Open15
Prismaの公式ドキュメントを読む
ここから色々読んでいく
いくつかプロダクトがある
- Prisma ORM: データモデリング、マイグレーション、クエリ
- Prisma Accelerate: connection pooling、キャッシュによりクエリを高速化
- Prisma Pulse: DBの変更をキャプチャし、アプリケーションに伝える
- Prisma Optimize: クエリを高速化するrecommendationをしてくれる
Prisma ORMの基本的な使い方
-
npm i -D prismaでインストール、npx prisma init --datasource-provider sqliteなどとして初期セットアップ。これによりschema.prismaが入ったprismaディレクトリができる。 - .prismaファイルの中身には、下記のようにスキーマを書いていく
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
}
- その後、
npx prisma migrate dev --name initなどとするとスキーマに対応するテーブルができる。この時、primsa/migrationsにSQLのマイグレーションファイルができるとともに、そのクエリが実行される。 - この後、node.jsでprisma clientを使って下記のようにクエリを書いていけば良い。
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
async function main() {
const user = await prisma.user.create({
data: {
name: 'Alice',
email: 'alice@prisma.io',
},
})
console.log(user)
}
main()
.then(async () => {
await prisma.$disconnect()
})
.catch(async (e) => {
console.error(e)
await prisma.$disconnect()
process.exit(1)
})
- prismaを使うと、relationが簡単にクエリできる。下記のように、ネストさせた状態でレコードを作ることもできるし、ネストさせた状態でデータ取得することもできる。このとき、型も完璧につく。
const user = await prisma.user.create({
data: {
name: 'Bob',
email: 'bob@prisma.io',
posts: {
create: [
{
title: 'Hello World',
published: true
},
{
title: 'My second post',
content: 'This is still a draft'
}
],
},
},
})
const usersWithPosts = await prisma.user.findMany({
include: {
posts: true,
},
})
- また、
npx prisma studioとすれば、GUIでデータを見ることもできる。
PostgreSQLで使う
セットアップ
- インストール後、
