AWS CloudWatchアラームを設定してみた
はじめに
こんにちは!みゃっちーです。🦔
AWS SCS試験ただ勉強してももったいないから面白そうな構成作ってみよう第4弾です。
今回はCloudWatchアラームを設定して、SNSトピックと連携させていきたいと思います!
想定している全体像
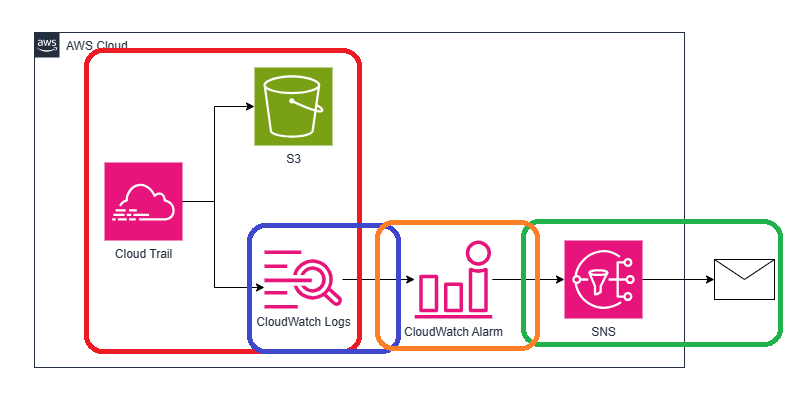
想定している全体像は下記の通りです。
AWS CloudTrailでユーザのAPI履歴をS3、CloudWatchLogsに送信し、特定のアラートでSNSでメールを送信する。
第1弾の記事
赤色で囲ったAWS CloudTrailの証跡をCloudWatch logsに取得する構築
第2弾の記事
青枠で囲った部分のCloudWatch メトリクスフィルターの設定を行い、EC2作成イベントの抽出
第3弾の記事
CloudWatchアラートが発行されたときに格納するSNSトピックとメールを送信するサブスクリプションの構築
ときて今回は、オレンジ色のCloudWatchアラームを設定して、SNSトピックとの連携を行います
AWS CloudWatch アラームとは?
公式の説明は下記の通りです。
1 つの CloudWatch メトリクスを監視する、または複数の CloudWatch メトリクスに基づく数式の結果を監視するメトリクスアラーム。アラームは、メトリクスや式の値が複数の期間にわたって特定のしきい値を超えた場合に 1 つ以上のアクションを実行します。アクションでは、Amazon SNS トピックに通知を送信したり、Amazon EC2 アクションまたは Amazon EC2 Auto Scaling アクションを実行できます。また、Systems Manager で OpsItem またはインシデントを作成できます。
このようにCloudWatch メトリクスの値を見て何らかのアクションをする仕組みです!今回はこれを、EC2作成メトリクスの数を監視して、特定の時間内に異常な数(特定の閾値以上)のEC2作成メトリクスが発生したときにメールを送信するということに活用します。
やってみた
1.CloudWatchアラートの作成を開く

