1.はじめに
初めまして。MTECの鈴木です。
本記事では我々が第38回人工知能学会全国大会(JSAI2024)で発表した「不動産価値推定における大規模言語モデルの活用可能性に関する検証」の内容について解説します。論文ではあまり言及していない部分についての補足や追加検証も行っておりますので、ぜひご一読ください!
この研究では、不動産(中古マンション)の価格を推定するタスクにおいて、大規模言語モデル(Large Language Models, 以下LLM)を用いることの有効性について検証しています。論文のアブストラクトは以下の通りです。
論文のアブストラクト
本研究では、不動産(中古マンション)の取引価格を推定するタスクに対する大規模言語モデル(LLM)の有効性について考察を行う。実務における不動産データ分析の課題として、①利用可能なデータが十分に無いこと、②データに欠損や表記ゆれなどが多いこと、が挙げられる。テーブルデータとして推定タスクを解く従来手法の場合、上記の課題に対応するためにコストをかけてデータを収集・整備する必要があった。一方で、LLMは地域に関する事前知識を有すること、Inputをテキストとして扱えることから、LLMを用いた推定では①や②の欠点を補えることが期待される。①や②に対するLLMのロバスト性について実験を行った結果、学習データに存在しない地域の物件や特徴量に表記ゆれがある物件に対して、従来の代表的なモデルよりもLLMの有効性が示唆される結果が得られた。
2.背景と課題
不動産価格の正確な推定は、都市計画や投資判断にとって重要となります。その際に、モデルを用いて不動産の属性情報から不動産価格を推定するといったニーズが存在します。
例えば、金融業界でも不動産投資信託(Real Estate Investment Trust,REIT)と呼ばれるものがあり、REITが保有する物件の不動産価値(の合計)などからREITの投資判断を行ったりしています。具体的には、NAV倍率と呼ばれる不動産価値に対する割安度を表す指標によって、REITの今の投資口価格(時価総額)が割高なのか割安なのかを判断しています。
しかしながらモデルを用いた価格の推定は時と場合によって難易度が高くなります。例えば、以下のようなケースの場合、従来の機械学習モデルでは新たな物件に対する推定精度が劣化する可能性が高いです。
- データ不足
地域によって取引データが少ないと過学習する可能性があります。
- 表記ゆれ
不動産に関する情報(ex.地名や最寄り駅など)に表記ゆれがあると、推定精度が劣化する可能性があります。例えば、人間の目であれば「自由が丘」と「自由ヶ丘」は同じと判断できますが、GBDTなど一般的な(言語モデルでない)機械学習モデルだと別のものとして認識してしまいます。
- 物件クラスの違い
一般的なマンションだけを学習データとしてモデルを作ると、高級マンションや訳ありマンションに対する推定精度は劣化する可能性があります。例えば4000万円~6000万円のマンションのみで学習したモデルが、8000万円や2000万円のマンションの価格を正しく推定するのは難しいと想像できます。
LLMが持つ事前知識を活用することで上記の課題を解決、すなわち「知らない地域の物件」や「地名などに表記ゆれがある物件」に対しても精度よく不動産価格を推定できることを期待しています。
3.提案手法
3-1.モデルのアーキテクチャ
以下の図のようにシンプルな形で、
LLMに不動産の物件情報を入力し不動産価格を出力させます。

3-2.学習方法
LLMの最終中間層にHead-Layerを付けて数値を出力する形にし、回帰タスクの形式、すなわち平均二乗誤差(MSE)を最小化するようにFine-tuningしています。
実装ではtransformersのAutoModelForSequenceClassificationを(num_labels=1とすることで)回帰モデルとして利用しています。
from transformers import AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained(checkpoint,num_labels=1,torch_dtype=torch.bfloat16)
このとき、利用するモデル(checkpoint)やtokenizerによっては、EmbeddingのresizeやPADトークンの扱いなどを修正する必要があるのでご注意ください。
