DEIM 2025 (オンライン)参加報告
トレジャーデータの油井です。この記事はデータベース系の国内会議DEIM 2025(第17回データ工学と情報マネジメントに関するフォーラム)のオンライン参加報告になります。
今年は昨年に引き続き、オンライン・オフラインの直列ハイブリッド形式での開催でした。コロナ禍のオンライン開催を経て[1]、DEIM 2023からオンラインとオフラインで分けて行う、直列ハイブリッド形式が導入されて続いております。
前半3日間(2/27~3/1)
オンラインで論文発表や技術報告など
後半2日間(3/3~3/4)
福岡国際会議場にてチュートリアル、ポスターセッション、スポンサーブース出展など
DEIMとは
DEIM(データ工学と情報マネジメントに関するフォーラム)は前身のDEWSから数えて30年近く続いているデータ工学領域では日本最大の国内会議です。
主催が、日本データベース学会、電子情報通信学会 データ工学研究専門委員会、情報処理学会 データベースシステム研究会で日本データベース学会の年次大会も兼ねています。学部生/修士の学生にとっては学部研究/修士研究をまとめて発表する場となっていて、研究成果を効果的に伝える力を磨く場であり、国際会議にステップアップのための登竜門的な役割を担っています。特に、学会での発表経験が少ない学生にとっては、将来の進路にも影響を与える場となっています。
私も学生の頃に前身のDEWSの頃からお世話になりました。振り返ってみると貴重な機会であり[2]、運営の皆さまには心より感謝しており、研究者時代より微力ながらコメンテータや座長で参加させて貰ってます。

企業の方も多く参加していて、昨年の参加レポートは、LayerX、LIFULL、GA technologies、DMM、Scaler、Wantedlyなど各社が公開されています。
担当したセッション
今年は初日の1C: データベースコア技術セッションでコメンテータ、2D: 時系列データ(2)で座長を務めさせて頂きました。
座長は司会運営や学生プレゼンテーション賞の推薦、コメンテータは会場から質問が出なかった場合に自ら質問を行なって議論を活発化することを促す役割を担っています。オンラインでの司会進行も2020年とか最初の頃は戸惑いましたが、5年ぐらい連続でやっているともうだいぶ慣れてきました。
特に学生プレゼンテーション賞は各セッションに一件の座長推薦となっており、その後の進路や奨学金の免除時の表彰実績などにも関わってくるため、予め担当セッションの予稿集を読み込んだ上で、当日のプレゼンテーションの内容や質疑応答での対応を鑑みて、受賞対象は慎重に選びます。セッションに寄りますが、各セッションで最大5件の発表が学生プレゼンテーション賞の対象となるため、1/5の確率での受賞となるため、学生にとっては貴重な機会となります。
1C: データベースコア技術
コメンテータとして参加した1C: データベースコア技術では、3件の学生発表と1件の技術報告(こちらはキャンセル)のみでしたが、他のセッションと比較してレベルの高い内容が揃っていたと思います。
セッションはZoomを使って進行していきます。1Cセッション参加者は28~30名程度でした。データベースのコア技術はDEIMの中では年々枠が小さくなってきており、アプリケーション寄りの発表が多いですが、それでもやっぱりデータ基盤技術や基盤システムに興味を持っている人は多いんですよね。

メタ索引技術
シノプシス埋込はDEIM 2022でも自分で担当したセッションで発表があってそれをPostgresに実装し、結合演算に対応した発展発表でした。
シノプシス埋込というのは索引構造に統計情報(sum/count)などのメタ情報を埋め込む技術です。
列志向DBやOrcFileだとページ単位に集約演算の高速化のためにsum/count持っているかと思いますが、そのcracking indexっぽいやつですね。
プレゼンではインタラクティブ分析向けに訴求していたので、質疑では、事前に複合索引を設計する難しさと、Database CrackingのCracker/adaptive IndexやAdaptive Radix Treeなど動的に索引を構成するような技術との棲み分けについて質問させて頂きました。以下のようなクエリが例に挙がっていましたが、amount > 100をインタラクティブ分析で追加した場合には複合索引も貼っていなければなりませんが、索引も貼りすぎると索引のメンテナンスコストも出てきて厄介になります。座長からの指摘でありましたが、データ分析でも毎日定型で(日付だけ変えたりして)同じような分析が行われることもあるので、確かに、そうした場合には事前索引の方が有効そうで適用ドメインの訴求の仕方次第かなと思いました。
select count(orderkey)
from sales_history
where orderkey > 10
-- and amount > 100 この部分を追加
Database Crackingは2007年に提案された結構古い技術で、CWIに滞在していた頃に話を聞いて面白い技術だなと思っていたが、2016年にこの論文が総括っぽいことをしている。
Database Crackingは、近年活発に研究されている分野です。データベース クラッキングの中心的な考え方は、クエリ処理の副産物として、適応的かつ段階的にインデックスを作成することです。..
