MediaPipeをMotionBuilderで実行する
この記事はUEC 2 Advent Calendar 2023の19日目の記事です。
昨日はryota2357さんによるPrattパーサを使って電卓を作ってみるでした。つよつよな技術記事で恐れ戦きましたね…。終始口をぽかんと開けることしかできませんでした。
にしても先週技術記事多くないですか()
1. はじめに
初めまして、nadegataといいます。
まず、MIKUEC2023にご来場・ご観覧された皆様、本当にありがとうございました。
MIKUEC2022を見て憧れてVLLに入部した身としては、このような素敵なイベントの制作に関われてとても感慨深いです。
さて、VLLで私は普段ダンス班・モーション修正班としてキャラクターの歌って踊る姿を作っているのですが、その関係で(中略)MediaPipeというものを目にし、興味を惹かれました。 MediaPipeはgoogleが提供する機械学習ライブラリで、例えばこんなことができます。
実は5月ごろに挑戦していたときのメモがあるらしい(以下。結局挫折しました)。
今回の記事は、上の記事を書いたときに成し遂げたかったことのリベンジも兼ね、普段VLLで頻繁に使うMotionBuilderというソフトでMediaPipeを実行しようとした時のことを紹介します。
2. 目的・目標
この記事を書くにあたって自身で設定した目標・目的は以下の通り。
- MotionBuilderでのスクリプティングに触れる
- MediaPipeをMotionBuilderで実行する
- MediaPipeを使って得られるデータを用意したキャラに適用する
3. 前提
3.1 MotionBuilderについて
Ⅱ類・Ⅲ類の一部の方はAutodesk社のAutoCADやFusion360を使ったことがあると思います。
MotionBuilderは同じくAutodesk社が提供するソフトウェアで、モーションデータのモデルへの適用、およびキャラクターモーションの作成に特化しています(多分)。
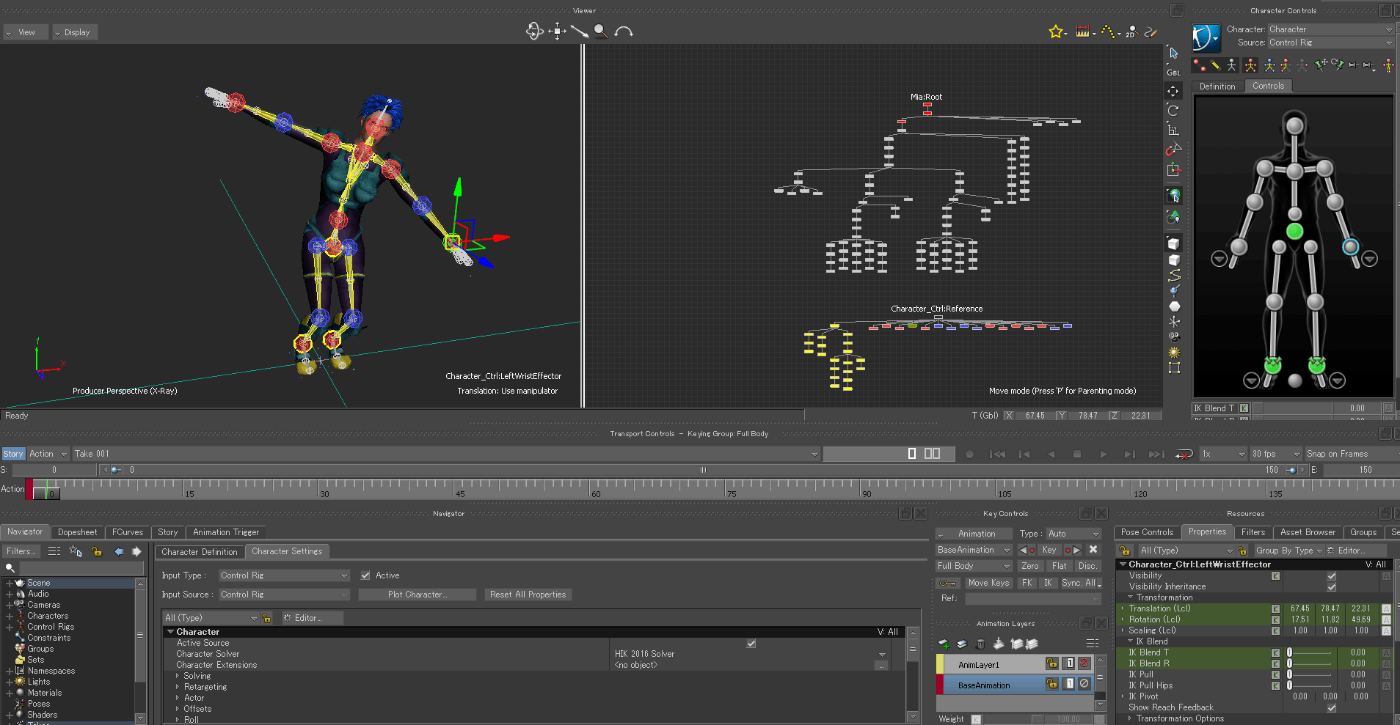
操作画面の例
VLLでは、モーションキャプチャーで得られたデータに含まれるノイズの除去や、ポーズ修正でこのソフトウェアが活躍します。PythonとC++のSDKがあり、特にPythonに関してはMotionBuilder上で実行できる機能があります。
3.2 MediaPipe Pose Detectionについて
以下画像はリンクより。

デモがあるのでぜひ体験してみてください(ウェブカメラへのアクセスを求められます)。速く、精度が高いのがお分かりいただけると思います。
4. PythonコードをMotionBuilderで実行する
MotionBuilderでどのようにpythonが実行されるかはこちらの動画が分かりやすいです。
ゆっくりやっていきます。
MotionBuilderにて、
画面左上 Settings >> Preferences >> Python >> Python startup folder のパスを確認。
以下の形になっているでしょうか(違う場合は書き換えてください)。
C:\Users\<username>\Documents\MB\"MotionBuilder <VersionNumber>"\config\PythonStartup
これはMotionBuilder起動時に参照されるフォルダであり、さらに起動時にフォルダ内の.pyファイルが自動的に実行されるフォルダの1つです。テストとしてtest.pyを管理者権限で作成、上記フォルダーに保存し、MotionBuilderを起動してみます。
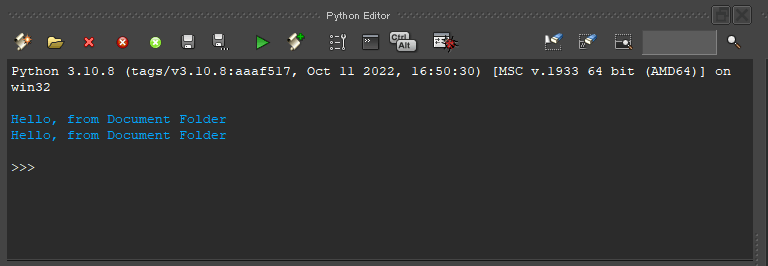
画面左上Layout >> Scripting >> Python Editorを見ると、確かにtest.pyが実行されていることが分かります。(2回実行されていることについては今回は触れません。)
ちなみに、Python Editorはいわゆる対話モードと同様に使います。キーボード操作に難ありだと思うので一覧の参照をおすすめします。
また、以下のようにコードを実行すれば、外部で作成したpyファイルを実行することもできます。

これでまず一つ目の目標は達成しました(実は私の中で初めての快挙)。
