WebSocket などの JSON を BigQuery に無限に溜め込むサンプル
本記事は 仮想通貨botter Advent Calendar 2023 25 日目の記事です。
この記事では Google Cloud Pub/Sub BigQuery サブスクリプションを利用して WebSocket などからの大量の JSON データをリアルタイムで BigQuery に溜め込む 為のサンプルを紹介します。
この記事を参考にして頂くことで、様々な取引所の WebSocket で配信されるデータ (約定など) を 手っ取り早く / なんでも / 雑に / 無限に BigQuery に投入することができます。 WebSocket と題していますが、REST API のレスポンスでも JSON であればなんでも可です。
BigQuery はコストさえ払えば無限のデータレイクとしても使えますし、データをあとで加工する為に未加工データを無料枠で一時保管しておく用途としても利用することが可能です。
前置き
こんにちは、まちゅけんです。 アドカレでは既に 16 日目でこちらの Zenn 本を投稿しました。
こちらの本の内容としてはデプロイに困っている方に向けてのソリューションとなっているのですが、自分が今年学んだ中で最も書きたい事ベースで出したので、割とニッチでお固めな内容となってしまっていました。
Merry Christmas 🎅🎄 ということで(?)、何故かやたらモチベーションがアップしていることもあり、ちょうど 25 日目の 2 ページ目が空いていました。 25 日目の記事では、botter の方々により広く有用な情報をアウトプットしてみようかと思います。
この記事では冒頭に書いたように WebSocket などからの大量の JSON データをリアルタイムで BigQuery に溜め込む 為のサンプルを紹介します。
既存の botter 向けデータレイクの参考記事としては、2022 年のアドカレで Yoshiso さんの AWS にてS3 + Athena を利用するものや、richwomenbtc さんのそれの GCP 版があります。
これらは S3 / GCS に時系列データを格安で保存する素晴らしい例です。 しかし DataFrame を作成してからアップロードしているというのもあり、WebSocket のなどように高頻度 (100ms 未満) で配信されるデータを突っ込む様な用途で使おうと思うと、DataFrame 作成の処理時間が配信頻度に対してネックになる場合があります。
その為、今回のソリューションでは WebSocket から配信された JSON を「JSON 文字列」としてそのままデータレイクに突っ込む というアプローチを行います。 このアプローチが優れている点としては ...
- JSON を生のまま突っ込めるので気持ちいい 😳
- つまり DataFrame に変換しづらい "半構造化データ" な JSON でも雑に投入することができる
- DataFrame を作成せず文字列としてそのまま投入するので、例えば主要銘柄の約定など WebSocket から高頻度で配信されるデータをそのまま投入しやすい
裏を返せば完全に未加工なデータを投入するというデメリットもありますが、今回利用する BigQuery は柔軟な JSON データのクエリなどもあります (後述) 。 ただしデータ投入・クエリの料金的には S3 / GCS のアプローチよりも基本的には高くなります。
アーキテクチャ
-
Cloud Pub/Sub BigQuery サブスクリプション
- Cloud Pub/Sub は Google Cloud におけるメッセージキューサービスです。
- BigQuery サブスクリプションを利用することでプログラム側では「BigQuery へのインサート処理」を書く代わりに「Pub/Sub への Publish 処理」を書くだけで手軽にデータを投入することができます。
- また BigQuery サブスクリプションは Publish したデータ以外に自動で時刻などのメタデータを付与してくれます。
- Google Cloud BigQuery
- Google Cloud におけるフルマネージド型の分析データ ウェアハウスです。 AWS では完全な互換サービスがありません 。
- フルマネージドなので、コストさえ払えば無限にデータを取り込むことが可能です。
- JSON 型カラム の機能があり、柔軟なデータ取り込み・クエリに対応しています。
- Google Cloud Compute Engine
- WebScoket からのデータを BigQuery サブスクリプション に Publish するプログラムを実行する為のコンピューティング環境です (AWS における EC2 と同じ)。
料金
今回の例を試す前に、Google Cloud の料金形態を理解しておきましょう。
- Cloud Pub/Sub BigQuery サブスクリプションによるデータの取り込みコストは ...
BigQuery サブスクリプションの料金は、すべての Google Cloud リージョンにおいて、サブスクリプションからの読み取り(サブスクライブ スループット)と BigQuery への書き込みに対して TiB あたり$50 です。
つまり 1 GB あたり $0.05 になります。 こちらは無料枠はありません。 配信頻度が非常に高いと思われる Binance USDⓈ-M BTCUSDT の WebSocket 約定 (trade ストリーム) を取り込んでいますが、1 日辺り 4~6 円ぐらいになっていました。
- BigQuery のストレージコストは ...
アクティブ ストレージ $0.020 per GB 毎月 10 GB まで無料。
上記 Binance USDⓈ-M BTCUSDT を一か月ほど取り込み、テーブル件数は 25,000,000 件ほどで、テーブルのストレージは 4.09 GB になっていました。 今回は無料枠の範囲内にはなってますが、増え続けた事を考えてコストを最適化したい場合はデータ加工後に削除することを検討しましょう。
- コンピューティングコストは ...
1 つの非プリエンプティブル e2-micro VM インスタンス(1 か月あたり)。次の米国リージョンのいずれかで利用できます。
ほぼ最小である e2-micro インスタンスなら 1 つ無料で作成できます。 今回実行するプログラムなら e2-micro インスタンスでも問題なく実行できます。 2 つ目の e2-micro インスタンスを建てたとしても大体 1,000 円以内です。
手順
大まかな流れとしてはこのような手順です。
- BigQuery でデータセット・サブスクリプションの宛先テーブルを作成する
- Pub/Sub のトピックと BigQuery サブスクリプションを作成する
- Cloud Shell でプログラムを試す
- Compute Engine にプログラムをデプロイする (任意)
botter の方は AWS しか利用してない方も多いと思うので、Google Cloud アカウントを持っていなければ開設しましょう。 最初は無料枠に加えて 90 日間 $300 分無料トライアルが貰えるのでひとまず上で説明したコストも抑えることができます。
BigQuery
まずは BigQuery の画面を開いて操作を行います。
https://console.cloud.google.com/bigquery
- データセットを作成します

