Open4
Cloud Spannerのベストプラクティス
上記ドキュメントをもとに、ややコツがいるとされるSpannerの使い方をまとめる
Spannerのアーキテクチャ
- ベストプラクティスの前提として、まずはSpannerのアーキテクチャについて簡単にまとめる(主に単一リージョンの場合にフォーカス)
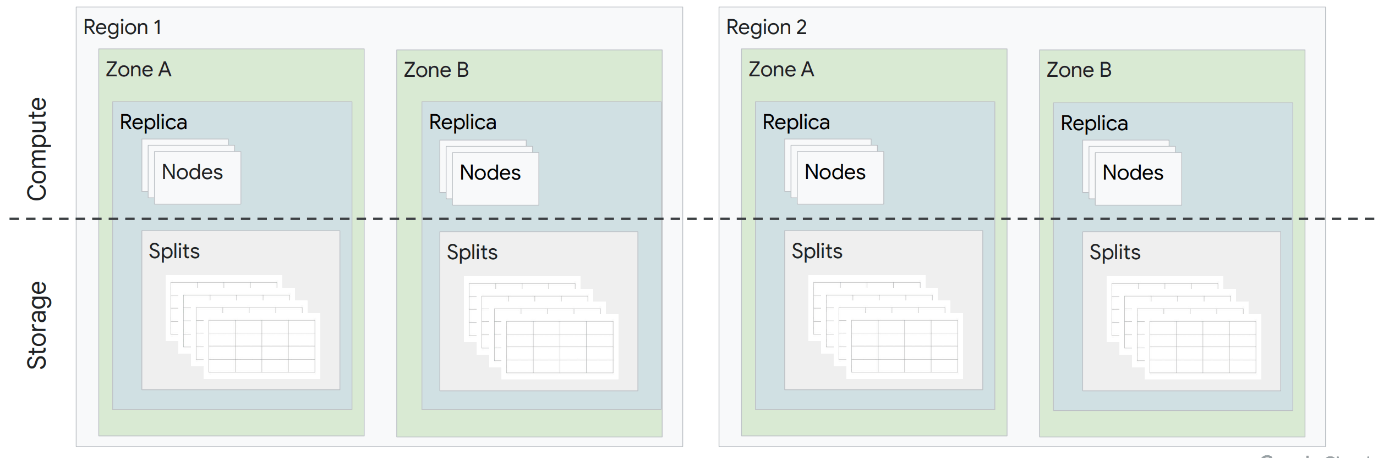
全体像
- Spannerは分散DB。レプリカが複数zone (場合によっては複数region)にまたがる。
- nodeが、DBに必要な計算能力(=CPU, RAM, storage)を提供する。1 nodeあたり4TBまで処理可能。
- テーブルはsplitという単位に自動分割され、自動レプリケーションされる。
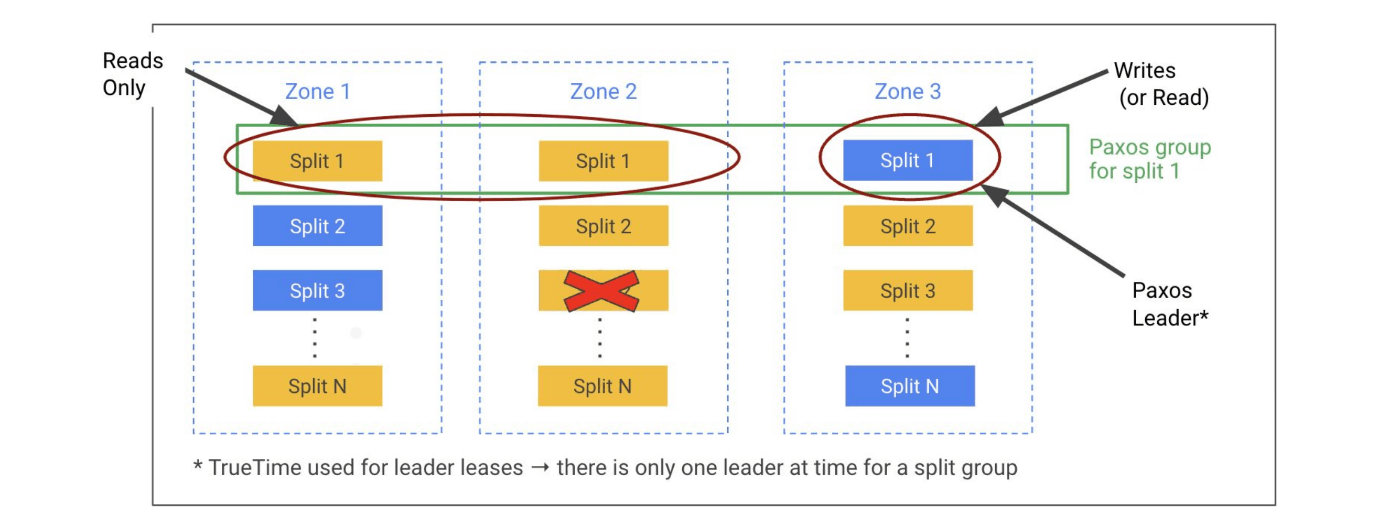
レプリケーション
- レプリカ間でのデータ同期はPaxos(分散合意アルゴリズム)で行われる。トランザクションをcommitするときは、定足数(過半数)のreplicaがcommitに投票しないといけない。
- レプリカには下記3種類ある。
- read-write: データのフルコピーを所持。commitに投票できる。リーダー選出に参加できるし、リーダーになれる。
- read-only: 複数リージョンの場合に使われる。データのフルコピーを所持し、読み出せる。commitに投票しない。
- witness: 複数リージョンの場合に使われる。データのフルコピーは所持しない。commitに投票し、リーダーにはなれないがリーダー選出に参加できる。
- 単一リージョンなら、全てread-writeレプリカになる。

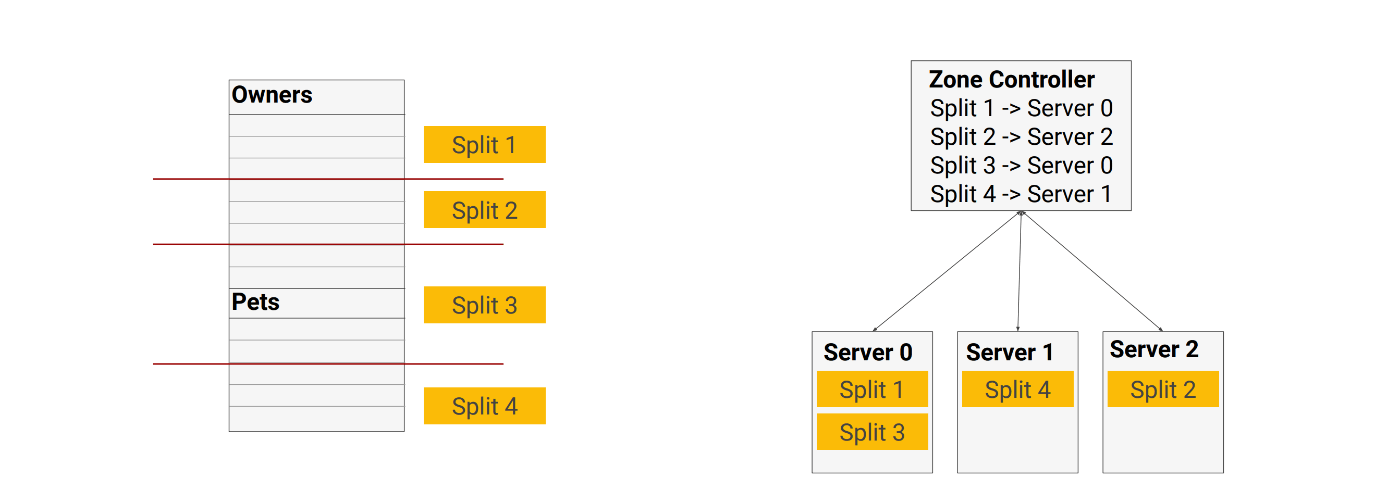
Split
- テーブルは、split (またはshard)に分割される。splitは、主キーによりソートされる。split内の全てのデータは一緒に保存される。
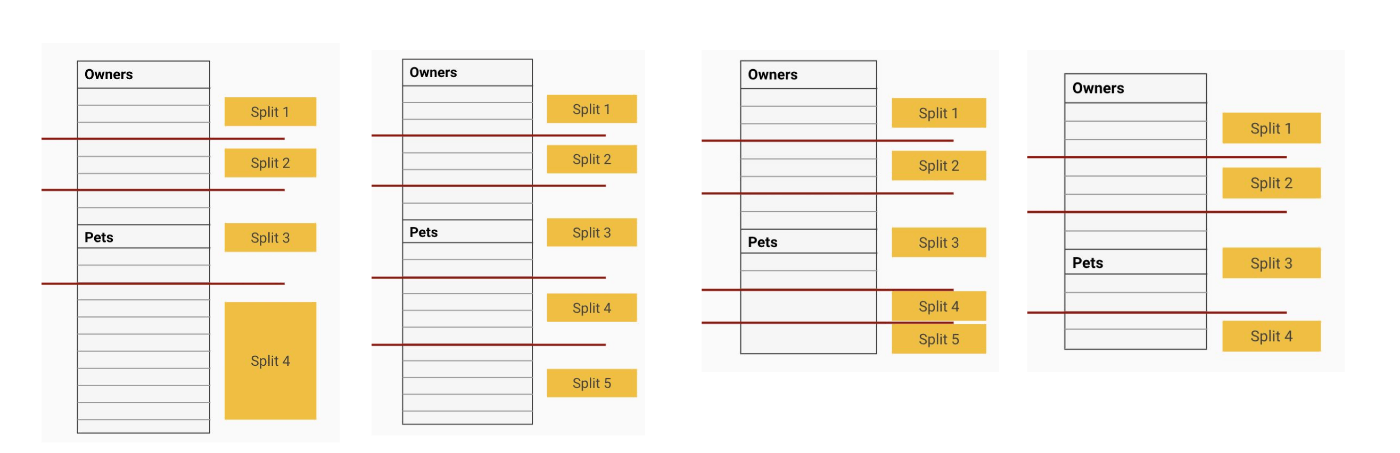
- splitは、時間経過とともに自動的にマージされたり、リバランスされたりする。
- 「どのデータがどのsplitにあるか」という情報は、location metadataというデータに記録されている。これをもとにクエリ時にデータを探し出す。
- それぞれのsplitには、そのsplitへの書き込みを行うリーダーとなるreplicaが割り当てられている。
