surrealdb 環境構築+簡単なCRUDを試す(v1.1.1)
公式
github
SurrealDBとは? (公式より)
SurrealDBは、ウェブ、モバイル、サーバーレス、Jamstack、バックエンド、従来のアプリケーションなど、モダンなアプリケーション向けに設計されたエンドツーエンドのクラウドネイティブデータベースです。
SurrealDBを使用することで、データベースとAPIインフラストラクチャを簡素化し、開発時間を短縮し、安全でパフォーマンスの高いアプリケーションを迅速かつコスト効率よく構築することができます。
特質すべき機能(公式より)
- 開発時間の短縮SurrealDB は、ほとんどのサーバーサイドのコンポーネントを不要にすることで、データベースと API スタックを簡素化し、安全でパフォーマンスの高いアプリケーションをより早く、より安く構築できるようにします。
- リアルタイムに連携する API バックエンドサービスSurrealDB は、データベースとしても API バックエンドサービスとしても機能するため、リアルタイムのコラボレーションが可能です。
- 複数のクエリ言語をサポートSurrealDBは、クライアントデバイスからのSQLクエリ、GraphQL、ACIDトランザクション、WebSocket接続、構造化/非構造化データ、グラフクエリ、フルテキストインデックス、地理空間クエリをサポートしています。
- きめ細かなアクセス制御:SurrealDBは、行レベルのパーミッションに基づくアクセス制御を提供し、データアクセスを正確に管理する能力を提供します。
その他の日本語紹介記事
Getting Started
windows, mac, linuxでローカルで動かせます。
▼インストール方法は公式のこちら
clientアプリ
ローカルで動作させたら、次にクライアントアプリがあると便利ですので、
先にインストールしておきます
▼surrealist(クライアントアプリ)
インストールは、ここからインストーラをダウンロードして実施。
※mac osでは、アプリケーションが署名されていないためWindows や Linux の対応するものよりも複雑とのこと。詳しい手順はこちら
rust製のwebviewを用いたクライアントアプリフレームワークのtauriで実装されているので、
rustの開発環境がある方は、git cloneしてビルドするのもありかも
▼Tauri
windowsローカルでサーバー起動
インストール
powershellで、ダウンロードしてインストール(upgradeも同様)
デフォルトでC:\Users\<ユーザー>\SurrealDB\surreal.exeに単一バイナリ42MB(!)が作成される。
iwr https://windows.surrealdb.com -useb | iex
実行
surreal start --log debug --user root --pass root memory
簡単なコマンドの説明
- surreal start: SurrealDBデータベース サーバーを起動
- -A: すべての機能を有効にする
- --auth: DBの認証を有効にする
- --user root --pass root:
アクセスのための初期ユーザー名とパスワードを設定(ここでは両方ともrootに設定)
一度初期認証情報が作成されると、それらはデータストアに永続化されるため、次回SurrealDBを起動する際にコマンドライン引数を含める必要はありません。(key/passは保管しておいてください) - memory:
データベースをメモリ上で実行。ディスクからの読み書きを行わないため、データへのアクセス時間が速くなりますが、サーバーが再起動されるとデータは失われます。
実行結果
.d8888b. 888 8888888b. 888888b.
d88P Y88b 888 888 'Y88b 888 '88b
Y88b. 888 888 888 888 .88P
'Y888b. 888 888 888d888 888d888 .d88b. 8888b. 888 888 888 8888888K.
