Azure AI Search: RAG for better results, larger scale, faster answers
朝から一番興奮するような内容でした。中身はAzure AI Search(以降、AI Searchと記載)の解説だったのですが、とても良かったので今日のブログはこれを中心に解説します。昨日のキーノートよりも面白かったです。
まずは、AI Searchのアプローチから。下図のように解説してました。横軸の右に向かって進める感じです。L0〜L3の流れはこれ以降も出てくるので覚えておいてください。下段のNewのところが新しく発表されたものでした。

続いて下図ではクエリーが発行されてからの流れの解説です。上の方のクエリーリライトの機能はSLMで行っています。そんなに難しい処理ではないので、SLMでも十分なんだと思います。下の方のランカーの部分はL2のNewで登場していたところです。

で、そのランカーの部分の説明です。コンテキストウィンドウが拡大していて、チャンクの長さがフィットするようになったとありますね。こういう地味な改善が精度向上に効いてくるんだと思います。
(https://storage.googleapis.com/zenn-user-upload/3814b2bee96d-20241121.jpg)
その次はインデックス作成における改善です。下図では、表のようにドキュメントの構造を意識してチャンキングしてくれます。これも精度向上の課題だったので、良いアップデートだと思います。

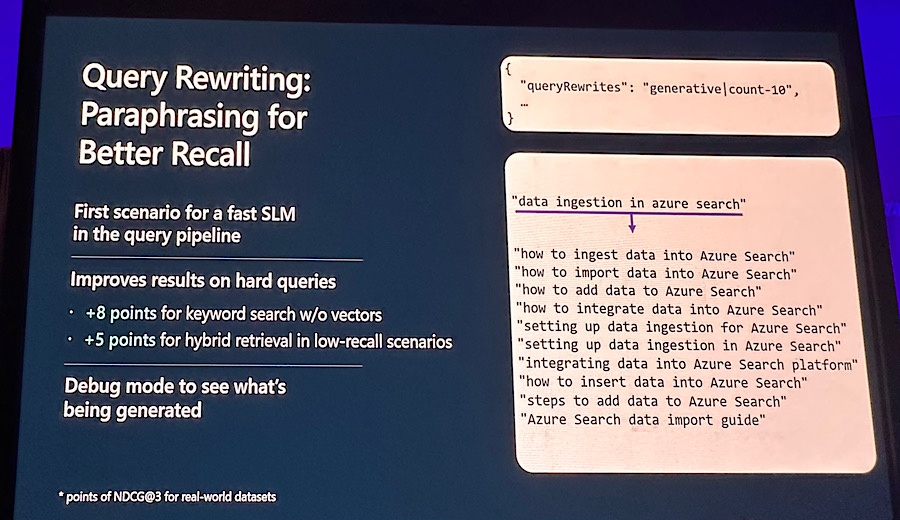
続いてクエリーリライトの機能についてです。SLMを用いてクエリーを書き直してしまう方法ですが、右側の方で書き直しています。「data ingestion in azure search」がイマイチで、下の方で候補が出てますね。
次はベクトルの圧縮です。下図の左側が11,719MBですが、圧縮後は122MBになっています。二桁減ってますが、こんなに圧縮しても精度が下がらないのが驚きです。精度については次のスライドにて。

で次が圧縮とクエリーの相関関係です、一番右側のオーバーサンプリングして、MRLとBQを組み合わせています。MRLはMatryoshka Representation Learningの略で、BQはBinary Quantizationの略です。このスライドに関連する解説を見つけたのでリンクを貼っておきます。

その他のAI Searchに関連する情報もアナウンスされてました。GitHubとの連携で、マーケットプレイスから利用できます。デモも行ってました。あとは、ナレッジソースとしてのCopilot Studioとの連携、Azure AI Agent Serviceとの連携などです。
Community Forum: Azure Unplugged: Pablo Castro on Azure AI Search
1つ目で熱い内容を解説してくれたPablo Castroさんに質問していくセッションでした。トークオンリーの内容で、頑張ってメモしたんですが、全部は聞き取れないものもありました。フリーディスカッションだとかなりきついですが、メモした内容をご参考までで載せておきます。写真みたいな感じで本当にフリーです。