私たちの目標は、データベース クラッキングのいくつかの側面を批判的にレビューし、可能性を特定し、有望な方向性を提案することです。...この研究では、データベースクラッキングに関する 8 つの論文を再検討し、合計 18 のクラッキング方法、6 つのソートアルゴリズム、および 3 つの完全なインデックス構造を評価します。... 最後に、クラッキングをさまざまなソート アルゴリズムや、最近提案された適応基数ツリー (ART) などのさまざまなメイン メモリ最適化インデックスと比較します。結果は、(1) 以前に提案されたクラッキング アルゴリズムは再現可能である、(2) 以前に提案されたクラッキング アルゴリズムを大幅に改善する余地がまだ十分にある、(3) クラッキング アルゴリズムを効率的に並列化するのは難しい作業である、(4) クラッキングはクエリの選択性に大きく依存する、(5) クラッキングは最新のインデックス作成の傾向に追いつく必要がある、(6) 異なるインデックス作成アルゴリズムには異なるインデックス作成シグネチャがあることを示しています。
グラフデータ管理とPolyStore
本セッションでもう一つ気になった発表は、グラフデータ管理で統一スキーマを活用して、グラフクエリのWhere句の処理には転置索引を使った異種データベースを用いるpolystore/統合データベースの研究。従来型の統合データベースでは、Foreign Data Wrapper(FDW)を利用してSQLの中でグラフクエリなどを実行していたのに対して[3]、この研究はグラフ問合せ言語であるCypherクエリのアクセラレーションとして、Match句の処理をBadgerDBにオフロードして転置索引として使っていました。
統一スキーマモデルを活用し、クエリの自動書き換えとプロパティ単位でのデータマイグレーションを実現している点に新規性がある一方で、動的なデータマイグレーションには運用の難しさや、スケーラビリティや信頼性の確保といった課題が出てきそうな感じはしますが、構想的に意欲的な研究でした。今回の実験範囲がCypherクエリのオフロードに留まっていたので、グラフDB側でproperty index貼ってしまえば良さそう[4]でグラフDB側の索引実装やExecutor/plannerを見直せば良いような気もするけど、提案手法の利点はどこ辺にあるのか一応質問させて頂きました。polystoreならではのところまで適用範囲を広げようとすると、GraphQLの表現力以上のことをしないといけなくて、そうするとFDW系(SQLの中でグラフMATCH句)に戻ってきそうな気もしないでもない。自分もこの辺の問題意識を理解するために、キャッチアップで関連研究とか、その評価の仕方をちゃんと読まないとな💦
会場での議論でもありましたが、連合(Federated)や統合データベースは、データベース研究分野では長い歴史があって、紆余曲折しながらも関係データベースが全てを飲み込んできたような歴史があるのでグラフ演算の未来もそうなのかなーっと思ったりもしました[5]。
2D: 時系列データ(2)
座長した2D: 時系列データ(2)のセッションでは、5件の学生発表がありました。ロング4件で質疑含めると時間進行がキツキツでした(少しオーバーした)。時系列データ処理はもう一個セッションがあるので人気なんですね。
時系列データはそんなに専門でもないのですが、以前に仕事で時系列分析のプロダクト化をした時にFLAMLやProphetを扱ったりしたのと、ARIMAとかAutoRegressive系の基礎知識(Yule Walker法)やApache Hivemallに異常検知を実装した時の経験が理解に役に立ちました。Yule Walker法/LevinsonアルゴリズムやBurg's methodあたりに当時感激した記憶が...
