Amazon Data Firehose 経由でS3にファイル転送
はじめに
今回は、Amazon Data Firehose を利用してアプリケーションのログを収集し、Amazon S3 に保存する方法を学びました。作業手順や各種設定内容を備忘録として記録しています。
Amazon Data Firehose とは
Amazon Data Firehose は、AWS が提供するフルマネージドのストリーミングデータ取り込みサービスです。
主な特徴
-
リアルタイムデータの収集
アプリケーションや各種データソースからのログやイベントを自動的に取り込みます。 -
データ処理
収集したデータに対して、変換、バッファリング、圧縮、暗号化などの処理を実施します。 -
多彩な送信先
処理後のデータは、Amazon S3、Redshift、Elasticsearch Service、Splunk などのストレージや分析プラットフォームへ配信可能です。 -
シンプルな設定
専用のインフラ管理が不要なため、エンジニアリングリソースを効率的に活用できます。
使用用途
今回のユースケースは、アプリケーションからのログを Firehose 経由で収集し、Amazon S3 に格納することです。
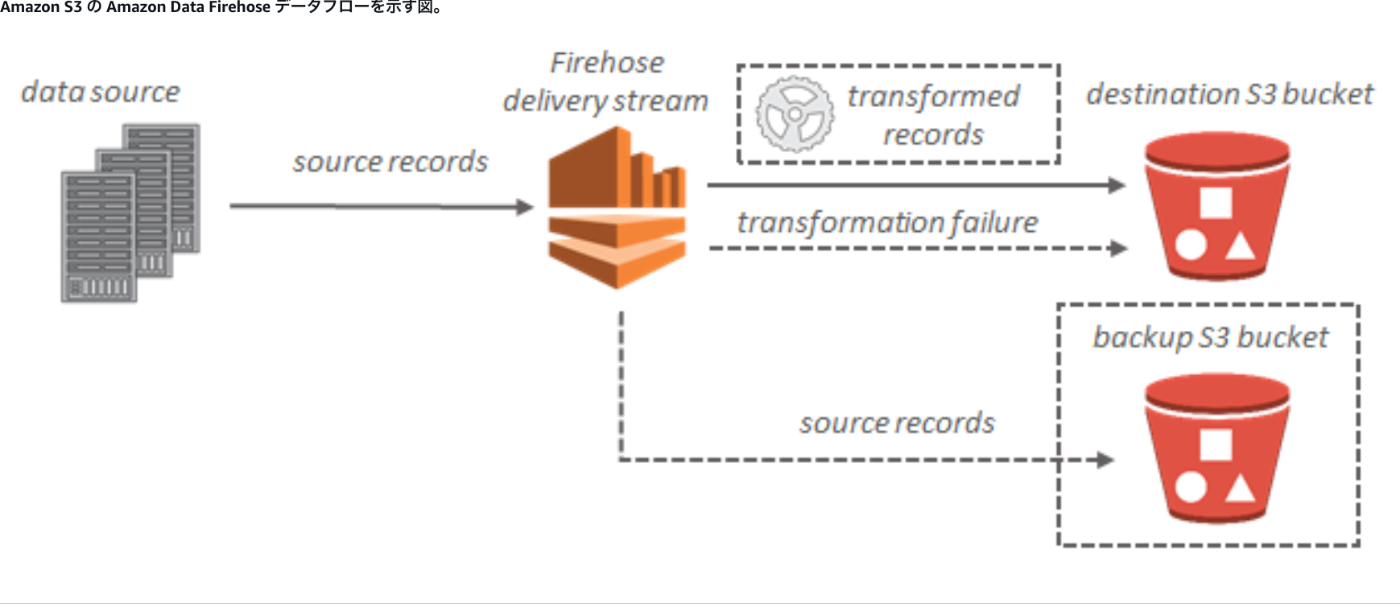
システムイメージ
全体の流れのイメージは以下の通りです。
AWS コンソールでの設定手順
1. ストリームの作成
AWS コンソールから Firehose のストリームを新規作成します。

2. ソースと送信先の選択
- ソース: ログなどの入力データを取り込む側
- 送信先: 処理後のデータを出力する側(今回は Amazon S3)

Firehose ストリームのソース
Firehose ストリームでは、データの送信元として以下のオプションが選択できます。
