生成AI×ノーコード|AWS Chatbotを利用して、SlackチャットからAmazon Bedrockに質問してみた
SlackとMicrosoft Teams(Teams) のチャットチャンネルからAWS Chatbot(Chatbot)を利用して「Agents for Amazon Bedrock」を実行できるようになりました。
このアップデート以前は、SlackなどのSaaSからAmazon BedrockへのAPIリクエストを可能にするために、LambdaやECSなどをAPIサーバとして、独自のプログラムファイルを用意する必要がありました。
今回のアップデートによって、その役割をChatbotで実装できるようになり、"ノーコードで導入できる"ようになりました。
規模にもよりますが、コード管理しなくていいのは最大の利点です。
このアップデートでは、Amazon BedrockのAIエージェント機能を使用します。これにより、学習済みのLLMの利用だけでなく、RAG(社内文書の読み込み)やファインチューニング(応答の調整)の設定もマネジメントコンソールから簡単に操作できるようになりました。
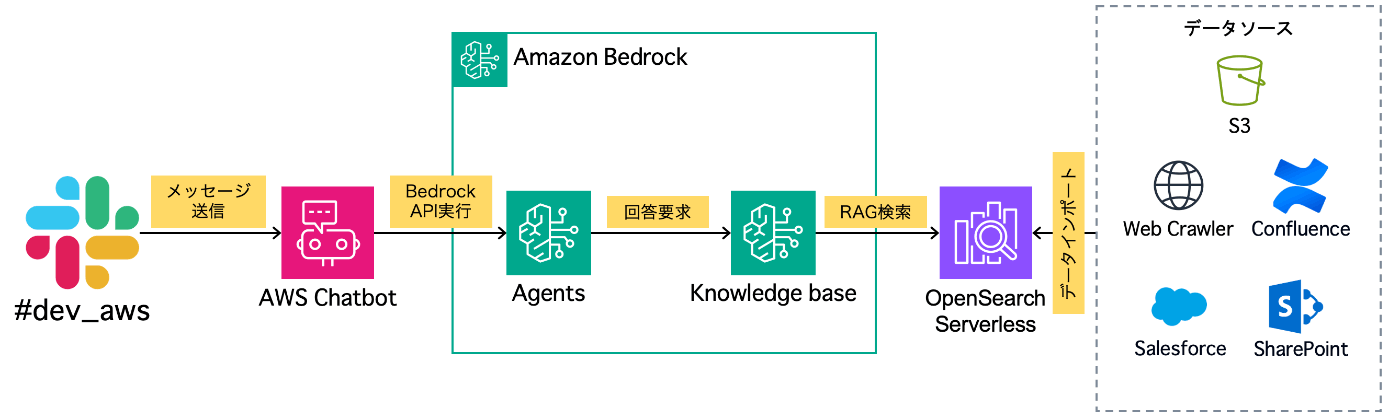
本ブログで紹介する全体構成
本ブログで紹介するデータソースは「S3」にします。
前提条件
- Slack ワークススペース を用意すること
- AWSアカウントを用意し、下記の要件を満たしてください
- Amazon Bedrock(Bedrock)でLLMを利用できること
本ブログでは、「東京リーション」を利用しています。
やってみた
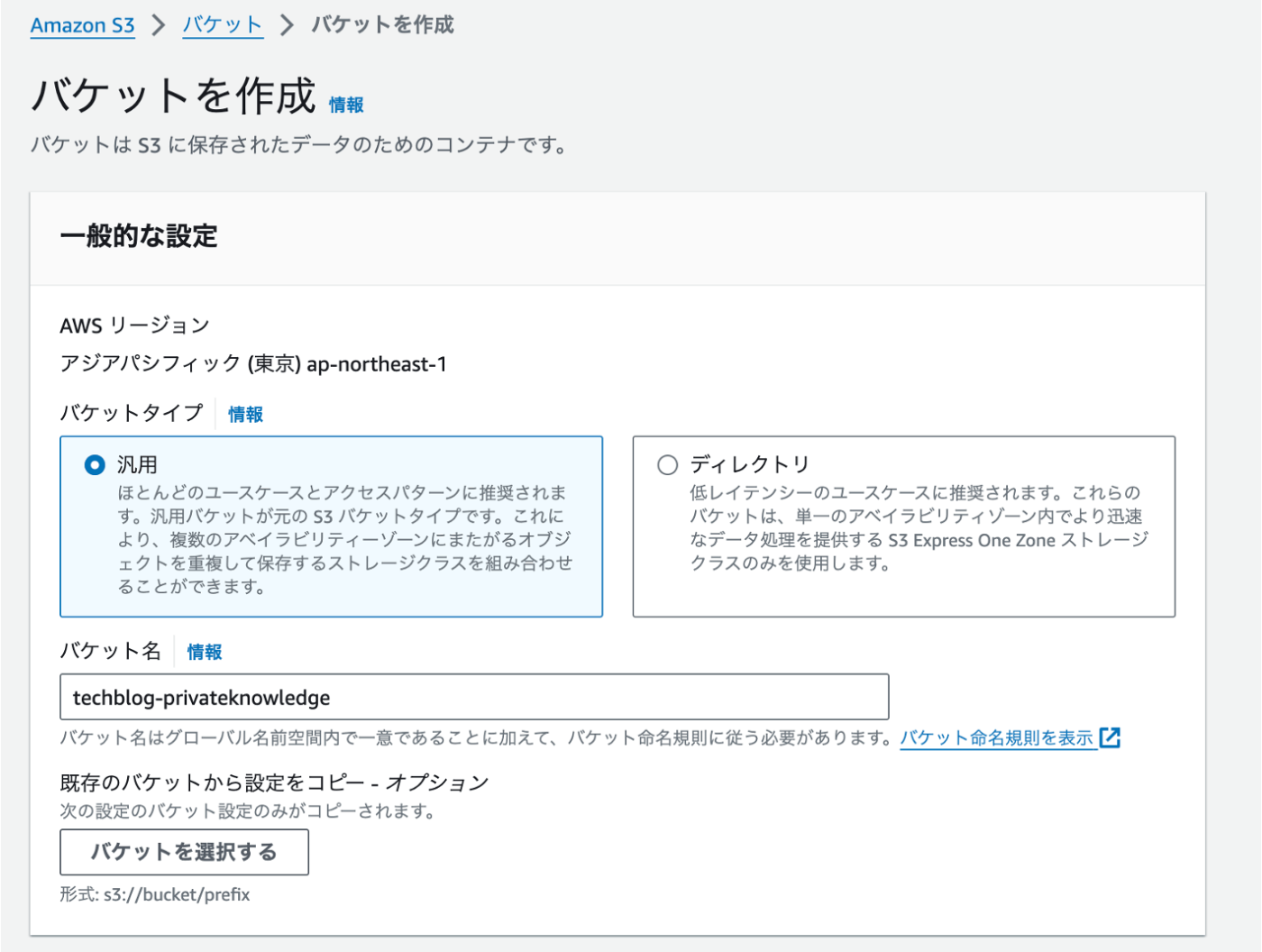
1. Amazon S3の作成
本ブログでは、Slack上に独自ファイルに記載した情報を出力させるためにS3バケットを用意します。
S3バケットの設定値は、バケット名のみを記載しています。後はデフォルト値です。
本ブログでは、テストデータとして「架空のシステム要件定義書」を利用します。
下記のテキストをコピーして、テキストエディタなどでテキストファイルを作成してください。
今回は、Wordファイル(dummyPj-(架空)オンライン予約システム要件定義書.docx)にしました。
(架空)オンライン予約システム要件定義書
(架空)オンライン予約システム要件定義書
1. はじめに
1.1 目的
本文書は、Microsoft Azureクラウドプラットフォームを活用したオンライン予約システムの要件を定義することを目的とする。