5. MediaPipeはMotionBuilderで実行できるか
5.1 事前準備
まず各パッケージをインストールします。
-
MediaPipe
mediapipe-0.10.9-cp310-cp310-win_amd64.whlです。 -
OpenCV
opencv_python‑4.5.5‑cp310‑cp310‑win_amd64.whlです。非公式なので注意
数あるパッケージから上記のものを選ぶのは、MotionBuilder内で動いていると思われるPythonのバージョンが3.10.xxだからです。「cp3xx」はPythonのバージョンを表しています。
次にコマンドプロンプト(管理者権限)から上記ファイルの保存場所にて以下コードを実行し、mediapipeとOpenCVのパッケージをンストールします。
mobupy -m pip install mediapipe-0.10.9-cp310-cp310-win_amd64.whl
mobupy -m pip install opencv_python-4.5.5-cp310-cp310-win_amd64.whl
mobupyって何だと思われるかもしれません。実はMotionBuilderで実行するファイルでパッケージが必要になる場合に注意することがあります。以下公式ヘルプより。
pip は、MotionBuilder Python インタプリタの mobupy を使用してコマンド ラインから呼び出されます。 MotionBuilder Python スクリプト エディタからは呼び出せません。
パッケージをインストールするには、Windows の場合は管理者権限、Linux の場合はスーパー ユーザ権限が必要になります。
MotionBuilder の site-packages フォルダへのインストール:
mobupy -m pip install <flags> <package> (管理者として実行しているコマンド ウィンドウから実行)
つまりコマンドプロンプト等でpy pip install <package>を実行するのではなく、mobupy pip install <package>というコードを実行するように、とのこと。さらにインストールするパッケージは専用のフォルダに保存されるようです。
もしエラーが出る(mobupyを認識しない)場合は、環境変数PathにC:¥Program Files¥Autodesk¥MotionBuilder <VersionNumber>¥bin¥x64を追加し、再起動して再度コマンドを実行してください。
最後にMotionBuilder上のPython Editorにてモジュール検索パスを調べます。
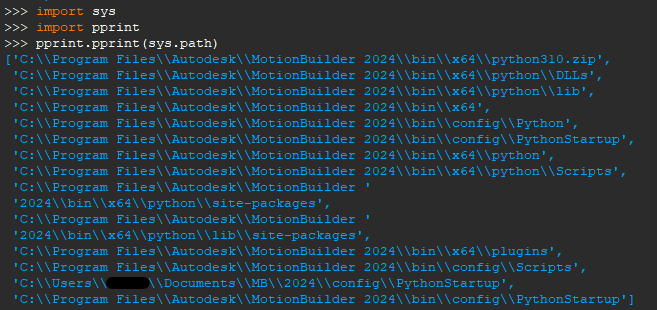
mobupyによるパッケージ保存先site-packagesフォルダにもパスが通っていることが確認できました。
5.2 実行
コードは公式githubより。
import cv2
import mediapipe as mp
import numpy as np
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_pose = mp.solutions.pose
# For static images:
IMAGE_FILES = []
BG_COLOR = (192, 192, 192) # gray
with mp_pose.Pose(
static_image_mode=True,
model_complexity=2,
enable_segmentation=True,
min_detection_confidence=0.5) as pose:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
image_height, image_width, _ = image.shape
# Convert the BGR image to RGB before processing.
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_height})'
)
annotated_image = image.copy()
