【個人開発】技術書特化の読書管理&コミュニティ「TecuTecu」を支える技術
技術書・専門書に特化した本選びや読書管理、レビュー、マークダウン記法での読書メモとかができる読書コミュニティTecuTecu - テクテク - を作って公開したので、機能の説明や使用してる技術を書きます。
作ったもの

はじめに
技術書や専門書特化のレビューコミュニティサイトが欲しいなと思ったのが動機です。今この記事を読んでる方はもしかしたら、Zenn や Qiita, 公式ドキュメントを読んで、あまり技術書とか読まないかもしれません。しかし、体系的に知識を入れたいとか、マネジメントやデザイン、資格取得など、プログラミング系以外の分野を勉強したい、といったときなど、本で学習したいときはあるのではないでしょうか。
そんなとき、技術書や専門書など学びを目的とした書籍に特化したサービスがあれば、質の高いレビューが集まるのでは、という仮説のもと作りました。これから紹介する機能などをみていただくとわかりますが、レビューサイトを作るという話だったのに、色々機能を付け足していってしまい、コンセプトがレビューサイトから読書コミュニティとなりました。やはり開発は膨張する...
ということで、サービスの中身や使用している技術などに興味のある方はぜひご覧ください。
機能
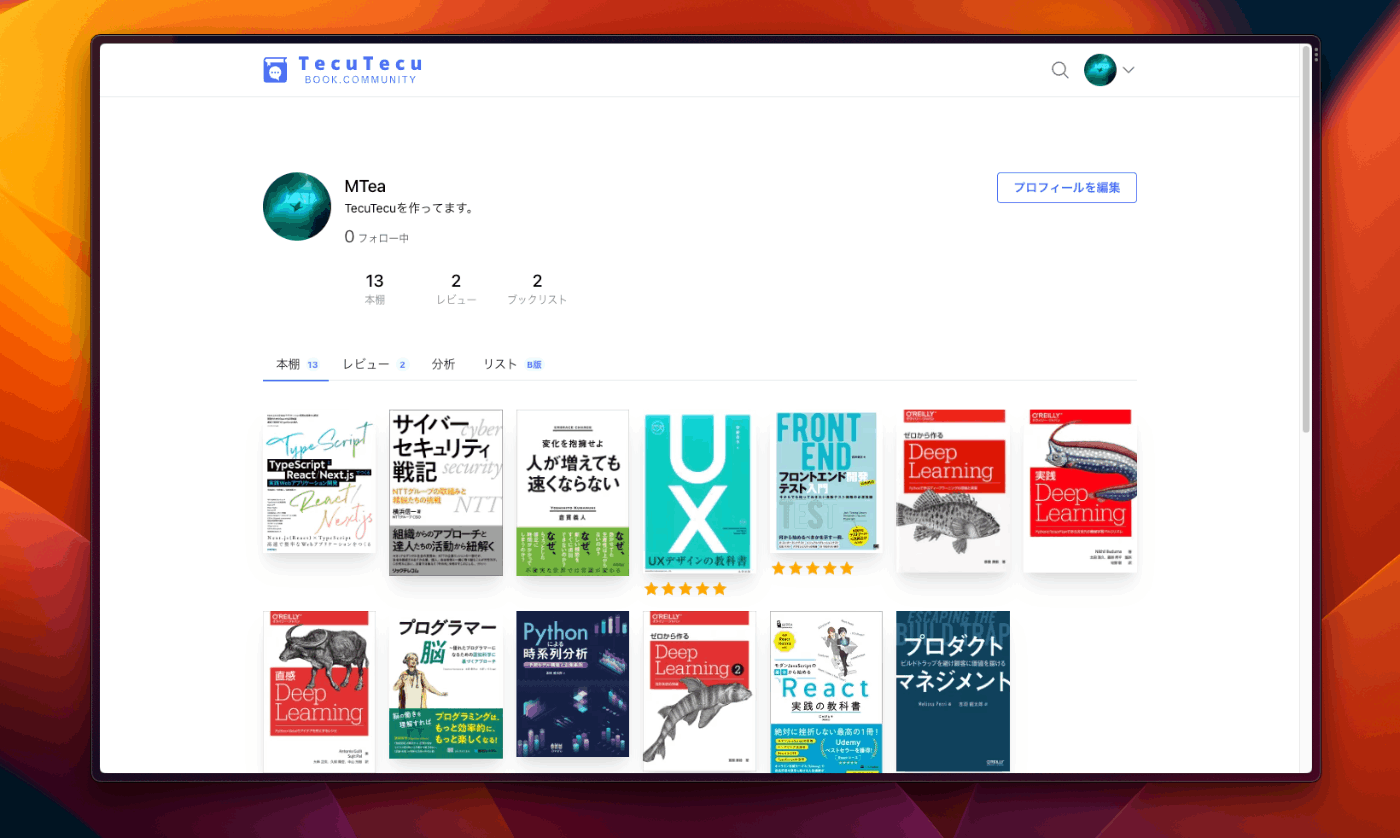
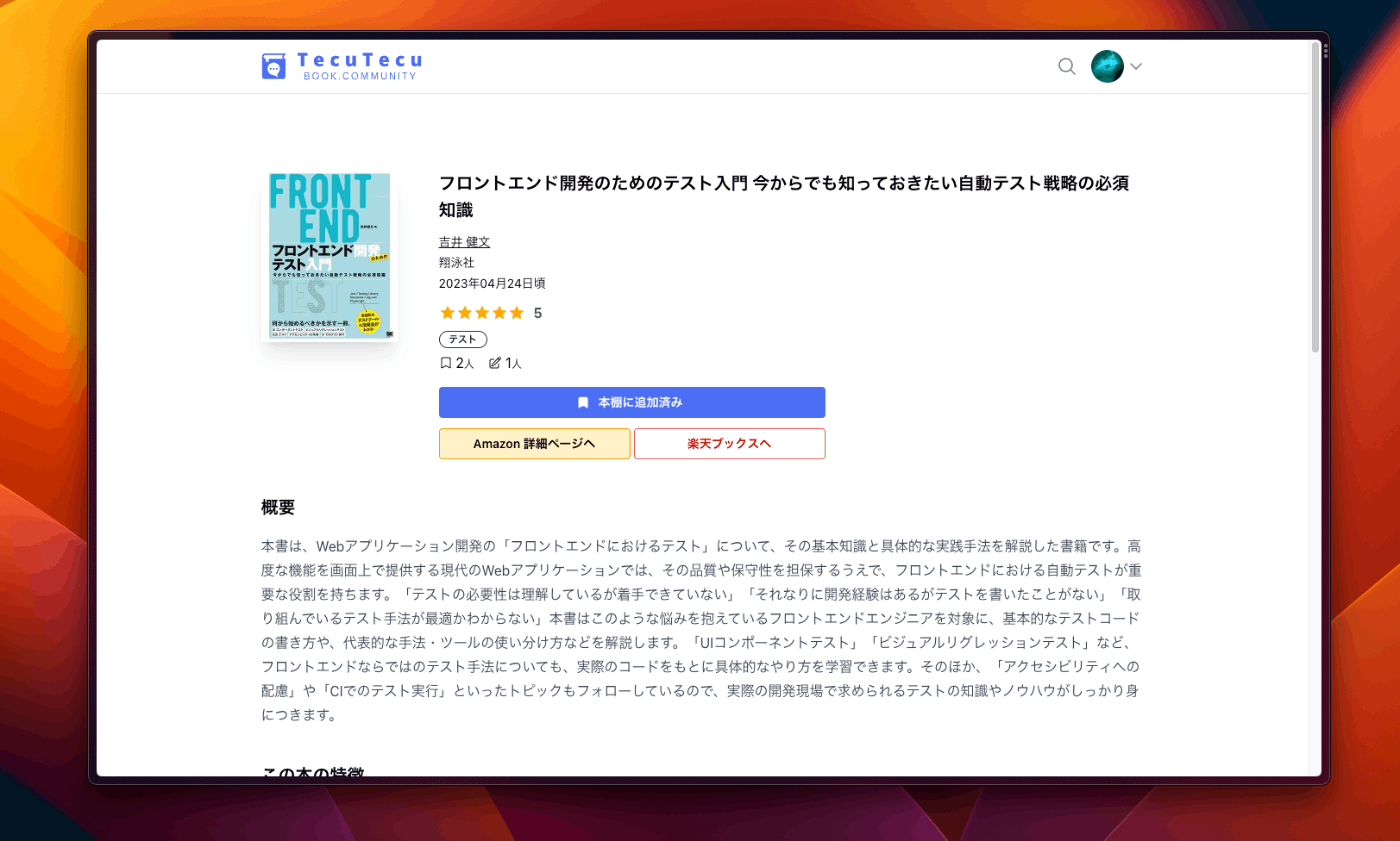
技術書や専門書等の書籍限定レビュー・記録共有ブックコミュニティです。
- ジャンル別検索、新刊情報
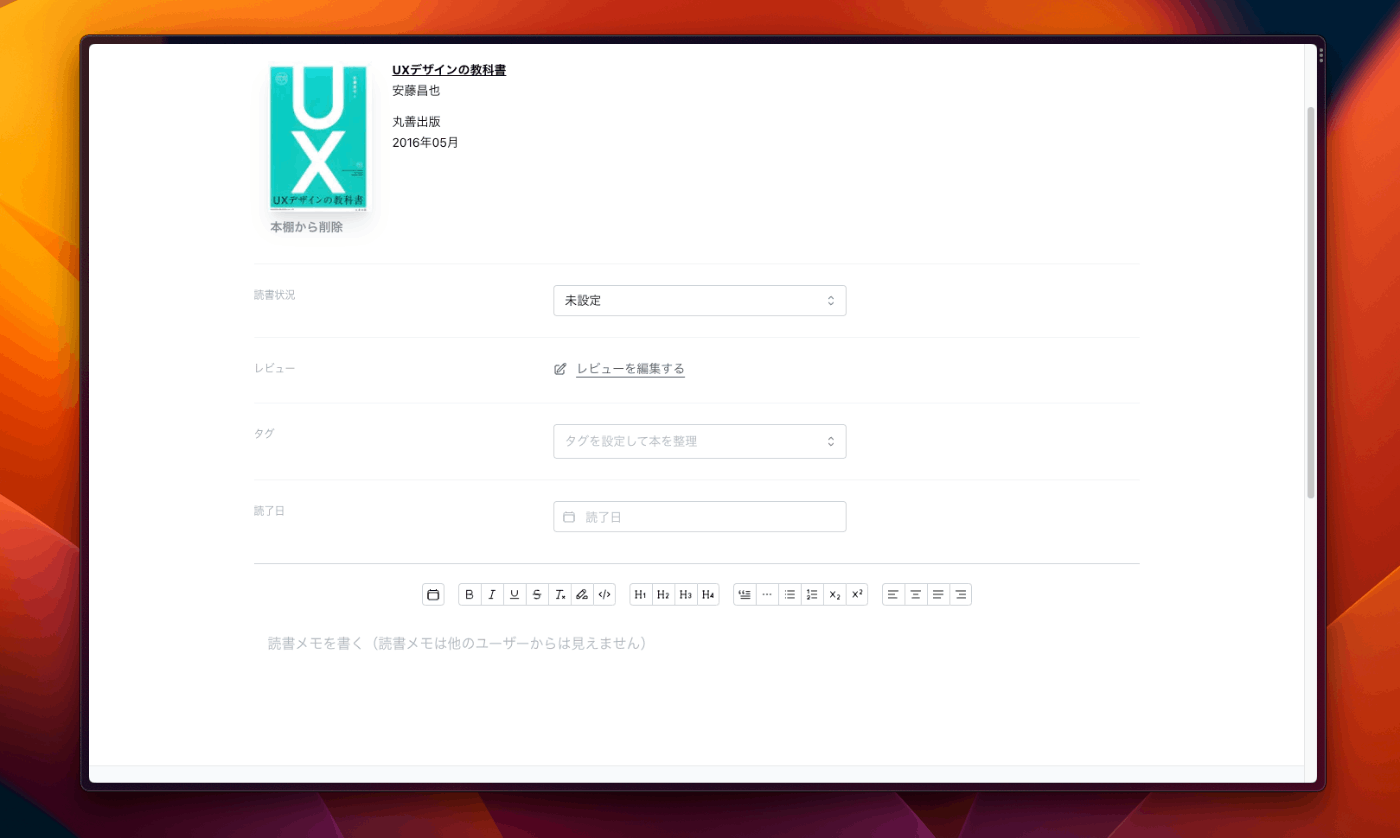
- レビュー
- マークダウン記法が使える読書メモ
- 本棚機能
- 本棚の本からリストを作れるブックリスト
- フォロー機能
上記のように何か色々機能があります。詳しくはサイトの方に行ってもらえると、大体わかると思います。
技術書特化のブク◯グといえば分かりやすいかもしれません。



技術スタックとか
技術スタック
- アプリケーション
- インフラ
アプリケーションの構成を見て気づいた方もいるかと思いますが、T3 Stackで作成しています。
また、以下記載していくライブラリ等の選定の理由にも T3 Stack公式で推奨されているものから選びました。
T3 Stack については、別記事に書こうと思っていますが、簡単に素早くプロトタイプを作成するときなどのケースで便利なのではないかと思います。
状態管理