1.2 システム概要
本システムは、様々な業種で利用可能な柔軟なオンライン予約システムであり、Azureのクラウドサービスを最大限に活用して構築される。
2. システムアーキテクチャ
2.1 全体構成
- フロントエンド:Azure Static Web Apps
- バックエンド:Azure Functions (サーバーレス)
- データベース:Azure Cosmos DB
- 認証:Azure Active Directory B2C
- キャッシュ:Azure Cache for Redis
- ストレージ:Azure Blob Storage
- CDN:Azure Content Delivery Network
3. 機能要件
3.1 ユーザー管理機能
3.1.1 ユーザー登録・認証
- Azure Active Directory B2Cを使用
- ソーシャルIDプロバイダー連携(Microsoft, Google, Facebook)
- 多要素認証(MFA)のサポート
3.1.2 ユーザープロフィール管理
- Azure Cosmos DBでユーザープロフィールデータを管理
- Azure Blob Storageでユーザーアバター画像を保存
3.2 予約機能
3.2.1 予約作成・管理
- Azure Functionsで予約ロジックを実装
- Azure Cosmos DBで予約データを保存
- Azure Cache for Redisで頻繁にアクセスされる予約情報をキャッシュ
3.2.2 空き状況確認
- Azure Functions経由でリアルタイムの空き状況を取得
- SignalRサービスを利用したリアルタイム更新
3.3 管理者機能
3.3.1 予約管理ダッシュボード
- Azure Application Insightsを利用した利用統計の表示
- Power BIとの連携によるデータの可視化
3.3.2 レポート生成
- Azure Logic Appsを使用した定期的なレポート生成と配信
4. 非機能要件
4.1 性能要件
- ページロード時間:2秒以内(Azure Front Door使用)
- API応答時間:200ms以内
- 同時接続ユーザー数:最大10,000人
4.2 可用性要件
- 稼働率:99.99%以上
- Azure Availability Zonesを利用した冗長構成
- Azure Traffic Managerによるグローバルロードバランシング
4.3 セキュリティ要件
- Azure DDoS Protectionによる保護