'Y88b. 888 888 888P' 888P' d8P Y8b '88b 888 888 888 888 'Y88b
'888 888 888 888 888 88888888 .d888888 888 888 888 888 888
Y88b d88P Y88b 888 888 888 Y8b. 888 888 888 888 .d88P 888 d88P
'Y8888P' 'Y88888 888 888 'Y8888 'Y888888 888 8888888P' 8888888P'
[2m2024-01-20T06:09:13.988673Z[0m [32m INFO[0m [2msurreal::env[0m[2m:[0m Running 1.1.1 for windows on x86_64
[2m2024-01-20T06:09:13.988922Z[0m [34mDEBUG[0m [2msurreal::dbs[0m[2m:[0m Database strict mode is false
[2m2024-01-20T06:09:13.989418Z[0m [33m WARN[0m [2msurreal::dbs[0m[2m:[0m ❌🔒 IMPORTANT: Authentication is disabled. This is not recommended for production use. 🔒❌
[2m2024-01-20T06:09:13.991697Z[0m [34mDEBUG[0m [2msurreal::dbs[0m[2m:[0m Server capabilities: scripting=false, guest_access=false, live_query_notifications=true, allow_funcs=all, deny_funcs=none, allow_net=none, deny_net=none
[2m2024-01-20T06:09:13.992112Z[0m [32m INFO[0m [2msurrealdb::kvs::ds[0m[2m:[0m Starting kvs store in memory
[2m2024-01-20T06:09:13.992425Z[0m [32m INFO[0m [2msurrealdb::kvs::ds[0m[2m:[0m Started kvs store in memory
[2m2024-01-20T06:09:13.993280Z[0m [32m INFO[0m [2msurrealdb::kvs::ds[0m[2m:[0m Credentials were provided, and no root users were found. The root user 'root' will be created
[2m2024-01-20T06:09:14.030221Z[0m [32m INFO[0m [2msurrealdb::node[0m[2m:[0m Started node agent
[2m2024-01-20T06:09:14.031109Z[0m [32m INFO[0m [2msurrealdb::net[0m[2m:[0m Started web server on 0.0.0.0:8000
client の設定→接続
クライアントアプリSurrealist (2024/1/20時点で、v1.11.1)で、
ローカルサーバーへアクセスするための認証情報を作成します。
-
「Select Tab」→「+ Add Session」をクリックして、セッション作成フォームを開く