今のところ、グローバルな状態管理のライブラリは使っていません。
基本的に、tRPC が React Query を使用しているので、サーバーから取得したデータは React Query で管理しています。
UIライブラリ
Mantine を使用しています。採用理由は、Rich text editor があったからです。マークダウン記法での読書メモを実装したくて選びました。
Mantine の Rich text editor は、WYSIWYG エディターで有名な Tiptapで実装されています。素の Tiptap を使うよりも簡単に組み込めるようになるみたいです。注意点として、Mantine の公式ドキュメントに記載のあるとおり、スタイルを変更するとか、onChange や onBlur といった関数の使い方など、詳細を見る場合は、Tiptap の方のドキュメントを探して読まないといけません。
他にも Mantine は、豊富な hooks やマイナーそうなコンポーネントなど、痒い所に手が届く感じでかなり助けられました。読書メモの自動保存にも Mantine の use-debounced-state などを使用して実装しています。
T3 Stack の一つである Tailwind CSS と Mantine の相性は悪くはないですが、良くもないので、設定が必要になります。
バックエンド
DB は PlanetScale、ORM に Prisma、フロントエンドとバックエンド間でのやりとりは tRPC を使っています。
PlanetScale と Prisma については、以下の記事が参考になります。
レンダリング
基本どのページもCSRです。書籍詳細ページなどは SSR にした方が良いのですが、以下の理由があって、まだ実装できていません。
- T3 Stack の公式が SSR を推奨していない
- tRPC で SSR を実装する場合、実装が少し面倒
- ISR は、Vercel からいつ移動するかわからない(コスト的な理由で)ので、出来ればしたくない
とはいっても、CSR だと色々デメリットはありますし、何より OGP で困ります。
例えば TecuTecu には、マイページで登録した技術書を一覧で見れる本棚がありますが、この URL をSNSで共有などした際に、OGPのタイトルは「〇〇さんの本棚」と表示される方がUX的には良いはずです。しかし、CSR だと当然ユーザー名が取得されていないので、「undefinedさんの本棚」とかになります。

