「DifyではじめるRAG」開発セミナー(2)
生成AI協会(GAIS)の渡辺です。
前回
■「DifyではじめるRAG」開発セミナー(1)
で、ご紹介した、2024年5月30日(木)に一般社団法人 生成AI協会(GAIS)がオンラインで開催した 「RAG 開発セミナー」 にて、アステリア株式会社のエバンジェリストであり、生成AI協会のエバンジェリストでもある 森一弥氏 のセミナーの模様の続きになります。
森氏は、Difyの実際の使用方法についてデモを行いました。
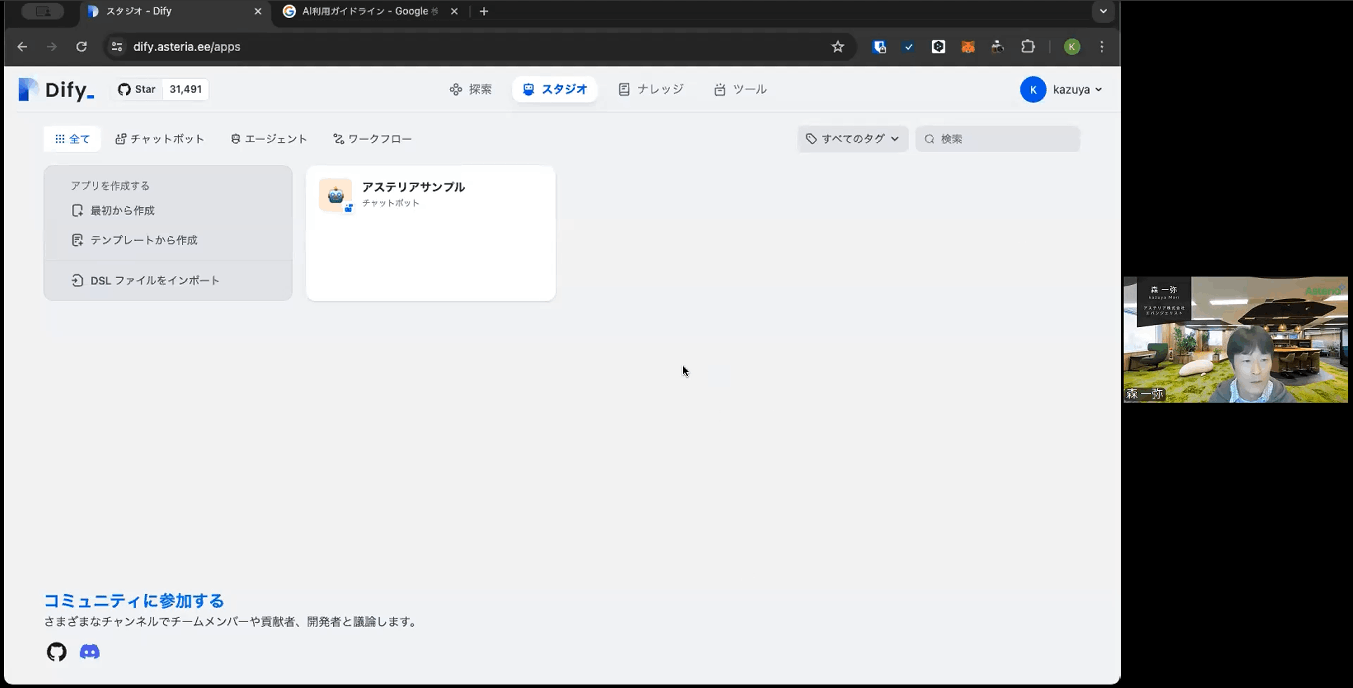
こちらがDifyにログインした際の画面です。チャットボットを作れるスタジオという形です。
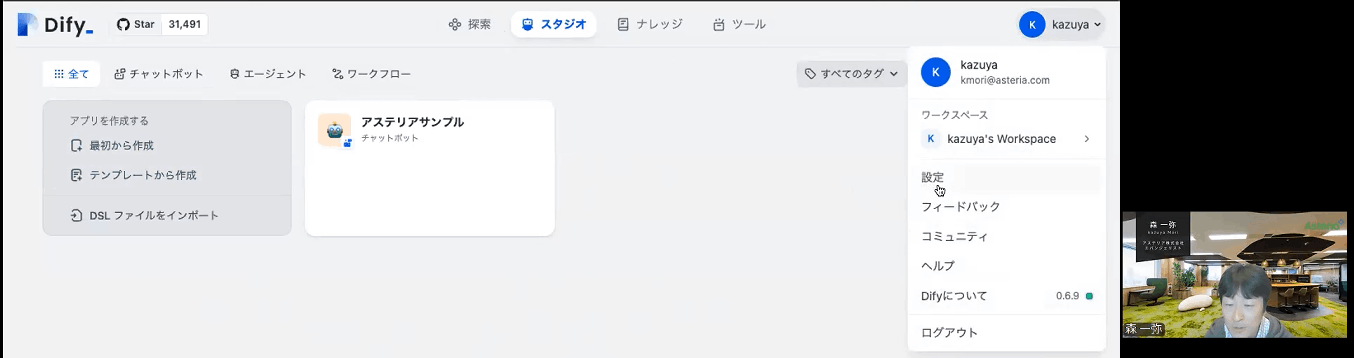
最初にやるのは「ユーザー」の中の「設定」から