・ここ10年くらいAI Searchの開発。はじめはML向けに開発をはじめた。2年くらい前からGenAIに変えてきた
・リドリーバルのための精度に向けて開発してきたランキングの推測に力を入れて開発した
・画像からサマリードキュメントまでターゲットに入れて開発している
・多くのアプリケーション向けに開発していて、いろいろなカスタマーから情報を得ている。アプリケーションにリスペクトして開発している
・スケールアップ、ダウンを意識して、ストレージのサイズの限界を意識して開発している
・エンプラ向けにはセキュリティを意識して開発してる。セキュリティを深く分析する仕組みがMSにあってそれに従っている。2つのレイヤーで考えていて、カスタマーレイヤーのコントロールが重要
・ランキングやクエリーリランキングはコスト的に効果もあるからオススメ。スケールすることも可能。
・AI Searchのどこが好きかは全部。データサイエンスの全部のエリアをハックできるところ。テクノロジーに触れて楽しめる。
・オーディオシナリオについては、レイテンシーを意識して開発している。音声から音声の変換が重要。インデックスファイルの開発が重要で取り組んでいる
・オーディオはAI SearchかCosmosDBか?RAGするならAI Search。現在はハイブリッドがベースラインになっている。AI Searchは利便性を追求している
・オブジェクトストレージをどう使うかはレイテンシーを意識して利用するべき。インデックスがネイティブでスムーズに使えるのでAI Searchはメリットがある。インデックスが組み込まれているとこで、スピードも増す
・ローコードのフレームワークは、シナリオによる。複雑なシナオリだと難しい。ファンクションコーリングを使うのがいいと思う
・プレビューが長いのは、特にSharePointとな接続はセキュリティの課題もある。
・みなさんには新しいアプリケーション開発に取り組んで欲しい
AI customization: Fine-tuning Azure OpenAI Service models
ファインチューニングの解説のセッションです。OpenAIのファインチューニングというキーワードに釣られたのですが、内容はそこまで?って感じでした。ファインチューニングの目的から始まって、後半はデモを行うタイプの内容です。いくつかのセッションに出てきてわかったのですが、最近ファインチューニングを取り上げるものが増えてきました。言っていることは概ね同じ内容で、低価格で個別要件にマッチさせるために実施しています。個人的にはPhi3とかでファインチューニングしてくれるものがあってもいいのに、とは思いますが、ほとんどはGPT-4o miniを使っています。逆にいうと現時点ではそれがベターな選択なんだと思います。
Accelerating time to value with Azure OpenAI
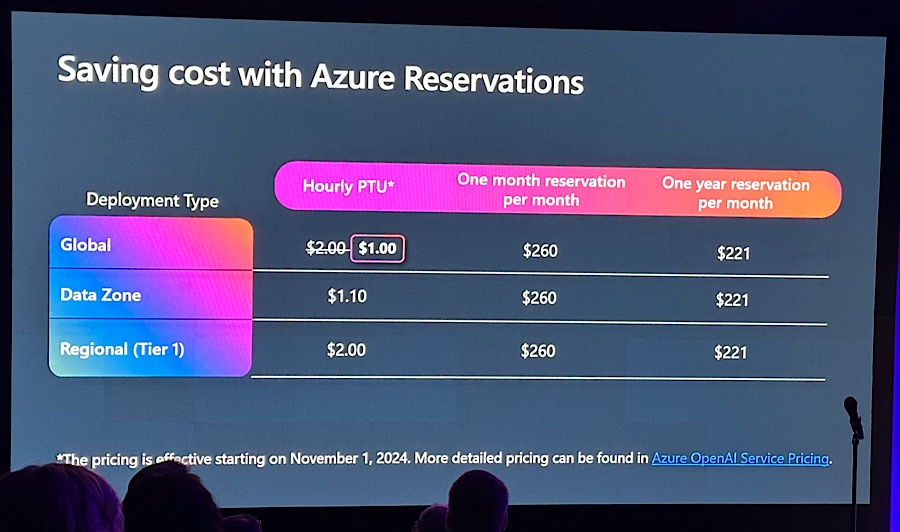
基本的にはこれまで発表されているOpenAIのモデルの説明が多かったです。Day1の方でも書いた「Azure OpenAI: the latest innovation for AI powered business value」の説明と重複するところも多かったですが、それぞれのモデルの最小単位が小さくなった点はフォローしておきます。下図のようにGlobalとData Zonesが使いやすくなりました。

