Colab で Kaggle (N番煎じ)
この記事はKaggle Advent Calendar 2021の6日目の記事です.
はじめに
この記事では Google Colabratory (通称colab) を使って Kaggle に挑戦するためのパイプラインを作るとういことをします. パイプラインといっていますが,実際には学習・推論・提出での枠組みというような感じです.
ネット上には数々の colab with kaggle の記事や kaggle code がありますが,今回はそれらの N番煎じとなることをご容赦ください..
colab で kaggle のコードコンペ参加したい人,独自の上手いディレクトリ構成案や実験管理方法が思い浮かばない人なんかに参考になればと思っています.逆に自分のコンペ取り組み環境がととのってたり,独自のパイプラインをお持ちの方にはあまり参考になることはないかもしれませんm(__)m
作ったパイプラインの特徴としては,
- colab と kaggle code で全く同じコードが使える
- ディレクトリの依存関係がない
- コードコンペでもストレスなくサブミットできる
- colab の複数セッションによる クロスバリデーションの並列学習ができる
くらいです.
この記事の内容は以下の通りです.
- Google Colabratory とは
- kagge code competition とは
- パイプラインを作る
- code competition でサブミット!
colab の始め方から kaggle のコードコンペでサブミットするまで頑張ります.大変長くなっていますがどうぞよろしくお願いします.今回実際に提出までするコードコンペは CommonLit Readability Prize です.
Google Colabratory とは
google colabratory (通称colab) は,ブラウザから Python を記述、実行できるサービスです.自分の google drive に colab notebook を作成するだけで環境構築不要でGPUもTPUも使える素晴らしいサービスです.現在は無料版colab,colab pro, colab pro+ の三種類が存在しています.この記事の内容は,おそらくどのcolabでも対応していると思いますが,私は執筆時点で colab pro+ を使っていました.
早速自分の google drive に colab notebook を作成してみます.
今回作るパイプラインも,これだけ自分で作ればあとは良しなにしてくれる物なので,この
MyDrive/CommonLit-Readability-Prizeフォルダ/Notebooksフォルダ/colab notebook の形が基本となります.
colab の特徴として,/content.という drive とは別の場所で colab が実行されており,その colab notebook のランタイム(セッション)がリセットされると content内に保存したデータやモデルはすべて消し去られてしまいます.
とはいえ,colab で drive をマウントすることで drive にあるフォルダへのデータ保存も簡単にできるので,普通に使うのに支障はほとんどないと思います.
また,今回の記事では kaggle api も使用するので,事前に api token の取得が必要です.取得方法などは別記事を参照ください.
Kaggle Code Competition とは

画像の左上のように code competition とあるコンペがコードコンペと呼ばれるものですね.
今回のReadabilityコンペは,kaggle code 上で (学習 + )推論を実行し,その実行の結果出力された予測値ファイルを提出するというものでした.コードコンペにも色々あると思いますが,一番オーソドックスなのがこの形のものなのではないでしょうか.
提出用コードの実行時間などの制限があるので,コンペ参加者は学習用のコードと提出用のコードをわけることが多いと思います.robeta base baseline [train],roberta base baseline [inference]みたいな感じで kaggle codeに載っているのをよく見ます.
今回作成したパイプラインは,学習部分をcolabで行い,得られた学習済みモデル等を使ってkaggle code上で推論を実行するとこを想定しています.
パイプラインを作る
- colab と kaggle code で全く同じコードが使える
- ディレクトリの依存関係がない
- コードコンペでもストレスなくサブミットできる
- colab の複数セッションによる クロスバリデーションの並列学習ができる
こんなパイプラインを目標に作っていきます.
次からは実際にコードを書いて Baseline-001.ipynbを完成させていきたいと思います.
運用時には1実験1notebookで使っています.この記事で書いたコードは削れるところは削って簡略化してますのでご注意ください.