データセット ID を指定します (例:datalake) 。
ロケーションは任意のリージョンを指定してください。

- テーブルを作成します

テーブル名を指定します (例:datalake) 。
スキーマで「テキストとして編集」をオンにして以下のテキストを張り付けます。subscription_name:STRING, message_id:STRING, publish_time:TIMESTAMP, data:JSON, attributes:JSON
これで BigQuery の準備は完了です!
Cloud Pub/Sub
次に Cloud Pub/Sub のサブスクリプション画面を開いて操作を行います。
https://console.cloud.google.com/cloudpubsub/subscription/list
- 新しいサブスクリプション作成します

- 同時に新しいトピックを作成します
サブスクリプション ID を指定します (例:bigquery-subscription) 。
トピック ID を指定します (例:bigquery-topic) 。

- その他のサブスクリプションの設定をします
BigQuery への書き込みを指定します。
先ほど作成したデータセットを指定します (例:datalake) 。
先ほど作成したテーブルを指定します (例:datalake) 。
黄色線部分の権限について怒られているservice-******@gcp-sa-pubsub.iam.gserviceaccount.comのアカウント名をコピーしておいてください。

メタデータを書き込むをチェックします。
有効期限なしに設定します。

** 作成を押す前に、権限の部分を対応します **。 - 新しいタブで IAM の画面を開いて Cloud Pub/Sub が BigQuery に書き込む権限を設定します
https://console.cloud.google.com/iam-admin/iam

新しいプリシンバルに先ほどの黄色線のアカウント名を張り付けます。
ロールを割り当てるでBigQuery データ編集者を割り当てます。

- Cloud Pub/Sub の画面に戻って作成を押下します

作成したサブスクリプションの画面が表示されていれば完了です!
Cloud Shell でプログラムを試す
ここで一旦、プログラムから作成した BigQuery テーブルと Cloud Pub/Sub のサブスクリプションを利用して実際にデータを取り込んでみましょう 🚀
ここでは Cloud Shell で作業してみます。 Google Cloud コンソール右上にあるこのアイコンからシェルを開いてください。


