


(今回は自分の備忘の調べてみた系の記事です)
イントロ
普段は管理の仕事が多いのでエンジニアとしての仕事をする時間はほとんどないのですが、最近CosmosDBを使っていて、色々と問題に遭遇するので一度調べてみました。ちなみに、全社的にみてもCosmosDBを使っているシステムは無くて、ノウハウがなくて困っているのもあって自分で調べてみました。
ちなみに、前提条件としての私のスペックを書いておくので、こんな感じの前提なんだなと参考にして頂ければと思います。
・Azureは触ったことなくて初心者
・CosmosDBについては全く知らない
・Pythonコーディングはほとんどしたことない
・AWSのAuroraやRDSはそこそこ知っている
・OracleDBが一番詳しい
CosmosDBとは?
そもそもCosmosDBとはなんぞや、なんですが、以下のリンクが入門書として良さそうでした。
全然知らなかったのですが、CosmosDBって守備範囲が広いですね。以下のDB(と使用するAPI)をカバーしているのですが、AWSみたいに製品ごとのマネージドサービスがあるというよりも、複数のデータベース製品をまとめて呼ぶ総称みたいな感じです。
・キーバリュー型:Azure Table API (現在は For NoSQL)
・カラム型:Cassandra API (現在は For Cassandra)
・ドキュメント型:SQL API / MongoDB API (現在は For MongoDB)
・グラフ型:Gremlin API (現在は For Gremlin)
※補足:最新のマニュアルを見ると、PostgreSQLも追加されていますね
ここまで見て思うのが、これだけ質の違うDBをどうやってまとめているのか?という疑問です。結論から言うと、それぞれのDBでコンテナ化しているので、物理的にも分けているという感じです。先ほどのリンクの9ページがわかりやすいので引用します。
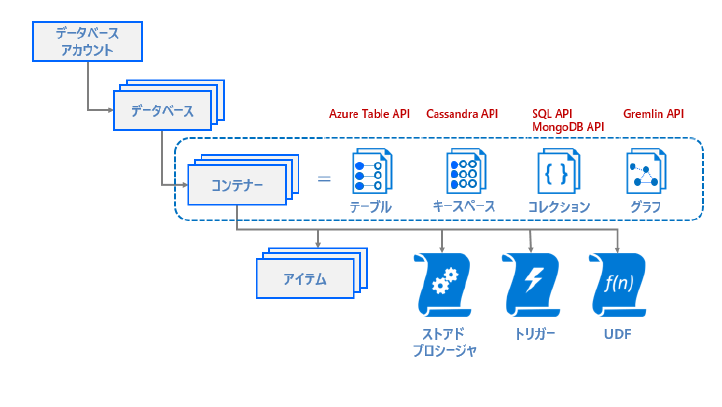
もちろん共用している物理層はあると思いますが、コンテナを抽象化レイヤーにして分割できる設計にしているようです。そのため、P.10には
Azure Cosmos DB のコンテナーがデータ設計、パフォーマンス設定、および、課金の単位になります。
のように記載されています。逆に言うと、CosmosDBと言っても、ディープダイブするには4つのデータベースタイプごとに行う必要があるということになりますね。
CosmosDBにおけるパーティション
さて、今回調査するにあたって知りたいのは、CosmosDBにどのように時系列データを保存すべきか、という方法です。時系列データは基本的に単調増加するデータが多いので、使えば使うほど容量が大きくなってパフォーマンスが悪くなります。そのため、CosmosDBに限った話ではないですが、時系列データを格納する時にはパーティション化するのがセオリーです。
なので、CosmosDBにおけるパーティションを調べていきます。先ほどの資料のP.64に以下のように記載されていました。
Azure Cosmos DB は、「パーティション」 単位でデータを分割して保持します。物理パーティションは、固定容量の SSD を基 盤とする予約済みストレージと、可変容量のコンピューティング リソース (CPU およびメモリ) の組み合わせです。
Azure Cosmos DB のコンテナーは論理リソースであり、1 つ以上の物理パーティション、またはサーバーにまたがることができま す。コンテナーは、ストレージとスループットに関して、事実上制限がありません。
パーティション数は、1 つのコンテナーまたは一連のコンテナーに対してプロビジョニングされた 「スループット (RU/秒)」 と 「スト レージ サイズ」 に基づいて、Azure Cosmos DB が決定します。
物理構成もこの記載から色々と推察できますが、長くなるのでここでは省略します。重要なのは論理パーティションを意識して設計し、物理パーティションはAzureに任せるということです。論理パーティションは20GBが上限のようなので、それを上回らないようにキーを設計してあげる必要があります。例えば、グローバルなデータがあったとして、国コードをパーティションキーにする場合、一番データの多そうなアメリカのデータが20GBを超えないようにする、と言うイメージです。