時系列予測のための基盤モデル
最初の発表は、Time-MoE、Google TimeFMとか時系列データ予測のためのfoundation modelとかキャッチアップできていなかったので勉強になりました。ICLR 2025 Spotlightの研究みたいだけど、それを使った研究がもうDEIM 2025に出てきて、arXivの頃から着目してたんだろうか、と最近の流れの速さに驚くなど[6]。様々な時系列データセットで学習済みの事前学習済みモデルが、本当に使えるのか、追加学習の効果はどれぐらいとか興味が湧いて面白い研究でした。従来型の異常検知手法とは比較されてなかったので、従来型の異常検知手法(例えばChangeFinder/SSTやその発展系)に対する利点は気になりました。
また、異常スコアの後処理を単純移動平均の固定長でやっていて、exponentialに周期の波が拡大していく場合の考慮はどうしているのか質問させて頂きました。
時系列Tensorデータの時系列データ分析
最後の2件は時系列Tensorデータ分析関連でした。
通常のtimeseries分析手法(自己回帰モデルのほとんど)は一本の時系列データを対象としていて、一般的には多次元データにはそのまま適用できません。そこで、CP(CANDECOMP/PARAFAC)分解を利用してテンソルを複数のランク1テンソルの和として近似した上で、時系列データ処理するようなことが一般に行われます。
ベースラインの比較がARIMAと既存手法のDISMOだったので外因変数扱える他のモデルと比較しての評価が気になったのと、あとは差分更新を行うスライスごとに最適なハイパーパラメータが異なりそうなので少し気になりました。プレゼンで例にあがってた天気などの変数は日時や集約時間に寄らずスパースなカテゴリカル変数のままだが、決定木系で時系列予測させた場合と比較してどうなんだろう[7]。
最後の発表は、トレンド・季節性の依存関係分析を乗法的にとらえる手法を提案されていました。
従来のSTL/SARIMAなどの時系列データ分析では加法モデルに基づいてトレンドと季節性を抽出します。
乗法モデルを時系列分析に用いること自体は特に新規性はなく、質疑では、Prophetなどで加法モデルも乗法モデルも扱えること、経験的に乗法モデルよりも加法モデルの方が上手くいく話や乗法モデルがどの程度現実の時系列データに適合するか見解を求めましたが、発表の構成や質疑等での受け答えもしっかりされていたのが印象的で(もう一件の発表と悩みましたが)学生プレゼンテーション賞に推薦させて頂きました。
他に参加したセッション
初日の後半は3C: クエリ最適化、二日目は4F: 推薦システム(4)、5C: 索引、
6G: ユーザモデリングの前半、6C: 先端ハードウェアの後半等のセッションをメインに聴講しました。
3C: クエリ最適化
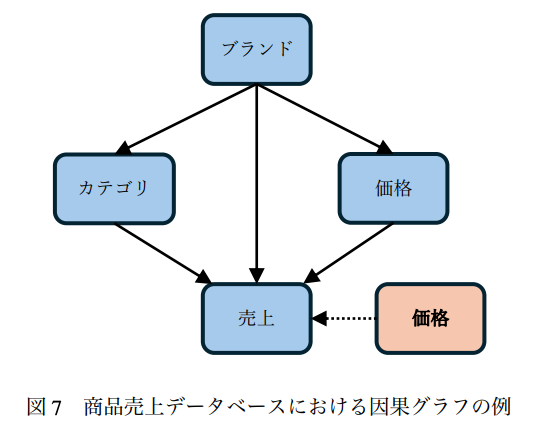
DoWhy使った仮説推論(WhatIf)問合せのための問合せ言語とか便利そうだなと思って聴いてました。HypeRスキーマ情報から因果グラフ作って集約属性を追加し、来歴情報(Lineage)組合せるのが新規性らしい。DoWhy以前、因果推論を利用しようとした時にチェックしたことがあるけど、再訪。
まだ実装されていないけど、以下のような問合せ言語を実装する予定らしい。
-- ソニー製の価格が 20 万円より大きいテレビの価格を 10 %下げたとき,
-- 各社の元々の売上高が 500 億円より大きいテレビの平均売上高はどう変化するか?