-
データベース: PostgreSQL や MySQL からデータ変更をキャプチャ
(※ Apache Iceberg テーブルへの送信のみ) - Direct PUT またはその他: アプリケーションから直接書き込む方法
- Kinesis データストリーム: 既存の Kinesis データストリームからの取り込み
-
Amazon MSK: Kafka クラスターからの取り込み
(※送信先は Amazon S3 のみ)
また、MySQL や PostgreSQL データベースをソースとして選択するオプションも用意されています。
Firehose ストリームの送信先
Amazon Data Firehose は、以下の送信先にデータを配信できます。
- Amazon S3
- Amazon Redshift
- Amazon OpenSearch Service / OpenSearch Serverless
- Apache Iceberg テーブル
- その他、Coralogix、Datadog、Dynatrace、HTTP エンドポイントなど
※なお、Logz.io は欧州(ミラノ)リージョンではサポートされていません。
レコードの変換・転換(オプション)
今回は、この機能は使用していません。
S3 送信先の設定
基本設定
- S3 バケット: 配信先となる S3 バケットを指定(新規作成または既存バケットを選択)
- S3 バケットプレフィックス(オプション): 配信データのファイル名やフォルダ構成を指定
詳細設定
-
S3 バケットエラー出力プレフィックス
エラー状態のデータ用プレフィックス
※ Firehose の動的パーティショニングを有効にする場合は必須です。 -
改行区切り文字
配信ファイル内のレコード区切りを指定します。 -
動的パーティショニング