今回知りたいのは時系列データなので、時間に関するデータをキーにしてパーティション管理していきます。例えば、1ヶ月のデータが20GBを超えてしまうのであれば、1つのパーティションはもっと小さな単位にする必要があります。要するに、週とか、日とかです。
ちなみに、CosmosDBにはDateTime型があるようです。ただ、これをパーティションキーにするのはあまり良くないと思います。公式のマニュアル に
Azure Cosmos DB は、string、number、boolean、null、array、object などの JSON 型をサポートしています。 これは直接 DateTime 型をサポートしていません。
(中略)
そのため、日付と時刻の情報を文字列として保存する必要があります。 日付と時刻の文字列に推奨される形式は yyyy-MM-ddTHH:mm:ss.fffffffZ であり、これは ISO 8601 UTC 標準に準拠しています。 Azure Cosmos DB においてはすべての日付を UTC として保存することをお勧めします。 日付文字列をこの形式に変換すると、日付を辞書式で並べ替えることができます。 UTC 以外の日付が格納されている場合は、クライアント側でロジックを処理する必要があります。
と記載されています。ここで重要なのは”文字列として保存”と言う部分です。秒以下の細かい単位が文字列で入ってしまうので、それをパーティションキーとするとどこで分割するのかわからなくなるので管理上も難しくなります。そのため、手間ですがパーティションの管理単位(月とか、週とか、日とか)をカラムとして追加して、それをキーにした方がいいと思います。あと考えられる方法はDateTimeを数値型(Number)に置き換えてしまう方法でしょうか。
ちなみに、後からキーを変更することはできないようなので、初期設定時には注意が必要です。この辺は他のDBも同じですね。パーティションキーを変更する場合はデータ再編が必要なので、CosmosDBも同じだと思います。
この設計で問題になることはないのか?
パーティションキーを月とか、週とか、日とかにした場合、問題が起きないのか?というと、使い方によっては問題になると思います。例えば、日をパーティションキーにした場合、基本的に一番最後の日にデータ書き込みが集中します。昨日や一昨日のデータを書き込むことは考えにくいでしょうし、更新されることもあまりないでしょう。多くのケースにおいて、過去データは参照が中心です。システム的に書き込みや更新の方が負荷は高いので、”今日”のパーティションがホットパーティションになる可能性はあります。なので、仮に参照中心のシステムであれば、日付をキーにするのはアンチパターンで、顧客IDなどのクエリで良く利用されるキーにすべきです。
ちなみに、なんで私が時系列単位に管理する方法を考えているのかといえば、古くなったデータを削除したいからです。そうしないと無限にデータが増えてしまいますからね。一般的なデータベースであれば、パーティション化することで、特定のパーティションをドロップすることができます。本当であれば、パーティションドロップしたいのですが、あまり上手い実装がなさそうです(見つけられていないだけかもしれないので、ご存じの方がいらっしゃったら教えて頂きたいです)。とはいえ、パーティション化することで、キーをベースにクエリを実行するのでフルスキャンを防ぐことができて、削除負荷も減らせるのでは?と考えています。
このように、削除運用と、最新の書き込みの両立は簡単ではありません。ここから先は性能試験をしながら確認するしかないですが、もし最新のパーティションがホットパーティションになる場合は、”日”に加えて”時”まで追加し、その情報でハッシュパーティションにするアイディアもあると思います。時まで追加することで24通りに分割できますし、ハッシュ化することで分散が可能になります。
というわけで、今回は結論までは出せていませんが、ここから先はアプリケーションの動きにもよるので、動かしてみて確認していきたいと思います。
オマケ
調べるうちにわかったのですが、TTL(Time to Live)という機能もありました。古い時間データを勝手に削除してくれるという便利機能です。本来はこちらを使ったほうがいいのでしょうね。今回は別のシステムに転送して、転送した古いデータを削除するという実装を考えていましたので、できれば勝手に削除されたくなかった、という背景はあります。ただ、バッチ処理の組み方次第ではTTLを使ったほうが便利そうなので、そこも含めて考えていきたいと思います。

Discussion