npx prisma initとすると.prismaファイルができるので、その中に接続情報を書いていく。(.envに実際の接続先URLはpostgresql://USER:PASSWORD@HOST:PORT/DATABASE?schema=SCHEMAの形で記載する)
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
- あとはスキーマを定義してmigrateすればテーブルが作られる。
Prisma clientを使う
-
npm i @prisma/clientでクライアントをインストール。この瞬間、裏でprisma generateコマンドが叩かれて、既存のprisma schemaから、そこに定義されたモデルに基づいたclientが生成される。 - schemaを変更した際は、
prisma migrate devもしくはprisma db pushコマンドを打つと、clientも更新される。

- あとは、普通にクエリを叩いていけばよい
docsからも気になったところを読んでいく
- schemaに記載する3つの内容
- Data source: DB接続
- Generator: prisma clientを生成することを指示
- Data model: データモデル
- Prisma ORMのワークフロー
- 典型的には、下記のように、prisma schemaを変更したあと、
prisma migrate devによりmigration ファイルを生成、DBに反映し、clientを更新する
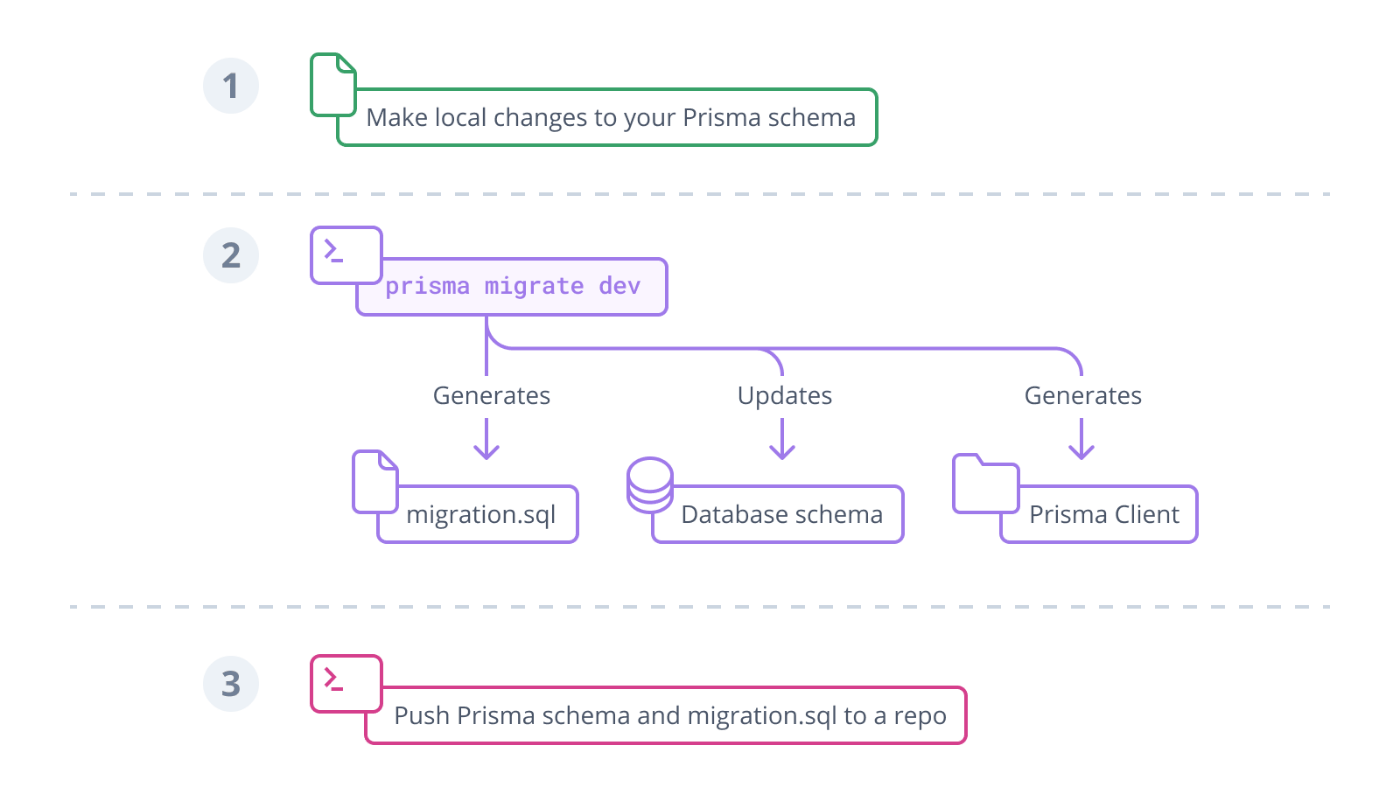
- ただし、なんらかの理由でprisma migrateを使いたくない場合は、DBをまず変更し、そこから
prisma db pullでprisma schemaを更新、prisma generateでclientを更新して使うこともできる。
- 典型的には、下記のように、prisma schemaを変更したあと、
なぜPrisma ORMを使うのか?
-
Prisma ORMは、クリーンでtype safeな、plain old javascript objectを返すAPIを提供することでDBクエリをシンプルに扱えるようにする
-
既存技術との比較
- 生SQL: なんでもできるが、当然SQLを直接書くのは面倒。また、型安全性にも乏しい。
- クエリビルダー: 比較的なんでもできる、ただ依然としてSQLの言葉でデータを考えないといけないので認知コストはある。
- 既存のORM: データをクラスという形で抽象化しているため一定扱いやすい。ただし、オブジェクト指向っぽいアプローチのORMだと、オブジェクト指向の考え方と実際のテーブルデータとの間に不整合(=インピーダンスミスマッチ)問題が生じてしまう(e.g., joinの概念がobjectだと表現しづらいので容易にn+1問題が生じる)。結果、余計な複雑さや落とし穴を導入してしまう。

- prismaの思想: アプリ開発者はSQLではなく「データ」を考えるべき。
- SQLはしっかり理解すれば素晴らしいが、たくさんのアンチパターンや落とし穴がある。これらを排除してデータだけに集中するのがあるべき姿。
- Prismaは、ちょうど良いバランスでこれを実現する

いつPrismaを使うべきか?