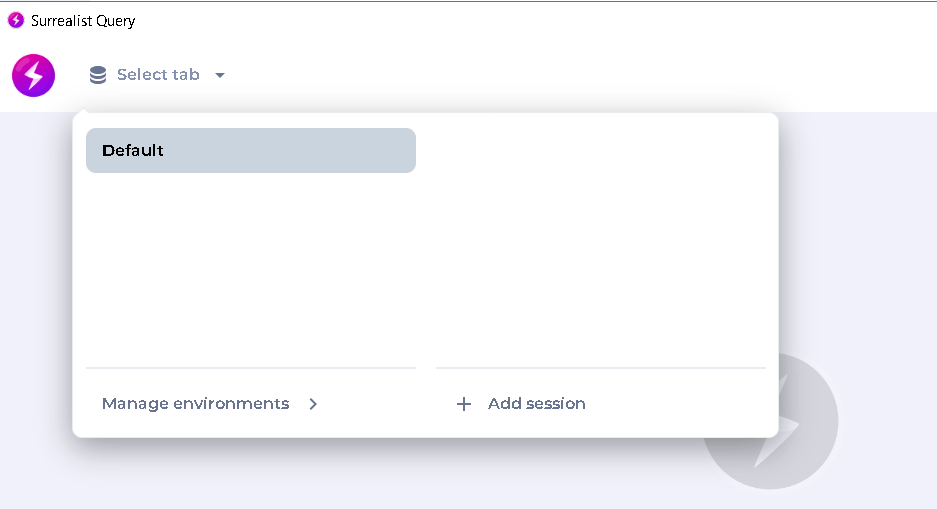
-
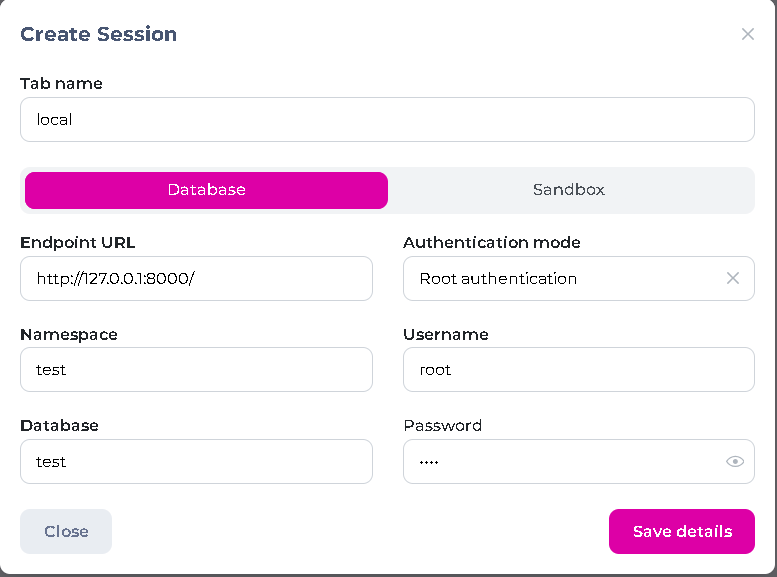
セッション情報を入力して保存
EndpointURL: 'http://127.0.0.1:8000/'
Namespace: 'test',
Database: 'test',
Username: 'root',
Password: 'root',
- セッション接続成功すると、クエリ入力画面に切り替わります
Clientアプリを使って、SurrealDBに対して CRUD的な動作を試す(その1)
Create(Inesrt)処理
SurealDBはschemelessのため、基本的にテーブルやフィールドを定義する必要がありません
(STRICTモードで起動されていると、先にテーブル定義が必要のようです)
つまり、RDBで言うところのtableが無くても、
Record(データ)のInsert処理を行えます。(mongodbのcollectionに近い?)
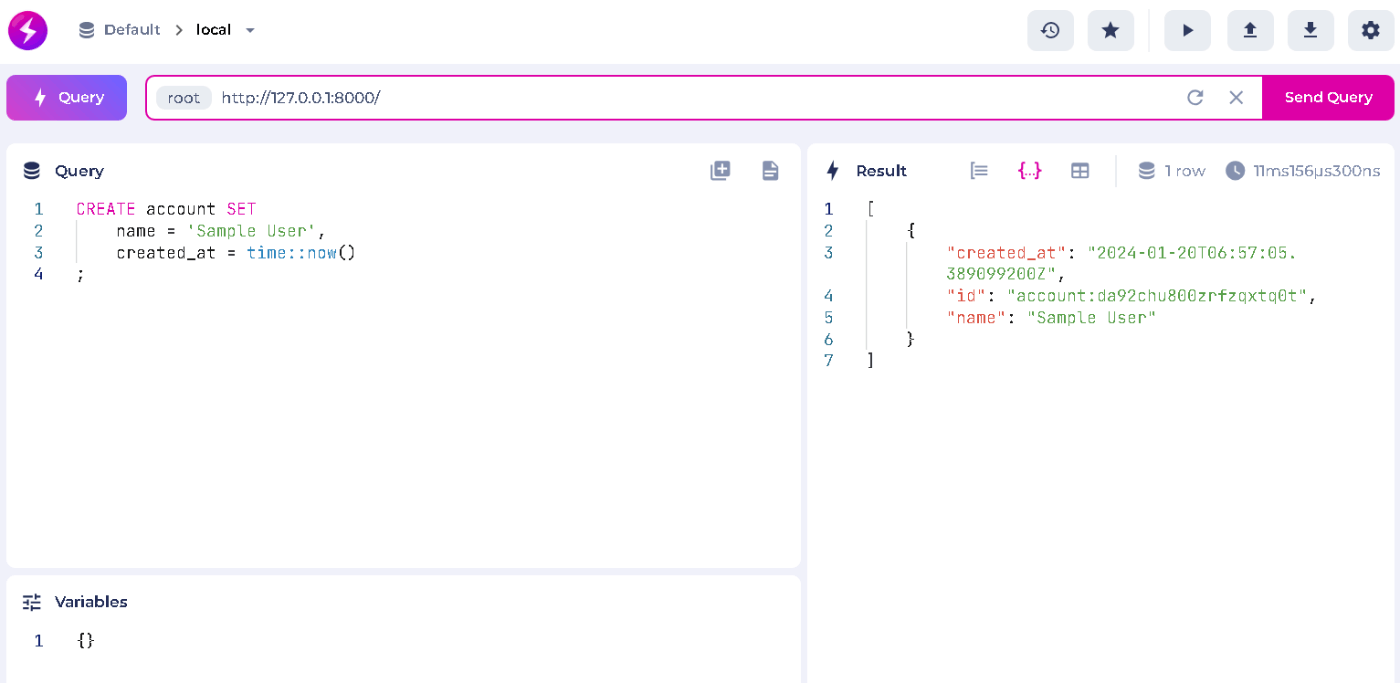
①accountというtable(collection) に、IDを指定せずRecordを1つcreate(insert)
CREATE account SET
name = 'Sample Account',
created_at = time::now()
;
実行すると、IDはランダムに振られます。
[
{
"created_at": "2024-01-20T06:57:05.389099200Z",
"id": "account:da92chu800zrfzqxtq0t",
"name": "Sample User"
}
]
※clientではこのように結果が表示されます。以下、client画面は省略
②autherというtableに、IDを明示的に指定してRecordを1つcreate(insert)
CREATE <テーブル名>:<ID>のように記述すると
IDを自分で指定してデータ登録することもできます。
さらに、各フィールドをname.firstのように、ツリー構造で指定することもできます。
CREATE author:john SET
name.first = 'John',
name.last = 'Adams',
name.full = string::join(' ', name.first, name.last),
age = 29,
admin = true,
signup_at = time::now()
;
[
{
"admin": true,
"age": 29,
"id": "author:john",
"name": {
"first": "John",
"full": "John Adams",
"last": "Adams"
},
"signup_at": "2024-01-20T07:08:38.888200900Z"
}
]
ちなみに、同じIDで登録しようとすると、
重複エラーが返されます。
Database record `author:john2` already exists
③相互レコードでレコードをリンクさせる
「相互レコード」を作成することで、レコードを相互にリンクさせられます。
(RDBでも、別テーブルのレコードのIDをフィールドとして持つことで、テーブル間の紐づけを行うので記述の仕方自体は珍しくないが、グラフ指向DB的に、内部で直接データがリンクされるのかも?)
リンクのさせ方は、
IDを指定する方法以外に、サブクエリも使えて柔軟です。