「モデルプロバイダー」を選択します。「OpenAI」とか「Gemini」とかクラウド上のLLMだけでなく、ローカルにLLMを作って、それを連携させることも可能です。

「モデルプロバイダー」の画面の右上「システムモデル設定」でデフォルトのモデルを選択します。今回は「gpt-4」を選択しています。
それでは、RAGを作っていきたいと思います。

上のメニューから「ナレッジ」を選択します。RAGの元にする文章を入れていきます。この内側にベクターストアがあって、その中にデータを入れていくのはこの「知識を作成」をクリックします。

ここにファイルをドラッグ&ドロップするだけです。ひとつのファイルの上限が15MBとなっていますが、そこは設定ファイルで変更が可能です。
今回は「総務省AI利用ガイドライン.pdf」を選択してみました。「次へ」をクリックすると

テキストの前処理の画面になります。いわゆる「チャンクに分割する」という画面になります。
通常、プログラムでやる場合は、ひとつのチャンクを500文字にする、とか、前後とのかぶりを何文字にします、とかノウハウ的な知識も必要になりますが、このDifyのいいところは「自動」を選択すれば、いい感じに処理をしてくれます。
ベクター形式に変換する際に、普通はエンベッティングという生成AIの技術のひとつを使いますが、この「高品質」はおそらくOpenAIのAPIを使っていて、APIの利用料がかかります。もうひとつの「経済的」の方は、内蔵の仕組みを使っているようで利用料がかかりません。
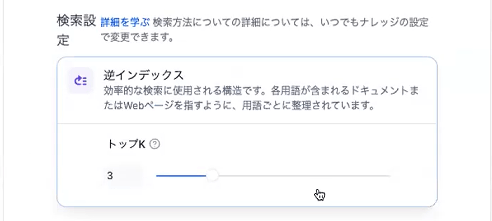
次に下の方の検索設定で、「トップK」が「3」となっています。これは、検索した際に結果を何件取得するかの設定で、上位3件を利用する設定になっています。「保存して処理」をクリックすると、データをチャンクに分割して埋め込みする、という処理が行われます。
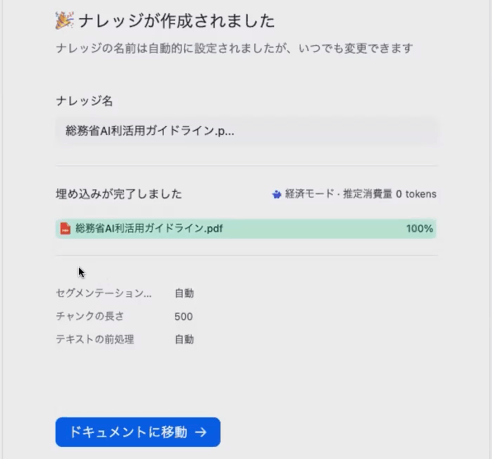
処理が完了したら「ドキュメントに移動」をクリックして戻ります。

ドキュメントに戻りましたら、読み込んだ文書をクリックして中を見てみます。

このようにチャンクに分かれたものが、確認できます。この1個1個のチャンクは、編集できるので、精度を上げたいときに活用できます。例えば、目次とかが検索結果に出てきても意味がないので、このデータは要らないと思ったら、ゴミ箱マークをクリックして消すことができます。
さて、文書の準備が出来ましたので、RAGの仕組みを作っていきたいと思います。
「スタジオ」の「アプリを作成する」の中から今回は「最初から作成」を選択します。

いろんなタイプのアプリを作れますが、RAGを作りたいので、「チャットボット」を選び、「チャットボットのオーケストレーション方法」として「Chatflow」を選択します。
「アプリのアイコンと名前」ですが、今回は「RAGテスト」とします。「作成」をクリックするとこのような画面になります。

いま、選択しているLLMの詳細が表示されています。

流れが示されて、直感的にわかると思います。左から仕組みが開始されて、LLMに問い合わせをして、結果が返ってくる流れが出来上がっています。

今回はRAGを作りたいので、このChatGPT-4に問い合わせをする前に、先ほどナレッジで読み込んだ文章を参考にしてほしいので、ここの間にプラスで「知識取得」を選びます。

