こんにちは。三菱UFJインフォメーションテクノロジーの小林と申します。
今回は、社内ChatGPTに聞きながらサーバ(Linux)のCPU/MEM分析アプリを作ってみました。
はじめに
StreamlitというPythonのWebフレームワークがとても便利なので使ってみます。
結論
- (今更ですが)ChatGPTは便利
- Streamlitを利用すると簡単にWeb分析アプリが作れる
最終的なソースコード
import streamlit as st
import pandas as pd
import plotly.express as px
# ファイルアップロード
uploaded_file = st.sidebar.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、1~4行目をスキップして5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, skiprows=4, encoding='cp932', parse_dates=[0])
st.write(data)
# サイドバーにチェックボックスを作成
st.sidebar.subheader('Columns to display')
default_cols = [data.columns[0], 'CPU(all)使用率', 'メモリ使用率']
cols = st.sidebar.multiselect("Select the columns", data.columns.tolist(), default=default_cols)
# 選択された列のみ表示
st.dataframe(data[cols])
# グラフ描画
st.subheader('Graph')
if data.columns[0] in cols:
fig = px.line(data[cols], x=data.columns[0], y=cols[1:])
fig.update_yaxes(range=[0,100])
st.plotly_chart(fig)
else:
st.line_chart(data[cols])
前提
- 社内向けのChatGPTを利用しています。今回はこちらを使って、Streamlitのサンプルコードを書いてみます。
- 社内にはサーバのCPUやメモリなどのパフォーマンス統計値を収集して閲覧できる仕組みがあります。
- 今回は、そこからパフォーマンス統計値データをダウンロードして、アプリにアップロードすることによってグラフィカルに確認できることを目標とします。
- 今回作成しているコード等は以下バージョンで検証しております。
streamlit==1.32.2
plotly==5.20.0
稼働統計データサンプル
インプット用のサンプルデータです。
Header1
Server,sampleA
Component,AAA,BBB,CCC
Category,CPU,CPU,MEMORY
指標,CPU(all)使用率,CPU(0)使用率,メモリ使用率
2024/03/15 00:00:00,10.0,1.0,3.0
2024/03/15 00:05:00,15.0,1.0,40.0
2024/03/15 00:10:00,40.0,1.0,80.0
サンプルの画面表示
以下のような分析アプリが作れます。

やってみます
Q がプロンプト(質問)でA が回答です。
初手聞いてみる
データをダウンロードしてきてそのままプロンプトにCSVを貼り、やりたいことを伝えてみます。
Q: - 以下のようなCSVがあります。
- 5行目が項目名
- 6行目以降がデータです。
- Streamlitを使ってこのCSVをアップロードしてグラフで表示させてください。
Header1
Server,sampleA
Component,AAA,BBB,CCC
Category,CPU,CPU,MEMORY
指標,CPU(all)使用率,CPU(0)使用率,メモリ使用率
2024/03/15 00:00:00,10.0,1.0,3.0
2024/03/15 00:05:00,15.0,1.0,40.0
2024/03/15 00:10:00,40.0,1.0,80.0
A: 以下のようにStreamlitを使ってCSVをアップロードし、グラフで表示させることができます。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# ファイルアップロード
uploaded_file = st.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, header=4)
st.write(data)
# グラフ描画
st.subheader('Graph')
st.line_chart(data.set_index('指標'))
