Amazon Kendra による機械学習を活用した情報検索を試してみた
こんにちは、@mrk_17tksmです!
社内の業務データをもとに Amazon Bedrock(TitanやClaudeなどのLLM)を使用して回答の生成結果に含んでほしいことありますよね。効率的に高精度な独自データを含む回答を生成するためには、RAG(検索拡張生成) と呼ばれる手法を利用します。RAGの検索結果をLLM(大規模言語モデル)の生成結果に含めることで、より正確な回答を生成することができます。
本ブログでは、AWS上でRAGを導入する際によく利用される『Amazon Kendra』を使って、独自データの検索結果を検証していきます。
■ Amazon Kendra とは
Amazon Kendra は機械学習(ML)アルゴリズムを活用した、エンタープライズ向けの情報検索サービスです。このサービスでは主に2点の機能を提供しています。
(1)あいまい検索機能
(2)他サービスとの統合機能
このサービスを利用することで企業や組織で蓄積された膨大なドキュメントやマニュアルを学習させて、従業員などの利用者が必要な情報を素早く検索できることが可能になります。
■ Amazon Kendra の基本料金
エンタープライズ向けのサービスであり、サービス内部で機械学習のインスタンスを確保している関係上、料金もそれなりにします。

ディベロッパー版で810ドル/月、エンタープライズ版で1,008ドル/月と固定費用がかかることに注意してください。開発プランであれば、最初の30日間で最大750時間の無料利用枠があるので、まずはここで試すことを推奨します。
無料利用枠でも他サービスとのコネクション費用は従量課金の対象になります。
■ 事前準備
