🔥
REST APIではなく、GraphQLが良い理由



目的
- 今後新たに自分たちの開発に加わる人がいるので GraphQL の大まかイメージをつかんてほしい。
- 新たに開発に入る人たちに、GraphQL の大まかなイメージを掴んでほしい。
- GraphQL の良さをみんなに知ってもらいたい。
REST API とは
- 現在最もメジャーな API の開発技法
- エンドポイントと HTTP メソッドによって処理が決定
- GET localhost:3000/api/user/1 //ある特定の user 情報を取得
- GET localhost:3000/api/users //全ての user の情報を取得
- POST localhost:3000/api/user //user を登録
など
REST API の問題点
エンドポイントの大量生成
- 例として、user に関するメソッドを考えていく。。user に関する必要そうなメソッドを実際どのような場面で使用されるかということと共に説明をしていく。
| エンドポイント | 内容 | 用途 |
|---|---|---|
| /api/user/1 (GET) | 特定(1人)のユーザ情報を全て取得する。 | 全ての情報が獲得できるため、 user 情報変更画面、user 情報確認画面などのユーザ設定画面で使いたい。 |
| /api/users (GET) | 全てのユーザかつそのユーザに含まれる情報を全てを取得。 | 管理者が、user 分析をするとき。 |
| /api/user (POST) | ユーザを登録する。 | 新規登録画面で使いたい。 |
| /api/user/abstract/1 (GET) | 特定(1 人)の絞られた情報を取得(名前のみなど) | 画面のナビゲージョンの右上に〇〇ログイン中と表示したい。 |
| /api/users/abstract. (GET) | 全てのユーザでそのユーザに含まれる限られた情報を取得。 | user が他の人の情報をみたい時。他の人の情報を見たいときに利用。user が他人の情報全てを見られたらヤバイので、見られる情報絞る。 |
表を見る限り、まだ多くのエンドポイント(メソッド)が出てきそう.....
無駄にリソースをとってきちゃう問題
先の上の表を見た時に、別に/api/user/1 (GET) /api/users (GET) /api/user (POST) をよんでフロントエンドでデータを整形すれば 3 つだけで良いと考える人がいるかもしればい。これは、確かに実装上可能だが、無駄な情報をとってきてしまう可能性がある。例えば、トップバー右上の〇〇さんログイン中のところを表示したい時に上記の 3 つのみしかメソッドがない場合は、api/user/1 (GET)を呼ぶことになる。しかしこのメソッドは、ユーザ全ての情報を取得するため、user の email や password,age などいらない情報を多く取得することになる。無駄にリソースをとってきちゃう問題(オーバーフェッチ)によりデータの取得が遅延、データ整形によるプログラムの複雑化が進んでしまう。