# Draw segmentation on the image.
# To improve segmentation around boundaries, consider applying a joint
# bilateral filter to "results.segmentation_mask" with "image".
condition = np.stack((results.segmentation_mask,) * 3, axis=-1) > 0.1
bg_image = np.zeros(image.shape, dtype=np.uint8)
bg_image[:] = BG_COLOR
annotated_image = np.where(condition, annotated_image, bg_image)
# Draw pose landmarks on the image.
mp_drawing.draw_landmarks(
annotated_image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
# Plot pose world landmarks.
mp_drawing.plot_landmarks(
results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
# For webcam input:
cap = cv2.VideoCapture(0)
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pose.process(image)
# Draw the pose annotation on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Pose', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Viewerにこのファイルを直接ドラッグアンドドロップ、またはexec(open("./PoseLandmark.py").read())を実行します。

画像はFaceLandmark実行時。PoseLandmark.pyでも同様
(注:顔と部屋がしっかり映ってしまっているので出力は隠しています)
確かに実行することができたので、これで2つ目の目標も達成です。
6. MediaPipeで得られたデータをMotionBuilderで利用する
いよいよ最後の目標「MediaPipeを使って得られるデータを用意したキャラに適用する」に挑戦していきます。これにはあと2つの課題に取り組まないといけません。
- Mediapipeで得るデータをMotionBuilderで取得
- モデルにリターゲット
6.1 MediaPipeで得られるデータを取得・反映
Mediapipe Pose landmark detectionでは、1フレームにつき、以下のlandmarkが出力されます。
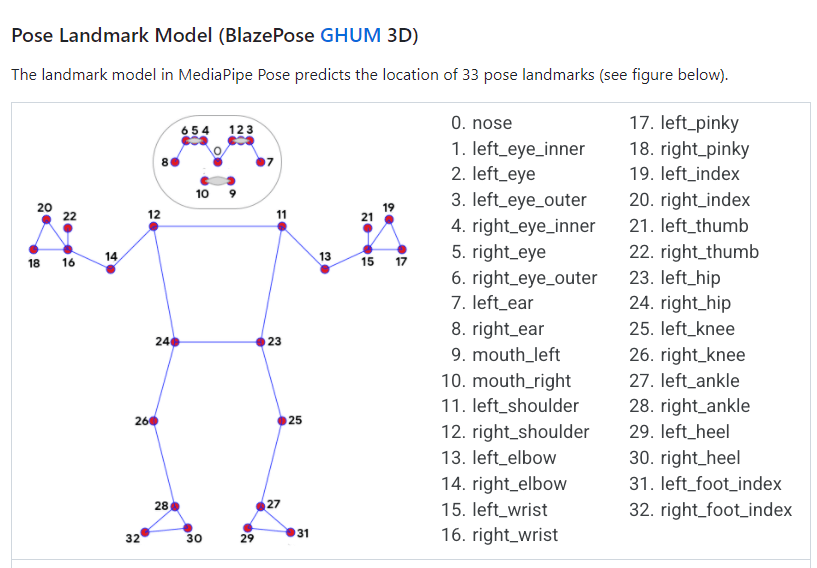
githubより
高速かつ大量に得られるデータを初めから処理しようとするのは困難なため、まず鼻のlandmarkのみの座標を取得し、その座標をMotionBuilderでマーカーに反映することに取り組んでみます。
上記コードの# For webcam input:以下を次のように書き換え、さらに1行目にfrom pyfbsdk import *を追記します。
# For webcam input:
cap = cv2.VideoCapture(0)
# create marker in MotionBuilder
mark = FBModelMarker("marker")
mark.Show = True
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pose.process(image)
#get Nose Landmark and expand them
xPos = -10*results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x
