TerraformでAthena環境を構築してS3のログをクエリ分析してみた
Hayatoです!
今回はTerraformでAmazon Athenaを構築する手順について書いていこうと思います。
「S3にログが保存されているものの、分析のために手動でAthenaの設定をするのは面倒…。Terraformを使ってこの一連の設定を自動化してみましょう!」
Terraformとは
Terraformは、HashiCorpが開発したInfrastructure as Code (IaC)ツールです。
インフラの構成をコードで定義し、自動的にプロビジョニング、管理するのに役立ちます。
AWSマネジメントコンソールからS3バケットを作ったりEC2を起動させたりすることはもちろんできますが、リソースの数が増えると、操作ミスや設定の抜け漏れが起きやすくなり、手間も増えてしまいます。
Terraformを使えば、リソースをコードで管理することができるため、構築作業を自動化・標準化でき、再現性の高い環境を手早く安全に作成できます。
Amazon Athenaとは
Amazon Athena は、Amazon S3 に保存された構造化・半構造化データ(例:CSV、JSON、Parquet、ORC など)に対して、標準的な SQLを使って直接クエリを実行し、サーバーレスでデータ分析を行えるサービスです。
AWS構成
今回のケースでは既にS3にログファイルが保存されていて、その分析が必要になった、というケースを想定して下記のような構成になっています。
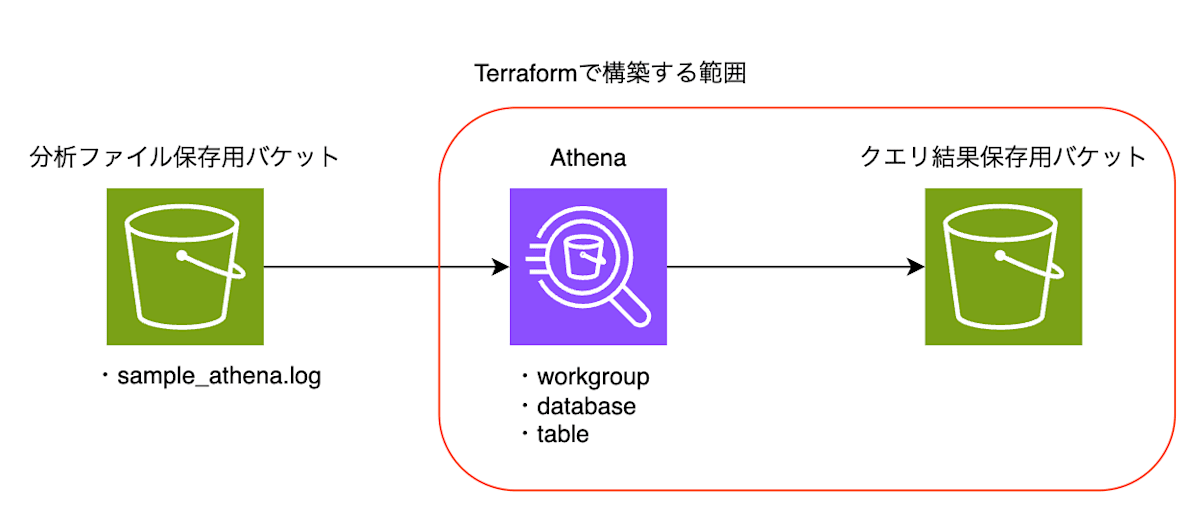
※事前作業として、S3バケットを1つ事前に作成してください。
作成したS3バケットに分析するファイルを保存してください。
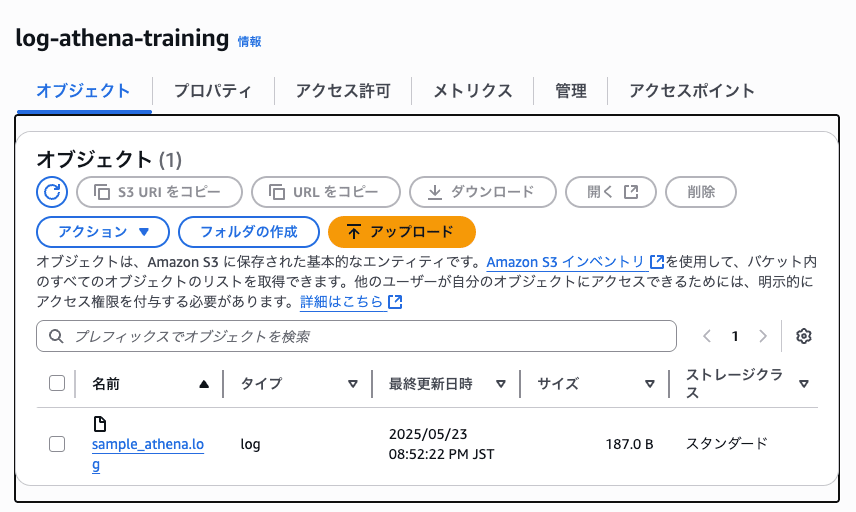
今回 log-athena-training という名前のバケットを作成し、
sample_athena.log というファイルを配置しています。
ファイル構成
作成するファイルは以下になります。
※コードをそのまま使用する際は、ファイルを同じディレクトリに配置してください。
- main.tf
ここでAWSリソースを定義します
# terraform configuration
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
}
}
}
# providerの指定
provider "aws" {
profile = "terraform"
region = "ap-northeast-1"
}
# クエリ結果保存用S3
resource "aws_s3_bucket" "result_bucket" {
bucket = "result-athena-training"
force_destroy = true
}
# パブリックアクセスをブロック
resource "aws_s3_bucket_public_access_block" "result_bucket" {
bucket = aws_s3_bucket.result_bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# Athena
# ワークグループの作成
resource "aws_athena_workgroup" "test" {