CAUSAL INFERENCE
SELECT ’カテゴリ’,’ブランド’,AVG(’売上高’)
FROM sales
WHERE ’カテゴリ’ = ’テレビ’ AND PRE(’売上高’) > 500 億
GROUP BY ’ブランド’
INTERVENE ’価格’ SET ’価格’*0.9
FOR ’ブランド’ = ’ソニー’ AND ’価格’ > 20 万;
CAUSAL GRAPH graph_name
EDGES (’ブランド’, ’カテゴリ’), (’ブランド’, ’価格’), (’ブランド’, ’売上高’), (’カテゴリ’, ’売上高’), (’価格’, ’ 売上高’)
EX_EDGES (’価格’, ’売上高’) IN ’カテゴリ’;
昔、TDのインターンでインターン生とCausal Discoveryに取り組んだの思い出しましたが、因果グラフの正確性・有用性に依存するので、因果グラフの構築にCausal Discoveryと組合せると良いんじゃないかと思った[8]。この辺、もうPostgresのFDWであったら便利そうであるかなーと探したが、まだなかった。TDでもこのようなWhatIf分析使えたら便利かもしれない。
意図をもう少し説明すると、因果推論は因果関係定義する因果グラフに依存しており、論文ではこれをデータベースのスキーマとか統計情報(属性集約)を利用して発見して以下のようにスキーマ定義のように因果グラフを定義するようなのですが、因果グラフ自体の確かさに因果推論の結果は左右されるわけです。場合によってはEdgeの重みまで与えないといけない。で、売上高とかは必ずしもデータベースのPK/FK関係や集約属性に依存するわけでないですよね。この因果関係自体を推論するのが因果探索(Causal Discovery)で妥当な因果グラフが定義できないと因果推論はうまく行かない。依って、因果関係自体の導出が重要。Causal Discovery自体がworkshopが開かれたり一分野になっている。
また、このセッションでは、企業からの報告が2件(NTT SICとNEC)ありました。1)PostgreSQLのテーブルパーティションを使うとパーティション数が多くなるとパーティション数の二乗に応じたプランニング時間が必要(線形探索されるため)で転置索引を導入したという発表と、2)Pandas互換ライブラリのFireDucksの発表。どちらも実践的な内容で参考になりました。Polarsは使ったことあるけど、Fireducksはまだ使ったことなかったのでメモ。
PostgreSQLのパーティション数の二乗に応じたプランニング時間が必要という発表では、
同値類 E に対する線形探索が問題であったことを踏まえて,E に対してハッシュテーブルなどのデータ構造を用いて探索を高速化し,その方式を PostgreSQL の開発者が新機能などについて議論するメーリングリストであるpgsql-hackers 上に提案していた [10].しかしながら,このような方式は,受け入れられなかった.これは,ハッシュテーブルに関わる計算量が大きく,テーブルがパーティション化されていない場合やパーティション数が少ない場合に性能劣化を引き起こす可能性があるためである
ということなので、同値類の線形探索しているところをシンプルにまずソートして二分探索するとか簡易な対策は試したのか聞いてみました。
4F: 推薦システム(4)
最近業務でリアルタイム推薦システムに携わっているので、推薦システムのセッションに参加。11時から仕事の1-on-1があったので最初の2件の発表だけ聴講しました。
1件目は、クロスドメイン推薦の汎用性向上に向けてメタ学習を利用した研究。
クロスドメイン推薦における異なるシナリオ間での知識転移を促進し,汎用性の高い推薦モデルを構築するために,メタ学習を利用。ICML 2017で発表されたメタ学習向けのフレームワークMAMLのOSSライブラリを利用されていました。
Amazon Review Datasetで、異なるジャンルのデータから知識転移をされていたのですが、評価がMAE(Mean Absolute Error)だったので、ユーザごとの評価の隔りをより学習できる部分があるのでそれだけでも利いちゃいそうだなーっと思いました。Rating予測のMAE評価だと、単一シナリオモデルよりは当然良くなるが、論文でも単純統合学習モデルとの比較では統計的な有意差は見られなかった結果が出ていたので少し気になりました。