2.アラートを設定するメトリクスを選択する

前回作成した「EC2_Surveillance」メトリクスグループの「RunInstance」を選択します。

3.メトリクスの条件を指定する

統計
メトリクスの統計方法は下記のようなものがあります。
主要なもの
- 平均 (Average)
- 合計 (Sum)
- 最大 (Maximum)
- 最小 (Minimum)
- サンプル数 (Sample Count)
その他
-
IQM (Interquartile mean):
- 説明: 四分位範囲のトリム平均、または値の中央の 50%。
- かみ砕き: データセットの最低25%と最高25%を除外して(トリムして)、残りの値の平均を計算する。
-
p (Percentile):
- 説明: データセットにおける値の相対的な位置。例えば、p95 は期間の 95 パーセントのデータがこの値を下回り、5 パーセントが上回っていることを示す。
- かみ砕き: 例えばp95の値が100の時は95%の値が100以下ということになる。
-
TM (Trimmed mean):
- 説明: 指定された範囲のデータポイントの平均。境界外の値は無視されます。
- かみ砕き: 例えばTM(10%:90%)の場合は最小値と最大値を除いたデータセットの10%から90%までの範囲にある値の平均を求めるということになる。
-
TC (Trimmed count):
- 説明: トリミング平均統計の選択した範囲内のデータポイント数。
- かみ砕き: 例えばTC(10%:90%)の値が3である場合は、最小値と最大値を除いたデータセットの10%から90%までの範囲にあるデータポイントは3つであるということになる。
-
TS (Trimmed sum):
- 説明: トリミング平均統計の選択した範囲内のデータポイントの値の合計。
- かみ砕き: 例えばTS(10%:90%)の場合は、TCを使って抽出したデータポイントの値をすべて足した数になる。
-
WM (Winsorized mean):
- 説明: トリム平均に似ていますが、境界外の値は無視されず、境界のエッジにある値と等しいと見なされます。
- かみ砕き: 例えばWM(10%:90%)の場合は、最小値と最大値から10%、90%外の値をこの範囲内の最小、最大の値に変換する。
今回はEC2の作成回数を確認したいので合計(SUM)を使いたいと思います。
期間
メトリクスを計算する間隔を設定します。
間隔が1分以内の場合(高解像度メトリクス)は料金が発生するので注意が必要です。
今回は5分で設定しました。
条件の設定
上記で算出した数値からアラートを発生させる条件を設定しますが、大きく分けて2種類用意されています。
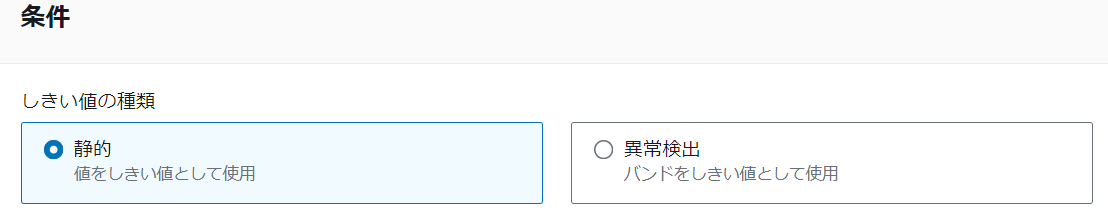
静的
今回は5分間に2個以上EC2インスタンスが作成されたときにアラートを発生させたいので
下記のように設定します。

次にその他設定です。

アラームを実行するデータポイントは、アラームを発生させるために必要なデータポイント数を設定することができます。
欠落データの処理は指定したメトリクスの収集時間ないにデータポイントが無かった場合の処理を設定可能で、このような項目を選択できます。
- 1.欠落データを見つかりませんとして処理
- 2.欠落データを適正(しきい値を超えていない)と処理
- 3.欠落データを無視(アラーム状態を維持する)と処理
- 4.欠落データを適正(しきい値を超えている)と処理
今回は、何かしらのリソースが作成されたときにログが発生し、通常時はデータが欠落するのが正常であるのでので2の適正として処理する。
異常検出
今回は使用しませんが、以下の公式説明のように過去のデータから予測を行い、予測外のメトリクスが検出されたときにアラームを発生させます。
CloudWatch の異常検出に基づいてアラームを作成できます。これにより、過去のメトリクスデータが分析され、予想される値のモデルが作成されます。予想される値では、メトリクスの一般的な時間単位、日単位、週単位のパターンを考慮します。
具体的なユースケースとしてはこのように具体的なしきい値を設定しにくい場合などに使用します。
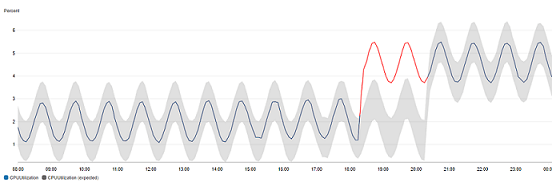
その他わかりやすい例もこちらに多数記載されています。
通知の設定
通知は下記のようにアラート状態、OK、データ不足の3つが選択可能です。
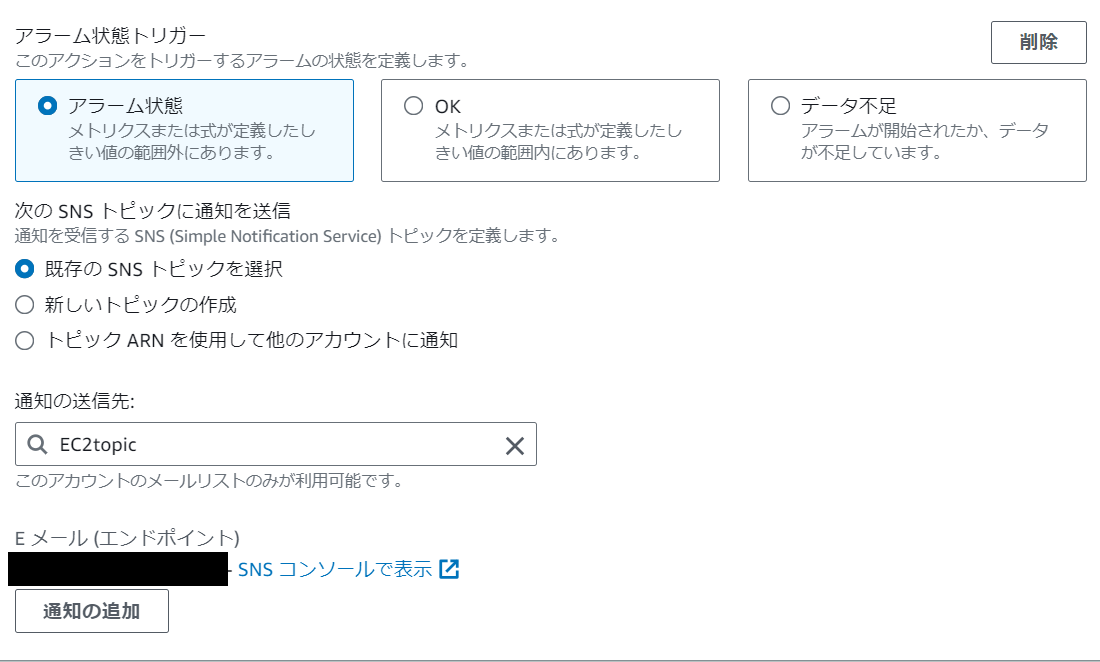
今回はアラート状態(5分間のEC2の作成時が2つ以上)の時に前回作成したSNSトピックに通知を送信するように設定します。
そして通知以外にも様々なサービスに対してアクションを起こすことが可能です。
- Lambda アクション
- Auto Scaling アクション
- EC2 アクション
- Systems Manager アクション 情報
ちなみにLambdaアクションは2023.12.23日に追加されたばかりです。
以前はSNSを経由せずにLambdaにアクションを起こせるのは便利ですね!
アラームの名前と説明の設定
次にアラームの名前と説明を追加します。この2つは送信されるメール本文にも記載されます。
動作確認
動作確認を行いますが、実際にEC2を作成してアラームを発生させるのと、AWS CLIのコマンドを使って強制的にアラーム状態にさせる方法2つで行っていきます。
AWS CloudShellからアラーム状態にする
故意にアラームを発生させるのが難しいケースはこちらの方法がお勧めで、わかりやすく書いてくださってます。
使用するコマンドは下記の通りで、状態を変更するアラートの名前とこの状態変更操作の名前を入れます。今回はEC2_TESTにしました。
aws cloudwatch set-alarm-state --alarm-name {アラートの名前} --state-value ALARM --state-reason "{状態を変えたこのコマンドの名前}"
そしてこのコマンドを実行するとアラームの状態が変更され、無事メールが送られてきました。