ユーザーによる独自データを保管するS3バケットが必要です。フォルダは必ず必要ではありませんが、Kendraに分析させたいデータ量を調整するために作成することを推奨します。
■ Amazon Kendra を構築してみる
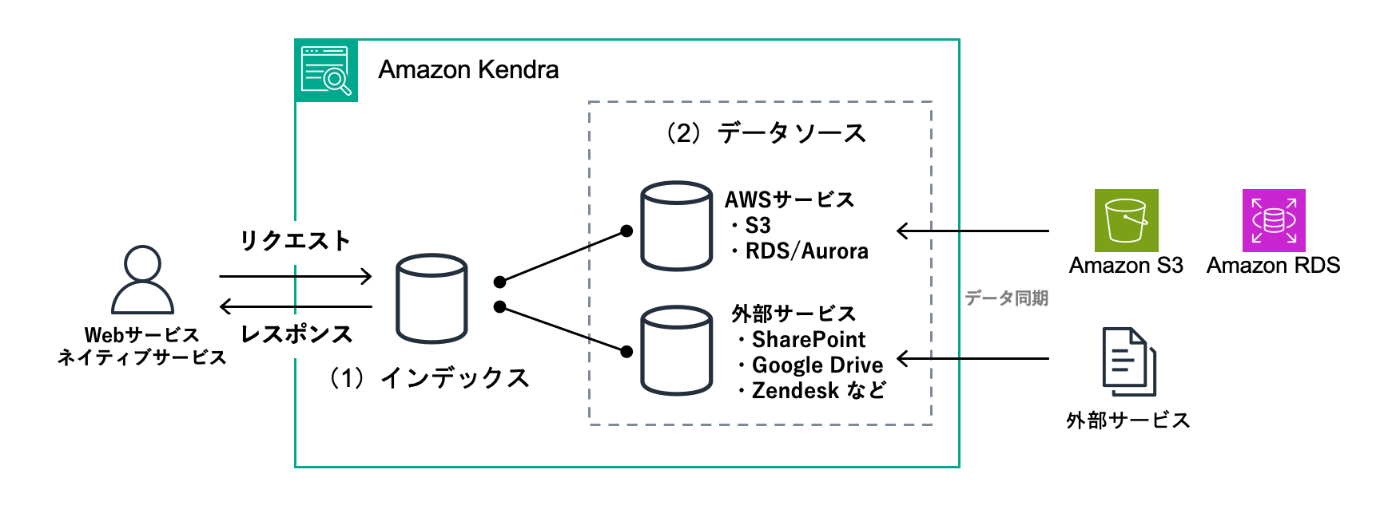
(1)インデックスの作成
Amazon Kendraを利用するためには、インデックス と呼ばれる独自データを管理するデータの集合体 を作成する必要があります。
インデックスでは、下記の3要素を含む各種データをデータソースから抽出します。
- テキスト情報(PDF、Word文書、HTMLなど)
- メタデータ属性(タイトル、作成日、最終更新日など)
- カスタム属性(各ドキュメントごとに属性の追加が可能)
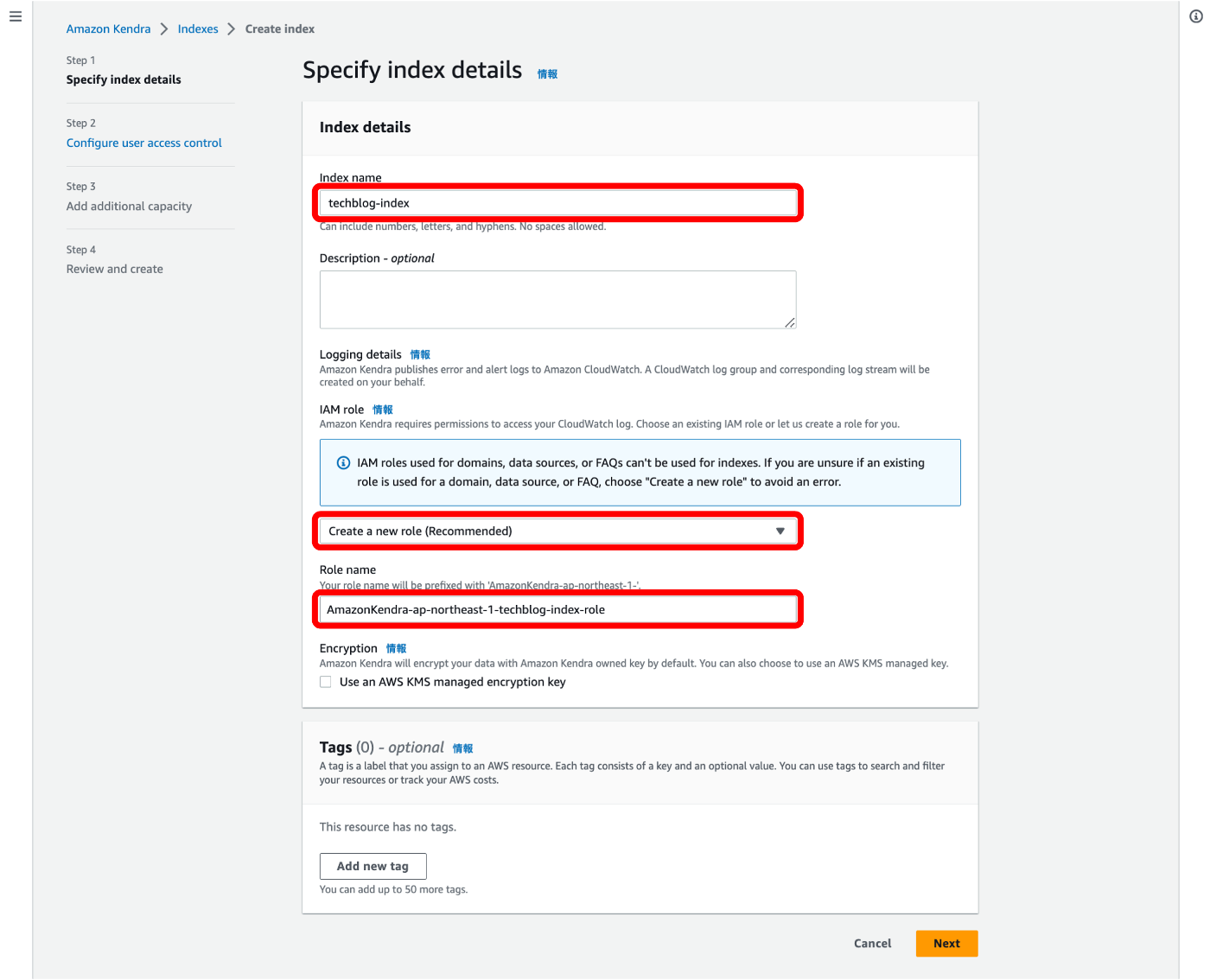