例として、article(記事)レコードを作成します。
以下の方法でautherテーブルとaccountテーブルにリンクします。
autherのレコードとのリンク→IDを指定
account レコードとのリンク→Sample User の ID を与えるサブクエリを使用
CREATE article SET
created_at = time::now(),
author = author:john,
account = (SELECT VALUE id FROM account WHERE name = 'Sample Account' LIMIT 1)[0],
title = 'Lorem ipsum dolor',
text = 'Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.'
;
サブクエリで指定したフィールドは、自動的に対象レコードのIDに置き変わって登録されます。
[
{
"author": "author:john",
"account": "account:j78z6lrys5grlf16rxpw",
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
Clientアプリを使って、SurrealDBに対して CRUD的な動作を試す(その2)
Select 処理
SQLの機能に加えて拡張した記述方法や、NoSQLの機能を持っているので、
色々と試してみます。
普通のSelect
SELECT * FROM article;
[
{
"account": "account:j78z6lrys5grlf16rxpw",
"author": "author:john",
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
1つのクエリで、複数の異なるテーブルから一度にデータを取得できます。
(この例だと、全てのarticle(事前に2件登録)とaccount(事前に2件登録)が配列として返されてます)
SELECT * FROM article, account;
[
{
"account": "account:j78z6lrys5grlf16rxpw",
"author": "author:john",
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"account": "account:fv9z5wd9hbplr9jlax2y",
"author": "author:john2",
"created_at": "2024-01-20T08:09:42.792736700Z",
"id": "article:z9ar08rb3vthxld1gcpu",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"created_at": "2024-01-20T08:06:09.880717900Z",
"id": "account:fv9z5wd9hbplr9jlax2y",
"name": "Sample Account2"
},
{
"created_at": "2024-01-20T07:50:52.857876400Z",
"id": "account:j78z6lrys5grlf16rxpw",
"name": "Sample Account"
}
]
相互レコードでレコード同士がリンクされている場合、
RDBのSQLではJOINを使わなければ書けなかったリンク先のテーブル条件でクエリを書けます!