送信されたメール

翻訳
このメールは、米国東部(バージニア北部)リージョンにおけるAmazon CloudWatchアラーム「EC2複数作成」が、「2023年12月26日 火曜日 03:54:47 UTC」に「EC2_test」の理由でALARM状態に入ったため、お知らせしています。
AWS Management Consoleでこのアラームを表示:
https://**************
アラームの詳細:
名前: EC2複数作成
説明: 5分間にEC2インスタンスが2台以上作成されました。
状態変更: OK -> ALARM
状態変更の理由: EC2_test
タイムスタンプ: 2023年12月26日 火曜日 03:54:47 UTC
AWSアカウント: 006226380476
アラームArn: arn:aws:**************************
閾値:
メトリックが最後の300秒のうち、少なくとも1つの1期間(300秒)にわたって2.0以上の場合、アラームはALARM状態になります。
モニタリングされるメトリック:
メトリック名前空間: EC2_Surveillance
メトリック名: RunInstance
寸法:
期間: 300秒
統計: 合計
単位: 未指定
欠落データの処理: notBreaching
状態変更アクション:
OK:
ALARM: [arn:*************************]
INSUFFICIENT_DATA:
このトピックからの通知を受け取りたくない場合は、以下のリンクをクリックして購読解除してください:
https://*********************************
このメールに直接返信しないでください。このメールに関する質問やコメントがある場合は、以下のリンクからお問い合わせください:
実際にEC2を立ててみる
実際に2台EC2を立ててみるとこのようにしっかりアラームになりメールも送信されました。

ただ、CloudShellの場合と違い、アラーム状態になった理由がEC2_testからこのように変わりました。
- Reason for State Change: Threshold Crossed: 1 out of the last 1 datapoints [2.0 (26/12/23 04:07:00)] was greater than or equal to the threshold (2.0) (minimum 1 datapoint for OK -> ALARM transition).
訳)状態変更の理由: 閾値が越えられました - 直近の1つのデータポイント [2.0 (23年12月26日 04:07:00)] が、閾値(2.0)以上であったためです(OKからALARMへの遷移には最低1つのデータポイントが必要です)。
さいごに
ここまで読んでいただきありがとうございました!
実際に作ってアウトプットしてみると、触ったサービスがすべてチャンス問題になるので書いていてもとても楽しいです!
今後も続けていきたいと思います(`・ω・´)ゞ
Discussion