Open96
仕事ではじめる機械学習
1章機械学習プロジェクトのはじめ方
機械学習プロジェクトの流れ
- ビジネス課題を機械学習課題に定式化する
- 類似の課題を論文を中心にサーベイする
- 機械学習をしないでいい方法を考える
- システム設計を考える
- 特徴量、教師データとログの設計をする
- 実データの収集と前処理をする
- 探索的データ分析とアルゴリズムを選定する
- 学習、パラメータをチューニングする
- システムに組み込む
- 予測精度、ビジネス指標をモニタリングする
- 解こうと思ってる課題が人間にも解けない場合は機械学習で解くのも難しい
- 機械学習事例を見たときはアルゴリズム、どのような特徴量をデータとして持つか、機械学習部分をどのように組み込むか、に着目する
- 機械学習で解ける範囲と解けない範囲の線引きが出来るようになること、実現するために手を動かせることが大事
ビジネス課題を機械学習課題に定式化する
- ビジネス課題を機械学習課題にブレイクダウンする
- 「ECサイトの売上を上げる」というビジネス課題に対して、「ユーザーごとにおすすめ商品を提示する」というアクションプランを作り、それを機械学習課題とする
- このブレイクダウンの過程でKPIが決まってくる(最低一つは決めた方がいい)
機械学習をしなくて良い方法を考える
- 機械学習を用いるシステム構築の難しさ
- 確率的な処理があるため自動テストがしにくい
- 長期運用してるとトレンドが変化してモデルの精度が落ちる
- 処理のパイプラインが複雑になる
- データの依存関係が複雑になる
- 実験コードやパラメータが残りやすい
- 開発と本番の言語、フレームワークがバラバラになりやすい
- 機械学習を用いるべきビジネス課題の条件
- 大量データに対して高速に安定して判断をする必要がある
- 予測結果の誤りを許容できる
- MVP(Most Valuable Product)を作る
- 最低限の顧客価値を生み出す最小のプロダクト
- ルールベースではどうか、既存のモジュールではどうかなど簡単に実装できるものがMVPとなりうる
- 問題設定から仮説検証までのサイクルは他のシステムのプロダクトのサイクルより長くなりがち
- MVPを作って最低限のコンセプトを検証することでシステムの設計に向かう
システム設計を考える
- 予測結果をどういう形で利用するのか
- バッチで予測処理をしてDBで配布
- Webアプリなどでユーザのアクションに応じて非同期に予測するのか
- 予測誤りをどこで吸収するのか
- 人手による確認や修正は必要なのか
- 必要な場合はどこで修正するのか
- 予測結果が重大な悪影響を与えないとわかっている場所で使用する
- 目標性能と撤退ラインを決める
- サンクコスト(既に投資した事業から撤退しても回収できないコスト)によるバイアスがかかる前に具体的な目標性能と撤退ラインを決める
特徴量、教師データとログの設計をする
- 予測に必要な特徴量を保持してるかドメイン知識のある人と検討
- 教師あり学習に必要な正解データをラベル付けする
- 特徴量を抽出するのに必要なログ設計をする
実データの収集と前処理をする
- ログデータをRDBに格納できる形に加工する
- 数値データの欠損値を処理したり、正規化する
- テキストデータを単語の頻度によって数値化したり低頻単語を除去したらカテゴリ変数をダミー変数化する
- ここが一番時間がかかる
探索的データ分析とアルゴリズムを選定する
- クラスタリングなどの教師なし学習や散布図行列などを使ってデータを可視化
- 相関のある変数を確認
- 少量のサンプリングしたデータで実際にシンプルなモデルを作成し特徴量の重要度を確認
- データ量を確認してバッチ処理をするかオンライン処理をするか検討
学習、パラメータをチューニングする
- 機械学習のアルゴリズムを調整するパラメータを探す
- 人力やルールベースの精度を超えることを目標とする
- データ異常を検知する意味でもシンプルなモデル(ロジスティック回帰など)で試す
- 精度が異常に高くなった場合は、学習データに正解が紛れている(Data Leakage)や過学習となっていないか疑う
- 性能改善を行う場合は何が誤りの原因になっているか共通項はないか探す
過学習を防ぐには
- 交差検証を行ってパラメータチューニングを行う
- 正則化を行う
- 学習曲線を見る
システムに組み込む
- 予測性能とビジネスインパクトをモニタリングする
- KPIの推移を見守りモデルの性能改善を続ける
- KPIの推移を見守るためにダッシュボード等を作成したり、異常時にはアラートを出したりする仕組みを作る
実システムにおける機械学習の問題点への対応方法
問題点
- 確率的な処理があるため自動テストがしにくい
- 長期運用しているとトレンドの変化などで入力の傾向が変化する
- 処理のパイプラインが複雑になる
- データの依存関係が複雑になる
- 実験コードやパラメータが残りやすい
- 開発と本番の言語/フレームワークがバラバラになりやすい
対応方法
- 人手でゴールドスタンダードを用意して、予測性能のモニタリングをする(1,2,4)
- あらかじめ用意しておいたデータと正解に対して予測性能を測定し、推移を監視(1)
- 予測性能をダッシュボードでモニタリングし、閾値を設けてアラートを飛ばす(2)
- モデルに必要なデータの更新を忘れていても、そのせいで性能が落ちたらモニタリングで気づける(4)
- 予測モデルをモジュール化してアルゴリズムのA/Bテストができるようにする(2)
- 1つのアルゴリズムでは性能の限界があるので、複数のアルゴリズムを並列に並べてA/Bテスト可能にし、入れ替えできるように設計する
- カナリアリリースをすることで予測性能の予期せぬ変化に対応できるようにする
- モデルのバージョン管理をして、いつでも切り戻し可能にする(4,5)
- ソースコード・モデル・データの3つをバージョン管理する(4,5)
- ドキュメントを残す(4)
- データ処理のパイプラインごと保存する(3,5)
- 前処理から予測モデル構築までのデータ処理のパイプラインを保存することで、パラメータの管理がしやすくなり、実験コードもひとまとめに管理しやすくなる
- 開発/本番環境の言語/フレームワークを揃える(6)
- 実験用のコードと本番用のコードを同一の言語/フレームワークで作ることで移植しやすくする
機械学習を含めたシステムを成功させるには
- チームメンバで重要な役割
- プロダクトに関するドメイン知識を持った人
- 統計や機械学習に明るい人
- データ分析基盤を作れるエンジニアリング能力のある人
- 失敗しても構わないとリスクを取ってくれる責任者
2章機械学習で何ができる?
