whisper.cppがいつのまにかmacOS用文字起こしの決定版になっていた
whisper.cppの進化が止まらない
OpenAIのWhisperオープンソース公開は文字起こし界隈に衝撃を与えました
whisper.cppは本家Whisperのリリース後早い段階で公開された派生物で、非GPU環境においてそれなりのメモリ消費量・速度で動作する特徴がありましたが、そのリリースから1年のうちに実はwhisper.cppはかなりのスピードで進化しており当時とはもはや別物になっています
とくにApple Silicon Mac / macOS上での動作速度がこの1年間で大きく向上しました
現代のコンピューター上でTransformer系のような大規模計算をする場合、CPUによる汎用演算にとどまらず搭載された各種アクセラレータをいかに使い倒せるかが重要で、whisper.cppはその名前からCPU側へ偏った実装という印象を(なぜか)受けますが
- ArmのNEONやIntelのAVXなどCPU上のベクター命令
- AppleのGPU用MPS(Metal Performance Shaders)
- NVIDIAのGPU用CUDA(cuBLAS経由)
- Core ML
を広くサポートしています
Mac/macOSに特化したトピックとしては、これらの中でも9月半ばにMetalサポートが取り込まれて大きなパフォーマンス面のジャンプがありました
11月半ばにmergeされたGPU利用範囲拡大によってEncoder部分のパフォーマンスがさらに伸びました
今回は執筆時点の最新リリースであるv1.5.1にてこれらの効果を確認してみます
パフォーマンステスト
約38分の講演音声という長めのファイルを利用した文字起こし速度の検証をしてみます
このサンプルの利用は下記のテスト記事にならったものです
デフォルト版(Metal)とCore ML対応版(Core ML + Metal)をそれぞれ一回実行して所要時間をtimeコマンドとwhisper.cpp内部のstat情報の両面から確認します
実行環境
- M1 Mac mini 16GB memory
- macOS Ventura 16.3.1
- whisper.cpp v1.5.1(ソースからのビルド)
非Core ML版(Accelerate Framework + Metal)
whisper.cpp % time ./main -m models/ggml-large-v3.bin -f ./test-data/input.wav
...
system_info: n_threads = 4 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | METAL
= 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | CUDA = 0 | COREML
= 0 | OPENVINO = 0 |
main: processing './test-data/input.wav' (36436381 samples, 2277.3 sec), 4 threads, 1 processors, 5 beams +
best of 5, lang = en, task = transcribe, timestamps = 1 ...
...
[00:37:45.560 --> 00:37:46.160] stuff itself.
[00:37:46.160 --> 00:37:46.960] It still works itself.
[00:37:46.960 --> 00:37:47.820] So, yeah.
[00:37:47.820 --> 00:37:54.880] Cool.
[00:37:54.880 --> 00:37:55.600] Yeah, thank you.
[00:37:55.600 --> 00:37:56.440] Thank you.
whisper_print_timings: load time = 9374.04 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 1493.89 ms
whisper_print_timings: sample time = 127299.16 ms / 81031 runs ( 1.57 ms per run)
whisper_print_timings: encode time = 228381.83 ms / 80 runs ( 2854.77 ms per run)
whisper_print_timings: decode time = 1340.59 ms / 28 runs ( 47.88 ms per run)
whisper_print_timings: batchd time = 1085236.00 ms / 80760 runs ( 13.44 ms per run)
whisper_print_timings: prompt time = 34772.73 ms / 17747 runs ( 1.96 ms per run)
whisper_print_timings: total time = 1488458.75 ms
ggml_metal_free: deallocating
ggml_metal_free: deallocating
./main -m models/ggml-large-v3.bin -f ./test-data/input.wav 369.85s user 34.04s system 27% cpu 24:48.63 total
large-v3モデルで2227秒の音声文字起こしが1489秒で完了しました