例:articleのahthor.ageが30才未満の全データ
SELECT * FROM article WHERE author.age < 30
JOIN使わなくても、自動的にauthorの条件を元にデータを引っ張ってこれる
[
{
"account": "account:j78z6lrys5grlf16rxpw",
"author": "author:john",
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"account": "account:fv9z5wd9hbplr9jlax2y",
"author": "author:john2",
"created_at": "2024-01-20T08:09:42.792736700Z",
"id": "article:z9ar08rb3vthxld1gcpu",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
相互レコードはキーで保存されているが、fetchを使うと、対象テーブルをレコードを展開して取得できます。超便利。
上記と同じ条件でデータを取得する際、
articleの中の、auther、accountフィールドをfetchすることで展開。
SELECT * FROM article WHERE author.age < 30 FETCH author, account;
fetchした対象のテーブルについては、自動的にjoinされてデータを展開して取得できます
※account、autherフィールドに展開
[
{
"account": {
"created_at": "2024-01-20T07:50:52.857876400Z",
"id": "account:j78z6lrys5grlf16rxpw",
"name": "Sample Account"
},
"author": {
"admin": true,
"age": 29,
"id": "author:john",
"name": {
"first": "John",
"full": "John Adams",
"last": "Adams"
},
"signup_at": "2024-01-20T07:51:16.538219100Z"
},
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"account": {
"created_at": "2024-01-20T08:06:09.880717900Z",
"id": "account:fv9z5wd9hbplr9jlax2y",
"name": "Sample Account2"
},
"author": {
"admin": true,
"age": 29,
"id": "author:john2",
"name": {
"first": "John2",
"full": "John2 Adams2",
"last": "Adams2"
},
"signup_at": "2024-01-20T08:08:05.520580900Z"
},
"created_at": "2024-01-20T08:09:42.792736700Z",
"id": "article:z9ar08rb3vthxld1gcpu",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
Clientアプリを使って、SurrealDBに対して CRUD的な動作を試す(その3)
Update, Delete, Remove table(RDBで言うところのDrop table)
それぞれ、SQLと同じような書式で実行可能。
Update
IDを指定して更新
UPDATE author:john SET name = 'David';
[
{
"admin": true,
"age": 29,
"id": "author:john",
"name": "David",
"signup_at": "2024-01-20T07:51:16.538219100Z"
}
]
IDではなく、条件指定して更新
UPDATE author SET name = 'David2' WHERE author.age < 30
結果は、更新対象の全レコードが返される
[
{
"admin": true,
"age": 29,
"id": "author:john",
"name": "David2",
"signup_at": "2024-01-20T07:51:16.538219100Z"
},
{
"admin": true,
"age": 29,
"id": "author:john2",
"name": "David2",
"signup_at": "2024-01-20T08:08:05.520580900Z"
}
]
IDを指定せず全レコード更新
UPDATE author SET name = 'David3';
結果は、更新対象の全レコードが返される
[
{
"admin": true,
"age": 29,
"id": "author:john",
"name": "David3",
"signup_at": "2024-01-20T07:51:16.538219100Z"
},
{
"admin": true,
"age": 29,
"id": "author:john3",
"name": "David3",
"signup_at": "2024-01-20T08:08:05.520580900Z"
}
]
Delete
IDを指定して削除
DELETE author:john;
結果
No results found for query
条件を指定せず全レコード削除
DELETE author;
結果
No results found for query
条件を指定せず全レコード削除
DELETE author;
結果
No results found for query
Remove table
remove table author;
結果
null
その後selectしてみる
select * from author;
結果
No results found for query
Clientアプリを使って、SurrealDBに対して CRUD的な動作を試す(その4)
ここで、相互レコードでリンクされているレコードは、どうなるのか?の疑問が湧いたので検証。
上記で、authorテーブルをremoveしてから、
authorとリンクしているarticleのデータを確認してみる。
SELECT * FROM article;
リンク時のキーはそのまま残ってる。
[
{
"account": "account:j78z6lrys5grlf16rxpw",
"author": "author:john",
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"account": "account:fv9z5wd9hbplr9jlax2y",
"author": "author:john2",
"created_at": "2024-01-20T08:09:42.792736700Z",
"id": "article:z9ar08rb3vthxld1gcpu",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
では、存在しないauthorテーブルを、fetchしてみると?