このコードでは、まずStreamlitのfile_uploaderを使ってCSVファイルをアップロードします。その後、pandasのread_csv関数を使ってCSVを読み込みます。ここで、header=4と指定することで5行目をヘッダー(列名)として設定します。
最後に、line_chart関数を使ってグラフを描画します。ここでは、set_index('指標')を使って'指標'列をインデックスに設定しています。
なお、このコードはCSVの内容によってはエラーが発生する可能性があります。具体的なエラー内容やCSVの詳細によりますが、適宜コードを修正してください。
回答帰ってきたのでこれでまずは動かしてみます。
文字コードのエラー
とりあえず動かしてみると、エラーが出ます。なので、そのまま社内ChatGPTに聞きます。
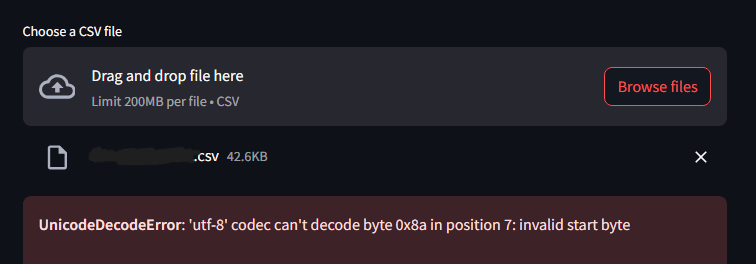
Q: 以下が出力されました。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8a in position 7: invalid start byte
A: エラーメッセージから判断すると、アップロードされたCSVファイルがUTF-8形式でエンコードされていない可能性があります。この問題を解決するためには、CSVファイルのエンコーディングを指定する必要があります。
以下のようにread_csv関数にencodingパラメータを追加してみてください。
data = pd.read_csv(uploaded_file, header=4, encoding='適切なエンコーディング')
ここで、'適切なエンコーディング'は、CSVファイルのエンコーディングに応じて変更してください。例えば、日本語のCSVファイルであれば、'cp932'(Shift_JIS)や'euc_jp'を試すと良いでしょう。
なお、どのエンコーディングを使用すべきか分からない場合は、ファイルの作成者に問い合わせるか、エンコーディングを自動的に推測するライブラリ(例えばchardet)を使用することを検討してみてください。
Q: エンコーディングはcp932です。
A: エンコーディングがcp932であることがわかったので、以下のようにコードを修正します。
data = pd.read_csv(uploaded_file, header=4, encoding='cp932', parse_dates=[0])
これで、アップロードされたCSVファイルがcp932でエンコードされていて、1列目が日付型であるという条件に対応できるはずです。
そのまま使えそうなのでやってみます。
余談になりますが、Streamlitはソースコードが変更されたらそれが検知されるので更新が楽ですね。

ここまでの実装だけで、既にみやすいグラフが完成しました。

見た目を整える
日付化されてなかったり、全部の指標が見えてたりするので、修正してもらいましょう。
Q: 1列目は日付型として処理してください。
A: pandasのread_csv関数には、特定の列を日付型として読み込むためのparse_datesパラメータがあります。これを使用して、1列目を日付型として読み込むように修正します。
以下のようにコードを修正してみてください。
data = pd.read_csv(uploaded_file, header=4, encoding='適切なエンコーディング', parse_dates=[0])
ここで、parse_dates=[0]とすることで、1列目(0-indexed)を日付型として読み込むように指定しています。
なお、日付の形式が標準的なもの(例えば'YYYY-MM-DD')でない場合は、date_parserパラメータを使用して日付のパース方法をカスタマイズすることも可能です。具体的な方法は、日付の形式によりますので、詳細が必要であればお知らせください。
Q: 表示させる列についてチェックボックスで指定できるようにしてください。
適宜サイドバーを使ってください。
A: Streamlitのサイドバーとチェックボックスを使用して、表示する列を指定できるようにするには、以下のようにコードを修正します。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# ファイルアップロード
uploaded_file = st.sidebar.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, header=4, encoding='cp932', parse_dates=[0])
st.write(data)
# サイドバーにチェックボックスを作成
st.sidebar.subheader('Columns to display')