また、コストについてもまとまっていたのでシェアします。GlobalとData Zonesが1時間あたりは安くなりますね。ちなみに、1ヶ月、1年になるとどのタイプでも同じ金額になるようです。
Serverless GenAI: building scalable RAG apps with Azure Cosmos DB
比較的CosmosDBの一般的な話から入ってました。vCore-Baseの話も出てましたが、概論だけでした。vCore-Baseは実際に使おうと思ってます。発表者のジェームズさんとは明後日にお話しする機会を頂いているので、そこで聞いてみようと思います。NDAベースだと記事にはできませんが。。。

※登壇者がジェームズさん
あと気になったのはCosmosDBでもハイブリッド検索ができるようになったことです。正直、こうなってくるとAI Searchとの違いがわからなくなってしまいますね。1つ目のセッションのパブロさんにも、このセッションのジェームズさんにも同じ質問が飛んでました。回答としては、より他との連携や攻めた使い方をするならAI Searchを使うべきで、可用性や守りを意識した場合はCosmosDBの方が正解みたいです。とはいえ、かなり被っている部分もあるので、そのうち統合されたりということもあるかもしれません。
How AT&T delivers RAG at scale
正直なところ、だいぶ頭も疲れてきたので、つまらんデモだったら流そうかと思ってたんですが、AT&Tの事例が思ったよりも面白かったので、さらに疲れました(苦笑)。英語漬けだといつもの何倍も疲れます。速報のために空き時間も調べたり記事書いているのもありますが。
さて中身に入っていきますが、AT&Tの説明の前にRAGの話がありました。基本的には1つ目のセッションと被っていたのでここでは割愛しますが、マトリョーシカのレイヤー手法はメジャーなんですね。ここでも話が出てきてました、
1つ目はAT&TのAI利用のユースケースです。下図のイメージになるのですが、参考になります。中身自体は想像の範囲内ですが、自分たちが進んでいる方向が正しいのかはこういう企業の情報を見ることで安心できます。

次は、AT&Tの社内システムの構成です。社外、社内、個人でナレッジを分けています。こういうIFの情報もわかると参考になります。裏のデータの管理や論理分割が透けて見えますから。

その次もありがたい情報です。プロダクションで使っている正確性と、レイテンシーの情報です。下図を見るとわかるのですが、大体85%で合格のようです。レイテンシーも20〜40秒なので、どちらの指標も結構甘めかなと思いました。逆に、この辺がスイートスポットだと考えると考えやすくなります。ちなみに、Out of Boxも参考になりますね。

次もよくある悩みですが、やはり画像の中に正解があるケースは多いようです。この辺は難しいところですが、拾えるようにしていかないとダメなんだなと思いました。

これも勉強になるなぁという情報です。画像というとマルチモデルって気がしてしまいますが、Goodでした(苦笑)Picのサマリーって何よ、って思ったのですが、複数の写真を1枚に収めたものみたいです。さらっと流れたので、どういうテクニックがあるのかはわからなかったです。

最後はAT&Tの今後のジャーニーも含めた情報です。3段目にGraphがありますが、この辺はまでは検討できるところです。その上にはAgentsがあって、一番上はマルチのベクトルストアになっていました。マルチのベクトルストアに関しては私自身アイディアがないので、今後追っていきたいと思います(今回のセッションでもそれほど言及はありませんでした)。


Discussion