アーキテクチャがスキーマ設計に及ぼす影響
- テーブルがsplitに分割され、個々のsplitはそれぞれのリーダーによって書き込まれるため、特定のsplitに書き込みが集中するとリーダーが過負荷になる。そのためhot spotを避ける設計が必要。
- また、よくクエリされる、親子関係にあるデータが一つのsplitにまとまっているとその分クエリ効率が良くなる。このためインターリーブの設計が重要
スキーマ設計のベストプラクティス
- とにかくホットスポットを回避し、サーバ間でデータを分割するのが重要。特にデータの一括挿入を行うときに効率的になる。
ホットスポットを回避する主キーの選択
- 値が単調に増加する主キー(e.g., タイムスタンプが先頭につくキー)は、書き込みレートが高いテーブルではNG。これをやると、新規挿入の処理が、全てキー空間の最後を担当するサーバーに行ってしまい、ホットスポットとなる。
- ホットスポットの回避方法
- UUIDをつかう
- ただし、タイムスタンプが上位ビットに格納されるv1はNG。v4が良い。
- UUIDをSTRING(36)列で使うと、Spanner組み込みのGENERATE_UUID()関数で自動生成できる
- ただし、サイズがやや大きいのと、サロゲートキーになるのでレコードに関する情報は持てない
- ビット反転などキーの構成方法
- 単調増加するキーを使った場合も、ビット反転すればホットスポットを回避できることがある。
- また、キーが複数のパーツで構成される場合(e.g., タイムスタンプ + ユーザーID)は、そのパーツの順序を入れ替える(e.g., ユーザーID + タイムスタンプ)ことでホットスポットを回避できることもある。
- ハッシュ化
- 単調増加するキーをハッシュ値にして、それを新しいカラム(e.g., shardId)などとして追加し、これを主キーに入れる
- UUIDをつかう
タイムスタンプキーの使い方
- タイムスタンプをキーにしていて、最新の履歴を読むケースが多いときは、テーブル作成時に
PRIMARY KEY (UserId, LastAccess DESC)などとして降順に並べておくとデータのシークが少なくて済む
ホットスポットを回避するインデックスの貼り方
- インデックス作成の際も、
CREATE NULL_FILTERED INDEX UsersByLastAccess ON Users(LastAccess);などと単調増加するものを貼ってしまうと、同様にホットスポットが生じてしまう。 - これを回避するには、主キーの時と同様、ハッシュ化されたshardIdを追加してそれにインデックス貼るなどが必要。
