Veo 3は映像界のGPT-3となりうるか?Google DeepMindの論文紹介
はじめに
本記事では、先日 Google DeepMind 社によって公開された Veo 3 に関する論文「Video models are zero-shot learners and reasoners」を紹介します。
Veo 3 とは
Veo 3 は、Google DeepMind が開発したテキスト・画像入力から動画を生成できる大規模モデルです。
前進としてはVeo 2 があり、Veo 3 はその改良版となります。2025 年 5 月に発表され同年 7 月に公開されました。
Google Cloud の Vertex AI 上で提供されており、APIを経由して以下のような設定で利用できます:
-
モデル ID:
veo-3.0-generate-preview - 入力:初期フレーム(画像)+テキストプロンプト
- 出力:16:9 比率、720p 解像度、8 秒間(24FPS)の動画
論文概要:「Video models are zero-shot learners and reasoners」
研究背景と目的(Why)
自然言語処理の分野では、GPT-3 の登場以降、大規模言語モデル(LLM)が
個別タスク特化型から*汎用的な基盤モデル(foundation model)*へと進化しました。
コンピュータビジョン分野もこの流れを踏襲していますが、依然としてセグメンテーションや物体検出など「特定タスク専用」のモデル(例:Segment Anything, YOLO など)が主流となっています。
そこで著者らは次の疑問を掲げます:
「動画生成モデルも、LLM のようにゼロショットで多様な視覚タスクを解けるようになるのではないか?」
手法(How)
本論文では追加学習を一切行わず、Veo 3 に対して以下の手順で実験を行いました:
- 入力:1 枚の画像(初期フレーム)+テキスト指示(プロンプト)
- 出力:Veo が生成する動画(各 8 秒、12 サンプルずつ生成)
-
評価対象:
- 62 の質的(qualitative)タスク
- 7 つの定量(quantitative)タスク
以下が論文で示されたタスクの一覧です。とんでもない数ですね。。。
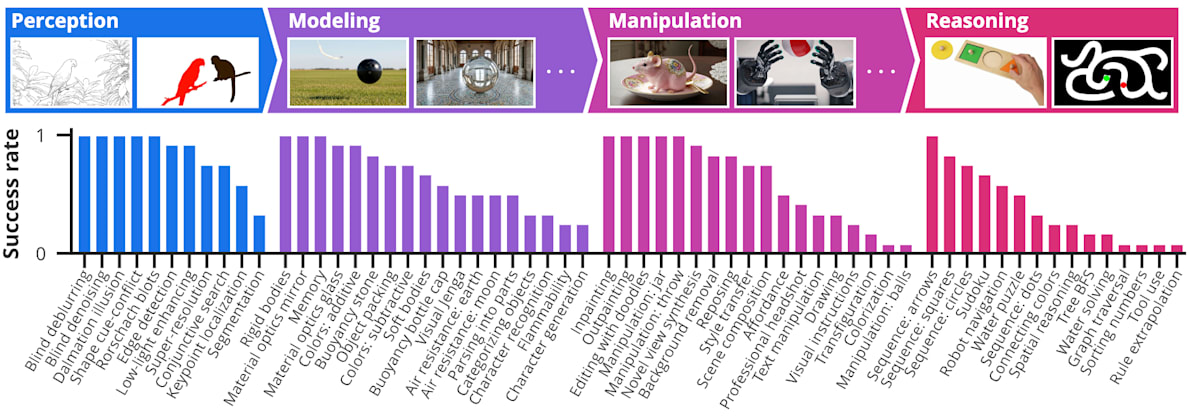
これらのタスクは以下の 4 つの階層で構成されています:
| 能力領域 | 代表タスク |
|---|---|
| ① 知覚 (Perception) | エッジ検出、セグメンテーション、ノイズ除去など |
| ② モデリング (Modeling) | 直感物理(浮力・反射・色混合など)、光学現象 |
| ③ 操作 (Manipulation) | 背景除去、色変換、3D 再構成、物体操作 |
| ④ 推論 (Reasoning) | 迷路解き、図形対称性、数列補完、アナロジー推論 |
評価には、Veo 2 および Nano Banana(Gemini 系画像編集モデル)を比較ベースとして使用。
結果(What)
🔸 定性評価(Qualitative)
-
知覚:
タスク特化学習なしで、エッジ検出・超解像・セグメンテーション・低照度補正を実行可能。
ダルメシアン錯視やロールシャッハ図のような曖昧画像の意味解釈も可能。 -
モデリング:
剛体/軟体/浮力/反射/屈折などの物理的概念を再現し、
「世界のルール」をある程度理解していることを示唆。 -
操作:
背景除去・スタイル変換・inpainting/outpainting などの画像編集をゼロショットで実行。
さらに「物体を掴んで動かす」「ツールを使う」などの動作をシミュレーションできた。 -
推論:
Chain-of-Thought(思考の連鎖)に対応するChain-of-Frames(フレームの連鎖)という概念を提唱。
フレームごとの生成過程を通じて、迷路探索や図形推論などの時空間的推論を実現した。
これらに関しては、元論文やプロジェクトページに多数の生成例が掲載されているので、ぜひそちらをご覧ください!
個人的には青と黄色のインクが混ざってちゃんと緑になったり、ロボットナビゲーションや迷路解きなど時空間的な推論が正しくできている例に驚きました。。。

🔸 定量評価(Quantitative)
| 分野 | タスク | 指標 | Veo 3 の結果 | 備考 |
|---|---|---|---|---|
| 知覚 | エッジ検出 | OIS@10 | 0.77 | SOTA(0.9)に接近 |
| 知覚 | セグメンテーション | mIoU | 0.74 | Nano Banana と同等 |
| 操作 | オブジェクト抽出 | pass@10 | 93% | Veo 2 の 2 倍超 |
| 操作 | 画像編集 | 人手評価 | 高忠実度・高精度 | |
| 推論 | 迷路解き | pass@10 | 78% | Veo 2 は 14% |
| 推論 | 対称性補完 | pass@1 | 約 88% | プロンプト依存性あり |
| 推論 | 視覚アナロジー | pass@1 | ~68%(color 条件) | 抽象変換は未成熟 |
これらすべての領域で、Veo 3 は前世代モデルの Veo2 や Nano Banana を上回る性能を示しました。
結論と意義(So what)
著者らは次のように結論づけています:
「Veo 3 は、ゼロショットで多様な視覚タスクを実行できる初期の“汎用動画生成モデル”であり、
将来的にはコンピュータビジョンの基盤モデルとなる可能性がある。」
多くのタスクにおいて Veo3 の性能は専門特化方モデルのレベルには達していませんが、これは LLM の黎明期における GPT-3 と同様の状況です。言語モデルが基盤モデルへと進化したように、視覚分野においても同様の進化が期待されるとのこと。
言語領域で GPT-3 が起こした変革(“あらゆるタスクを一つのモデルが解く”)と同じ流れが、いま映像領域でも始まりつつあるということです。
おわりに
最近では OpenAI からも Sora2 が出て、動画生成モデルの進化が目覚ましいですね。
nano banana 含め、画像・動画生成モデルが色々なタスクをこなせるのはなんとなく知っていましたが、この論文を読むとその多様性と可能性に改めて驚かされました。
と同時に、専門特化のモデルを構築するような研究は今後どうなってしまうのだろう、という疑問も湧いてきますね。。。
今後もこの分野の動向を追っていきたいと思います。
Discussion