- Azure Key Vaultでの機密情報管理
- Azure Security Centerによる脅威検出と防御
4.4 拡張性要件
- Azure Auto Scaleを利用した自動スケーリング
- マイクロサービスアーキテクチャの採用(Azure Kubernetes Service)
4.5 バックアップと災害復旧
- Azure Backup使用
- 地理冗長ストレージ(GRS)の利用
- Azure Site Recoveryによる災害復旧計画
5. 開発・運用環境
5.1 開発環境
- Azure DevOpsでのソース管理とCI/CD
- Azure Kubernetes Serviceを使用した開発・ステージング環境
5.2 監視・ロギング
- Azure Monitorによる総合的な監視
- Azure Log Analyticsでのログ分析
- Azure Application Insightsによるアプリケーション監視
5.3 コスト管理
- Azure Cost Managementによるコスト最適化
- リソースタグ付けによる部門別コスト管理
6. コンプライアンスと規制対応
- Azure Complianceを活用したGDPR、HIPAA等への対応
- Azure Information Protectionによるデータ保護とガバナンス
7. コスト見積もり
- 初期構築コスト:¥2,000,000
- 月額運用コスト:¥250,000(予測値)
- Azure Calculator使用によるコスト最適化
8. プロジェクトスケジュール
| フェーズ | 期間 |
|---|---|
| 1. 要件定義・設計フェーズ | 4週間 |
| 2. 開発フェーズ | 12週間 |
| 3. テストフェーズ | 4週間 |
| 4. 移行・展開フェーズ | 2週間 |
| 5. 運用開始・安定化フェーズ | 4週間 |
合計:26週間(約6ヶ月)
9. リスク管理
| リスク | 対策 |
|---|---|
| Azureサービスの仕様変更 | 定期的な情報収集と迅速な対応 |
| コスト超過 | Azure Cost Managementによる継続的な監視と最適化 |
| セキュリティ脅威 | Azure Security Centerを活用した常時監視と対策 |
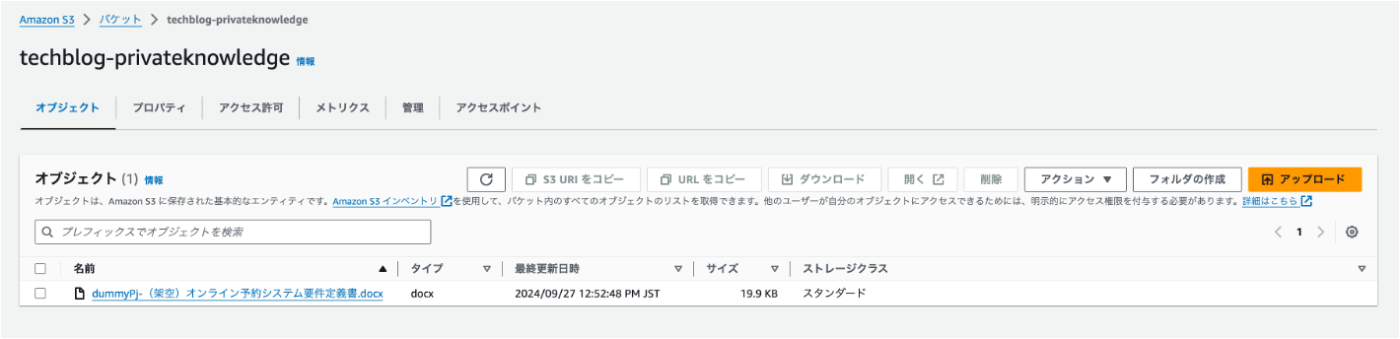
S3バケットにインポートします。
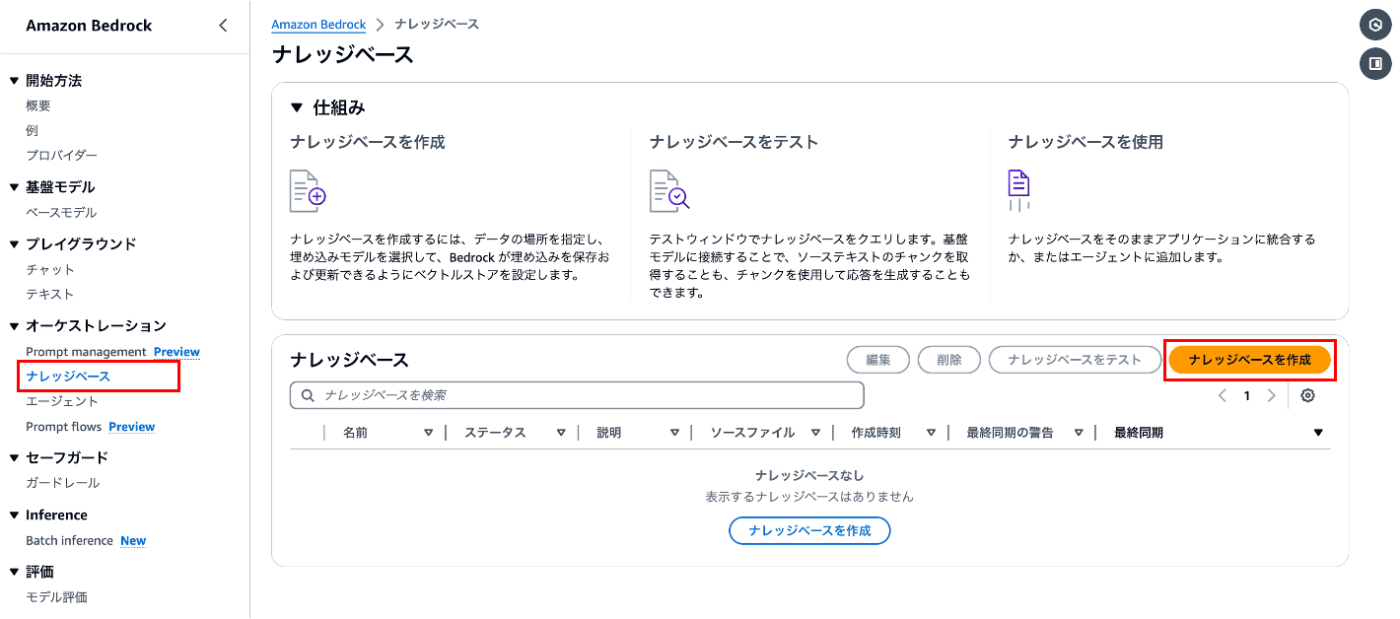