name = "test"
configuration {
result_configuration {
output_location = "s3://${aws_s3_bucket.result_bucket.bucket}/query-results/"
}
}
force_destroy = true
}
# DBの作成
resource "aws_athena_database" "db" {
name = "db_log"
bucket = aws_s3_bucket.result_bucket.id
force_destroy = true
}
# テーブルの作成
resource "aws_athena_named_query" "create_table" {
name = "create_sample_table"
database = aws_athena_database.db.id
query = file("./create-table.sql.tpl")
workgroup = aws_athena_workgroup.test.name
}
- create-table.sql.tpl
クエリを記載します。
スキーマはログファイルと揃えましょう。
CREATE EXTERNAL TABLE IF NOT EXISTS db_log.sample_table (
`id` int,
`name` string,
`number` int,
`position` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS TEXTFILE
LOCATION 's3://log-athena-training/'
;
- .tool-versions
.tool-versionsはasdfでバージョン管理をしている都合上使用しています。
asdfを使用していない際は不要になります。
terraform 1.10.5
実行結果
下記のコマンドを順番に実行してください
terraform init
terraform plan
terraform apply
plan, applyは実行後、yesと入力してEnterをしてください。
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
上記のように成功したら、AWSコンソールを確認してみましょう!
Athenaの画面に移動したら右上にあるワークグループを確認しましょう。
今回設定した test に変更します
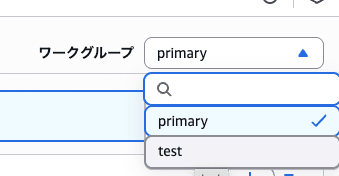
この時点ではまだテーブルを作成するクエリが実行されていません。
aws_athena_named_query はクエリを保存するだけで実行まではしません
(terraform apply 時点でクエリも自動実行させたい場合、aws_athena_named_query ではなく null_resource や local-exec を使って aws athena start-query-execution を実行する方法もあります。
※今後検討したいポイントです。)
保存したクエリ から create_sample_table を選択し、
エディタ から実行してみましょう!