Config
最初に,notebookで行う実験やその他諸々の設定をします.
class Config:
name = "baseline-001"
only_inference = False
model_name = "roberta-base"
learning_rate = 1e-5
max_length = 256
epochs = 8
batch_size = 16
n_fold = 5
trn_fold = [0, 1, 2, 3, 4]
seed = 2022
target_col = "target"
debug = False
# Colab Env
upload_from_colab = True
api_path = "/content/drive/MyDrive/kaggle.json"
drive_path = "/content/drive/MyDrive/CommonLit-Readability-Prize"
# Kaggle Env
kaggle_dataset_path = None
後々説明がありますが,Colab Env の api_path は kaggle api token のパス,drive_pathはNotebooksフォルダが配置されている元フォルダのパスを指定します.また,kaggle_dataset_pathはkaggle code 上で推論コードを実行するときに指定するので,colabで実行する分には関係ありません.
-
name: 実験の名前 -
only_inference: 学習はせず,推論だけ実行するなら True -
model_name: 今回は roberta-base と呼ばれるモデルを使います -
learning_rate: 学習率 -
max_length: 最大単語数 -
epochs: エポック数 -
batch_size: バッチサイズ -
n_fold: 今回は 5fold cross validation を行います -
trn_fold: 例えば[0]を指定すると,最初のfoldを予測対象とした学習のみ行われます.大きいモデルを使って5foldすべての結果を得るのに時間がかかりすぎるの避けて,fold 一つの結果だけでも見たい!学習時間を減らしたい!というときに使うイメージがあります. -
seed: 乱数固定用 -
target_col: 目的変数名 -
debug: debug モードの on/off
Library
次に notebook 内で使うライブラリをインポートします.
import os
import json
import warnings
import shutil
import logging
import joblib
import random
import datetime
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm.auto import tqdm
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras import backend as K
Colab と Kaggle Code 上の環境の違いから,Kaggl では問題なくインポートできるけど,Colab だとできないライブラリもあるので,そういうものはまた後でインポートしようと思います.
Utils
便利な関数たちを用意しておきます.と言っても今回は2つだけでした.
class Logger:
"""参考) https://github.com/ghmagazine/kagglebook/blob/master/ch04-model-interface/code/util.py"""
def __init__(self, path):
self.general_logger = logging.getLogger(path)
stream_handler = logging.StreamHandler()
file_general_handler = logging.FileHandler(os.path.join(path, 'Experiment.log'))
if len(self.general_logger.handlers) == 0:
self.general_logger.addHandler(stream_handler)
self.general_logger.addHandler(file_general_handler)
self.general_logger.setLevel(logging.INFO)
def info(self, message):
# display time
self.general_logger.info('[{}] - {}'.format(self.now_string(), message))
@staticmethod
def now_string():
return str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
def seed_everything(seed=42):
"""参考) https://qiita.com/kaggle_grandmaster-arai-san/items/d59b2fb7142ec7e270a5"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
Logger は適当な log を txtファイルに出力させるためのもの,seed_everything はシード固定用ですね.
SetUp
今回のnotebookで一番肝心なところだと思っているセットアップ部分です.ここでデータのロードや,ディレクトリの設置などを行います.少し長いので,小分けにしてみていきたいと思います.
COLAB = "google.colab" in sys.modules
このコードで Colab 環境なのか Kaggle 環境なのかを判別しています.
if COLAB:
print("This environment is Google Colab")
# mount
from google.colab import drive
if not os.path.isdir("/content/drive"):
drive.mount('/content/drive')
# import library
! pip install --quiet transformers
! pip install --quiet iterative-stratification
! pip install --quiet tensorflow-addons
# use kaggle api (need kaggle token)
f = open(Config.api_path, 'r')
json_data = json.load(f)
os.environ["KAGGLE_USERNAME"] = json_data["username"]
os.environ["KAGGLE_KEY"] = json_data["key"]
# set dirs
DRIVE = Config.drive_path
EXP = (Config.name if Config.name is not None
else get("http://172.28.0.2:9000/api/sessions").json()[0]["name"][:-6])
INPUT = os.path.join(DRIVE, "Input")
OUTPUT = os.path.join(DRIVE, "Output")
SUBMISSION = os.path.join(DRIVE, "Submission")
OUTPUT_EXP = os.path.join(OUTPUT, EXP)
EXP_MODEL = os.path.join(OUTPUT_EXP, "model")
EXP_FIG = os.path.join(OUTPUT_EXP, "fig")
EXP_PREDS = os.path.join(OUTPUT_EXP, "preds")
# make dirs
for d in [INPUT, SUBMISSION, EXP_MODEL, EXP_FIG, EXP_PREDS]:
os.makedirs(d, exist_ok=True)
if not os.path.isfile(os.path.join(INPUT, "train.csv.zip")):
# load dataset
! kaggle competitions download -c commonlitreadabilityprize -p $INPUT
# utils
logger = Logger(OUTPUT_EXP)
まずcolab環境下でのセットアップです.