Lambda 関数などを利用して、データのパーティション分割を実施可能です。 -
S3 バッファのヒント
配信前のバッファリング設定 -
圧縮・暗号化設定
GZIP、Snappy、Zip などの圧縮形式や、AWS KMS を利用したサーバーサイド暗号化の設定が可能です。 -
シリアル化設定
特に Amazon MSK をソースとする場合に、Kafka の各フィールド(値、キー、ヘッダー)の取り扱い方法を指定できます。
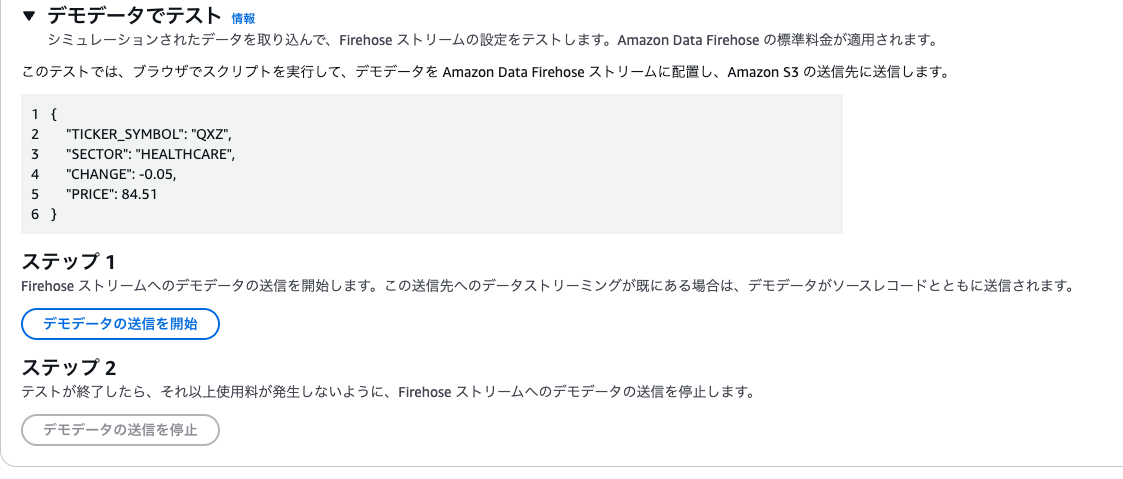
デモ実施
1. テストデータの送信
AWS コンソール上で「デモデータを送信」を実行し、約5秒後に「デモデータの送信を停止」をクリックすると、デモデータが設定したストリームに流れ込みます。
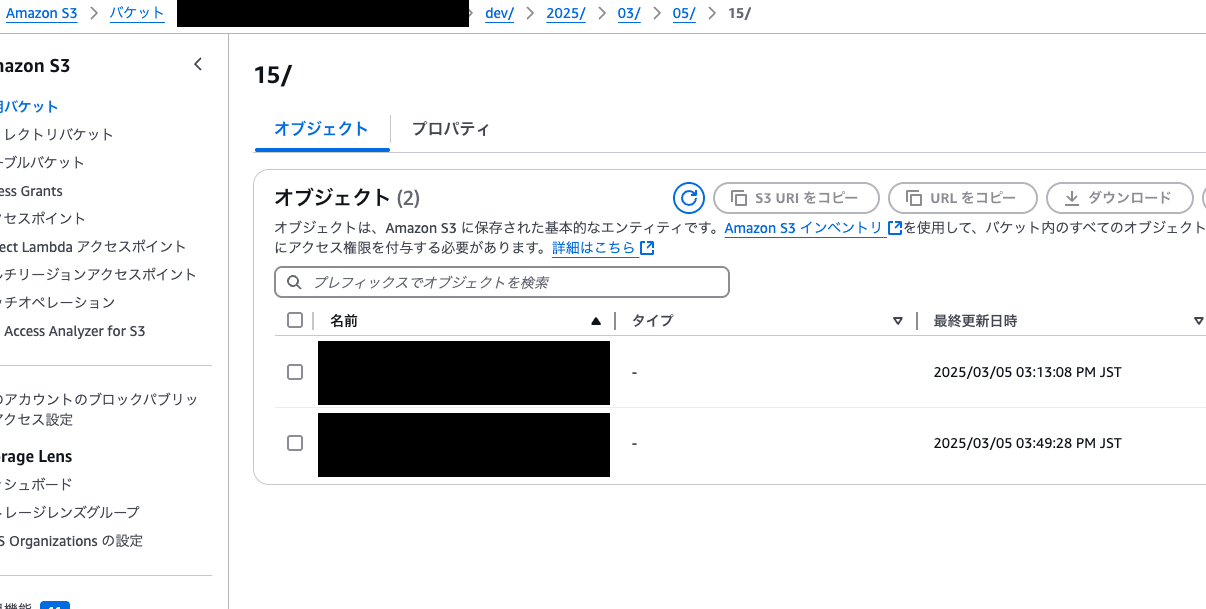
2. S3 への転送確認
S3 バケットにデータが正常に転送されたことを確認します。
AWS SDK の活用
Amazon Data Firehose には、AWS SDK を利用した API が用意されています。
詳細は 公式ドキュメント をご参照ください。
懸念点
使用用途としてS3に保存したログを検索などかけたいそうなのですが、S3に保存したものは日付のファイル毎でしか分けることができず。他の方法を考え中。
もしかしたらAWS athena で検索が容易になるかもしれないので調査中。
まとめ
今回、Amazon Data Firehose を利用したログ収集の実装方法と設定内容について学び、デモを通して動作確認を行いました。
Firehose を利用することで、複雑なインフラ管理を行うことなくリアルタイムなデータ取り込みと配信が可能になる点が魅力です。
今後、さらなるデータ変換や分析への応用など、拡張性の高さを生かして利用を検討していきたいと思います。
Discussion