2件目は、Personalized Page Rank(PPR)[9]をパーソナライズド推薦に利用する発表。
Random Walkの経路長によってPPRベクトルにおける起点ノードの影響が変化することに注目して、全体重要性と起点近接性がPPRベクトルに与える影響を単調にバランスする手法を提案。PPRを推薦に用いるってあまり産業界では聞かないので、なかなか面白い発表でした。
評価にnDCGを使っていたんですが、推薦システムの推薦結果の評価に一般的に利用されるnDCGじゃなくて、本発表でのnDCGは二つのベクトルの上位kノード(本研究ではk=1024)がどれだけ類似しているかを定量化する指標の定義で、素のPageRankのベクトルとPPRのベクトルの比較などに利用されていた。
パーソナライズド推薦システムに用いることが元々の動機であったはずであるので、重要ノード(推薦アイアテム)をユーザごとにtop-k推薦したとき(起点ノードはユーザの最後に高評価したアイテムを用いるとかすれば良い)の推薦結果の尺度であるnDCGで他の一般的な推薦手法との比較結果を見たかったので、質疑応答ではコメントさせて貰った。
5C: 索引
5C: 索引は索引関係が集まった濃いセッションでした。同時実行制御、並列処理の話題が多いかな。
最初の発表は、B+木のMVCCの話。従来のMVCCでは、読み取り時にリーフのLinkedListのバージョン操作走査で、以下に図のようにランダムアクセスが発生してI/O待ち(CPUキャッシュミス)が発生して辛いので改善した話でした。

とりあえずprefetch命令入れてみるのが第一歩かなと思ったので、質疑では、prefetch入れることは試したのか聞いてみた[10]。
3番目の発表はロックフリーMASS-treeのtrie木化。昔ロックフリーのバッファ管理やってたりとかPrefix B-treeを実装したことがあったので、まだ未チェックならばPrefix B-treeはチェックすると良いよとコメントしてみた。B+-treeのsplit時に中間ノードのエントリを少し工夫するだけで、パトリシア木(トライの賢い版)みたいな構成になるので結構エレガントだと思う。
1979年のBIT誌の上田先生の記事にもある結構クラシカルなアルゴリズムなんですが、B+木同様、結構今でも通用する索引構造なので紹介してみてみた。著者のRudolf BayerはB木、UB木の生みの親ですが、1977年時点でprefix B-treeまで生み出していたのであった。なお、自分でも以前、このスライドで紹介してます。
Mass木みたいに前段数バイト分trieとB+木を組み合せるのとどちらが良いかというと整数だとMass木の方が良さそうだが、文字列だとprefix B+木の方がトラバースに必要なノード数が少ない分、prefix B木の方が良い気がする。Paper trailのMASS木の解説や批評コメントを参照のこと。
4番目の発表は、SOSP'23で発表されたSPFresh[11]のmassiveな更新処理性能を高めるといった方向性の研究。代表点の更新やクラスタ再割り当て処理を並列化し、各プロセスが楽観的に更新を実行した後にバージョン検証を行うことで、更新処理の排他制御を回避ということでした。同時実行時の更新性能は上がるけど、バージョンチェインの探索分の検索負荷も上がるので、逐次更新はしたいけど、どこまで同時実行性能が求めるか、ですね。
セッション最後の発表はNTTデータの方によるPostgresのXID周回問題の話。VACUUMで回収されたXIDをどう管理しているんかなーっと軽く質問してみた。ところどころに回収不能(まだ実行中)があると再利用のためにRoaring Bitmapっぽいので回収されたXIDを管理しなきゃいけないのかなっと思ったが、実運用上はロングランニングトランザクションとかあんま考慮せずにショートトランザクションが多いから、シンプルにここまでは回収済みというlow watermarkっぽいので良いっぽい。
6G: ユーザモデリング
普段行かないセッションにどんな感じか偵察で参加。ザッピングできるのがオンラインの利点。本セッションでは、転移学習関連の最初の2件の発表を聞きました。