yPos = -10*results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y
zPos = results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].z
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
# apply Nose's position to marker's position
mark.Translation = FBVector3d(xPos, yPos, zPos)
cv2.imshow('MediaPipe Pose', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
pyfbsdkはMotionBuilderのAPIにアクセスするためのモジュールです。詳細はこちら。
これで初めに作成した赤いマーカーが鼻のlandmarkの座標に従って移動するようになりました。
すなわち、画面に出力されているウェブカメラからの映像に映る私の動きの通りに、MotionBuilder上でマーカーが動くようになりました(以下)。
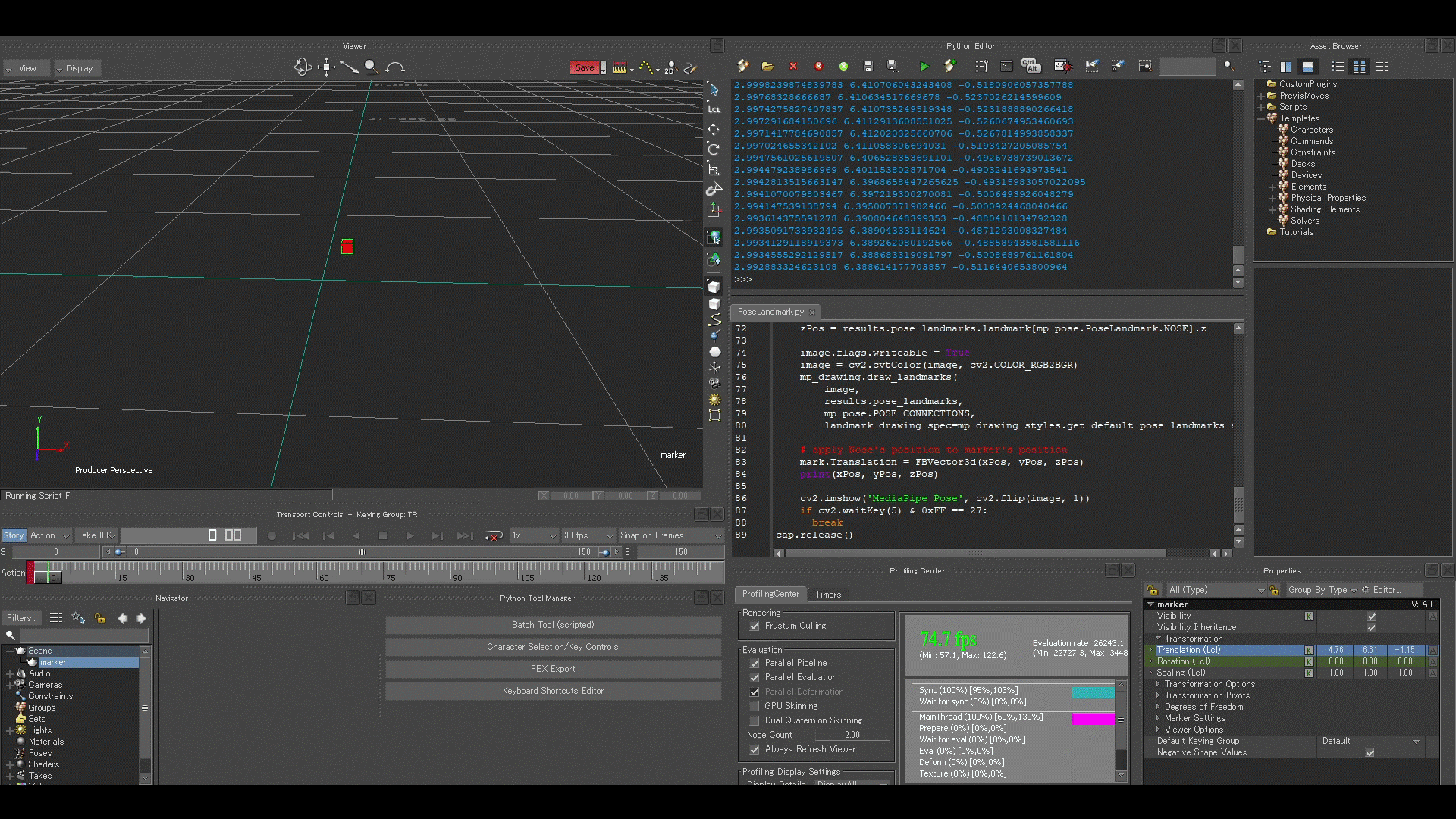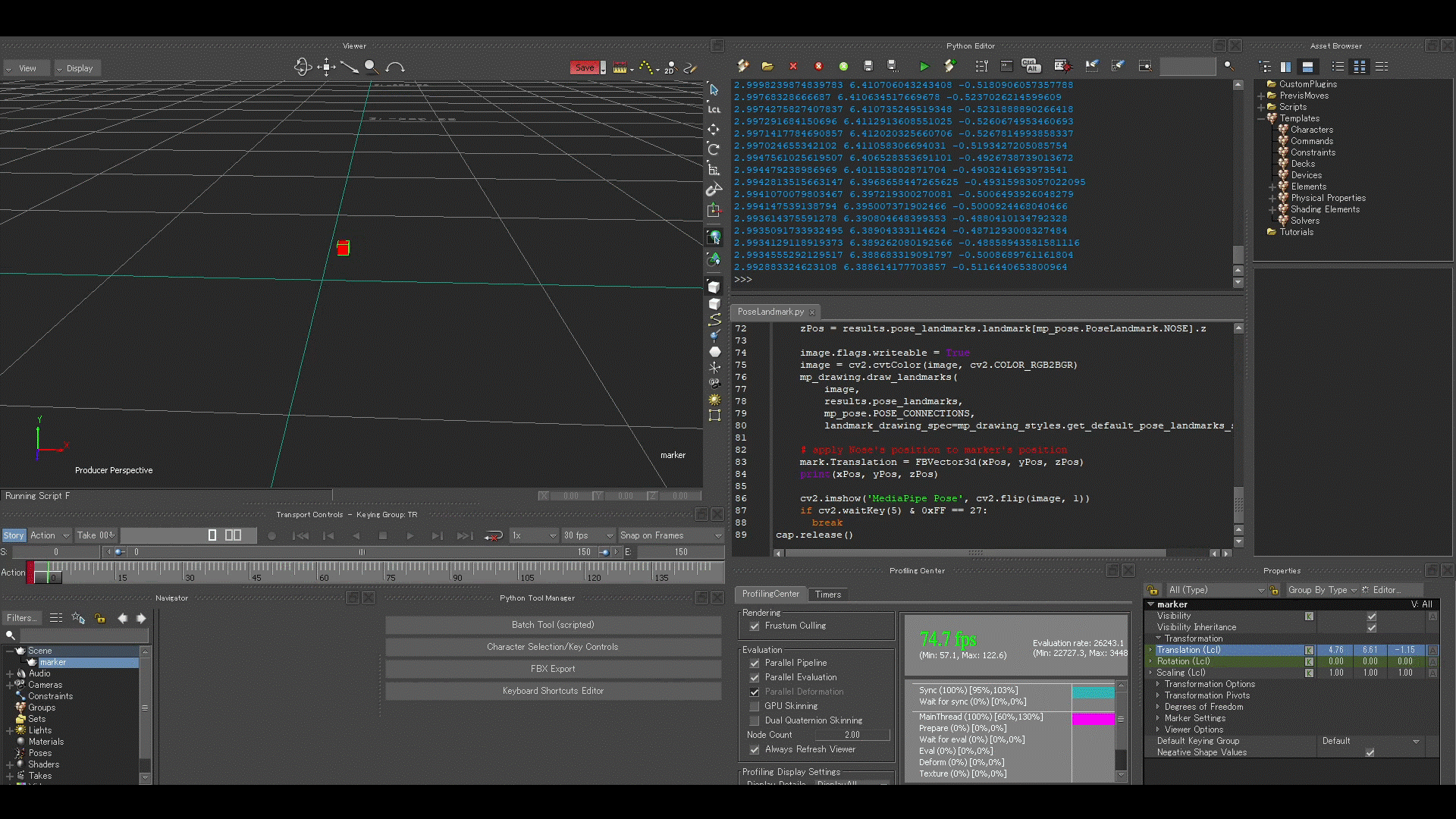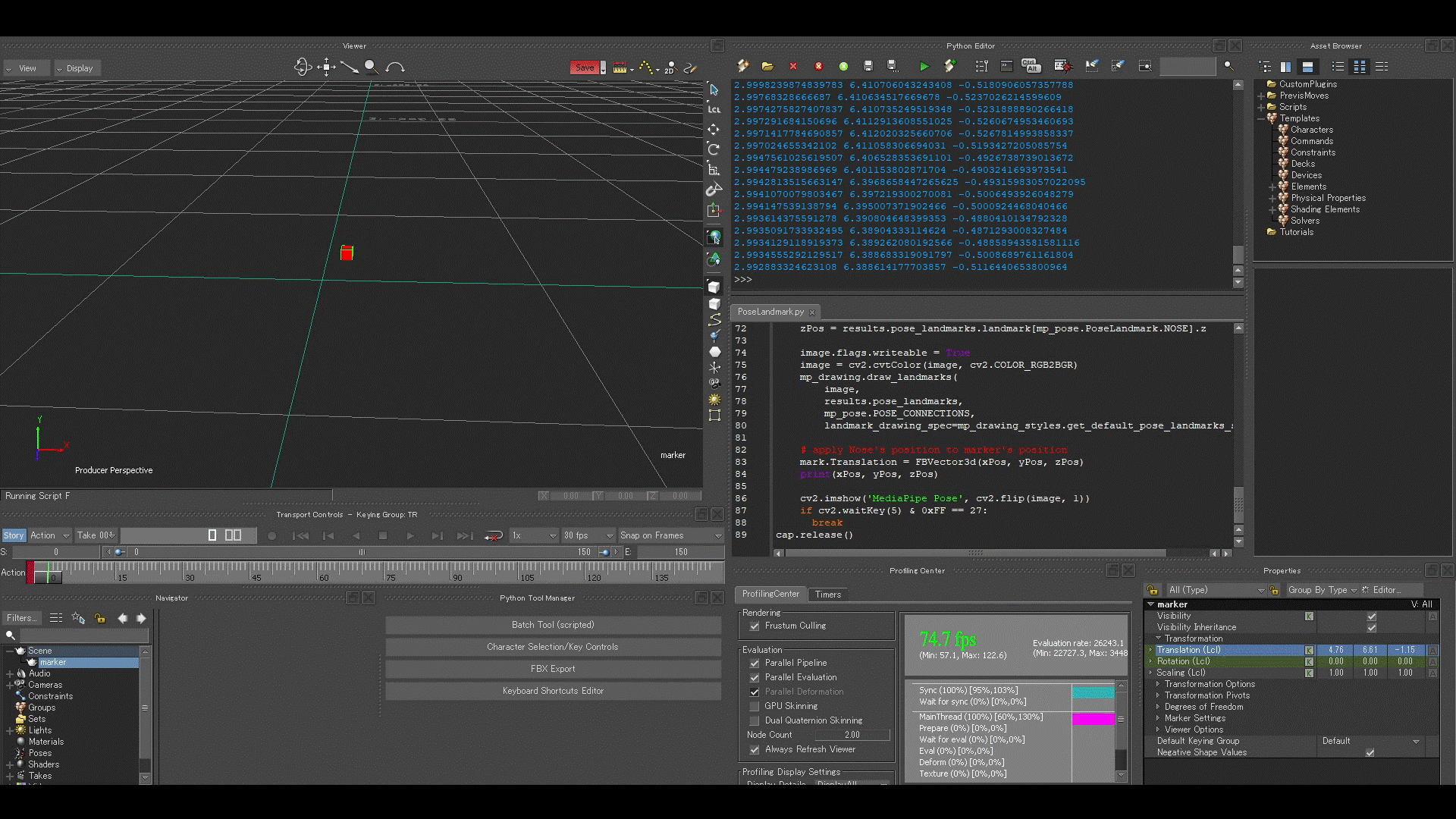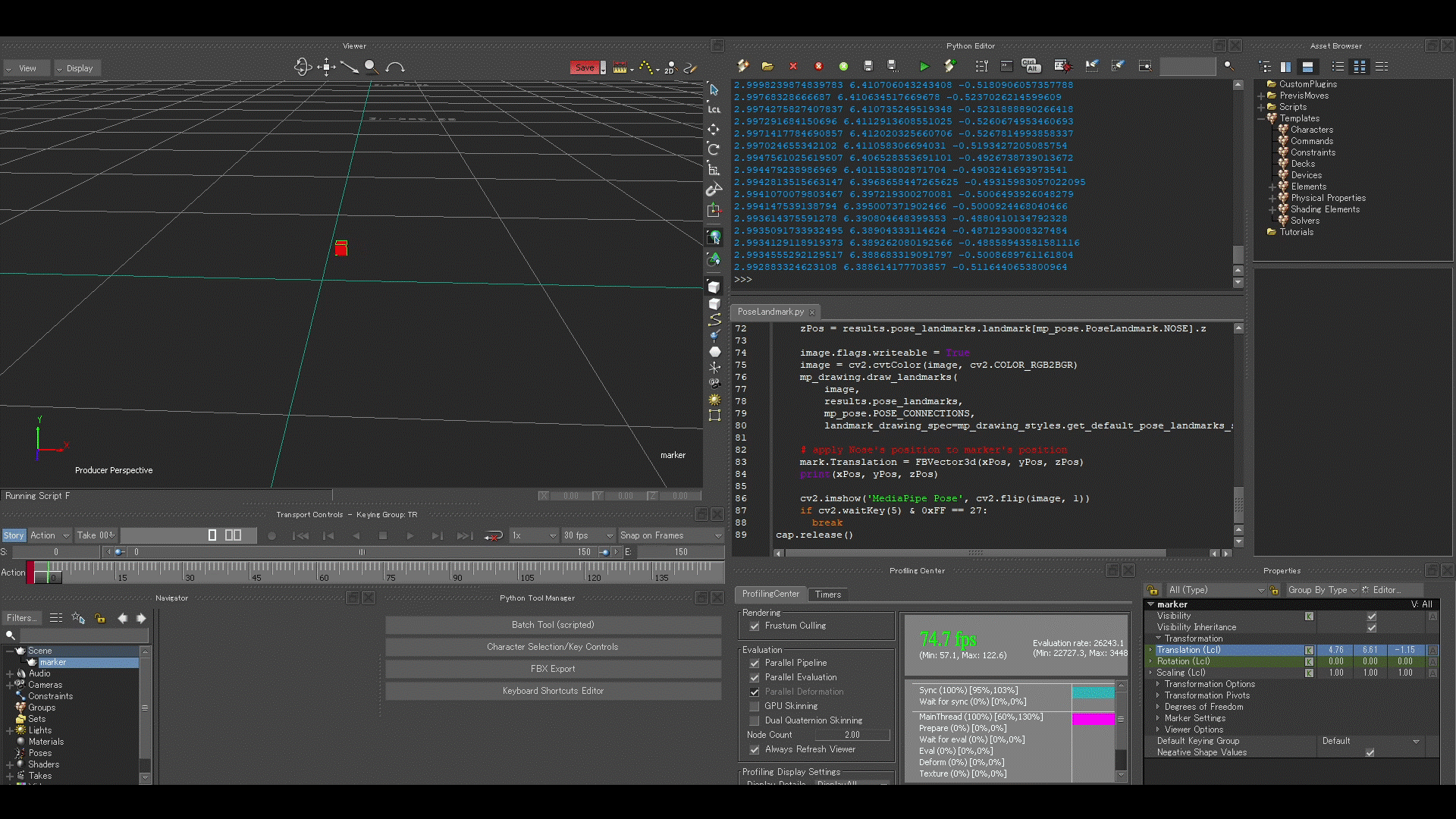
これを応用します。
この後のリターゲット時には32個のlandmarkが必ずしも要る訳ではないこと、また全て反映させると動作が重くなること、さらに各landmarkが上記画像のように数字で指定できることを踏まえて、実際にlandmarkの座標を反映するマーカーを選び上記コードを応用したものが以下。
# For webcam input:
cap = cv2.VideoCapture(0)