#mount で自分の google drive をマウントします.GUIの方でマウントしたほうが,何度もマウントする必要がなくなりストレス軽減になるので個人的にはそちらを使ってます.
#import library では colab にもともと入っていないライブラリをインストールします.
#use kaggle api で,事前に取得したkaggle api tokenを使えるようにセッティングします.こちらの記事を参考にしました.
#set dirsと#make dirsでディレクトリを設置します.#load datasetでは,kaggle apiを用いてコンペティションのデータをダウンロードし,Inputフォルダにぶち込んでいます.
ここで,ディレクトリを設置前のディレクトリ構成が
MyDrive
├── CommonLit-Readability-Prize
│ └── Notebooks
│ └── Baseline-000.ipynb
└── kaggle.json
こんな感じ.今回はMyDrive下にコンペティション参加用のディレクトリを作っています.いたってシンプルでしたね.上で書いたコードを実行すると,
MyDrive
├── CommonLit-Readability-Prize
│ ├── Input
│ │ ├── sample_submission.csv.zip
│ │ ├── test.csv.zip
│ │ └── train.csv.zip
│ ├── Notebooks
│ │ └── Baseline-000.ipynb
│ ├── Output
│ │ └── baseline-001
│ │ ├── fig
│ │ ├── model
│ │ └── preds
│ └── Submission
└── kaggle.json
こんな感じでけっこう増えました.新しく増築されたのはInput,Output\baseline-001,Submissionの3つです.
-
Inputフォルダにはダウンロードしたコンペティションデータが格納されています. -
Outputフォルダには,EXP(Config.name か colab notebook の名前)をキーにした新しいフォルダが notebook ごとに作られ,その下に図などを保存するfigフォルダ,学習済みのモデルなどを保存するmodelフォルダ,oof や test の予測値を保存するpredsフォルダも同様に作られます. -
Submissionフォルダには提出用の csv ファイルが保存されます.
Output\EXPのフォルダは,Kaggle Code の出力を参考にしています.notebook ごとに outputが存在するような感じですね.
また,各ディレクトリはnotebook実行ごとに作られますが,
for d in [INPUT, SUBMISSION, EXP_MODEL, EXP_FIG, EXP_PREDS]:
os.makedirs(d, exist_ok=True)
exist_ok=Trueで既にあるディレクトリは作られずにスルーされるので,フォルダの中身のリセットなどはなく無問題です.また,コンペティションデータのロードは初回実行の1回のみなので,それだけ時間がかかります.
#utilsでは ログファイルが保存される場所を指定し,loggerの設定をします.
以上がColab環境のセットアップです.
次は Kaggle 環境でのセットアップです.
else:
print("This environment is Kaggle Kernel")
# set dirs
INPUT = "../input/commonlitreadabilityprize"
EXP, OUTPUT, SUBMISSION = "./", "./", "./"
EXP_MODEL = os.path.join(EXP, "model")
EXP_FIG = os.path.join(EXP, "fig")
EXP_PREDS = os.path.join(EXP, "preds")
# copy dirs
if Config.kaggle_dataset_path is not None:
KD_MODEL = os.path.join(Config.kaggle_dataset_path, "model")
KD_EXP_PREDS = os.path.join(Config.kaggle_dataset_path, "preds")
shutil.copytree(KD_MODEL, EXP_MODEL)
shutil.copytree(KD_EXP_PREDS, EXP_PREDS)
# make dirs
for d in [EXP_MODEL, EXP_FIG, EXP_PREDS]:
os.makedirs(d, exist_ok=True)
# utils
logger = Logger(EXP)
#set dirs,#make dirs は Kaggle 環境で Colab 環境のディレクトリ構成に合わせるためのパスの設定とフォルダ作成を行っています.logger の設定も同様です.
