似てるSQLコードを炙り出す!dbt Fusionが検討中の機能「model overlap」を自前実装してみた
どうも、stable株式会社でデータエンジニアをしているmyshmehです。
この記事はdbt Advent Calendar 2025の1日目の記事です。
dbt meetup#17では、Coalesce 2025で共有されたFusionの最新情報をお届けしました。その中で、検討中の機能として、model overlapを紹介しました。

この機能は、コードがどれだけ近いのか検知するもので、イベントではdbtのモデルコードのリファクタに使えるのではと発表されていました。
本記事では、このmodel overlap機能について、勝手に私が予想した実装内容・デモをご紹介いたします!Fusionの描く未来がどのようなものか、具体的なイメージの助けになれば幸いです。
Coalesce 2025で発表されたFusion機能のまとめは、こちらを参照ください。
1. 前提: 世は大AIエージェント時代っ
2025年に入り、Vibe Codingは最早当たり前のソフトウェア開発プラクティスになりました。
データエンジニアリング文脈でも、dbtモデルコードやアドホッククエリを生成させるのに、claudeやcodexを使っている方は多いのではないでしょうか?
BIツールでもAIアシスタント機能の標準搭載が目立ち始め、ビジネスユーザーが自然言語でクエリを書けるようになりました。
この変化はコード生産量を劇的に向上させた一方で、新たな課題も生み出しています。
2. 問題: 似たロジックの散在
AI生成のコードが大勢を占める世界観がきて、以下の問題が発生しうる(or 既にしている)と考えています。
AIエージェントが大量生成したコードに、似たロジックが散在
dbtモデルを生成させると、他のモデルと内容がほとんど同じものを新規作成されることは結構あると思っています。特に、mart層のdbtモデルを生成させる際、wide以降の集計ロジックが被ることはよくあるのではないでしょうか。
Lightdashでwrite-backしたコードに、似たロジックが散在
harryさんの記事に代表されるように、BIツールの集計クエリを、マートモデルとしてdbtへ書き戻す取り組みが見られます。
これは、大事な指標はSSOTやクオリティ担保の目的でdbtモデルに昇格させていく考え方だと理解しています。この中で、特に、SSOTの文脈が運用上確保できるのかが焦点になると想像しています。
つまり、BIユーザがAI生成したり、秘伝のタレから作った集計クエリたちが大量にwrite-backされた時に、レビュワーとしてのデータオーナー・AIは適切に共通ロジックを集約できるのかという事です。
(おまけ) RedashのFork地獄
Redashでは、秘伝のクエリをForkして、似て非なる指標が大量発生する問題が有名です。AIのクエリ生成によって、この問題が加速することは間違いないでしょう。
これらの問題を放置しておくと、指標の揺らぎやモデルコードの変更容易性低下を引き起こしてしまいます。結果として、長期的な生産性はあまり上がらないのではないでしょうか。
3. 解決策: model ovelap
Fusionのmodel overlap機能は、検討中のアイデアで、似ているモデルを検知するものと紹介されました。
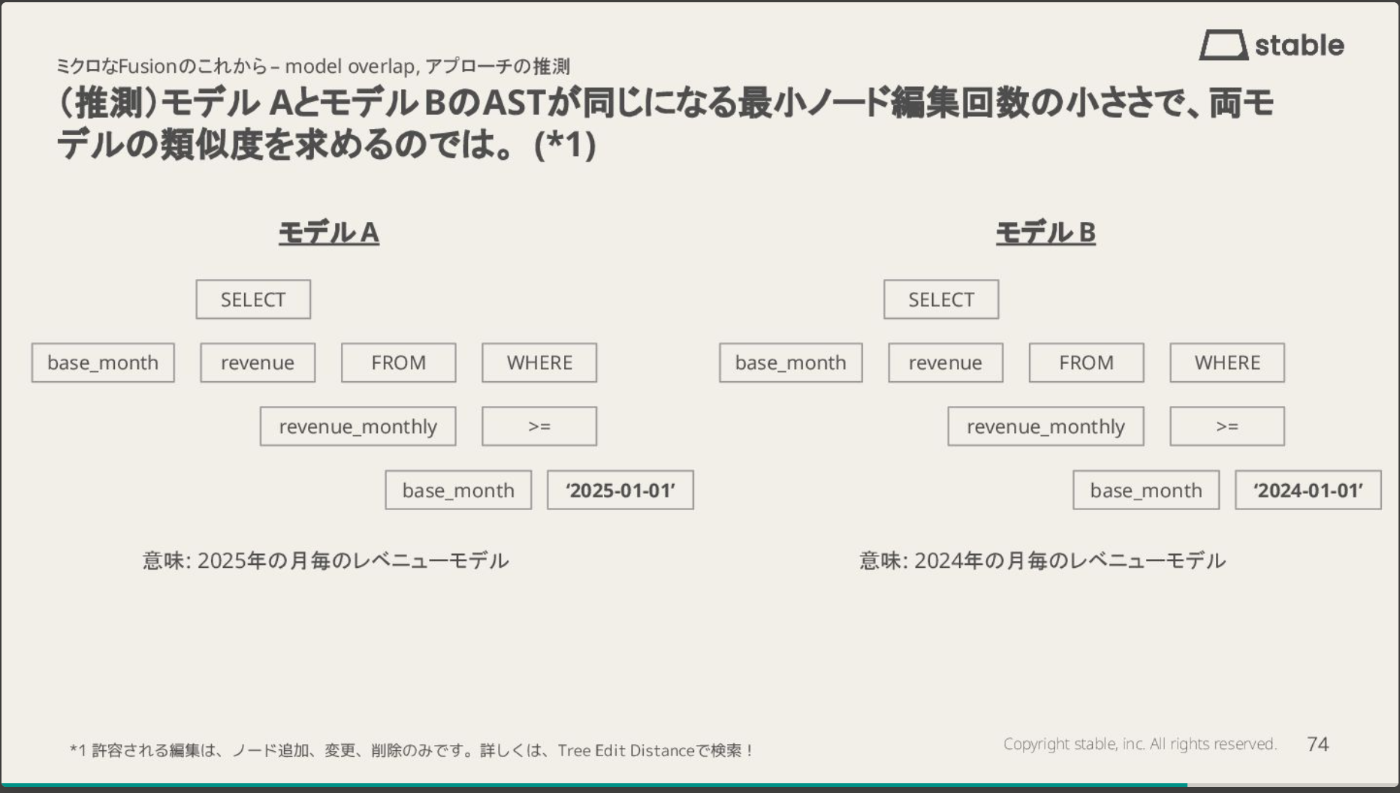
dbt meetup#17では、その実装アプローチとして、モデルAとモデルBのASTが同じになる最小ノード編集回数の小ささで、両モデルの類似度を求めるのではと推測させていただきました。