# Create list of each element
mark = [0]*29
xPos = [0]*29
yPos = [0]*29
zPos = [0]*29
# create marker in MotionBuilder
mark[0] = FBModelMarker("marker0")
mark[0].Show = True
for i in range(11,17):
mark[i] = FBModelMarker("marker%d"%(i))
mark[i].Show = True
for j in range(23,29):
mark[j] = FBModelMarker("marker%d"%(j))
mark[j].Show = True
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pose.process(image)
#get Landmarks'position and expand them
xPos[0] = -100*(results.pose_landmarks.landmark[0].x)
yPos[0] = -100*(results.pose_landmarks.landmark[0].y)
zPos[0] = results.pose_landmarks.landmark[0].z
for i in range(11,17):
xPos[i] = -100*(results.pose_landmarks.landmark[i].x)
yPos[i] = -100*(results.pose_landmarks.landmark[i].y)
zPos[i] = results.pose_landmarks.landmark[i].z
for j in range(23,29):
xPos[j] = -100*(results.pose_landmarks.landmark[j].x)
yPos[j] = -100*(results.pose_landmarks.landmark[j].y)
zPos[j] = results.pose_landmarks.landmark[j].z
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
# apply Nose's position to marker's position
mark[0].Translation = FBVector3d(xPos[0], yPos[0], zPos[0])
for i in range(11,17):
mark[i].Translation = FBVector3d(xPos[i], yPos[i], zPos[i])
for j in range(23,29):
mark[j].Translation = FBVector3d(xPos[j], yPos[j], zPos[j])
cv2.imshow('MediaPipe Pose', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
同じく# For webcam input以下の書き換えです
出力結果は以下の通り。
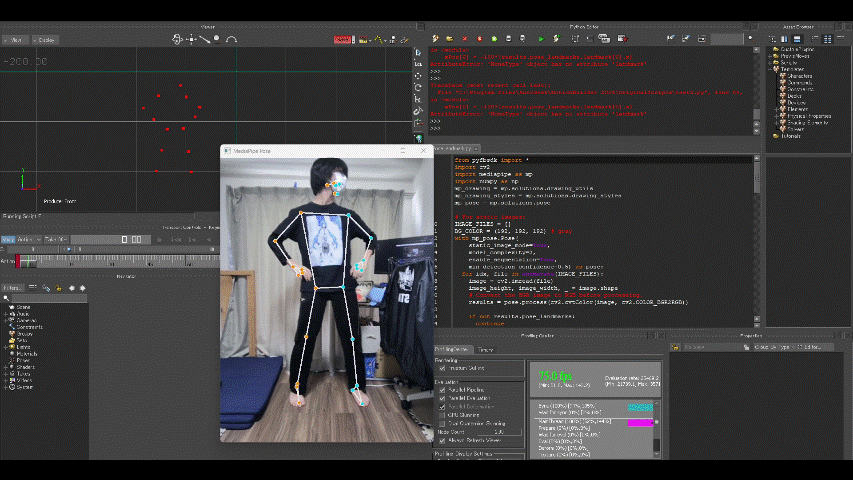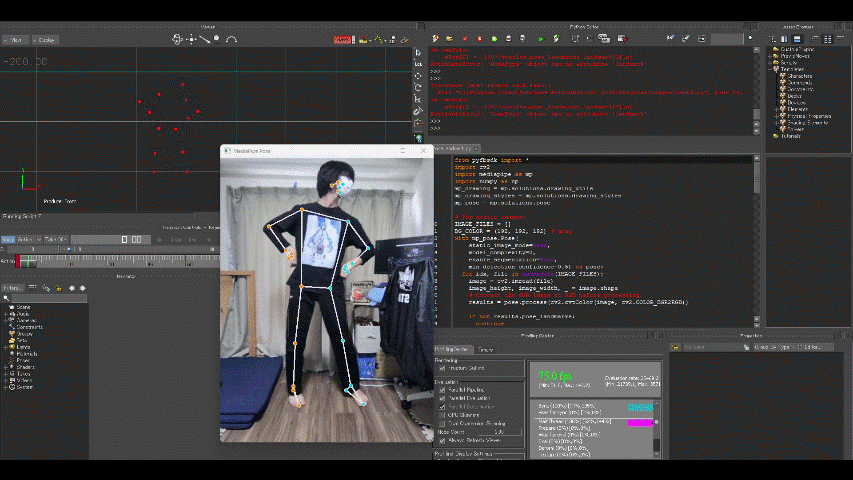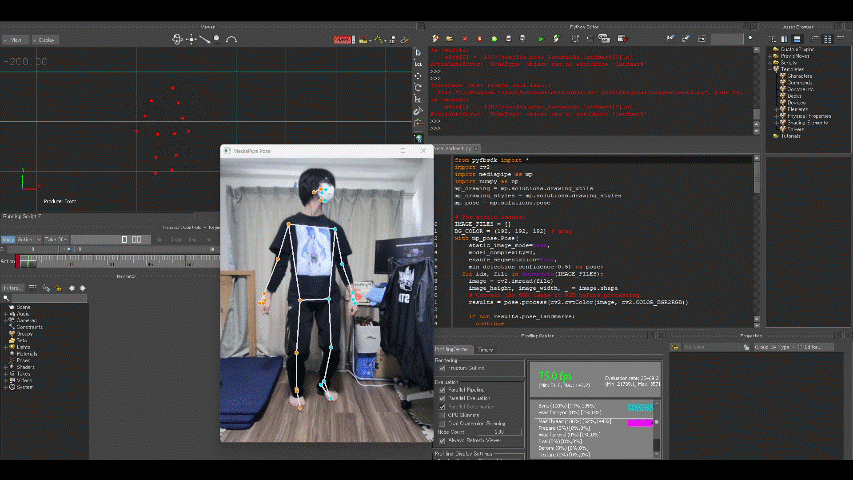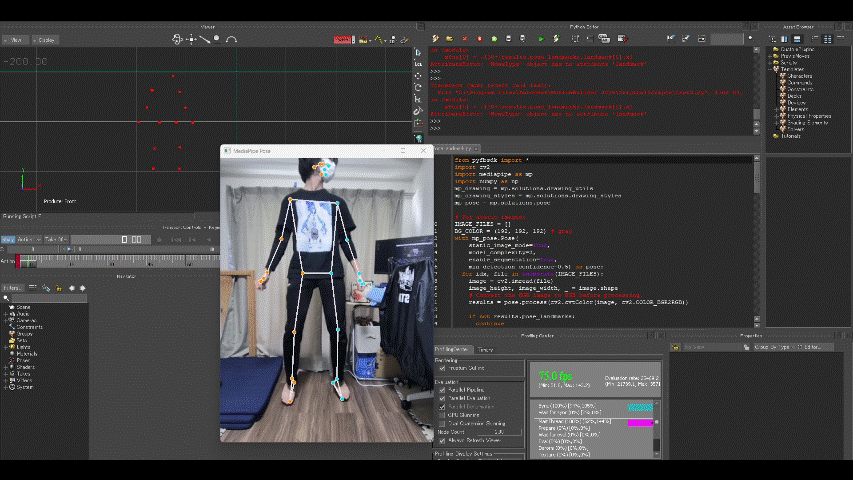
マーカーの動きをモデルに適用するには十分すぎる精度です(感激)。
1つ目の課題がクリアできたので、最後の課題であるモデルへの適用をやっていきましょう。
6.3 マーカーをモデルにリターゲット
MotionBuilderでの操作はここでは触れません。
マーカーの動きをモデル(MotionBuilder Tutorialsフォルダのmia_characterized.fbx)に適用した結果が以下。
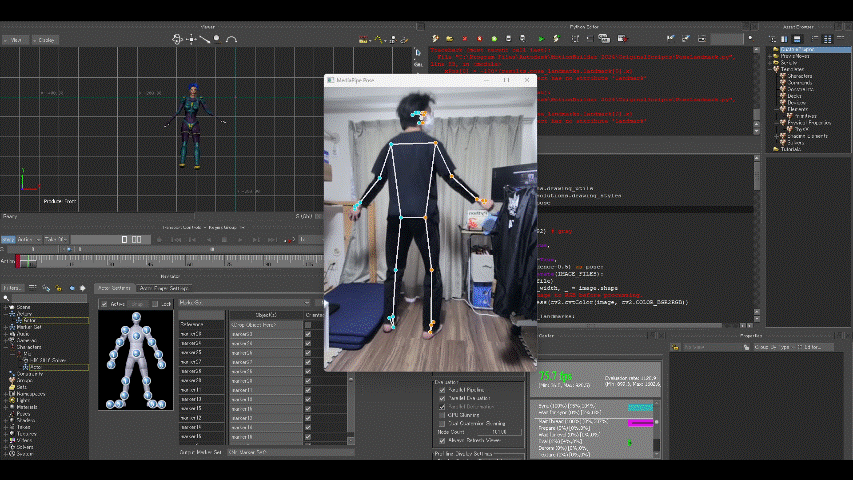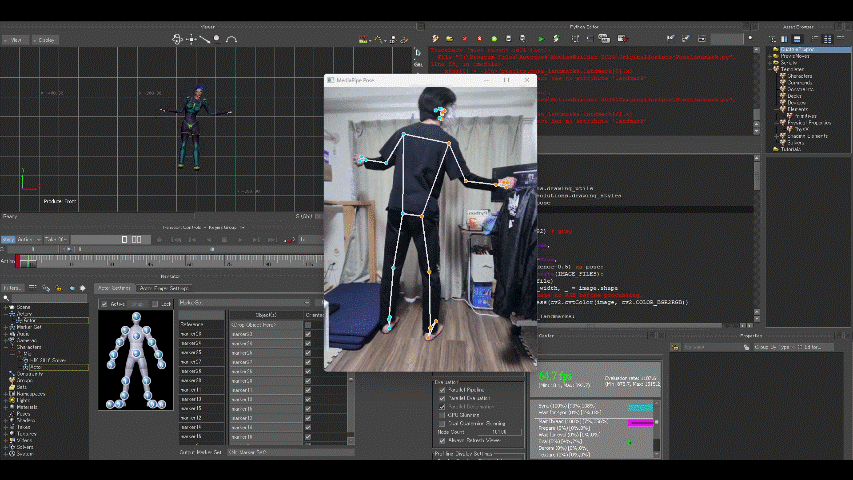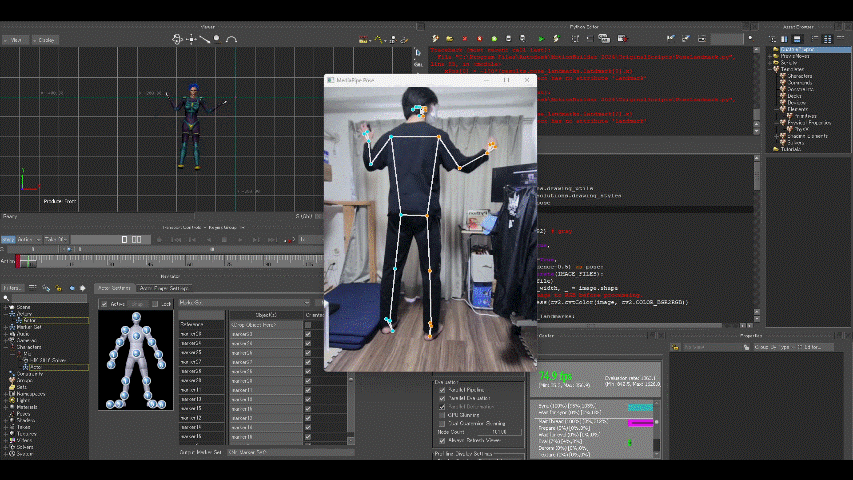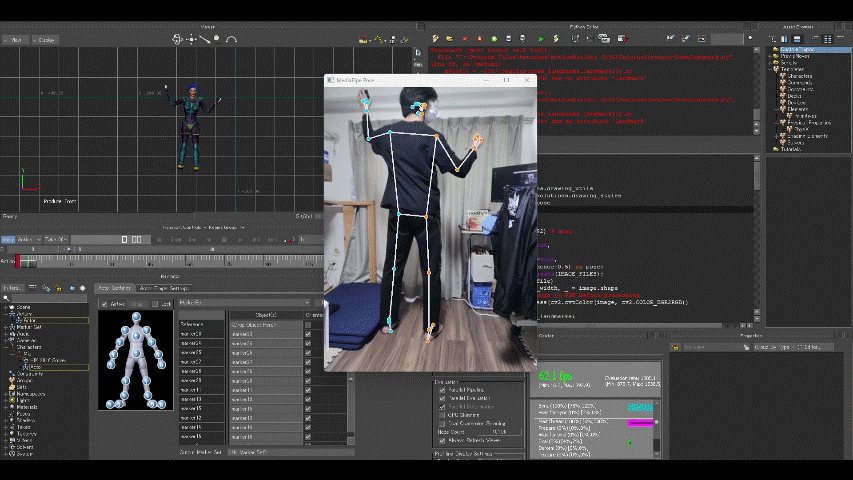