① インデックス名とCloudWatchにログを収集するためのIAMロールを設定します。
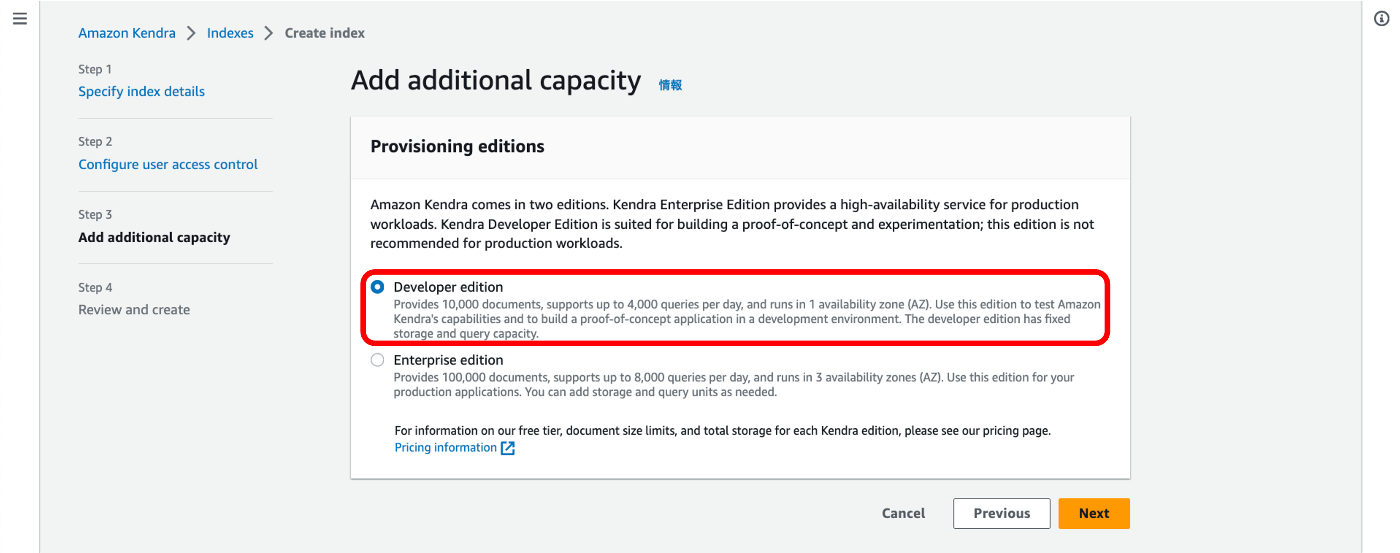
② 『Developer Edition』 を選択します。
作成ボタンをポチッと押して、30秒ほど待つとインデックスが作成されます。
(2)データソースの作成
③ S3やRDS/Aurora、外部サービスから独自データをAmazon Kendraに同期させるため、データソースを構成します。
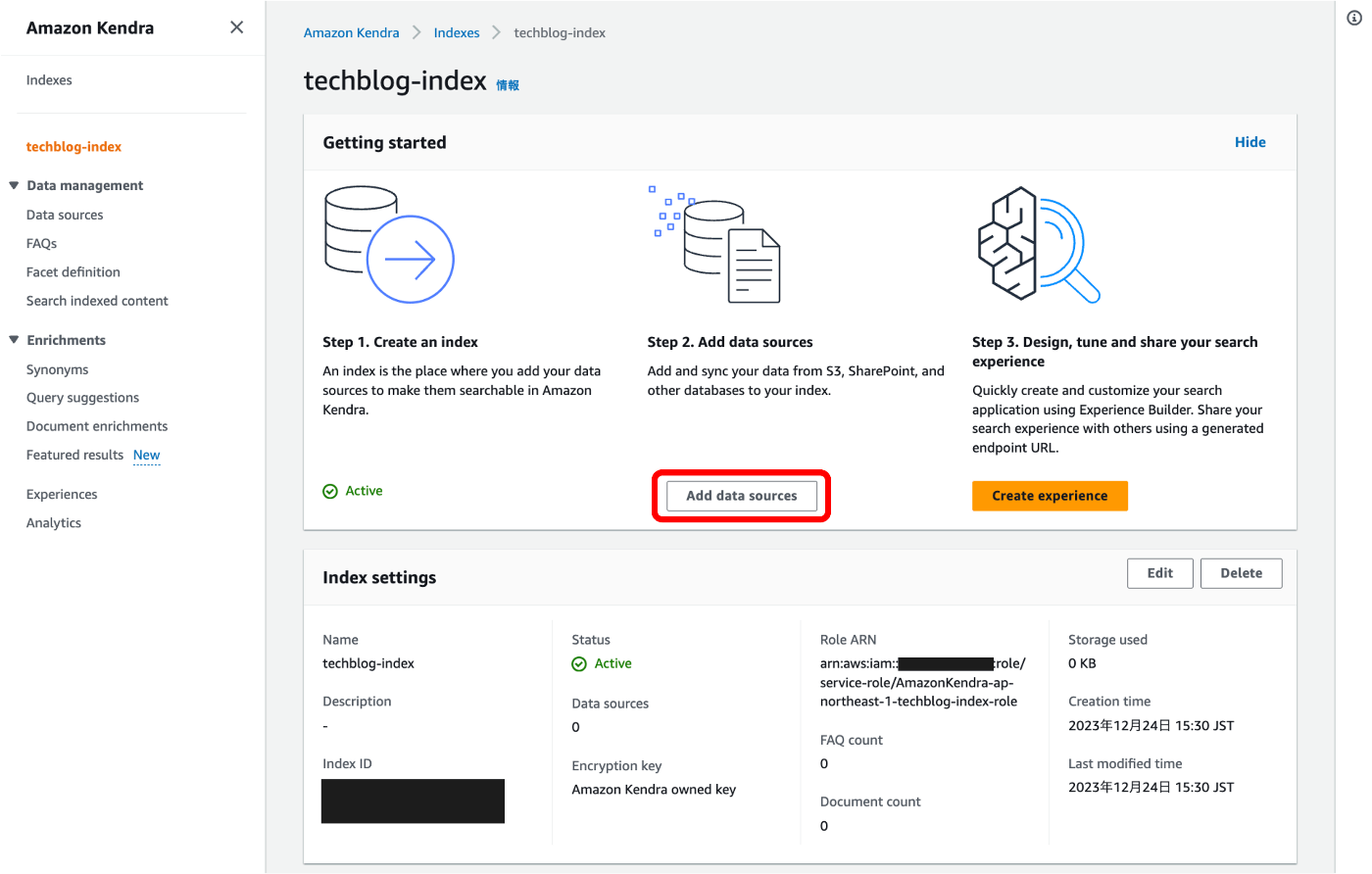
④ 今回は、S3バケットを使ってみます。

⑤ データソース名とデータソースの言語(日本語)を選択します。
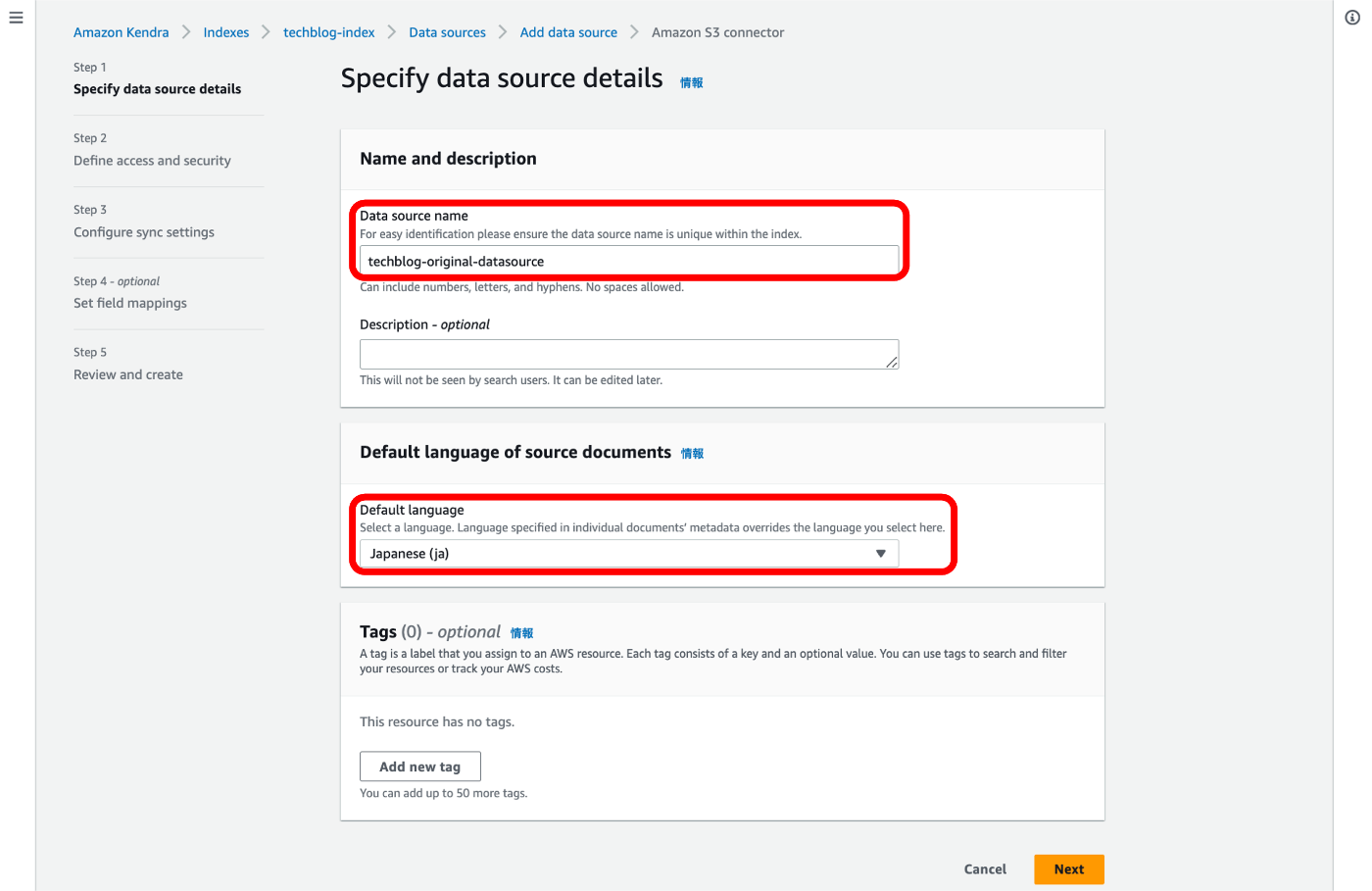
