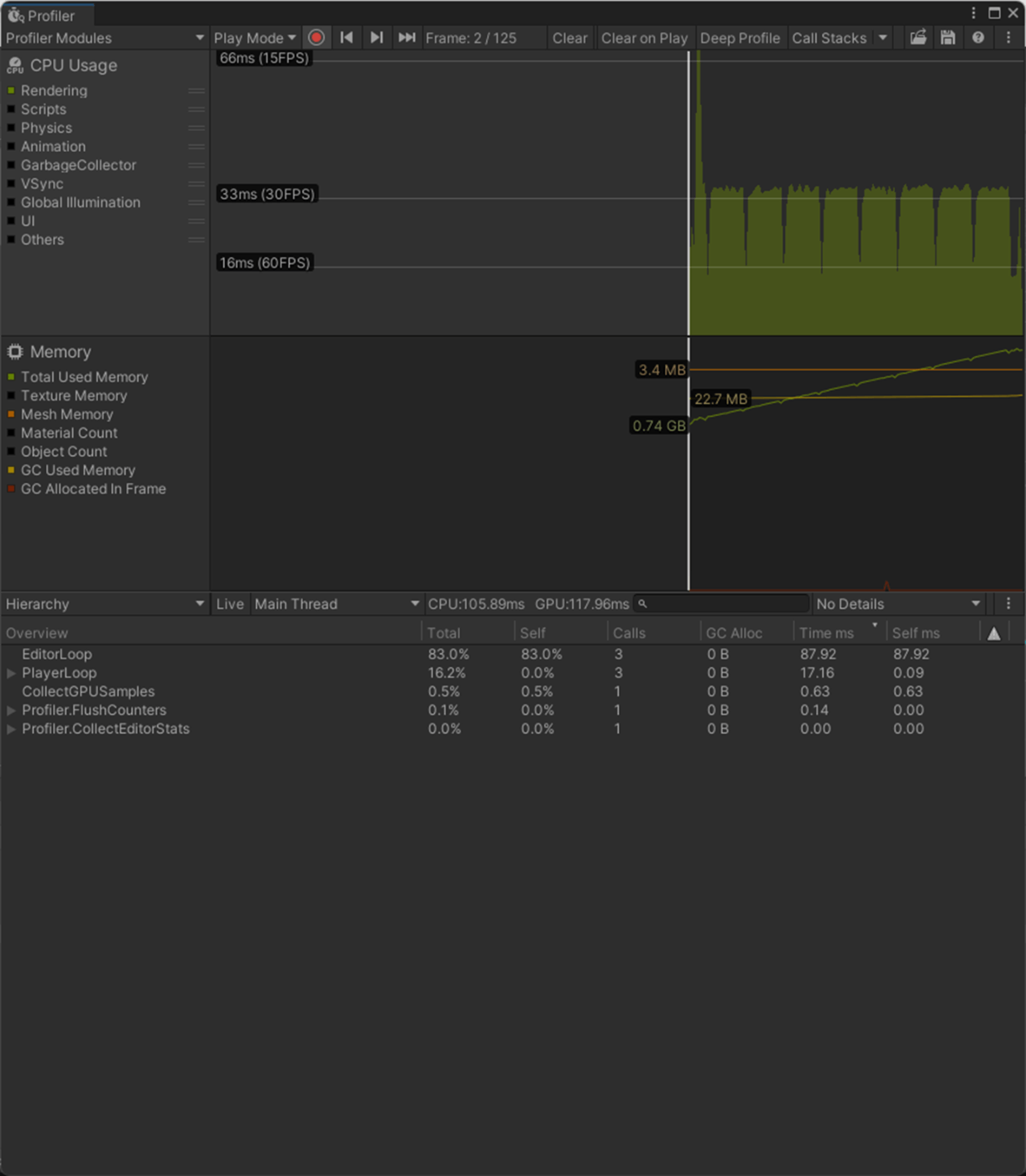
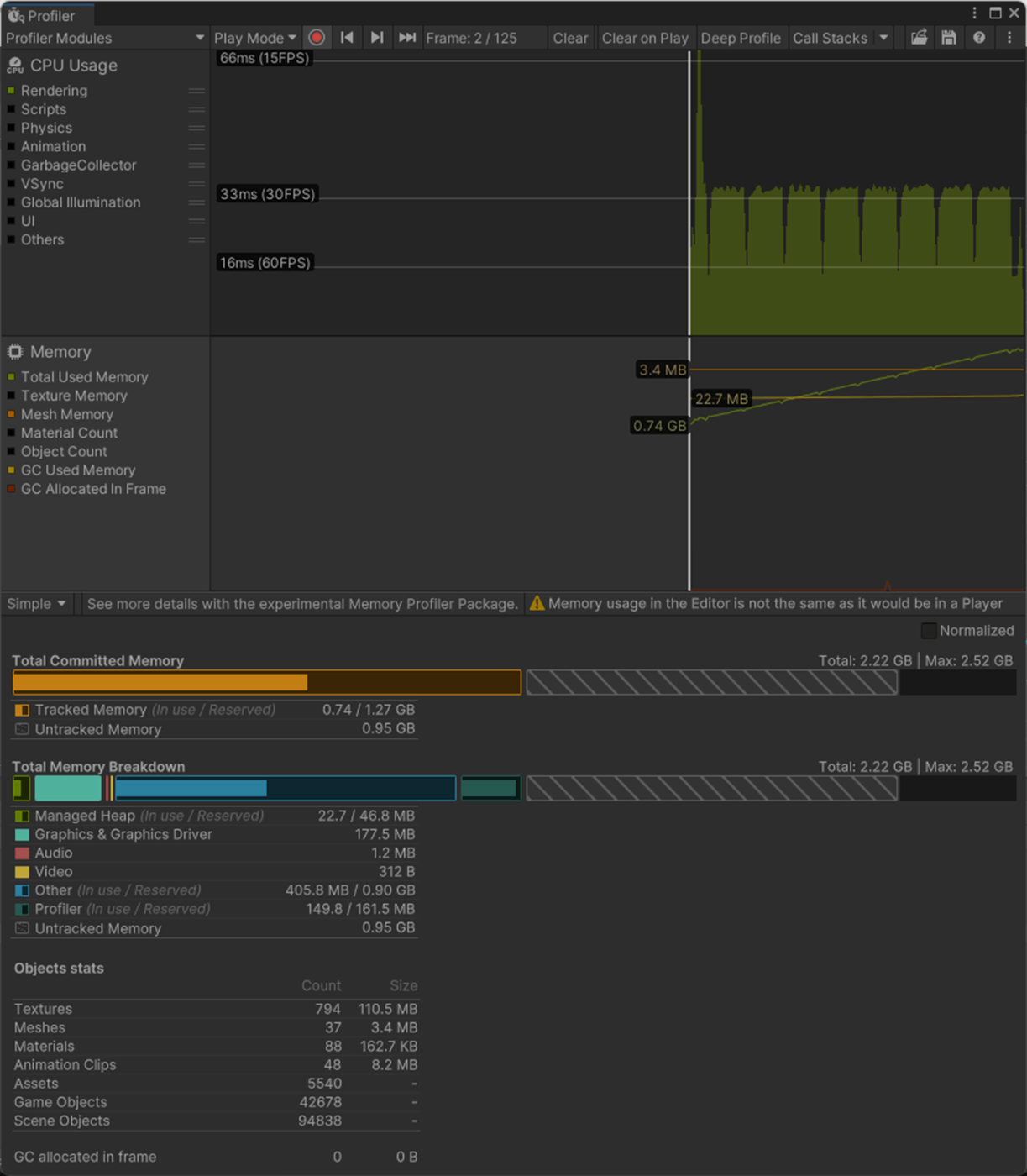
参照サイト、参照サイト
・Normals
モデルの法線を使用するのか、しないのか、またどのように使用するのか設定する