- 私のサンプルコードをクローンしてディレクトリを移動します
git clone https://github.com/MtkN1/bigquery-subscription.git \ && cd bigquery-subscription
サンプルコードのメインスクリプトは以下のようなコードになっています。 冒頭で紹介したような Binance USDⓈ-M BTCUSDT の WebSocket 約定を BigQuery に投入する処理になっています。
- Cloud Pub/Sub トピック ID をコピーします

- 環境変数
PUBSUB_TOPIC_IDを指定します
サンプルコードでは環境変数PUBSUB_TOPIC_IDから Cloud Pub/Sub トピック ID を読み込むようにしています。 以下コマンドの{YOUR_PUBSUB_TOPIC_ID}をコピーしたご自身のトピック ID に置き換えて実行してください。.envファイルにトピック ID が書き出されます。echo PUBSUB_TOPIC_ID={YOUR_PUBSUB_TOPIC_ID} >> .env - サンプルコードを起動する 🚀
サンプルコードには Dockerfile などが含まれているので、Cloud Shell に内蔵されている Docker コマンドで実行可能です。 以下のコマンドを実行すると BigQuery にデータが取り込まれます。
※ Google Cloud の認証ポップアップが表示されたら許可を押してください。docker compose up --build - BigQuery のテーブルを確認します
このような形でdataカラムに約定の JSON データが格納されているはずです 🎉
(データが表示されていなければ右上の更新を押してください)
publish_timeなどのメタデータも自動で付与されています。

- 確認ができたら Ctrl+C でプログラムを終了します
Cloud Shell は一時的な開発環境です。 シェルを閉じたらこのプログラムも停止します。 永続的にデータを投入し続けるには、Compute Engine インスタンスを作成してプログラムをデプロイする必要があります。
Compute Engine
- インスタンスへ SSH 接続する為のメタデータを設定する
- 無料枠で VM インスタンスを作成する (任意)
リージョンをus-west1(無料枠の中で日本から地理的に近い)
マシンタイムをe2-micro
ブートディスクを タイプ:標準永続ディスクサイズ:30GB - アクセススコープを設定する
Compute Engine から Cloud Pub/Sub にアクセス可能にする為にアクセススコープを「すべての Cloud API に完全アクセス権を許可」に設定します。 - インスタンスに SSH 接続する
- プログラムをデプロイする
上記手順で示した Docker コマンド (インスタンスに Docker のインストールが必要) や、nuhop または tmux コマンドなどでプログラムをデプロイしましょう。
デプロイ方法に関しても多岐にわたりますが、それこそ私のアドカレ 16 日目の記事が参考になるかもしれません。
クエリしてみる
SQL
取り込んだデータについては BigQuery JSON 型カラムの機能でクエリすることが可能です。
BigQuery のコンソール画面を開いてクエリを試してみましょう。 作成したテーブル (例: datalake) から「クエリ」を選択して SQL クエリのタブを開いてください。
以下の SQL を実行してみましょう。 単純に 1000 件の約定のデータを取得できます。
SELECT
*
FROM
`datalake.datalake`
LIMIT
1000
では次に WHERE 条件を付けて絞り込みを行います。 この条件ではテーブルから 数量が 1.0 枚以上の約定 を絞り込むことができます。
SELECT
*
FROM
`datalake.datalake`
WHERE
LAX_FLOAT64(data.q) >= 1.0
LIMIT
1000
-
data.qで JSON 型dataカラムのqキーを取得しています -
LAX_FLOAT64関数で文字列になっているqキーの数量を FLOAT に変換して>= 1.0の比較演算子で条件を作っています
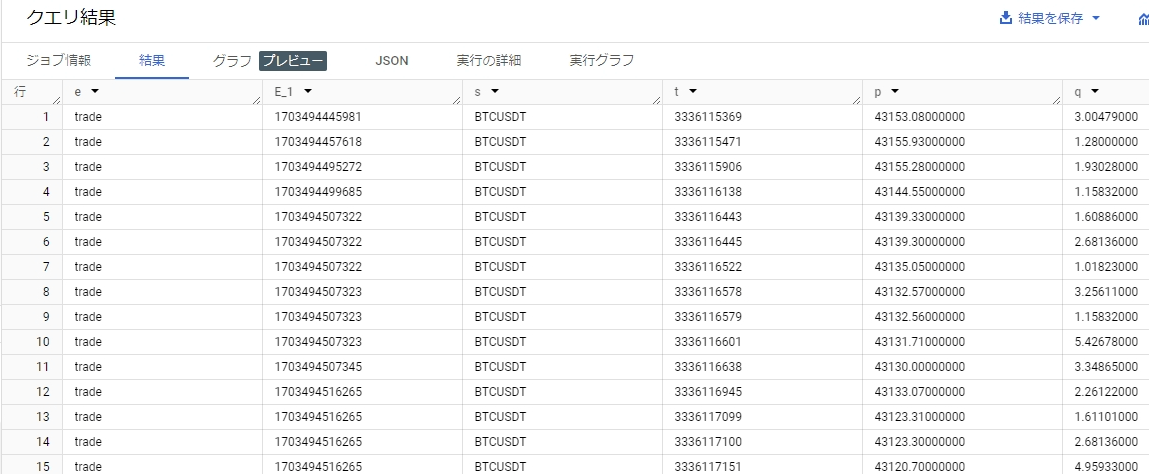
下のように数量 1.0 枚以上の約定を絞られているはずです。