⑥ S3サービスとAmazon Kendraを連携するためのIAMロールを新規作成します。

⑦ 独自データを保管することになるS3バケットの指定とAmazon Kendraとの同期タイミングを設定します。
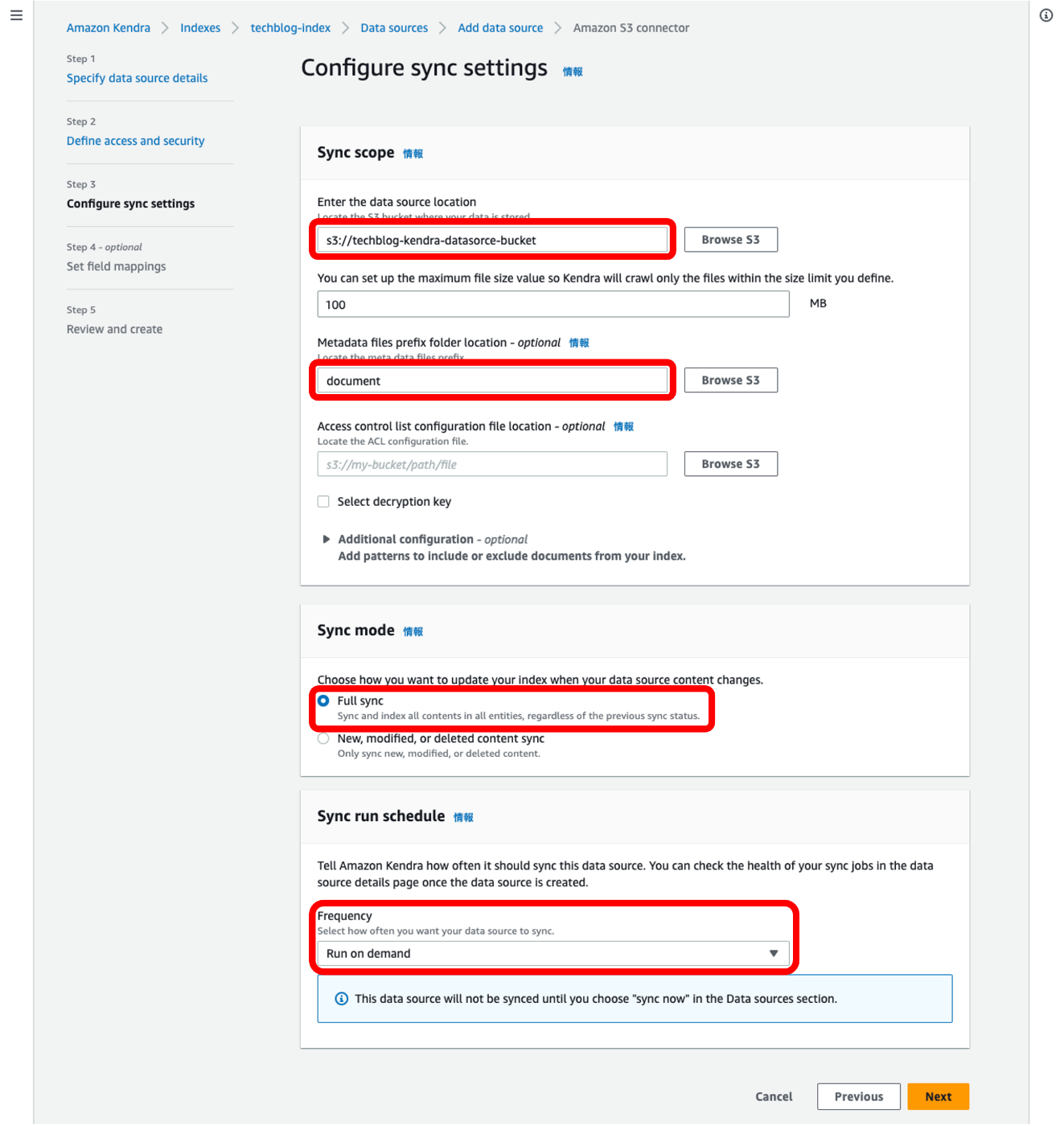
データソースの作成が完了しました。
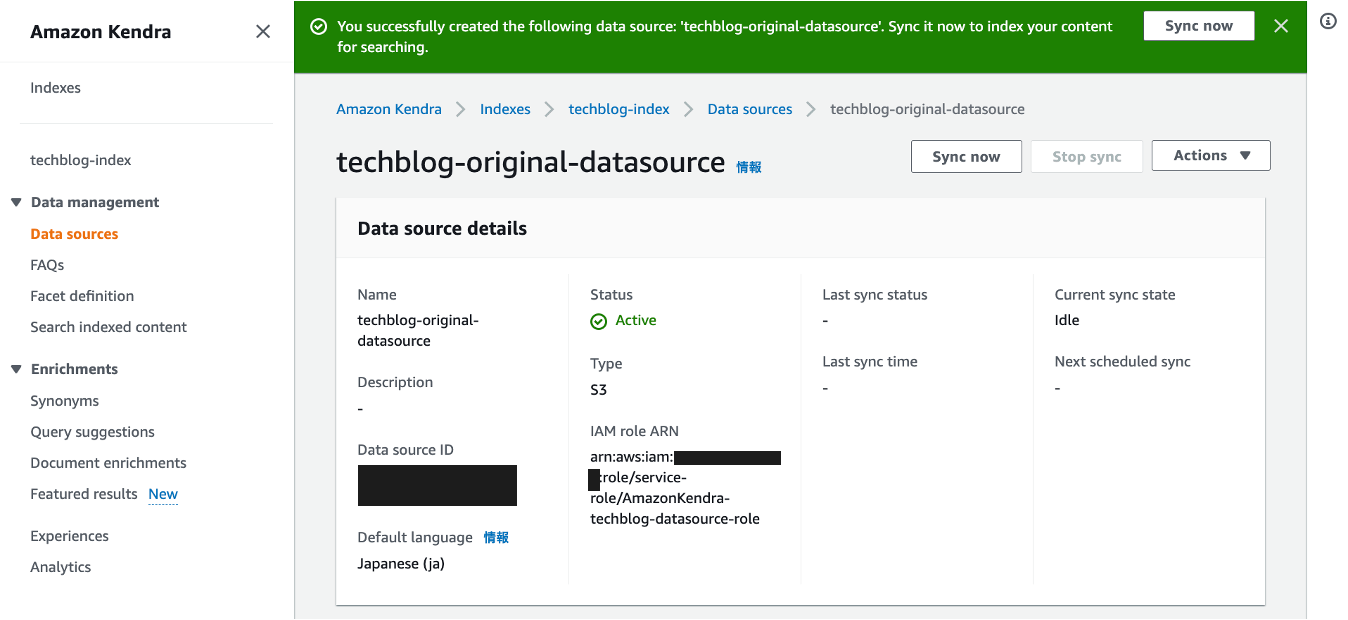
Amazon Kendraの構築は以上です。
■ Amazon Kendra に独自データをインポートする
今回の独自データは、Microsoftの「Contoso Corporation」の紹介ページを使用します。

S3バケットに評価用のPDFデータをインポートします。