また、細かい話になりますが、Fine-tuningの際はLoRA[1]という手法を使っており、Head-LayerだけでなくLLMの部分もチューニングの対象としています。その際は、デフォルト設定ではなく、LoRAでアダプター(target_modules)が付けられる全てのモジュールをチューニングの対象としました。特に、LLMにおける各トークンの埋め込みは不動産価格推定のための埋め込みになっていないため、少なくとも(デフォルトでは設定外になっている)"embed_tokens"をtarget_modulesに設定することがポイントとなります。
from peft import LoraConfig, PeftType, TaskType
#peftのパラメータ
peft_config = LoraConfig(
peft_type = PeftType.LORA,
task_type = TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1,
target_modules=["embed_tokens","lm_head","q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj","down_proj"],
)
3-3.利用したLLM
GPU1つでFine-tuningが可能かつ、日本の土地や不動産に関する事前知識を持っていそうなモデルの1つであるELYZA-japanese-Llama-2-7b-fast-instructを利用しました。
また論文の投稿後に登場したLlama-3-ELYZA-JP-8Bでも追試を行っています。
4.実験設定
4-1.データ
国土交通省の不動産取引情報から中古マンションのデータを利用しました。
各物件ごとにLLMに物件の属性情報をプロンプトとして入力し、物件の価格の推定を行います。LLMにテキストとして入力するので本来であれば前処理は不要なのですが、後述の従来手法とフェアに比較するために少し加工しています。例えば、建築年や面積などは数値情報として扱えるような形に加工しています。また、取引年(=不動産の売買があった時点)の情報は、将来的な運用を考えた際に未来の時点を入力することになってしまうため、経過年数(=取引年-建築年)といった形で加工を施しています。加工の有無およびカテゴリカルとしての取り扱いについては以下をご参照ください。
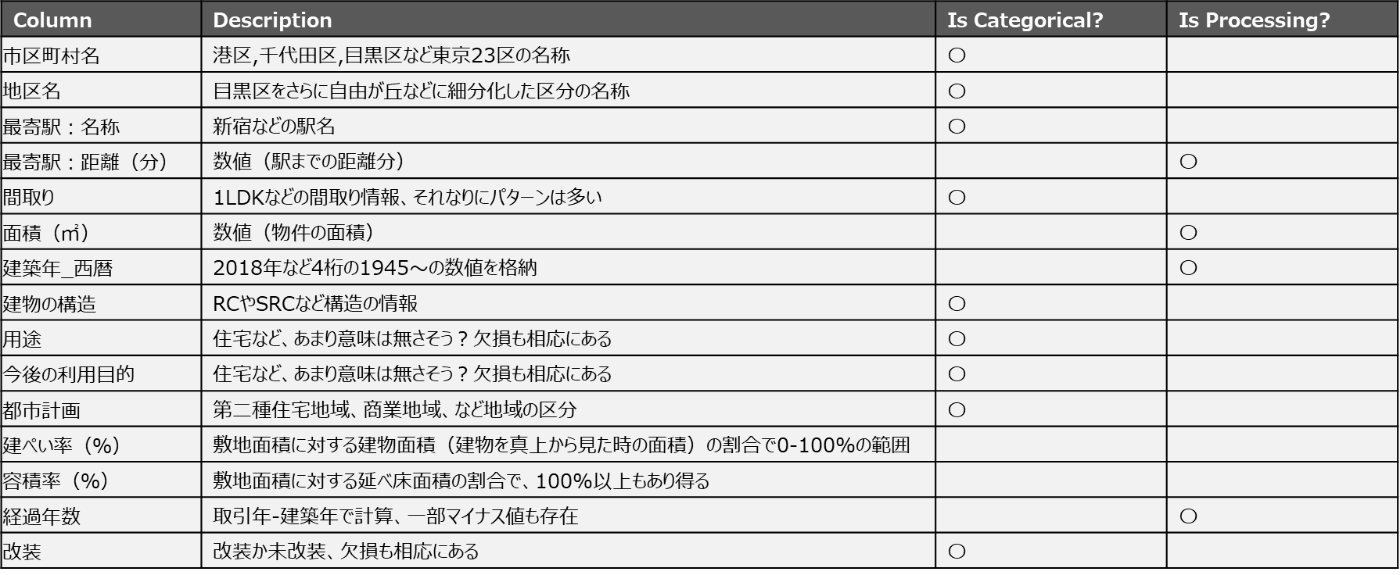
また、予測する価格については百万円単位にした後に対数値を取っています。これは、価格帯がかなり大きくばらつくので一般論として対数スケールにしているということ、LLMが事前知識として既に価格を知ってしまっているといったリークを避けること、といった2つの目的意識があります。
実際に、各物件の特徴量(=テーブルデータの1行に該当)をプロンプトとして以下のような形で入力をしています。学習の際はプロンプト文と対数価格(百万円)のペアを用いてモデルを学習し、推論の際はモデルにプロンプト文を入力することで推定値を出力させます。
LLMへの入力例

4-2.学習/検証データ
元々のデータ数はかなり多いのですが、少量データというシチュエーションを想定して、東京23区のデータを1000件ずつサンプリングしました。また、バイアスを除くためにサンプリングは5回試行しており、精度評価はその5回の平均値で見ています。
4-3.テストデータ
以下の5つのケースでそれぞれ1000件ずつデータを準備し、モデルを評価しました。Case0を除いて、分布外(Out-Of-Distribution:OOD)のデータセットとなっています。また特にCase3はOODの中でも、いわゆる補外(Extrapolation)のデータセットとなります。
- Case 0: 学習データと同様の物件
- Case 1: 学習データにはない新しい地域の物件(東京23区外、ex.八王子市や三鷹市)
- Case 2: 学習データにはない新しい地域の物件(大阪)
- Case 3: 東京23区内だが、学習データにはない価格帯の物件
- Case 4: Case0で地区や最寄り駅の情報を敢えて表記ゆれさせた物件
今回の実験では、Case0と比較してOODデータの精度の劣化が限定的であれば汎化性能が高い、という相対的な精度の評価を目的としています。
4-4.比較対象
従来手法として以下の代表的なモデルとの比較を行います。
BERTについてはLLMが持つ事前知識の必要性について確認する意図で比較しています。
- LightGBM: 決定木ベースの機械学習モデル
