Open2
Difyで画像生成AIを作る
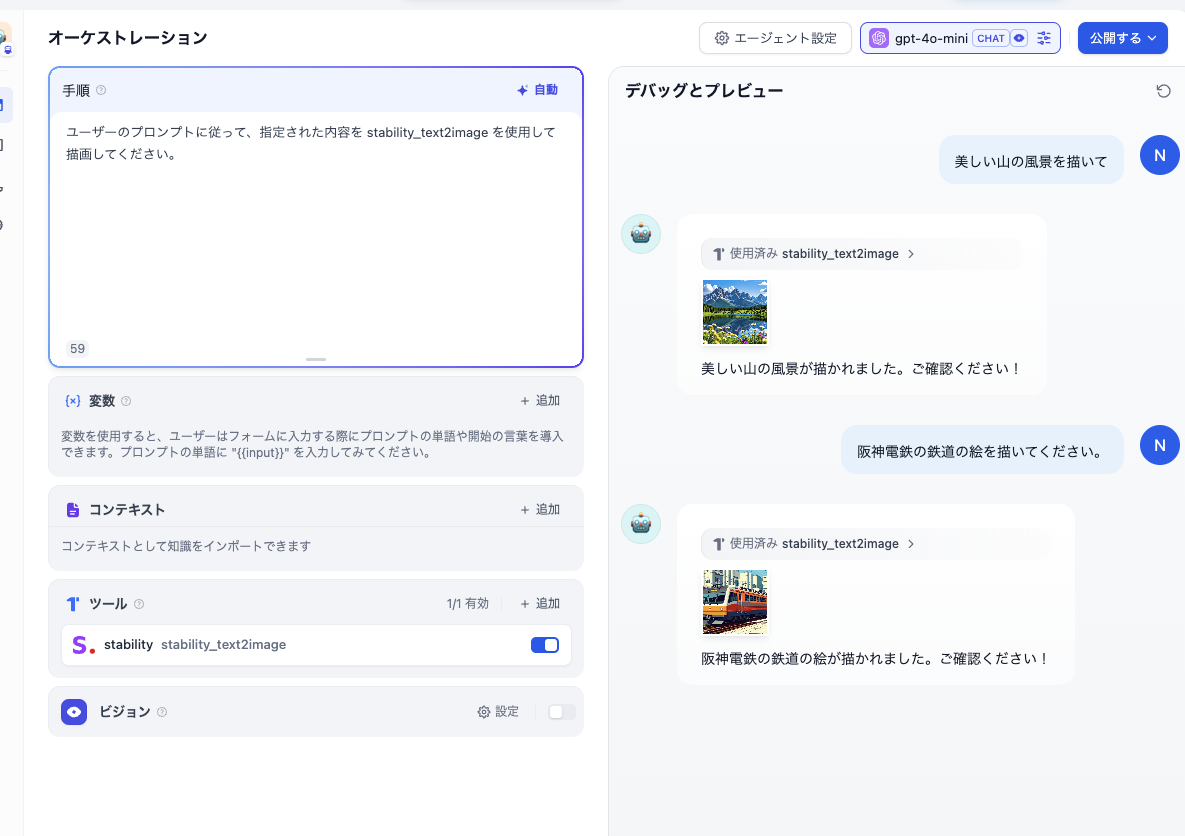
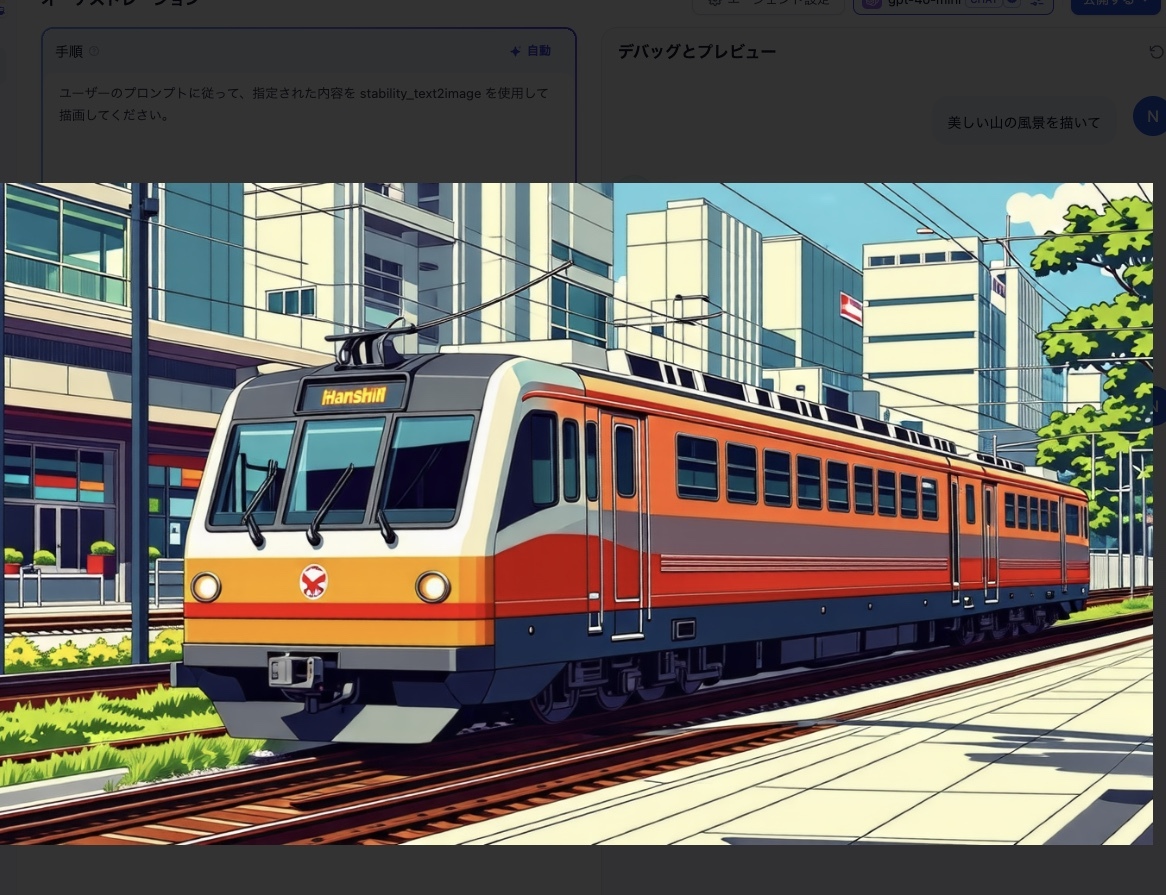
完成系
完成版のDSLファイル
app:
description: ''
icon: 🤖
icon_background: '#FFEAD5'
mode: agent-chat
name: のびすけ秘書
use_icon_as_answer_icon: false
kind: app
model_config:
agent_mode:
enabled: true
max_iteration: 5
prompt: null
strategy: function_call
tools:
- enabled: true
provider_id: stability
provider_name: stability
provider_type: builtin
tool_label: StableDiffusion
tool_name: stability_text2image
tool_parameters:
aspect_ratio: ''
model: ''
negative_prompt: ''
prompt: ''
seeds: ''
annotation_reply:
enabled: false
chat_prompt_config: {}
completion_prompt_config: {}
dataset_configs:
datasets:
datasets: []
reranking_enable: false
retrieval_model: multiple
top_k: 4
dataset_query_variable: ''
external_data_tools: []
file_upload:
allowed_file_extensions:
- .JPG
- .JPEG
- .PNG
- .GIF
- .WEBP
- .SVG
- .MP4
- .MOV
- .MPEG
- .MPGA
allowed_file_types: []
allowed_file_upload_methods:
- remote_url
- local_file
enabled: false
image:
detail: high
enabled: false
number_limits: 3
transfer_methods:
- remote_url
- local_file