なので、マイページだけは SSR にしています。これで下のように OGP が適切に表示されるようになりました。動的 OGP 画像などはまだ未実装ですが、OGP タイトルはユーザー名が適用されています。 しかし、初回アクセス時に 5.0s くらいの時間ロードがかかるようになってしまいました。Vercelや PlanetScale のリージョンは Japan で、PlanetSclae のダッシュボードを確認しても特に時間がかかっているクエリはなさそうなので、原因がわかっていません。単純に SSR の問題なのか、高速化する方法があるのかまだ調査中です。時間がかかるのは初回レンダリングなので、改善できるまで5秒だけ待っていただけると...。
書籍情報の取得
楽天の API を使用しています。本当は Amazon の Product Advertising API(PA-API) を使いたいのですが、こちらはまずアソシエイト・プログラムの審査に合格しないと使用できないため、楽天の API を使いました。
具体的には API を叩いて取得した情報を DB に保存するスクリプトを組んでローカルで実行しています。自動化するとか色々他に方法はあると思いますが、使われるかわからないサービスでそこまでするコストを割けませんでした。
楽天のAPIは下記で試すことができます。
スクリプトは例えば以下のような感じです。楽天の API は、ページネーションに対応した形で来るので、ループするようにして、複数回叩く必要があります。下記のコードは書籍 API のジャンル 001005 を指定して API を取得しています。
import { PrismaClient } from '@prisma/client';
import dotenv from 'dotenv';
dotenv.config();
const prisma = new PrismaClient();
const getBooks = async () => {
const rakutenAppId = process.env.RAKUTEN_APP_ID;
let url = `https://app.rakuten.co.jp/services/api/BooksBook/Search/20170404?format=json&booksGenreId=001005&page=1&applicationId=${rakutenAppId}`;
const initialResponse = await fetch(url);