Amazon KendraのデータソースとS3バケットを同期します。『Sync now』をポチッと押します。Current sync stateを確認すると、crawling(情報の読込み)とindexing(索引付け)を Amazon Kendraは実施しています。
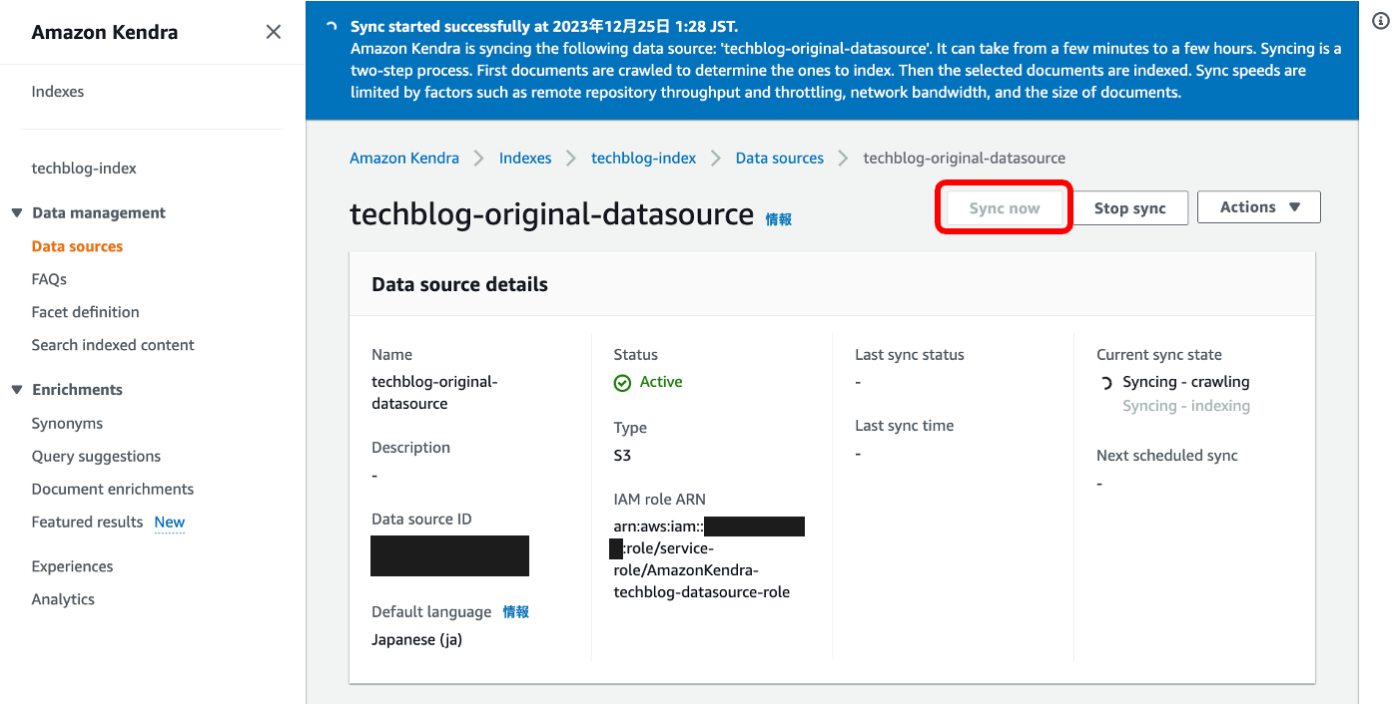
PDFファイル3枚のデータ容量で10分ほどかかりました。
■ Amazon Kendra による情報検索(AI検索)を試してみる
コンソールからSearch indexed contentを選択することでテストすることができます。
また、データソースの作成時に言語を日本語に設定したため、クエリの言語も必ず日本語に切り替えてください。
ドキュメント内の単語を使って質問してみました。
Q1. Contoso Corporationはどのような企業ですか?