2. Knowledge Base for Amazon Bedrockの作成
上記で用意した独自ファイルの内容をBedrockへ学習させるために、Knowledge Base(ナレッジベース)を作成します。
Amazon Bedrock コンソールにアクセスして、「ナレッジベースを作成」ボタンを押下します。
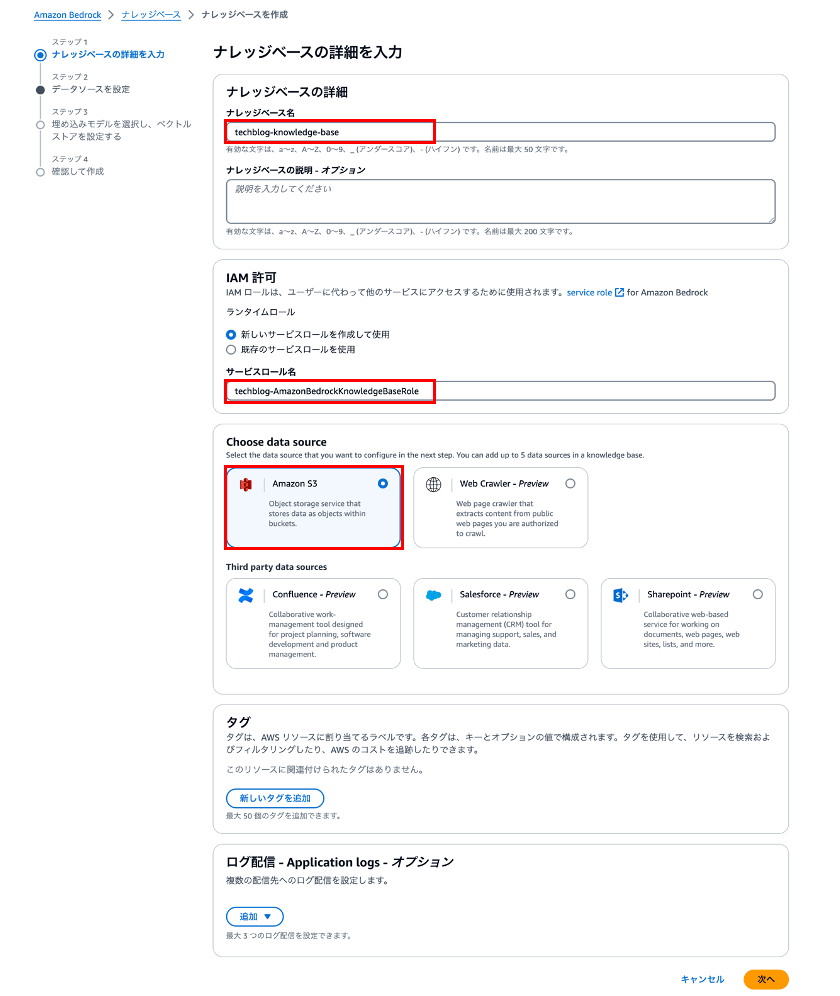
① ナレッジーベースの詳細を入力
ナレッジーベース名やサービスロールなどの項目を記入します。
| 項目 | 設定値(例) |
|---|---|
| ナレッジベース名 | techblog-knowledge-base |
| サービスロール名 | techblog-AmazonBedrockKnowledgeBaseRole |
| Choose data source | Amazon S3 |
<余談>
以前、サービスロール名には「AmazonBedrockExecutionRoleForKnowledgeBase_」を分頭に付ける必要がありましたが、現在は不要になったようです。
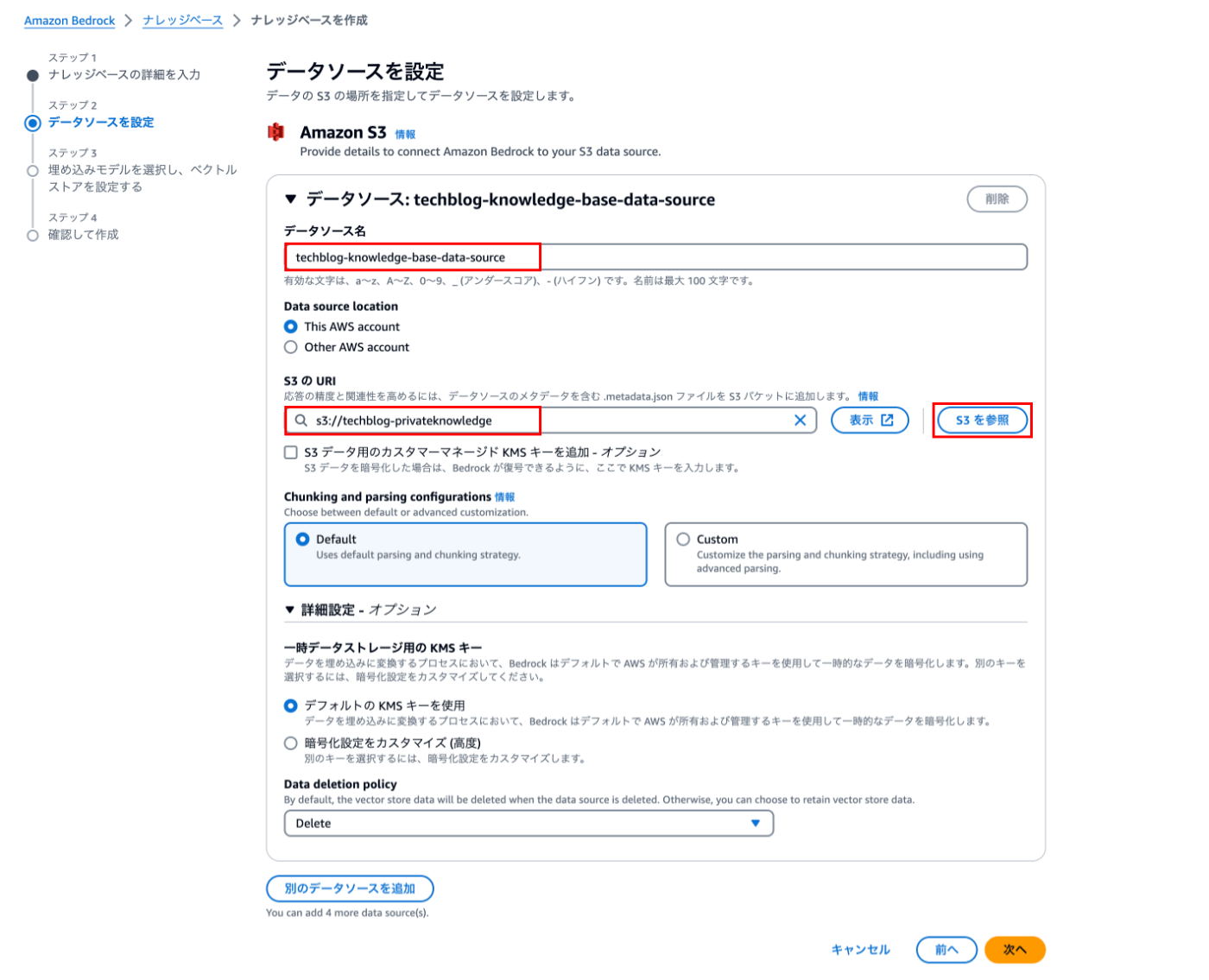
② データソースを設定
データソース名や(S3バケットを利用)格納したS3バケットorS3オブジェクトを定義します。
| 項目 | 設定値(例) |
|---|---|
| データソース名 | techblog-knowledge-base-data-source |
| Data source location | This AWS Account |
| S3のURI | 「S3を参照」から選択 |
③ 埋め込みモデルを選択し、ベクトルストアを設定する
テキストデータを機械学習できる媒体にするために、高次元空間にフォーマットする必要があります。
「ベクトルの次元」の数が大きいほど、回答の精度が向上します。ただし、計算コストが増大するため、コンピューティング性能(高コスト)を求められます。
検証目的で安く抑えたい場合は、Pinecone をご利用ください。本ブログではセットアップが簡単なAmazon OpenSearch Serverlessで紹介します。
| 項目 | 設定値(例) |
|---|---|
| 埋め込みモデル | Titan Embeddings G1 |
| ベクトルデータベース |
新しいベクトルストアをクイック作成⭐️すぐ削除するのであればオススメ(1AZ構成で1日あたり8ドルかかる) |
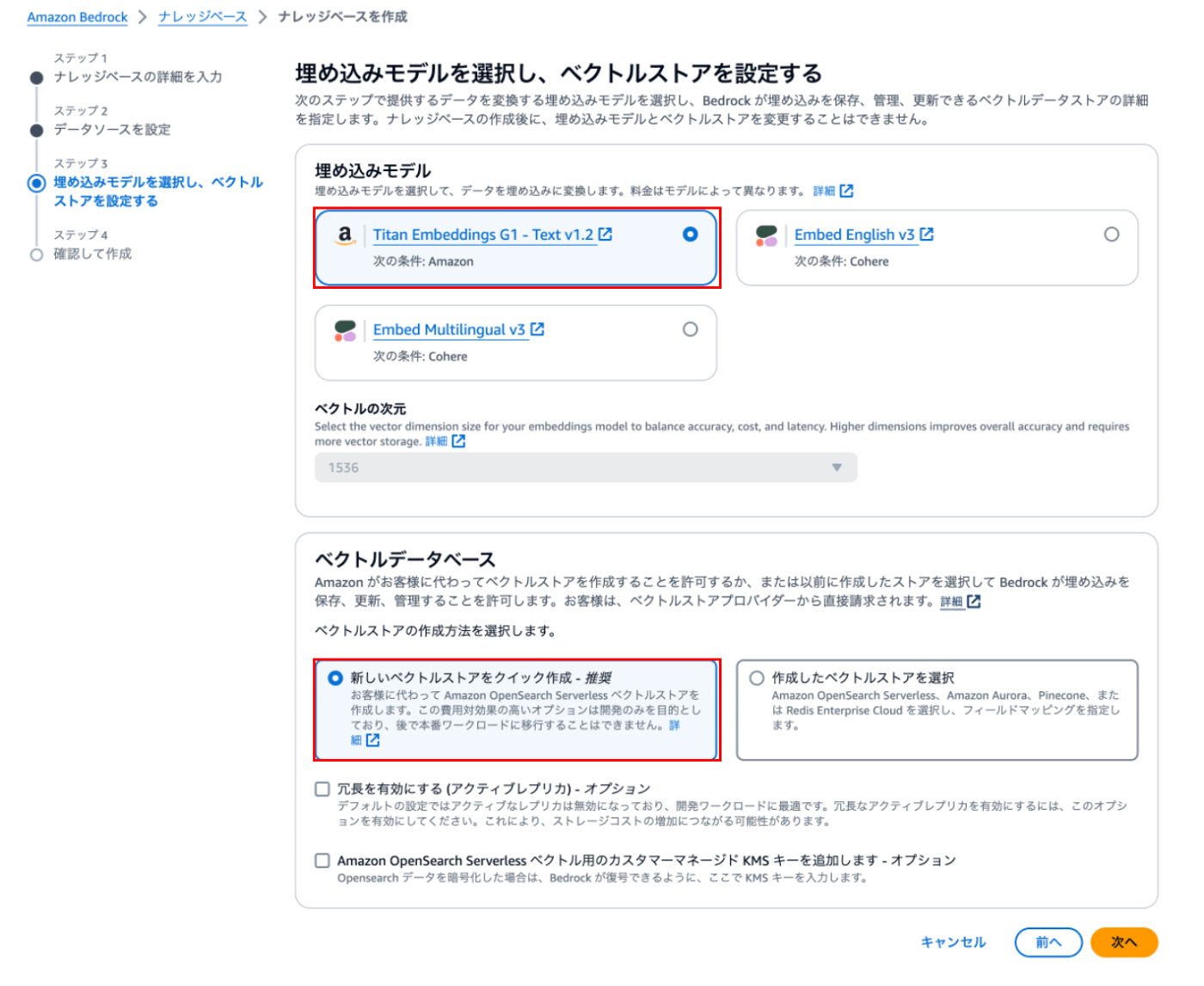