const initialData = await initialResponse.json();
const pageCount = initialData.pageCount;
for (let currentPage = 1; currentPage <= pageCount; currentPage++) {
url = `https://app.rakuten.co.jp/services/api/BooksBook/Search/20170404?format=json&booksGenreId=001005&page=${currentPage}&applicationId=${rakutenAppId}`;
const response = await fetch(url);
const data = await response.json();
const formattedBooks = data.Items.map((item: any, index: number) => {
return {
id: (index + 1).toString(),
title: item.Item.title,
subtitle: item.Item.subTitle,
description: item.Item.itemCaption,
publisher: item.Item.publisherName,
image: item.Item.largeImageUrl,
isbn: item.Item.isbn,
publishedAt: item.Item.salesDate,
rakutenUrl: item.Item.affiliateUrl,
authors: item.Item.author.split('/').map((name: string) => ({
name: name.trim(),
})),
};
});
console.log(formattedBooks);
for (let book of formattedBooks) {
const authorEntities = await Promise.all(
book.authors.map((author: { name: any; }) =>
prisma.author.upsert({
where: { name: author.name },
update: {},
create: { name: author.name },
})
)
);
const existingBook = await prisma.book.findUnique({
where: { isbn: book.isbn },
});
if (!existingBook) {
const createdBook = await prisma.book.create({
data: {
title: book.title.substring(0, 250),
subtitle: book.subtitle.substring(0, 250),
description: book.description,
publisher: book.publisher.substring(0, 250),
image: book.image,
rakutenUrl: book.rakutenUrl,
isbn: book.isbn,
publishedAt: book.publishedAt,
},
});
for (let author of authorEntities) {
await prisma.authorBook.create({
data: {
authorId: author.id,
bookId: createdBook.id,
},
});
}
console.log("Created book:", createdBook);
} else {
console.log("Book already exists:", existingBook);
}
}
}
};
getBooks();
ジャンル 001005 は、コンピュータ系のジャンル番号で、これを指定することで、全体の書籍ではなく技術書や専門書の分野の書籍だけを取得しています。ただし、上限が 3,000 件なので、全ての技術書を一度の実行で取得することはできないため、クエリの指定方法を変えた他のスクリプトを叩いたりして、十分な情報を取得するようにしました。ただ、まだ登録されていないものはあるので、レビューしたい本などが探してもない場合は、お問い合わせなどから教えてもらえると登録します。
おわりに
読んでいただきありがとうございました。T3 Stack での開発や書籍 API から DB に保存する方法など、詳細な技術やコードに関してもそのうち書きたいと思っています。
初めての個人開発なので、機能面や SEO、パフォーマンス含めて至らないところがあると思いまが、改善していこうと思いますので、ぜひ TecuTecu - テクテク - を使ってみてください。
フィードバックやリクエスト、質問等歓迎です。できれば書籍のレビューお願いします🙏
Discussion