cols = st.sidebar.multiselect("Select the columns", data.columns.tolist())
# 選択された列のみを表示
st.dataframe(data[cols])
# グラフ描画
st.subheader('Graph')
st.line_chart(data[cols].set_index(data.columns[0]))
このコードでは、まずsidebar.file_uploaderを使ってCSVファイルをアップロードします。その後、sidebar.multiselectを使って、表示する列を複数選択できるチェックボックスを作成します。ここで、data.columns.tolist()を使って、全ての列名をリストとして取得しています。
最後に、選択された列のみを表示するようにdataframeとline_chartを修正します。ここでは、data[cols]を使って選択された列のみを抽出しています。

動いているように見えますが、エラー出てるのでそのまま聞いてみます。
Q: KeyError: "None of ['指標'] are in the columns"
Traceback:
File "C:\~省略~\.venv\Lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 542, in _run_script
exec(code, module.__dict__)
File "C:\~省略~\app.py", line 21, in <module>
st.line_chart(data[cols].set_index(data.columns[0]))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\~省略~\.venv\Lib\site-packages\pandas\core\frame.py", line 6109, in set_index
raise KeyError(f"None of {missing} are in the columns")
A: エラーメッセージから判断すると、set_index(data.columns[0])の部分でエラーが発生しているようです。これは、選択された列(cols)に1列目(data.columns[0])が含まれていないためと考えられます。
この問題を解決するためには、1列目が必ず含まれるようにチェックボックスの選択肢を調整するか、set_indexの部分を修正する必要があります。
以下のようにコードを修正してみてください。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# ファイルアップロード
uploaded_file = st.sidebar.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, header=4, encoding='cp932', parse_dates=[0])
st.write(data)
# サイドバーにチェックボックスを作成
st.sidebar.subheader('Columns to display')
cols = st.sidebar.multiselect("Select the columns", data.columns.tolist(), default=data.columns[0])
# 選択された列のみを表示
st.dataframe(data[cols])
# グラフ描画
st.subheader('Graph')
if data.columns[0] in cols:
st.line_chart(data[cols].set_index(data.columns[0]))
else:
st.line_chart(data[cols])
このコードでは、multiselectのdefaultパラメータを使って、1列目がデフォルトで選択されるように設定しています。また、line_chartの部分では、1列目が選択されている場合のみset_indexを使用し、そうでない場合はset_indexを使用しないように修正しています。
不要な初めの行を捨てる
これでもたぶん動くと思いますが、データの最初の方の行は無視できるのでそれを伝えて加工処理を実装してもらいます。
Q: ファイルについて1~4行目までは捨ててください
A: pandasのread_csv関数には、読み込む際にスキップする行を指定するskiprowsパラメータがあります。これを使用して、1~4行目をスキップするように修正します。
以下のようにコードを修正してみてください。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# ファイルアップロード
