Azureリソースを使用したRAGベースライン実装ハンズオン
前提知識
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)の生成能力と外部知識ベースからの情報検索を組み合わせた先進的なアプローチです。この手法の主な目的は、LLMの応答の質、正確性、そして関連性を向上させることにあります。
準備
データセット
今回は3社分の有価証券報告書をデータセットとして使用します
以下からダウンロードしてください
リソースの立ち上げ
ベースラインに必要なAzureリソース
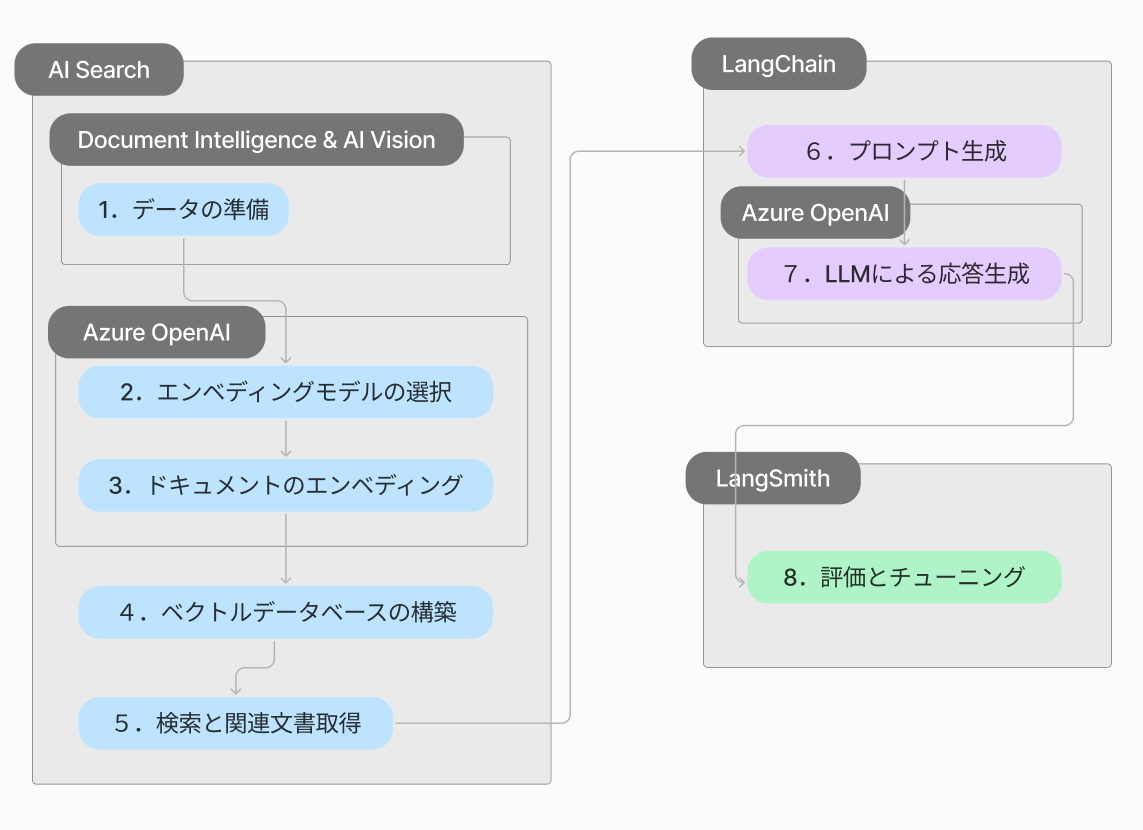
リソースグループの作成
- リソースグループ名:(任意)
- リージョン:Japan East
Azure Open AIの作成
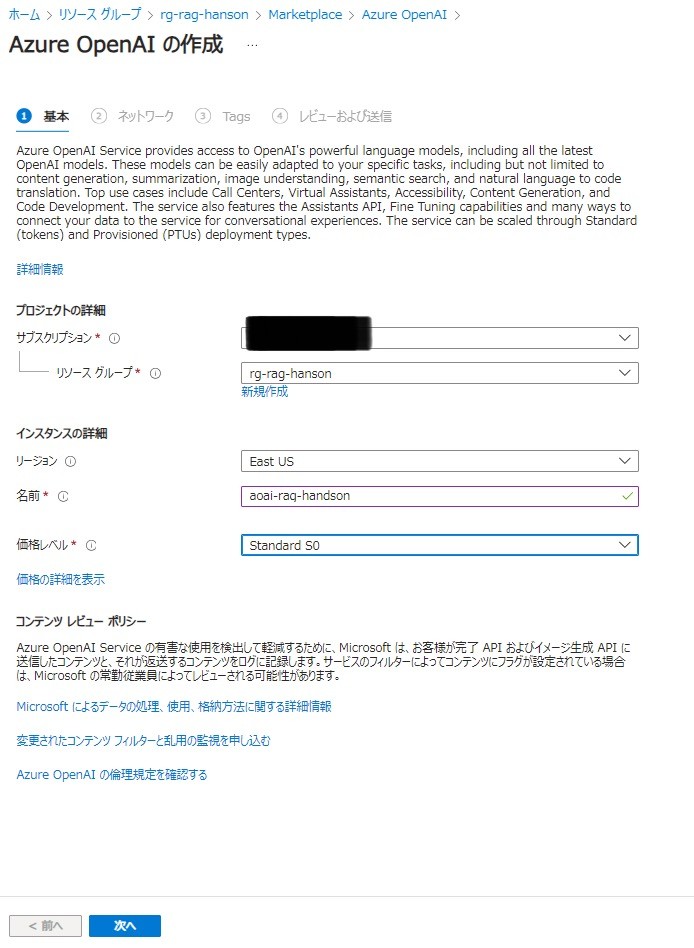
- リソースグループ:前段階で作成したリソースグループ
- リージョン:East US(リージョンによって使用できるモデルに制限があります)
- 名前:(任意)
- 価格レベル:Standard S0
デプロイが完了したら作成したリソースページに移動します
画面上部、[Azure OpenAI Studioに移動する]をクリック
画面上部[すべてのリソース]をクリックして、先ほど作成されたリソースが選択されていることを確認。
-
GPT4o-mini (チャットモデル)
[共有リソース]>[デプロイ]>[モデルのデプロイをクリック]
GPT-4o-miniを選択して[確認]

- デプロイ名:gpt-4o-mini
- モデルバージョン:2024-07-18(既定)
- デプロイの種類:グローバル標準
- 1分あたりのトークンレート制限:500K
- コンテンツフィルター:DefaultV2
[デプロイ]をクリック
-
text-embedding-ada-002(埋め込みモデル)
同様に[共有リソース]>[デプロイ]>[モデルのデプロイをクリック]