- つかうべきとき
- サーバサイドでDBをつかうとき
- 生産性、DXをあげたいとき: prismaは開発者体験を最重視して設計されている
- チームで活動しているとき: prisma schemaで簡単に現在の状況がわかる、学習コスト低い
- DB関連のツールが一気通貫で欲しい時: migration, prototyping, seeding, GUIなど一式揃っている
- 型安全性が欲しい時: 既存ORM (e.g., TypeORM)と比べても高い型安全性
- 透明性が高くメンテされてるツールをつかいたいとき
- つかうべきでないとき
- DBに対して本当になんでもやりたいとき: 制御性は生SQLの方が当然上
- バックエンドで何もコード書きたくないとき:BaaSを使った方がよい。GraphQLならHasuraとか
マイグレーション
概要・メンタルモデル
- https://www.prisma.io/docs/orm/prisma-migrate/understanding-prisma-migrate/overview
- https://www.prisma.io/docs/orm/prisma-migrate/understanding-prisma-migrate/mental-model
- prismaのmigrationは宣言型と手続型のハイブリッド
- 宣言: prisma.schemaから宣言的に生成される
- 手続: 生成されたSQLファイルは手動カスタマイズ可能
- 典型的なワークフロー
- ローカル: prisma.schemaを書いてprisma migrate dev or prisma db pushでdb schemaをdbに反映
- eva/prod: PRをマージした時に、CIでprisma migrate deployでdbに反映
- migration stateの保持: 下記にprisma migrationの状態が保持される
- prisma schema
- prisma/migrationsフォルダ以下のsqlファイル
- dbの_prisma_migrationテーブル
- prisma migrateをするにあたっての要件
- dbはlocal/eva/prod環境ごとに分ける
- ローカル開発時には、dbは基本的に使い捨てと捉える
- 環境ごとのdbの設定は揃える
- prisma schemaがsingle source of truthとなるようにする
- 各コマンドの考え方
- prisma migrate dev
- これを打つと、prisma/migrationsにsqlが作成され、実行される。その時、_prisma_migrationsテーブルも更新される。migration sqlをいじりたい時は、--create-onlyでsqlの生成で止めておき、sqlをいじってから実行する

- これを打つと、prisma/migrationsにsqlが作成され、実行される。その時、_prisma_migrationsテーブルも更新される。migration sqlをいじりたい時は、--create-onlyでsqlの生成で止めておき、sqlをいじってから実行する
- prisma migrate diff
- prisma/migrationsのsqlと実際のDBのスキーマが乖離している場合に、それを埋めるsqlを生成できる

- prisma/migrationsのsqlと実際のDBのスキーマが乖離している場合に、それを埋めるsqlを生成できる
- prisma db push
- prisma/migrationsを作らずに、prisma schemaと現在のdbの状態を同期できる
- クイックにローカルで色々ためしたいときに使う

- prisma migrate deploy
- prisma/migrationsと_prisma_migrationsテーブルから、適用すべきsqlをpickし、それを適用する
- prisma migrate dev
migration historyとshadow database
- https://www.prisma.io/docs/orm/prisma-migrate/understanding-prisma-migrate/migration-histories
- すでにapplyされたmigrationは絶対にいじらない
- いじった場合、下記のような問題が生じる
-
- varchar(550)のprisma schemaからmigrationを生成、applyしてからSQLの方だけvarchar(560)に書き換え
- その後、prisma migrate devすると、migration不整合によりローカルのデータが全てリセットされるが、migration自体は成功する。ただし、追加で、当該カラムをvarchar(550)に戻すようなマイグレーションが生成される
- この状態だと、prod環境では、prismaは常に「migration historyとschemaがあってませんよ」という警告を発するようになる
-
- どうしてもすでにapply済みのmigrationをいじりたい場合は、migrationのchecksumを手動で生成して_prisma_migrationsテーブルを書き換えるという荒技がある。しかし、これは「apply済みのmigrationをいじっても絶対に無害である」という確信がある時のみ
- いじった場合、下記のような問題が生じる
- shadow database
- https://www.prisma.io/docs/orm/prisma-migrate/understanding-prisma-migrate/shadow-database
- 主にローカル開発で使われる概念。schemaのdriftを検知したりする
- prisma migrate devすると、自動的に作られる。migrate diffのときも使われる
- schema driftの検知の仕組み
- まっさらなshadow databaseを作り、現在適用済みまでのmigrationをそこに適用
- その結果できたshadow databaseを現在のdbと比較
- 比較結果をdriftとして検知
- prisma migrate devの際は、shadow databaseでdriftが検知されなかったら、そのまま新規migration sqlを生成して適用、その後自動的にshadow databaseは破棄される