number_limits: 3
model:
completion_params:
frequency_penalty: 0.1
presence_penalty: 0.1
stop: []
temperature: 0.8
top_p: 0.9
mode: chat
name: gpt-4o-mini
provider: openai
more_like_this:
enabled: false
opening_statement: ''
pre_prompt: ユーザーのプロンプトに従って、指定された内容を stability_text2image を使用して描画してください。
prompt_type: simple
retriever_resource:
enabled: true
sensitive_word_avoidance:
configs: []
enabled: false
type: ''
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: false
text_to_speech:
enabled: false
language: ''
voice: ''
user_input_form: []
version: 0.1.5
ハンズオン
公式ハンズオン古かった。
準備
- Stability https://platform.stability.ai/ のAPIキーの取得
- Groq CloudのAPIキーの取得(組織環境とかだとすでに設定されてるかもしれない。)
- Difyのアカウント
構成イメージ
A. テキストを理解するAI (groq経由のLlama) => B. 画像生成をするAI (Stable Diffusion)
ツール設定
ツールの中にStabilityがあるので、APIキーを設定
モデルプロバイダー設定
モデルプロバイダーも設定。組織環境とかだとすでに設定されてるかもしれない。
エージェント作成
Difyのアプリ作成からエージェントを作成する。
※公式ハンズオン資料がエージェントと書きつつ、スクショ画像がエージェントではなくチャットボットになっていたので注意
- 左上のプロンプト:
ユーザーのプロンプトに従って、指定された内容を stability_text2image を使用して描画してください。など - 左下でツール設定: Stable diffutionを設定
- 右上でモデル設定: Llamaなどを設定 (こっちは文章やり取りだけなのでgpt-4o-miniなどでもOK)

完成
これでおkなはず