このように、プログラム側では JSON 形式の 文字列 を Pub/Sub を通して BigQuery しただけですが、BigQuery の機能で data.q のように JSON を解釈してくれてクエリする ことができました。 これにより雑に突っ込んだ JSON を柔軟にクエリできることが今回の記事で紹介したかったソリューションとなります。
さらに、以下のようにカラム名を定義することで通常のテーブルのようにデータを平坦化することが可能です。
SELECT
JSON_VALUE(data.e) AS e,
JSON_VALUE(data.E) AS E,
JSON_VALUE(data.s) AS s,
JSON_VALUE(data.t) AS t,
JSON_VALUE(data.p) AS p,
JSON_VALUE(data.q) AS q,
JSON_VALUE(data.b) AS b,
JSON_VALUE(data.a) AS a,
JSON_VALUE(data.T) AS T,
JSON_VALUE(data.m) AS m,
JSON_VALUE(data.M) AS M
FROM
`datalake.datalake`
WHERE
LAX_FLOAT64(data.q) > 1.0
LIMIT
1000
JSON 型カラムの詳しい操作方法については、Google Cloud ドキュメントをご覧ください。
今回の Binance の約定は 1 行の JSON ドキュメント (オブジェクト) でしうたが、配列になっている JSON は JSON_QUERY_ARRAY などを利用して解釈することができます。
Storage Read API
SQL によるクエリではなく、テーブルのデータをそのままダウンロードして Python や Jupyter Notebook からデータを絞り込み・加工を行いたい場合は、クライアントライブラリの Storage Read API でを利用すると効率的にデータをダウンロードすることができます。 参考までに。
参考資料
今回の記事はこちらのドキュメントを嚙み砕いたチュートリアルとなっていました。
複数の取引所のデータを取り込んで区別する
今回のサンプルコードでは、1 つの WebSocket チャンネルのみデータを取り込んでいます。 サンプルコードを改修してチャンネルを増やしたり、producer 関数をコピーして別の取引所の WebSocket の接続を増やしたりしてみてください。
そうすると作成した 1 つのテーブルに様々なデータが投入されます。 1 つの取引所の複数チャンネルであれば何かしら区別することはできますが、完全に別の取引所のデータを入れると区別ができません。 なのでテーブルを増やして区別したいと思うかもしれませんが、テーブルを増やすと BigQuery サブスクリプションも都度作成する必要があって面倒です。
その際は attributes (属性) を利用することをおすすめします。 consumer 関数内の Publish するメッセージを作成する PubsubMessage クラスの生成時 attributes 引数を辞書で指定します。
pubsub_v1.PubsubMessage(data=message.encode(), attributes={"exchange": "binance"})
そうすることで、BigQuery テーブルの attributes カラムにデータが記録されます。 これで 1 つのテーブルでどの取引所の WebSocket からのデータなのかを区別することができます。
おわりに
最後までこちらの記事を読んで頂きありがうございました!
内容についての間違い、バグ、または質問などがあれば X アカウントにお気軽にお知らせください。
もしこの記事が気に入って頂けましたら Zeen や X アカウントのフォロー・いいねをよろしくお願いします 🙇♂️🙇♂️
データを色々溜め込んでよき botters ライフを 👋👋
Discussion