uploaded_file = st.sidebar.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、1~4行目をスキップして5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, skiprows=4, encoding='cp932', parse_dates=[0])
st.write(data)
# サイドバーにチェックボックスを作成
st.sidebar.subheader('Columns to display')
cols = st.sidebar.multiselect("Select the columns", data.columns.tolist(), default=data.columns[0])
# 選択された列のみを表示
st.dataframe(data[cols])
# グラフ描画
st.subheader('Graph')
if data.columns[0] in cols:
st.line_chart(data[cols].set_index(data.columns[0]))
else:
st.line_chart(data[cols])
ここで、skiprows=4とすることで、1~4行目をスキップして5行目からデータを読み込むように指定しています。
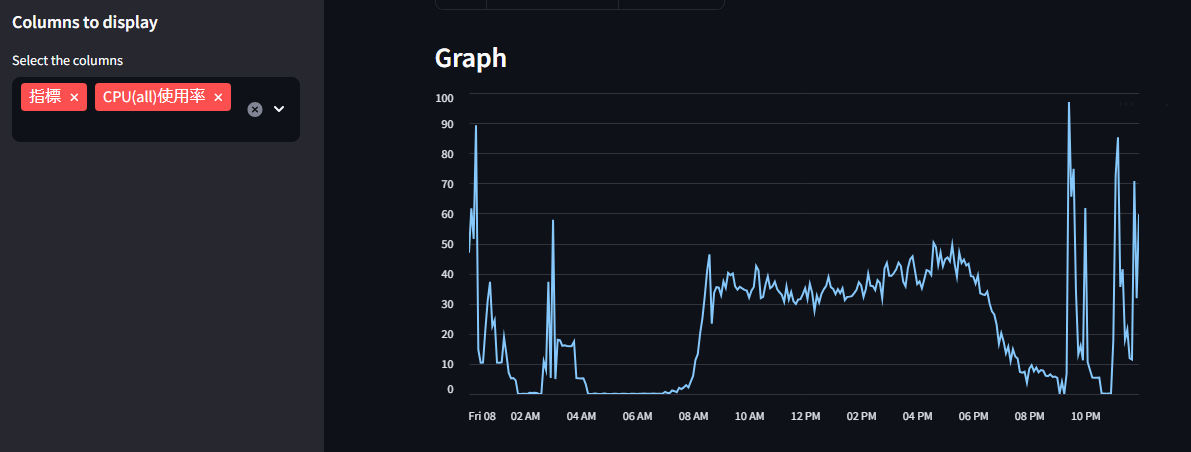
ここまでである程度ミニマムな分析アプリが完成しました。
カラムの初期値
また、見え方として、大体の場合はCPU(all)とメモリ使用率が欲しいのでそれを初期値にするように処理を追加してもらいます。
Q: デフォルトのカラムは「CPU(all)使用率」と「メモリ使用率」にしてください。
A: multiselectのdefaultパラメータを使って、デフォルトで選択される列を「CPU(all)使用率」と「メモリ使用率」に設定します。
以下のようにコードを修正してみてください。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
# ファイルアップロード
uploaded_file = st.sidebar.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
# CSVを読み込み、1~4行目をスキップして5行目をヘッダーとして設定
data = pd.read_csv(uploaded_file, skiprows=4, encoding='cp932', parse_dates=[0])
st.write(data)
# サイドバーにチェックボックスを作成
st.sidebar.subheader('Columns to display')
default_cols = [data.columns[0], 'CPU(all)使用率', 'メモリ使用率']
cols = st.sidebar.multiselect("Select the columns", data.columns.tolist(), default=default_cols)
# 選択された列のみを表示
st.dataframe(data[cols])
# グラフ描画
st.subheader('Graph')
if data.columns[0] in cols:
st.line_chart(data[cols].set_index(data.columns[0]))
else:
st.line_chart(data[cols])
ここで、default_colsにデフォルトで選択される列名のリストを設定し、それをmultiselectのdefaultパラメータに渡しています。
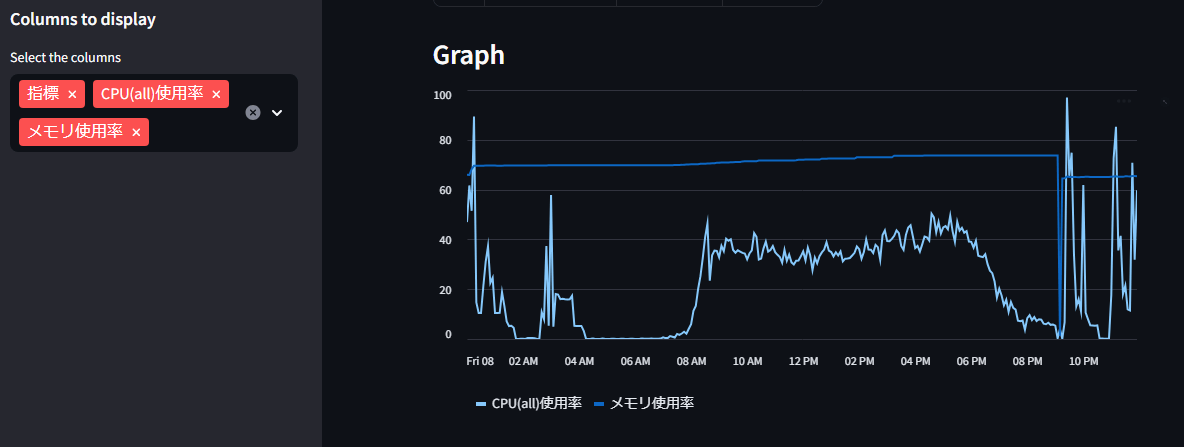
当初の要件としては満足しましたので、一旦ここまでにします。
ここまでで30分ぐらいでした。あっという間にアプリが作れてしまいますね。
まとめ
- 初めに書いた通り、ChatGPTは優秀です。
- Streamlitだと至極簡単に分析アプリが作れる。
- ただし、「こういう風にしたい」という成果物のイメージがあった方が早いです。
以上、いかがでしたでしょうか。
社内でもChatGPTの利用が進んでおり、日常の開発業務の中でも当たり前に活用されております。
また、銀行系であるためCOBOLを使った開発が多いという印象があるかと思いますが、実はそれだけではなくて、モダンな開発もされております。
一緒に開発、してみませんか。
興味を持たれた方は是非ご連絡ください!お待ちしております。
なお、掲載したソースコードはサンプルになります。本ソースコードを使用することで発生するいかなる損害や不利益について、当社は一切の責任を負いませんので自己の責任においてご利用ください。

Discussion