(クラウドソーシングなどを利用して)いくつかの質疑応答によってユーザの嗜好モデルを作るにあたって、回答者に好ましくないアイテムを見せずにできるだけ短く、かつユーザの満足度の高い形で嗜好モデルを得るというような問題設定でベイズ最適化を利用。アイデアとしては、ユーザクラスタの嗜好を利用して回答者にとって好ましくないアイテムの提示を避けながら、好ましいアイテムを効率的に発見するという話でした。
評価でユーザが高評価を上げるようなアイテムの推薦を良し、低評価アイテムを出さなかったら良しだったのですが、ユーザのクラスタや嗜好にはこのアイテムを低評価するようなユーザ嗜好やクラスタというのも考えられるので、Multi-Armed Bandit(MAB)同様にExploitしているばかりではなくあえてcounterpartを当ててexploreしていかないと局所解に落ちることがないか、逆に嗜好モデルを得るための収束に時間がかかってしまうのでないかと質問させて貰いました[12]。
最適化の効率性と品質を定量的に評価する指標として、全ての回答者における評価値の平均を算出した平均評価値 (Mean Average Preference Value)というのを利用されていたのですが、MAPVで嗜好モデル作るに当たっては良い指標なのか?(つまりユーザにとって満足のいくアイテムばかりを示しても良い嗜好モデルが作れないのではないか)、別の軸でも評価しないといけないのではないかと直感的には思いました。
6C: 先端ハードウェア
前半は6Gセッションにいたので、6Cセッションは後半の富士通の方の発表から参加しました。残念ながら、子供のお迎えで18時前後の最後の一件は聞けず。
GPUをハードウェアレベルで分割して共有する技術の登場により,GPU使用率をさらに高めることができるようになった.しかし,可能なGPUの分割パターンはあらかじめ決められているため,GPU共有を行った場合でもGPU使用率の向上には限界があり,電力効率には改善の余地がある。<snip> GPU使用率が同程度のワークロード群を同一GPUに集約した上で,性能要件を満たす範囲内で動作周波数を下げることで電力効率を上げる。
NVDIAのGPUでMIG分割を利用して、ワークロードを振り分ける。各MIGインスタンスにはコア数を変えたいくつかのバリエーションを用意して、基本的にはアプリケーションが必要なコア数の制約条件を与えた上で、bin packingみたいな感じでMIGインスタンスを割り当ててGPUコア利用が同程度のワークロード群を同一GPUに集約した上で集約した上で、性能要件を満たす範囲内で動作周波数を下げることで電力効率を上げるというような話でした[13]。YARN/schedulerやwork stealing/migrationっぽい話が、MIGを利用したGPU分割利用によってあるですね。
質疑では、GPUの電力効率が最大なのは100%コアが動いている時なので、cgroupsのCPUオーバコミットみたいな形にあえてしてしまって、割り当てられたコア数を超えるスレッド数を必要なアプリケーションを割り当ててしまっても、コンテキストスイッチは発生するのでオーバヘッドはあるが、GPUコアを常に活用するようにしてしまっても良いのではと思って質問。回答としては、ストリームデータをYOLOv4みたいな動作推定する場合は期待されるFPS(Frame Per Second)があってフレーム落ちとかしたら性能要件的にダメなので、オーバーコミット等は考えていないということでした。
まとめ
他にも良い発表があったと思いますが思いの外長くなってしまったのでこの辺で〆。今回も自分から普段摂取しないような情報やトレンドのキャッチアップにもなって良い学びの機会でした。オンラインで2日間だけでしたが、振り返ってみると思ったよりも色々得るものがあったかな、と。
今回は、発表を聴講しつつ、論文についてChatGPTで壁打ちしながら、発表への理解を広げたり、論文を理解することも出来て新しい体験(学会発表の新しい聴講スタイル)でした。
今回はオンライン参加のみでしたが、オンラインであるから参加できたこともあり直列ハイブリッド式はありがたかったです。だんだんと現地に回帰の方向でオンラインも並列でやるのは大変だと思いますが、運営の皆様に感謝。次回は現地参加したい!