これは、一般的にはTree Edit Distance (TED)と呼ばれる手法です。このセクションでは、この手法について少し深掘りしていこうと思います!
3-1. Tree Edit Distance (TED) とは
TEDは、ツリー同士の構造的な類似性を定量的に評価するための一般的な指標です。前述の通り、類似度は「一方から他方へのツリーに変換するために必要な最小編集コスト」で求められます。
技術的な系譜として、TEDは、文字列の異なりを求める「レーベンシュタイン距離」という手法を、ツリー構造に一般化したものです。
3-2. アルゴリズムイメージ
「一方から他方へのツリーに変換する」
モデルAをモデルBに変換するために、TEDでは、以下のツリー構造に対する操作が用意されています。
- ノード削除: 既存ノードを削除し、その子ノードを親ノードに接続する。
- ノード追加: 新しいノードを挿入し、親ノードの子ノードの一部をその新しいノードの下に移動する。
- ノード変更: ノード名を変更する。
これらの操作をして、ツリーの変換を行います。
「最小編集コスト」
ツリー同士がどれだけ異なるかの指標として、ノード変換に必要な上記操作の組み合わせのうち、合計編集コストが最も少ないものを採用します。
ここでいう編集コストは上記操作毎に設定が可能で、これにより、どの操作が類似度にどの程度影響を与えるかチューニングすることができます。
3-3. 具体例
類似度が高い例(i.e. 最小編集コストが低い)
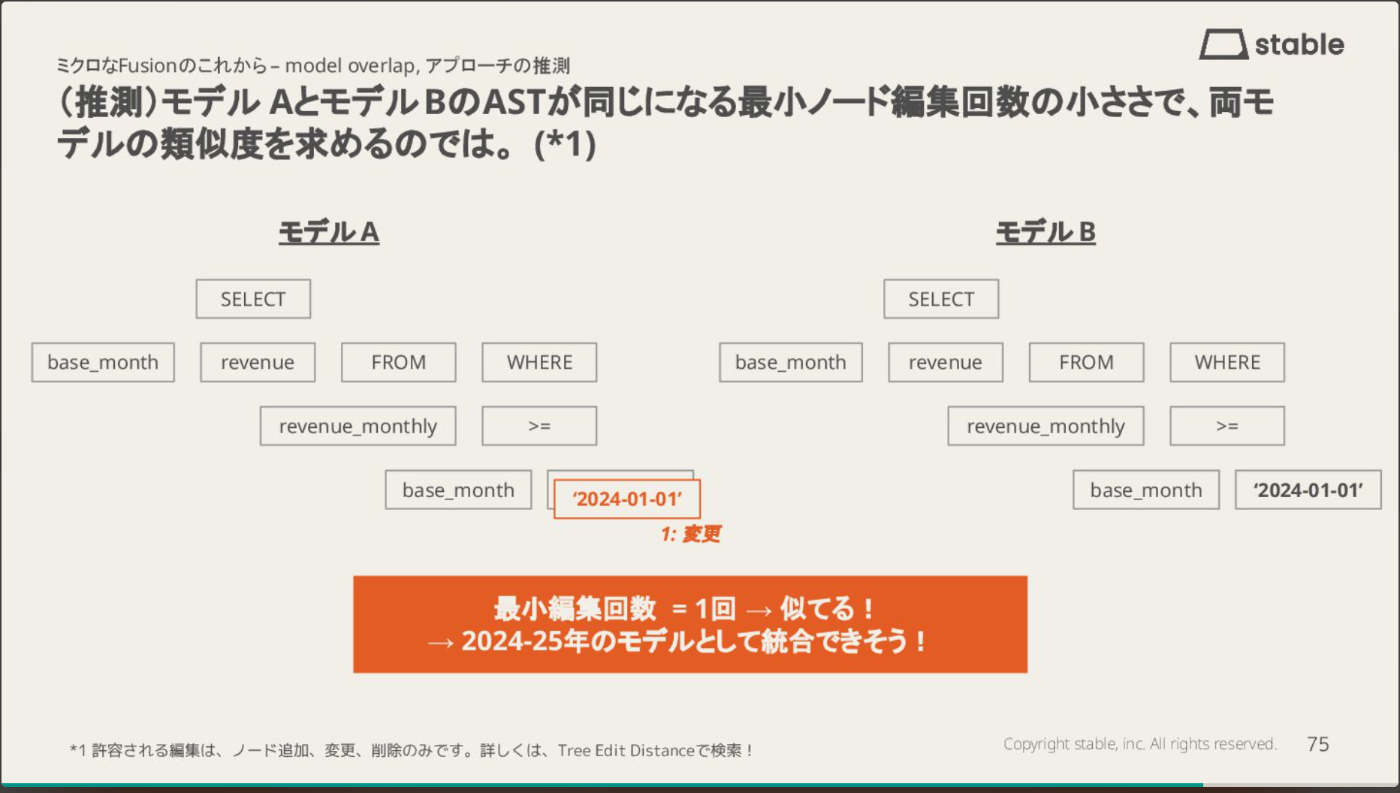
下図は、2025年と2024年の月別レベニューモデルを比較した例です。両モデルのAST構造はほぼ同一で、異なるのは日付リテラル('2025-01-01' vs '2024-01-01')のみです。

この場合、必要な編集操作はノード変更1回だけなので、最小編集回数は1となり、類似度は非常に高いと判定されます。このような高い類似度は、両モデルを統合してパラメータ化できる可能性を示唆しています。
類似度が低い例(i.e. 最小編集コストが高い)
下図は、月別レベニューモデル(モデルA)とシニア世代のユーザIDモデル(モデルC)を比較した例です。両モデルは同じSELECT文の形式ですが、参照テーブル、取得カラム、フィルタ条件がすべて異なります。

モデルAをモデルCに変換するには、ノード削除1回・ノード変更4回の計5回の編集操作が必要となり、類似度は低いと判定されます。このようなケースは、そもそもクエリの目的が異なるため、リファクタ候補にはなりません。

3-4. 実装アプローチ
Complexityに関して、以下の世に知られるアプローチのどれも、基本的に実行時間・メモリ空間ともにPolynomial(n^k)な限度に留まります。しかし、かなりコストの高い処理であることは間違いありません。
| Algorithm | Time Complexity | Space Complexity |
|---|---|---|
| Tai | O(m³n³) | O(m³n³) |
| Zhang & Shasha | O(m²n²) | O(mn) |
| APTED | O(n³) | O(mn) |
Note: m, n は各ツリーのノード数で、n ≥ mです。
上記の中でも、APTEDはツリーの構造に影響を受けず、一定のパフォーマンスを出すことができるため、現状の有力な実装アプローチとして知られているようです。
TEDに関しての詳しい情報は、こちらを参照ください。
4. デモ: model overlapによるリファクタ候補の特定
本章のデモでは、SQLパーサーとTEDを用いて、model overlapを模したプログラムを作成したいと思います!