Kaggle 環境でのセットアップでの #copy dirsは,この notebook で作ったディレクトリ構成をもつ kaggle dataset または kaggle code の output dataset のパスを Config で指定すれば,その model フォルダと preds フォルダを中身丸ごと 実行する kaggle code の output フォルダにコピーします.こうすることで,後でもでてきますが kaggle code での推論を,Colab と同様のコードで行えるようにしました.
SetUp の最後はその他の設定と,インストールしたライブラリのインポートをしておしまいです.
# utils
warnings.filterwarnings("ignore")
sns.set(style='whitegrid')
seed_everything(seed=Config.seed)
# 2nd import
from transformers import AutoTokenizer, TFAutoModel, WarmUp
import tensorflow_addons as tfa
Load Data
# load data
train = pd.read_csv(os.path.join(INPUT, "train.csv.zip" if COLAB else "train.csv"))
test = pd.read_csv(os.path.join(INPUT, "test.csv"))
sample_submission = pd.read_csv(os.path.join(INPUT, "sample_submission.csv"))
if Config.debug:
train = train.sample(100).reset_index(drop=True)
# cv split
train["fold"] = -1
for i_fold, lst in enumerate(
KFold(
n_splits=Config.n_fold,
shuffle=True,
random_state=Config.seed).split(
X=train,
y=train[Config.target_col]
)):
if i_fold in Config.trn_fold:
train.loc[lst[1].tolist(), "fold"] = i_fold
#load_dataで Input フォルダにある学習データ,テストデータ,サンプルサブミッションデータをロードし,#cv_splitで train に fold 番号を付与します.
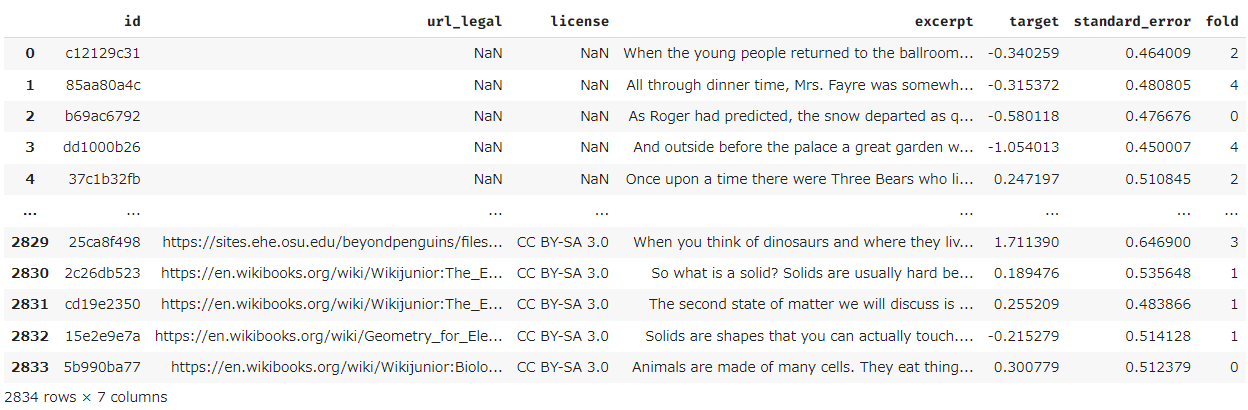
train はこんな感じです,右端のfold列が付与した fold 番号になります.
Model & Tokenizer
まず keras モデルを定義します.個人的に NLP コンペは使える事前学習済みモデルの多さから Pytorch での実装 kaggle code が多いように思いますが,今回は tensorflow/keras でモデルを構築しました.
また,tokenizer 定義ようの関数もここで用意しました.
def get_model(model_name, max_length):
transformer = TFAutoModel.from_pretrained(model_name)
input_ids = tf.keras.layers.Input(shape=(max_length, ), dtype=tf.int32, name="input_ids")
attention_mask = tf.keras.layers.Input(shape=(max_length, ), dtype=tf.int32, name="attention_mask")
x = transformer(input_ids, attention_mask=attention_mask)
x = x[0][:, 0, :]
output = tf.keras.layers.Dense(1, activation="linear")(x)
model = tf.keras.Model(inputs=[input_ids, attention_mask],
outputs=[output])
return model
def get_tokenizer(model_name):
return AutoTokenizer.from_pretrained(model_name)
Funcs
ここでは,学習・推論に使う関数などを定義していきます.