GraphQL とは
- Facebook が開発した webApi のためのクエリ言語
- 独自のクエリ言語でリクエストを行う。
- データの問い合わせを Query
- データの書き込みを Mutation
GraphQL の良いところ
単一のエンドポイント
- localhost:3000/graphql のみ
- 独自のクエリ言語で問い合わせ、リクエストを行う。
- 例: 特定のユーザ情報がほしい場合
query{
getUser {
id
name
age
}
}
フロンエンド(リクエストを投げる方)が、必要なデータを決めれる
フロントエンドで必要なデータを決めて、そのデータのみをとってくることが可能。これによりデータ取りすぎちゃう問題を回避することができる。
例:特定の user 情報を取得したいとき
- 全ての情報を取得したい場合
query{
getUser {
id
name
age
email
password
}
}
- 名前だけ欲しい場合
query{
getUser {
name
}
}
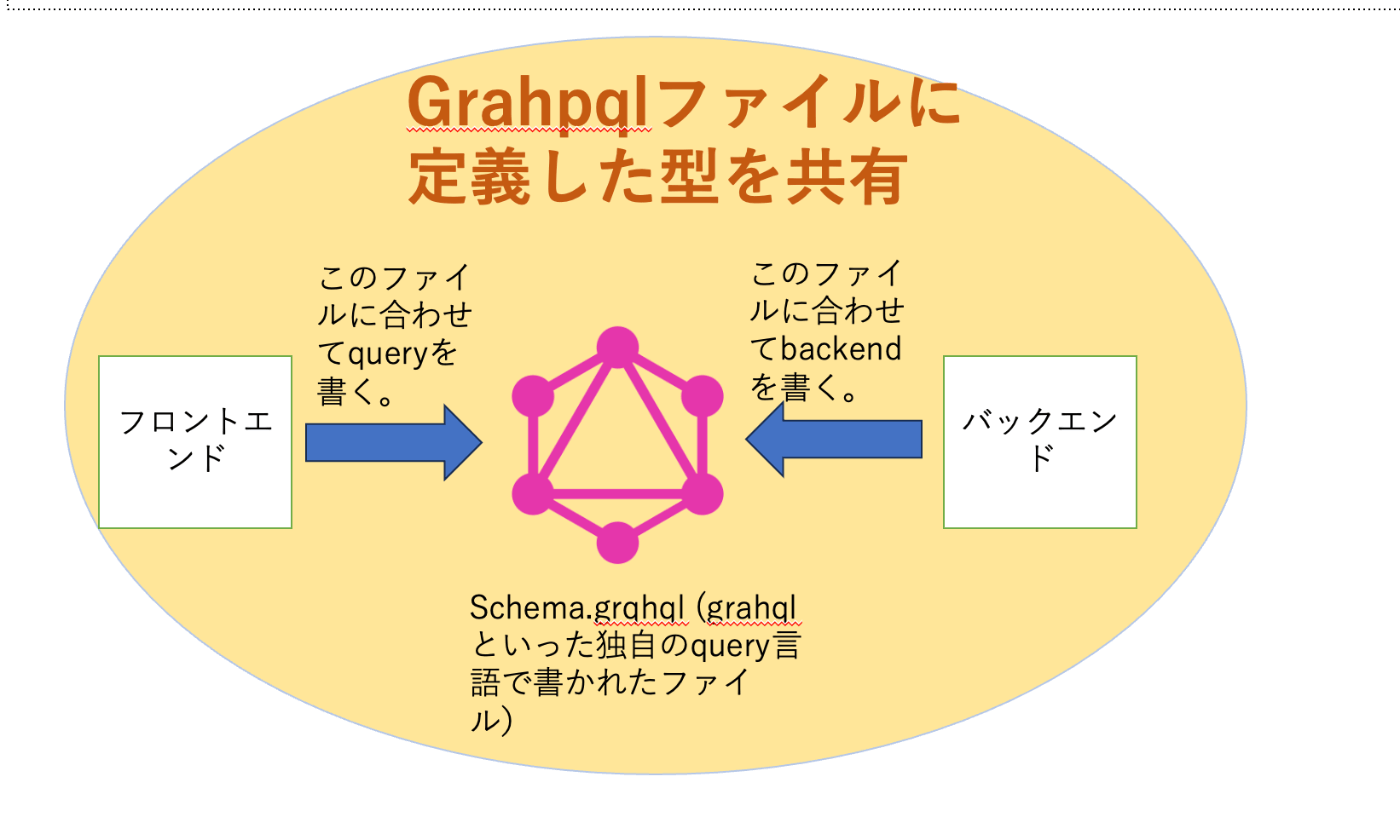
型に強い
GraphQL で作成した型は、フロントエンドとバックエンドで共有できる。これにより、フロントエンドとバックエンドの肩の違いを防ぐことができる。
まとめ
| REST API | GraphQL | |
|---|---|---|
| エンドポイント | 複数存在 api/user/1 api/users api/user/abstract などが必要になり。 | 1 つだけ /grahql のみ |
| データ取得の柔軟性 | 面倒だが、エンドポイントを大量生成 OR 限られたエンドポイントのみを実装し、フロントエンドをデータを整形。無駄な情報をとってきてしまってパフォーマンスが落ちる。 | フロントエンドで必要なものだけを選択して取得できるため 無駄な情報を取得しない& エンドポイントは 1 つだからプログラムが複雑にならない。 |
| 型 | backend との型とフロントエンドの型を揃えないといけないため、型の違いのエラー多発 | バックエンドとフロントエンドで型を共有できるため型によるエラーが起こらない & 型を自動生成もできるため工数削減 |
| メソッドの種類 | GET PUT POST DELETE | Mutation と Query |
Discussion