分類
パーセプトロン
- 入力ベクトルと学習した重みベクトルを掛け合わせた値を足して0以上か以下かで2つに分類する
- オンライン学習
- 予測性能そこそこ、学習速い
- 過学習しやすい
- 線形分離のみ可能
- 損失関数にヒンジ損失を使う
- 損失関数の全データの和が目的関数で、これが最小化するように確率的勾配降下法で学習させる
- 確率的勾配降下法でどのくらいの幅でパラメータを修正するかを決めるハイパーパラメータを学習率という
- 重みベクトルと入力ベクトルをかけた結果の正負に応じてステップ関数で+1か-1に振り分ける。ステップ関数のような非線形変換する関数を活性化関数と呼ぶ
ロジスティック回帰
- 出力とは別にその出力のクラスに所属する確率値が出せる
- オンライン学習でもバッチ学習でも可能
- 予測性能はまずまず、学習及び推論は速い
- 過学習を防ぐための正則化項が含まれる
- 正則化項は学習時にペナルティを与えることで決定境界を滑らかにする働きを持つ
- 目的関数=損失関数の全データの和+正則化項
- L1正則化(Lasso):重みパラメータの絶対値に任意の正則化パラメータを掛けた値を正則化項とする。重みを0に近づける効果があるため特徴選択の効果が生まれる
- L2正則化(Ridge):重みパラメータの2乗の和に任意の正則化パラメータを掛けた値を正則化項とする。係数の大きさを制限する
- 線形分離のみ可能
- 損失関数は交差エントロピー誤差関数、活性化関数はシグモイド関数
- シグモイド関数は入力が0のときは0.5、値が大きくなるほど1に、小さくなるほど0に近づく
- 0.5という閾値をハイパーパラメータととらえて調整することも可能
- 交差エントロピー誤差関数はt=1(正解)のときはlogynをt=0(不正解)のときはlog(1-yn)を足し合わせたもの
- このときynが0または1にならないように微小の値を足す(対数に0を渡すと-∞となるため)
- 確率的勾配降下法を使うことで最適化できる
SVM
- カーネルと呼ばれる方法で非線形分類も可能
- 特徴量を疑似的に追加してデータをより高次元のベクトルにすることで線形分離可能にする
- 線形カーネル/多項式カーネル/RBFカーネル
- 線形カーネルは疎なベクトル(テキストデータなど)に、RBFカーネルは密なベクトル(画像や音声信号など)に使用される
- マージン最大化をすることで滑らかな超平面を学習可能
- 超平面をどのように引けば2クラスそれぞれ最も近いデータ(サポートベクター)までの距離が最大化できるかを考える
- マージンを最大化することで過学習を抑えられる
- 線形カーネルなら次元数の多い疎なデータも学習可能
- オンライン学習でもバッチ学習でも可能
- 損失関数はヒンジ損失
- f(x)=1で横軸と交差することで決定境界ギリギリで正解しているデータにも弱いペナルティを与える
ニューラルネットワーク
- 多層パーセプトロン
- 入力層
- 中間層
- 出力層
- softmax関数で正規化して確率とみなせるようにする
- 非線形なデータを分離できる
- 多層なため直線ではない決定境界をとれる
- 学習に時間がかかる
- パラメータの数が多いので過学習しやすい
- 重みの初期値に依存して局所最適解にはまりやすい
- 活性化関数は最初期はステップ関数、その後シグモイド関数がよく利用された。深層学習の発展とともにReLUなどの関数が利用されている
- フィードフォワード型のニューラルネットワークは誤差逆伝播法(バックプロパゲーション)で学習
- ランダムに初期化した重みの値を使って出力値をネットワークの順方向に計算し、計算した値と正解となる値との誤差をネットワークの逆方向に計算して重みを修正する
- 中間層を増やすと誤差逆伝播法が使えなくなる欠点を修正して深層学習に発展
k-NN
- データを1つずつ逐次学習する
- 全データとの距離計算をする必要があるため、予測計算に時間がかかる
- 距離は2つの点を結んだユークリッド距離を用いることが多いが、データの散らばる方向(分散)を考慮できるマハラノビス距離を用いることもある
- kの数によるがそこそこの予測性能
- kは投票する個数、k=3のときはデータに最も近い3点のうち得票数が多いクラスに所属しているとみなす
- kの数は交差検証で決める
- 自然言語処理などの高次元で疎なデータの場合は予測性能がでないことが多いから次元削除手法で次元圧縮する
- Elasticsearchのような全文検索エンジンのスコアを距離とみなして使うこともできる
- 特徴量間のスケールをそろえる必要がある
決定木、ランダムフォレスト、GBDT
決定木
- 学習したモデルを人間が見て解釈しやすい
- 入力データの正規化不要
- カテゴリ変数やその欠損値を入力しても内部で処理可能
- 特定の条件下では過学習しやすい
- 木の深さが深くなると学習に使えるデータが少なくなるため
- 枝刈りである程度防げる
- 非線形分離可能だが、線形分離可能な問題は苦手
- クラスごとのデータ数に偏りのあるデータは苦手
- データの小さな変化に対して結果が大きく変わりやすい
- 予測性能はまずまず
- バッチ学習のみ可能
- 不純度を使って同じクラスがまとまるように条件分岐を学習する
- 情報ゲインやジニ係数を用いる
ランダムフォレスト
- 決定木にアンサンブル学習を持ち込んだ発展形
- 利用する標本をランダムに選択(ブートストラップ標本)し、利用する特徴量をランダムに選択して複数の決定木をつくる。回帰では決定木の結果を平均化、分類では多数決を取る
- 枝刈りをしないため木の数や深さと調整すべきパラメータが少なく過学習しやすい
- 予測性能は決定木より高い
GBDT
- 決定木にアンサンブル学習を持ち込んだ発展形
- サンプリングしたデータに対して直列的に浅い木を学習していく勾配ブースティング法を使う。予測した値と実際の値のずれを目的変数として考慮することで弱点を補強しながら複数の学習器を学習させる
- 直列学習のため時間がかかり、パラメータも多いためチューニングのコストも大きくなるが、ランダムフォレストより高い予測性能
回帰
- 線形回帰はデータを直線で、多項式回帰は曲線で近似したもの