def get_score(y_true, y_pred):
"""evaluation"""
return mean_squared_error(y_true, y_pred) ** 0.5
def get_model_inputs(text, tokenizer, max_length):
"""bert model input"""
input_text = tokenizer.batch_encode_plus(
text,
padding="max_length",
truncation=True,
max_length=max_length,
)
return dict(input_text)
def get_tf_dataset(X, y=None):
"""transform to tf dataset"""
dataset = (tf.data.Dataset.from_tensor_slices((X, y)).
batch(Config.batch_size).
prefetch(tf.data.experimental.AUTOTUNE))
return dataset
def training(train_df, valid_df, filepath):
"""training for one fold"""
# model input
tokenizer = get_tokenizer(model_name=Config.model_name)
train_x = get_model_inputs(
text=train_df["excerpt"].tolist(),
tokenizer=tokenizer,
max_length=Config.max_length)
valid_x = get_model_inputs(
text=valid_df["excerpt"].tolist(),
tokenizer=tokenizer,
max_length=Config.max_length)
train_y = train_df[Config.target_col].values
valid_y = valid_df[Config.target_col].values
train_dataset = get_tf_dataset(X=train_x, y=train_y)
valid_dataset = get_tf_dataset(X=valid_x, y=valid_y)
print("ds",train_dataset)
# model setting
model = get_model(model_name=Config.model_name, max_length=Config.max_length)
optimizer = tfa.optimizers.AdamW(learning_rate=Config.learning_rate, weight_decay=1e-5)
loss = tf.keras.losses.MeanSquaredError()
metrics = tf.keras.metrics.RootMeanSquaredError()
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
checkpoint = tf.keras.callbacks.ModelCheckpoint(
filepath,
monitor="val_loss",
verbose=1,
save_best_only=True,
save_weights_only=True,
mode="min")
# model training
model.fit(
train_dataset,
epochs=Config.epochs,
verbose=1,
callbacks=[checkpoint],
batch_size=Config.batch_size,
validation_data=valid_dataset)
def inference(test_df, filepath):
# model inputs
tokenizer = get_tokenizer(model_name=Config.model_name)
test_x = get_model_inputs(
text=test_df["excerpt"].tolist(),
tokenizer=tokenizer,
max_length=Config.max_length)
test_dataset = get_tf_dataset(test_x)
# model setting
model = get_model(model_name=Config.model_name, max_length=Config.max_length)
model.load_weights(filepath)
# model prediction
preds = model.predict(test_dataset)
return preds.reshape(-1)
def train_cv(train):
oof = np.zeros(len(train))
for i_fold in range(Config.n_fold):
if i_fold in Config.trn_fold:
K.clear_session()
filepath = os.path.join(
EXP_MODEL,
f"{Config.name}-seed{Config.seed}-fold{i_fold}.h5")
valid_mask = np.array(train["fold"] == i_fold, dtype=bool)
tr_df, va_df = (train[~valid_mask].reset_index(drop=True),
train[valid_mask].reset_index(drop=True))
if not os.path.isfile(filepath): # if trained model, no training
training(tr_df, va_df, filepath)
preds = inference(va_df, filepath)
oof[valid_mask] = preds
# fold score
score = get_score(va_df[Config.target_col].values, preds)
logger.info(f"{Config.name}-seed{Config.seed}-fold{i_fold} >>>>> Score={score:.4f}")
return oof
def predict_cv(test):
K.clear_session()
fold_preds = []
for i_fold in range(Config.n_fold):
if i_fold in Config.trn_fold:
filepath = os.path.join(
EXP_MODEL,
f"{Config.name}-seed{Config.seed}-fold{i_fold}.h5")
preds = inference(test, filepath)
fold_preds.append(preds)
return fold_preds
def plot_result(target, oof):
"""regression result"""
fig, ax = plt.subplots(figsize=(8, 8))
ax = sns.distplot(target, label="y", color='cyan', ax=ax)
ax = sns.distplot(oof, label="oof", color="magenta", ax=ax)
ax.legend()
return fig
たくさんありますが,ここではtrain_cv関数だけ見ていこうと思います.train_cvはoof 予測値を返します.また,
for i_fold in range(Config.n_fold):
if i_fold in Config.trn_fold:
ここで trn_fold の時のみ training を実行してます.
if not os.path.isfile(filepath):
training(tr_df, va_df, filepath)
この if 文では,もし既に学習済みモデルが保存されていれば新しく学習をせずにスキップするようにしてます.こうすることで,複数のセッションで同じ notebook を回した時も,間違えて既に学習が完了したモデルを上書きせずにすみます. 実際の複数セッションによる実行方法は以下のような感じですね.