- shadow databaseは、自動で作成・破棄されるため普段は目につかないが、cloud databaseなど、dbの作成・削除が自由にできない環境では、明示的にshadow database urlを指定することで、そのdbをshadow dabaseとして使い続けられる
DBのPrototype
- https://www.prisma.io/docs/orm/prisma-migrate/workflows/prototyping-your-schema
- db pushで、migrationファイルを生成せずにdbの状態をprisma.schemaと合わせられる。この状態で色々いじれる
- その後、prisma migrate devとすると、dbは完全にリセットされるが、最新のschemaに合わせたマイグレーションファイルが生成できる
マイグレーションのsquash
- https://www.prisma.io/docs/orm/prisma-migrate/workflows/squashing-migrations
- ローカルで、複数のmigrationを一個にまとめる
- prisma migrate devをローカルで複数回実行
- その後、できたmigration sqlファイルを全部削除
- もう一度prisma migrate devを実行すると、1のマイグレーションが一つにまとまる。ただしデータは全部消える
ダウンマイグレーション
- 基本的に、成功したマイグレーションを戻したい時は、schema.prismaをいじって新しいマイグレーションを生成するのが良い
- マイグレーションの失敗可能性を見越して、あらかじめdown migrationのSQLを作っておく手段は一応ある。
- up migrationのため、schema.prismaをいじる
- prisma migrate devする前に、prisma migrate diffを使って、「to: up前のschema」、「from: up後のschema」として、ダウンマイグレーションのsqlを生成。
npx prisma migrate diff \ --from-schema-datamodel prisma/schema.prisma \ --to-schema-datasource prisma/schema.prisma \ --script > down.sql- prisma migrate devで、ローカルで普通にup migrationを実行
- そのmigrationのフォルダに、2で生成したdown migration sqlを格納
- prod環境などで、up migration失敗したら、
npx prisma db execute --file ./down.sql --schema prisma/schema.prismaなどとしてdown migrationを実行。その後、npx prisma migrate resolve --rolled-back add_profileなどとして、失敗したup migrationをロールバック済み状態にする
patching & hotfixing
- 本番データベースで、prismaを介さず手動で何かいじってしまった時
- ローカルで、その操作に相当するschemaの変更を加えて、prisma migrate devする
- その後、本番で、primsma migrate deployせずに、
prisma migrate resolve --applied "<migration名>"でそのマイグレーションをapply済みとしてマークする
- マイグレーションが失敗したとき
- rollbackするパターン
- そのマイグレーションにロールバックフラグをつける
prisma migrate resolve --rolled-back "<migration名>" - もしmigrationが部分的に実行されてしまっていたら、if not existsをつけるなど適宜sqlを改変
- その後、
prisma migrate deployで再適用
- そのマイグレーションにロールバックフラグをつける
- appliedにしてしまうパターン
- そのマイグレーションの内容を手動でDBに適用してしまう
-
prisma migrate resolve --applied "<migration名>"で適用済みフラグをつける
- rollbackするパターン
- なお、いずれのケースにおいても、prisma diffとprisma executeで、修正のためのsql生成を補助してもらうことができる
コマンドまとめ
| コマンド | schema.prismaへの影響 | migrations/*.sqlへの影響 | _prisma_migrationsテーブルへの影響 | Shadow Databaseへの影響 | Databaseそのものへの影響 | 備考 |
|---|---|---|---|---|---|---|
| prisma migrate dev | スキーマ定義から差分を計算し、新規マイグレーションを生成 | 差分に基づく新規マイグレーションファイルが作成される | 実行済みマイグレーションとしてレコードが追加・更新される | 一時的に作成され、処理完了後は自動削除される | 対象のDBにマイグレーションが適用される | 主に開発中用。頻繁に実行するとマイグレーションが多数蓄積される可能性あり |
| prisma migrate deploy | schema.prismaの定義と既存マイグレーションの整合性を検証 | 既存のマイグレーションファイルを順次実行 | 実行済みとして記録される | - | 本番DBに対してマイグレーションを適用 | 本番環境向け。事前に生成されたマイグレーションをそのまま適用 |
| prisma migrate execute | - | migrationsの中にあるsqlを個別で実行可能。(別にmigrations以下じゃなくても良い) | - | - | sqlの実行結果が反映される | 手動や緊急対応で特定のマイグレーションの実行状態を調整する際に使用 |
| prisma db push | schema.prismaの内容を直接DBへ反映 | - | - | - | schema.prismaの定義に基づいて直接スキーマを更新 | 履歴が残らず、プロトタイピングや初期開発向け。後から差分管理が難しい |
| prisma migrate resolve | - | - | マイグレーションの適用状態を手動で調整する | - | - | 適用状態の不整合解消やトラブルシュート時に利用 |
ログインするとコメントできます