text-embedding-ada-002を選択して[確認]

- デプロイ名:text-embedding-ada-002
- モデルバージョン:2(既定)
- デプロイの種類:Standard
- 1分あたりのトークン数レート制限:60K
- コンテンツフィルター:DefaultV2
- 動的クォータを有効にする:有効
[デプロイ]をクリック
ストレージアカウントの作成
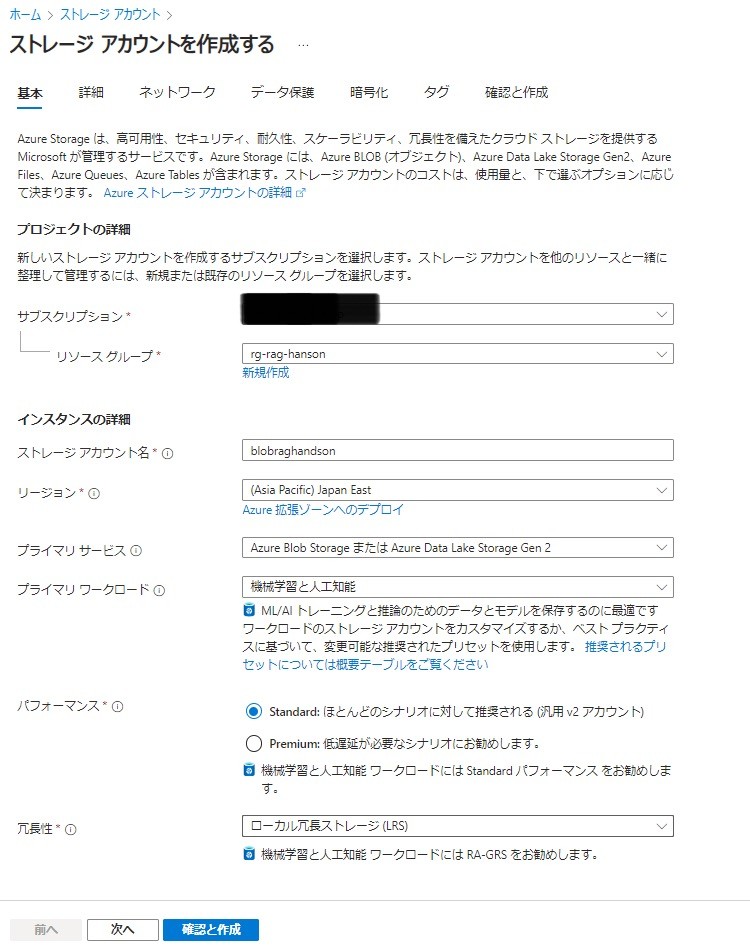
- リソースグループ:前段階で作成したリソースグループ
- ストレージアカウント名:(任意)
- リージョン:Japan East
- プライマリサービス:Azure Blob StorageまたはAzure Data Lake Storage Gen2
- プライマリ
- パフォーマンス:Standard
- 冗長性:ローカル冗長ストレージ
[確認と作成]>[作成]をクリック
-
containerの作成
デプロイ完了後、リソースのページに移動。
[データストレージ]>[コンテナ]>[+コンテナ]をクリック
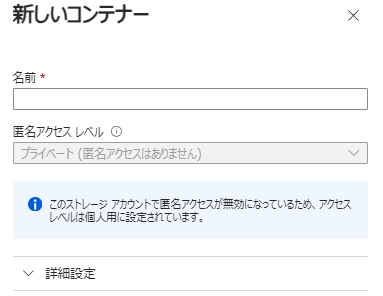
- 名前:vectorcontainer
[作成]をクリック
作成した[vectorcontainer]をクリック
-
データのアップロード
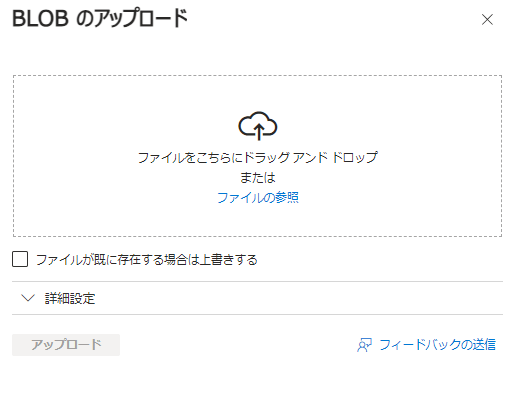
[↑アップロード]をクリック
ダウンロードしておいたPDFファイル3つを参照して[アップロード]をクリック
Azure AI Searchの作成
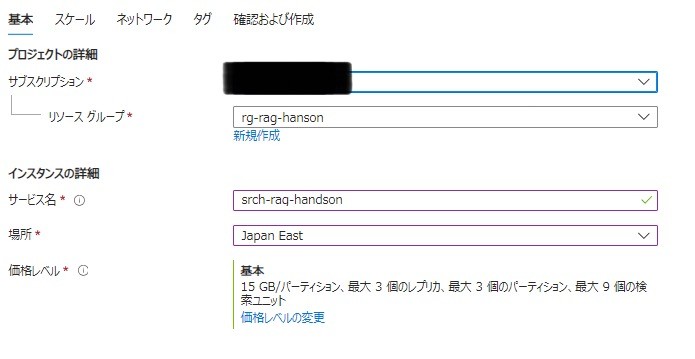
- リソースグループ:前段階で作成したリソースグループ
- サービス名:(任意)
- 場所:Japan East
- 価格レベル: 基本
[次: スケール]>[確認および作成]>[作成]をクリック
-
インデックスの作成
デプロイ完了後リソースに移動
