はじめに
こんにちは。三菱UFJインフォメーションテクノロジー2年目の越智です。
普段は主に行内向けの分散系システムの基盤構築やテストを担当しています。
2024/12/2-2024/12/6に米国・ラスベガスで開催されたAWS re:Invent 2024に現地参加してきました。
私は金融機関との関わりが特に深い、「レジリエンス」をテーマに各種セッションやワークショップに参加してきました。
このレポートでは各セッションの概要や学び、主なアップデートについて概観をお伝えしようと思います。
AWS re:Invent 2024について
AWSが主催する最大規模の学習型カンファレンスで、AWSに関連した新機能の発表やベストプラクティスに関連するプレゼンテーション、AWSサービスのハンズオントレーニングなどが行われます。
2024年も前回同様に米国・ラスベガスで開催され、世界中のAWSパートナーやユーザが一堂に会しました。
レジリエンスとは?
レジリエンス(resilience)は、システムが障害や予期せぬ高負荷による中断に耐え、中断から速やかに復旧することができる能力のことを意味しています。
ポイントは「障害が起こる」ことを前提として「いかに迅速に復旧できるか」という点にあります。
この考え方は、 Werner Vogels (Amazon.comのCTO)の有名な言葉で端的に表現されています。
"Everything fails, all the time." / Werner Vogels (CTO, Amazon.com)
システムを障害から迅速に回復できるように構成することで、最終的にお客様に提供するサービスへの影響を最小限にすることがレジリエンスの目的です。
参加セッションについて
ARC302 | GenAI resilience: Chaos engineering with AWS Fault Injection Service
セッション概要
生成AIを使ったチャットアプリケーションに対して、カオスエンジニアリング実験を行うという内容のワークショップでした。具体的には、以下のようなアーキテクチャのアプリケーションを対象としてAWS Fault Injection Serviceを適用しました。

セッション詳細
初めに「レジリエンスとは何か?」についての簡単な講義が行われた後、課題のアーキテクチャに対して、参加者自らがカオスエンジニアリング実験の仮説(※1)を立てる、というワークを実施しました。
※1) カオスエンジニアリング実験では初めにシステムの定常状態を定義し、定常状態に対して実験変数を注入した際の挙動について仮説を立てます。実験によって仮説を検証し、システムの改善に繋げるのがカオスエンジニアリング実験のゴールです。
例えば、VPCに対して実験を行う場合は、以下のような仮説を立てることができます(実際にワークショップで提示された例です)。
【実験】ランダムなVPCについて10分間、200msのネットワークレイテンシを注入する。
【仮説】
- 定常状態: アプリケーションに対するリクエストの失敗は1%未満。99パーセンタイルの遅延は200ミリ秒を超えない。
- 実験状態: 5%未満のリクエストが失敗する。99パーセンタイルの遅延は500道ミリ秒を超えない。
- RTO: レイテンシの注入後、システムは5分以内に定常状態に回復する。
ワークショップでは上記の仮説の設定と検証のためにLocustを用いて負荷掛けを行い、レイテンシを計測していました。
ワークショップではVPC以外にもAWS Lambda、Amazon Auroraインスタンス、Amazon Bedrockの障害シナリオについても用意されていたのですが、時間の都合上すべては実施できませんでした。
感想・得られた知見
カオスエンジニアリングでのObservabiltyの重要性を再認識しました。システムの稼働状況を適切な粒度で把握できていないと適切な仮説設定と実験による知見のフィードバックができないためです。
また、実際に自分で手を動かして仮説検証を行うことで、適切なObservabilityの粒度や使用するツールの妥当性について理解を深められると感じました。
ARC334 | Building resilient applications on AWS with Capital One
セッション概要
AWSとCapital Oneによるプレゼン形式のセッション(Breakout Session)で、
- レジリエンスを高めるための基本原則とは?
- Captial Oneがミッションクリティカルシステムに対して実際に採用したアプローチとは?
が大きなテーマでした。
セッション詳細
初めにAWSのスピーカーからレジリエンスを高めるための基本原則として
- Fault Isolation (≒障害の影響範囲の局所化)
- Observability
- Recovery
の3つについて説明がありました。
Fault Isolationは、障害が発生した時の影響範囲をいかに局所化するか?という点がポイントの考え方です。
セッションではPhysical Design(AZやリージョンの分離等)で物理的に障害範囲を限定するだけではなく、Logical(論理的)に障害範囲を限定することが重要である、と強調されていました(アプリケーションのリアーキテクチャやAWSアカウントの分離などが該当します)。
Capital Oneのスピーカーからは、社内でミッションクリティカルシステムの構築の際に用いられているアプローチとして
- Cross-region failover
- AZ diversity
- Cell-based isolation
の3つが取り上げられていました。
AWS上のミッションクリティカルシステムの例として、Core Bankingシステムのアーキテクチャが紹介されました。アーキテクチャは下図のようなもので、リージョン単位で"Cellular Architecture"を採用している点が大きな特徴です。CellどうしはStorage含めて分離されているため、個々のCellが独立してサービスを提供することができます。これにより、単一のリージョンやAZで障害が発生したとしてもダウンタイムなしにサービス提供を継続させることを目的としていると考えられます。