- OLS: 線形回帰モデル(非カテゴリカル変数のみ利用)
- BERT: 提案手法と同じアーキテクチャでLLM(Elyza)ではなくBERTを利用
BERTもLLMと同様に日本語に対応しているtohoku-nlp/bert-base-japanese-v2を利用しました。
4-5.評価方法
論文では、MSEとMERの2つの評価指標を設定しました。
- MSE(Mean Squared Error): 平均二乗誤差
- MER(Median Error Rate): 中央誤差率
5.結果と考察
5-1.実験結果
基本的にMSEとMERの傾向は同じだったのでMSEの結果だけ紹介します。
MSEスコア
| Case0 | Case1 | Case2 | Case3 | Case4 | |
|---|---|---|---|---|---|
| LightGBM | 0.060 | 0.513 | 0.569 | 1.775 | 0.101 |
| OLS | 0.139 | 0.444 | 0.566 | 4.001 | 0.139 |
| BERT_Reg | 0.076 | 0.586 | 0.592 | 1.686 | 0.076 |
| Elyza_Reg | 0.069 | 0.245 | 0.225 | 1.900 | 0.078 |
| Llama3Elyza_Reg | 0.058 | 0.222 | 0.223 | 1.677 | 0.062 |
5-2.考察
-
提案手法(Elyza_Reg)
提案手法はCase0ではLightGBMに劣るものの、Case1,2(新しい地域)やCase4(表記ゆれがあるデータ)での精度劣化が限定的であり、LLMが利活用できる可能性を示唆しています。特にCase1,2はBERTだと精度が悪いことからも、LLMの事前知識も重要なポイントとなっている可能性があります。
-
追試(Llama3Elyza_Reg)
さらに高精度なLlama3Elyzaに置き換えると、Case0でもLightGBMの精度を上回っており、なおかつCase1,2,4でも提案手法(Elyza_Reg)より精度が向上しています。このことから、より良い事前学習モデルをベースに使うとさらに推定精度が良くなることが示唆されます。
5-3.モデルの限界
-
外挿性能
MSEの結果を見てわかるように、Case3(外挿)はLLMを用いても精度がかなり悪く、今回のアプローチ方法でも上手くいかないことが分かります。やはり学習データに存在しない価格帯の物件に対しての推定は難しく、その他のアプローチを考える必要がありそうです。例えば、Fine-tuning後でもある程度プロンプトに自由度を残すことで、GeoLLM[2]で行っているように物件に関わるテキスト情報などを自由に追加で入力できるようなアプローチを採用するなどの方向が考えられます。
-
学習コスト
今回はデータ数=1000件で学習していますが、データ数が増えると計算リソースがより必要になります。LightGBMやOLSと比較して、圧倒的に計算時間の観点では劣るためそこがトレードオフとなっています。従って、少量データが学習に利用可能かつ推論対象は分布外データというシチュエーションにおいてLLMの活用を考えるのが合理的かと思われます。
6.おわりに
本研究では、不動産価格予測における課題に対して、LLMを活用することで解決できる方法を提案しました。新しい地域やデータの表記ゆれに対するアプローチ方法は、LLMならではの方法で親和性が高いと考えられます。一方で、データクレンジングにコスト(人手)をかけることができ、十分にデータが存在する場合は従来のテーブル形式のタスクとしてGBDTのモデルなどを使った方が計算コスト的には良いと考えられます。
今回の研究は不動産領域でしたが、MTECでは他にも生成AIやLLMの金融領域への利活用に関する研究を行っています。これまでの活動一覧については、以下のサイトをご覧ください。
また、MTECにご興味のある方は、ぜひ以下の採用サイトをご覧ください。
最後までお読みいただき、ありがとうございました!
7.参考文献
- Edward J. Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models", ICLR 2021.
- Rohin Manvi et al., "GeoLLM: Extracting Geospatial Knowledge from Large Language Models", ICLR 2024.

Discussion