当該プログラムを使い、コンパイルしたSQLコードを比較して、リファクタ候補となるモデルたちの特定を試みます。
4-1. 問題の設定
以下の開発環境を前提とします。
- dbt project: jaffle-shop
- DWH: snowflake
dbt projectに関して、jaffle-shopのマート層に以下のモデルコードを追加します。これらは、日・週・月別のrevenueデータを表しています。
with orders as (
select * from {{ ref('orders') }}
),
daily_revenue as (
select
date_trunc('day', ordered_at) as date_day,
count(*) as count_orders,
sum(subtotal) as gross_revenue,
sum(tax_paid) as total_tax,
sum(order_total) as total_revenue,
sum(order_cost) as total_cost,
sum(order_total) - sum(order_cost) as gross_profit
from orders
group by 1
)
select * from daily_revenue
with orders as (
select * from {{ ref('orders') }}
),
weekly_revenue as (
select
date_trunc('week', ordered_at) as date_week,
count(*) as count_orders,
sum(subtotal) as gross_revenue,
sum(tax_paid) as total_tax,
sum(order_total) as total_revenue,
sum(order_cost) as total_cost,
sum(order_total) - sum(order_cost) as gross_profit
from orders
group by 1
)
select * from weekly_revenue
with orders as (
select * from {{ ref('orders') }}
),
monthly_revenue as (
select
date_trunc('month', ordered_at) as date_month, count(*) as count_orders,
sum(subtotal) as gross_revenue, sum(tax_paid) as total_tax,
sum(order_total) as total_revenue, sum(order_cost) as total_cost,
sum(order_total) - sum(order_cost) as gross_profit
from orders
group by 1
)
select * from monthly_revenue
上記追加モデルのポイントは、集計粒度が違うだけで、集計ロジックや最終カラムセットが同等であるということです。
4-2. プログラム概要
今回は、pythonでCLIプログラムを組みました。実装内容の詳細が気になる方や、実際に試してみたい方は、こちらを参照ください。
プログラムの大まかな流れ
SQLファイル → AST変換 → TED計算 → 結果出力という流れで類似度を処理します。
- Input
- 2つのSQLファイルを受け取ります。
- Parser