- Ridge回帰は学習した重みの2乗を正則化項(L2正規化)に、Lasso回帰は学習した重みの絶対値を正則化項(L1正規化)に、Elastic Netはその両方を正則化項として線形回帰に追加したもの。Lasso回帰やElastic NetはL1正規化によりいくつかの重みが0になり、特徴を絞り込む性質がある
- 回帰木は決定木ベースの回帰で、非線形なデータに対してフィッティングできる
- SVRはSVMベースの回帰で、非線形なデータに対してもフィッティングできる
線形回帰
- 目的関数=損失関数の全データでの和
- 損失関数は二乗誤差を使い、入力データを二乗誤差が最小となるような直線で近似しその係数をパラメータとして得るのが線形回帰
クラスタリング
- 教師なし学習
- データの傾向をつかむために使われる
- 階層的クラスタリング・k-meansなど
次元削除
- 高次元のデータからできるだけ情報を保存するように低次元のデータに変換すること
- クラスタリングした結果も次元削除をして可視化することで傾向をつかめる
- 疎なデータから密なデータに変換し圧縮することも可能
- 次元削除したデータを教師あり学習の教師データにすることも可能
- 主成分分析やt-SNEなど
その他
推薦
- ユーザが好みそうなアイテムや閲覧しているアイテムに類似しているアイテムを提示
- ユーザの行動履歴やアイテムの閲覧傾向をもとに、似たユーザ同士や似たアイテム同士を利用する
異常検知
- クレカの不正な決済やDoS攻撃による不正検知など異常を検出するためのデータマイニング手法
- 外れ値検知ともいう
- 異常のデータの件数はとても少ないため分類モデルを用いて学習しようとすると常に正常の値を出力する。そのため教師なし学習をすることが多い
頻出パターンマイニング
- データ中に高頻度に出現するパターンを抽出する手法
- 購買情報から頻出するパターンを抽出するなど
- 相関ルールと呼ばれる方法が有名でAprioriアルゴリズムを使って解くことが可能
- 時系列の分析を行うときはARIMA(自己回帰移動平均モデル)といったアルゴリズムが使われる
強化学習
- 経験をもとに試行錯誤してある目的のためにあらゆる場面での最適行動の方針を獲得する手法
- 囲碁や将棋のようにゲームに勝つという目的に対して何かしらの行動をとり、その行動の良しあしをもとに次の手を決める
- 自動運転やゲームAIなどの分野で注目
3章学習結果を評価するには
分類の評価
- 正解率
- 適合率
- 再現率
- F値
正解率
- 正解率 = 正解した数/予測した全データ数
- 迷惑メールと普通のメールを分類する場合
- 100件のメールのうち、60件がスパム40件が普通のメール
- 100件すべてをスパムと判定する分類器の正解率は60%。ランダムに判定する場合は50%
- すべてをスパムと判定する分類器は正しいといえるのか?
データの偏りを考慮する適合率と再現率
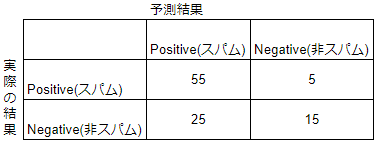
- スパムと予測したメールが80件で実際にスパムだったメールが55件の場合
- 適合率 = 本当にスパムだったメール数/スパムと予測したメール数
- 55/80 = 0.69
- 再現率 = 本当にスパムだったメール数/全スパムメール数
- 55/60 = 0.92
- 適合率に比べ再現率のほうが1に近いため再現率重視と評価。適合率と再現率はトレードオフなので、問題設定しだいでどちらを重視するか決める
- スパムメールの場合は適合率重視のほうがよい(スパムメールが届くほうが、スパムじゃないメールがスパム判定されるほうが困るため)
- 発生件数の少ない病気の検診の場合は再現率重視のほうがいい(病気を見抜ける確率が高いほうがよく、偽陽性と判定しても再検査すればよいと考えるため)
F値でバランスのいい性能を見る
- F値は適合率と再現率の調和平均
- F価 = 2/((1/適合率)+(1/再現率)) = 0.79
- 適合率と再現率のバランスが良ければF値が高くなる
混同行列
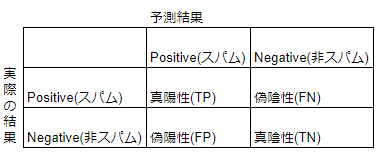
多クラス分類の平均の取り方:マイクロ平均・マクロ平均
マイクロ平均
- 適合率 = TP1+TP2+TP3/TP1+TP2+TP3+FP1+FP2+FP3
- クラスをまたいだ全体のパフォーマンスの概要を知るのに向いている
マクロ平均
- 適合率 = 適合率1+適合率2+適合率3/3
- クラスごとにデータ数の偏りがある場合はマクロ平均を使用して偏りの影響を考慮できる
ROC曲線

- モデルの閾値を変化させていったときにFPRとTPRがどのように変化するかのグラフ例
- 閾値を下げると最初はTPR(陽性率、再現率)が上がっていき、実際に陽性のものをカバーする率は上がっていくが、徐々にFPR(偽陽性率)が上がっていき、陰性でないものを陽性と判定する率が上がっていってしまうことがわかる
- ROC曲線とx軸の間の面積をAUCといい、AUCが0.5に近いと精度の悪いモデル、1に近いと精度のいいモデルと判断できる
分類モデルを比較する
- データに偏りがあることを想定しF値を基準に比較することが多いが、実際の問題では適合率を優先するのか再現率を優先するのかを決めて確率の閾値を決めてからチューニングを行うとよい
- 例:適合率が0.9以上にならないモデルは採用しないと決めて、そのうえでF値が高いモデルを採用する
- AUCを使用する場合もある
- 学習モデルの性能が高いこととビジネスゴールを満たすことは別問題で、そのモデルがそもそも何を実現したかったのかを考える
回帰の評価
平均二乗誤差(RMSE,Root Mean Squared Error)
- 予測した値と実測の値の2つの配列について各要素の差を2乗した値を総和し、要素数で割った値の平方根を取る
- 回帰分析で全データの平均値を出力する予測モデルを考えたとき、平均二乗誤差は標準偏差となる
決定係数
- 常に平均値を出力する予測モデルに比べて相対的にどのくらい性能がいいのか表す。1に近いほど性能が良く、0に近いほどあまりよくない性能といえる
- 決定係数 = 1 - (実測値と予測値の2乗の合計) / (実測値と実測値の平均の2乗の合計)
機械学習を組み込んだシステムのA/Bテスト
- A/Bテストとは同時期に2つのパターンを試すこと
- オフラインで評価できるのは適合率や再現率などの指標