画面上部[データのインポートとベクター化]をクリック

[Azure Data Lake Storage Gen2]を選択
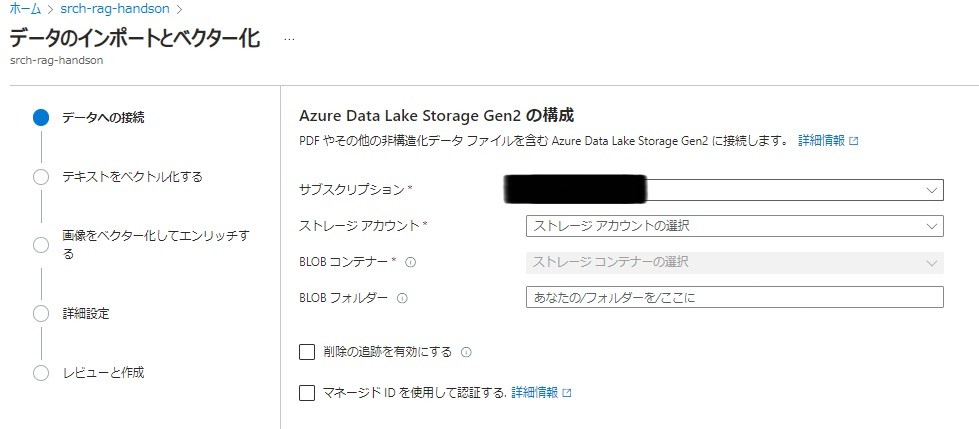
- キーストレージアカウント:前段階で作成したストレージアカウント
- Blobコンテナー:vectorcontainer
[次へ]をクリック
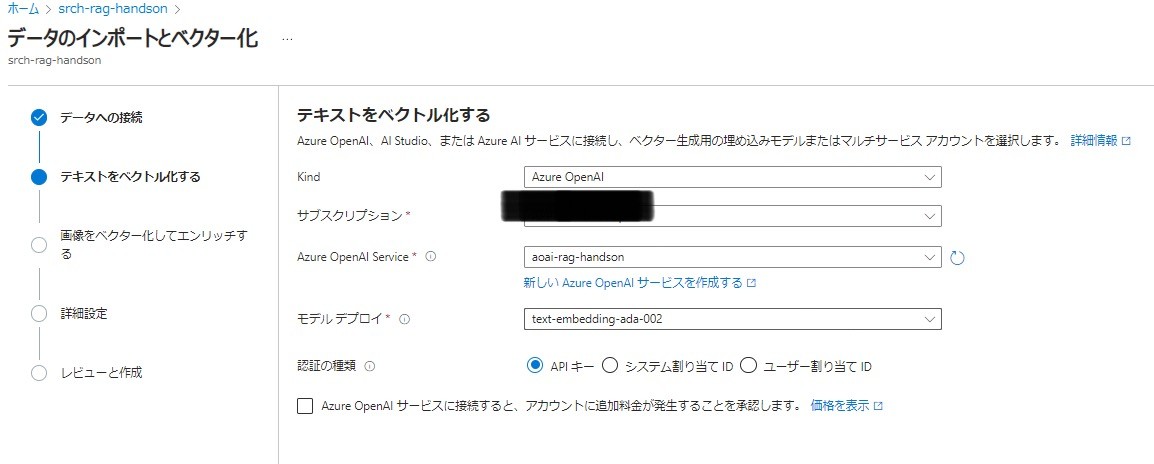
- Azure OpenAI Service:前段階で作成したOpenAIリソース
- モデルデプロイ:text-embedding-ada-002
- 認証の種類:APIキー
- Azure OpenAI サービスに接続すると、アカウントに追加料金が発生することを承認します:有効
[次へ]をクリック

- 画像をベクトル化する
- AIスキルを使用してデータを強化する
どちらもチェックせずに[次へ]

- セマンティックランカーを有効にする:有効
- スケジュール:一度だけ
[次へ]をクリック

- オブジェクト名のプレフィックス:(任意)
[作成]をクリック
- インデックス
- インデクサー
- データソース
- スキルセット
以上作成されたことを確認しておきましょう
LangChainによるパイプライン実装
LangChainとは
LangChain は、大規模言語モデル (LLM) に基づいてアプリケーションを構築するためのオープンソースフレームワークです。LLM は、大量のデータで事前にトレーニングされた大規模な深層学習モデルで、ユーザーのクエリに対する応答を生成できます。たとえば、質問に答えたり、テキストベースのプロンプトから画像を作成したりします。LangChain は、モデルが生成する情報のカスタマイズ、正確性、関連性を向上させるためのツールと抽象化を提供します
jupyter notebookでの実装をお勧めします
環境設定
必要なライブラリのインストール
pip install langchain langchain-community langchain-openai openai