- SQLコードをASTにパースします。ライブラリに関して、ゆるく軽量にSQLをパースできる
sqlparseを採用しています。
- SQLコードをASTにパースします。ライブラリに関して、ゆるく軽量にSQLをパースできる
- Comparator
- ASTというツリー構造を用いて、TEDを計算します。
- 具体的なアルゴリズムとして、今回はパフォーマンスが安定していそうなAPTEDを採用しました。ライブラリに関しては、Database Rearch Groupが公開しているDatabaseGroup/aptedのpythonポート(JoaoFelipe/apted)を使っています。
- APTEDの計算結果として、最小の編集コストとその際の編集パスが返却されます。
- Output
- どれだけ似てるか判断しやすいように、編集コストは、Similarity Scoreとして0 - 1のスケールに正規化しました。0が全く異なり(全てのノードを作り直す必要があった)、1が全く同じ(何もノード操作を要さなかった)事を示しています。
- 補足情報として、Syntax Tree 1が2に変換されるまでの一連のノード操作をEdit Operationsという形で付記しています。
CLIインターフェース
以下の2つの方法を用意しました。
-- 1) 2ファイルの類似度を出力
sql-similarity /path/to/file1.sql /path/to/file2.sql
-- 2) ディレクトリ中にある全SQLファイルの全組み合わせの類似度を出力
sql-similarity /path/to/directory
4-3. 実験
sql-similarityは、SQLコードをパースするため、dbtモデルコードをそのまま渡すことはできません。つまり、一度当該コードをコンパイルして、コンパイルした純粋なSQLコードを指定する必要があります。
したがって、以下のようにtarget/compiled/models/martsを指定して、本プロジェクトのマートモデルの類似度を計算します。
sql-similarity jaffle-shop/target/compiled/models/marts
4-4. 結果
上記コマンドを実行すると、以下の結果が標準出力に返却されました。
Batch Comparison: jaffle-shop/target/compiled/models/marts
Files: 6 | Comparisons: 15 | Errors: 0
File 1 File 2 Score Distance
──────────────────────────────────────────────────────────
daily_revenue.sql monthly_revenue.sql 0.971 4
daily_revenue.sql weekly_revenue.sql 0.971 4
monthly_revenue.sql weekly_revenue.sql 0.971 4
customers.sql daily_revenue.sql 0.393 148
customers.sql monthly_revenue.sql 0.393 148
customers.sql weekly_revenue.sql 0.393 148
customers.sql orders.sql 0.379 157
customers.sql order_items.sql 0.357 157
order_items.sql orders.sql 0.340 167
daily_revenue.sql orders.sql 0.328 170