後は、リソースの設定確認をして作成します。5~7分ほどで作成されます。
3. Agents for Amazon Bedrockの作成
上記で学習させたナレッジベースを利用するために Agents for Amazon Bedrock(エージェント)、いわゆる「自律型AIエージェント」を作成します。利用者が「〇〇して」と命令したことに対して、このエージェントがBedrock内部で自律して働いてくれます。
同様に「エージェントを作成」ボタンを押下します。
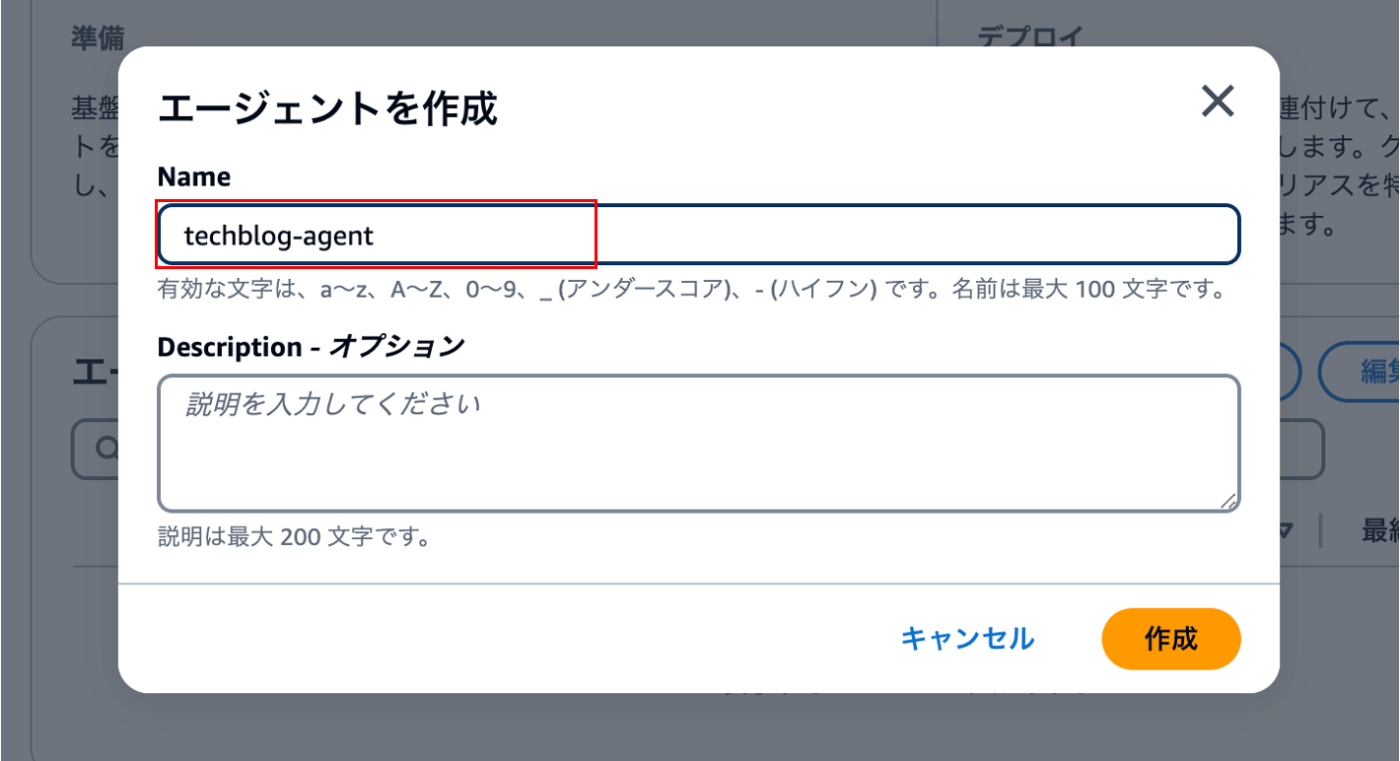
① エージェントの作成
エージェント名を記入して、作成します。
| 項目 | 設定値(例) |
|---|---|
| Name | techblog-agent |
② エージェントの詳細設定 - リソースロールの割り当て
エージェント用のLLMを設定します。
「エージェントリソースロール」とは、エージェントがBedrockの機能や他のAWSリソースを操作するために必要なロールです。新規作成または既存のロールを割り当てる必要があります。
※新規作成する場合、ナレッジベースを追加することはまだできません。③の手順で設定できます。
また、「エージェント向けの指示」を定義する必要があります(これ必要ですかね?)。
下記の指示をコピペします。
期待される成果物を明確に回答してください。
虚偽の情報を回答することは認められません。
出力フォーマットは、以下の条件を設けます。
・読みやすい文章にしてください
・箇条書きや改行を利用してください
| 項目 | 設定値(例) |
|---|---|
| エージェント名 | techblog-agent |
| エージェントリソースロール | 新しいサービスロールを作成して使用 |
| モデルを選択 |
Anthropic/Claude 3.5 Sonnet
|
| エージェント向けの指示 | 上記をコピペする |
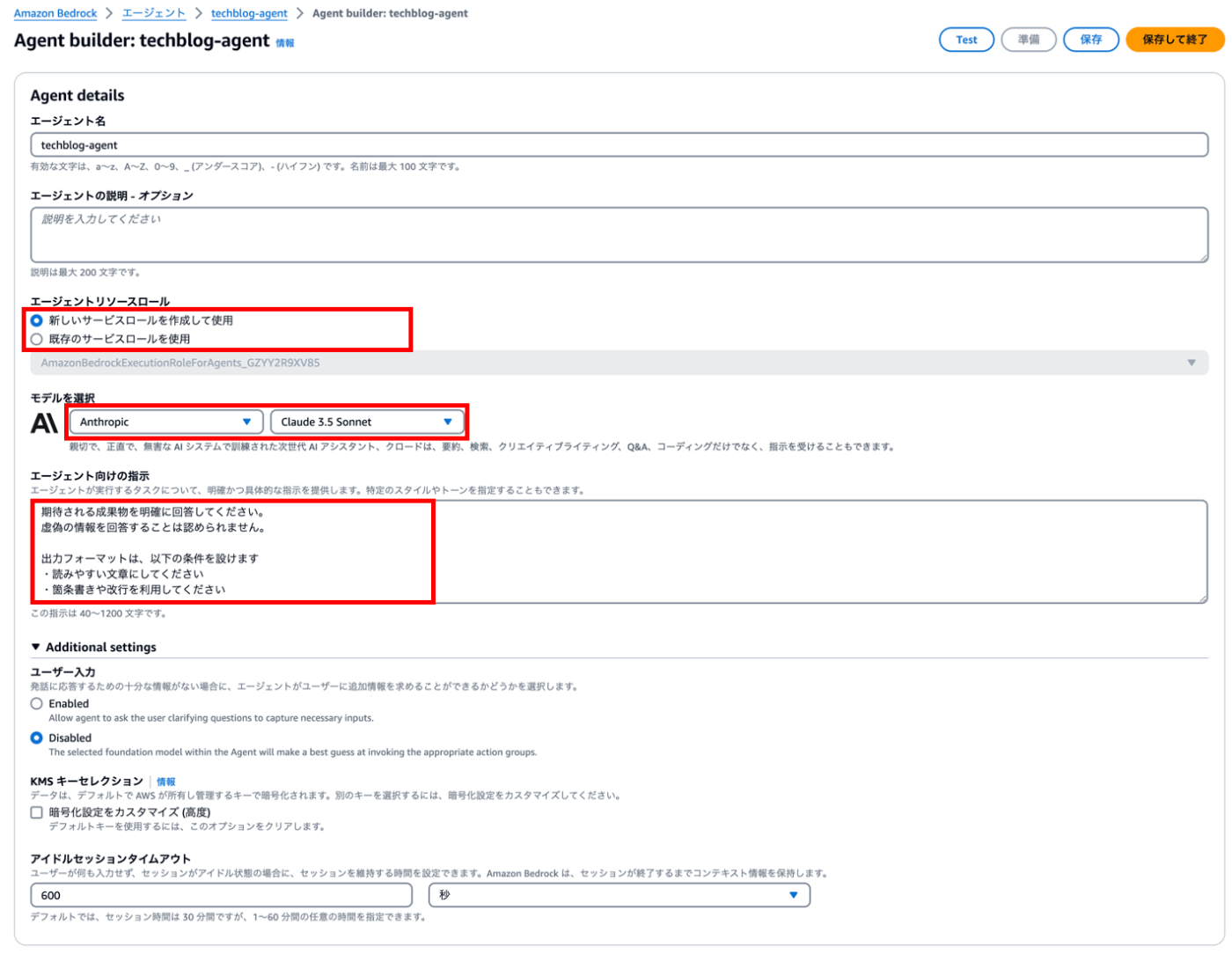
この状態で右上の「保存」を押下します。
③ エージェントの詳細設定 - ナレッジベースの設定
②のあと、エージェントにナレッジベースを登録します。
「Edit in Agent Builder」を押下します。
追加していきます。
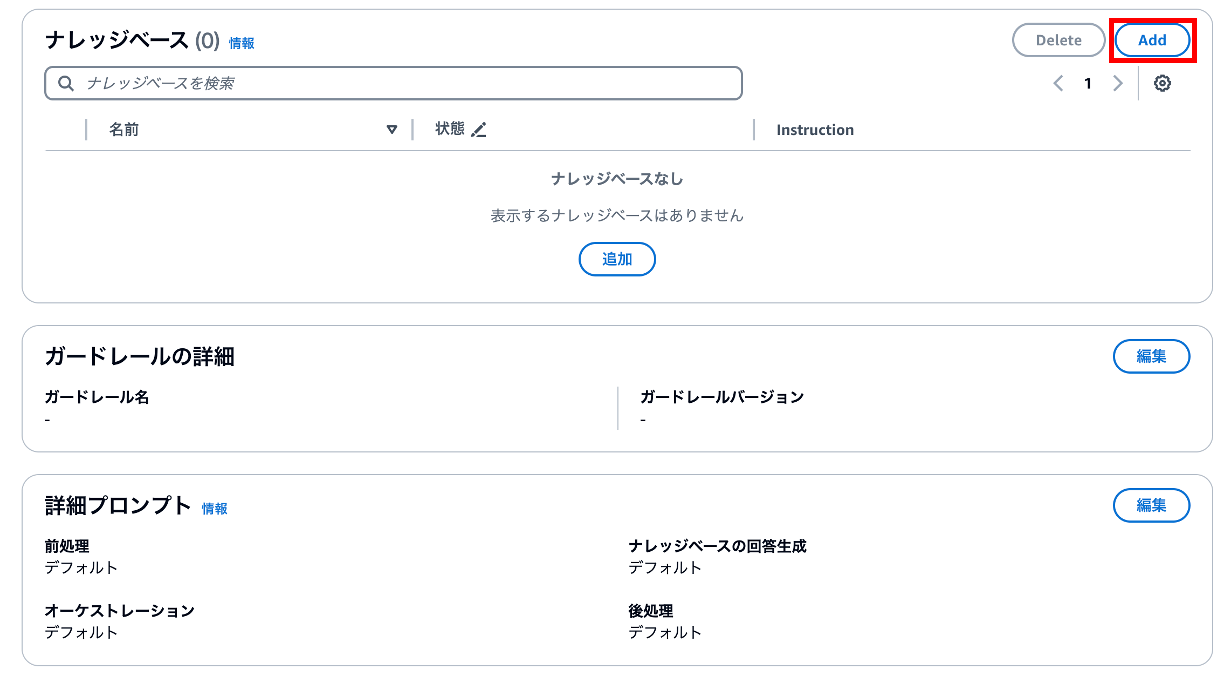
作成したナレッジベースを選択して、追加します。
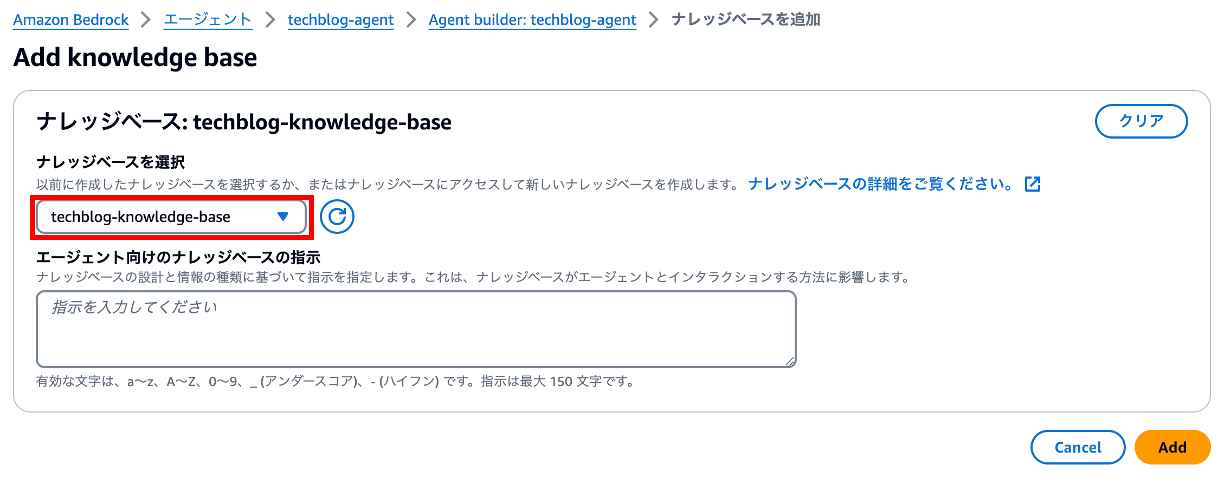