Azure OpenAI のエンドポイント、APIキー、AI Searchのサービスネーム、インデックス、APIキーを環境変数に設定します
import os
os.environ["AZURE_OPENAI_API_KEY"] = "<YOUR_AZURE_OPENAI_API_KEY>"
os.environ["AZURE_OPENAI_ENDPOINT"] = "<YOUR_AZURE_OPENAI_ENDPOINT>"
os.environ["AZURE_AI_SEARCH_SERVICE_NAME"] = "<YOUR_SEARCH_SERVICE_NAME>"
os.environ["AZURE_AI_SEARCH_INDEX_NAME"] = "<YOUR_SEARCH_INDEX_NAME>"
os.environ["AZURE_AI_SEARCH_API_KEY"] = "<YOUR_API_KEY>"
LLMモデルの初期化
AzureChatOpenAIクラスのインスタンスを作成
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
api_version="2024-02-01",
azure_deployment="gpt-4o-mini",
max_tokens=1000,
temperature=0.7,
)
システムメッセージの初期化
from langchain.schema import HumanMessage, SystemMessage
system_message = SystemMessage(content="You are a helpful assistant.")
chat関数の実装
def chat(user_input):
input_messages = [
system_message,
HumanMessage(content=user_input)
]
ai_msg = llm.invoke(input_messages)
return ai_msg.content
実行してみる
chat("こんにちわ")
AI Searchとの接続
AzureAISearchRetrieverクラスのインスタンスを作成する
from langchain_community.retrievers import AzureAISearchRetriever
retriever = AzureAISearchRetriever(
content_key="chunk", top_k=5, index_name=os.environ["AZURE_AI_SEARCH_INDEX_NAME"]
)
検索を実行してみる
retriever.invoke("伊藤忠商事")
パイプラインを作成する
検索結果をもとに回答を生成するプロンプトテンプレートを作成する
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"""Answer the question based only on the context provided.
Context: {context}
Question: {question}"""
)
検索結果を整形する関数を作成
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
検索→回答生成のパイプラインをLCEL記法を使用して実装
LangChain の新記法「LangChain Expression Language (LCEL)」入門
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
実行してみる
chain.invoke("伊藤忠商事の企業理念とそれに基づいたサステイナビリティな活動について教えて")
まとめ
どんなRAGプロジェクトでもひとまず最速でベースラインを構築して、その入力と出力を観察しながらチューニングをしていくことが最良への近道です!
Discussion