A. [一部抜粋] Contoso Corporation は、パリに本社を置く多国籍企業です。 同社は、100,000 を超える製品を持つ製造、販売、およびサポート組織です。
正解ですね。抽出してほしい情報を抜き出すことに成功しました。
ドキュメント内の単語ではワーカーと表示されているが、日本語(労働者)で質問してみました。
Q2. Contoso Corporationの本社には何人の労働者がいますか?
A. [一部抜粋] サテライトオフィスには平均250⼈の労働者がいます。
これは間違いですね。本社には25,000人いるため、250人ではないです。ワーカー=労働者と認識はしてくれませんでした。
念の為、「ワーカー」に置換して質問してみました。
Q3. Contoso Corporationの本社には何人のワーカーがいますか?
A. [一部抜粋] 本社には 25,000 ⼈のワーカーがいます。
正解です。
最後に企業全体の労働者を計算させてみます。
Q4. Contoso Corporationに所属するHeadquarters、地域ハブ、およびサテライトオフィスのワーカーの総数は何人ですか?
A. 回答不能
コンテンツ情報の悪い可能性がありますが、複雑な質問はダメなようです(AIでどうにかしてくれないかな・・・)。
■ 最後に
最後まで読んでいただき、大変ありがとうございます。
Amazon Kendraを試してみた結果、1つのデータソースを使用する場合、SharePointやTeamsなどの検索機能と同様の機能があることがわかりました。複数のデータソースを組み合わせることで、より高い精度の情報検索が可能だと思いますが、調整や検証には時間がかかるかもしれません。
完全一致する単語で検索するのであれば、有能なので割り切って利用しようかな。
Discussion