すると箱が1個追加されますので、箱の中身を設定していきます。
「知識」を押して、+(プラス)のボタンを押して、先ほど読み込んだ文書を選択します。

「追加」のボタンをクリックすると、これでもう最初に入力した質問の内容を踏まえて検索してくれるようになりました。

次に、このLLMのところに「システム・プロンプト」を入れていきます。ひとつ前の「知識取得」の検索結果を踏まえて回答してもらうように、「コンテキスト」に「知識取得」の「結果:result」を入れます。「システム・プロンプト」には、「質問の内容を、参考情報を踏まえたうえで回答してください」のように入れてみます。「### 参考情報」で「コンテキスト」を選択し、「### 質問内容」で「sys.query」を選択します。
本番の時は、英語で書いた方が多少はAPIの利用が安くなったりするかもしれません。
ちなみにこの「###」(シャープ記号3つ)は、OpenAIのマニュアルにも書いてありますが、セクションを分けるような記号です。

上の「デバッグとプレビュー」をクリックするとチャットのインターフェースが出てきますので、試しに「生成AIについて教えてください」と入力してみます。
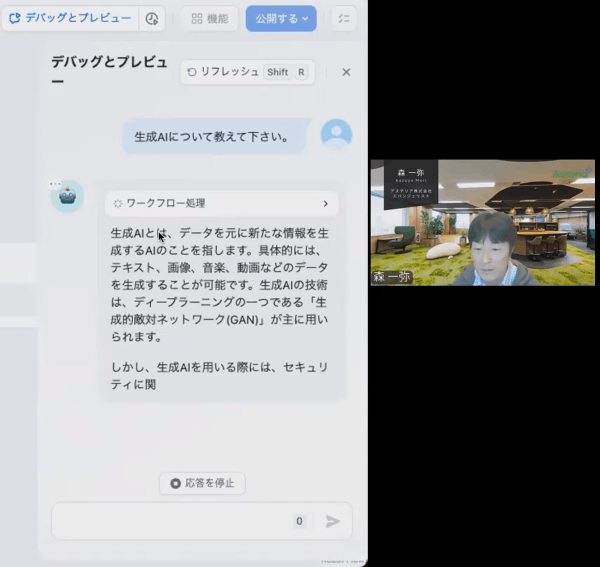
そうするとこんな感じで、回答が出てくるRAGの仕組みが出来ました。

本当にデータベースの内容を参照しているのか、わかる仕組みが入っています。
「ワークフロー処理」を開いて、最初の「開始」のところを開くと、私が入力した「生成AIについて教えてください」というのが入っています。それに対して

この「知識取得」のところで、データベースを検索しにいって、「総務省AI利活用ガイドライン.pdf」の中から、関連事項を引っ張って来てくれているのがわかります。

そしてLLMにいって、その回答が出てきてることがわかります。このようにデバッグが可能な仕組みになっています。

上のメニューで「公開する」を選択してアプリを公開します。アプリとして実行することも出来ますし、「サイトに埋め込む」を選択して

既存のWebサイトに、フレームを切って入れたり、右下の方に表示するようにすることも出来ます。
こんなに簡単にRAGが作れてしまいますので、皆さんもぜひ試してみてください。

ちなみに、この「ツール」というメニューでは、さまざまなツールとの連携が出来るようになっています。Googleで検索して、その結果を踏まえて回答するアプリも作れますし、画像生成系やWikipediaとか、YoutubeやStable Diffusionなどと連携することも可能です。このツールの活用で、いろんな仕組みが簡単に作れることがお分かりいただけると思います。

まとめとしては、自社のデータは、RAGの環境を作ることで利活用が進むのではないかと思います。生成AIの技術革新の競争が激しい中、より優れたLLMのモデルが出てきた時に、LLMを切り替えることも出来ますし、ノーコード・ツールの「Dify」が便利だということがわかっていただけかと思います。

もう少し詳しいお話しが聞きたいという方は、個別のご相談も承っておりますので連絡をいただければと思います。本日はありがとうございました。
森氏はGAISの公式WebにDifyについて次の記事を投稿しています。こちらも参考にしてください。
■プログラムのいらないAI開発「Dify」のインパクト(森一弥氏)
https://gais.jp/dify-impact/
■ライター紹介:渡辺 誠(わたなべ まこと)
ご連絡は Facebook に
- NPO法人 IoTメディアラボラトリー 理事
- 一般社団法人 生成AI協会(GAIS) 理事
- センスウェイ株式会社 CTO
- 東京ワイン倶楽部 幹事メンバー
- 日本ソムリエ協会(J.S.A.) ワインエキスパート
Discussion