えぇ、動きがぎこちないって? ……完全に私の技量不足です。
マーカーだけのときは高精度だったので、モデルへの適用がうまくいってません。
モデルの骨格と自分の骨格の違いも考えていないし、キャリブレーションもしていない、微調整もしていない、、、。一応少しは粘ってみた(左右が逆なのも調整した結果です)のですがマーカーの動きをモデルへ利用するにはまだまだ練習が要りそうです。
ただ、これで最後の目標も達成できたので、最初に設定した目標を完遂することができました。
7. さいごに
まずはここまでお付き合いくださり、ありがとうございました。
大学生になってそろそろ2年経つのだから電通大生っぽい(プログラム書けたり何かしら開発できたり)ことがしたいと熱望していたので、今回でその夢はほぼ叶えられたかなと思います。
少し話を戻すと先ほどの出力結果は、カメラに対して正面を向いたときは非常に精度が高いのですが、カメラに対してlandmarkが重なったり、体を横に向けたりすると急に精度が落ちます。画像認識でのポーズ推定なので仕方がないと思いますが、今後はカメラを2台以上にして、ある方向からは重なって認識できない部分を、別のカメラからの入力で補完できるようにしたいですね。とはいえ、今の私にとっては十分すぎる結果です。本当に嬉しいです。
実は今日がVLLに入って丁度1年となります。大学に入って初めて勉強そっちのけで没頭できるくらいの夢を見させてもらって、先輩や仲間の支えのおかげで少しずつ技術が身に付き、一緒に制作に取り組んでくれる頼りになる後輩もいて、充実した毎日でした。
ちょっと授業をサボりすぎたかな、、、まぁいいや
改めて長文にお付き合いくださりありがとうございました。
明日のUEC 2 Advent Calendar 2023は、シチリア産ぽんかんさん担当です。「弾丸単発旅のすゝめ」とのこと、お楽しみに~
Discussion
実行開始時に鼻のlandmarkを検出しないとエラーが返され、実行が停止するようです