感想・得られた知見
Capital Oneのトークで、レジリエンスに投資する理由は単なるリスク軽減のためではなく、顧客の満足度を高め信頼を獲得するためである、とポジティブに捉えていたのが印象的でした。グローバルで比較して日本ではまだレジリンスの取り組みが進んでいるとは言い難いですが、システムを作る側の意識的な改革もレジリエンスの取り組みの中の重要な要素の一つではないかと感じました。
FSI328 | Make application highly resilient with FIS
セッション概要
Builder's Sessionと呼ばれる6名程度のグループに分かれてのハンズオンセッションした。
デジタルウォレットアプリ(当行で言うダイレクトバンキングアプリ)に対してAWS Fault Injection Serviceを用いたカオスエンジニアリング実験を行いました。
アプリの名前から想像される通り、金融機関が提供するミッションクリティカルなサービスを意識したセッションでした。

セッション詳細
障害ケースとしては以下の4つを仮定し、それぞれの障害ケースを踏まえてアプリケーションのアーキテクチャをどのように改善できるかを議論する、というのが基本的な流れでした。
- Amazon ECSタスクのダウン
- Amazon EC2インスタンスのダウン
- AZのダウン
- Amazon RDSインスタンスのダウン
AZ障害に対しては、Amazon ECSクラスタがマルチAZで展開されていることを前提とした上で、Amazon Application Recovery Controller(ARC)のZonal Shift機能を使用して、正常なAZにトラフィックを迂回する、というソリューションが提案されていました。
さらに、Amazon RDSインスタンス障害時のフェイルオーバに伴うデータロストを防ぐためにAmazon Managed Streaming for Apache Kafkaでトラフィックをキューイングする、というソリューションが提案されていました。
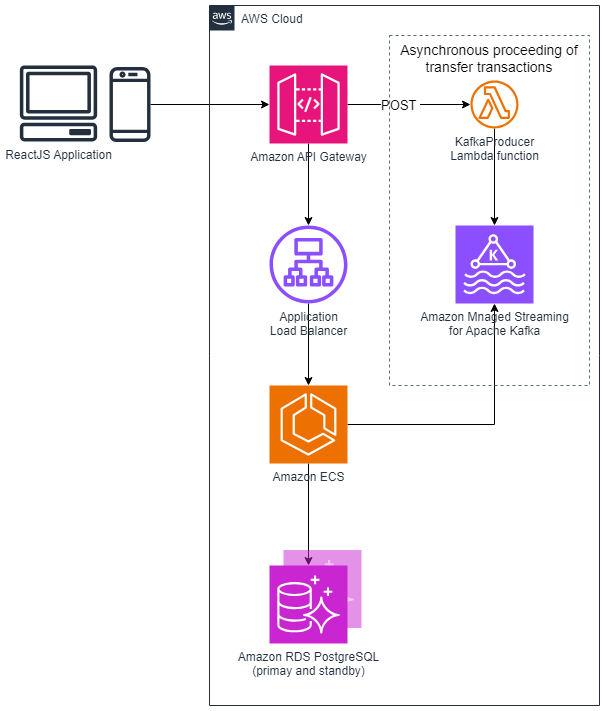
感想・得られた知見
Amazon RDSインスタンスのダウンに対応したAWSのソリューションが興味深く感じました。
私個人的にはAmazon RDSを冗長構成にする、という解しか思いつかず、フェールオーバ時のデータロストについては考えが全く及んでいませんでした。
障害が起こることを前提とした上で、サービス提供への影響まで考慮した上で徹底的にAWSサービスを使い倒す、という考え方は今まであまり触れてこなかったもので、勉強になりました。
まとめ
参加したセッションで共通してObservabilityの重要性が強調されているのが印象的でした。
カオスエンジニアリング実験など、レジリエンス向上のための具体的なアクションを取るためには、サービスやシステムの定常的な挙動を詳細かつ定量的に把握することが非常に重要であると学びました。
また、ミッションクリティカルシステムにおいても、「障害は起こることを前提として、AWS上で回復力のあるアーキテクチャを考えるべき」というAWS側のメッセージが強く感じられました。
社内に目を向けると、AWSの特性を踏まえた適切なFault Isolation方法の検討や、新規サービス利用の検討(AWSを使い倒す)など、AWS利用を前提としたレジリエンス関連の議論をさらに深める必要があると感じました。
当社では様々なシステムでAWS活用を進めています。
この記事を読んで当社の取り組みに興味を持たれた方はぜひ以下のリンクもご覧になってください!

Discussion