- 対象の colab notebook の「コピーを作成」
- trn_fold を notebook ごとで別々のものにする.(ex: [0, 1, 2], [3, 4]など)
- それらの notebook の実行完了後,どれかの trn_fold を すべてのfoldにして実行
- oof 予測値,test 予測値,submission file,学習済みモデルをゲット
Main
if not Config.only_inference:
# training
print("# ---------- # Start Training # ---------- #")
oof = train_cv(train)
oof_df = pd.DataFrame(oof, columns=[Config.target_col])
oof_df.to_csv(os.path.join(EXP_PREDS, "oof_df.csv"), index=False)
fold_mask = train["fold"].isin(Config.trn_fold)
target = train[Config.target_col]
# get oof score
score = get_score(target[fold_mask].values, oof[fold_mask])
logger.info(f"OOF-Score >>>>> {score:.4f}")
# save result
fig = plot_result(target[fold_mask].values, oof[fold_mask])
fig.savefig(os.path.join(EXP_FIG, "regression_result.png"), dpi=300)
# prediction
print("# ---------- # Start Inference # ---------- #")
fold_preds = predict_cv(test)
fold_preds_df = pd.DataFrame()
for i in range(len(fold_preds)): # single fold ok
fold_preds_df[f"FOLD{i}"] = fold_preds[i]
fold_preds_df.to_csv(os.path.join(EXP_PREDS, f"fold_preds_df.csv"), index=False)
# make submission
print("# ---------- # Make Submission # ---------- #")
sample_submission["target"] = fold_preds_df.mean(axis=1)
filename = Config.name + ".csv" if COLAB else "submission.csv"
sample_submission.to_csv(os.path.join(SUBMISSION, filename), index=False)
次に Main です.ここは上で定義した関数やデータを用いて学習・推論・サブミッションファイルの作成を行います.
if not Config.only_inference:の条件下では学習がスキップされます.ただし学習済みモデルが保存されていれば,学習が実行されたとしても,そのモデルがロードされ validation dataに対する予測のみが実行されるので,再度学習が実行されることはならないです.
また,filename = Config.name + ".csv" if COLAB else "submission.csv"にあるように,kaggle code 上で実行しサブミッションファイルを作成し提出する今回のようなコードコンペでは,サブミッションファイル名を submission.csvにしないと提出できない罠があるので注意です.