- オンラインではモデルを適用しない場合のパフォーマンスや複数のモデルによる予測結果を使った場合のパフォーマンスを比較することでより最適なモデルを選択できるようになる
- 副次的に新しいモデルの段階的なリリースや切り戻しも可能になる
- 検証のイテレーションサイクルを素早く回せるようになり、機会損失も抑えられるようになる
- オフラインで複数のモデルを用意しA/Bテストで選別し、さらにいいモデルをオフラインで検証し、A/Bテストに投入するというサイクルを回すとよい
4章システムに機械学習を組み込む
システムに機械学習を含める流れ
システム設計
混乱しやすい「バッチ処理」と「バッチ学習」
- バッチ処理とリアルタイム処理
- バッチ処理は一括で何かを処理すること
- リアルタイム処理は刻々と流れてくるセンサーデータやログデータに対して逐次処理を行うこと
- バッチ学習(一括学習)とオンライン学習(逐次学習)
- 一括学習では重みの計算のためにすべての学習データが必要
- 逐次学習ではその時その時で投入するデータと計算済みの重みが必要なだけ
- バッチ処理/リアルタイム処理で学習を行うパターン例
- バッチ処理で学習、予測、予測結果をDB経由でサービングする
- バッチ処理で学習、リアルタイム処理で予測、予測結果をAPI経由でサービングする
- バッチ処理で学習、エッジのリアルタイム処理で予測する
- リアルタイム処理で学習、予測、サービングする
バッチ処理で学習、予測、予測結果をDB経由でサービングする
- 分類問題などについて教師あり学習のモデルを一括学習し、そのモデルを使った予測をバッチ処理で行い、その予測結果をDBに格納する
- 予測に必要な情報は予測バッチ実行時に存在する
- イベントをトリガーとして即時に予測結果を返す必要がない
- 予測の頻度は1日1回程度で問題のないようなパターンで使用
- DBを介して機械学習のバッチシステムと予測結果を使用するシステムをつなぐため、両システムの言語が異なってもよい
- 学習バッチの実行間隔は予測の間隔よりも広くとる
- 定期的な再学習を行う場合はゴールドスタンダードを利用するなど、学習し直した後に精度が低下していないことを確認する
- データ量の増加などで予測にかかる時間が予想以上に増加してしまわないように注意が必要
- Apache Sparkなど並列分散処理が可能な環境で予測するのが良い
バッチ処理で学習、リアルタイム処理で予測、予測結果をAPI経由でサービングする
- 一括学習は同様、HTTPやRPCのリクエストに対して予測結果をレスポンスとして返すAPIサーバを用意する
- Webアプリケーションなどのクライアントと機械学習に使うプログラミング言語を分けられる
- Webアプリケーションなどのクライアント側のイベントに足してリアルタイム処理で予測できる
- APIサーバの開発運用コストが発生
- 各クラウドの機械学習サービスやBentoML・Cortexなど予測結果のサービングのためのフレームワークを利用する手もある
- 学習に使うアルゴリズムや特徴量を変えた複数のモデルによるA/Bテストがやりやすい
- 予測結果を得るためのレイテンシが大きくなる
- 予測結果や特徴量などをキャッシュするなどで対策
- 予測処理事態が重い場合は非同期処理にするなどで対策
- 特徴量の計算が重い場合に特徴ベクトルを事前に作成しRDBなどにキャッシュする方法もある
バッチ処理で学習、エッジのリアルタイム処理で予測する
- バッチ処理で学習したモデルをiOSやAndroidなどの端末や組み込み機器、JavaScriptを通してブラウザなどのエッジ環境で予測する
- 学習したモデルをクライアントで利用できるサイズまで最適化し変換する
- TensorFlow Liteの形式にモデルを変換
- Core MLでscikit-learnやXGBoost、Kerasなどのフレームワークで学習したモデルをiOS向けに変換
- ブラウザでのy疎奥はTensorFlow.jsを用いることが可能。WebAssemblyを使った予測の高速化も可能
- クライアントで予測するので通信レイテンシを気にしなくてよい
- モデルを変換しクライアントの環境へデプロイする仕組みを作る必要がある
- 学習したモデルをクライアントで利用できるサイズまで最適化し変換する
リアルタイム処理で学習をする
- 一部のアルゴリズム(バンディットアルゴリズム)などやリアルタイムレコメンドではリアルタイム処理を使って即時にパラメータ更新が必要
- メッセージキューなどを使って入出力のデータをやりとり
- 短いサイクルでモデルを更新する必要がある場合は、1時間おきなど任意のタイミングで蓄えたデータに対してバッチ処理で学習し、最適化方針は見にバッチ学習で追加学習を行うのが良い
教師データを取得するためのログ設計
特徴量や教師データに使いうる情報
- ユーザ情報
- コンテンツ情報
- ユーザー行動ログ
- 上記2つがRDBMSに保管することが多い一方で、行動ログはデータ量が多いためオブジェクトストレージや分散RDBMS、Hadoop上のストレージなどに保管することが多い
ログを保持する場所
- 分散RDBMS、DWHに格納する
- 分散処理基盤HadoopクラスタのHDFSに格納する
- クラウドのオブジェクトストレージに格納する
- SQLでデータにアクセスできるようにすると検索しやすい
- RedshiftやBigQueryなど
- オンプレミスの制約がある場合はHadoopのHDFSも選択肢
- クラウドストレージに直接格納するのも選択肢
- AWS Glue やDataproc、Azure HDInsightなどの分散処理環境を使用してデータを検索・加工可能
- FluentdやApache Flume、Logstashといったログ収集ソフトウェアを使用して保管先に転送する
ログを設計する上での注意点
- 保存していないデータを増やすのは困難
- 現在取得しているログで教師データを作れるか
- 取得していても既に削除済みなどで保管していないこともある
- マスタデータの変更履歴を保管していなかったこともある
- ログ形式が変化し取得する情報が変わる場合がある
- データ量を多く使いたいから古い特徴量のモデルを使い続ける
- できる限り過去の特量量を計算するバックフィルを行い、新しい特徴量のモデルを利用する