「ENABLED」になっていればOKです。

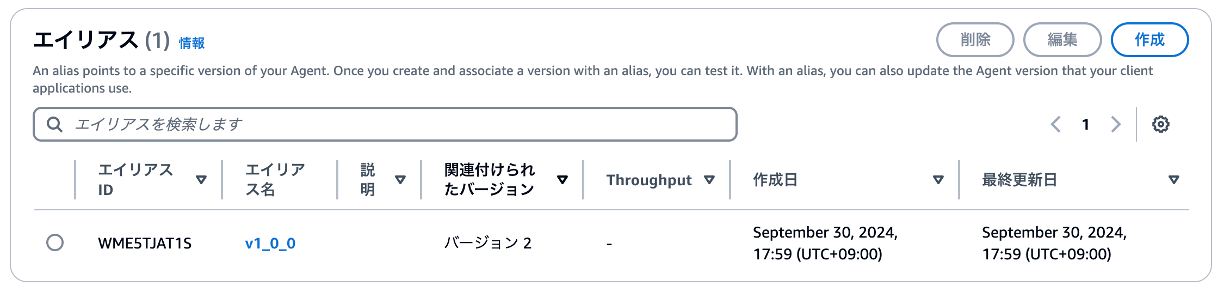
④ エイリアスバージョンの作成
最終的にChatbotコネクタを登録するコマンドをSlack上で実行するのですが、エージェントのエイリアスIDが必要になるので作成していきます。「作成」を押下します。
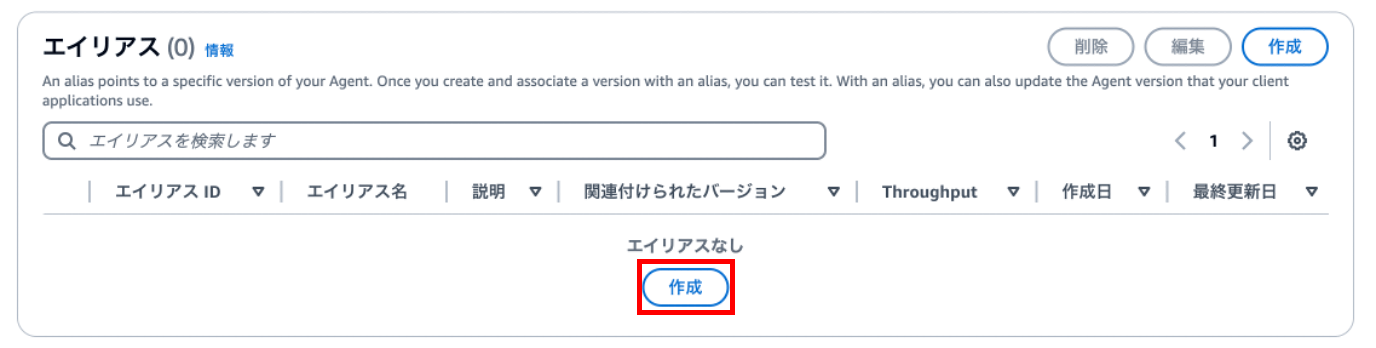
下記の設定値を定義します。
| 項目 | 設定値(例) |
|---|---|
| エイリアス名 | v1_0_0 |
| バージョンを関連付ける | 新しいバージョンを作成し、このエイリアスに関連付けます。 |
⑤ エージェントのARN をメモする
ARN ← これなんて読むんでしょうね?僕は「あらーん」と読んでいます。
メモってください。5. SlackとChatbotコネクタの接続 で使用します。
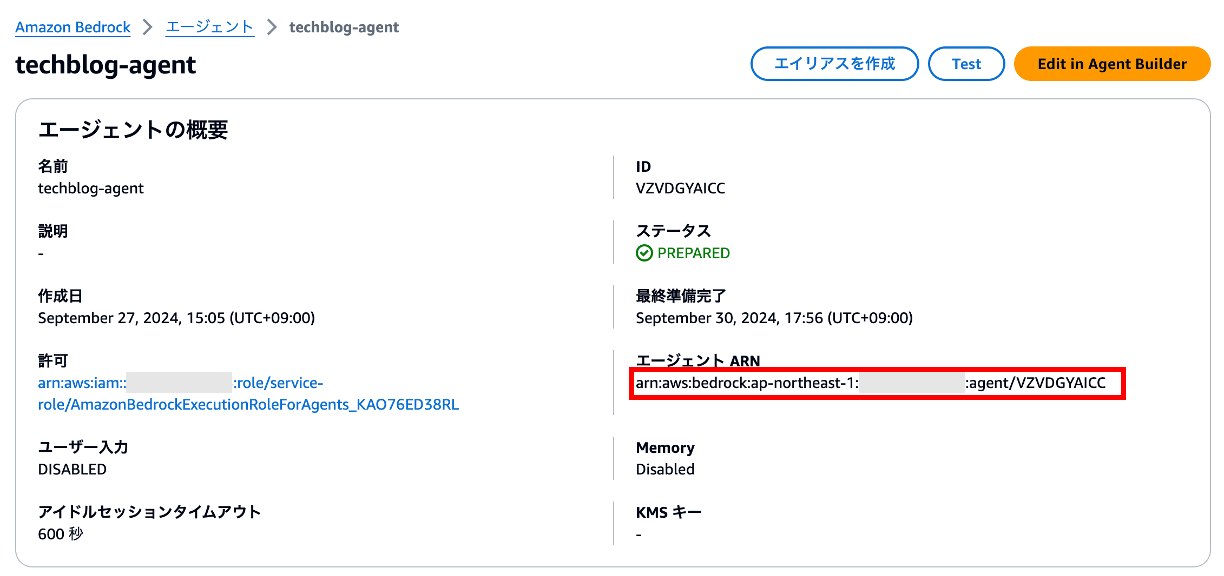
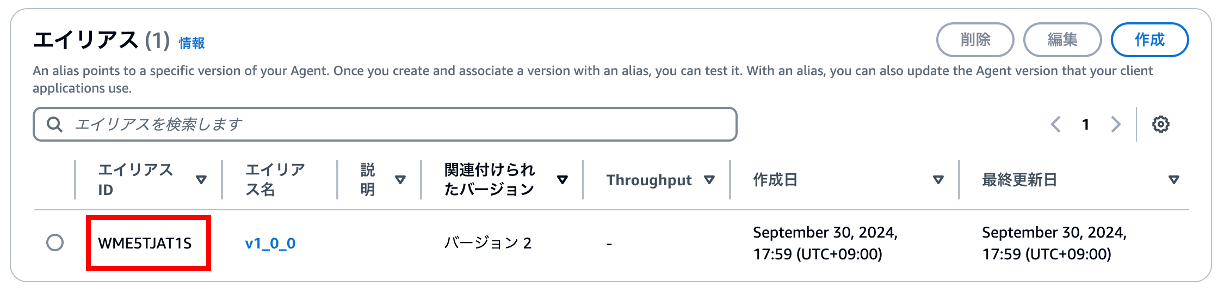
⑥ エージェントのエイリアスIDをメモする
メモってください。5. SlackとChatbotコネクタの接続 で使用します。
4. AWS Chatbotの作成+Slack連携
ChatbotとSlackを連携していきます。
AWS Chatbot コンソールにアクセスして、「チャットクライアントを設定」→「Slack」を押下します。

① Slackワークスペースとの連携
初回時はログインを求められます。ログイン後、SlackにChatbotの操作権限を要求する画面が表示されるため、「許可」します。
② ChatbotアプリとBedrock間の権限設定とチャンネル登録
次にChatbotアプリを連携したSlackに登録するため、「新しいチャネルの設定」を押下します。
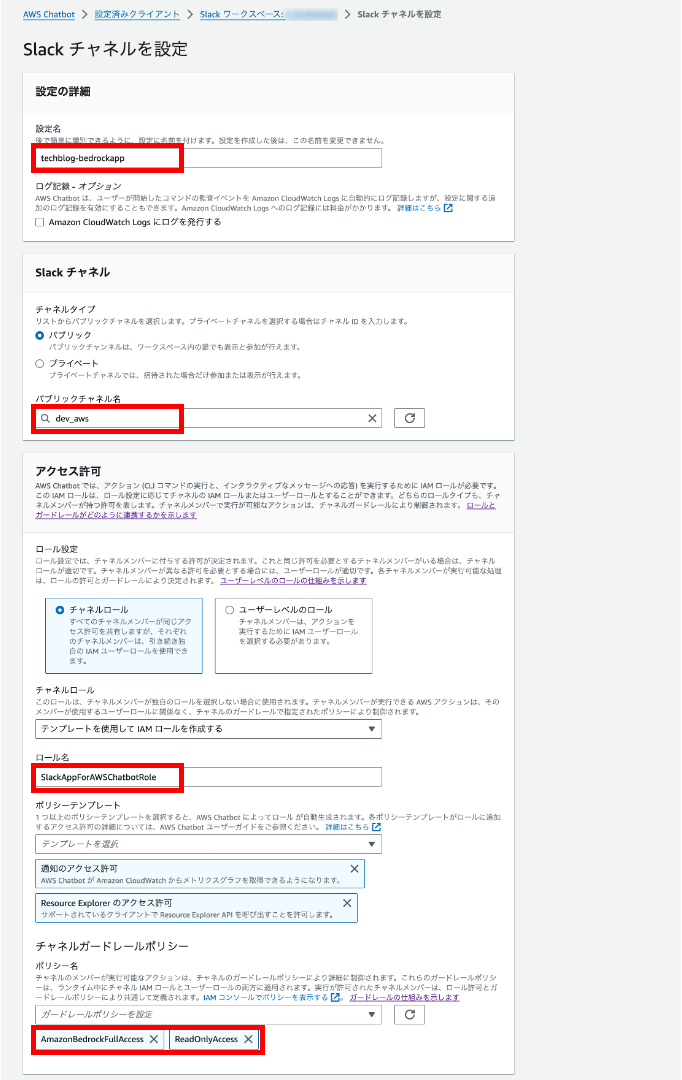
チャネルの詳細設定値を定義します。ChatbotがBedrockを呼び出す権限周りは絞りたい場合に限り、調整しましょう。Slack側のアクセスセキュリティを対策していれば、フルアクセス権限を付与してもいいと思います。
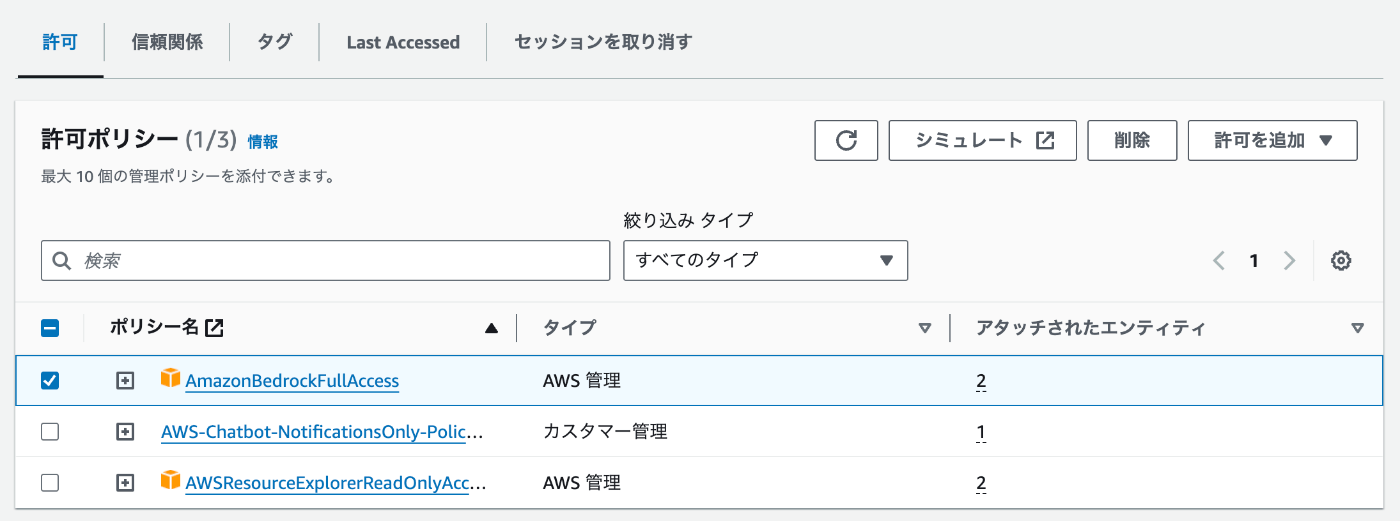
ポリシーを絞りたい場合は、下記のロールポリシーを用意して割り当ててください。この場合、AmazonBedrockFullAccessとReadOnlyAccessは不要です。