- ただし、インターリーブされたインデックスの作成においては気にしなくていい(なぜならインターリーブされている時点で、親の行に紐づくサーバにしか書き込みが行かないから)
SQLのベストプラクティス
クエリパラメータを利用する
- 直接変数埋め込みではなくパラメータを使う。SQLインジェクションも防げるし、パラメータの中身が変わっても同じ実行プランを使いまわせる(=Spannerが実行プランをキャッシュしてくれる)ので高速になる
Spannerによるクエリの実行方法を理解する
- コンソールでクエリの実行プランが確認できるのでそれを見てチューニングする
セカンダリインデックスを利用する
- インデックスを貼ると当然クエリは速くなる。
- 新しいデータベースを作ると、3日後にSpannerは自動的にインデックスを使うようになる。インデクスの利用を強制する場合は、
SELECT s.SingerId FROM Singers@{FORCE_INDEX=SingersByLastName}などと明示的に指示することもできる - さらに、index作成時にSTORING句で他のカラムを指定すると、そのカラムだけ欲しいときにパフォーマンスを向上できる
- インデックスが多くなると書き込みが遅くなる。ほとんどのケースでは、インデックスは少なくすることが推奨されている。
スキャンを最適化する
- spannerのクエリでは、データのスキャン時に行指向とバッチ指向の2つがあり、自動で切り替わる。基本的にはそれでいいが、よりチューニングしたい場合は明示的に指定することもできる
範囲キーのルックアップを最適化する
- betweenで範囲指定できるときはそうするし、できないときは
IN UNNEST (@KeyList)みたいにする
joinを最適化する
- 可能な限り、インターリーブされたデータをjoinする。同じsplit内の処理になるので速い。
- よりチューニングしたい場合は、joinの順序や、joinの実装方法も明示的に指定できる
読み書きトランザクションで大量の読み取りを回避する
- 大量の行を読み取るトランザクションがあると、それらの行にはロックがかかり、他のトランザクションから書き込めなくなってしまう。
ORDER BY
- order byをつけないと順序保証されない
LIKEの代わりにSTARTS_WITHを使う
- クエリ効率が良くなる