- 1と2でそれぞれ学習したモデルをアンサンブルする
- アンサンブルすると性能が上がることも多いが過去のトレンドの変化も含んだモデルになり精度が伸び悩む場合もある
- ある程度の期間でウィンドウを切って学習することも検討
5章学習のためのリソースを収集する
学習のためのリソースの取得方法
- 教師データに含まれるデータ
- 入力:アクセスログなどから抽出した特徴量
- 出力:分類ラベルや予測値
- 特徴量は経験則や先入観に基づく直感で選定する
- 出力のラベルや値は以下のように求める
- 完全に自動(ログ取得の仕組みを用意して自動で抽出する)
- 人力で行う(コンテンツなどを見て付与する)
- 自動+人力(機械的に情報を付与して人手で確認する)
- 教師データを作るのは誰か
- 公開されたデータセットやモデルを活用
- 開発者自身が教師データを作る
- 同僚や友人などにデータを入力してもらう
- クラウドソーシングを活用する
- サービスに組み込み、ユーザに入力してもらう
公開されたデータセットやモデルを活用する
- すでに世の中に存在する学習済みモデル
- UCI Machine Learning Repository
- コンペティション用に用意されたデータセットを使ってベースラインを学習し転用する
- Kaggle
- ImageNet
- 事前学習済みpre-trainedモデル
- TensorFlow Hub
- PyTorch Hub
- 日本語のテキストデータ
- Wikipediaのダンプデータ(Wiki-40B)
- 有償の新聞コーパス
- 上記を利用する上での注意事項
- モデルやデータセットは商用利用可能なライセンスか
- 学習済みモデルやデータセットを自分のドメイン(自分たちが運用するシステム・サービス)に適用できるか
- 半教師あり学習・転移学習・ファインチューニングなどを活用する
- 画像の物体認識を行うタスクでは自分の解きたい画像の正解データセットを追加することで少ない追加コストで目的の画像を認識するモデルを学習できる
- Embeddingを行う
- BERTを使った分類モデルをファインチューニングして学習する
- 半教師あり学習・転移学習・ファインチューニングなどを活用する
開発者自身が教師データを作る
- どのデータを特徴量とするかが性能に直結することも多い
- 開発者自身が教師データを作ることは重要
- 1カテゴリ1000個程度のデータを収集して自分で分類してみる
- その過程で分類を排他的に行うのか、1つのデータが複数のカテゴリを持つのか定義が固まっていく
- 結果、用いるべきアルゴリズムや予測の方法が変わってくる
- 予測に重要なデータがどういうものかわかり(ドメイン知識)、それを特量量に含めると性能が上がることがある
- ラベリングなどの過程で出来上がった基準や分類に困ったコンテンツについては判断基準と実例を残しておくとよい
- 注意点として、一人の感覚で分類していると思い込みによる偏りが発生することもある
同僚や友人などにデータを入力してもらう
- 事前にデータの内容を言葉で表現できるようにしておく
- 作業内容や判断基準についてきちんと説明しておく。文書化する
- 同一のデータに対して複数名に正解を付与してもらうことも重要
- そもそも人間でも判断の難しい課題が存在する
- 付与された正解データが作業者間でどれくらい一致するか把握することも大事
- 偶然に一致する可能性を考慮した基準であるκ係数(カッパ係数)を使って難易度を判断
クラウドソーシングを活用する
- マイクロタスク型クラウドソーシングでデータの入力やレベルの付与などを依頼する
- Amazon Mechanical Turk
- Yahoo!クラウドソーシング
- クラウドサービスを使用したラベルの付与
- メリット
- 専門の作業者を雇うより作業がとても早く、金額も専門家への依頼より安い
- 作業が速く終わるため試行錯誤しやすい
- 作業コストが低いから複数人に同一タスクを依頼するなど冗長性をもったデータ作成が可能
- 注意点
- 作業者が短時間で解けるようにする必要がありタスクの設計が難しい
- 高い専門性が求められる作業は手順の分割・詳細化が必要
- 作業結果の質を担保するために結果を利用する際の工夫が必要
- 結果の質を保つために
- 同じタスクを複数人に出して多数決を取る
- 事前に練習問題を解いてもらったりアンケートするなどで作業者をふるいにかける
- データを得た後に質をどうひょうかするかについてあらかじめ考えておく
- カテゴリごとにサンプルチェックするなど
サービスに組み込みユーザに入力してもらう
- 活用例
- アンケートを取る
- コンテンツのタグをユーザに付与してもらう
- コンテンツのカテゴリ申請をしてもらう
- 不適切なコンテンツを報告してもらう
6章継続的トレーニングをするための機械学習基盤
機械学習システム特有の難しさ
データサイエンティスト vs ソフトウェアエンジニア
- データサイエンティストの領域とソフトウェアエンジニアの領域
- ソフトウェアエンジニアはデータ基盤の運用とモデルの運用を担当
- データサイエンティストはモデルの開発を担当
- 両者は協業する必要がある
- 協業する上で障害となるスキルセットの違い
- データサイエンティストはGitなどのバージョン管理やユニットテストを書かない
- データサイエンティストの目標
- 分析結果から導出されるアクションや予測モデルによる売り上げ改善などをKPIとする
- 使い慣れている道具を自由に使い最短で結果を出すこと
- その反面メンテナンス性や再利用性の高いコードを書くことに対する優先度は低い
- 分析結果から導出されるアクションや予測モデルによる売り上げ改善などをKPIとする
- ソフトウェアエンジニアの目標
- 本番環境での運用開発を見据えたシステム開発が重要
- データサイエンティストが作った予測モデルから安定的に予測結果をサービングしシステムの安定稼働を重視
- 機械学習の開発フローでは中間データが多く、安全にデプロイし続けるためには複雑なパイプラインの管理や学習されたモデルの検証が必要
- 予測モデルの挙動をモニタリングしやすいような設計が必要
- データサイエンティストが作った予測モデルから安定的に予測結果をサービングしシステムの安定稼働を重視