# upload output folder to kaggle dataset
if Config.upload_from_colab:
from kaggle.api.kaggle_api_extended import KaggleApi
def dataset_create_new(dataset_name, upload_dir):
dataset_metadata = {}
dataset_metadata['id'] = f'{os.environ["KAGGLE_USERNAME"]}/{dataset_name}'
dataset_metadata['licenses'] = [{'name': 'CC0-1.0'}]
dataset_metadata['title'] = dataset_name
with open(os.path.join(upload_dir, 'dataset-metadata.json'), 'w') as f:
json.dump(dataset_metadata, f, indent=4)
api = KaggleApi()
api.authenticate()
api.dataset_create_new(folder=upload_dir, convert_to_csv=False, dir_mode='tar')
dataset_create_new(dataset_name=EXP, upload_dir=OUTPUT_EXP)
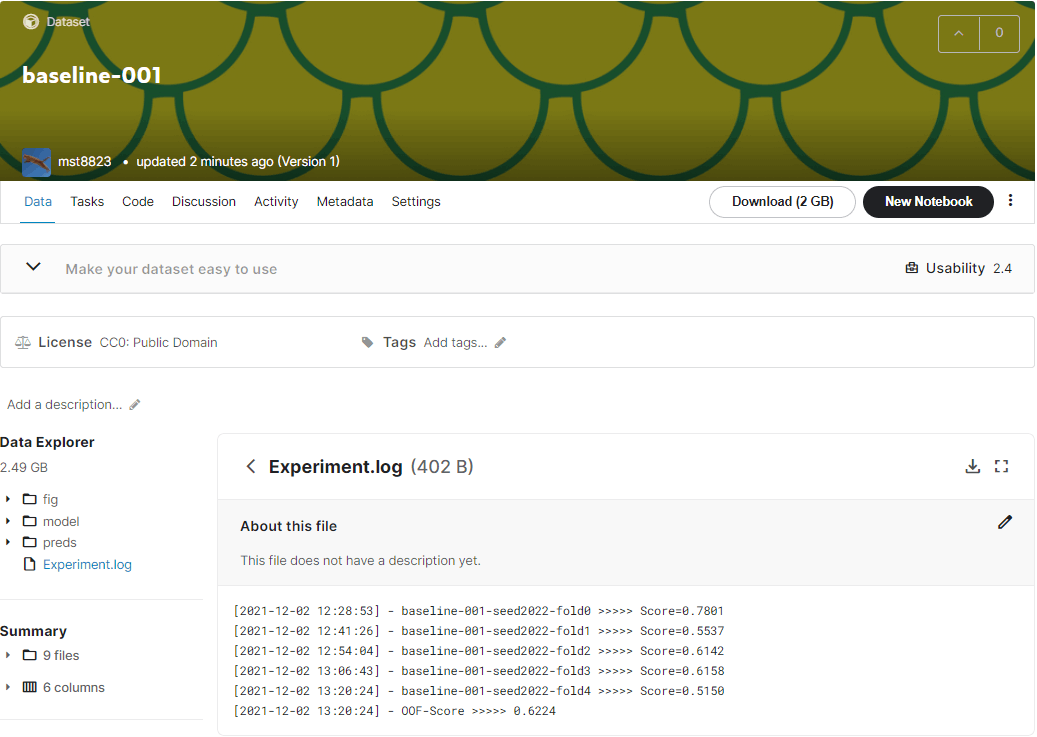
コードとしては最後です.これは Output\EXP のフォルダごと自分 kaggle private dataset にアップロードするものです.こちらの記事を参考にさせていただきました.
アップロード後の kaggle dataset はこんな感じです.(公開のため public dataset に切り替えています) 保存したログも一緒にアップロードされてますね.
Submit する
上のコードを全部実行して,output したフォルダを kaggle dataset にアップロードできれば,あとは このコードを kaggle code 上で実行して,作成された submission.csvを提出すれば完了です.
kaggle code 上での実行は以下の通りです.
- コードをkaggle code の notebook にコピー
- アップロードした dataset を その notebook の input に設置.このとき,roberta-base の事前学習重みも inputに設置する必要があります.(コードコンペの提出用notebookの実行時はinter netをoff にする必要があります)

- Config の model_name と kaggle_dataset_path を変更.only_inference=Trueにしてもok
model_name = "../input/roberta-base"
kaggle_dataset_path = "../input/baseline-001"
- AcceleratorをGPUにして Save & Run All (Commit)を押して待つ
- 作成された
submission.csvファイルを提出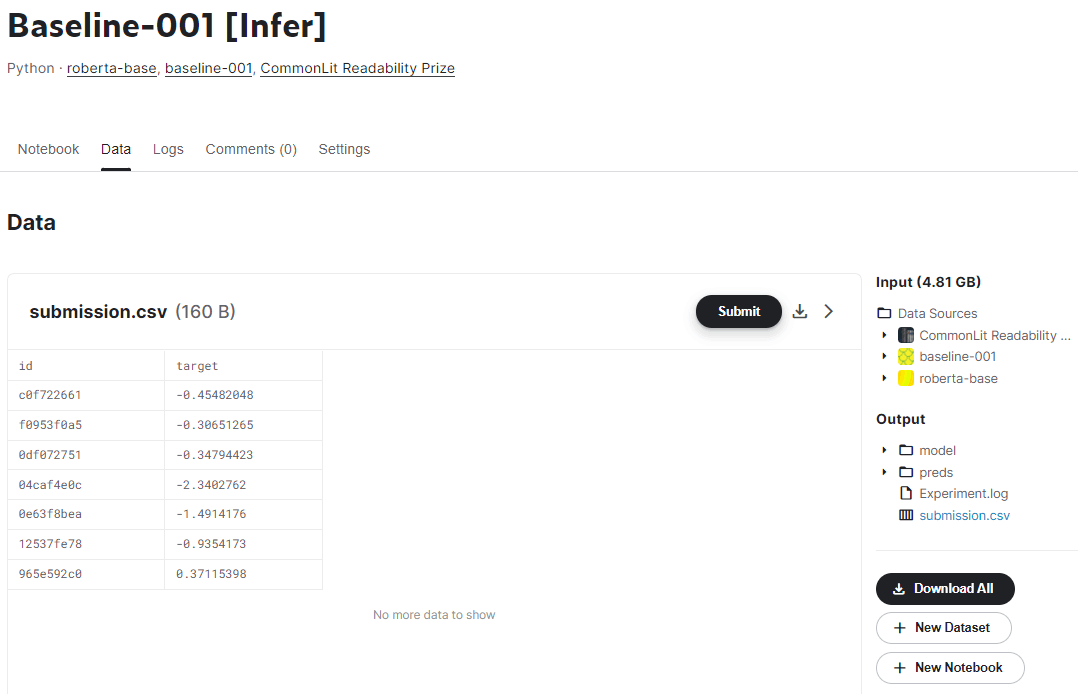
最後に実際のスコアを見てみましょう.結果発表~!!!!!

ハイパラもモデルも特に何も考えてないのでこんなもんですね.2300/3633 位でした笑
以上でパイプライン(?)の作成~サブミットまでは終わりになります.
後はおまけと感想だけです,長い記事を読んでいただきありがとうございました.これが何かの役に立てばうれしいです.
実際にサブミットしたコードはこちらです.
おまけ