実時間の約1.50倍速!かなり高速です
アクティビティモニタを確認するとGPUへしっかり負荷をかけられておりCPUには余裕があることがわかります
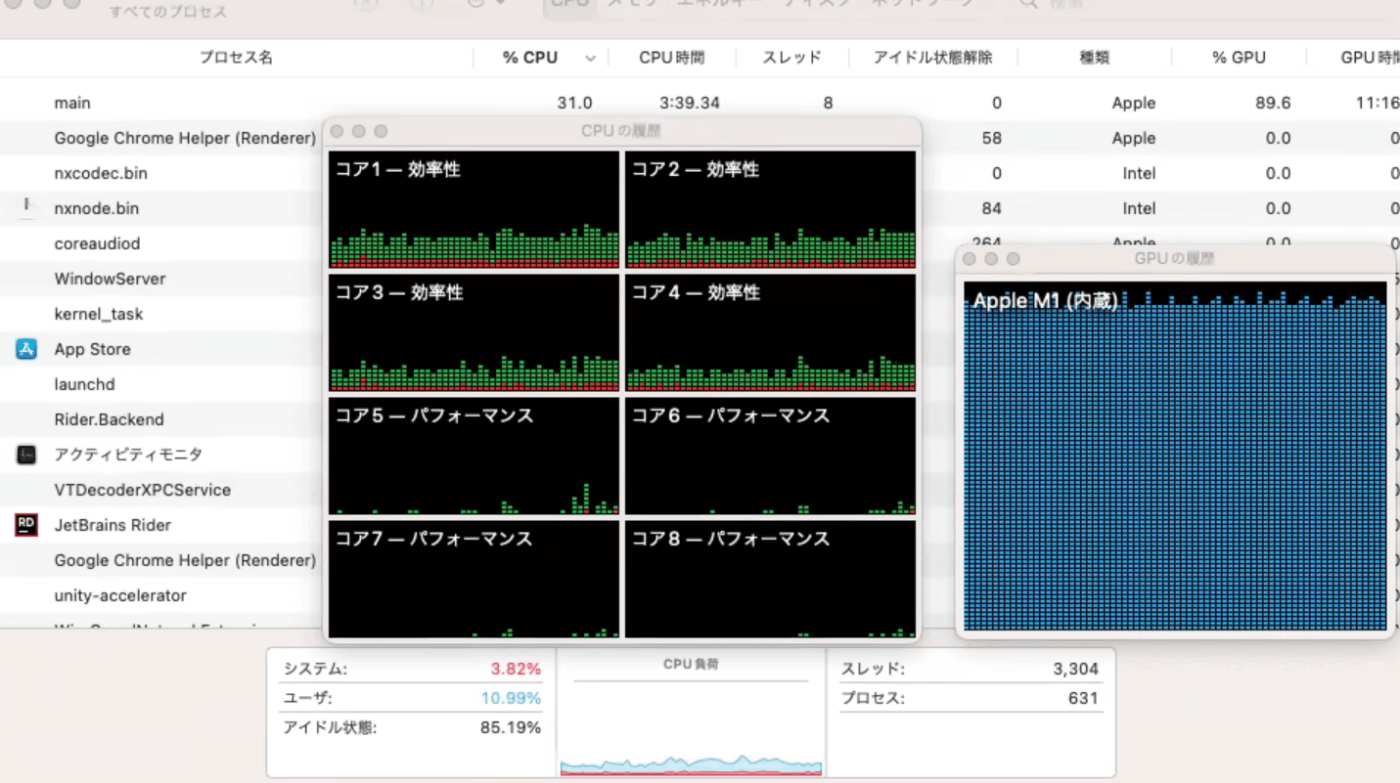
whisper.cppはCore ML + ANE経由で推論処理をしていた時期が長いのですが、ANEは初回実行時のオーバーヘッドがかなり大きくて使いづらい部分があったので自前MPS実装版のほうが何かと手軽に扱えるようになった印象です
Core ML版モデルの調達
Core ML対応版を機能させるためには元モデルから変換したCore ML用の追加データが必要で、M1 Macだとまる一日かけても変換完了しないという結構しんどい状況だったのですが、つい最近Hugging Faceでホストされるようになりました
該当PR
ダウンロードしたファイルはzip圧縮されているのでmodelsディレクトリ以下へ展開します
次のように.binファイルと並列で.mlmodelcディレクトリが配置されていればOKです
ggml-large-v3-encoder.mlmodelc/
ggml-large-v3.bin
Core ML + Metal版
whisper.cpp % time ./main.coreml -m models/ggml-large-v3.bin -f ./test-data/input.wav
...
[00:37:45.580 --> 00:37:46.580] stuff itself.
[00:37:46.580 --> 00:37:47.580] It still works itself.
[00:37:47.580 --> 00:37:48.580] So, yeah.
[00:37:48.580 --> 00:37:49.580] Cool.
[00:37:49.580 --> 00:37:50.580] Yeah.
[00:37:50.580 --> 00:37:51.580] Thank you.
whisper_print_timings: load time = 9290.99 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 1368.71 ms
whisper_print_timings: sample time = 130656.13 ms / 80526 runs ( 1.62 ms per run)
whisper_print_timings: encode time = 157479.08 ms / 81 runs ( 1944.19 ms per run)
whisper_print_timings: decode time = 3955.40 ms / 80 runs ( 49.44 ms per run)
whisper_print_timings: batchd time = 1073831.00 ms / 80190 runs ( 13.39 ms per run)
whisper_print_timings: prompt time = 35541.57 ms / 18168 runs ( 1.96 ms per run)
whisper_print_timings: total time = 1419958.75 ms
ggml_metal_free: deallocating
ggml_metal_free: deallocating
./main.coreml -m models/ggml-large-v3.bin -f ./test-data/input.wav 377.87s user 66.05s system 31% cpu 23:42.21 total
パフォーマンス比較
Core ML + Metal版の所要時間は1422秒、速度は実時間の1.50倍速→1.57倍速へと高速化しました
実行時間の内訳から、Encoder部分にかかる時間が
228381.83 ms → 157479.08 ms
と大きく短縮されたことがわかります
MLXの登場
2023年も終わろうかというタイミング、本記事の公開準備をしているさなかにAppleのリサーチチームがAppleアーキテクチャへ最適化したMLフレームワークをリリースしました
Whisperも移植例として公開されており、さっそくM1系環境上でパフォーマンス検証をした方の記事があがっています
M1 Proで10分の音声を216秒で処理できている(実時間の2.78倍速)とあるので、本記事で利用したM1とのGPUコア数差を考えると互角エリアにありMLX版Whisperとwhisper.cppはかなり良い勝負をしていそうです
まとめ
whisper.cppの出始めの頃はM1 Macだとギリギリsmallモデルをリアルタイム処理できるぐらいでしたがv1.5.1時点では内蔵GPUを効果的に利用できてlargeモデルすら余裕を持ってリアルタイム処理できます
Whisperの実装は各種存在しますが、それらの多くはNVIDIAのGPUとの組み合わせで最大のパフォーマンスを発揮することへ特化しており、Appleの環境への対応を謳っているものでも実際にはAccelerateフレームワーク経由のCPUベクター演算どまりであることが多いです
FP16のWhisperモデルでApple SiliconのGPU(MPS)をゴリゴリ使い倒したオープンソースの高速処理実装は今のところwhisper.cppのみであり、macOS上で気軽に高性能の文字起こしを使いたいときは基本的にwhisper.cppほぼ一択と考えてよさそうで、し、た、、が
AppleのリサーチチームによるMLXベースのWhisper実装が現れたので一択ではなくなりました
Discussion