- 本番環境での運用開発を見据えたシステム開発が重要
- 上記のような違いのあるメンバーでチームを組むことの難しさがある
同一の予測結果を得る難しさ
- CACEの原則
- Change Anything, Change Everything
- 与えられたデータが変わると予測結果が変わる
- データは変化しうる
- Change Anything, Change Everything
- ユーザ情報のようなマスタデータが変化するなど大規模データにおいて過去のある時点でのデータを常に同一の形で用意することが難しい
- 異なる実行環境でライブラリやそのバージョン、ハードウェアなどの依存関係を再現することが難しい
- 実験時と本番環境でのパイプラインに使われる言語やコードが異なる
- 入力データの分布や仮定が学習時と本番環境で異なる
- ハイパーパラメータなどの設定が記録に残されていない
- 学習にかかる時間やコストがとても大きい
継続的トレーニングとサービングの必要性
- 学習済みのモデルを使い続けるためには暗黙的に以下の仮定を置いてる
- 入力データの分布は学習時と予測時で大きく変わらない
- 入力データの使える特徴量も学習時と予測時とで一致し、十分にある
- 上記の仮定が満たされない場合は定期的に新しいデータを用いて予測モデルを更新する必要がある
- 長期的にシステムを維持するためには、自動的にモデルを再学習して提供する予測モデルの継続的トレーニングが重要
継続的トレーニングとML Ops
リリースのアジリティを上げるための機械学習基礎
- データサイエンティストにも本番環境に学習済みモデルを容易にデプロイできる仕組みを用意する
- モデルを試行錯誤するサイクルとリリースのサイクルを近づけることでビジネス価値を継続的にアウトプットできる
ML Ops:機械学習基盤におけるCI/CD/CTを目指す取り組み
- ML OpsはMLシステム開発(Dev)とMLシステム運用(Ops)の統合を目的とするMLエンジニアリングの文化と手法
- ML Opsを実践すると、統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、MLシステム構築のすべてのステップで自動化とモニタリングを推進できる
- ソース管理・単体テスト・統合テストの継続的インテグレーション(CI)とソフトウェアモジュールまたはパッケージの継続的デリバリー(CD)とモデルの継続的トレーニング(CT)を行うための取り組み
機械学習基盤のステップ
- 継続的トレーニングを可能な状態にするために、データサイエンティストや機械学習エンジニア、ソフトウェアエンジニアなど多くのステークホルダーが協力しながら進められる基盤を作っていくにはどうしたらいいかを考える
- 機械学習基盤のステップ別のコンポーネント
- 共通の実験環境
- 予測結果のサービング
- 学習、予測共通の処理のパイプライン化
- モデルの継続的トレーニング・デプロイ
共通の実験環境
- 機械学習環境の課題
- Pythonパッケージのバージョンなど、実験環境を再現する方法が共有されてない
- ソースコードを読み解くのが難しく、コラボレーションが起こりにくい
- 学習時のデータのスナップショットが存在せず、同じモデルを再度学習できない
- 以下のような取り組みがよい
- 共通の実験用Dockerなどのイメージを作成し、バージョニングして実験環境を再現しやすくする
- 共用のJupyterLabやクラウドサービスがホストするJupyter環境を利用して実験の内容を共有、再実行による確認やレビューをしやすくする
- MLflowなどの実験管理のためのツールを活用して、同じモデルを学習するための情報や実験結果の共有をしやすくする
- 合わせてHydraを使うなどして各種パラメータを設定ファイルとして管理しておく
予測結果のサービング
- データサイエンティストがモデルのデプロイとAPIサーバの運用を担当しない仕組みづくり
- クラウドサービスを使用する
- TensorFlow Serving/TorchServe(特定のフレームワーク)
- Seldon Core/BentoML/Cortex(複数のフレームワーク)
- モデルのバージョン管理を行う
- 誤ったモデルのデプロイの阻止
- 切り戻しのため
- MLflow Model Registry/クラウドサービスのモデル管理機能を利用
- ウェブアプリケーションの監視機能を入れる
学習、予測共通の処理のパイプライン化
- 学習のタスクと前処理を1つのタスクとして実行する
- デメリットとして前処理などの共通処理の再利用性が落ちる
- 前処理など共通の処理を分割しワークフローエンジンを活用して処理する
- Apache AirflowやPrefectなどの汎用なもの
- クラウドサービス
- 機械学習用のMetaflow/Kubeflow/Pipelines/Kedroなど
- Feature Store
- 特徴量を事前計算して集約することでキャッシュを活用して予測の際の前処理のレイテンシを抑えたり、ストリーミング処理でも共通の前処理がしやすくなる
- 複数のチームで特徴量を再利用するわけでなければDBやKVSなどに入れるくらいでいい
モデルの継続的学習・デプロイ
- 新しいモデルの再学習とデプロイを自動化するための取り組み
- 特徴量エンジニアリングのロジックのユニットテスト
- 学習時の損失が収束するテスト
- パイプラインがモデルなどのアーティファクトを生成するテスト
- 予測の秒間クエリ
- 予測の精度が閾値を超えているかの確認
- ステージング環境へのPull Requestのマージなどをトリガーしたモデルなどのデプロイ
- ステージング環境でのパイプラインの動作検証
予測結果のサービングを継続し続けるために
監視・モニタリング
- モデルパフォーマンスのモニタリングの難しさ
- HTTPのステータスコードのような明確なエラーコードがない
- 確率的なふるまいが前提なのでKPIが自明ではない
- 修正のためのアクションが自明ではない
- 予測結果のサービス時のメトリクス
- メモリ/CPUなどのハードウェアリソースの使用量
- 予測のレスポンスタイム
- レスポンスが遅いとコンバージョン率が下がるリスクがある
- 予測値のあるwindowでの各種統計量や分布