SELECT * FROM article fetch author;
authorがnullになって取得される。エラーにならないので扱いやすそう。
[
{
"account": "account:j78z6lrys5grlf16rxpw",
"author": null,
"created_at": "2024-01-20T07:51:34.551872500Z",
"id": "article:ox2uk691ga6g3q4gygeo",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
},
{
"account": "account:fv9z5wd9hbplr9jlax2y",
"author": null,
"created_at": "2024-01-20T08:09:42.792736700Z",
"id": "article:z9ar08rb3vthxld1gcpu",
"text": "Donec eleifend, nunc vitae commodo accumsan, mauris est fringilla.",
"title": "Lorem ipsum dolor"
}
]
感想
公式サイトにも記載の通り、SurrealDBは、基本的にはdocumentとしてデータを保存するdocument databse。
でもグラフデータを保存することで簡単に個々のレコードをfetchすることで、JOINや複数回クエリを実行することなく、いくつかのテーブルデータをまとめて1つのデータとして取得できたり、これらの操作を行うためのSQLの文法をベースとしたSurrealQL が用意されていて
- SQL文法を知っているRDBユーザーがそのまま移行しやすい
- データの結合などをアプリケーション側でやらなくても、DB側で集計してくれる
など、個人的な感想としては
mongo に対してSQLで操作できるようにしつつ、データ間のリンクを保持することでグラフ指向DBのように簡単にデータを扱えるようになった、超上位互換的なポジションという感触。
さらに、
各データベースで複数の認証スコープ定義を定義できるため、テーブル、レコード、フィールド全体にわたるカスタム認証が可能になります。
https://docs.surrealdb.com/docs/introduction/concepts#system-structure
とのこと。
その他、シャーディングやレプリケーション、性能面については未検証なので、実運用に向け、諸々検証したい。
レプリケーションについて軽く調べた。
前提(SurrealDBのアーキテクチャ)
SurrealDBはレイヤーアプローチで構築されており、コンピュートとストレージは分離されています。
(コンピュートレイヤーとストレージレイヤーをそれぞれ独立してスケールアップできるメリットがあり)
embedded modeとdistributed modeがあり、
前者はローカルのSSDなどにデータ永続化するsingle node mode、distributed modeは分散ストレージを利用してデータ永続化するmode。
distributed modeであれば自動的にレプリケーションが行われるわけだが、distributed mode構成におけるストレージレイヤーとして、TiKVとFoundationDBが使えるようだが、
公式サイトの情報量や、ビルドされているバイナリはデフォルトでTiKVなので、TiKV推しの感触。
(FoundationDBを使うには、それようにソースからビルドしなおさないといけない)
TiKVは分散アルゴリズム的に(?)3 nodeが最小構成として必要で、awsのkubernetes を使った構成例を見ると、それなりにコストかかりそうなのでいったん検証ストップして様子見。
FoundationDBは、最小クラスタ構成として1 node(冗長性は無いが)から構成可能なので、
冗長性を持たせる意味で最小限の2 node 運用可能か?
その他のレプリケーションアプローチとして、ストレージをRocksDBで担うsingle node運用を行って、
RocksDBのレプリケーションを行うという方法がある。
それ用のモジュールもあるのだが、残念ながら、現在保守されていない。
今後やりたいことのメモ
- FoundationDBをバックエンドに用いたクラスタ構成を構築検証
- TiKVバックエンドにしたとき最低どの程度のスペックがあれば正常に稼働するかを検証
まだまだ安定して無さそう @20250217
堅牢性が必要な環境で使うのはもう少し後にしよう。