| 項目 | 設定値(例) |
|---|---|
| 設定名 | techblog-bedrockapp |
| Slack チャネル | 登録したいチャンネルを選択 |
| ロール設定 | チャネルロール |
| ロール名 | SlackAppForAWSChatbotRole |
| ポリシー名 |
AmazonBedrockFullAccess, ReadOnlyAccess
|
③ チャネルロールに信頼ポリシーを割り当てる
「チャネルロール」を押下します。
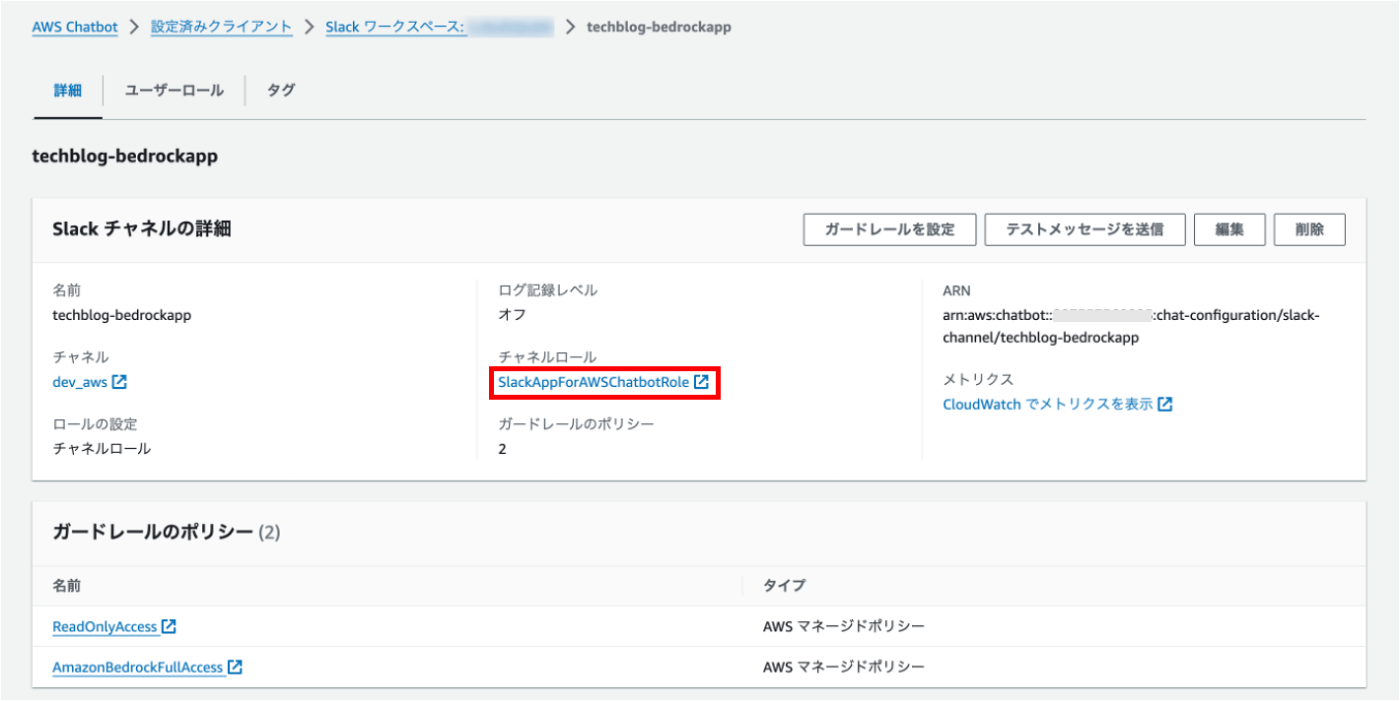
「AmazonBedrockFullAccess」を追加します。
ちなみに許可ポリシーを追加しないと下記のようなエラーが出ます。
User: arn:aws:sts::<AWSアカウントID>:assumed-role/SlackAppForAWSChatbotRole/chatbot-session-slack-<SlackID> is not authorized to perform: bedrock:InvokeAgent on resource: arn:aws:bedrock:ap-northeast-1:<AWSアカウントID>:agent-alias/VZVDGYAICC/WME5TJAT1S because no identity-based policy allows the bedrock:InvokeAgent action (Service: BedrockAgentRuntime, Status Code: 403, Request ID: 20a54d43-e295-4316-824b-6452b53e6b93)
5. SlackとChatbotコネクタの接続
いよいよ、Slack上でBedrockを呼び出すためのコネクタをSlackに登録します。
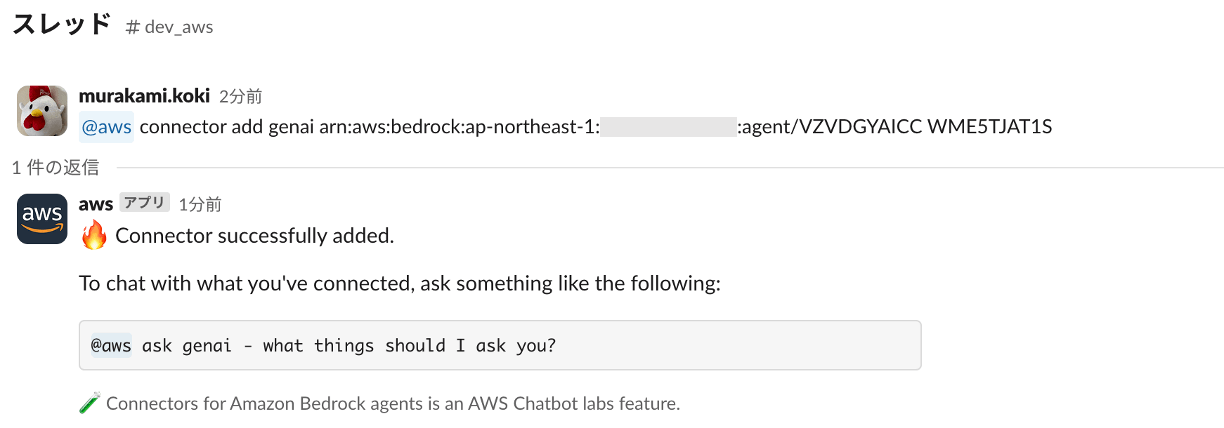
@aws connector add <呼び出すときのエイリアス> arn:aws:bedrock:ap-northeast-1:<AWSアカウントID>:agent/<エージェントID(メモ)> <エイリアスID(メモ)>
@aws connector add genai arn:aws:bedrock:ap-northeast-1:<AWSアカウントID>:agent/VZVDGYAICC WME5TJAT1S
実行後、「🔥 Connector successfully added.」と返ってきたら成功です!