- 入力値の統計量、特に欠損値/NaNの頻度
- 予測結果が想定範囲内のものになっているのかを検証するため
- 実験時との違いでアラートを決める
- ヒューリスティクスをもとにして検証する(新しい予測結果の正解ラベルを得られる前に検証できるようにする)
- 学習時のメトリクス
- モデルの学習時からの日数(鮮度)
- 古すぎるモデルは新しいデータに適応できない可能性が高いという仮説のもとモニタリングする
- 長期に渡ってダウントレンドになっていないか確認する
- 学習時の予測精度や学習時間
- 継続的トレーニングを実現するコストの確認
- モデルの学習時からの日数(鮮度)
- 予測の難しさが変化しているかどうかに注目する
- 訓練データサイズが減っていないか
- 目的変数の時間変化は激しくないか
- Pelative Information Gain(RIG)を見る
- 平均と比べたときの相対誤差をモニタリングするなど
- 予測性能のモニタリングは時系列での比較が可能なもの、ビジネスへの影響がわかりやすい値を採用するとよい
- ビジネスKPIのモニタリングも行い、予測精度と合わせて確認する
定期的なテスト
- 日次などの定期的な自動テストを行うことで健全な予測ができているか確認する
- 本番環境での予測結果に対する最新正解データでの予測精度の検証
- 人間が判断したラベルとの比較
- Human in the Loop(人間がアノテーションや正解ラベルの付与で関わること)
- データの品質の検証
- 予測結果のサービング時の入力データの質や健全性をテストする
- 学習時のデータと異なる分布や範囲のデータに対しては適切な予測を行えないため
- 入力データの検証
- 入力データのスキーマの検証
- 特徴量がどのような特性を持っているかあらかじめスキーマとして学習データから定義しておく
- そのスキーマから外れた場合はアラートを上げる
- データが想定された範囲か
- 既知のカテゴリ値か
- NaN/Inf値が生成されないか
- 特徴量の多次元配列の要素数は同じか
- 特定の入力がなくなってないか
- 入力データの偏りや変化の検証をするための閾値の例
- 分布の比較にはカテゴリ値にチェビシェフ距離
- 数値にJensen-Shannon divergence
- 入力データのスキーマの検証
- 本番環境での予測結果に対する最新正解データでの予測精度の検証
- 予測システムにかかわる障害調査の4つの質問
- パイプラインにバグがあるか
- 間違えたモデルをデプロイしたか
- データセットに問題があるか
- モデルが古くなっていないか
7章効果検証:機械学習に基づいた施策の成果を判断する
効果検証の概要
ビジネス指標(メトリクス)を用いた施策の評価
- 機械学習は通常予測をもとに何らかの意思決定を行う
- 機械学習モデルが実際にビジネスで利用したときにどれほどのインパクトがあるかは予測精度からは通常わからない
- 意思決定の結果がどれだけビジネスに影響を与えるかで評価(意思決定システムとしてとらえた単位の性能評価)
- ビジネスサイドの人間には予測器の精度よりも、予測器による意思決定の結果利益をどれだけ押し上げたのかを重視するため、データサイエンティストもビジネス指標を使ってコミュニケーションできるとよい
施策実行後の効果検証の重要性
- 予測精度からビジネス指標に与える影響度が予測しづらい
- Booking.comでは実験時の予測精度の向上度合いとリリース後のビジネスインパクトに相関がなかったことを報告
- 予測を利用した機能の性能が高止まりしたケースなど
- レコメンドシステムのような継続的なモデルの再学習が必要なケースでは、モデルの学習・サービング・パフォーマンス監視の仕組みの維持コストがかかるため、計測してメンテナンスコストを払う価値があるかどうか見極めるのも重要
オフライン検証とオンライン検証
- オフライン検証
- 過去のデータを使ったシミュレーション
- オンライン検証
- 実際にプロダクトに適用して実験を行う
- A/Bテストが良く用いられる
- オフライン検証の後A/Bテストでオンライン検証を行う方式が多い
指標の選定
- 代替指標
- プロダクトの長期的なゴールとなるに近い指標が望ましいが、顧客生涯価値のような遅行指標は検証に非常に時間がかかる
- ゴールとなる指標を達成するためのマイルストーンとなる先行指標のうちゴール指標と比例関係にあるのが理想
- 比例関係がずれがちな指標としては商品の購入をゴールとしたときの「流入獲得の広告クリック率」
- 広告クリック率を上げることに最適化して商品に興味ない人の注意を引き付ける結果になると意味がない
- 結果を検証するには指標が計測可能なことが前提。ログ出力・保持ポリシーを確認する
因果効果の推定
相関関係と因果関係の区別
- 施策Xと効果Yのどちらにも影響を与える交絡因子をいかに除去するかが鍵
ルービンの因果モデル
- インターネット広告の場合
- 介入:広告を見せること
- 結果変数:購買行動
- 介入群(実験群):介入した標本
- 対照群(統制群):介入してない標本
- 潜在的結果変数
- 観測可能な結果変数は介入を行った場合か否かのどちらかに限定。広告を見た人が広告に触れなかった場合のケースは反事実。観測できないが潜在的に存在しうる結果変数を潜在的結果変数と呼ぶ
- 平均処置効果(ATE)
- ATE = E(Y1-Y0) = E(Y1) - E(Y0)
セレクションバイアスによる見せかけの効果
- ATEをシンプルに観測出来た値で取得すると
E(Y1|介入あり) - E(Y0|介入なし)
となる(セレクションバイアス)
- 介入有無と結果変数に相関があるとATEの公式と一致しない
ランダム化比較試験(RCT)
- 標本に対してランダムに介入有無を決定することで性質の等しい2軍の片方に介入した状態を作る
- Googleブランド効果測定・Facebookブランドリフト調査
過去との比較で判断するのは難しい
- 施策と同時期に別の施策があるかもしれない
- RCTで同じタイムスパンにおける2群を比較すると簡潔に施策による介入効果以外の要因をそろえることが可能
- RCTを行わない方法として時系列モデルを構築して生成した反事実ケースの予測値と実績の比較を行うCasual Impactという手法もあるがYの未来予測が可能なモデルが必要でそのモデルの精度に依存する