Importは、モデルの法線を使用する。もし法線がなければUnityが算出する。
Calculateは、UnityがNormals Mode、Smoothness Source、Smoothing Angle に基づいて法線を計算する。(なおImportでNormals Modeなどの値を変えても陰影は変わらなかった。Importはあくまでもモデルの法線をそのまま使う)
Noneは、法線を無効にする。
実験してみた
ImportとCalculateはシェーディングがライトの回転に合わせて変化していることが分かる。
パフォーマンスの面もImportとNoneで実験してみた。
Importだと法線を使用するので、CPU、GPU、メモリ(Mesh)、アプリサイズに負荷がかかっていることが分かる。
Normals None
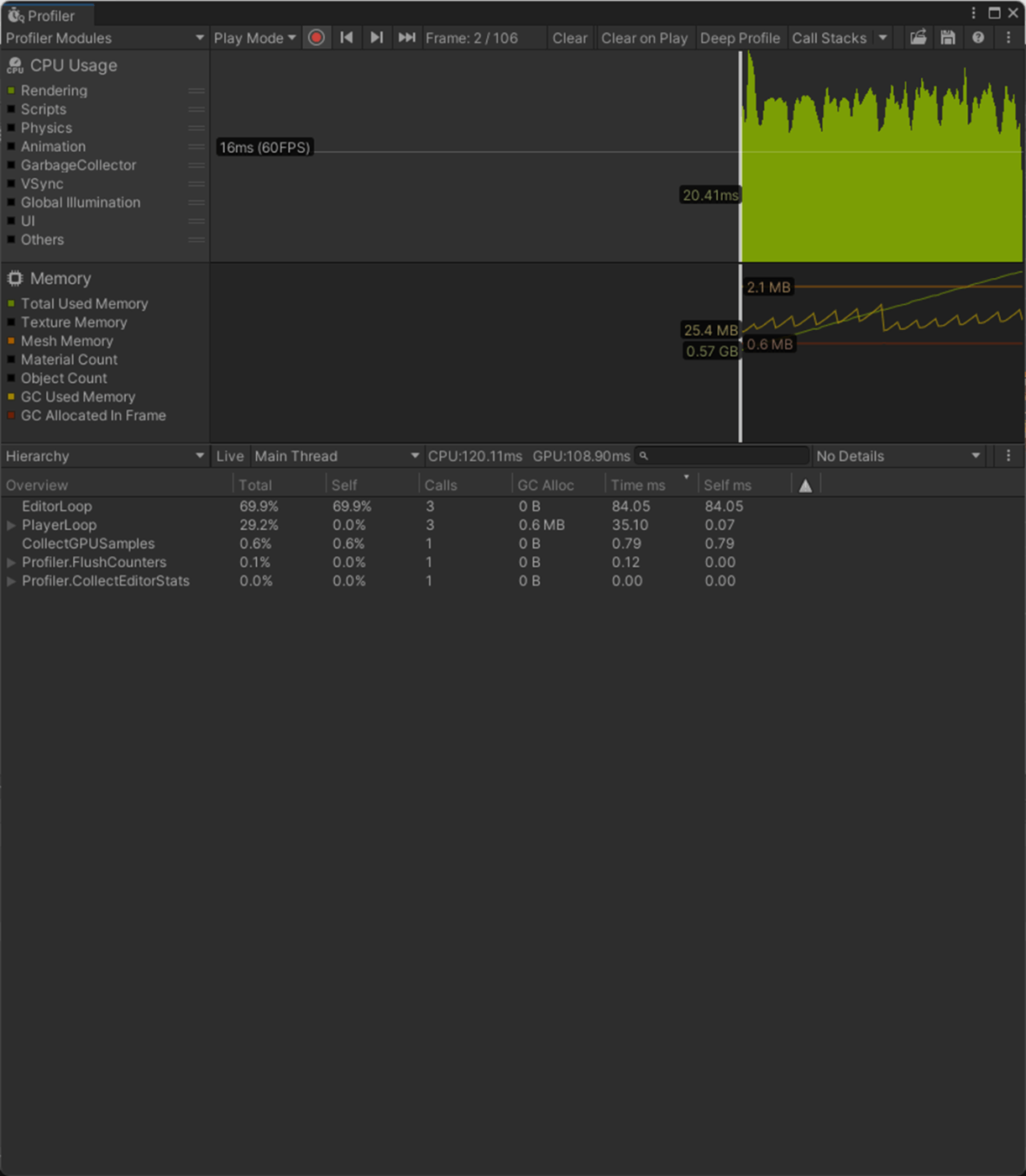
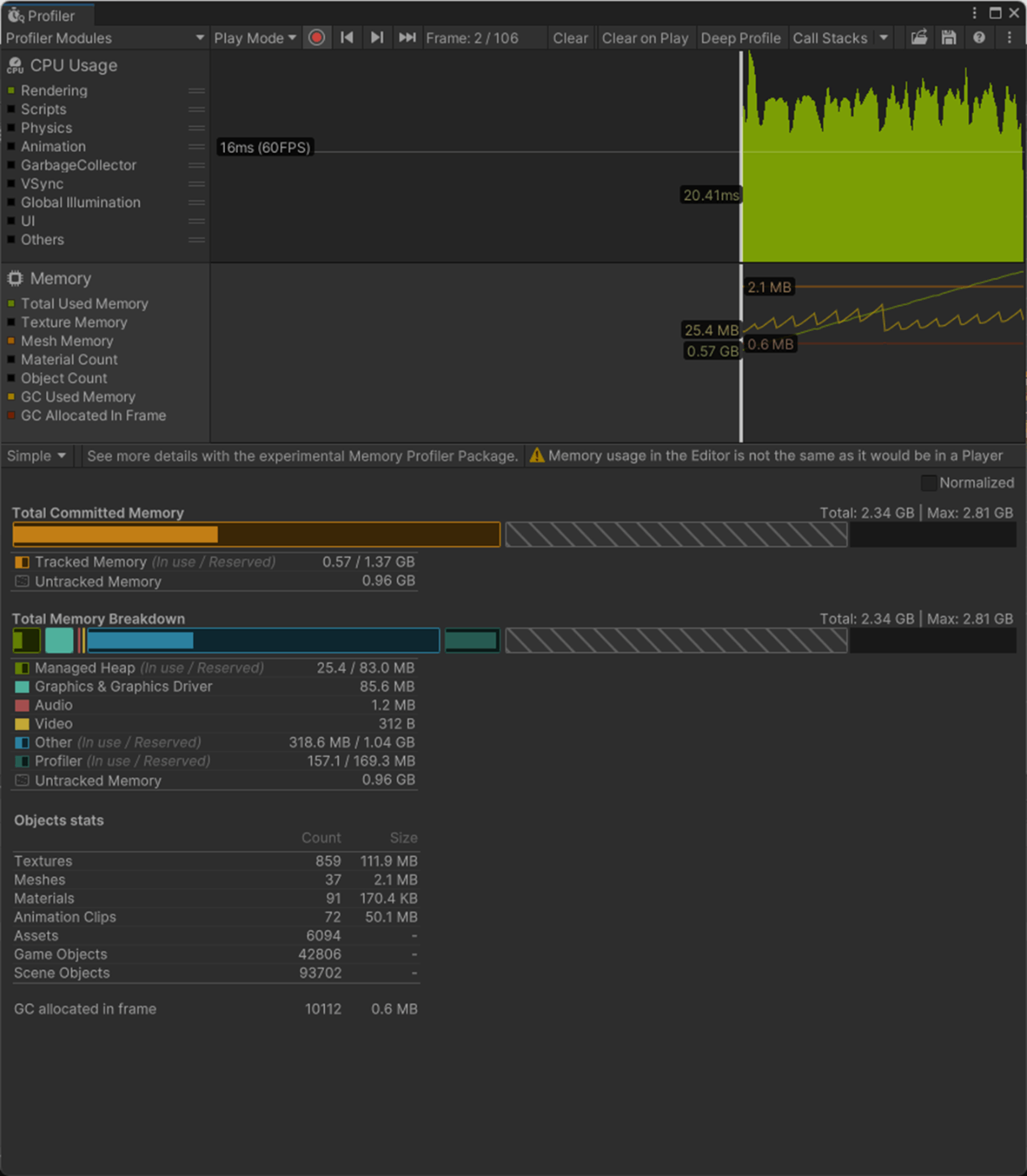
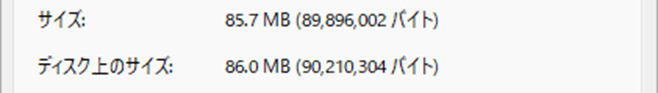
Normals Import