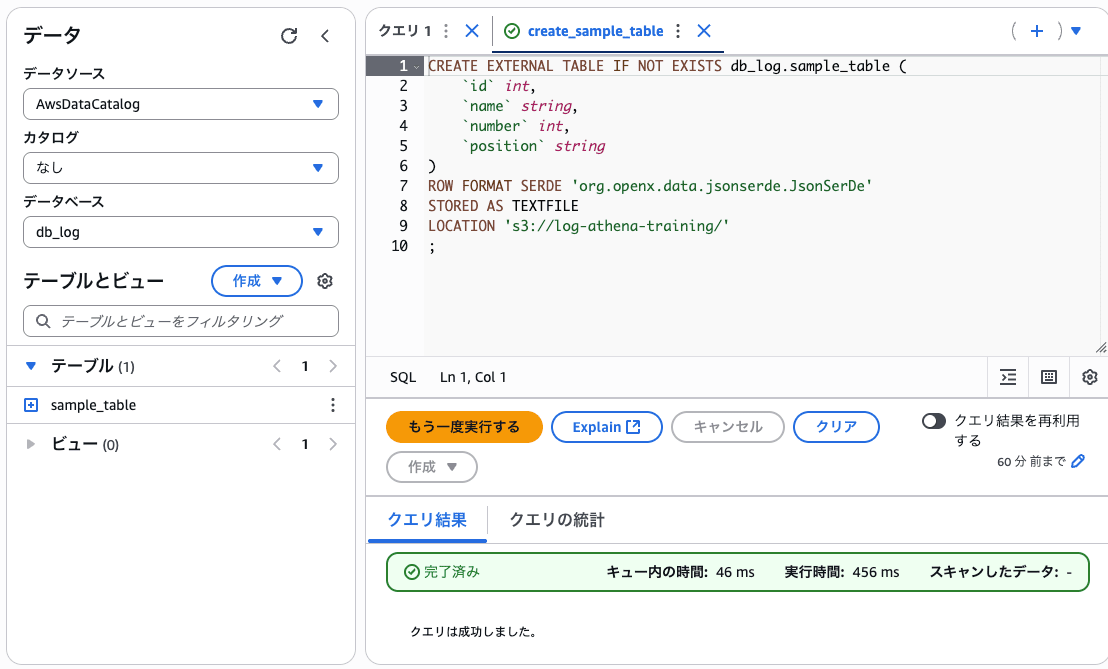
ここで作成したテーブルの値を見てみましょう。
select * from sample_table;
このクエリを実行します。
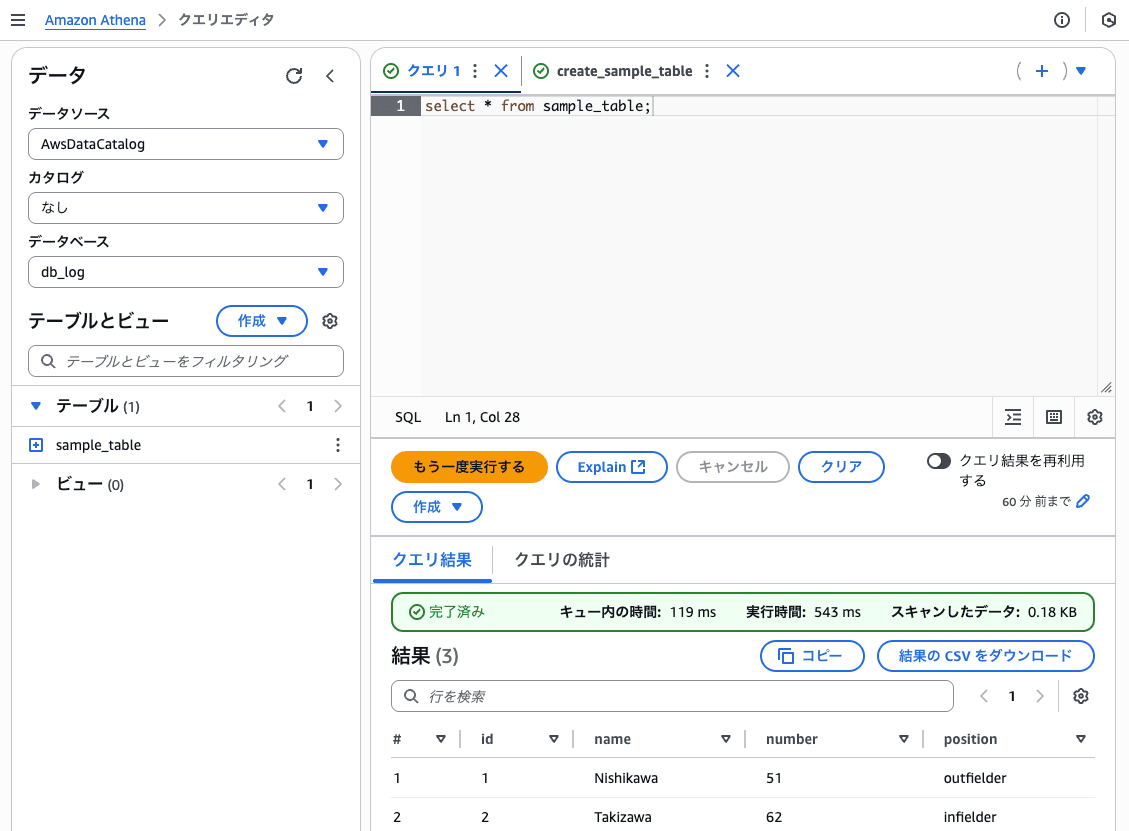
クエリが無事成功すると、結果 のところに表示されます。
また、クエリ結果保存用のS3にクエリ結果が保存されます。
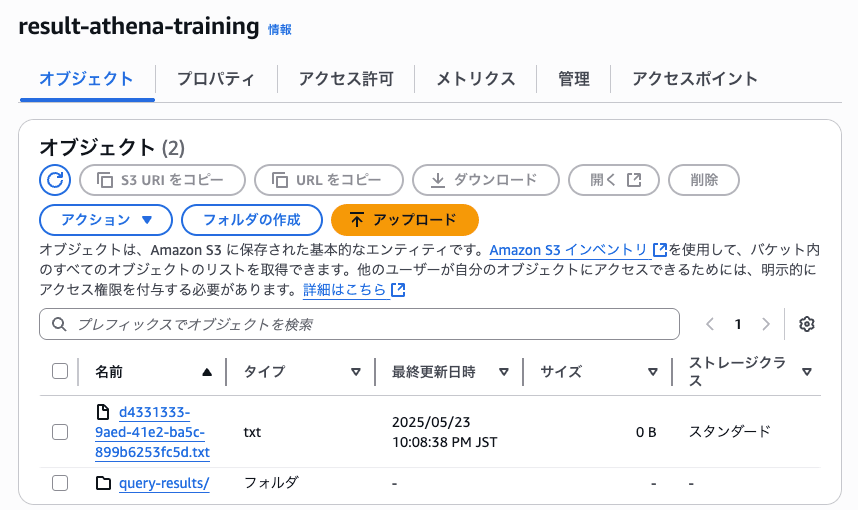
query-results/ 配下にcsvファイルが生成されるのでそちらで結果を確認できます。
余談ですが、
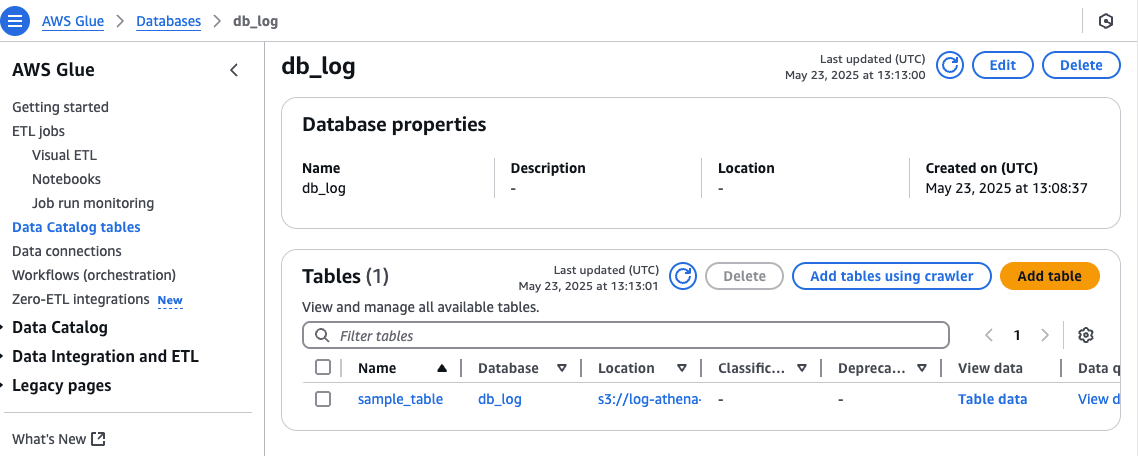
実はAthenaで作成したデータベースやテーブルの定義は、内部的にはAWS GlueのData Catalogに保存されています。
実際にGlueのコンソールにアクセスすると、今回作成した db_log というデータベース、sample_table というテーブルが登録されていることが確認できます。
構築・実行できたら不要な課金を防ぐために作成したリソースを削除しましょう
terraform destroy
また、事前に作成したS3バケットも不要でしたら削除しましょう。
最後に
最後までお読みいただきありがとうございました。
今回はTerraformでAthenaを構築してみましたが、他のサービスも構築してみようと思います!
Discussion