monthly_revenue.sql orders.sql 0.328 170
orders.sql weekly_revenue.sql 0.328 170
daily_revenue.sql order_items.sql 0.207 149
monthly_revenue.sql order_items.sql 0.207 149
order_items.sql weekly_revenue.sql 0.207 149
出力結果は、類似度を元に降順で比較結果が並びます。幾つか結果について深ぼってみましょう。
類似度の高いケース
daily_revenue.sql vs weekly_revenue.sql(Score: 0.971)は、date_truncの引数が'day'から'week'に、CTEとカラム名がdaily_revenue/date_dayからweekly_revenue/date_weekに変わっただけで、構造はほぼ同一です。ツリー全体で138ノードある中で、編集距離4という結果は、この最小限の差分を表しています。

加えて、daily_revenue.sql vs monthly_revenue.sql(Score: 0.971)も同様のスコアですが、注目すべきはmonthly_revenue.sqlのSQLが意図的に異なるフォーマット(複数カラムを1行に詰め込む形式)で記述されている点です。TEDはASTレベルで比較するため、空白やインデントの違いに影響されず、本質的な構造の類似性を検出できています。

では、*_revenueモデルは、リファクタの対象として妥当なのでしょうか?本質的な違いは期間の粒度だけですから、集計ロジックを何度も繰り返す必要はないはずです。例えば、以下のようなリファクタリングが可能ではないでしょうか。
with orders as (
select * from {{ ref('orders') }}
),
daily_revenue as (
select
date_trunc('day', ordered_at) as date_day,
count(*) as count_orders,
sum(subtotal) as gross_revenue,
sum(tax_paid) as total_tax,
sum(order_total) as total_revenue,
sum(order_cost) as total_cost,
sum(order_total) - sum(order_cost) as gross_profit
from orders
group by 1
)
select * from daily_revenue
select
date_trunc('week', date_day) as date_week,
sum(count_orders) as count_orders,
sum(gross_revenue) as gross_revenue,
sum(total_tax) as total_tax,
sum(total_revenue) as total_revenue,
sum(total_cost) as total_cost,
sum(gross_profit) as gross_profit
from {{ ref('daily_revenue') }}
group by 1
daily_revenueのデータを流用すれば、(weekly|monthly)_revenueは時間の粒度に従い各指標をsumすれば足ります。
このように、TEDを利用すれば、リファクタ候補となるdbtモデルコードを特定することができるとわかりました!