つかってみた
使用するときも簡単です。
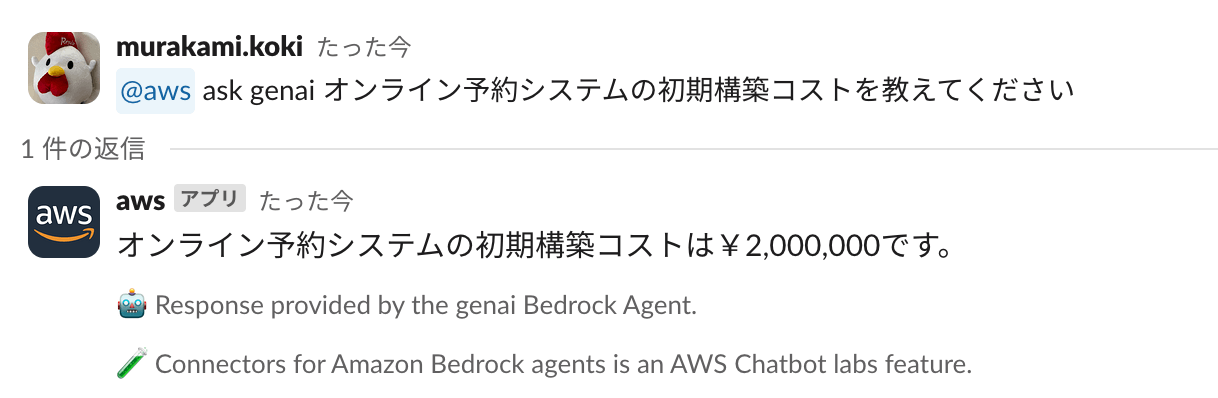
@aws ask <エイリアス> <質問内容>
@aws ask genai オンライン予約システムの初期構築コストを教えてください
当たっていますね👍
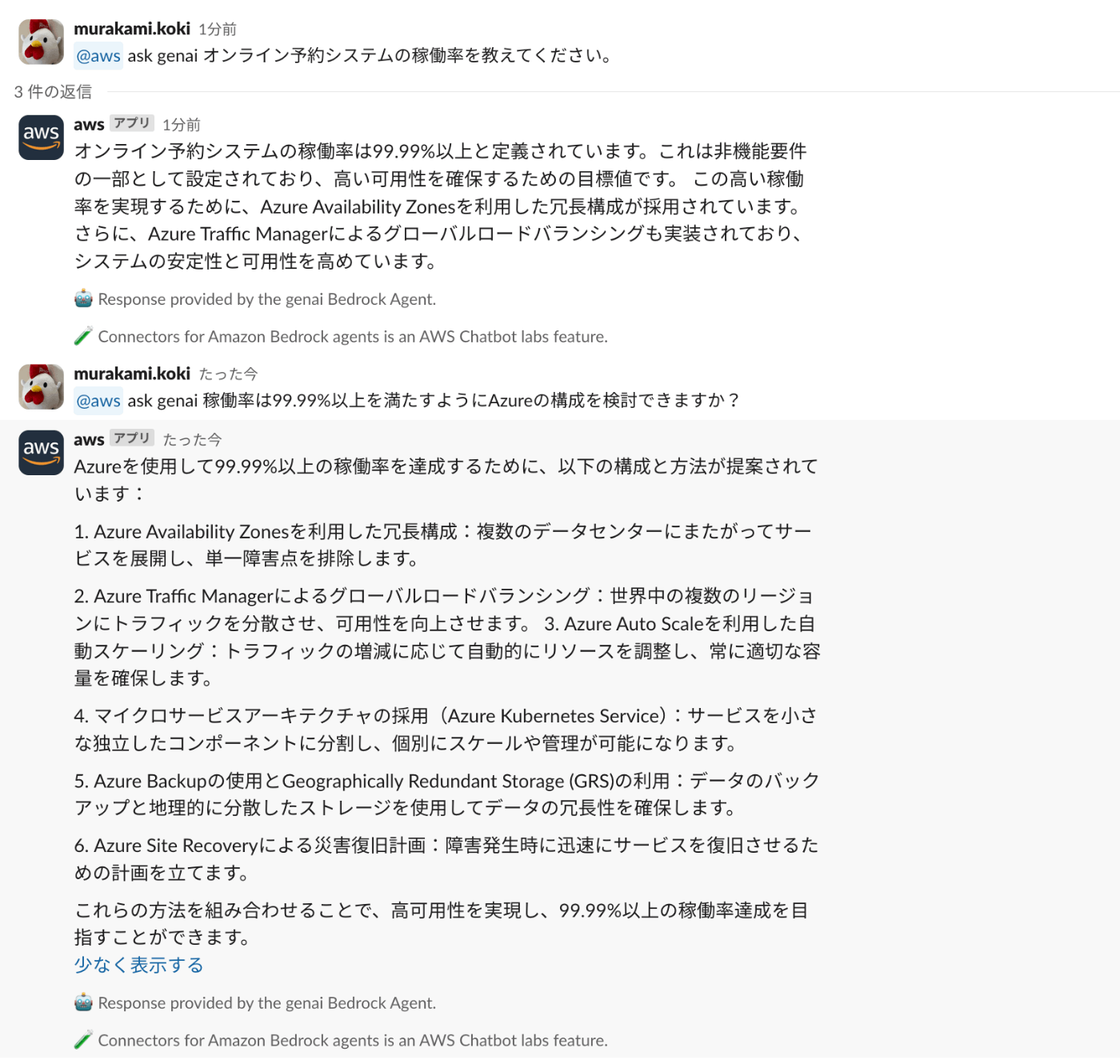
@aws ask genai オンライン予約システムの稼働率を教えてください。
@aws ask genai 稼働率は99.99%以上を満たすようにAzureの構成を検討できますか?
(個人的に物足りない気もしますが...)要件に合わせて構成提案できていますね👍
条件を追加したり、Azureの高可用性アーキテクチャを学習させたりすることで精度を高めれそうですね
Discussion