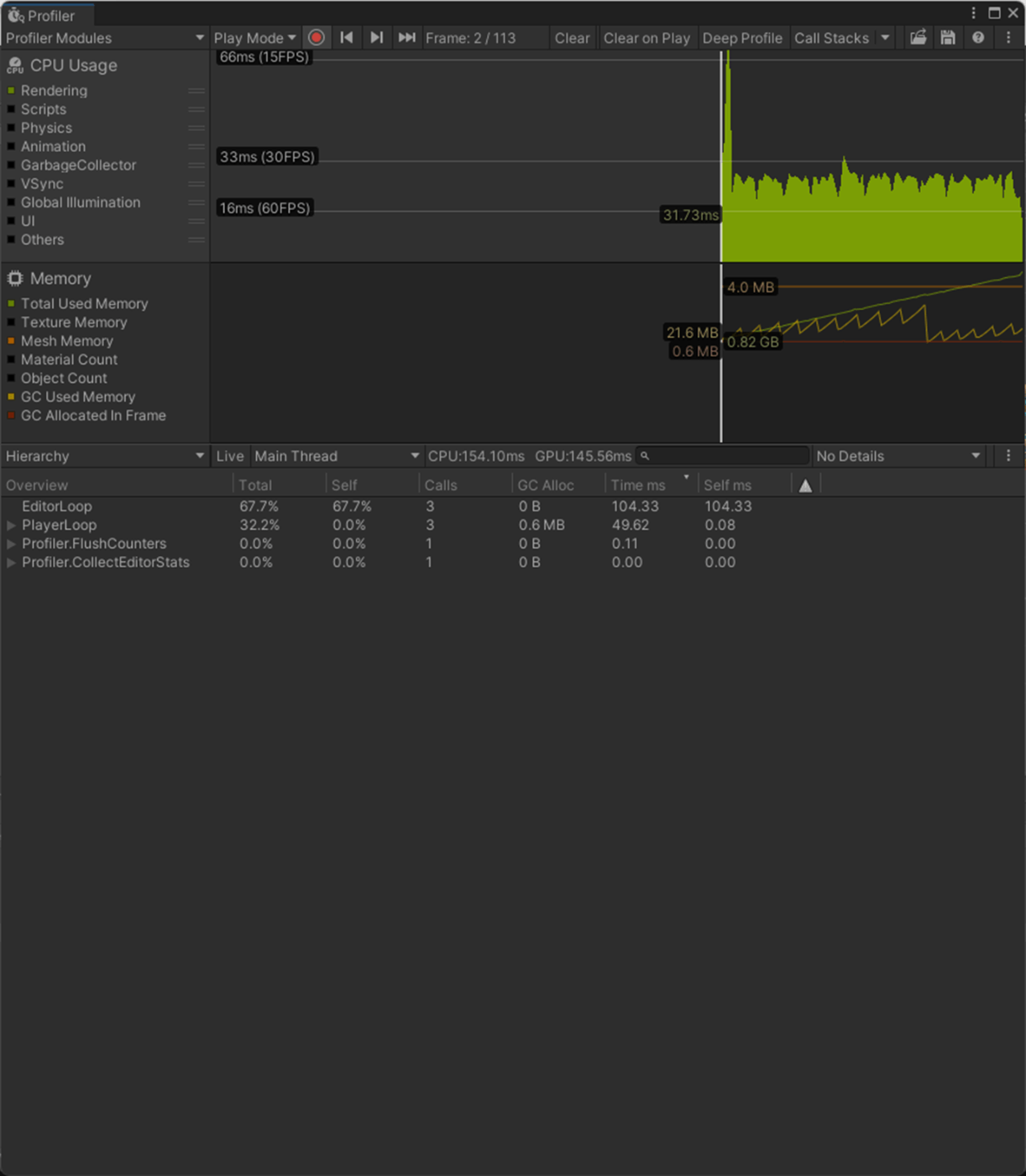
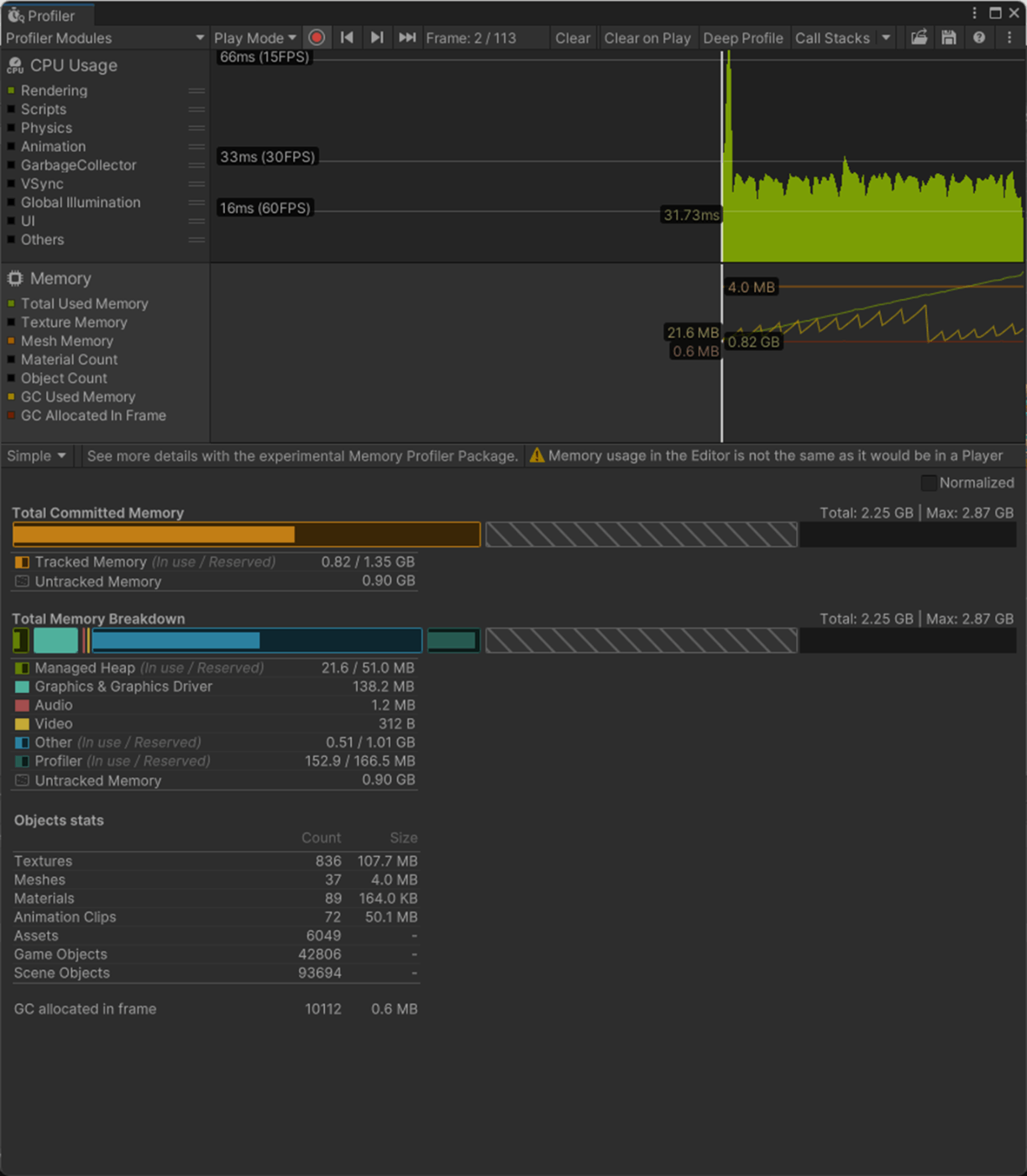

参照サイト
・Blend Shape Normals
ブレンドシェイプの法線を使用するのか、しないのか、またどのように使用するのか設定する。
ブレンドシェイプ作成できないので、検証していないがパフォーマンス回りはNormalsと同じ結果になると思う。
カスタム法線とシェイプキー法線が競合して、ブレンドシェイプを使用して表情が変わった際に陰影がおかしくなる問題起こる可能性があるので、この問題が発生した場合は、Noneにすると良い。
参照サイト、参照サイト、
Discussion