番外編: AIを使った論文の読み方
時間節約のために、ChatGPTを使って予め論文の概要等を把握してから、読み進めることで論文の理解が進みました。概要を把握して、壁打ちとか査読者の視点でレビューさせると便利。研究者時代にこういうのあったら生産性もっと上がったな、と。聴講中にも質問があったら壁打ちさせたり。
AIを使った論文の読み方は joisino_ さんのこの記事とか参考にしました。
利用したプロンプトの例。
プロンプト例
## 論文情報
以下の項目を正確に記述してください。
- 論文のタイトル
- 著者と所属
- カンファレンス/ジャーナル名
- 発表年
## 論文概要
論文全体の要約を日本語で 2~3 文で記述してください。
## 詳細解説
以下の項目をそれぞれ解説してください。
- 問題設定: 問題の入力と出力、必要なデータを詳細に説明してください。
- 提案手法: 提案手法を適宜数式と具体例を用いて詳細に説明してください。
- 新規性: 先行研究との比較を交えながら具体的に説明してください。
- 実験設定: 使用したデータセットと評価指標の定義を詳細に説明してください。
- 実験結果: 論文中で報告されている具体的な数値を用いて説明してください。
論文の内容を正確に反映することを優先し、不明瞭な点がある場合はその旨を明記してください。
この論文について、この論文の議論で面白い点はなんですか?
# criticalな質問
この論文に対して査読者の観点でcriticalな質問してください。
# 論文の新規性と有用性
また論文の新規性と有用性について批評的に評価してください。
-
完全オンラインや並列ハイブリッド開催は特別の機材が必要であったり、運営側の負担が大きかったために導入されましたが、家庭や仕事の都合で現地参加できない場合でも、ピンポイントで特定のセッションだけ参加できるので、(個人的にも)直列ハイブリッド式は有り難かったりします。昨年は現地参加もしましたが、今年は仕事や家庭の事情もあり、オンラインで二日間だけ参加しました。 ↩︎
-
特に古いDEWS、初期のDEIMは夕食後に他大学や他の研究者と交流する貴重な機会(宴会)がありました。 ↩︎
-
例えば、Neo4jだとproperty index貼れる。 ↩︎
-
Postgresを例にすれば、XMLやJSONなどの半構造データの取り扱いや、フルテキスト索引、ベクトル演算、GIS演算など。最近はグラフ演算も。 ↩︎
-
SARIMAXやProphetは外因性変数を扱えます。FLAMLでもmultivariate timeseriesを扱えて弊社でもプロダクトに利用しています。Gradient Boosting Decision Trees(GBDT)が主に使われますが、決定木なのでスパースなカテゴリカル変数でも量的変数でもうまく扱えます。Kaggleなどの時系列コンペでよく使われますが、tsfreshなどでLAG特徴量を作れば、決定木系でも多変量かつ外挿の時系列データ分析をうまくできたりします。過去弊社でも携わった人流予測の時系列分析コンペでも上位入賞者はGBDT系でした。 ↩︎
-
因果推論(Causal Inference)は因果グラフがGivenで設計が難しいのですが、因果探索(Causal Discovery)は因果構造自体を明らかにするアプローチで概念的に異なる。この記事の説明が詳しい ↩︎
-
PPRは経路群における各ノードの訪問確率によって起点ノードに対する各ノードの重要度を定量化する指標。 ↩︎
-
NGTの開発者の方のインタビューでHNSWにおけるprefetch話があるが、リンクを辿る索引構造のtraversalでprefetchって意外と効くということでした。 ↩︎
-
SPFreshは膨大な数のベクトルがリアルタイムに追加される環境下で、ベクトル検索インデックスの更新(特にクラスタ分割に伴う再割り当て)を効率的に実施するための手法で、最近のLLMのベクトル検索にも利用される。 ↩︎
-
MIG単位には動作周波数を落とせなくてGPU全体の動作周波数を落とす必要があり、そんなに頻繁にも変えられないので、集約する必要がある。 ↩︎
Discussion