今回のNLPコードコンペなど,インターネットoffの状態で事前学習モデルが必要なときがあります.私は他の人がkaggle dataset にあげてくださっているものをありがたく使っているのですが,自分でも同様に kaggle dataset にアップロードする方法を備忘録として載せておきます.
from kaggle.api.kaggle_api_extended import KaggleApi
def dataset_create_new(dataset_name, upload_dir):
dataset_metadata = {}
dataset_metadata['id'] = f'{os.environ["KAGGLE_USERNAME"]}/{dataset_name}'
dataset_metadata['licenses'] = [{'name': 'CC0-1.0'}]
dataset_metadata['title'] = dataset_name
with open(os.path.join(upload_dir, 'dataset-metadata.json'), 'w') as f:
json.dump(dataset_metadata, f, indent=4)
api = KaggleApi()
api.authenticate()
api.dataset_create_new(folder=upload_dir, convert_to_csv=False, dir_mode='tar')
# In a google colab install git-lfs
!sudo apt-get install git-lfs
!git lfs install
# Then
!git clone https://huggingface.co/microsoft/deberta-v3-small
# upload to kaggle dataset
dataset_create_new(dataset_name="deberta-v3-small", upload_dir="/content/deberta-v3-small")
なんとなく deberta-v3 をアップロードしてみました.ほぼこちらのスレッドの通りです.
感想
今回の notebook では Config における設定項目も最小限程度に抑えたつもりなので,変更できる箇所が限られています.私が実際に使うときは,スケジューラーやその他のハイパラの設定やTPUを用いた学習ができるようにして運用していました.また他の実験管理ツール(W&B,MLflowなど)の使用も考えられます.
また,パイプライン(?)といっても色々なところが具体的に書いてあります.そのあたりはコンペの都度変える必要があるので,もっと抽象化できるところもあると思います.もしアドバイスなどあれば教えていただければ嬉しいです.
ここまで読んでいただいてありがとうございました!またどこかのコンペでお会いしましょう!
参考
- https://www.kaggle.com/yasufuminakama/ventilator-pressure-lstm-starter
- https://github.com/ghmagazine/kagglebook/blob/master/ch04-model-interface/code
- https://qiita.com/kaggle_grandmaster-arai-san/items/d59b2fb7142ec7e270a5
- https://kopaprin.hatenadiary.jp/entry/2020/05/07/083000
- https://www.currypurin.com/entry/2021/03/04/070000
- https://discuss.huggingface.co/t/download-models-for-local-loading/1963
Discussion