仮説検定の枠組み
なぜ仮説検定なのか
- 事前に適用対象を絞って効果があることを確認(仮説検定)してから全体適用を繰り返すことでリスクを抑えたリリースサイクルが実現できる
A/Bテストの設計と実施
- A/Bテストの流れは次の通り
- 指標の選定
- 2群の抽出
- A/Aテスト
- 片方に介入
- 結果の確認
- テスト終了
2群の抽出と標本サイズ
- 統計的に適切な標本サイズが得られるようにする必要がある
- 標本サイズが大きすぎるとテストの影響を受けるユーザが多くなるため、施策がマイナス効果だった場合に悪影響が大きくなりすぎる
- 全ユーザを半々で分けると、ほかのテストを同時に実施できなくなる(テスト同士が干渉してしまう可能性がある)
継続的なA/Bテストと終了判定
- オンラインテストでは標本サイズが逐次観測データが得られるため、標本サイズが適切になるタイミングまでテストを継続する意思決定を行う必要がある
- 継続的なA/Bテストは新データを使って結果変数の事後分布を更新していくベイズ統計の考え方にマッチする
- テストの終了タイミングは介入群と対照群の結果変数の時系列プロットに信頼区間を重ねることで可視化しやすい
- 信頼区間が分離したら差がある
- 分離しない場合は有意差が出たとしても小さい
- 対照群との対比で何%の性能向上が見込まれれば導入するかを事前に決めておくことで、テストを終了する段階を決めることができる
A/Aテストによる均質さの確認
- ランダム抽出により均質な2群が得られていることを確認するためのテスト
- 抽出後に時間をおいて2群に差がないことを確認して片方に介入する
- もしくは過去のデータを使って差がないことを確認する
施策同士の相互作用に注意
- テスト対象の2群間で共有している要素がないかテスト設計段階で確認する
A/Bテストの仕組み作り
- プロダクトがA/Bテストに対応している必要がある
- 学習データの分離が必要なときもある
- 稼働中の機械学習モデルが学習データに影響を与えて(ユーザの行動がモデルをもとにした施策の結果変わるなどして)ほかのモデルの学習に影響が出るなど
- 効率の悪いテストを早期に止めるためのアラートや自動停止機能、テスト同士で相互作用があるものを自動で検出する機能などあるとよい
オフライン検証
- 実験環境で実施可能なオフライン評価実験の方法が注目されている
ビジネス指標を使った予測モデルの評価
- 予測をもとに行動した結果を考えると把握しやすくなる
- (例)営業支援システムで見込み顧客を分類するモデルの場合
- 真陽性(顧客になる人を顧客になると判定):売り上げ増加
- 偽陽性(顧客にならない人を顧客になると判定):営業コスト増加
- 偽陰性(顧客になる人を顧客にならないと判定):見込み顧客を逃す機会損失
- 真陰性(顧客にならない人を顧客にならないと判定):営業コスト削減
- (例)営業支援システムで見込み顧客を分類するモデルの場合
- 言語化した上でさらに利益・損失の数値化ができれば予測モデルを使ったときの期待収益が高まる
- 予測を大きく外した時に必要なリカバリ業務もはっきりするメリットもある
反実仮想の扱い
- 不明なレコードは捨てて評価してしまう
- 結果を予測するモデル利用して結果を生成して評価する(予測モデルの精度に依存する)
Off Policy Evaluation
- 行動決定ポリシーの評価を過去の別のポリシーによって生成されたログをもとに行うこと
- 特に行動が離散である場合に適用できるポリシー性能評価手法は一般的になりつつある
ビジネス設定を損失関数に反映する
- 偽陽性と偽陰性のインパクトが異なる場合はレコードごとの重み(sample weight)を訓練時の損失関数および評価関数に反映できる
- 広告配信で利用する予測器では広告案件ごとの売り上げへの影響度を重みとして損失関数に反映したweighted loglossを使う例もある
- 損失関数そのものを独自の関数に置き換えることも可能
A/Bテストができないとき
- 自然に得られた観察データをもとに介入効果を推定する様々な手法がある
観察データを使った効果検証
- 反実仮想に相当する対照群が得られないため交絡因子の影響やセレクションバイアスを除去するのが難しい
- 差の差法
- 介入群と似た傾向を示している群の結果変数の時間変化を利用して介入前後の比較を行う手法
- 説明モデルを利用した重回帰分析
- 介入を受ける確率を利用してバイアスを補正する方法
- 比較対照の時系列を生成する方法
8章機械学習のモデルを解釈する
線形回帰の係数から原因を読み解く
- カテゴリ値を線形回帰の説明変数とすると問題があることもある
- カテゴリ値をOne-Hot Encodingで数値化して説明変数とする
- 多重共線性によって過学習してしまうのでカテゴリ値を1つ削除する
- 3値カテゴリの場合、削除した1種類のデータの影響はほかの係数やintercept(切片)に内包されるため、係数をみてもその項目の影響度がわかりづらくなる
10章Uplift Modelingによるマーケティング資源の効率化
- 疫学統計やダイレクトマーケティングにおいて活用される
- ランダム化比較試験のデータを分析することで、どのような患者に対して薬が作用するのか、どのような顧客に対してダイレクトメールを送付すると成果にむずびつくのか、を予測できる
Uplift Modelingの四象限のセグメント
| 介入行為なし | 介入行為あり | カテゴリ | 取るべきアクション |
|---|---|---|---|
| CVしない | CVしない | 無関心 | 介入行為にコストがかかる場合介入を控える |
| CVしない | CVする | 説得可能 | 出来る限りこのセグメントに介入する |
| CVする | CVしない | 天邪鬼 | 絶対に介入してはいけない |
| CVする | CVする | 鉄板 | 介入行為にコストがかかる場合、介入を控える |
A/Bテストの拡張を通じたUplift Modelingの概要
- CV率がA=4%とB=5%の場合、単純なA/Bテストの場合はBを採用する
- 性別の軸でA/Bテストを拡張すると
- A,男性=6%
- A,女性=2%
- B,男性=2%
- B,女性=8%
- 男性にはAを女性にはBを採用する