(参考)低い類似度のケース
逆に、daily_revenue.sql vs order_items.sql(Score: 0.207)に関して、 order_items.sqlのコードをみてみると、daily_revenue.sqlと違い集計関数の多用がなかったり、left joinを多く使っている点から構造的なかなり違うことがわかります。結果として、クエリの目的も共通点が見られないので、リファクタ候補にはあがらなそうです。
with
order_items as (
select * from db_name.schema_name.stg_order_items
),
orders as (
select * from db_name.schema_name.stg_orders
),
products as (
select * from db_name.schema_name.stg_products
),
supplies as (
select * from db_name.schema_name.stg_supplies
),
order_supplies_summary as (
select
product_id,
sum(supply_cost) as supply_cost
from supplies
group by 1
),
joined as (
select
order_items.*,
orders.ordered_at,
products.product_name,
products.product_price,
products.is_food_item,
products.is_drink_item,
order_supplies_summary.supply_cost
from order_items
left join orders on order_items.order_id = orders.order_id
left join products on order_items.product_id = products.product_id
left join order_supplies_summary
on order_items.product_id = order_supplies_summary.product_id
)
select * from joined
5. 今後の課題
今回、TEDを用いてモデル類似度の計算を実装してみて、以下の課題がありました。
5-1. パフォーマンス (めっちゃ重いよ!!)
デモのコマンドは、5s程度かかりました。また、1000行規模のSQLコードを与えると、数分の実行時間がかかります。
cProfileを使うと、以下の通り、実行時間ではapted.pyというaptedライブラリの関数がボトルネックになっている印象でした。

APTEDはそもそも複雑なアルゴリズムであるものの、JoaoFelipe/aptedはアクティブにメンテされておらず、もしかしたら実装内容に何か課題があるかもしれません。
時間を見つけて、元のDatabaseGroup/aptedや、DatabaseGroupのC++版のAPTED実装(DatabaseGroup/tree-similarity)を試してみても良いかもしれません。
5-2. 比較のスコープ (CTEレベルで見た方が良い?)
今回は、Fusionのmodel overlapに倣って、モデルコード同士を比較しました。しかし、私が今年データエンジニアをやってみて、CTEレベルでも似た処理がSQLファイルを超えて散在する事を観測しています。
アルゴリズムの複雑性の問題はありますが、リファクタ対象を効果的に発見するには、類似度の比較対象をもっと細かくしても良いかもしれません。
6. Fusionでの活用シーン
Fusionにmodel overlapが実装されたら、具体的にどのような使い方が想定できるでしょうか?
現状、AIエージェントにリファクタを促すと、まずリファクタ対象の検索をするためにdbtプロジェクト内の全モデルコードをコンテキストに入れる必要があると思います。
AIエージェントにこの機能を使わせれば、定量的にリファクタ候補を検出し、自律的なコードリファクタリングを促すことができるのではないでしょうか。
7. おわりに
本記事では、Fusionで検討中のmodel overlap機能を一足先に仮実装してみました。
SQLコードのフォーマットに影響されず、コード構造の類似度を求める本手法によって、AIが大量生成したコードの中からリファクタ候補を効率的に特定できる可能性が示せたのではないかと思います。
Vibe Codingが当たり前になった今、コードの品質管理はこれまで以上に重要になっています。model overlap機能は、人間のレビュワーが見落としがちな重複ロジックを機械的に検出し、SSOTの維持やコードベースの変更容易性向上に貢献してくれるでしょう。
Fusionが正式にこの機能をリリースした際には、今回の仮実装と比較して、どのようなアプローチが採用されているか確認してみたいと思います。
明日以降のdbt Advent Calendar 2025もお楽しみに!
Discussion